
Abstract
To achieve efficient and stable autonomous operation during excavator robotic trimming plane operations, this study proposes an online trajectory planning method based on deep reinforcement learning (RL) using the Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm. This method involves the construction of a simulation environment to generate training data, where the joint angles of the boom, arm, and bucket of the excavator robotic working device serve as state observation variables, and the angle changes of each joint constitute the action information. The interaction between the simulation environment and the autonomous learning algorithm is facilitated by these state observations, and the policy network is trained using a reward function. Under identical experimental conditions, the proposed algorithm exhibits higher training time compared with other RL algorithms designed for continuous action spaces. Specifically, the training time of the proposed algorithm is reduced by 24.81%, 40.29%, and 34.51% compared with those of the DDPG, traditional TD3, and TRPO algorithms, respectively. In addition, the time of the proposed algorithm compared with the DDPG algorithm, TRPO algorithm, and traditional TD3 algorithm, the time required to complete a given task is reduced by 1.807, 3.703, and 5.011 s, respectively. These results indicate that the proposed optimization algorithm offers improved efficiency and faster convergence than the DDPG, traditional TD3, and TRPO algorithms, ultimately generating an efficient task trajectory. Moreover, the method effectively minimizes the large impacts on each joint, ensuring that the excavator robotic system operates with high efficiency and stability.
Introduction
Excavators, as widely used mechanical equipment, play a crucial role in industries such as transportation, mineral excavation, forestry, mining, and construction. 1 However, the dangerous and harsh working environments of excavators, coupled with long-term high-intensity operations, pose notable challenges. Traditional manual operation not only strains workers but also increases fatigue risk, leading to low efficiency, unnecessary energy loss, and equipment failure. To address these issues and ensure personnel safety while improving equipment productivity, the intelligent transformation of excavators has become a focal point for researchers worldwide. Autonomous excavators offer considerable economic and social benefits by eliminating safety hazards in dangerous environments, making them suitable for applications in nuclear radiation, space exploration, and underwater operations. 2 As a result, the automation and intelligence of excavators have become an inevitable development trend.3,4
Currently, research on intelligent excavators, both domestically and internationally, has made notable progress. At Lancaster University5–7 in the United Kingdom, advancements include the integration of GPS positioning and laser scanning for location information acquisition and environmental detection, along with hydraulic system modifications controlled by a PC104 computer. Similarly, the Australian Robotics Center8,9 and Seoul National University in South Korea 10 have developed autonomous excavation systems. Their research focuses on trajectory planning, position control, and trajectory tracking, which satisfy the requirements of intelligent operations.
Shanhe Group, a domestic company, has developed an excavation robot test platform that allows excavators to transition gradually from manual to autonomous operation. 11 Zhejiang University successfully created a WY-3.5 experimental excavation robot capable of hierarchical planning and local autonomous control, providing a theoretical foundation for excavators operating under real-world conditions. 12 Based on the above, among the various intelligent technologies for excavators, operation task trajectory planning is a high-level planning technology that plays a pivotal role. This planning technology not only directly influences the working efficiency and energy consumption of the excavator but also ensures the repeatable accuracy of the planned trajectory-an essential factor for maintaining the stability and reliability of equipment during operation. Thus, as a core technology for autonomous excavator operation, effective trajectory planning holds great importance.
In recent years, considerable progress has been made in trajectory planning research. Park et al. 13 developed a minimum energy-consumption excavation trajectory optimization model in South Korea, considering both the operating range and the excavation environment during the optimization process. This approach resulted in an effective low-energy consumption trajectory. Kim et al. 14 employed B-spline interpolation curves and proposed a recursive geometric algorithm to achieve a minimum time and torque operation trajectory with high reliability and robustness. Yoshida et al. 15 focused on minimizing the energy consumption by creating an excavation material model using the discrete element method, ultimately planning an optimal energy-efficient trajectory while accounting for excavation resistance. Similarly, Bi et al. 16 optimized the time and energy consumption through a staged approach using genetic algorithms to derive a high-efficiency, low-energy trajectory. Wang et al. 17 also used genetic algorithms to refine the polynomial interpolation, achieving an optimal energy-consumption trajectory for excavation tasks. Zhang et al. 18 developed a trajectory planning program that automates the speed and acceleration planning of each hydraulic cylinder by setting the motion trajectory of the bucket teeth, thereby ensuring smoother excavator operation. Zhao et al. 19 proposed a novel trajectory generation method for autonomous excavation teaching. This method converts inefficient and equipment-damaging human-operation trajectories into fast, smooth trajectories and integrates this framework into a complete autonomous excavation platform. On-site environmental validation confirmed the effectiveness of their approach. Fan et al. 20 introduced a cubic polynomial S-curve interpolation method for planning multi-objective trajectories and used a multi-objective simplification algorithm based on the decomposition of mixed constraints to optimize constrained multi-objective problems. Zou et al. 21 optimized the trajectory planning for horizontal and slope excavation operations by using numerical optimization iterations to derive trajectories that meet the constraints and ensure high efficiency. Inner and Kucuk 22 employed a particle swarm optimization algorithm to optimize the dexterous workspace of 10 GSP (General Stewart-Gough Platforms) configurations, maximizing the mechanism movement flexibility. Ege and Kucuk 23 proposed an energy-optimization method based on actuator power consumption for a new three-axis robotic knee prosthesis to minimize battery power usage. Kucuk 24 applied a particle swarm optimization algorithm to obtain a high-efficiency operational trajectory by optimizing cubic spline interpolation for a full-plane parallel mechanism using time as the optimization target. Simon and Isik 25 proposed a trigonometric function parameterization-based robot trajectory generation method to overcome the smoothness and vibration suppression limitations of traditional polynomial trajectories. In summary, all of the above trajectory planning methods employ interpolation functions in principle and use numerical optimization or intelligent algorithms to obtain optimal trajectories. However, these methods primarily rely on offline optimization and are generally designed for static environments. They do not fully account for real-time environmental changes, limiting their flexibility in complex construction scenarios and making it difficult to meet real-time replanning demands in dynamic environments.
With the continuous innovation and rising maturity of artificial intelligence, self-learning algorithms based on reinforcement learning (RL) and deep learning have been recently applied to the research of excavator task trajectory planning in the recent years. Egli et al.26–28 employed the Trust Region Policy Optimization (TRPO) algorithm to perform high-precision tracking of the target trajectory at the end of the bucket tooth tip of a data-driven excavator robotic. Kurinov et al. 29 used the “covariance matrix adaptive” Proximal Policy Optimization (PPO) algorithm to time-optimize the unloading trajectory. Hodel 30 employed the TRPO algorithm to optimize a smooth trimming plane operation trajectory. A newly proposed learning function proposed by Yang et al. 31 introduce an effective method for applying adaptive agent models in reliability assessment. However, the PPO algorithm relies on a complex clipping mechanism, while the TRPO algorithm can lead to overestimation due to its use of a single Q-network, which negatively influences policy stability.
Regarding the problems existing by the above studies, this study focuses on the PC1012 excavator robotic and employs an improved version of the Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm to determine the time-optimal trajectory for the excavator’s working device, as shown in Figure 1. The input of the framework is the state information of the boom, arm and bucket joints (i.e. the value of each joint angle), while the output corresponds to the action information (i.e. the change in each joint angle). Once the current state information of each joint is input, the data is normalized and passed to the deep RL module. During autonomous neural network training, the environment constructed by the excavator robotic and the target point provides the necessary training data. Specifically, the joint angles and the target angles of the boom, arm, and bucket serve as inputs to the neural network, which then calculates and outputs the corresponding changes in joint angles based on these state variables. The output is evaluated using a reward function that accounts for joint angle constraints, total motion time, and relative distance to the target. The neural network parameters are updated based on these evaluation metrics. Through iterative training and learning, the system ultimately generates an optimal strategy with a high reward value.
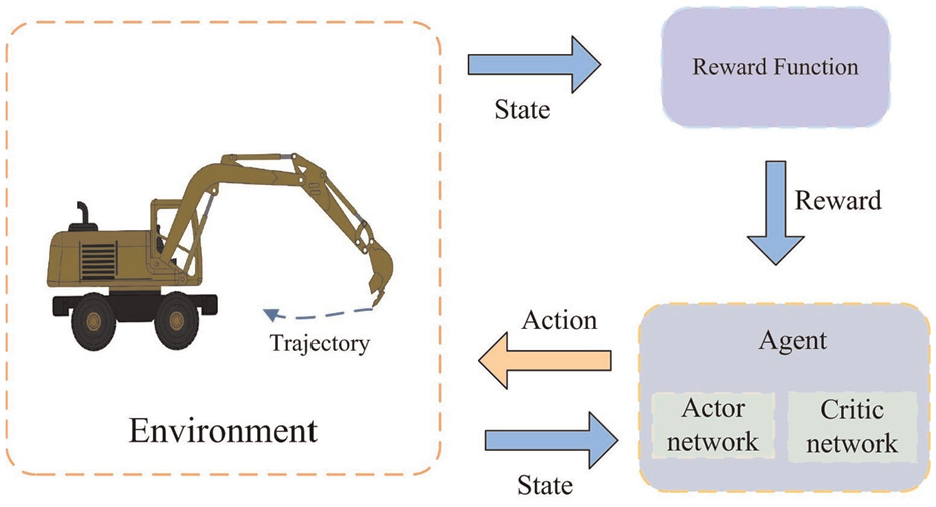
Online trajectory planning framework for excavator robotics based on reinforcement learning.
The main contributions of this study are summarized as follows:
(1) A deep RL algorithm is employed to achieve efficient and stable trajectory planning for autonomous, online trimming plane operations of excavator robotics.
(2) A multiagent system is developed for the boom, arm, and bucket joints, incorporating an adaptive weight sampling mechanism and a centralized training-distributed execution method. The TD3 algorithm is applied to optimize the time-optimal motion trajectory.
(3) A reward function is designed that considers whether the joint angle exceeds its permissible limit as well as the total movement time and the relative distance to the target. The network output is evaluated based on the reward value, which allows parameter correction of the system’s training network. The optimal movement strategy with a high reward value is generated through continuous training and learning.
The remainder of this paper is organized as follows: Section “Multiagent, autonomous-learning trajectory planning” introduces multiagent, autonomous-learning trajectory planning. Section “Excavator working device system modeling” discusses the kinematic modeling of the boom, arm, and bucket joints. Section “Experiment and result analysis” analyzes the experimental results, and Section “Conclusions” concludes the study.
Multiagent, autonomous-learning trajectory planning
For autonomous excavator robotics, planning the movement of each joint of the working device to achieve high efficiency and smooth operation while assuming that the drive and joint spaces are interchangeable is a key challenge. This study focuses on end-to-end trajectory planning task of the excavator robotics, optimizing working time. The boom, arm, and bucket joints are treated as independent decision-making intelligent entities. A deep neural network is used to approximate the trajectory planning strategy for the target task, and the TD3 algorithm derives dynamic decision behaviors that maximize the reward value for these joints. In other words, the time-optimal trajectory formed by the end of the bucket tooth tip is a combined decision sequence of three joints.
TD3 algorithm
It is not easy to accurately design the Q-value function used for evaluation because the boom, arm, and bucket joint operations are continuous actions. Hence, the policy gradient algorithm is employed to solve this problem. TD3 is a deterministic policy gradient algorithm based on the Actor–Critic framework, which directly optimizes the strategy via maximization of expected cumulative reward. And the TD3 algorithm structure framework is shown in Figure 2. The TD3 algorithm contains Actor and Target Actor as actuators, and Critic_0, Critic_1, Target Critic_0, and Target Critic_1 as evaluators, which are referred to as decision networks and estimation networks, respectively.

Structural framework of the TD3 algorithm.
During the training process, each action of the agent generates experience information

In equation (1),
The regularization technique of target policy smoothing is employed in the Bellman update of the Actor network to reduce the phenomenon that the deterministic policy method produces high variance target values when updating the Actor. Actor network update gradients:
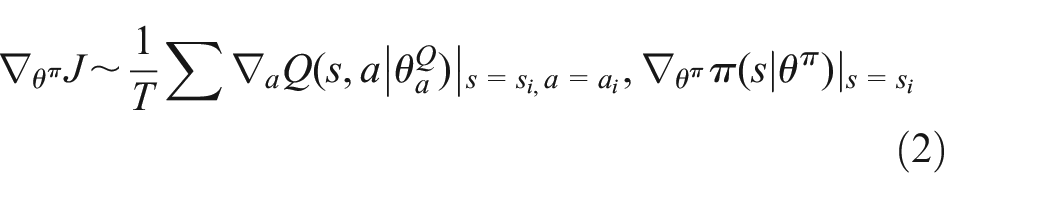
Deep neural networks with parameters
Time-optimal trajectory based on TD3 algorithm
In line with the theoretical knowledge provided in Section “TD3 algorithm,” aiming at enhancing the optimization performance of the TD3 algorithm, its sampling mechanism and training method are improved to obtain an efficient autonomous operation trajectory.
Priority sampling mechanism
The sequence data of the boom, arm, and bucket joints that can reach the target point are stored in the experience pool as a four-tuple:
First, the temporal difference (TD) error is calculated using a dual Critic network. A priority experience playback sampling probability distribution is then constructed based on the absolute value of the TD error. The adaptive weights increase the influence of the loss function value on the sampling weights. The loss function value for each sample is calculated and sorted in absolute value from large to small. And high error samples are preferentially extracted for training. Secondly, to ensure that the total sampling probabilities sum to 1, the adaptive weight calculation formula is given as follows:

In equation (3),
Finally, in the multiagent system, this mechanism forms a closed-loop optimization cycle of “high error sample priority training-weight focus on stubborn samples-update priority distribution.” To facilitate coordinated learning among agents, each agent’s sampling weight is calculated individually. Each agent then selects samplesaccoridng to its own weights to update the policy network parameters.
Centralized training-distributed execution mechanism
In the multiagent system comprising boom, arm, and bucket joints, the state transitions depend on the actions of all agents, and each agent’s reward is influenced by other agents. In other words, changing one agent’s strategy directly influences the optimal decisions and value function estimations of the other agents. Therefore, this study adopts a centralized training-distributed execution architecture for simulation in order to ensure convergence of the multiagent system algorithm, as shown in Figure 3.
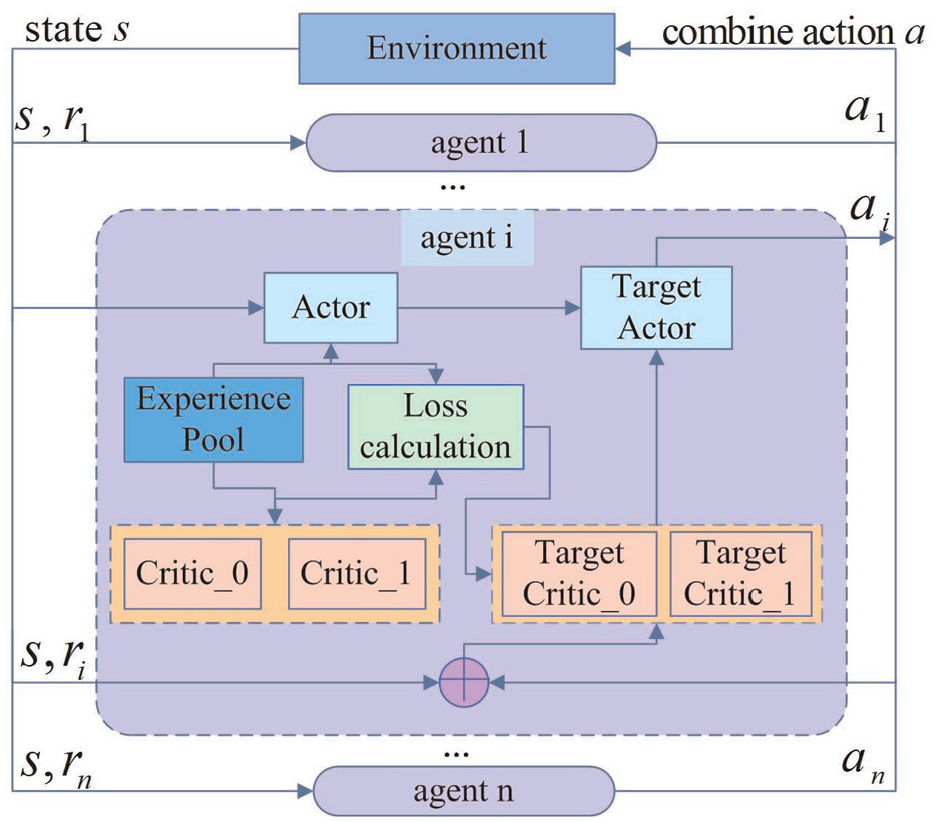
Centralized training-distributed execution architecture.
Since joint actions determine the state transitions and reward value functions of the entire system, and the decisions among agents are coupled, centralized training is implemented. During training, the state
During the execution phase, each agent (boom, arm, and bucket) relies solely on its own observed state (i.e. its joint angle values) and action information, without access to the actions or states of the other agents. To address this limitation, each agent adopts a distributed execution mechanism, in which the information available to a single agent is used as the input to its Actor network, and the output is the corresponding action. This method enables independent decision-making without real-time communication among agents. Once a sufficient number of training iterations have been completed, coordinated behavior is achieved through the trained policies alone, eliminating the need for an additional coordination mechanism. This method effectively compensates for the model’s limited exploration capabilities.
Time-optimal trajectory planning
The core task of this study is to establish a self-learning system that enables the excavator’s working device to autonomously plan the time-optimal trajectory. For the boom, arm, and bucket joint agents, the actuator’s estimation network (Actor) is used for policy iteration and updates. The actuator decision network (Target Actor) interacts with the experience pool for sampling, and its network parameters are regularly updated by the Actor. The evaluators, Critic_0 and Critic_1, iteratively update the value function and calculate the Q-value for the current Actor’s behavior. The evaluator decision networks, Target Critic_0 and Target Critic_1, calculate the global reward, and their parameters are regularly updated from Critic_0 and Critic_1. To ensure efficient operation of the excavator’s working device within the permissible range, the agent’s reward function is defined as follows:


In these equations,
Because the TD3 algorithm struggles to learn effectively in environments with sparse reward signals due to low exploration efficiency, a dense reward function that considers whether the joint angle exceeds the limit is added to the sparse reward function that only considers the total movement time and the relative distance to the target, thereby speeding up the training of the agent. From equations (4) and (5), we can deduce that the reward decreases when any joint motion exceeds its permissible range. Similarly, a longer motion time and a greater distance between the bucket tooth tip and target point also reduces the reward. Because each joint is an independent agent, each agent’s reward value is the same during interaction with the environment, and the shared evaluation network is influenced by the actions of all agents.
The time-optimal trajectory planning process based on the TD3 algorithm is outlined in Algorithm 1.

Excavator working device system modeling
Although most robotic studies32,33 employ the Denavit–Hartenberg method, this study uses the product of exponentials (PoE) formula from screw theory to establish the kinematic model of the excavator. The PoE method was chosen for two distinct advantages: (1) It provides a unified representation of both revolute and prismatic joints through twist coordinates, eliminating the need for assigning separate coordinate frames; (2) Its compact matrix exponential form offers a clear geometric interpretation for multi-degree-of-freedom systems such as excavator arms. As shown in Figure 4, where 1 denotes the slewing platform, 2 the boom joint, 3 the arm joint, and 4 the bucket joint. As shown in the Figure 4, the motion of the boom, arm, and bucket joints is mainly described based on the basic coordinate system

Structure diagram of the excavator based on the product of exponentials formula (PoE) method.
Structural parameters of the PC1012 excavator robotic.

First, when each joint is at zero position, that is,
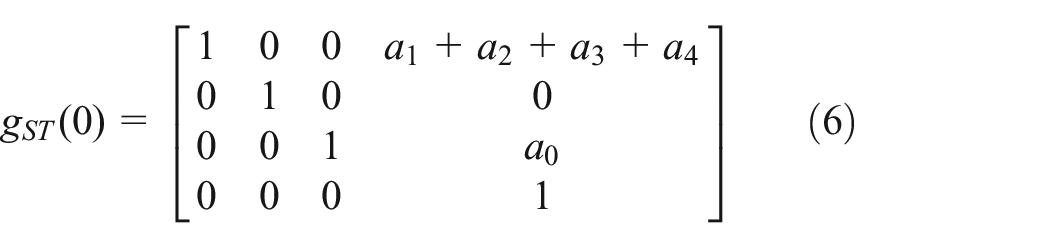
The rotation coordinate expression for each joint is expressed as follows:

where
Second, the position description of the coordinate system

where
Finally, using equations (6)–(8) and Chasles’ theorem, the forward kinematic equation of the excavator’s working device is calculated as follows:

where
Inverse kinematics
For the trajectory planning task of autonomous operation of excavator robotics, under the premise of a given target point, motion curves of the boom, arm, and bucket joints that meet the optimization objectives and constraints are designed in the joint space, such that the end of the bucket tooth tip forms a corresponding operation trajectory. The numerical analysis method 34 is used for kinematic inverse solution in order to realize transformation from the target point at the end of the bucket tooth tip to the angle values of each joint of the working device in the early stage of task planning:






where
Experiment and result analysis
An autonomous ground trimming plane operations by the PC1012 excavator robotic was considered as the optimization target. This study then selected the target point of the operation and the corresponding kinematic inverse solution results (see Table 2). The operating system environment was Windows10 x64, and the software toolkit version used was TensorFlow 2.1.0. The hardware information is as follows: Intel i5-9600K, GTX1060, DDR4 16 GB, 240 GB SSD. Simulation verification and data processing were implemented in the MATLAB 2022b environment.
Transformation of target points from pose space to joint space.

Model parameter configuration
Prior to using the TD3 algorithm to train the agent, the essential elements of the model were defined.
State
Action
Reward function
(a) the first part considers whether each joint angle movement exceeds its allowed range of motion;
(b) the second part takes into consideration total time to complete the task and the distance between current bucket tooth tip end point and the given target point.
Network design: The Actor and Critic network structures are essentially the same, sampling the fully connected network with a double hidden layer structure; the hidden layer contains 512 neurons, and the rectified linear unit function is used as the activation function. Of these, the Actor network receives normalized state observation information, and after passing the fully connected layer, the Softmax function is set as the last layer of the neural network to convert the output result into the change value of each joint angle, as shown in Figure 5; the Critic network outputs a 1D state value function, as shown in Figure 6.
Hyperparameter setting: Sample Adam network optimizer with a learning rate of 0.00015, a batch size of 256, an experience library capacity set to 5000, and an initial number of training samples of 2000.

Structure diagram of the Actor neural network.

Structure diagram of the Critic neural network.
Analysis of experimental results
Since there exists no unified standard for evaluation of quality of RL algorithms, this study performed evaluations from two aspects:
(1) Trend of the reward value curve: the larger the reward value, the better the algorithm; the faster the curve converges, the better the convergence of the algorithm.
(2) Final optimization result of the algorithm, that is, time required for each joint to complete the task; the higher the efficiency of completing the task, the better the algorithm’s performance.
Therefore, this study used the deep deterministic policy gradient (DDPG) algorithm, TRPO algorithm, traditional TD3 algorithm, and improved TD3 algorithm suitable for solving continuous action space in RL to achieve time-optimal trajectory for the excavator.
For a comprehensive evaluation, two key indicators were used: (1) training efficiency, measured by the number of iterations required for convergence; and (2) task completion time, measuring how quickly the algorithm guides the system to complete the task. Under identical environmental conditions, including the same state and action space dimensions and hyperparameter configurations, the four algorithms-DDPG, TRPO, traditional TD3, and the improved TD3-were each applied to obtain the time-optimal trajectory of the excavator robotic. The training times for each are shown in Table 3. As illustrated, the improved TD3 algorithm achieved a training time that was 24.81% shorter than DDPG, 40.29% shorter than traditional TD3, and 34.51% shorter than TRPO. These results demonstrate that the improved TD3 algorithm developed in this study offers significantly shorter training time and higher optimization efficiency.
Training time of various algorithms.

DDPG: deep deterministic policy gradient; TD3: twin delayed deep deterministic policy gradient algorithm; TRPO: trust region policy optimization.
Furthermore, based on the average reward value curves presented in Figure 7, the improved TD3 algorithm achieved convergence by the 600th iteration, while DDPG, TRPO, and traditional TD3 converged at the 986th, 1500th, and 1495th iterations, respectively. As training progressed, the reward values of all four algorithms gradually increased and eventually stabilized. This trend confirms that, through continuous interaction between the policy network and the environment, the reward function effectively guided parameter updates, enabling all networks to converge toward an optimal strategy. Notably, the average reward value achieved by the improved TD3 algorithm not only stabilized earlier but also reached a higher average reward value compared with the other three algorithms. Thus, the improved TD3 algorithm demonstrated not only shorter training time and greater optimization efficiency, but also lower reward fluctuation, higher reward values, and an overall more efficient training process.

Comparison of algorithms with respect to reward value curves.
Finally, the DDPG algorithm, TRPO algorithm, traditional TD3 algorithm, and the improved TD3 algorithm, with its optimal strategy as obtained in this study, were selected to solve the angle change curve of autonomous operation of each joint, as shown in Figures 8 to 11.
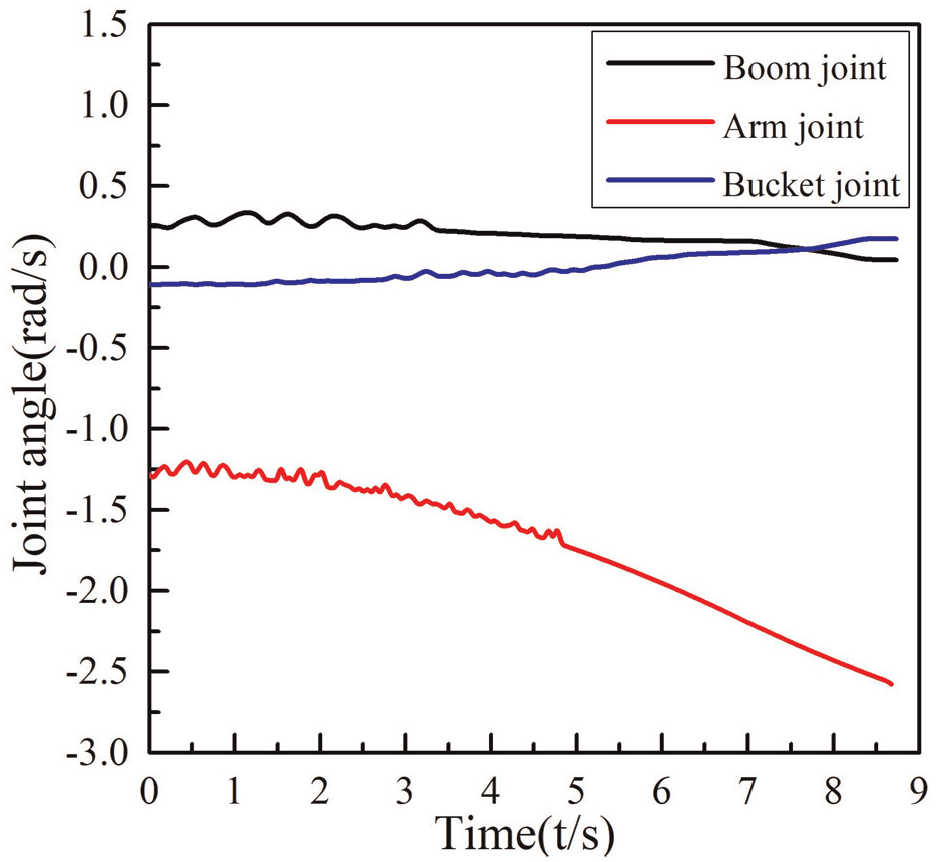
Joint angles optimized via the deep deterministic policy gradient (DDPG) algorithm.

Joint angles optimized by the TRPO algorithm.
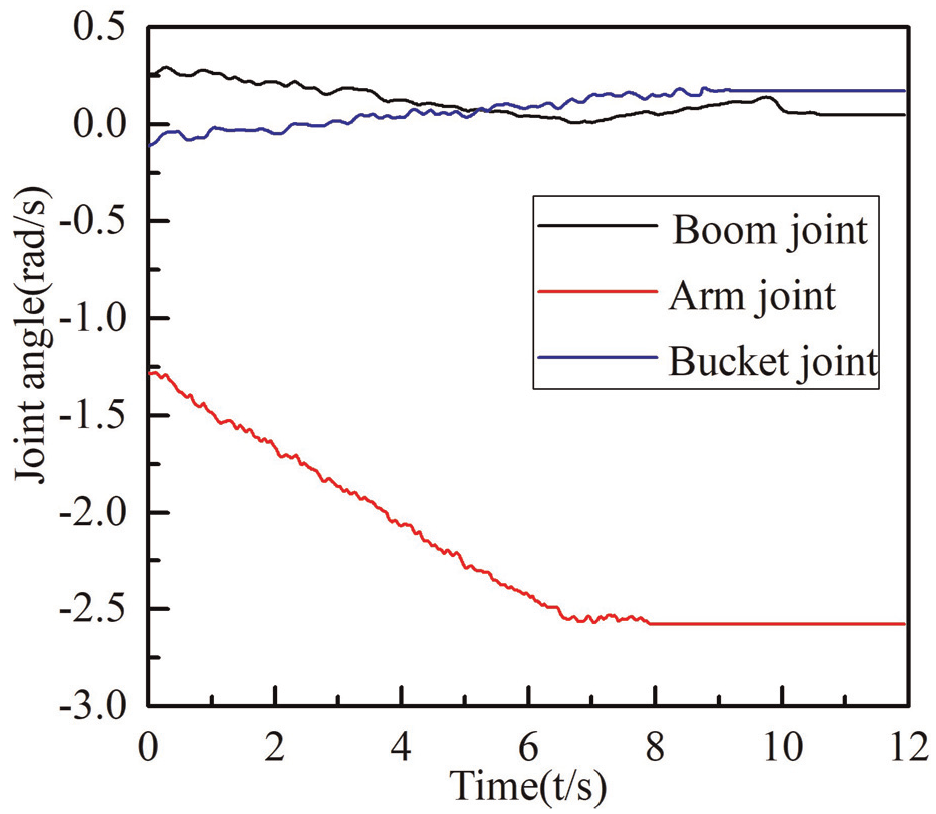
Joint angles optimized by the traditional TD3 algorithm.

Joint angles optimized by the improved TD3 algorithm.
Figures 8 to 11 show that the planning results of the four algorithms exhibit jitter in the early stage. This is likely due to the low probability of the incorrect decision actions being output by the agent during the initial stage, leading to the jitter effect. However, as the training progresses, the curves gradually become smoother due to the balance between exploration and utilization. In comparison, the joint angle curve produced by the improved TD3 algorithm, trained in this study, is smoother, with each joint making a small change to the target point, which helped protect the hydraulic drive device. In addition, the improved TD3 algorithm completed the ground leveling task in 6.925 s, while the DDPG algorithm took 8.732 s, the TRPO algorithm took 10.628 s, and the traditional TD3 algorithm took 11.936 s, demonstrating that the trajectory planned by the proposed method is more efficient.
In light of the training time, reward value, and joint angle motion curve of each algorithm, the DDPG algorithm with shorter training time, larger reward value, and smoother joint angle is selected, as well as the optimal strategy of the improved TD3 algorithm obtained in this paper. Under the condition of known operation time, the joint angle values generated by the optimal strategy were substituted into the excavator robotics model, with the trajectory generated by the end of the bucket tooth tip shown in Figure 12. The figure shows that the time-optimal trajectory obtained upon training the DDPG algorithm is relatively rough, potentially causing large impacts on the boom, dipper, and bucket joints. In contrast, the operation trajectory generated by the improved TD3 algorithm was not only efficient but also continuous and smooth. The experimental results exceeded those of traditional reinforcement learning algorithms and traditional planning algorithms, with good performance and stable results, verifying the effectiveness of the algorithm framework.

Trimming plane operation comparison chart.
Conclusions
Based on the establishment of kinematic equations for the excavator robotic working device using screw theory, this study proposes a trajectory planning method for autonomous learning in a multiagent system. The TD3 algorithm-an adaptive weight sampling mechanism and a centralized training-distributed execution framework-as used to train the neural network. By comparing optimization results in continuous action space among the DDPG, TRPO, traditional TD3, and the improved TD3 algorithms, the following findings were obtained. First, the training time of the improved TD3 algorithm was 24.81% shorter than that of DDPG, 40.29% shorter than that of the traditional TD3, and 34.51% shorter than that of TRPO. In addition, it achieved the highest average reward value. Second, the time of the proposed algorithm compared with the DDPG algorithm, TRPO algorithm, and traditional TD3 algorithm, the time required to complete a given task is reduced by 1.807, 3.703, and 5.011 s, respectively. These results demonstrate that the improved TD3 algorithm developed in this study converges more quickly and efficiently to a time-optimal trajectory, enabling efficient and stable autonomous operation of the excavator robotic.
This study primarily addresses optimal trajectory planning based on kinematic modeling, without considering the system’s dynamic model or corresponding energy consumption optimization. Future work can incorporate dynamic modeling to optimize trajectories that account for time and energy consumption, ultimately enabling multiobjective optimal trajectory planning for excavator robotics.
Footnotes
Handling Editor: Divyam Semwal
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Natural Science Foundation of China (Grant No. 61905172), General Project of Shanxi Provincial Basic Research Program (Grant No. 202303021211169), Key Research and Development Plan of Shanxi Province (Grant No. 202202150401007), Shanxi Province Science and Technology Cooperation and Exchange Project (Grant No. 202304041101001).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.