
Abstract
In order to accurately and quickly predict the failure probability of gears with multiple failure modes, a novel reliability analysis methodology based on the mixed Copula (MCopula) function model is proposed to deal with the complex correlation among different failure functions. Firstly, we construct a novel MCopula model based on three famous Copula functions: Gumbel Copula, Clayton Copula, and Frank Copula functions. Secondly, we use and improve the particle swarm optimization (PSO) method to optimally calculate the weight coefficients in the proposed MCopula model. Thirdly, the maximum likelihood estimation (MLE) method is adopted to estimate related parameters in the proposed MCopula model. Finally, we verify the proposed reliability analysis methodology with a standard life-prediction case of a strut system and a practical life-problem case of a gear pair system. Comparison results of both cases show that, by using the proposed methodology, the failure probability of a gear pair system with multiple failure correlations can be quickly calculated through a small number of samples and can be estimated as accurately as that by the Monte Carlo scheme. Consequently, our proposed novel methodology successfully analyzes the reliability problems for a gear pair system with multiple failure modes. The proposed methodology can be further applied to solve the reliability problem for other machine parts.
Keywords
Introduction
As an important transmission component, the metal gear is widely and vastly used in automation machines, which is one of the most common failure parts encountered in a mechanical system. 1 Therefore, it is of great significance to study the issue of analyzing and further improving the reliability of gears so as to help extending the service life of whole machine. Traditional reliability theories of mechanical systems or parts were based on the so called “failure modes.” And, it was usually assumed that different failure modes of a machine part are independent with each other. However, in practical applications, it was found that different failure modes of machine parts may be affected by the same factors, such as the load, temperature, and material. That means certain degrees of correlations exist among failure modes.2–7 In the past, many scholars studied the reliability as well as the failure mode problems of mechanic parts.8–15 Ditlevsen 8 first proposed the narrow bound method for system reliability calculations using some widely accepted failure mode correlations. However, this method becomes very complex as the failure mode increases, and the calculation results are limited for factors within a small interval. Cui and Blockley 16 proposed a reliability analysis method based on the interval probability theory, which had a narrower range than the previous narrow bound method. On the basis of Ditlevsen’s theory, Yu et al. 17 proposed a reliability analysis method which uses the linear coefficients scheme to establish the correlation between the primary and the secondary failure modes. And, they verified their proposed method by taking a transmission shaft as an example. Zhou et al. 18 proposed a non-empirical model based on the Nataf transformation to quantitatively analyze the common-cause failure probability of load-dependent systems, which transformed one complex correlation problem into two independent problems. Zhu et al. 19 proposed a combined machine learning strategy to evaluate the fatigue of turbine blade disks. Luo et al. 20 proposed a method combining enhanced uniform importance sampling coupled and support vector regression (EUIS-SVR) for structural reliability analysis with low failure probability. In the above investigations, most of the proposed failure models adopted the assumption that a linear correlation exits among reliability variables. However, these simple models will cause large calculation error of failure probability in structural reliability analysis since the actual relationship among reliability variables are far more complex for this kind of problem.
Because the Copula function has a concise form and is suitable for being used as a model to describe the non-linear relationship between reliability variables, it has received more attention than the linear correlation coefficient method recently.21–23 Tang et al. 24 used Copula functions to analyze the reliability of a system’s structure. Mi et al. 25 proposed a reliability evaluation model which specifically considered the effect of strength degradation, and established the correlation among different failure modes via Copula functions. Sun et al. 21 used the Copula function method to capture the dependent relations among residual life distributions, and performed some tests on a microwave machine to verify their proposed method. Jiang et al. 26 analyzed the reliability of a machine structure based on the vine-Copula function. Their proposed method has been proven to be effective in dealing with complex multi-dimensional correlation problems. Although the single Copula function method introduced above has better accuracy and is more efficient than the traditional linear coefficient method, it is still necessary to find more comprehensive reliability analysis methods when facing highly non-linear problems of finding the failure mode correlations for the complex machine parts such as gears.
To better solve the reliability analysis problem of transmission gears, we propose a novel methodology of the integral mixed Copula (MCopula) function with multiple-failure-correlation modes (IMCMFCM). In this proposed IMCMFCM methodology, we majorly adopt the maximum likelihood estimation (MLE) method and together with the improved particle swarm optimization (IPSO) method to estimate the related parameters appeared in the MCopula function. Besides, to identify the performance of our proposed IMCMFCM methodology, some theoretical as well as practical reliability analysis cases are carried out and the results are compared with those obtained by the standard PSO (SPSO) algorithm based MCopula function, the linearly decreasing inertia weight PSO (LDIPSO) algorithm based MCopula function, 27 and the exponential reduction inertia weight PSO (e2PSO) algorithm based MCopula function. 28
Theoretical bases of IMCMFCM methodology
Copula function
The Copula function is a joint distribution function including a marginal distribution function, which may be used to provide a non-linear correlation between variables. The fundamental theory about the Copula function is given as follows. 29
Supposed that an N-dimensional random variable
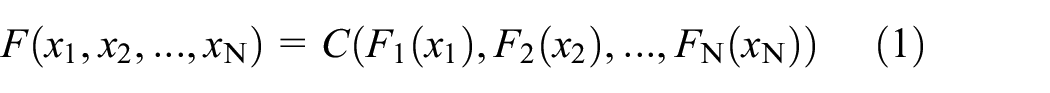
If

where

where
MCopula function
Among the known Copula functions, the Archimedean Copula function was especially popular because of its excellent reliability prediction ability for machine parts. And, the Gumbel Copula, Clayton Copula, and Frank Copula functions were three commonly used Archimedean Copula functions.
31
Different Copula functions can describe different tail features of random variables. The Gumbel Copula function is very sensitive to the upper tail feature of random variables. On the contrary, the Clayton Copula function is sensitive to the lower tail feature of random variables. The Frank Copula function is suitable for describing the symmetric tail feature of random variables.
32
Usually, a single Copula function is valid for describing only partial characteristics of random variables. However, it can neither be used to describe the whole characteristics of random variables with simple correlations nor to or describe the partial characteristic of random variable with complex correlations. To overcome this weakness, we now consider a linear combination of different Copula functions which is a new kind of MCopula function, denoted as

where
It is noted that different Copula functions may be used to correlate random variables of reliability that have different characteristics. Hence, based on the requirement of high prediction performance in the reliability analysis, we carefully choose three commonly used Copula functions: the binary Gumbel Copula function (

Parameters estimation
To optimally determine the parameters appeared in the proposed MCopula function, we firstly use the Monte Carlo (MC) scheme to randomly generate the sample data and the MLE scheme to estimate the dependent parameters, where both schemes were quite successfully applied in reliability analysis problems.3,33,34 Secondly, the weight coefficient is determined by the IPSO algorithm proposed by this study. Details are described as follows.
Sample data generation via the MC scheme
All random variables (
Determination of
Supposed that the marginal distribution functions of the random variables

Then, the joint distribution function of the random variables

Further, the joint density function of
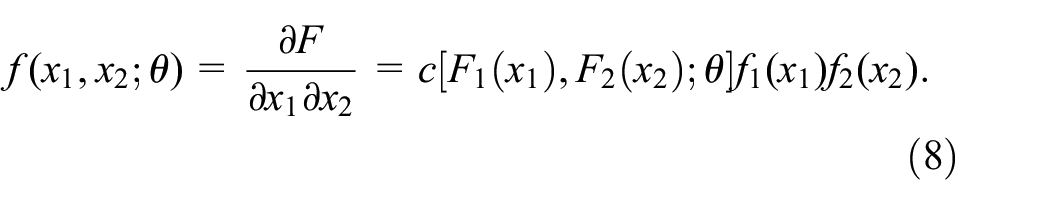
The likelihood function of the samples

The logarithmic likelihood function are:

The optimal value of

The optimal weight coefficient in the MCopula function can be obtained by minimize the Euclidean distance between the empirical Copula function (

where

where
The above optimization equation is a constrained nonlinear equation. By introducing the penalty function, we may transform this constrained problem into an unconstrained one. Eventually, we have the following transformed objective function as:

where
Besides, to improve the solution accuracy of the MCopula function, we adopt the known MLE method and IPSO algorithm to find the optimal
Test of goodness of fit t
In order to estimate the accuracy of the proposed bivariate Copula function, we adopt a commonly-used index of goodness of fit. Among published methods of K-S, AIC, and the minimum distance for calculate the goodness of fit,4,26,32 we select the popular AIC criterion and the minimum distance schemes as the testing methods, as follows:
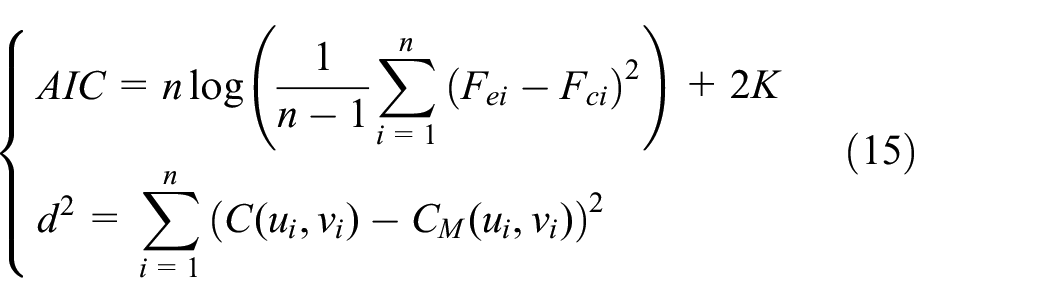
where
IPSO
In the traditional PSO algorithm for optimization calculations,
35
all particles with adaptive velocities and positions follow the current optimal particle to search the target in space. The velocity and position of the ith particle in the n-dimensional searching space are
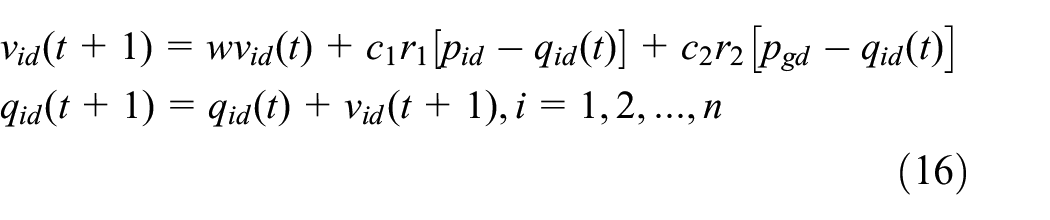
where
Improvement of inertia weight in calculation
It is known that larger inertia weight can raise the global searching ability of the PSO algorithm, while a smaller inertia weight can enhance the local searching ability of the PSO algorithm. An improper inertia weight may easily cause the PSO calculation falling into premature convergence and occurring oscillation near the point where the global optimal solution happens. To solve this problem, we introduce an exponential decreasing inertia weight coefficient as following:
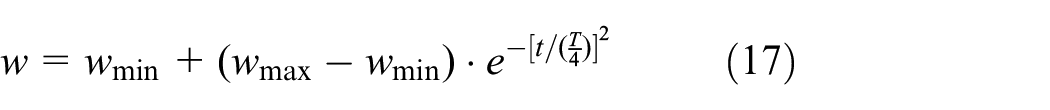
where t is the current iteration number and T is the total iteration numbers.
Improvement of learning factor in calculation
A proper learning factor can enhance the self-learning speed in calculations and help for quickly converging to the optimal solution. Therefore, we define a new asynchronous learning factor as follows.

where
Through the combination of the asynchronous changes in the learning factor and the weight coefficient, the IPSO algorithm has a stronger global searching ability than before in the initial stage. And, it also has the ability of fast convergence to the global optimal solution in the later stage.
IMCMFCM methodology
Our proposed IMCMFCM methodology contains five major steps, as illustrated in the followings.
Step1: Sample data generation. Firstly, the MC scheme is used to generate the sample data. Then, based on these data, we define a cumulative distribution function by the kernel density estimation scheme.
Step2 : MCopula model. We mix the Gumbel, Clayton, and Frank Copula functions to from a new MCopula function. Furthermore, we develop an IPSO algorithm to enhance the calculation performance. The integration of the above two schemes are called the IPSO-MCopula model.
Step3 : Calculation of parameters. The dependent parameter
Step4 : Test of goodness of fit. We test the proposed IPSO-MCopula model with the AIC criterion and the minimum distance criterion.
Step5 : Verifications. Use the IPSO-MCopula model to solve the correlations among random variables for different cases.
The above manipulation procedure of IMCMFCM Methodology is also shown in Figure 1

Procedure of IMCMFCM methodology.
Results and discussion
Comparison of the IPSO algorithm with other algorithms
To confirm the performance of our proposed IPSO algorithm in searching global optimal values, we test the calculation performance of the IPSO, SPSO (inertia weight
Standard test functions. 36

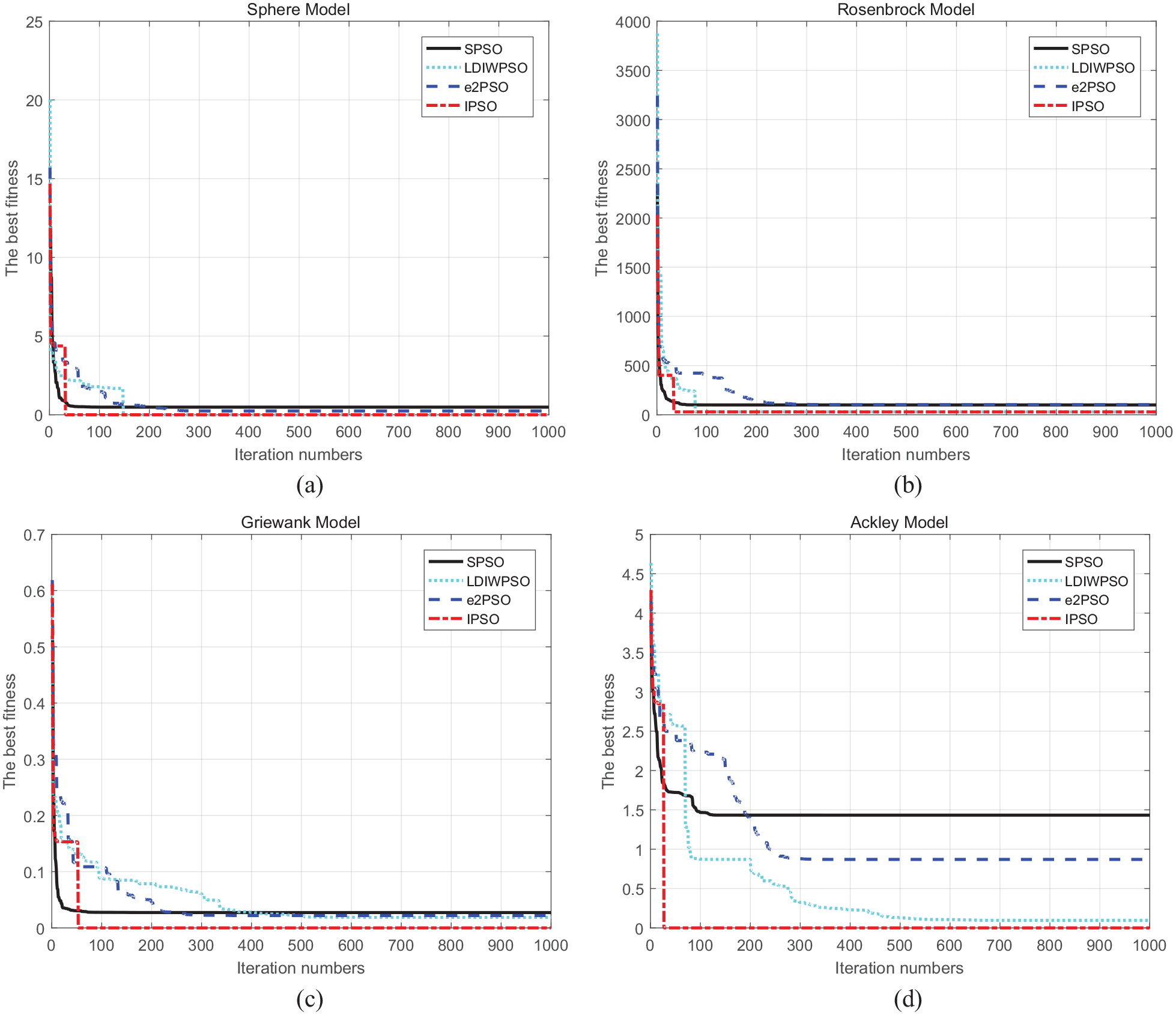
Comparison of the optimization effect using different calculation algorithms: (a) sphere model, (b) rosenbrock model, (c) griewank model, and (d) ackley model.
It is seen form Figure 2 that the calculation by the IPSO algorithm converges quicker and the best fitness is smaller than those by other three algorithms. The smaller the best fitness value, the better the optimization effect of the algorithm. Besides, in order to gain further insight into the performance of our proposed IPSO algorithm, we use the mean and standard deviation as the performance indicators, and adopt a maximum of 1000 iterations in each calculation. Considering the randomness of the algorithms, each algorithm was repeated 20 times, and the average value and the standard deviation of the best fitness was obtained, as shown in Table 2. The test results show that, for all function models, the standard deviation obtained by using the IPSO algorithm are much smaller and more accurate than those obtained by other algorithms. We can conclude that the IPSO algorithm performs well not only for multimodal functions, but also for unimodal functions.
Mean and standard deviation by standard test models with different algorithms.

Next, we further test the proposed IPSO algorithm by examining the best fitness as the population size changes. In these tests, we still adopt the same four kinds of model functions in IPSO algorithm as previously done, which are Sphere, Rosenbrock, Griewank, and Ackley models. We set a limitation of 1000 maximum iterations in calculations. Considering the randomness of the algorithms, each algorithm was repeated 20 times, the average value of the best fitness obtained by IPSO with using four different models are shown in Table 3. It is found that, for different adopted model functions, using the IPSO algorithm in calculations may always make the fitness correctly converge to its ideal value regardless of the population size. However, as the population size increases, the convergence speed of average fitness reduces. Obviously, a proper choice of population size is quite important in best fitness calculations. As a consequence, we have carried out the test and verified that the IPSO algorithm has good optimization performance.
Average fitness by different models with different population sizes.

N: population size.
Comparison of IPSO-MCopula model with other models for a strut system
We now verify the performance of the proposed IPSO-MCopula model through the example of a hollow metal strut subjected to forces at two ends
3
(as shown in Figure 3) where the failure functions of the stability failure mode (

and


Hollow metal strut subjected to forces at two ends.
In equations (19) and (20),
Parameters in equations (19) and (20). 3

In our proposed IMCMFCM methodology, firstly we adopt the MC scheme to generate 2000 sample data, and the IPSO method with a population size of 80 and a maximum number of iterations of 1000 is used to optimize the algorithm parameters in calculation. Then, we employ the improved fourth-order moment method to calculate the failure probability
Failure probability and algorithm parameters by IPSO-MCopula model for a strut system.

Failure probability and goodness of fit by different Copula function models for a strut system.

E: error.
Comparison basis
For the calculation of failure probability (
Application of the IPSO-MCopula model to gear reliability analysis
To further verify our proposed IMCMFCM methodology, we now carry out a practical reliability analysis for a gear pair in a mechanical gearbox (shown in Figure 4). We firstly set some proper conditions for the gear pair in consideration. The number of teeth and modulus of the pinion are 19 and 8 mm, respectively, and its material is Cr. The large gear has 38 teeth and is made from steel. Both gears have a tooth width of 45 i and a dimension accuracy of level 7. The transmitted torque is 1862

Configuration of a gear pair used in reliability analysis (cyan and blue parts).
Definite variables of the gear pair geometry.

Mean and standard deviation of random variables for the tooth contact fatigue failure mode.

Mean and standard deviation of random variables for the tooth root bending failure mode.

Based on the concept proposed by Liu and Chen,
33
we establish two marginal distribution functions, one for describing the failure mode of the contact fatigue failure of tooth surface (
(1) Marginal distribution function of the contact fatigue failure of tooth surface:
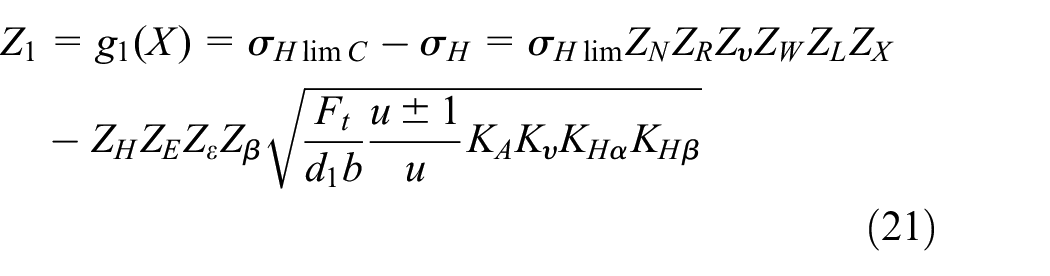
(2) Marginal distribution function of the bending fatigue fracture of tooth root:

With using the proposed IMCMFCM methodology, we firstly generate a certain samples by the MC scheme, and then theoretically build the marginal distributions from the generated data by the kernel density estimation method for the aforementioned two failure modes. Secondly, we calculate the related parameters in the proposed IPSO-MCopula function model by the IPSO and the MLE method with a population size of 80 and a maximum iteration number of 1000. In order to test the influence of different sample sizes on the calculation efficiency and accuracy of the algorithm, the calculation results for different sample sizes are listed in Tables 10 and 11. In addition, the sample of MC method is 107, and the result obtained is used as the truth value to test other algorithms. In Table 10, the failure probability
Failure probability and algorithm parameters by IPSO-MCopula model for a gear pair system.

Failure probability and goodness of fit by different Copula function models for a gear pair system.

Figure 5(a) (contact fatigue failure mode) and (b) (bending failure mode) show the marginal distribution obtained by IPSO-MCopula and its comparison with empirical values when the sample size is 2000. It is seen that the fitted conditions of the built marginal distribution functions are satisfactory for both failure modes. In conjunction with the contour plots of the probability density function (PDF) and the cumulative distribution function (CDF) for the mixed Copula functions, as shown in Figure 6, it can be found that the PDF and the CDF for the two failure modes of the gear pair are very sensitive to the change of weight coefficient, especially the upper-tail shape in PDF or CDF contour. Among the calculation results of failure probability (

Comparisons between the theoretical and the empirical marginal distributions: (a) contact-fatigue failure mode of tooth surface and (b) bending failure mode of tooth root.

Distributions and contour plot of CDF and PDF of the mixed Copula: (a) CDF of the mixed Copula, (b) contour plot of CDF of the mixed Copula, (c) PDF of the mixed Copula, and (d) contour plot of PDF of the mixed Copula.
Conclusion
In this study, a reliability analysis methodology of IMCMFCM for multiple failure modes of gears is proposed based on the novel IPSO-MCopula model which is an optimal combination of the well-known Clayton Copula, Gumbel Copula, and Frank Copula functions in order to more precisely establish the reliability correlation for different failure modes of gears. To optimally determine the calculation parameters in the IPSO-MCopula function model, which are closely related to the computational accuracy and speed, we adopt the MLE method to estimate the dependent parameter of
For the standard test function, the proposed IPSO has faster convergence speed and smaller average fitness values compared to SPSO, LDIWPSO and e2PSO.
The proposed MCopula model includes copulas with different tail relationships, which can be well used to describe the correlation between multiple failure modes.
The proposed IPSO-MCopula model, with only using a small amount of sample data, has higher computational efficiency and reliability-prediction ability than that obtained by the traditional MC method with using a large number of samples.
The proposed IPSO-McCopula model has achieved good results in the analysis of multiple failure modes of gear. As a consequence, the proposed reliability analysis methodology of IMCMFCM is convincible and satisfactory for theoretically and practically investigating the reliability prediction problem of gear systems.
At present, this paper only studies the reliability of the system when the failure mode is explicit, and does not study the failure mode is implicit. This situation can be dealt with by methods such as approximate model, which is also the focus of our future research.
Footnotes
Handling Editor: Chenhui Liang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Natural Science Foundation of Fujian Province (No. 2022J011181), the Special Project of Central Government Guiding Local Science and Technology Development (No. 2021L3029), the Leading Technology Project of Sanming City (No. 2023-G-2 and No. 2022-G-13), the Major science and technology projects of Fujian Province (No. 2022HZ026025), the Department of Education Science and Technology Program of Fujian Province (No. JAT200641), and the National Natural Foundation Cultivation Project of Sanming University (No. PYT2006). Also, this work was supported by the Project of the Department of Science and Technology of Fujian Province, China (2021G02013, 2020H0049, 2021H0060), and in part by the Sanming University of Fujian Province, China (19YG05, 19YG04).