
Abstract
As the digitalization of industrial assets advances, data-driven fault diagnosis has increasingly garnered attention. However, models often underperform due to the lack of sufficient training data and the complexity of operational environments. In scenarios where a similar task with abundant data exists in the source domain, leveraging the knowledge embedded in this source data could be key to constructing an effective diagnostic model for the target domain. Following this idea, this study introduces a novel cross-domain decision method, weighted structure expansion and reduction (WSER), for fault diagnosis. This method initially extracts features from the time, frequency, and time-frequency domains. It then estimates data weights following the idea of instance transfer to mitigate the dissimilarity between the source and target data distributions. Based on these estimated weights, feature selection is further performed. The extracted source knowledge is subsequently transferred to the target domain using the proposed WSER method. The proposed method is applied on two public engineering fault datasets, and the results demonstrate the effectiveness of the proposed method in increasing the accuracy of fault diagnosis.
Introduction
In recent years, the advent of increasingly complex systems in fields such as manufacturing, aviation, and power generation has given rise to unprecedented challenges in fault diagnosis. These systems, characterized by their intricate network of interconnected components and subsystems, require sophisticated diagnostic techniques to ensure their reliable and safe operation. Furthermore, faults within these systems could have far-reaching implications, which may cause performance degradation, system failure, and even catastrophic accidents. 1 Therefore, developing effective and robust methods of fault diagnosis can be of paramount importance.
The existing fault diagnosis methods can be classified into model-based, signal-based, knowledge-based methods. 2 The knowledge-based methods, also known as data-driven methods, can help extract the underlying knowledge about the systems without previously known models or signal patterns based on the collected historical data. Such methods can be effective for complex systems where the explicit system models or signal symptoms are hard to establish. Currently, machine learning methods have been widely applied in the data-driven fault diagnosis, 3 such as support vector machine (SVM), k-nearest neighbor (KNN), and neural network (NN).1,4,5 These machine learning methods can help establish well-performing models with a large amount of data.
However, in some cases, there may not be enough data for model training, such as the situations where the complex systems are newly applied or used infrequently, and the data collection may cost too much time. In such cases, the model trained with insufficient data may not perform well on the target task of fault diagnosis. In addition, machine learning methods work well under a general assumption: the training data and the testing data should be drawn from the same distribution. 6 Even if there exists a large amount of data collected from a similar system, the obtained model trained using the data can still perform poorly on the target task with a different data distribution.
To address the problems mentioned above, more and more attention has been paid to transfer learning. Transfer learning methods are proposed to learn and transfer shared knowledge from a similar domain (source domain) to the current domain (target domain).7,8 Transfer learning methods have been widely applied for fault diagnosis. For example, Zhao et al. 9 proposed a transfer learning method based on bidirectional gated recurrent unit and manifold embedded distribution alignment, to tackle the fault diagnosis problem with limited labeled data; Wu et al. 10 developed an adaptive deep transfer learning method for bearing fault diagnosis, which was constructed based on instance transfer and feature transfer; Liu et al. 11 proposed a transfer learning method based on model transfer for fault diagnosis in building chillers; and Yang et al. 12 proposed a feature-based transfer learning neural network to identify the healthy conditions of real machines with the diagnosis knowledge obtained from experimental machines. The above-mentioned studies demonstrate the effectiveness of transfer learning in tackling fault diagnosis problems with few or even without labeled data, and transfer learning is thus studied in this paper.
In addition, many machine learning methods are considered black-box, where the process of generating decisions could be complicated for decision makers to understand. The generated model may not be suitable for high-stacks decision making. 13 In high-stakes decisions there are often considerations outside the collected data that need to be combined with a risk calculation. It may be hard to manually calibrate how much the additional information adjusts the estimated risk with a black-box model. For example, in the fault diagnosis, there could be some conditions that are not easy collected as data, but very useful for the diagnosis of specific system or components. Besides, it can be unclear what factors are considered in the construction of the model, which could lead to risky or unreliable results. For example, the chatbot Tay in 2016, designed to continuously learn and improve through interactions, became a “troubled girl” embodying gender discrimination, and racial prejudice within less than 24 h of engaging with humans. The black box nature of machine learning algorithms, in which the decision-making process becomes opaque and difficult to trace, exacerbates the potential for unintended consequences.
Building the diagnosis model with an explainable method, such as decision tree, can thus be essential for complex system with high reliability. In existing machine learning methods, decision tree, logistic regression, and linear regression can be more explainable than others from the perspective of model. Compared with the linear methods, decision tree can capture the nonlinear relationship, and extract more complicated patterns. Currently, some decision transfer learning methods based on decision tree have been proposed, such as Structure Expansion Reduction (SER), Structure Transfer (STRUT), and Transfer in Decision Trees (TDT) methods.14–16 In these methods, STRUT method keeps the structure of the source decision tree but adjust its threshold values, and SER and TDT methods use the labeled target data to adjust the structure of the decision tree trained using the source data, which could be more flexible on knowledge transfer. Compared with STRUT method, SER and TDT methods could be more flexible considering the domain dissimilarity. Different to TDT method, in SER method, after expanding the source decision tree, a reduction operation is then conducted to further improve the tree structure. The SER method is thus focused in this study.
Existing transfer learning methods can be classified into four categories according to the transferred objects, including instance, feature, model and relationship. 17 SER is a model-based transfer learning method, but can be different from the existing transfer learning methods. In instance-based transfer learning, the shared knowledge is assumed to be contained in the source data, and the data weights are estimated or the data are selected to help adapt the marginal distributions. For examples, Huang et al. 18 proposed Kernel Mean Matching (KMM) to match the means between the source and the target data in a Reproducing Kernel Hilbert Space, and Sugiyama et al. 19 proposed Kullback-Leibler Importance Estimation Procedure (KLIEP) to minimize the Kullback-Leibler (KL) divergence of the source and the target data. Feature-based methods focus on transforming one feature representation to align with those of the other one, or transforming both feature representations to align them to each other. For examples, Daumé 20 proposed the Feature Augmentation Method to transform the original features by feature replication, Pan et al. 21 proposed the Transfer Component Analysis (TCA) to adapt marginal distribution by minimizing the distribution difference using Maximum Mean Discrepancy, and Fernando et al. 22 proposed Subspace Alignment (SA) to transform source subspace obtained with Principal Component Analysis into the target one. Model-based methods assume that the knowledge can be shared with the model or its parameters. For examples, Duan et al. 23 proposed a framework, Domain Adaptation Machine, to construct a robust classifier with some base classifiers preobtained on multiple source domains, Zhuang et al. 24 proposed the Matrix Tri-Factorization Based Classification Framework to characterize the connections among the document classes and the concepts conveyed by the word clusters using parameters, and Gao et al. 25 proposed an ensemble-based framework, Locally Weighted Ensemble, to combine various learners generated with different source domains or learning algorithms. Relational-based transfer learning approaches focus on transfer the learned source’s logical relationships or rules to the target domain. For examples, Wang et al. 26 proposed a relational knowledge transfer to extract the relational knowledge from data manifold structure and transfer it backwards to help generate virtual data for unseen categories, and Qin et al. 27 proposed a relational-based transductive transfer learning method, where the time series are clustered using the similarity measured with the relational knowledge.
Compared with the instance-based methods, SER can better dig the deep knowledge with the decision tree model, which can avoid the problem of the high dissimilarity between the marginal distributions or the high inconsistency between the label spaces. In addition, most feature, model and relational-based transfer learning methods could be a black box for certain tasks, while the SER constructed based on decision tree can be of better interpretability, where the results can be more reliable for diagnostic problems of complex system. However, the original SER only focus on transferability between the tree structures at the source and the target domain, where the marginal distribution is not considered when applicable, which can further facilitate the knowledge transfer.
In this work, a cross-domain decision method is proposed based on the improved SER method. In the proposed method, features are first extracted from the time domain, the frequency domain and the time-frequency domain. The data weights are then estimated following the idea of instance transfer. The extracted features are selected based on the estimated data weights. The knowledge contained in the source decision tree model is further transferred using the proposed weighted SER (WSER) method by considering the estimated data weights.
The main contributions of this paper include: (1) A cross-domain decision method WSER is introduced based on decision tree with instance transfer and model transfer. (2) The weights of the labeled source and the target data are calculated following the idea of instance transfer. (3) A new feature selection algorithm is developed to prioritize and select features with the estimated data weights. (4) The effectiveness of the proposed method is demonstrated through its application on two engineering fault datasets, showcasing its practical utility.
The remainder of this paper is organized as follows. Section 2 briefly reviews the preliminaries of the related algorithms. Section 3 elaborates the details of the proposed method. The proposed method is further verified using two public engineering fault datasets in Section 4. Finally, this paper is concluded in Section 5.
Theoretical backgrounds
Feature extraction
Fast Fourier transformation
Fast Fourier Transformation (FFT) is an algorithm used to efficiently compute the discrete Fourier transform (DFT) of a sequence or time-domain signal. 28 The FFT algorithm is widely used in various fields, including signal processing, image processing, audio analysis, and many other applications that involve analyzing the frequency content of signals.29–31
The main advantage of the FFT algorithm is its computational efficiency, making it possible to perform high-speed spectral analysis on large sets of data in real-time or near real-time applications. The algorithm exploits the symmetry and periodicity properties of the DFT to reduce the number of computations required. It divides the DFT calculation into smaller subproblems and recursively combines the results, resulting in a significant reduction in computational complexity.
Based on the FFT algorithm,
30
the spectrum
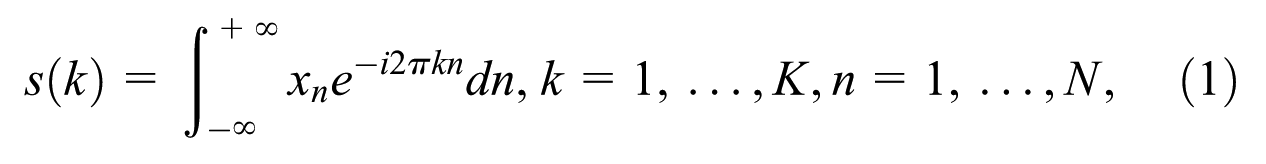
where

where
By evaluating vibration signals of fault condition with those of the healthy condition through FFT algorithm, the fault diagnosis can be better conducted with specific frequency components.
Wavelet packet transform
Wavelet Packet Transform (WPT) algorithm is a signal processing technique that extends the capabilities of wavelet analysis by providing a more detailed and flexible decomposition of signals into subbands.32,33 It is a multi-resolution analysis tool that allows for a more comprehensive exploration of signal features in both time and frequency domains.
Unlike traditional wavelet analysis, which decomposes signals into a binary tree structure of low-pass and high-pass subbands, the WPT algorithm decomposes signals into multiple subbands at each level, allowing for a richer representation of signal components. This decomposition can be performed recursively to achieve greater granularity and capture fine-scale details in the signal. 34 The WPT algorithm provides a flexible framework for signal analysis, offering the ability to select and analyze specific subbands of interest. The WPT algorithm is thus used in this paper to extract the time-frequency domain features.
Given a wavelet packet function

The computation of the wavelet packet coefficients
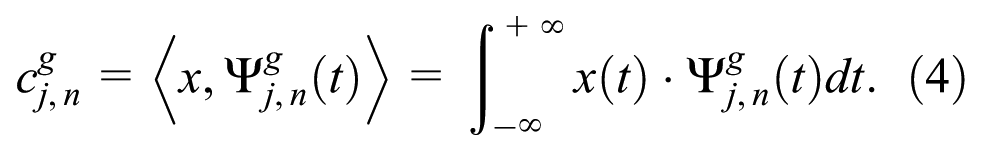
The wavelet packet node energy

The obtained
Feature selection
Feature selection is a process of selecting a subset of relevant features or variables from a larger set of available features, which can be an important step in the preprocessing stage to improve model performance, reduce overfitting, and enhance interpretability.
The objective of feature selection lies in identifying and retaining those features that hold the highest value of information and discriminatory power for the target task, while discarding irrelevant or redundant features that may introduce noise or add unnecessary complexity to the model.
Feature selection algorithms can be broadly categorized into three types, including filter, wrapper, and embedded algorithms. 36 Filter algorithms rank features based on the statistical properties or the relevance to the target variable, wrapper algorithms evaluate feature subsets by using a specific learning algorithm, and embedded algorithms incorporate feature selection as part of the learning algorithm itself.
In this paper, the recursive feature elimination (RFE) algorithm is mainly considered. As a wrapper algorithm, the RFE algorithm can consider the interaction and combination effects of features, which can lead to more accurate feature selection.37,38 The RFE algorithm incorporates the model performance during the feature selection process, which ensures that the selected features are directly related to the model performance. In addition, the RFE algorithm is a flexible algorithm that can be used with various methods for model construction. The application of other feature selection algorithms in different scenarios is not extensively discussed in this paper.
Methods
In this section, a cross-domain decision method aimed at fault diagnosis is proposed by considering instance and model transfer. Initially, features are extracted from time series data, and subsequently, the data weights are heuristically estimated. Feature selection proceeds based on these estimated weights. The source knowledge related to fault diagnosis is then acquired from the source domain via decision tree. This knowledge is subsequently transferred to the target domain employing the WSER method.
Framework
The operational physical parameters of machinery serve as references that aid in abnormality detection and diagnosis., and high-sensitivity accelerometer-generated vibration signals are primarily utilized for this purpose.39,40 The vibration signals collected as time series data are thus mainly focused on in this paper.
Given two fault diagnosis problems from the source domain

The process of the proposed method.
As stated in Figure 1, to help extract the fault patterns from the signal data in time series, the features are first extracted with the data
Feature extraction
The features derived from vibration signal data encapsulate the health status information of machine components, holding crucial importance for fault diagnosis and prognosis. 41 Signal processing techniques across a multitude of domains − time, frequency, and time-frequency, have been leveraged on the collected vibration data to glean a variety of original features.34,42
In this section, various features are extracted from time, frequency, and time –frequency domains, which could be further used to help construct the diagnosis model.
Time-domain features
Time-domain analysis, a straightforward technique typically used in the initial stages of mechanical fault diagnosis, provides amplitude information of the signal in relation to time. 41 Statistical attributes are often involved in time-domain features, which are particularly sensitive to impulse faults. 33 The 16 dimensional features are calculated in this paper, such as mean, absolute mean, variance, and so on, which are defined as in Table 1.
Time-domain features.

Frequency-domain features
Frequency-domain approaches typically entail an analysis of vibration signals to identify characteristic frequencies associated with the rotation of bearings. 30
The FFT is adopted on the time-domain vibration signals to help extract the frequency-domain features, which can provide information on defect frequencies of the components. 43 The 12 features are calculated considering the statistical results of frequency, such as mean, variance, maximum, and so on, 39 which are defined as in Table 2.
Frequency-domain features.

Time-frequency-domain features
As stated above, time-domain features and frequency-domain features are easily extracted and commonly used in fault diagnosis. However, time and frequency information cannot be simultaneously considered in the extracted features above. Time-frequency domain analysis is thus further utilized to help extract comprehensive features, which may be more effective in fault diagnosis. 44 Many time-frequency domain analysis technologies have been developed, including short-time Fourier transform (STFT), wavelet packet transform (WPT), Hilbert-Huang transform (HHT) algorithms, etc.33,45,46 In this paper, the WPT algorithm is adopted to extract the time-frequency-domain features with accelerometer sensor signals due to its flexible decomposition, excellent time-frequency localization, computational efficiency, and wide applicability.34,40,47
The vibration signals are first decomposed into four scales using WPT algorithm, and the procedure can be referred in Rauber et al.
34
The energy values of wavelet packet nodes are further calculated at the 4th level, deriving 16 time-frequency-domain features,
33
with decomposition refined down to the fourth level. and refining is done down to the fourth decomposition level. This analysis considers a 1-D time-domain vibration signal comprising
In WPT algorithm, with a tree depth of
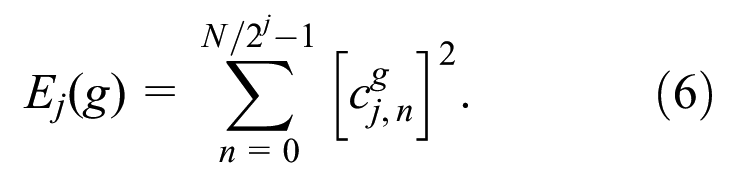
Then, the
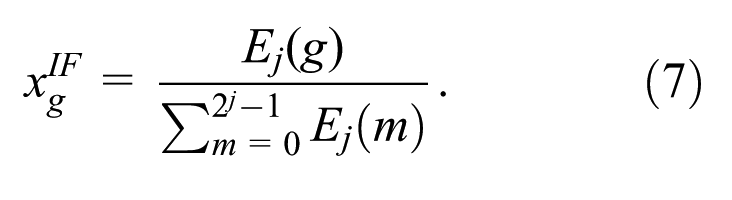
With tree depth
Weight estimation
After the data
Given the source data
The weights are then normalized as

A model is then trained using decision tree with the labeled data
Then the error of the derived model on

where


where
And the weights can be updated as

where
To avoid the overfitting of the target labeled data, the max iteration number
Feature selection
As stated above, 44 features are extracted from the data. However, not all features are very relevant to model construction, and the irrelevant or redundant features may lead to model overfitting or high complexity. 50 The feature selection is thus conducted to help find the most effective features, which can also assist in reducing the data dimensionality and complexity. 36
To obtain the relevant feature subset from the 44 features, the RFE algorithm is applied in this paper, where decision trees serve as the base classifier, which is wrapped by the RFE algorithm. Compared to other classification methods, decision tree can have better interpretability, which is also used for model construction and knowledge transfer in the source and target domains in the subsequent sections. Decision tree is thus chosen here as the base classifier for feature selection to help keep consistency. The
The
As stated above, the source data with high weights can be more similar to the target data, and the
Model construction based on instance and model transfer
When the data
As stated above, when labeled target data
The source model is first trained using the source data
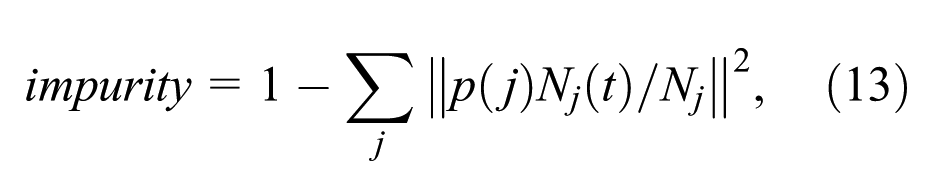

where
After the source model
Similar to SER method, WSER applies two transformations using the limited labeled target data
Given a leaf node
The reduction is then conducted based on the leaf error and subtree error. These are defined as the empirical error on

where
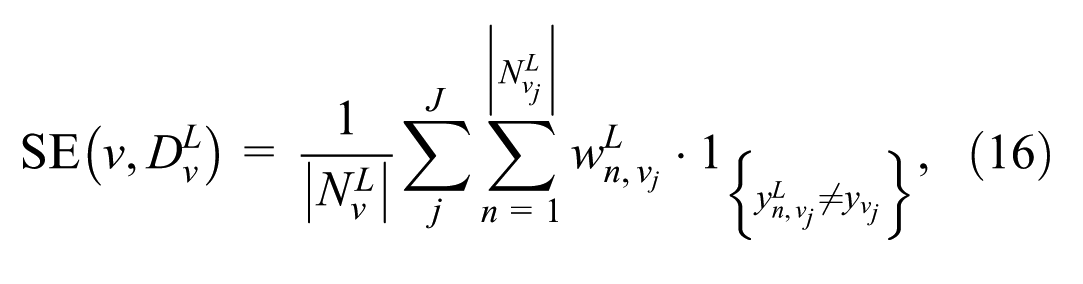
where
The WSER algorithm is summarized as follows.

Experiments
To validate the effectiveness of the proposed fault diagnosis method, the method is adopted on two public engineering fault datasets, including the bearing data provided by the Bearing Data Center of the Case Western Reserve University (CWRU) and the gearbox dataset from the Southeast University (SEU). The comparative experiments of the proposed method against machine learning and transfer learning-based methods are performed to underscoring its effectiveness.
Dataset
CWRU dataset
The CWRU dataset, widely recognized as a standard in rolling bearing fault diagnosis datasets, encompasses a driving motor, a torque transducer, and a load motor. Test bearings 6205-2RS JEM SKF and 6203-2RS JEM SKF are mounted at the drive end and the fan end of the driving motor, respectively, to uphold the motor shaft. 53 Bearing vibration data are collected by the acceleration sensors mounted at the ends of driving motor under various operational loads and bearing conditions. 33 The CWRU bearing data have been used extensively in various researches, which can provide an effective validation for bearing fault diagnosis.1,53,54
The vibration signals collected at the sampling frequency of 12 kHz are adopted in this paper. Four kinds of bearing health conditions are identified in the data, such as normal (N), inner race fault (IR), outer race fault (OR), and roller fault (RF). Different fault diameters, 0.007, 0.014, and 0.021 in, are contained in the three types of faults. All bearings are re-fitted onto the testing rig under four distinct operational conditions, that is, the constant speeds for motor loads of 0, 1, 2, and 3 horsepower (HP). These loads correspond to the motor’s four types of speeds, which are 1797, 1772, 1750, and 1730 rpm, respectively.
To extract the samples from the signal data, the sample length is set as 1024, which means each sample contains 1024 signal points. 9000 samples are randomly extracted from the signal data under different operating conditions. The details of the preprocessed data samples are given in Table 3.
The details of extracted CWRU data samples.

As shown in Table 3, four datasets are obtained after data preprocessing, where data have the same label spaces of health conditions, but are collected under different operating conditions. To validate the effectiveness of the proposed method, 12 transfer tasks
SEU dataset
The SEU dataset is a gearbox dataset collected from the Drivetrain Dynamics Simulator by Shao et al. 55 The details of SEU dataset is given in Table 4. This dataset consists of two sub-datasets, including the bearing and gear datasets, where eight channels were collected, and the data of channel 2 are mainly used following the setting of the work in Zhao et al. 56
The details of extracted SEU data samples.

As shown in Tables 4 and 5 different health statuses can be found in two sub-datasets, including one health and four fault statuses, while the fault statuses can differ between bearing and gear. The transfer tasks are established between two different working conditions with rotating speed system load set to be 20 Hz – 0 V or 30 Hz – 2 V for each sub-datasets, which are separately denoted as tasks 0 and 1. In total, there are four transfer learning settings, including
Performances of the

Note. Bolded results indicate the best model performance under the same conditions.
Results
Results of CWRU dataset
Performance of the proposed method
Following data preparation, the proposed method is employed to verify its efficacy. As delineated above, 12 transfer tasks are performed. Each task consists of a source domain
The data weights are further estimated, and the weighted data are used for feature selection using
The proposed method WSER is then used to generate the target diagnosis models based on the obtained data
As shown in Table 5, the
Effect of different categories of features on model performance
To understand how time, frequency, and time-frequency features affect diagnostic model performance, models are constructed using each of these feature types separately. They are examined by
As shown in Table 6, the models constructed using only time features comprehensively perform worse than those based on frequency features and time-frequency features. The frequency feature based models comprehensively perform better than time-frequency feature based models comprehensively. In addition, the models constructed using all the features perform better at the most cases. The results show that among three categories of features, the frequency features can be more important than others, which means the fault status tends to be reflected by the frequency information of the CWRU dataset.
The performance on CWRU dataset constructed with different categories of features.

Note. Bolded results indicate the best model performance under the same conditions.
Feature selection in transfer tasks on CWRU dataset
As stated in Section 3.4, the features are ranked using RFE algorithm, and the ranking results are presented in Figure 2 to illustrate which features are more important for model construction on the specific tasks.

The feature selection at 10 iterations on tasks
As shown in Figure 2, on the tasks
Results of SEU dataset
Results of the proposed method
For SEU dataset, four transfer tasks are performed. Each task consists of a source domain and a target domain, with 4500 pieces of training data in
Performances of the

Note. Bolded results indicate the best model performance under the same conditions.
As shown in Table 7, the
Effect of different categories of features on model performance
The performance of models constructed with time, frequency, and time-frequency features are given as follows to help learn the effect of different categories of features on the transfer tasks for SEU dataset.
As shown in Table 8, the models constructed using all the features perform better at the most cases. Differently, the time feature based models perform poorly compared with other models, and the time-frequency feature based models show better performance compared with frequency feature based models on tasks
The performance on SEU dataset constructed with different categories of features.

Note. Bolded results indicate the best model performance under the same conditions.
Feature selection in transfer tasks on SEU dataset
The ranking results of SEU dataset are further presented in Figure 3 to show feature importance on the specific tasks.
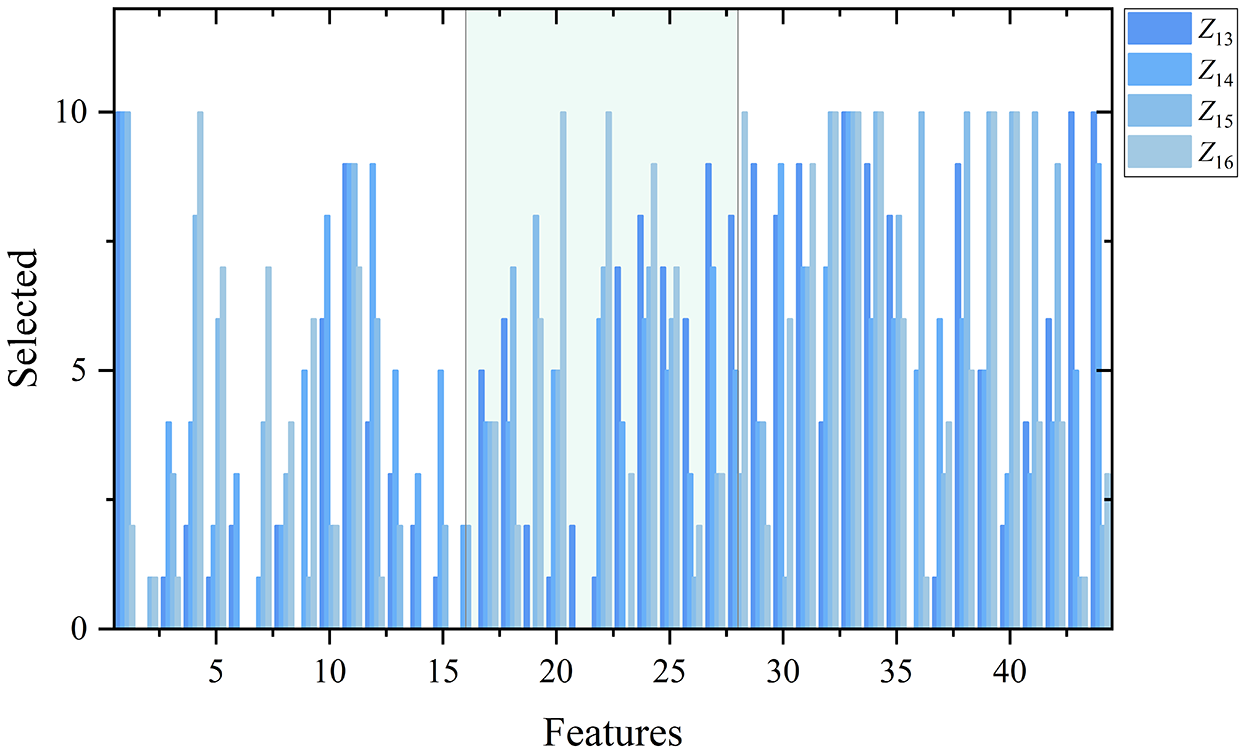
The feature selection at 10 iterations on tasks
As shown in Figure 3, on the tasks
Comparative analysis
Comparison with machine learning methods
Results of CWRU dataset
To further highlight the effectiveness of the proposed method, the performance of the proposed method is compared with those of some typical machine learning methods, including Support Vector Machine (SVM), Logistic Regression (LR), K-Nearest Neighbor (KNN), AdaBoost (ADB), Fully Connected Neural Network (FNN), and Gaussian Naive Bayes (GNB). The six methods are used to train models with the labeled data
Comparison of the proposed method with machine learning methods for CWRU dataset.
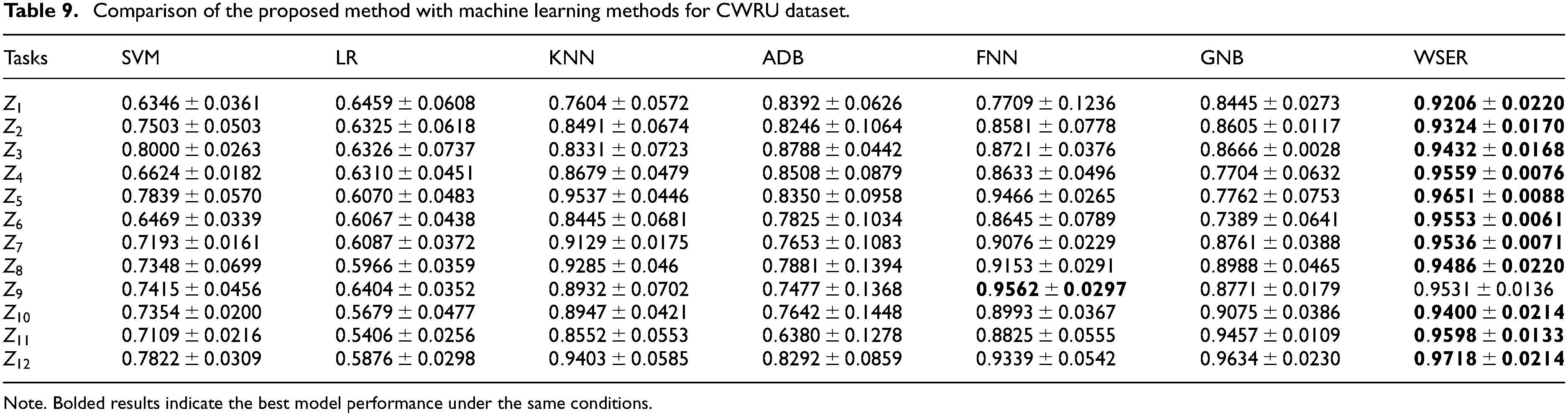
Note. Bolded results indicate the best model performance under the same conditions.
As shown in Table 9, the WSER models perform better than SVM, LR, KNN, ADB, FNN and GNB models on most of the tasks, and only the FNN model performs better than WSER model on task
The models trained using the six machine learning methods with only labeled target data of datasets
Performances of machine learning models in single target domain for CWRU dataset.

As shown in Tables 9 and 10, most machine learning methods perform better with the assistance of the source data. This indicates that the model performance in the target domain can be effectively enhanced by the knowledge contained within the source data.
Results of SEU dataset
The above six machine learning methods are also used to train models with the labeled data
Comparison of the proposed method with machine learning methods for SEU dataset.

Note. Bolded results indicate the best model performance under the same conditions.
Performances of machine learning models in single target domain for SEU dataset.

As shown in Table 11, the WSER models perform better than SVM, LR, KNN, ADB, FNN, and GNB models on most of the tasks, and only the FNN model performs better than WSER model on task
As shown in Tables 11 and 12, the models trained using labeled source and target data perform slightly better than those trained using only labeled target data, which indicates the feasibility of making use of the knowledge contained in the source data. In addition, the performance of the models trained using the proposed methods perform better than others at the most cases, which also indicates the effectiveness of the proposed method.
Comparison with transfer learning based methods
Results of CWRU dataset
The WSER method is developed based on the integration of the decision tree method and transfer learning. Its efficacy can also be underscored when compared with the combination of the decision tree method and other transfer learning methods.
Comparative experiments are performed by employing seven methods, derived via following three different ways.
The methods are given by combining the decision tree method with two instance-based transfer learning methods, including Nearest Neighbors Weighting (NNW) 58 and Kullback-Leibler Importance Estimation Procedure (KLIEP). 19
The methods are given by combining the decision tree method with three typical feature-based transfer learning methods, including correlation alignment (CORAL), 59 transfer component analysis (TCA), 21 and subspace alignment (SA). 22
The methods are given by combining the decision tree method with two model-based transfer learning methods designed for decision tree method, including SER, and STRUT. 15
The performance of the models trained using the methods derived above is examined using
Comparison of the proposed method with transfer learning based methods for CWRU dataset.

Note. Bolded results indicate the best model performance under the same conditions.
As shown in Table 13, compared with the WSER models, TCA model performs better on task
Results of SEU dataset
The models are also trained using the methods derived above on SEU dataset, and examined using
Comparison of the proposed method with transfer learning based methods for SEU dataset.

Note. Bolded results indicate the best model performance under the same conditions.
As shown in Table 14, WSER models performs better than those of other compared methods in all the rest cases, which further highlights the effectiveness of the proposed method.
Discussion
The results presented in Tables 5 and 7 offer insightful observations regarding model performance across different domains. When the models are constructed directly based on the labeled data in the target domain, the model performance can be limited. After reweighting the source data, notable improvements can be observed on some tasks for models built with the weighted data. The enhancement of model performance on specific tasks suggests that data weighting can help reduce the difference in feature distribution between the source and target domains on these tasks. However, there are still some tasks where the model performance gets worse with the weighted data. This may indicate a large difference in feature distribution between the source and target domains on these tasks, making it difficult to bridge this gap through data weighting alone. In contrast, the proposed method, which employs labeled data from both the source and target domains, demonstrates a clear advantage. Its performance surpasses that of models constructed either solely with the labeled data from the target domain or with the weighted labeled data from both domains. This indicates that the validity of the proposed method in not only extracting shared knowledge from the source domain but also in facilitating a more effective transfer of this knowledge between the two domains. Consequently, the proposed method enhances model performance in the target domain, even in situations where the feature distributions between the source and target domains are markedly distinct, which underscores the robustness of the proposed method in adapting to and overcoming challenges posed by significant differences in feature distribution.
In addition, the proposed WSER method outperforms the compared methods without transfer learning, indicating that the knowledge from the source domain can be utilized to construct an effective model for the target task. Moreover, according to Tables 13 and 14, the WSER method achieves better performance compared to other transfer-learning-based methods. These results demonstrate the effectiveness of the WSER method in extracting and transferring knowledge for fault diagnosis.
To sum up, when dealing with limited data in fault diagnosis problems, it can be challenging to construct an effective model due to cost or other limitations. The proposed method addresses this issue by extracting knowledge from a source domain and transferring it to the target domain. The fault diagnosis model built with transferred knowledge can provide better predictive power for the target task. Additionally, the proposed method based on decision tree offers better interpretability compared to other black-box machine learning methods. This transparency allows engineers to understand how the recommended decisions are made, enhancing the reliability of system operation and maintenance.
Conclusion
Data-driven methods can be effective for fault diagnosis of complex systems. However, the application of data-driven fault diagnosis methods can be limited due to the lack of data. To tackle this challenge, this study develops a cross-domain decision method for fault diagnosis. This method can facilitate the knowledge transfer from the source domain to the target domain. Firstly, the features are extracted from the time, frequency, and time-frequency domains. The data weights are determined following the idea of instance transfer, which can reduce the distribution dissimilarity between the source and target data. The extracted features are then selected using the estimated data weights. Finally, the knowledge contained in the source model is transferred to the target domain using the proposed method. The efficacy of the method is thoroughly validated on the CWRU and SEU engineering fault datasets. This validation is further accentuated through a comparative analysis of the proposed method against machine learning methods and other transfer learning-based methods, underlining its superior performance.
The principal limitations of this study are as follows: (1) the proposed method constructs the model with features extracted using specific methods, which may need adjustment in different decision scenarios; and (2) the feature spaces of the source and the target domains are assumed to be the same, which may not be applicable in some problems.
In the next step, the proposed method would be extended to situations where the source and the target domains share heterogeneous feature spaces. In addition, the transfer task with no labeled data available in the target domain will be further investigated.
Footnotes
Handling Editor: Chenhui Liang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by the Science and Technology Project for State Grid Anhui Electric Power Co., Ltd (No. 52120522000M).