
Abstract
The susceptibility of tools in Computer Numerical Control (CNC) machines makes them the most vulnerable elements in milling processes. The final product quality and the operations safety are directly influenced by the wear condition. To address this issue, the present paper introduces a hybrid approach incorporating feature extraction and optimized machine learning algorithms for tool wear prediction. The approach involves extracting a set of features from time-series signals obtained during the milling processes. These features allow the capture of valuable characteristics relating to the dynamic signal behavior. Subsequently, a feature selection process is proposed, employing Relief and intersection feature ranks. This step automatically identifies and selects the most pertinent features. Finally, an optimized support vector machine for regression (OSVR) is employed to predict the evolution of wear in machining tool cuts. The proposed method’s effectiveness is validated from three milling tool wear experiments. This validation includes comparative results with the Linear Regression (LR), Convolutional Neural Network (CNN), CNN-ResNet50, and Support Vector Regression (SVR) methods.
Introduction
Prognostic and health management (PHM) has attracted a considerable amount of attention due to the challenges involved and the development of fault detection, diagnosis and prognosis. Intelligent technologies are applied to solve classification and regression problems with improved recognition and performance. For future machine health prediction, different signal processing, feature extraction, and artificial intelligence (AI) techniques have been developed to ensure human safety and system reliability.1–4 Degradation in dynamic systems state is a completely normal (inevitable) phenomenon, since such systems operate constantly under severe conditions and in continuous (repetitive) tasks.5,6 Therefore, a fault presence is a matter of component operating time. The objective in this domain is to monitor the system’s condition (to detect and diagnose any occurring defects) and, more importantly, to track the fault’s evolution for an accurate estimation of the component’s future condition.
In today’s manufacturing systems, tool wear evolution refers to the progressive deterioration and changes that occur in the cutting tool’s condition over time, while performing machining tasks. During the cutting process, the tool is subjected to various mechanical and thermal stresses, leading to material degradation and wear. Initially, tool wear may be minimal, but friction and abrasion progressively wreak havoc as the tool interacts with the workpiece, causing progressive deterioration. As tool wear progresses, cutting edges may become rounded, reducing the machined part’s precision and surface quality. Monitoring and understanding tool wear evolution are crucial in machining operations to optimize tool life, maintain product quality, and enhance process efficiency through timely tool replacements or adjustments. Employing advanced tool materials and coatings, as well as implementing effective cutting strategies, are essential for mitigating the impact of tool wear in modern manufacturing processes. It is therefore necessary to monitor and predict cutting tool wear to avoid component deterioration and rejected products. 7
Basically, for tool wear monitoring (TWM), three main methods are introduced: physics-based models, data-driven based models and hybrid models. In physics-based models, the physical phenomenon can be expressed in a mathematical degradation model or defects propagation. However, it is very difficult to express a non-linear function which must correspond to a very important system knowledge. In data-driven models, prediction is based on historical data. Such models are widely used, as no detailed knowledge of the monitored components is required. The machines are equipped with sensors and data collection systems that continuously gather information during the machining process. Above all, it generates very satisfactory results with the integration of artificial intelligence (AI) tools as a very powerful learning tool. In hybrid methods, physics and data-based models are implemented to model the tool failure function.8,9 However, this method requires a deep background knowledge and some models are not upgradeable with online data, which limits their application. 10
In the last decade, researchers have focused on the development of AI techniques, which has led to an increased focus on innovation ideas. Numerous studies have presented new health indicators (HI) for better extraction of monitored components.11,12 The main problem with these improvement indicators is that their applicability is very limited to certain signals, and it is not possible to generalize this kind of indicator to other signal categories (temperature, acceleration, acoustics, etc.) under high noise background. The TWM process is based primarily on feature extraction, using various advanced signal processing techniques to isolate defects from noise. Several approaches for signal decomposition, including empirical mode decomposition (EMD). EMD decomposes complex data into intrinsic mode functions (IMFs) using a filter that adapts to the signal. Although the summation of these IMFs provides the same information as the original vibration signal but at different frequency levels, EMD has two main drawbacks: mode mixing and inaccuracies in instantaneous values. To address these issues, the improved EMD (EEMD) introduces finite amplitude white noise to the raw signal during decomposition, and this process is repeated with several sets of white noise to obtain averaged IMFs, reducing the risk of mode mixing and improving accuracy.13–17
The biggest challenge in vibration signal monitoring is the real background noise, often covering fault signatures and making complex signals harder to analyze. Local mean decomposition (LMD) was introduced as an alternative method, decomposing non-stationary signals into product functions (PFs) that consist of signal envelopes and frequency-modulated (FM) signals. Unlike the EMD, LMD requires fewer iterative decompositions and can immediately produce instantaneous frequency modulated (FM) and instantaneous amplitude (AM) without Hilbert transform (HT). However, LMD also shares limitations with EMD, including mode mixing and end effect. To address these issues, researchers proposed the Robust LMD (RLMD), which optimizes the parameter selection process by integrating boundary conditions, envelope approximation, and stopping criteria sifting. Unlike previous studies that focused on individual parameters separately, RLMD employs three algorithms for optimization and uses a heuristic solution to automatically determine the optimal number of sieving iterations in the process. 18 This enhanced approach considers both global and local features of the target signal, aiming to improve the performance of LMD in monitoring complex vibration signals more effectively.19,20
The major issue with big data for online monitoring lies in efficiently handling the continuous data influx, improving accuracy and reducing the time required for analysis. The integration of signal processing techniques can directly impact the results’ accuracy, especially considering the input signal diversity, such as vibration, current, acoustics, temperature, etc. Therefore, research in this area focuses on the machine learning aspect, in particular on developing and extracting a robust and satisfactory model.21–23 To address this, researchers concentrate on feature selection and engineering to identify relevant information from the varied input signals.24,25 Real-time model training is also indispensable for constantly adapting the model as new data appears. Furthermore, the model’s scalability to handle large data sets and its ability to handle data imbalance are key considerations. The research aims to achieve model interpretability, enabling a better understanding and reliability of the model’s predictions.26,27
Deep Learning (DL) methods have gained prominence in Prognostics and Health Management (PHM), 28 including Tool Wear Monitoring (TWM). The research efforts reflect a proactive exploration of DL’s potential, with various studies highlighting advantages, discussing opportunities, and addressing challenges. Rezaeianjouybari et al. 29 introduced a DL-based PHM framework, emphasizing its capabilities. As DL evolves, diverse network types are emerging to address the specific PHM requirements. Zhang et al. 30 proposed a compact Convolutional Neural Network (CNN) to mitigate overfitting, enhancing model generalizability for fault diagnosis. Wen et al. 31 utilized a residual CNN for estimating equipment remaining useful life, leveraging residual connections for efficient learning of complex patterns. 32 Explores tool condition monitoring in machining, collecting data on cutting force, vibration, and surface texture. Signal processing techniques extract time-domain, frequency domain, and time-frequency features. Gray level processing reveals synchronous changes in surface texture features during cutting tool breakage. Subsequently, an intelligent tool wear prediction model is constructed using support vector regression (SVR), with kernel function parameters optimized through grid search, genetic algorithm, and particle swarm optimization. 33
Cai et al. 34 achieved progress in tool condition monitoring through a Stacked Bidirectional Long-Short Term Memory Network (SBiLSTM), effectively capturing temporal dependencies and improving monitoring accuracy, especially for varying conditions. However, as data structures become more complex, a singular network type may prove insufficient. To address this, researchers explore advanced DL architectures, incorporating multiple neural network types and attention mechanisms to handle complex, multidimensional information. Ensembling techniques, combining different network architectures, are also being explored to enhance overall model performance by leveraging individual strengths.
Support Vector Machines (SVM) and Deep Learning (DL) are powerful machine learning techniques, each with distinct advantages. SVM offers training efficiency, simplicity and interpretability making it well suited to small datasets and scenarios in which understanding the model’s decision is crucial. It handles outliers more effectively and requires less data to be efficient. SVM’s explicit feature engineering through kernel functions enhances its capability to capture non-linear relationships. 35 On the other hand, DL excels in complex, high-dimensional data, automatically learning intricate patterns without manual feature engineering. It thrives on abundant data and has achieved remarkable success in image recognition, natural language processing, and speech recognition.
Support vector regression (SVR) represents the algorithm’s basic implementation, suitable for simple regression tasks with linearly separable data. It is designed to find an optimal hyperplane within a predefined margin which best fits the training data. However, its performance may be restricted in complex or non-linear regression problems, requiring feature engineering or kernel transformation. The conventional SVR model’s inherent transparency and control require a thorough grasp of the algorithm, allowing for manual fine-tuning of hyperparameters based on domain expertise. However, this method faces challenges in terms of computational intensity, especially when dealing with large datasets or complex kernel functions. 36
The Optimized SVR (OSVR) is an advanced version that incorporates various techniques to address those drawbacks and boost performance. 37 It includes using different kernels for nonlinear regression, adjusting hyperparameters to improve generalization and utilizing model selection techniques for optimal parameter configuration. 38 OSVR implemented capitalizes on efficiency and optimization, harnessing optimized functions for faster training. The automatic hyperparameter tuning streamlines the modelling process, potentially enhancing predictive performance. 39 Additionally, it provides a parallel computing support and facilitating preprocessing tasks. OSVR excels in handling non-linear regression tasks and complex datasets, offering enhanced predictive accuracy and robustness. 36
Consequently, this paper presents an innovative approach that leverages optimized machine learning algorithms to predict tool wear in machining processes. The proposed method involves several essential stages. First, it extracts a set of features from time-series signals. Next, it integrates an automatic feature selection process, utilizing Relief and intersection feature ranks to automatically select the most relevant features. Finally, an optimized support vector machine is utilized to forecast the wear evolution in cutting tools.
The present manuscript is organized as follows: Section “Mathematical background” introduces the fundamental methodologies encompassing feature extraction, automatic feature selection and OSVM. The proposed method framework is outlined in section “Proposed approach methodology,” followed by the experimental study presentation in section “Experimental setup of CNC machine tool wear.” The proposed method’s application results are presented in section “Results and discussion,” followed by the study’s conclusions in section “Conclusion” and future work in section “Future work.”
Mathematical background
Feature extraction
In signal analysis, scalar feature extraction involves examining the signal to obtain numerical parameters that characterize different aspects of time series signals. 40 These features serve as essential inputs for a variety of analyses, including fault detection, condition monitoring, and machine learning algorithms. Some scalar features commonly used in vibration signal analysis are listed below 41 :
1. Mean: This represents the average value of the vibration signal, providing an indication of its central tendency.

2. Standard deviation (SD): A measure of the dispersion or spread of the signal values around the mean, offering insights into its variability.

3. Skewness (Skw): This feature quantifies the asymmetry of the signal distribution, helping to identify any skewed patterns.

4. Kurtosis (Kur): Describing the shape of the signal compared to a normal distribution, kurtosis indicates whether it is peaked. 42

5. Peak to peak (P2P): P2P indicator is a measure in signal processing that represents the amplitude difference between the maximum positive and maximum negative peaks in a signal or waveform. It provides information about the overall range or magnitude of the signal.

6. Variance (Var): Variance is the average of the squared differences from the mean of a values set. It quantifies the amount of variability or scatter in the data. A higher variance indicates greater variability in the data which indicates a faulty state in acquired signal.

7. Root Mean Square (RMS): The RMS provides a measure of the effective or root mean square value of a signal, it is particularly useful for quantifying the amplitude of varying signals.

Automatic feature selection
Relief feature selection is a technique used in both classification and regression tasks. It selects relevant features from a dataset by evaluating their importance in distinguishing instances in the feature space. The method involves comparing each instance with its nearest neighbours and computing feature importance scores based on the differences in feature values. The top-k features with the highest scores are then selected for building the predictive model, leading to improved performance and reduced dataset dimensionality. 43
A brief overview of relief feature selection is given below:
1. Nearest Neighbor Approach: For each instance in the dataset, Relief compares its feature values with those of its nearest neighbors from the similar target values (for regression). The number of nearest neighbors is a parameter that must be specified using the following equation:

- Where Wi represents the weight assigned to the i-th feature.
- y i is the target value for the i-th instance.
- y[near-hit]j is the target value of the j-th instance among the k nearest instances with similar feature values to the i-th instance.
- y[near-miss]m is the target value of the m-th instance among the l nearest instances with dissimilar feature values to the i-th instance.
2. Feature Importance Scores: Relief computes an importance score for each feature based on the differences between the feature values of the instance and its nearest neighbors. These feature scores indicate how much they correlate with the target variable (regression).
3. Selecting Top Features: Once the importance scores of all the features have been calculated, the top-k features with the highest scores according to fixed threshold (Thresholdrank = 0.5).
In our research, a comprehensive feature selection strategy is used to improve the robustness and generalization capabilities of our predictive models. This approach involves the use of three distinct learning method types (C14, C16, and C46), using various machine learning algorithms or models (Figure 1).

Feature selection steps.
First, each of these learning methods is applied independently to our dataset. For each method, specific feature selection criteria or techniques are used to identify the most relevant features.
Next, the intersection of the ranking of features selected by the three learning methods is performed. This step allows to isolate the subset of features that are consistently important in the different learning techniques. These selected features are referred to as “stable features” and ensure that the predictive models are based on the most significant and reliable information, thereby enhancing their performance and accuracy. Secondly, this approach is used to avoid the data over-fitting issue, which can affect estimated TWM results.
Optimized support vector regression
The optimization problem described can be solved more easily in its Lagrange dual formulation. The solution to the dual problem provides a lower bound for the solution of the primal problem. However, the optimal values of the primal and dual problems may differ, creating a “duality gap.” In convex problems satisfying a constraint qualification condition, the optimal solution of the primal problem can be determined by solving the dual problem. 44 To obtain the dual formula (L), a Lagrangian function is constructed from the primal function, introducing nonnegative multipliers for each observation. The goal is then to minimize this dual formula.

In nonlinear SVM regression, the dual formula replaces the inner product of the predictors (xi, xj) with the corresponding element of the Gram matrix (gi, j). The goal of nonlinear SVM regression is to find the coefficients that minimize a certain objective function. 45

Subject to
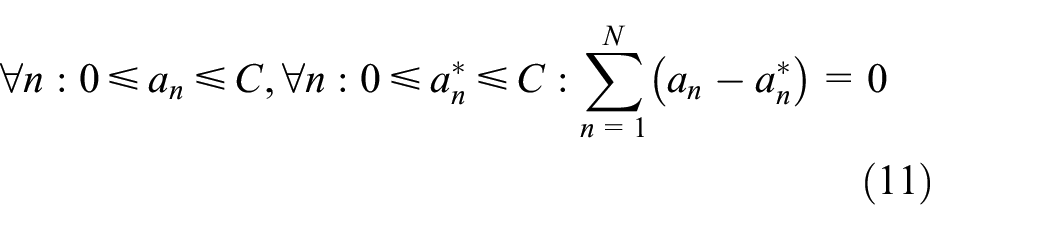
The function used to predict new values f(x) in nonlinear SVM regression is typically equal to:

The minimization problem in nonlinear SVM regression can be expressed in the standard quadratic programming form and solved using common quadratic programming techniques. However, the computational cost can be high, especially when dealing with large Gram matrices that cannot fit into memory. To overcome this, decomposition methods, also known as chunking and working set methods, can be employed.
Decomposition methods involve dividing the observations into two separate sets: the working set and the remaining set. By modifying only the elements within the working set during each iteration, these methods reduce the storage requirements. This is achieved by utilizing only a subset of columns from the Gram matrix in each iteration.
One popular approach for solving SVM problems, including nonlinear SVM regression, is the sequential minimal optimization (SMO) method. SMO performs a series of two-point optimizations. In each iteration, a working set of two points is chosen based on a selection rule that incorporates second-order information. The Lagrange multipliers for this working set are then analytically solved using a specific approach described in Fan et al.46,47
In SVM regression, the gradient vector (∇L) for the active set is updated after each iteration. The decomposed equation for the gradient vector can be expressed as follows:

The iterative single data algorithm (ISDA) is an approach in which one Lagrange multiplier is updated in each iteration. 48 ISDA is commonly used without the bias term, denoted as b, by incorporating a small positive constant, typically denoted as a, into the kernel function. By omitting the bias term, the constraint related to the sum of Lagrange multipliers is no longer considered.

Each of the solver algorithms iteratively computes until a specific convergence criterion is satisfied. There are several options for convergence criteria, including:
- After each iteration, the software assesses the feasibility gap. If the feasibility gap is found to be smaller than the specified value defined by Gap Tolerance (GT), then the algorithm has satisfied the convergence criterion. At this point, the software returns a solution. The feasibility gap refers to the measure of how close the current solution is to satisfying all constraints and optimality conditions. By comparing the feasibility gap against the GT threshold, the algorithm determines whether the solution has converged adequately.

- After each iteration, the software evaluates the gradient vector (∇L). It checks whether the difference in the gradient vector values between the current iteration and the previous iteration is smaller than the specified value defined by delta gradient tolerance (DGT). If this condition is met, the algorithm is considered to have satisfied the convergence criterion, and the software returns a solution. The DGT criterion ensures that the gradient vector has converged sufficiently, indicating that the optimization process has reached a stable point.
- After each iteration, the software calculates the karush-kuhn-tucker (KKT) violation for all the αn and
Evaluation criteria
Root Mean Square Error (RMSE) and Mean Absolute Error (MAE) are both widely used performance metrics for evaluating regression models in machine learning. They provide a measure of how well the model’s predictions match the actual target values. However, there are some differences between these two metrics 49 :
The RMSE calculates the square root of the average of the squared differences between the predicted values and the actual target values. By squaring the errors before averaging them, RMSE gives higher weight to larger errors, making it more sensitive to outliers compared to MAE. RMSE also has the advantage that it represents the standard deviation of the prediction errors, which is useful for understanding the spread of the errors. However, because of the squaring operation, RMSE penalizes large errors more heavily, which might not be desired in certain applications.

MAE measures the average absolute difference between the predicted values and the actual target values. It provides a simple and interpretable metric that directly represents the magnitude of the prediction errors. MAE is less sensitive to outliers since it considers the absolute values of the errors, which means that large errors do not have a disproportionately large impact on the overall metric. However, MAE does not penalize larger errors as strongly as RMSE does, which can be a drawback if you want to give more weight to larger errors.

Where,
Proposed approach methodology
The proposed methodology comprises essentially three parts as shown in Figure 2:
(a) Feature extraction: The initial phase involves the extraction of a diverse features set from time-series signals obtained during milling processes. This meticulous process captures essential characteristics reflecting the dynamic signals behavior. These features serve as crucial input variables for subsequent analyses, providing a nuanced understanding of the underlying patterns in the machining data.
(b) Feature selection: Following feature extraction, a refined feature selection process is introduced. This process is characterized by its meticulous nature and employs Relief and intersection feature ranks (described in section “Automatic feature selection”). By doing so, the approach automatically identifies and prioritizes the most relevant features among the extracted set. This strategic selection ensures that only the most informative features contribute to the subsequent modeling, optimizing the analysis efficiency and effectiveness.
(c) ML regression: The final phase integrates an optimized support vector machine into the machine learning regression framework (described in section “ Optimized support vector regression”). This sophisticated algorithm is specifically tailored to predict the wear evolution in machining tool cuts.

Diagram of proposed approach.
Experimental setup of CNC machine tool wear
The data set corresponds to a computer numerical control (CNC) cutting tool is introduced in the prognosis and health management (PHM) challenge provided by Simtech Institute in Singapore. 50 The experimental setup consists of six cutter tools used to cut an identical piece over identical cycle. Total cycles number is equal to 315, in which a cycle represents a single cutting operation of a workpiece (315 cuts). Table 1, shows the detail of CNC cutting tool.
CNC machine tool parameters.

Figure 3 shows the experimental set-up platform. A microscope was used after each cut to measure tool flank wear, and these values are taken as target samples. A tri-component force transducer was installed between the workpiece and the machining table to measure cutting force, while the acceleration and acoustic emission sensors are mounted on the workpiece to collect vibration and acoustic emission signals using a National Instrument (NI) PCI1200 card with a sampling frequency of 50 kHz. The signals collected are then amplified using a Kistler multi-channel load. 51

Experimental setup.
The data for a single cut contains the measured wear value for the target and the seven signals collected for the inputs, of which the first three signals are the X, Y and Z dimensions of the force (N), the second three signals X, Y and Z of the vibration (mm/s2) and the last for the acoustic emission (V). Only three out of six milling cutters (C1, C4, and C6) are labelled with a wear measurement.
The wear of each individual flute was assessed through manual inspection utilizing an optical microscope (LEICA MZ12). The elements of CNC machines and tool degradation are presented in the Figure 4.

(a) The workpeace and cutter and (b) cutter degradation after 315 cuts. 51
In the context of our research, Figure 5 illustrates the process through which experimental data is systematically acquired. This particular illustration provides an overview of the sequential steps and methodologies involved in collecting essential information for our study. Additional information regarding the material of cutters and experimental specifications can be found in reference. 52

Platform of experimental data acquisition. 10
Results and discussion
The tool wear of the three cutters (C1, C4, and C6) are measured from the degraded blade after each cutting operation in three different flutes (Figure 6). The black curve represents the average of the degraded flute wear. The average is used to estimate the overall average wear degradation on any material type. The objective of this study is to avoid incorporating material characteristics into the AI-based prediction model.
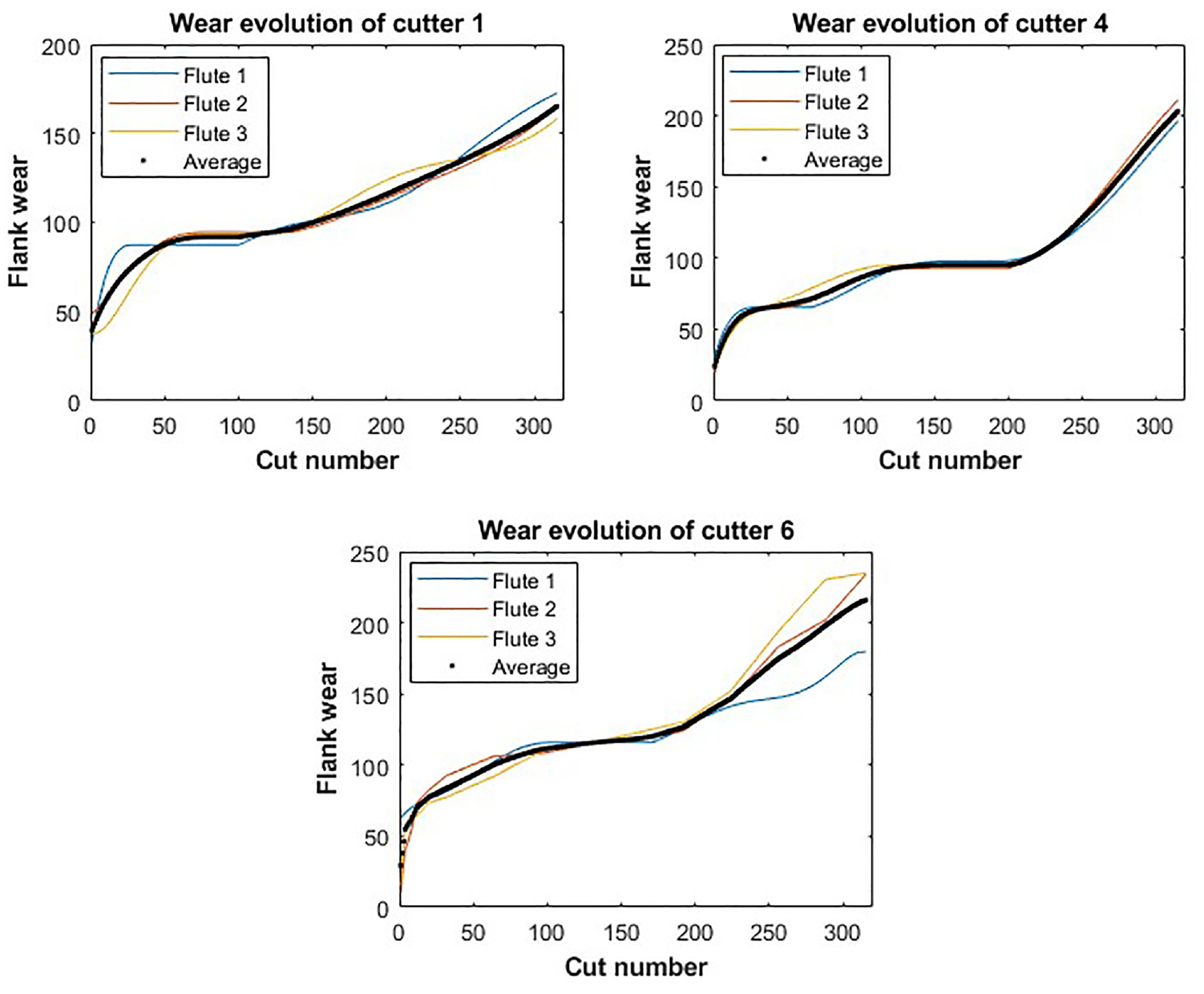
Wear degradation flutes of three cutters.
Figure 7 illustrates wear degradation within the cutting tool process. In this display, the specific values associated with wear degradation are presented as a target, facilitating recognition and understanding within the model framework.

Averaged wear degradation of three cutters.
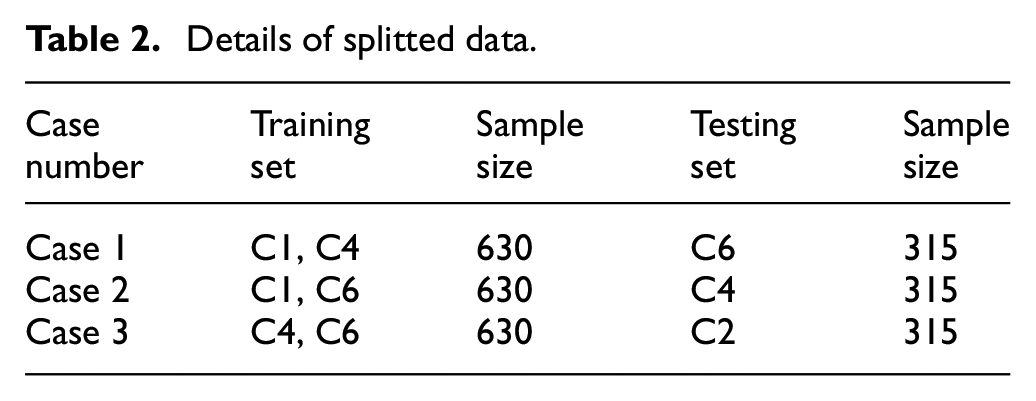
Table 2 provides the data size, with the training set comprising 630 samples from the two cutting machines: C1–C4 for case 1, C1–C6 for case 2 and C4–C6 for case 3. Meanwhile, the test set consists of 315 samples distributed as follows: C6 for case 1, C1 for case 2 and C4 for case 3.
Details of splitted data.
A specific feature set is subsequently derived from the first six signals. These features play a crucial role in capturing the distinct characteristics of defect degradation. Using these features, the objective is to closely monitor the evolution and propagation of wear in cutters. This analytical approach allows a comprehensive understanding of wear progress as a function of the cut number, and how it propagates through the machine components.
Figure 8 illustrates a set of features extracted from the input signals of three distinct cutters: C1, C4, and C6. These features, characterized by their monotonic behavior, serve as effective indicators for monitoring wear degradation. Among these indicators, those with the highest correlation with outputs are considered particularly valuable. From the Figure 8, it is clear that the main extracted features exhibit a monotonic trend. The standard deviation (STD) of the initial signal is particularly noticeable, while the other features are unnoticed due to their extremely low values. These values are derived from signals 1 to 6.

Features of cutters 1, 4, and 6.
The obtained feature matrices consist of three initial matrices, each containing 315 rows and 42 columns, and these matrices are divided between the three scenarios or cases mentioned above. These three matrices are subsequently fused in the feature selection section, in order to select only those features relevant to the prediction of cutter wear degradation. The regression relief function is used to select the optimal features based on the correlated inputs–outputs for each individual case. This is achieved by selecting features that are consistent across the corresponding cases. This selection process is crucial for establishing normalization among the chosen features, guaranteeing uniform representation across all scenarios. This approach allows prioritizing features that demonstrate stability and reliability in distinct scenarios, reinforcing our analysis’s robustness.
The selected features serve as inputs for our optimized vector regression (OSVR), and the wear prediction results are depicted in Figure 9. In this figure, a good prediction can be observed for monitoring the defect evolution and preventing part damage for the three cutters evaluated: C1, C4, and C6. Further insight into the accuracy of these predictions can be gained from the data presented in Figure 10, which presents the associated prediction errors.
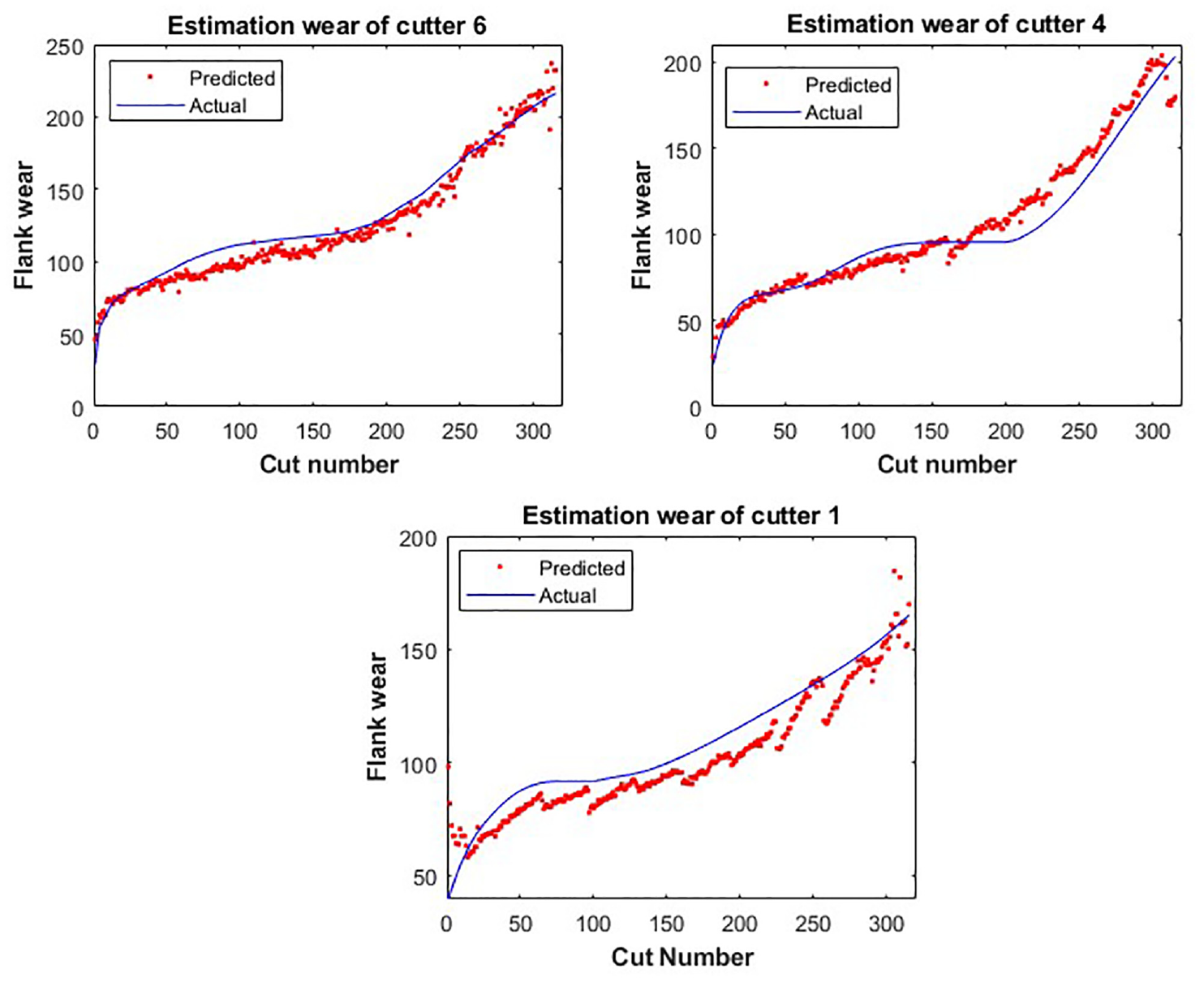
Wear estimation output.

Prediction errors.
Table 3 provides a comprehensive comparison between our proposed approach to tool wear monitoring and several previous studies. 10 The main objective of this comparison is to evaluate and demonstrate the effectiveness of our new methodology. The PAWO presents the proposed approach results without optimization.
Performance of implemented algorithms.

Table 3 clearly indicates a superior level of performance achieved through the use of the proposed approach. This result considerably reinforces the validity and effectiveness of the steps integrated within our methodology. The obtained results highlight the perfect complementarity of the combined elements and steps, reaffirming the robustness and value of the proposed approach compared to the alternatives presented in the table.
Conclusion
The proposed approach, using optimized machine learning algorithms, is a promising solution for predicting tool wear. The process involves two critical steps: feature extraction and automatic feature selection. Feature extraction involves identifying relevant indicators and characteristics in the machining data that can assess the tool wear evolution. Automatic feature selection based on relief and features intersection for learning ensures that only the most informative features are retained, reducing noise, and improving model accuracy. The optimized support vector machine is used to train the wear tool model by introducing the selected features as inputs. The efficiency of the proposed approach is demonstrated by the results obtained in tool wear estimation, comparing favorably to CNN, LR, SVR, and Resnet-50 with respective values of 8.7, 7.1, and 10.4 for RMSE, and 7.7, 7.1, and 7.3 for MAE. These results ultimately contribute to the enhancement of maintenance decision-making for CNC machines. In overall, this research provides valuable insights into the data-driven approach applied to CNC machining and predictive maintenance applications.
Future work
In this study, the data is constrained due to its limited quantity, and an imbalance in the dataset is observed. To solve this problem, our future work will investigate the influence of unbalanced data on machine learning models and implement strategies to mitigate its impact. In addition, exhaustive data labeling requires considerable human effort and hardware resources. To address this challenge, our plan is to explore both the potential of the proposed approach and transfer learning techniques, which have shown promise in solving such problems.
Furthermore, as part of our methodology, we aim to integrate emission acoustic signals into predictive wear analysis, especially considering their limited utilization in research due to white noise challenges. This integration will leverage cutting-edge signal processing techniques, enhancing the precision and reliability of wear prediction without imposing significant execution time constraints on signal processing tools. By implementing advanced signal processing methodologies, we anticipate a more nuanced and accurate evaluation of wear patterns, thereby contributing to a comprehensive understanding of material degradation over time.
Footnotes
Handling Editor: Chenhui Liang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.