
Abstract
This work presents an advanced structural reliability analysis of circular concrete-filled steel tubular (CFST) members through machine learning and global optimization, together with numerical Monte Carlo simulations (MCS). The artificial neural network (ANN) model is developed and validated against available experimental data. On the basis of monetary cost of materials, the optimal design of CFST members with reliability constraint is formulated and solved by balancing composite motion optimization (BCMO) algorithm. Based on the MCS, reliability analysis is then carried out to calculate the coefficient of variation of optimal design under different loads. Subsequently, a comprehensive prediction simulation, taking account of the uncertainty of experimental data and potential errors from models (ANN, MCS, and BCMO), is performed to generate the statistics on the axial capacity of CFST members. The critical value for the optimal solution is also investigated as a function of the input variables. The results of this study can be applied to achieve a better reliability-based design optimization with minimum cost for the circular CFST columns.
Keywords
Introduction
Concrete-filled steel tubular (CFST) members present remarkable characteristics due to combination the advantages of the two constituent phases: the tensile strength of the steel tube and compressive strength of the concrete cylinder. This combination enhances significant members’ structural responses including ductility,1,2 strength,3,4 fire resistance,5,6 load-bearing capacity,7–9 earthquake resistance,10,11 energy-absorption capacity,12,13 etc. Thus, many researchers and engineers have dedicated a great deal of attention to the axial strength of CFST columns. 14 have performed compression tests on both hollow steel and composite members. For hollow steel members, they observed both inward and outward local instabilities. On the other hand, for composite members, only outward local buckling was seen, proving that the concrete cylinder prevents inward deformation of the steel. As a result, the composite columns were stronger than steel alone, because the wall tended only to buckle toward the outside. The same conclusion has been reached by other researchers – for instance,15–17 etc. CFST columns have been employed in many types of infrastructure, such as bridges, buildings and underground facilities.11,18
It should be noted that although the design for CFST columns is available in existing standards including American, 19 British, 20 European, 21 and Australian/New Zealand, 22 however, these standards do not consider various ranges of material strengths and/or geometrical parameters.23–26 For example, the yield stress of steel and compressive strength of concrete limit to 460 MPa and 50 MPa for Eurocode 4 and those of AISC 360-16 are 525 MPa and 69 MPa, respectively. Among them, AS/NZS 2327 allows the use of high strength steel and concrete up to 690 MPa and 100 MPa. Moreover, CFST structures are part of a field of research that has attracted a great deal of attention over recent decades, with researchers/engineers seeking economical and optimized constructions. Many optimization studies have proposed optimal designs for structural members at minimal cost. 27 optimized fiber-reinforced CFST members based on dimensions of columns and percentage of reinforcements. 28 designed a cantilever retaining wall with minimal cost based on the gray wolf optimization technique. Other optimization techniques have been successfully employed for optimal design of structural members with minimal cost: particle swarm optimization, 29 biogeography-based optimization, 30 etc. However, to the best of the authors’ knowledge, optimal design of circular CFST columns at minimal cost has rarely been investigated. 27
One crucial aspect is the reliability to predict the column’s capacity within a certain specified confidence interval.31–37 Even with modern, advanced analysis tools which are capable of efficiently estimating the capacity of complex structures under given conditions, the ultimate loads, geometric, and material nonlinearities are still not easily predictable. 38 It is worth noticing that in practice, structural elements may have imperfections in different forms and at different levels due to manufacturing, transportation, and other constructional processes.33,39,40 Indeed, structural element capacity is remarkably difficult to predict and assess. First, geometrical imperfections could occur during the manufacturing processes, mostly in the cross-section or along the length of structural members; or there may be fluctuations of the mechanical properties of the constituent materials. Second, during assembly and/or construction, residual stresses could appear within the structural elements. Finally, eccentricity of the compressive loads could also reduce the member’s capacity. Each of the above is a factor that significantly affects the compressive resistance of members, which must be taken into account in the initial design. 41 Moreover, previous works40,42,43 have shown that failing to consider the effect of imperfections may affect the prediction of CFST members’ capacity, leading to potential risks in practice at both the micro- and macroscopic scales. Consequently, statistical analysis and uncertainty quantification should be conducted to answer the question: how accurate are the predicted capacity values when applying given material properties, geometrical data, and boundary conditions?44–46
Many studies have been focused on this problem for CFST column revealing the natural complex of the problem and weakness of some codes. Kang et al. 47 found that the complication of predicting load capacity of a composite member and more test samples were required for such member compared to a non-composite one. Thai et al. 48 provided a thorough study of reliability assessment of current codes for CFST columns with a globally collected database. This study also figured out that the current EC4 code should be extended to be up-to-date.
Besides, there are several methods to estimate the ultimate load of structural CFST members under different types of loads (see Kang et al., 47 Moon et al., 49 Güneyisi et al., 50 and Ahmadi et al. 51 ). Regression machine-learning techniques have been widely used recently to solve this complicated problem. Thanh Duong et al. 52 developed high-quality ANN model to predict the load capacity of CFST column with R2 is up to 0.9899. Naser et al. 53 used genetic algorithms and gene expression programing for improving the accuracy of prediction. Lee et al. 54 used Categorical Gradient Boosting algorithm and compared the results with those from AISC 360-16, Eurocode 4, and AS/NZS 2327. Zarringol and Thai 55 predicted of the load-shortening curve of CFST columns using ANN-based models. Coupling with the use of machine learning models, reliability assessment for the CFST columns is much more challenging with the unavoidable model uncertainty.56,57 Besides, there is an evidence of the weakness of these machine learning models such as the quality degradation for the out-of-boundaries prediction. 58 Unfortunately, the uncertainty of machine-learning model is commonly neglected in many cases.
Generally, this paper fills the gap by proposing, a novel comprehensive investigation study for optimizing the design of circular CFST columns, incorporating a data-driven model and reliability constraints. Section “Experimental database and research methodology” introduces the experimental database and research methodology, including ANN, Monte Carlo Simulation (MCS), and Balancing Composite Motion Optimization (BCMO) as well as optimization with reliability constraint. Finally, Section “Results and discussions” presents the results and discussion, including prediction, design optimization, and uncertainty quantification for CFST members. The proposed method allows us to obtain a comprehensive picture of the reliability of CFST members, where structural uncertainties are considered.
Experimental database and research methodology
Experimental database
In this work, 1245 axially loaded circular CFST column tests were gathered from Thai et al., 59 which was mostly from two well-recognized sources Goode and Lam 60 and Denavit Mark et al. 61 The selection of tests was based on the following criteria: (i) only monotonic uniaxial compression was considered; (ii) the specimens were fully loaded; and (iii) the specimens did not include internal steel reinforcement, shear stub, and tab stiffeners. Table 1 gives a summary of statistical input variables of the dataset. Histograms of variables are given in Appendix A. In addition, correlation coefficients between measured axial capacity and input variables are also given in Table 2. More details of the database can be found in Thai et al. 59
Descriptive statistics of collected database.
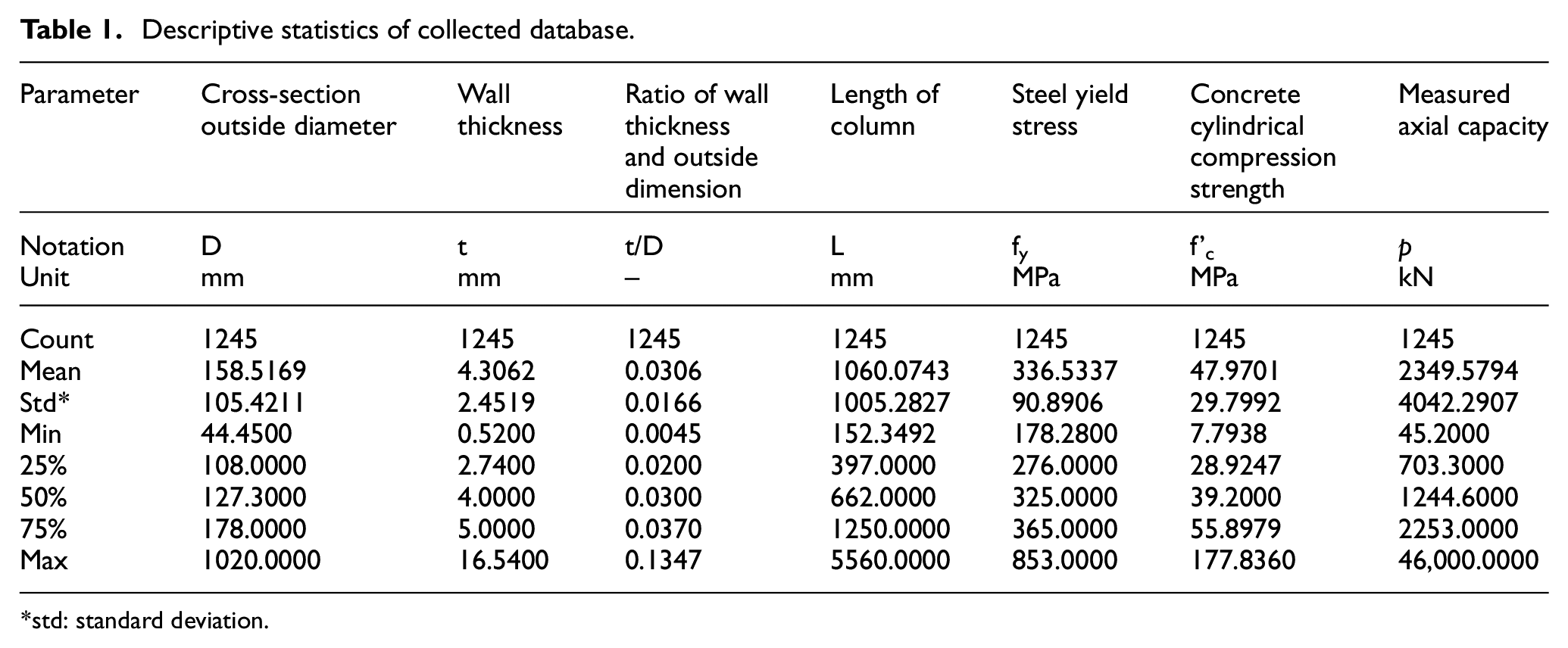
std: standard deviation.
Linear statistical correlation coefficient r of the database (including a value-color scale) (see Appendix B for details).


Note. In a correlation matrix, shaded cells typically highlight specific correlations based on their values or significance levels. These shadings often serve to help users quickly identify patterns and relationships between variables.
Artificial neural network (ANN)
The data-driven model relies on labeled database to predict the variables of interest. Conventionally, the database is first split into training and testing datasets. The aim of the training process is to minimize the error between predicted values and the labels in the training set. In the case of ANNs, each of them is a system containing nodes, with weighted links between such nodes. ANNs are divided into layers including input layer, hidden layer(s), and output layer, with nodes in one layer connected to nodes in the previous layer. The training process is triggered at the input layer, with parts of the training dataset or so-called batch. These signals are propagated through the network by a mathematical combination of input signals and activation function. The training dataset is “fed” through the network repeatedly. The weights in an ANN are adjusted during the training process by backpropagation, so the error is minimized after a given number of iterations. Once the ANN is developed, the system is tested and validated by predicting the variable of interest in the test dataset and comparing the results with the corresponding labels on the test dataset.
Monte Carlo simulation (MCS)
For the MCS, once the distributions of the inputs are found or assumed by the law of large numbers, an unlabeled database is established with n samples, each of them is randomly generated corresponding to their distribution.62,63 Thus, the MCS requires a substantial number of runs to obtain a meaningful result. Unfortunately, increasing the number of trials in the MCS is computationally expensive, especially in the case of optimization. In this paper, it is assumed that input variables including D, t/D, fy, and fc, are random variables following normal distributions. The length of column, L, is practically considered as a known and deterministic variable due to the design task. A database of input variables, which is used to predict column strength P by ANN, is randomly generated with the assumed means and standard deviations, std. The stochastic characteristics of n samples of P are observed and the function f = P-N is calculated to determine the number of negative values, nf, which have an applied load greater than the capacity of the column. The failure probability of the CFST column is then found by equation (1):

Optimization with reliability constraint and data-driven model
This paper uses an objective function, OF, representing the monetary cost of the column per unit strength, which can be expressed as:
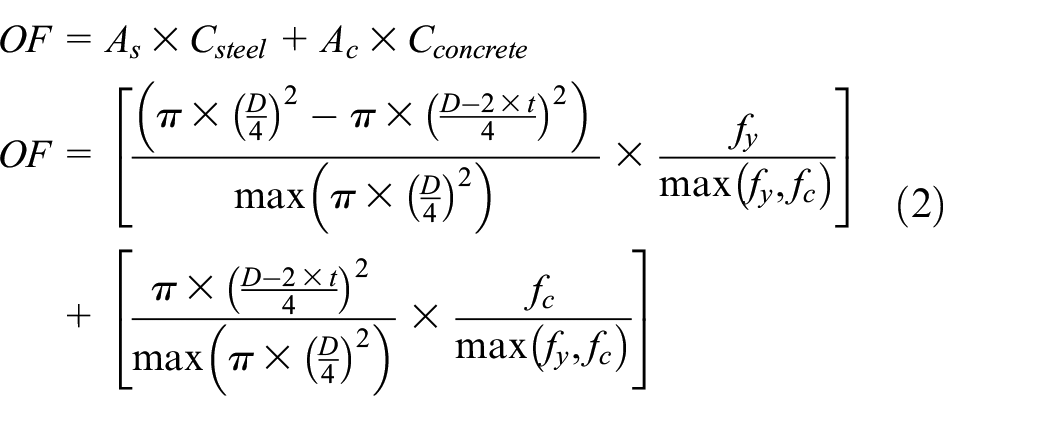
where As and Ac are the areas of steel and concrete normalized by the maximum area of the cross-section in the database; Csteel and Cconcrete are the costs of steel and concrete with the monetary values represented by the strength of materials;
The reliability constraints are established from the column failure probability (Pf) which is determined by conventional Monte Carlo simulation (MCS) and does not exceed a given threshold Pfmax (e.g., 0.01 or 0.05). For each trial in the simulation, the axial load capacity of the column is calculated from a database driven model, trained on an experimental database.
The optimization problem in this paper can be stated as below. The notations µ, std and CoV represent mean, standard deviation and coefficient of variation.
- Given an applied axial load N, column length L, and coefficients of variation CoV of the design parameters (stdD, stdt/D, stdfy, and stdf’c);
- Find µ D , µ t/D , µ fy , µ f’c which minimize OF in equation (1)
- Subjected to: Pf≤Prmax;
- where: Pf is obtained by Monte Carlo simulation with the load-bearing capacity of the column obtained by a data-driven model.
Balancing composite motion optimization (BCMO)
Proposed by Le-Duc et al., 64 the first step of the BCMO algorithm is similar to other metaheuristics, with the creation of the initial population. In this paper, individuals in the population are ranked based on objective function (OF). The composite motion of the ith individual in the population will depend on two critical points. The first one is the minimum point of the OF, which is represented by the instant global optimization point, Xoin. To avoid early termination of the algorithm due to premature convergence, Xoin is chosen between the performance of the best individual in the previous generation and an individual which extracts information from the current generation. The second one is a randomly chosen individual point which has better performance than the ith individual. The process of extracting information and searching for motion is repeated until the pre-set maximum number of generations is reached.
The advantage of the BCMO is that the number of parameters is limited by the number of individuals, and maximum number of generations is used as the stop criterion. This algorithm is also tested in this study, revealing its computational efficiency. This reduction in the computational cost is particularly useful in a combination of optimization and reliability assessment with MCS, and thus has been chosen from among various other metaheuristic algorithms.
Uncertainties
The incorporation of ANN and MCS together in the optimization algorithm leads to the accumulation of errors from each individual model. The errors from the MCS and BCMO can be mitigated with improved computational power while that from the ANN model is taken into account by adding a margin of error in each run of the simulations or prediction of column capacity in equation (3). By using approximation, the unknown error of the ANN model is replaced by the mean and standard deviation of error on the test dataset. As expected, the appearance of the error from ANN models increases the value of the objective function, OF.

where P is the predicted load capacity of the column, PANN is the load capacity of the column predicted directly by the ANN model; µerror,ANN and stderror,ANN are the mean and standard deviation of error of the prediction, assumed to be equal to the mean and standard deviation on the test dataset, µerror,test, stderror,test.
Boundaries for design optimization variables
It should be noted that developed ANN model in this paper is only valid if the inputs are between the minimum and maximum values in the database. An out-of-boundary input may lead to the explosion of unpredictable errors, similar to an extrapolation prediction. Thus, the input boundary of an ANN model is defined based on the upper bound (UB) and lower bound (LB) of those inputs (i.e., D, t/D, fy and fc′) in the database. The jth input must be within the range [LBj, UBj] to guarantee the accuracy of the prediction.
The situation is more complicated because of the incorporation of MCS and ANN to obtain the failure probability. The inputs of the MCS are the mean and standard deviation of diameter: µD, stdD; of ratio of wall thickness to diameter: µt/D, stdt/D; of yield strength of steel: µfy, stdfy and of cylindrical strength of concrete: µf’c, stdf’c. Obviously, all predictions by ANN in the MCS should have the inputs within their corresponding bounds.
To preserve this, the minimum bound of the mean input for MCS must be higher than the LB in the data-driven model, and vice versa. The distance between these bounds can be set from the mean, std of the inputs and the probability of out-of-boundary prediction is acceptable. In this study, it is assumed that for the jth input: + The LB of the optimization is m × stdj larger than that of the ANN model; + The UB of the optimization is m × stdj smaller than that of the ANN model
where m is a control number relating to the probability of out-of-boundary prediction.
There is a trade-off in the width of the range of input and the probability of out-of-boundary prediction, Pobp, occurred. If a large value of m is chosen, the higher probability of within-boundary prediction is obtained. For example, if m = 3 is chosen then the probability of out-of-boundary prediction is 0.00135, when the diameter is a normally distributed variable. If m = 2 then this value is 0.02275. However, this leads to the narrowing down of input boundaries for design variables of the optimization. The boundary of the mean of the jth input is reduced from [LBj, UBj] to [LBj + m × stdj, UBj − m × stdj], where m is the critical values deciding the width of such range. The UB and LB of mean of the jth input, LBmean,j, UBmean,j, are mathematically expressed in equation (4) below:


where j represents: D or t/D or L or fy or f’c.
Figure 1 illustrates the boundaries of diameter in the database: [44.450; 1020] mm. This range is used as the boundary of the ANN model. Because the standard deviation of diameter is unknown, it is assumed here that LB of D in the database (LBD) is equal to the µD. For instance, the range of µD for optimization with CoVD = 0.1, m = 2 is [53.340, 816.0] mm and with CoVD = 0.1, m = 3 is [57.785, 714.0] mm. Table 3 compares design variable inputs with different values of m. The corresponding value of p is also included with the standard deviation in the database at 4042 kN, as shown in the Supplementary material. In this study, m = 2 is chosen.

Relationship between the boundaries of the ANNP model and optimization problem for the diameter.
Boundaries for optimization design variables with CoV = 0.1.

Chosen in this study.
Used with stdP from database (4042 kN in Table 1) for reference of prediction after optimization design.
Variables found.
The proposed framework
Figure 2 illustrates the proposed framework of this study and the interaction of ANN model, MCS, and BCMO. The ANN model is nested in the MCS. To its turn, the MCS is a subroutine of the BCMO. Initially, for developing the ANN model, the database is divided into train set and test set for training and validating process. Using distribution of residual on the test set as the model uncertainty and natural boundaries from minimum and maximum of samples in the database, the lower and upper bounds of the optimization can be set up.

The proposed framework of reliability-constrained optimization with ANN model.
Once the spaces of design variables are obtained, random mean of the inputs can be generated within the BCMO. With means and known corresponding CoVs, n samples (i.e., n set of inputs for ANN) are generated. Consequently, n values of P are calculated. These values will be compared with applied load, N, to obtain the failure probability (Pf in equation (1)) of each individual in the BCMO. Maintaining this probability to be less than a desired threshold failure probability, Prmax, is the process of satisfying the constrain for the BCMO. The objective function is calculated from equation (2) with the corresponding µD, µt/D, µfy, and µf’c. The BCMO is continuously checked for all individuals in the next generation are between LBj and UBj. To the end, means of D, t/D, L, fy, f’c, and P corresponding to the minimum of OF are obtained.
Results and discussions
The ANNP model
As per the above discussion, the collected database is used to develop a model to predict the capacity of the column P, the ANNP. The database is split into train set (used for developing ANNp) and test set (used for validating this model) with the corresponding ratio of 8:2. The chosen configuration of the ANN network contains five hidden layers. Each has 32 nodes, fully connected to nodes of the preceding and following layers. The fine adjustment of the weights requires a large number of interactions, and gradually converges with 105 iterations to obtain the final Mean Absolute Error (MAE), on the test dataset at 141.0549 MPa. This error is about 6% of the mean of P in Table 4. The coefficient of determination, R2, on the test dataset is 0.9883, implying that in general, the model is well matched with the labels of the database.
Evaluation metrics for ANN model on testing data set.

Assuming that the error of the ANNP model follows a normal distribution, the mean error on the test dataset, which is close to zero (i.e., −10.1352 MPa) indicating the minor bias of this model. It incorporates the standard deviation, std, at 4480.5966 kN, providing the particular distribution of the model error. This low bias is illustrated in Figure 3, with the high density of data points scattered around the 1:1 line. This error is added to the prediction in the MCS, as discussed above.

Predicted versus experimental data on training and testing dataset of the ANNP model developed to predict load-bearing capacity of the column p.
MCS with ANNP model
In this section, the developed ANN trained in the previous section is used for the conventional MCS with the control case which has inputs: µD = 442.212 mm; µt/D = 0.0811; L = 4000 mm (deterministic); µfy = 218.5305; µf’c = 10.0336; and all random inputs have the coefficient of variation at 0.1. Given a deterministic axial load, N, which has 15,000 kN applied to the column, a MCS with 106 trials is implemented.
Accounting for the error from ANN model, the mean and standard deviation of column capacity, µP and stdP are at 26255.578 kN and 6875 kN, respectively, and thus, the CoVP is 0.2618. Consequently, the function of P-N has µP-N at 11255.578 kN. The standard deviation, stdP-N is equal to the standard deviation of P due to the assumption that the applied load N is deterministic.
Without the error from the ANN model, the stdP and stdP-N is reduced to 4498.643 kN while the corresponding means of P and (P-N) are only higher than those with errors. This is due to the mean error close to zero (i.e., −10.1352 kN), compared to the much larger stdP-N. The standard deviation of error is 4480.5966 which is almost equal to that of (P-N) (i.e., 4498.643 kN). The histogram of (P-N) is given in Figure 4 with an obviously wider variance of data when accounting for the error from the data-driven model. Consequently, the failure probability Pf, which indicates the probability of (P-N) < 0, when errors are included, is higher than when the ANN error is ignored: 0.0497 compared to 0.01539 (shaded in blue), respectively.

Numeric example of distribution of P-N function, Pf = 0.0497 (with error), 0.01539 (without error).
A parametric study on the effect of inputs’ coefficients of covariance on standard deviation of P is provided in Figure 5, revealing the linear positive correlations between input and interest variables. The trend can also be seen earlier than with µP, when fluctuations almost disappeared when n = 103. Besides, the clear separation of the cases with and without error in the simulation can be observed. For deterministic inputs (CoVs = 0), the randomness of P only relies on the error of ANN model, which is equal to 4480.5966 kN; this is also the starting point for cases with error included. Without such error, the starting point is consistently (0,0). Here, it can be observed that the effect of important inputs such as D or t/D on the stdP based on their corresponding distances to the case where all inputs are random variables. When the inputs that have only a slight effect on the column capacity, P, the angle to the horizontal is smaller, and can be almost zero as in the case of f’c.
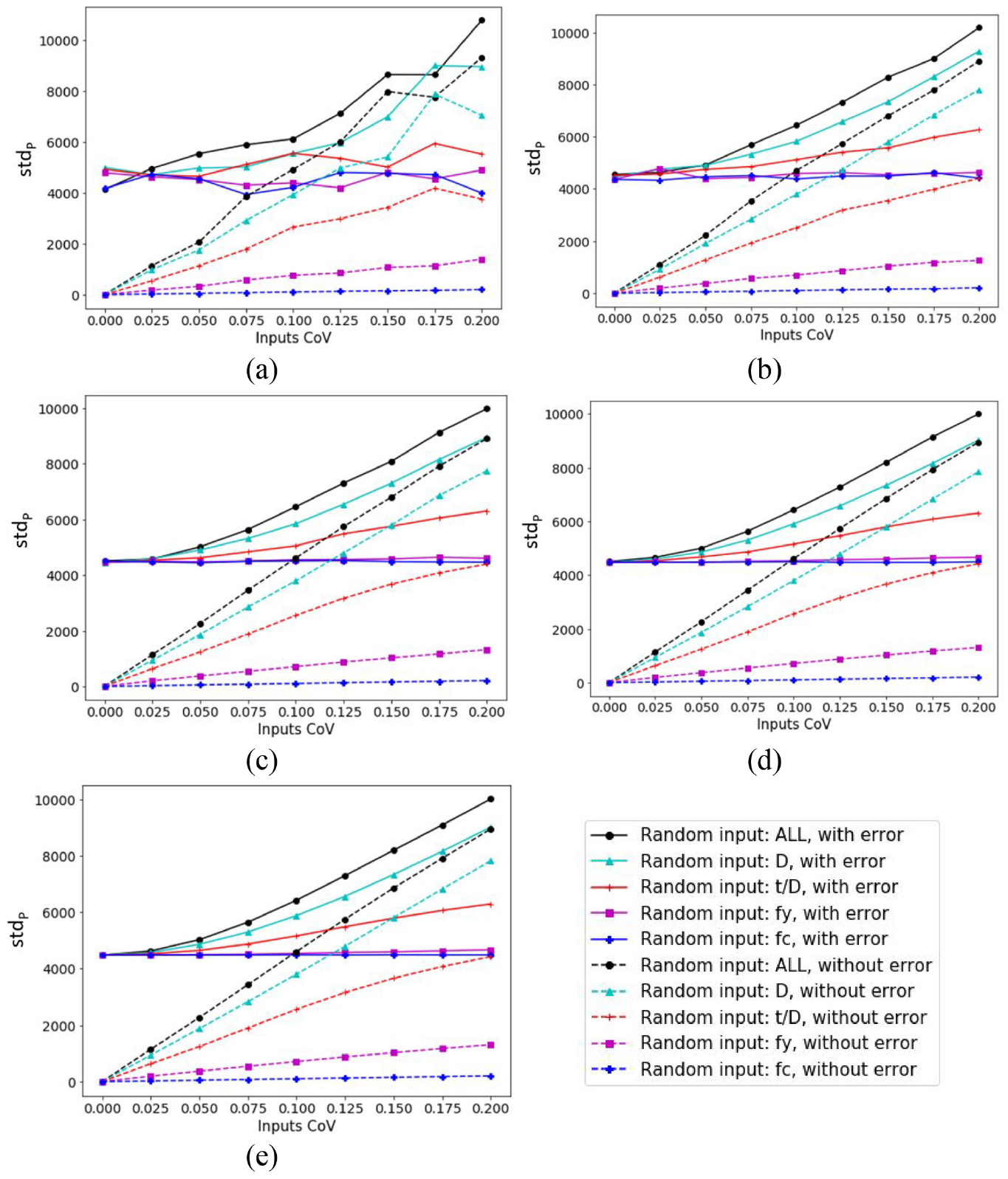
Standard deviation of column capacity versus random inputs CoV with n: (a) 102, (b) 103, (c) 104, (d) 105, and (e) 106.
The investigation into the critical value for optimization, the failure probability, Pf, is presented in Figure 6. The general trends can be observed with the consistently higher failure probability of MCS with ANN error and the effect of important inputs on the results. The first trend indicates a trade-off between the OF and the uncertainty of the ANN model. The second trend implies the concentration of optimization on the important inputs to obtain the best results. With n = 104, most fluctuations have disappeared, and to reduce the computational effort for the optimization procedure, this value is chosen as the number of trials for analyses in the next section.

Column failure probability versus random inputs CoV with n: (a) 102, (b) 103, (c) 104, (d) 105, and (e) 106.
Optimization with MCS and ANN model
The BCMO algorithm is implemented with the control case in the previous section and different threshold for failure probability Prmax and CoVs of inputs (assumed to be equal). The results of this investigation are provided in Table 5. It is reasonable to observe a consistently higher OF in the case of higher required reliability level (i.e., Prmax = 0.01). Without the randomness of inputs (inputs’ CoVs are zero), the corresponding OF threshold is 0.0155, compared to that of the counterpart (i.e., Prmax = 0.05), which is 0.0130. The means of the column capacities are 25,700 kN and 22,587 kN. When the variation of inputs is greatest, CoVs are 0.2, µP of Prmax = 0.01 is 47,035 kN and Prmax = 0.05 is 36,075 kN.
Optimization results of the numerical example with different input CoVs and threshold for probability of failure.

Case study in Section “MCS with ANNP model.”
The values of µP plainly show a positive correlation with the inputs’ CoVs – in other words, the higher the µP, the higher the variance of inputs. This is due to the flattening of the probability distribution function or the larger standard deviation of mean of P, the randomness of the inputs increases. For instance, µP is 26156.303 kN when input CoVs are 0.025; this value increases to 47035.617 kN with CoVs at 0.2 (Prmax = 0.01).
It is also seen in Table 5 that µD is the variable which changes most, having the tendency to increase, notwithstanding some exceptions. This parameter jumps from 400 mm to 561 mm in the case of Prmax = 0.05 and to 715 mm when Prmax = 0.01. Meanwhile, other input parameters can be varied to obtain the best OF such as f’c, or almost the same, such as t/D and fy.
For further investigation, different applied loads, N, are chosen (i.e., 10, 15, and 20 MN) along with the variety of input CoVs as given in Figure 7(a), which closely matches the intuition that higher applied load requires more material cost, and thus, has a higher corresponding best OF. For example, with the threshold of Prmax = 0.01 and input CoVs = 0.2, the best surrogate cost of N = 20,000 kN is 0.05713 compared to that of N = 10,000 kN at 0.03611. Results of the optimization implemented with ANN error are consistently higher than those without it. Again, it is illustrated in Figure 7(a) that higher variance of the input (CoV) leads to the higher requirement of OF. The µP in Figure 7(b) shows the tendency to increase with the Prmax and input CoV with some interesting exceptions where fluctuation occurred.
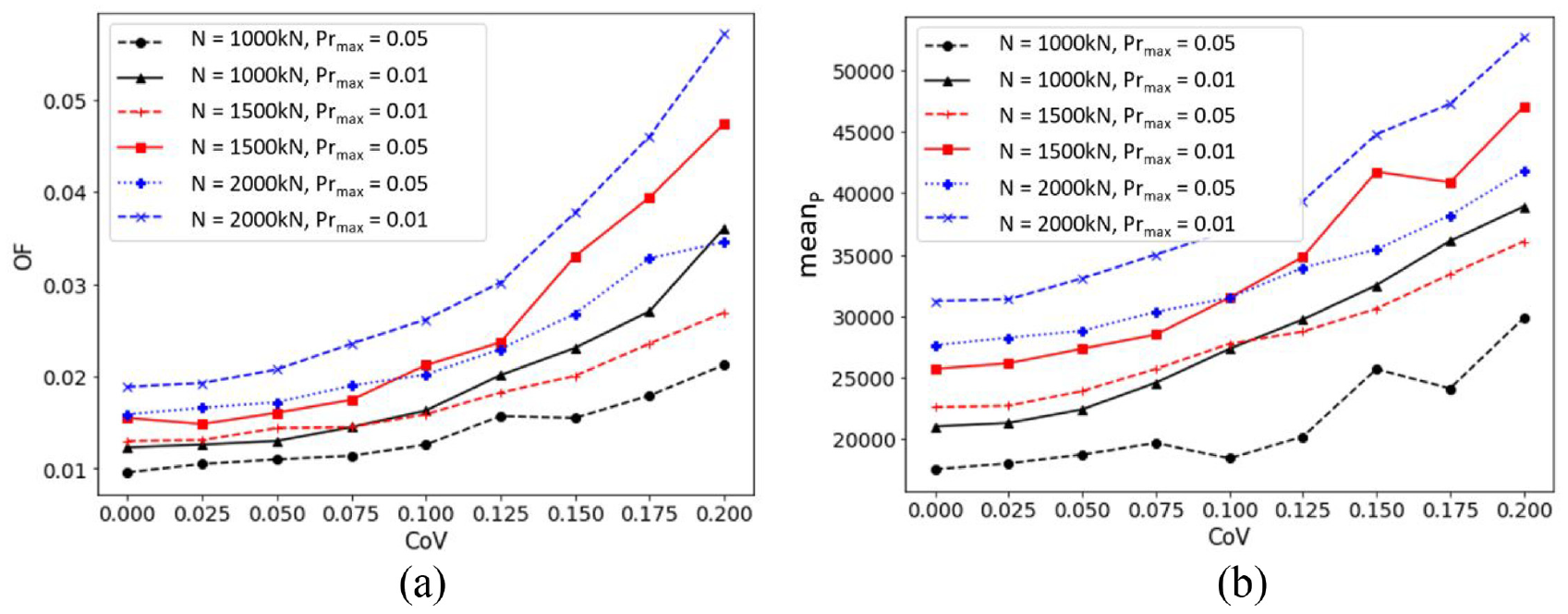
Results of BCMO with MCS and ANNP with different applied axial loads and input CoVs versus: (a) objective function OF and (b) mean of p, µP.
It is worth noting that the analyses in Figure 7 and Table 5 include the out-of-bounds defined in section “Boundaries for design optimization variables” where the maximum CoV is 0.1 and thus out-of-boundary predictions occurred. The maximum µP corresponding to CoV = 0.1 is 36,941 kN (with N = 20,000 kN and Prmax = 0.01). This value is within the range of µP [8129, 37915] kN. For instance, the out-of-boundary prediction happened when CoV is larger than 0.1. In the case of N = 20,000 kN and N = 15,000 kN (Prmax = 0.01, CoV > 0.15), µP is larger than 40,000 kN. Even though the main trends are preserved, these results are unpredictable as extrapolations.
Conclusion and outlook
This paper presented a reliability-based investigation for circular CFST members under axial compression. An advanced machine learning method was developed and trained to estimate the axial capacity of the composite elements. The random uncertainties (from both the experimental database and the prediction model) were then incorporated into the prediction machine learning model. The reliability analysis was conducted afterward based on the numerical Monte Carlo technique. The conclusions of this work are listed as follows:
The machine learning prediction model exhibited a considerable ability to predict the axial capacity of CFST columns, with R2 up to 0.9883 and MAE = 141.0549 MPa on the testing dataset;
Optimization using the BCMO algorithm was conducted under different failure probability thresholds and coefficient of variation of inputs: the higher the required reliability, the larger the value of the objective function;
Effect of quality of ANN model to the results is also observed by comparison between with/without model error: the uncertainty of data-driven model significantly affects to the output despite of the high accuracy on the evaluation metrics. The weakness of ANN model or machine learning model are revealed in this study: (1) model depend on the boundaries of inputs and outputs to avoid the out-of-boundary effect and (2) reduction of reliability due to this error. Using a less economic column section with higher capacity is the compensation for this uncertainty;
This paper also demonstrated the ability to perform a reliability analysis based on machine learning and global optimization without using specific finite element software.
By combining machine learning and the global optimization technique, the proposed reliability-based procedure can be applied for any structural members (columns and beams).
However, as there are many other factors which might, in practice, affect the structural performance and reliability of a CFST column, future study is needed to address other types of uncertainties: initial imperfections, material properties, structural configurations, and model uncertainties.
Abbreviation and notation

Replication of results
The dataset required to reproduce these findings is appended to this manuscript at https://docs.google.com/spreadsheets/d/1h4S_Vh7t59d8E98AqIYc-2-6T0GI9Djx/edit?usp=sharing&ouid=103283763960933314228&rtpof=true&sd=true.
Footnotes
Appendix A. Histogram of variables
Appendix B. Calculation of linear statistical correlation coefficient
The Pearson linear correlation coefficient r between two real-valued random variables could be calculated based on the following equation 65 :
where n is the number of the samples,
Handling Editor: Divyam Semwal
Author contributions
Conceptualization: Hieu Chi Phan, Tien-Thinh Le; Methodology: Hieu Chi Phan, Tien-Thinh Le; Formal analysis and investigation: Huan Thanh Duong; Writing – original draft preparation: Hieu Chi Phan, Tien-Thinh Le, Huan Thanh Duong, Minh Lu Le; Writing – review and editing: Tien-Thinh Le, Minh Lu Le; Supervision: Hieu Chi Phan, Tien-Thinh Le.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Ethical approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
Informed consent
Informed consent was obtained from all individual participants included in the study.
Data availability
The dataset required to reproduce these findings is appended to this manuscript at https://docs.google.com/spreadsheets/d/1h4S_Vh7t59d8E98AqIYc-2-6T0GI9Djx/edit?usp=sharing&ouid=103283763960933314228&rtpof=true&sd=true.