
Abstract
This paper proposes an uncalibrated adaptive visual servoing (VS) control framework based on dual-camera fusion to address key technical challenges in robotic visual servoing systems, including real-time state estimation, multi-space coordination, and dynamic target tracking. By combining the complementary advantages of “eye-in-hand” and “eye-to-hand” camera configurations, an adaptive switching mechanism is designed to achieve coordinated control between image space and Cartesian space, addressing convergence problems of traditional methods during target occlusion or field-of-view loss. Key features of the framework include: an uncalibrated control method based on the image Jacobian matrix; adaptive parameter adjustment based on Kalman filtering (KF); and a dual-camera fusion switching strategy. Experiments show the method achieves a positioning accuracy of 1.197 mm and an orientation accuracy of 0.149° in a representative static positioning task; demonstrates effective performance in scenarios involving out-of-view target acquisition and occlusion recovery; and reduces tracking errors by 13%–28% while shortening convergence time by 5%–32% in dynamic tracking tasks. This framework provides a practical technical approach for visual servoing systems in complex environments, showing potential for broad industrial applications.
Introduction
Visual servoing (VS) has emerged as a fundamental technology in automation and intelligent manufacturing, offering precise positioning and tracking capabilities for complex robotic tasks. VS systems guide robot motion through image feature feedback, directing feature points toward desired positions. 1 The non-contact measurement and real-time feedback characteristics of VS have enabled its application in industrial assembly, agricultural harvesting, and dynamic target tracking. However, with Industry 4.0’s demands for enhanced system adaptability, VS technology continues to face challenges in dynamic environment adaptation, real-time state estimation, target occlusion handling, and multi-space coordination. These limitations restrict its deployment in unstructured environments and necessitate more sophisticated control strategies.
Traditional VS technology relies on two primary configuration paradigms. The “eye-in-hand” configuration acquires local image features by mounting cameras on robot end-effectors. Li et al. 2 developed a hybrid solution combining PBVS with binocular cameras and monocular uncalibrated visual servoing for underwater environments, addressing system uncertainties while experiencing some complexity in switching mechanisms. Ahmad et al. 3 employed deep learning for watermelon flower size and orientation estimation, achieving positioning errors of 1.028 cm and improving agricultural automation efficiency, though adaptability to lighting variations and occlusion remains limited. Drummond and Cipolla 4 investigated Lie algebras in affine transformations, constructing a framework for handling continuous disturbances and providing theoretical foundations, though practical applicability to complex three-dimensional targets requires further validation. Chang 5 proposed combining “look-then-move” and “visual tracking” approaches for smartphone assembly, addressing field-of-view limitations while maintaining room for improvement in long-distance initial positioning efficiency. Zhang et al. 6 designed “rotational perspective moment” features for multi-rotor aircraft control precision, Cui et al. 7 applied “eye-in-hand” configuration for flexible refueling boom vibration control, while Li et al. 8 implemented a cherry tomato harvesting system using RGB-D cameras, achieving a 96.25% success rate. Zheng et al. 9 and Yang et al., 10 respectively, applied the “eye-in-hand” configuration to quadrotor positioning and fixed-wing UAV tracking tasks. However, this configuration remains susceptible to failure during target occlusion or rapid movement, exposing its operational limitations.
In contrast, the “eye-to-hand” configuration provides global perspective through fixed cameras. He et al. 11 developed a 2.5D visual servoing method for textureless part grasping, though with limited support for local fine operations. These methods often exhibit reduced control precision when lacking local feature feedback. Rastegarpanah et al. 12 optimized hybrid visual servoing trajectory efficiency through 3D feature estimation, while Rastegarpanah et al. 13 introduced adaptive gain mechanisms to enhance system performance, though multi-camera collaborative data fusion requires further development. Both configurations possess distinct characteristics, yet single perspectives struggle to balance global and local requirements, providing motivation for this paper’s dual-camera fusion architecture.
Recent developments in VS technology have addressed dynamic target tracking. Gao et al. 14 developed neural network adaptive controllers for underwater uncertainty handling, though dependence on training data affects real-time performance. Li et al.15,16 proposed uncalibrated tracking methods for dynamic feature points and fruits, respectively, handling unknown motion parameters while lacking effective recovery mechanisms for out-of-view targets. Hao et al. 17 combined DETR and BILSTM for trajectory prediction in object detection, introducing Kolmogorov–Arnold Networks (KANs) to improve model efficiency and reduce complexity. Wang et al. 18 enhanced moving target prediction precision by combining hand-eye vision with end-effector pose, though stability during velocity variations requires improvement. While these studies advanced dynamic adaptability, continuous tracking capability for out-of-view targets remains insufficient, motivating the global camera guidance approach introduced in this paper.
In industrial applications, VS technology has demonstrated progress. Liu et al. 19 integrated vision with laser sensors, reducing rivet positioning time to 1–5 s for high-efficiency requirements. Chen et al. 20 developed collision-free IBVS path planning achieving 100% collision avoidance through systematic design, while Li et al. 21 enhanced depth estimation through RGB-D technology, improving real-time performance and accuracy. However, these methods often require precise calibration or specific hardware, with limited flexibility under environmental variations, establishing the context for this paper’s uncalibrated strategy.
Machine learning has advanced adaptive VS methods. Gu et al. 1 and Shi et al. 22 implemented adaptive servo gain adjustment through Q-learning, improving convergence speed while inadequately addressing target loss scenarios. Zhang et al. 23 developed RARLC controllers that reduced errors within three cycles, demonstrating rapid learning capabilities. Hernandez-Barragan et al. 24 employed damped least squares to mitigate singularities, enhancing redundant robot manipulability, while Zhong et al. 25 and Chang et al. 26 combined Kalman filtering to address uncalibrated control and depth estimation challenges, respectively. Xie et al. 27 developed data-driven IBVS for 7-DOF manipulators, though dependence on extensive data affects real-time performance. These methods enhanced adaptability but remain insufficient for extreme occlusion and target loss scenarios.
To address single configuration limitations, hybrid VS methods have gained attention. Liu and Dong 28 applied polar coordinate RMPC to IBVS, optimizing 6-DOF manipulator trajectories; Yang et al. 29 proposed three-stage motion planning for flexible joint manipulator applications; Brown et al. 30 reduced PBVS errors through ALS methods. Rotithor et al. 31 improved insertion task control through DMP and IBVS switching. Chaber et al. 32 simplified MPC models to reduce computational requirements, Chen et al. 33 combined fuzzy neural networks to address SMC chattering issues, while Li et al. 34 optimized image moment features for ultra-redundant manipulator tracking. Although these methods performed effectively in specific scenarios, global and local information fusion remains limited, particularly regarding out-of-view target handling and multi-camera collaboration. To our knowledge, no research has fully exploited the complementary characteristics of “eye-in-hand” and “eye-to-hand” cameras to design VS systems that balance global monitoring and local precise control.
To address these challenges, this paper proposes a dual-camera fusion control architecture that enhances system environmental adaptability by integrating the complementary advantages of “eye-in-hand” and “eye-to-hand” configurations. Compared to single-perspective approaches,20,34 this architecture mitigates target loss risks in occlusion or limited field-of-view scenarios through dynamic coordination of multimodal visual information, leveraging global camera guidance for control restoration and addressing limitations in dynamic tracking methods.15,17 We develop a Kalman filter-based adaptive regulation mechanism that optimizes dynamic tracking stability through global velocity estimation, advancing beyond traditional local error adjustments.1,22 Furthermore, through motion driving strategies based directly on image features, this architecture circumvents traditional calibration process complexity,5,21 optimizing system initialization and enhancing operational flexibility. Experimental results demonstrate that the proposed method achieves improved performance in static positioning precision and dynamic tracking compared to traditional methods, providing a systematic solution for VS technology in unstructured environments.
The contributions of this paper are reflected in the following three aspects:
A hybrid visual servoing architecture that synergistically fuses two control schemes: Position-Based Visual Servoing (PBVS) for long-range guidance using a global camera, and Image-Based Visual Servoing (IBVS) for high-precision alignment using a local “eye-in-hand” camera. This dual-mode framework addresses complex scenarios including target occlusion and out-of-view acquisition.
An adaptive control mechanism featuring global-local synergy that utilizes a Kalman filter with global camera observations to estimate target velocity. This velocity information proactively tunes local controller gains, enhancing performance in dynamic tracking tasks.
A hybrid switching strategy that combines global guidance with local alignment. This strategy, based on error thresholds and hysteresis mechanisms, ensures smooth and reliable transitions between PBVS and IBVS modes while providing fault tolerance for local vision failure.
Dual-camera fusion visual servoing system
To address the precision and reliability demands of industrial target localization and tracking, this paper presents a hybrid visual servoing control framework based on “eye-in-hand” and “eye-to-hand” dual-camera configurations. The overall control flow, depicted in Figure 1, fuses the long-range guidance of Position-Based Visual Servoing (PBVS) with the close-range precision of Image-Based Visual Servoing (IBVS).

Hybrid visual servoing framework with dual-camera integration.
The physical implementation of this framework, shown in Figure 2, integrates two complementary camera configurations: a global camera fixed above the workspace for long-range guidance and occlusion handling, and a local camera mounted on the end-effector for high-precision final alignment. To transform raw camera images into control-relevant inputs, the system employs a feature extraction and processing pipeline detailed in Figure 3. This pipeline consists of two parallel channels: the RGB channel locates feature points using a gradient-based corner detection algorithm with sub-pixel refinement, while the depth channel extracts corresponding depth values. The criterion for corner detection is given by:
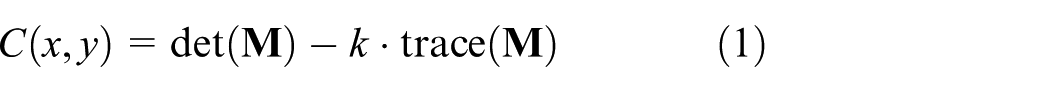
For features captured by the global camera, the target pose in the robot base frame,

where

These spatial pose relationships form the mathematical foundation for the PBVS control component.
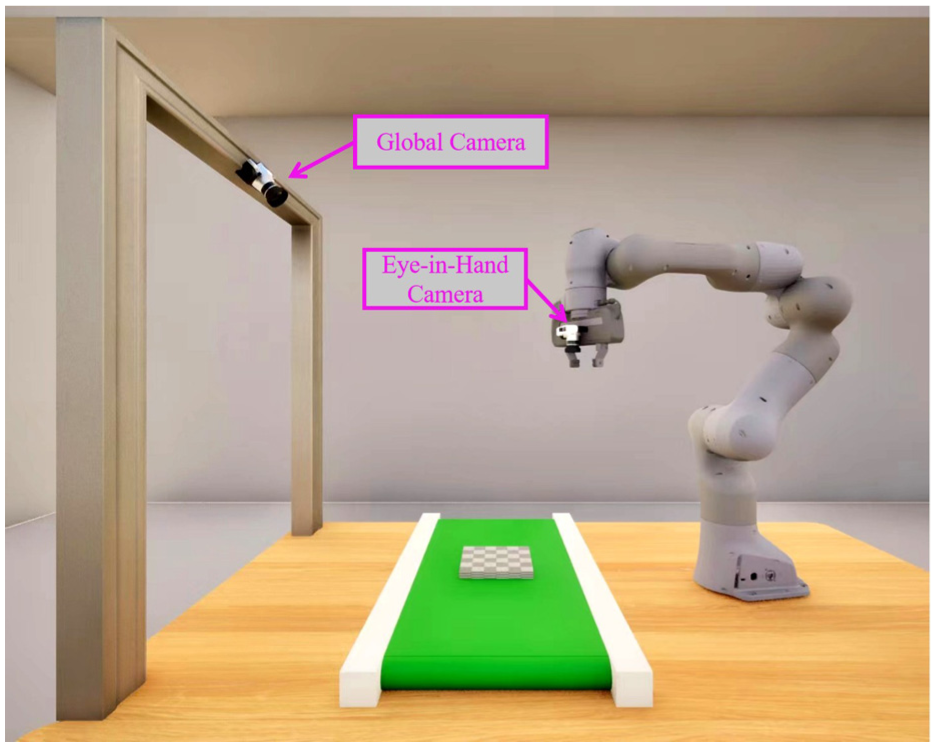
Dual-camera configuration simulation.

Feature extraction and processing pipeline.
This integration of a dual-camera configuration and a dedicated information processing pipeline establishes a complete hybrid control framework. The subsequent sections will detail its uncalibrated control method, state estimation, and adaptive optimization strategy.
Uncalibrated visual servoing control method
The core objective of the proposed control method is to minimize the image feature error vector

where

Here,
For the complete system of
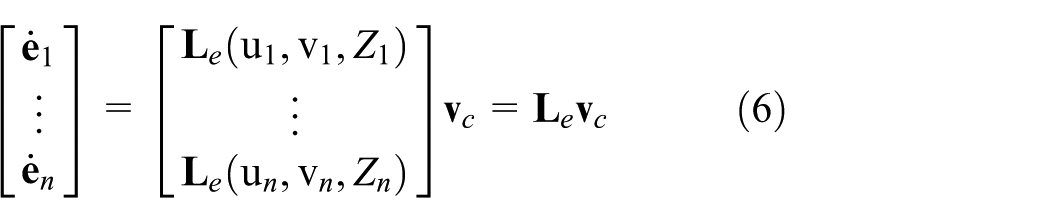
In this expression,
Based on this kinematic relationship, a classical Image-Based Visual Servoing (IBVS) control law is formulated to compute the camera velocity command

where

where
This IBVS controller is integrated into a hybrid switching strategy with a PBVS controller to leverage the strengths of both configurations. To ensure stable transitions and explicitly prevent mode chattering—a key concern in switching control—a hysteresis mechanism is implemented:

The thresholds,
Furthermore, to enhance the smoothness of the robot’s motion, particularly during mode transitions, a rate-limiting module is implemented at the low-level control interface. This module independently constrains each component of the 6D command acceleration vector, which is composed of a linear acceleration

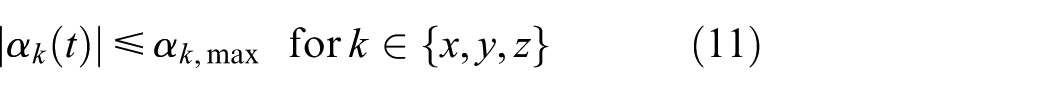
where
State estimation and adaptive optimization
To enhance the system’s performance in dynamic environments, this study proposes a state-aware adaptive PID control strategy. The core of this strategy is its ability to dynamically optimize control gains based on the target’s real-time motion characteristics. To acquire these crucial dynamic states—specifically the target’s 3D position and velocity—a classic Kalman filter is employed as the state estimator. This section will first detail the implementation of the state estimator and then elaborate on the novel adaptive tuning law that relies on its output.
Target state estimation using a Kalman filter
A Kalman filter based on a six-dimensional state space is employed to simultaneously estimate the target’s position and velocity. The state vector

where

where
The process noise covariance matrix

where

This corresponds to the position measurement noise from the ZED camera. The filter is implemented using standard recursive prediction and update steps, with the measurement matrix

To enhance practical performance, a position differencing method aids velocity estimation. Here, the 3D position measurement vector at the previous time step,

Furthermore, an anomaly detection mechanism resets the filter if the estimated velocity magnitude exceeds 5 m/s, improving robustness.
For the standard constant velocity model adopted in this study, its controllability and observability are theoretically guaranteed, which ensures the convergence of the filter’s estimation error and establishes a foundation for long-term stable estimation.
Adaptive PID parameter tuning
The proposed adaptive tuning strategy directly leverages the target’s velocity vector
A nonlinear gain tuning law is introduced for the eight dual-axis PID controllers. The design of this law is formulated as:

where the base gain

The lower bound prevents the control gain from being nullified, while the upper bound acts as a safety barrier against excessive gains.
To theoretically prove the reliability of this adaptive controller, its stability is analyzed using Lyapunov’s second method. A Lyapunov candidate function

Here,
Experimental results and analysis
Hardware platform configuration
The experimental platform for this study consists of a 7-degree-of-freedom Franka Emika Panda collaborative robot and a dual-camera system, as shown in Figure 4. The vision system employs a hybrid “eye-in-hand” and “eye-to-hand” configuration: an Intel RealSense D415 camera is mounted on the end-effector as a local camera, and a ZED 2 stereo camera is fixed above the workspace as a global camera. A conveyor belt system is integrated to simulate dynamic industrial scenarios. The entire system utilizes a dual-host architecture for vision processing and robot control, communicating via Ethernet at a servoing frequency of 25 Hz.

Schematic diagram of the experimental platform.
Performance evaluation metrics
To quantitatively evaluate the proposed method’s performance, a suite of core metrics covering both image and Cartesian space was established. Experiments were conducted using a 3 × 4 checkerboard as the target, with its feature points and the end-effector pose providing the respective error benchmarks for the image and Cartesian spaces.
In the image space, the feature point error (

In Cartesian space, the end-effector pose is evaluated from two dimensions: accuracy and stability. Pose accuracy is quantified by positional and orientation errors: the positional error (

while the orientation error (

On the other hand, the system’s steady-state stability is measured by the positional standard deviation (

Furthermore, dynamic performance is assessed by the convergence time and steady-state tracking error.
Static target positioning accuracy validation
To rigorously evaluate the static positioning performance of the proposed dual-camera fusion hybrid control method, this section analyzes a representative positioning task. In this task, the robot end-effector is required to move from an initial standby region to a precise target pose within the forward workspace. This process simulates a common industrial workflow and is designed to test the method’s accuracy and stability throughout the entire motion. For performance comparison, the proposed method was tested against a conventional Position-Based Visual Servoing (PBVS) method under identical task conditions.
The complete process and results of this positioning task are presented in Figures 5 and 6. In the 3D spatial trajectory plot (Figure 5), the trajectory corresponding to the proposed method exhibits a smooth path and converges precisely to the desired target point. In contrast, the trajectory of the conventional PBVS method shows a clear spatial deviation from the target at the end of the task. This performance difference is further confirmed by the positional error convergence comparison plot (Figure 6), which shows that the positioning error (

3D trajectories for static positioning: proposed method versus conventional PBVS.

Positional error (
The final quantitative metrics of the experiment confirm the aforementioned visual observations. The proposed method achieves a final positional error of 1.197 mm and an orientation error of 0.149°, demonstrating higher positioning accuracy compared to the 37.85 mm and 2.163° achieved by the PBVS method. Regarding steady-state stability, the positional standard deviation of the proposed method is 0.322 mm, which is comparable to the 0.309 mm of the PBVS method. This indicates that good stability is maintained while accuracy is improved.
The observed performance difference stems from the novel control framework proposed in this study. The core advantage of this framework lies in the combination of dual-camera synergy and adaptive control. In the final positioning phase, the system switches to image-based closed-loop control. This approach not only reduces the reliance on precise hand-eye calibration, but its adaptive gain strategy also optimizes the error convergence process, jointly ensuring the final positioning accuracy. In contrast, the performance bottleneck of conventional PBVS lies in its complete reliance on 3D reconstruction. Its accuracy is inevitably limited by factors such as camera depth uncertainty and eye-to-hand calibration error, and its fixed linear control law is ill-suited for the final fine-tuning task required to achieve millimeter-level precision.
Sensitivity analysis to depth measurement noise
To investigate the system’s performance under sensor inaccuracies, this section evaluates the impact of depth measurement noise on both positioning accuracy (
The results are presented in Figure 7. The plots demonstrate a non-linear relationship between noise level and performance degradation. Notably, the system exhibits a degree of tolerance to minor noise: as the standard deviation of the depth noise (
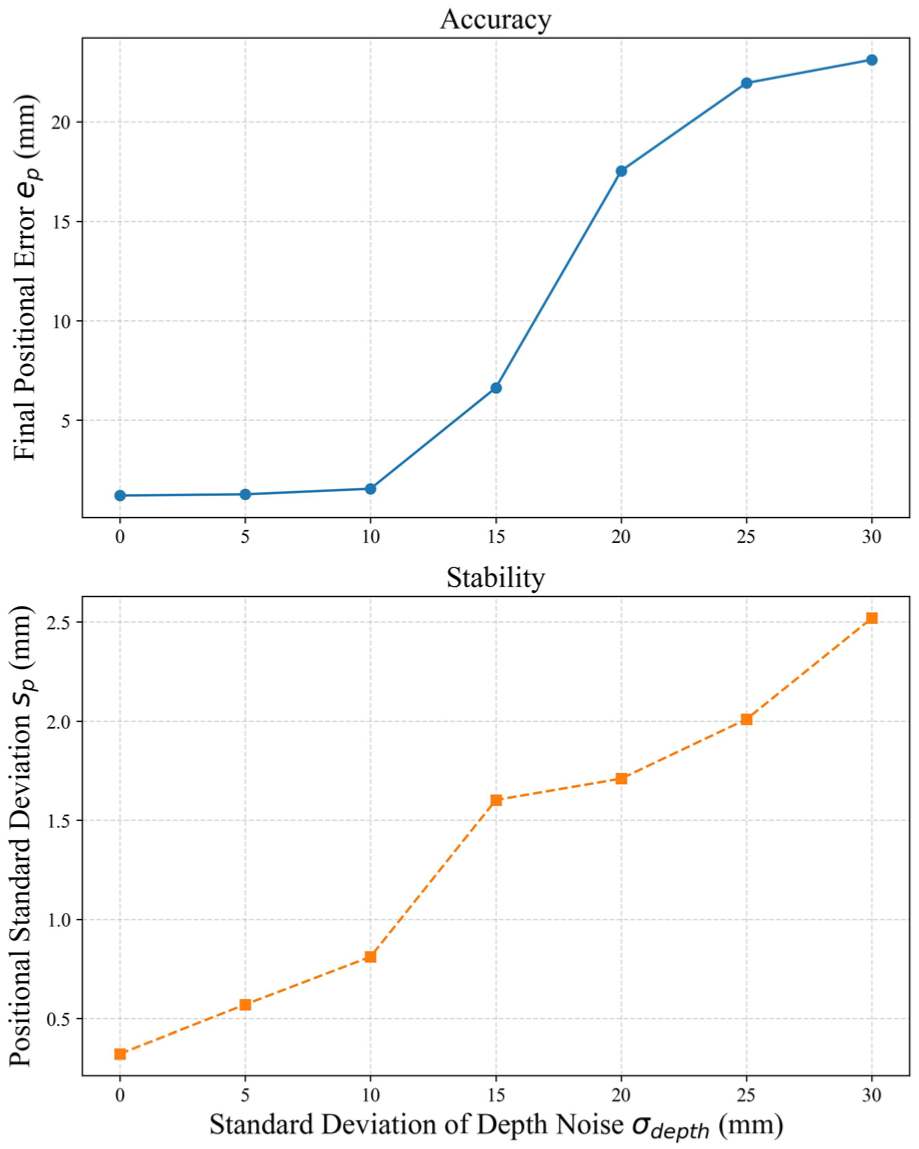
Analysis of the impact of depth measurement noise on positioning accuracy (
Experiments in challenging scenarios
To evaluate the performance of the proposed framework under non-ideal conditions, this section presents experiments in two typical challenging scenarios: out-of-view target acquisition and temporary local camera occlusion. These experiments are designed to validate the system’s stability and recovery capabilities when subjected to such disturbances.
Out-of-view target acquisition
This experiment validates the system’s capability to acquire a target initially located outside the local camera’s field of view. The test involves the robot moving from a fixed initial pose to four different target points within the workspace. During this process, the system first utilizes the global camera for long-range guidance (PBVS mode) and then automatically switches to the local camera (IBVS mode) to perform precise positioning once the target enters its view. As illustrated in Figure 8, the trajectories for all test cases successfully converged, with the final positioning errors remaining at the millimeter level, consistent with the static positioning results. These outcomes demonstrate that the hybrid switching strategy enables reliable mode transitions. The transition from PBVS to IBVS is smooth, with no significant jitter caused by the switching observed in the trajectories, which reflects the strategy’s stability and effectiveness in handling large initial deviations by combining the advantages of both methods.

Cartesian end-effector trajectories for four target positions.
Occlusion recovery experiment
To test the system’s recovery capability upon temporary loss of local visual information, this experiment applied a temporary occlusion to the local camera as the system approached a steady state. During the occlusion, the system automatically switches to PBVS mode to maintain pose stability using information from the global camera, thus preventing task interruption. After the occlusion is removed, it switches back to IBVS mode to resume precise positioning. The experiment was conducted under two conditions, with the target at the center and the edge of the field of view.
As shown in Figure 9, the system successfully recovers and converges quickly in both conditions. The final image error stabilizes at ∼0.5 pixels, with the 3D positional error in the 2–3 mm range. This successful recovery is attributed to the PBVS control during the occlusion phase, which prevents excessive end-effector drift and keeps the initial error for recovery within a threshold acceptable for IBVS. The entire recovery process exhibits no significant velocity spikes or oscillations, demonstrating that the framework’s switching mechanism provides an effective fault-tolerance and recovery strategy, which is important for enhancing system reliability in complex environments.
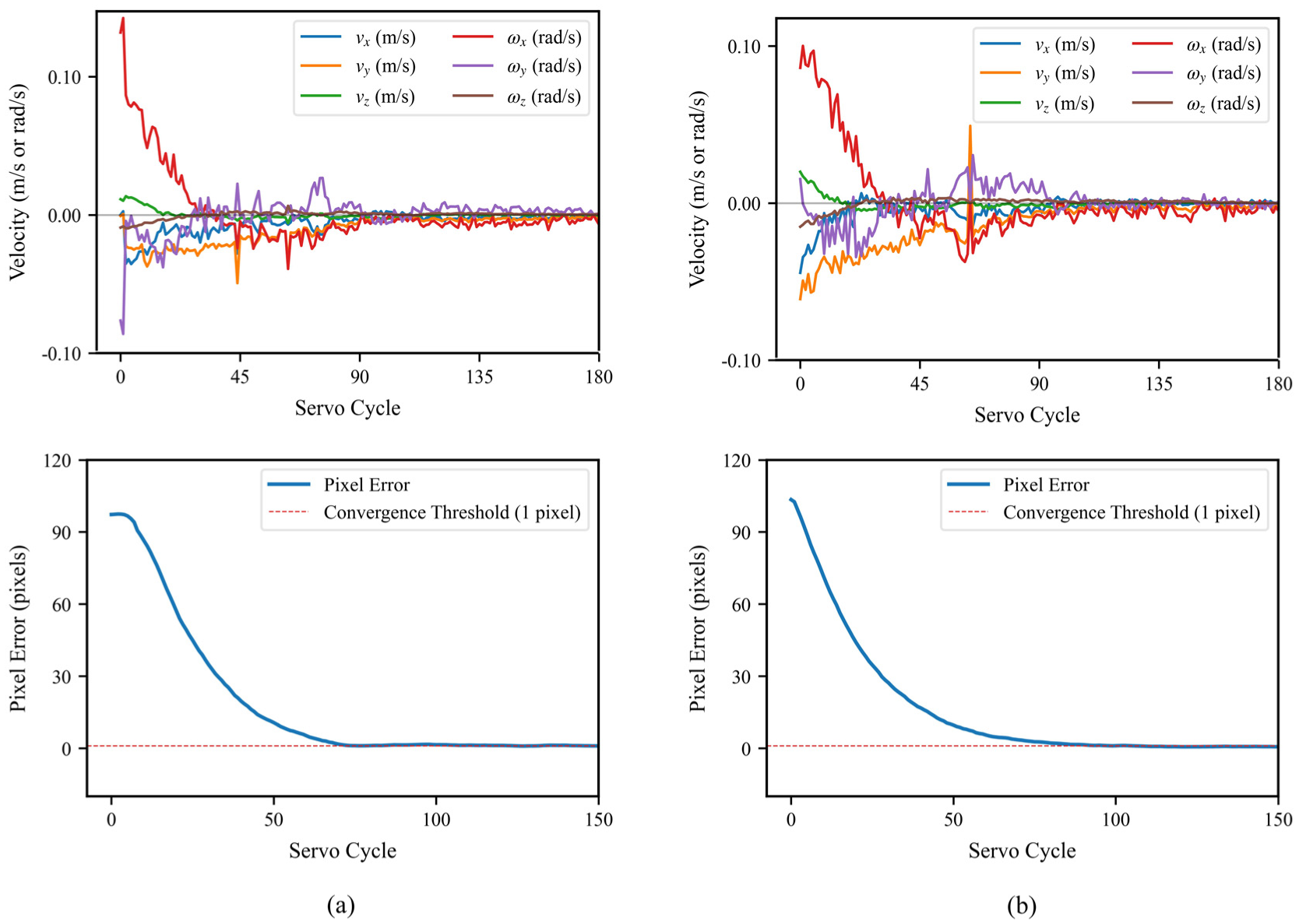
End-effector 6-DOF velocity and feature error convergence post-occlusion: (a) center of field of view; (b) edge of field of view.
Dynamic scene experiments
This section evaluates the dynamic tracking performance of the proposed framework under various target poses and velocities. To examine the effectiveness of the adaptive control strategy, the proposed method is compared against a non-adaptive baseline. This baseline, referred to as “Ours w/o Comp.” in the results, utilizes the same dual-camera switching framework as the proposed method but employs a fixed-gain controller (
Tracking performance across different poses
To investigate the system’s tracking capability for dynamic targets across diverse spatial poses, experiments were conducted with a conveyor belt speed fixed at 2.3 cm/s under four pose conditions: translation, rotation, tilt, and a combination of rotation and tilt. The proposed method integrates a Kalman filter with an adaptive PID controller. Performance was assessed using steady-state tracking error (
Dynamic tracking performance comparison across pose variations.

The results in Table 1 show that the proposed method achieved improved performance across all conditions. Compared to the baseline, in the translation scenario, the steady-state error decreased to 21.636 pixels and convergence time shortened to 3400 ms, representing reductions of 15% and 32%, respectively. For the rotation case, the error was 21.627 pixels, lower than the baseline’s 27.188 pixels. Under the tilt condition, the error was 21.423 pixels, compared to the baseline’s 24.611 pixels. In the complex rotation-plus-tilt scenario, the proposed method’s error of 20.865 pixels also reflected an improvement over the baseline’s 25.252 pixels.
This performance improvement stems from the dynamic compensation mechanism. The Kalman filter estimates target velocity, and the adaptive PID gain tuning allows the controller to better match the target’s dynamics, thereby enhancing tracking performance. Figure 10 illustrates this process for each of the four conditions. It can be observed that the error stabilizes quickly even in the complex rotation-plus-tilt scenario, demonstrating the effectiveness of the adaptive strategy. Although the baseline method exhibited a slightly lower variance in some non-rotational conditions (e.g. 0.074 vs 0.131 pixel2 in translation), the proposed method showed a lower variance in the rotation case (0.164 vs 0.515 pixel2). Overall, the adaptive approach achieves a favorable balance between tracking accuracy, convergence speed, and stability.

Dynamic tracking performance comparison at 2.3 cm/s conveyor speed. The figure includes four conditions: (a) translation, (b) rotation, (c) tilt, and (d) rotation combined with tilt. Each condition comprises three subfigures from top to bottom: (i) tracking process photographs, (ii) end-effector pose diagrams, and (iii) error variation comparison curves.
Tracking performance across different speeds
This subsection further examines tracking performance across a range of conveyor speeds, from 2 to 8 cm/s, covering low-to-high velocity ranges. To exclude interference from pose variations, all experiments utilized a uniform, basic horizontal pose to ensure consistency. Table 2 details the comparative results.
Dynamic tracking performance comparison across speed variations.

The results show that while the tracking error for both methods increases with speed, the proposed method maintains a lower error across all tested velocities. This performance difference becomes more apparent at higher speeds; for instance, at 8 cm/s, the error for the proposed method was 71.33 pixels, a 28% reduction compared to the baseline’s 99.45 pixels. This is attributed to the adaptive gain mechanism’s response to varying speeds: at low speeds, the gains adjust moderately to maintain stability, while at higher speeds, the controller increases the gains to boost dynamic response. The bar charts in Figure 11 visualize these performance metrics. These results confirm the adaptive strategy’s ability to balance error suppression with stability across different dynamic conditions.
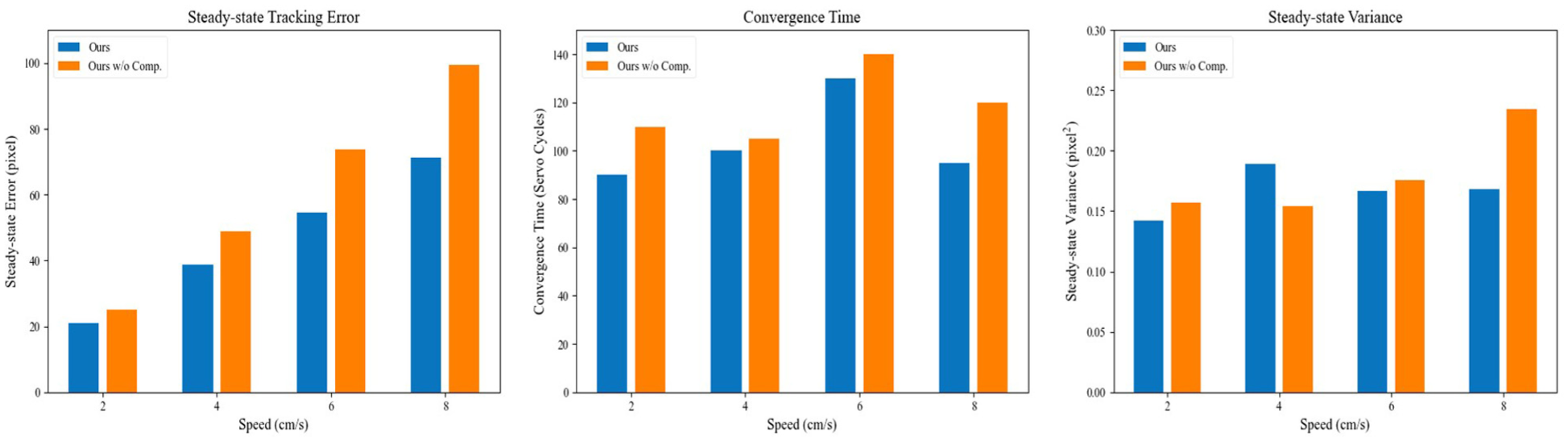
Dynamic tracking performance comparison across different speeds.
Tracking adaptability under speed step disturbances
This section assesses the system’s tracking adaptability under abrupt speed changes. To emphasize the effects of velocity transients, experiments were conducted using a horizontal target pose, simulating two step disturbances introduced at ∼10th servoing cycle: (1) an acceleration from 2 to 8 cm/s and (2) a deceleration from 5 to 0 cm/s.
Figure 12 illustrates the resulting error variations. In the acceleration case (a), the proposed method demonstrates a faster response post-disturbance, with its steady-state error converging to a mean of 78.324 pixels, compared to the baseline’s slower stabilization at 102.920 pixels. In the deceleration case (b), where the target comes to a complete stop, the proposed method reaches the convergence threshold (

Tracking error comparison under speed disturbances: (a) speed increases from 2 to 8 cm/s; (b) speed decreases from 5 to 0 cm/s.
Conclusion
This paper proposed an uncalibrated adaptive visual servoing framework based on dual-camera fusion. By leveraging the complementary strengths of “eye-in-hand” and “eye-to-hand” configurations through a hybrid switching strategy, the proposed method addresses challenges such as target occlusion and limited fields of view, while avoiding the need for complex hand-eye calibration. A key feature is the adaptive control strategy that fuses global velocity estimates with local image error for dynamic gain compensation, which was shown to improve the tracking of moving targets. Experimental results demonstrated the framework’s capabilities, showing millimeter-level accuracy in static positioning and reduced tracking errors in dynamic scenarios compared to a non-adaptive baseline.
However, this work also has several limitations that open avenues for future research. First, the current system relies on structured features; future work will integrate deep learning-based techniques for feature extraction to enhance adaptability in unstructured scenes. Second, the sensitivity analysis revealed that positioning accuracy degrades under significant depth measurement noise. To mitigate this, future research could explore the fusion of additional sensor modalities or develop control laws that are inherently less sensitive to depth parameters.
Footnotes
Handling Editor: Hang Su
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.