
Abstract
A flexible reinforcement learning (RL) optimal collision-avoidance control formulation for unmanned aerial vehicles (UAVs) with discrete-time frameworks is revealed in this work. By utilizing the neural network (NN) estimating capacity and the actor-critic control scheme of the RL technique, an adaptive RL optimal collision-free controller with a minimal learning parameter (MLP) is formulated, which is based on a novel strategic utility function. The optimal collision-avoidance control issue, which couldn’t be addressed in the prior literature, can be resolved by the suggested approaches. Furthermore, the proposed MPL adaptive optimal control formulation allows for a reduction in the quantity of adaptive laws, leading to reduced computational complexity. Additionally, a rigorous stability analysis is provided, demonstrating that the uniform ultimate boundedness (UUB) of all signals in the closed-loop system is ensured by the proposed adaptive RL. Finally, the simulation outcomes illustrate the effectiveness of the proposed optimal RL control approaches.
Keywords
Introduction
The unmanned aerial vehicles (UAVs) compact and lightweight design, coupled with their capacity to perform tasks inconvenient or challenging for humans, has garnered widespread acclaim. They have demonstrated their prowess in diverse domains, including industrial inspections, emergency response and disaster relief, and daily assistance. Nonetheless, throughout this developmental trajectory, there has been an incremental rise in incidents where quadcopters have inflicted harm upon individuals and property, thereby jeopardizing airspace safety.1,2 Thus, ensuring the possession of autonomous obstacle avoidance capability in quadcopters is regarded as the paramount and indispensable functional prerequisite for the execution of intricate operational tasks.
Regarding the obstacle avoidance issue in UAVs, a substantial body of literature has already presented various solutions from different perspectives. The obstacle avoidance problem in UAVs primarily refers to the design of a method that enables the UAV to safely reach the target point from the starting point within a specified flight environment. This entails not only considering how to safely navigate the UAVs around obstacles but also satisfying the requirements of the corresponding flight trajectory and the physical constraints of the UAVs itself. 3 The obstacle avoidance method based on the route planning algorithm is also known as the global planning obstacle avoidance algorithm. Its basic idea is to use the route planning algorithm to find a flight path that allows the unmanned aerial vehicle to depart from the starting point, avoid all obstacles, and reach the target point. Then, the route tracking and guidance method is applied to control the unmanned aerial vehicle to fly along the generated route, achieving the purpose of obstacle avoidance.4–6 The obstacle avoidance method based on the local collision prevention algorithm is also known as local planning obstacle avoidance. It refers to using the local collision prevention controller of UAVs to perform real-time evasion of detected obstacles. These methods do not rely on global information and do not require knowledge of the initial and target points. They only rely on real-time obstacle information detected by UAVs sensors and are commonly used for obstacles with insufficient prior information or sudden obstacles. 7 The obstacle avoidance scheme deriving from the artificial potential function method utilizes virtual potential fields to produce attractive and repulsive forces on the UAVs, and forms the resultant force through attraction and repulsion, establishing the low-level regulation controller, thereby obtaining an effective local obstacle avoidance flight path. 8 However, traditional UAVs obstacle avoidance algorithms typically require the construction of offline three-dimensional maps. Based on the global map, these algorithms use obstacle points as constraints and employ path planning algorithms to compute the optimal path. While some obstacle avoidance algorithms avoid the complex map construction process, they often require manual adjustment of numerous parameters, and the robots cannot utilize obstacle avoidance experience for self-iteration during the obstacle avoidance process. Based on the aforementioned analysis, there is an urgent demand for enabling intelligent obstacle avoidance in quadcopter unmanned aerial vehicles through real-time feedback and autonomous decision-making in complex environments.
With the advancement of machine learning, in the face of challenges related to integrating the human “trial-and-error-improvement” autonomous learning mechanism into obstacle avoidance control of quadcopter drones, several a priori research propositions are expounded as follows. Researchers have incorporated supervised learning into UAVs obstacle avoidance, treating obstacle avoidance as a classification problem based on supervised learning. 9 Reinforcement learning primarily optimizes its own behavior through interaction with the external environment. Its advantage lies in its independence from the offline maps required by traditional non-machine learning methods and the annotated datasets needed for supervised learning. By learning the mapping relationship between input data and output actions through deep learning models, reinforcement learning enables intelligent agents to handle decision-making problems in high-dimensional continuous spaces, avoiding the complex offline map construction work. 10 A deep reinforcement learning approach, based on uncertain perception, is proposed in which enables quadcopter drones to maintain “vigilance” in unfamiliar unknown environments by estimating collision probabilities. This approach reduces the speed of operation and minimizes the possibility of collisions. 11 The DDPG algorithm is applied to plan the desired path for quadcopter drones and combined it with a PID controller to achieve collision-free target tracking tasks using a hierarchical structure. 12 The DDPG algorithm, as a classical algorithm for continuous action control, has been widely used in obstacle avoidance, path planning, and other problems. Ding et al. 13 divides the path planning task of UAVs into a Path Travel Policy Module and an Information Exploration Policy Module using the DDPG algorithm. To assist in guiding the generation of UAV flight path trajectories and enhancing the model’s learning capabilities, an improved Artificial Potential Field (APF) force-guiding mechanism is introduced in the Path Travel Policy Module. The Information Exploration Policy Module provides the UAV with a series of temporary target points, enabling the UAV to exhibit better obstacle avoidance performance on complex maps. Li et al., 14 building upon the Proximal Policy Optimization (PPO) algorithm for proximal policy optimization, improves the reward function design by introducing density rewards, distance rewards, and step-length penalties. This reduces congestion occurrences and enhances the task efficiency of the agent. Han et al. 15 proposes an obstacle avoidance algorithm that combines Artificial Potential Fields with deep reinforcement learning. By modifying the Artificial Potential Field (APF), obstacles directly affect intermediate target positions rather than control commands, making it useful for guiding previously trained one-dimensional deep reinforcement learning controllers. Yan et al. 16 presents a distributed formation and obstacle avoidance approach based on Multi-Agent Reinforcement Learning (MARL). Agents in the system make decisions and distributed controls using only local and relevant information. In the event of any disconnection, they rapidly reconfigure themselves into a new topology. This method shows improved performance in terms of formation error, formation convergence rate, and obstacle avoidance success rate. Considering the heterogeneity of agents cannot be overlooked in crowded scenarios, Zhu et al. 17 models agents using Oriented Bounding Capsules (OBC) and transforms the interaction state space of robot-obstacle agent pairs. To address speed heterogeneity, a collision risk function related to speed is designed to shape robot behavior. This method enhances the success rate of collision avoidance for agents in congested scenes. However, it suffers from the problem of overestimation bias in Q-values. When this cumulative error reaches a certain level, it can lead to suboptimal policy updates and divergence behavior.
An aspect of practical significance that warrants attention is the presence of unknown information. In the work by Doukhi and Lee, 18 a robust adaptive NN control strategy is developed for a quadrotor UAVs. This controller takes into account uncertainties arising from disturbances, inertia, mass, and aerodynamics. By employing adaptive neural networks and certainty equivalent control, the controller approximates the unknown dynamics, obviating the need for precise models or disturbance information. Wang et al. 19 propose an innovative adaptive control scheme catering to uncertain discrete-time nonlinear systems that presents a rigorous strict-feedback form. This algorithm utilizes a singular neural network approximation to convert the initial system into a predictor form, effectively addressing the noncausal issue. The designed controller is consisted of just one pair of single actor controller and one adaptive compensator, thus streamlining the implementation process and alleviating computational load. To enhance control performance by leveraging estimated unknown information, the evaluation of control performance often involves the utilization of a long-term performance index, which has garnered considerable attention in the literature. In addressing this user-specified long-term cost, the control community frequently employs the reinforcement learning (RL) technique, as highlighted in the works of Refs.20–22 In Chen et al., 23 a dynamic surface control scheme using RBFNN and disturbance observer is proposed to handle uncertainty and saturation, avoiding complexity explosion and ensuring convergence of closed-loop signals. In addition, Moreover, in the context of time-varying-constrained nonlinear systems, previous studies24,27 have utilized barrier Lyapunov functions to guarantee constraint adherence, utilizing NNs for approximating the unknown information in control strategy.
Taking into consideration the aforementioned content, addressing the issue of autonomous intelligent obstacle avoidance for quadcopter drones based on real-time environmental feedback, this paper summarizes the innovations of the “trial-and-error correction” evaluation-action intelligent control framework using reinforcement learning as follows:
The article presents an innovative approach that combines neural networks and actor-critic control mechanism of RL to develop an optimal collision-free RL strategy for UAVs with discrete-time systems.
The article introduces the idea of utilizing an MLP architectural strategy to reduce the number of adaptive adjustments within the adaptive control framework of RL. This leads to decreased computational complexity and improved operational efficiency.
The established RL framework and the MLP-based RL control system guarantee the stability of the closed-loop systems. This is supported by the analysis of uniformly ultimately bounded (UUB) behavior. Furthermore, it leverages the potential of deep learning models to adeptly tackle decision-making obstacles across vast continuous domains.
As for the structure of this work, it is stated as follows: Section “Problem formulation” introduces a nonlinear model of an UAVs and transforms the model into a discrete form. In Section “Design of reinforcement learning control strategy,” a pioneering online reinforcement learning control scheme for UAVs, considering collision risk, is presented. Section “Simulation” showcases simulations that validate the proficiency of the devised controllers. Lastly, Section “Conclusion” offers a conclusion, summarizing the key findings of the paper.
Problem formulation
Six DOF system model
The schematic diagram of the quadrotor UAVs under consideration is taken into consideration. To facilitate the description of motion, two reference frames are introduced: the inertial coordinate system denoted as


where the Euler angle vector, denoted as
The rotational matrix

Furthermore,

Consequently, the explicit form of quadrotor UAVs attitude dynamics is written as:

The primary aim of this article is to formulate and establish two adaptive neural network reinforcement learning (NN RL) controllers for UAVs. These controllers ensure the attainment of uniformly ultimately bounded signals throughout the closed-loop system, while also enabling the convergence of tracking errors to the proximity of zero without any potential collision hazards.
Radial basis function neural network
In the context of this article, the definition of the radial basis function neural network (RBFNN) function

where

where
Numerous relevant publications have provided evidence of the capability of RBFNN to approximate diverse nonlinear functions across a confined domain

where the ideal weight vector
Design of reinforcement learning control strategy
Within this section, an adaptive RL control scheme for discrete nonlinear systems of UAVs (5) is constructed as follows 27 :

where
Designs of critic NNs for avoiding obstacles
The purpose of the utility function denotes to a phenomenna that avoiding collision among UAVs, and keeping farther away from a obstacle, as shown in Figure 1. According to Refs,22,25,27 by making inspection of the idea of few-shot learning, the utility cost function is proposed as follows:

where
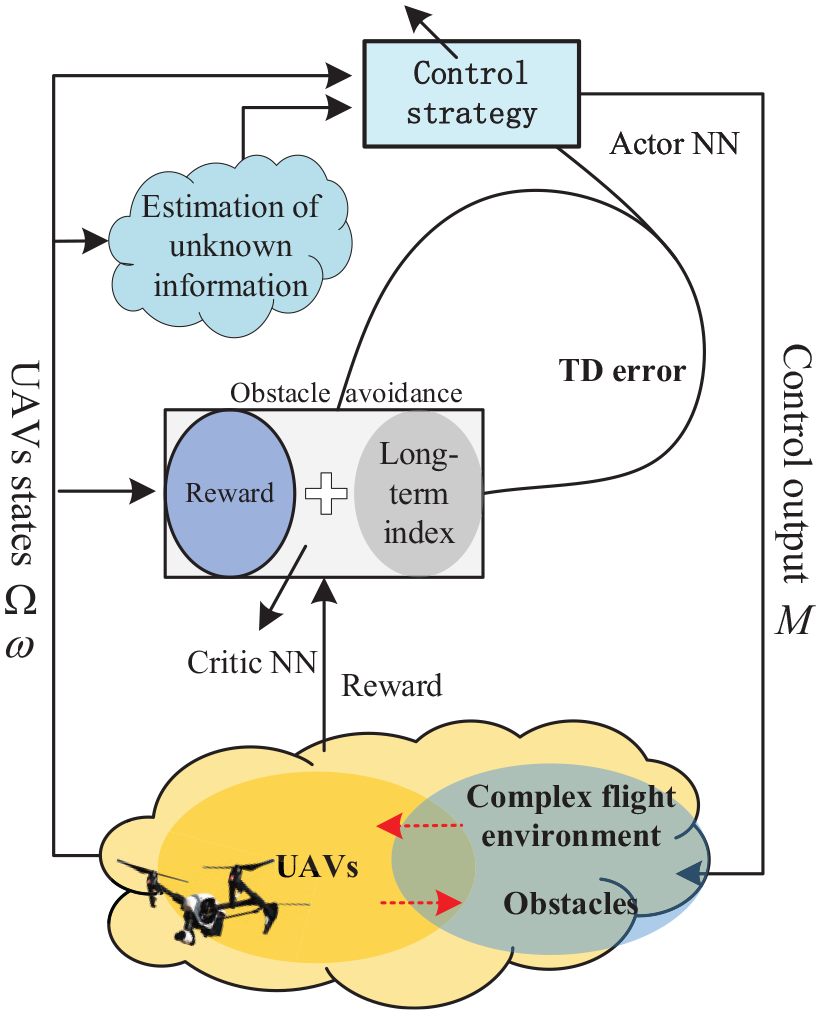
Reinforcement learning-based UAVs collision avoidance control framework.
Therefore, in order to encapsulate the overall performance of the policy over an extended period, the utility function for long-term policy evaluation is formulated in the following manner:

where the symbol
Given the challenging nature of obtaining an exact value for

where
Let us define the following Bellman error, which quantifies the discrepancy between the estimated value and the expected value in the Bellman equation, serving as a measure of the quality of the approximate solution:

where

In the upcoming content, a comprehensive exploration is undertaken to delve into the intricacies involved in formulating the backstepping RL mechanism for the purpose of designing advanced controllers:
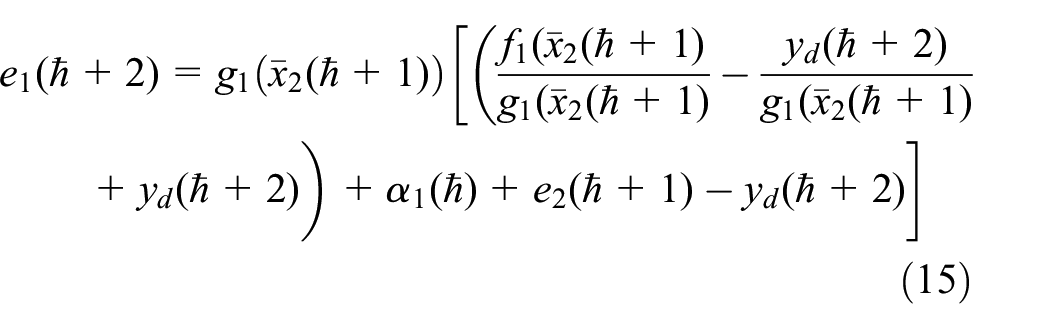
where
Define

The elusive function

where
By substituting (17) into (15), it yields

Let

where

The design of the virtual controller takes place in the following manner:

By substituting (21) into (20), one has
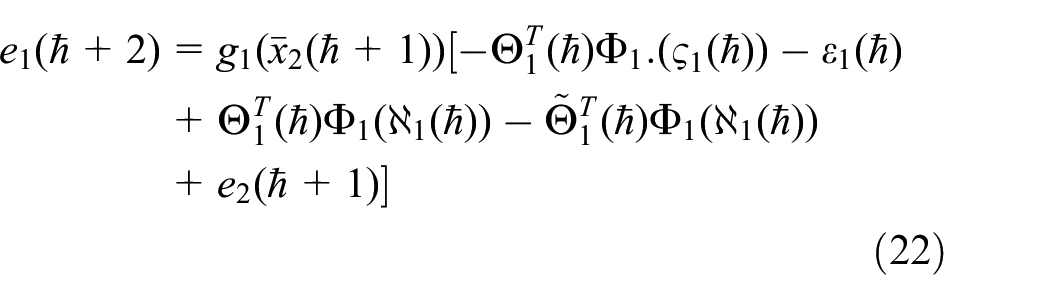
where
At the time instance corresponding to

where
The definition of the strategic utility function encompasses a comprehensive evaluation framework that takes into account the strategic effectiveness and overall value derived from a particular course of collision-avoiding action, and we have

Select the expense metric as


Define

Utilize RBFNN to approximate the unfamiliar function
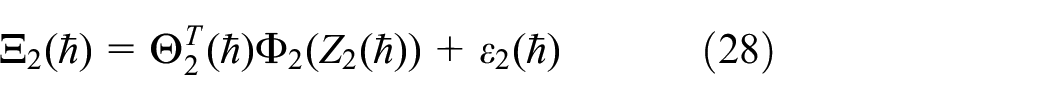
where the optimal weight vector is denoted as
By replacing (28) in (26), it is possible to derive

Design the controller as

Through the process of substituting the equation (30) into the expression (29), we are able to arrive at the following result:

where
The strategic utility function is defined, providing a comprehensive framework for evaluating the overall effectiveness and value of strategic choices and decisions:

Choose the cost function

The previously mentioned design and analysis are consolidated and presented concisely in the subsequent theorem.
Proof: The Lyapunov function is determined by carefully selecting a suitable mathematical representation, resulting in
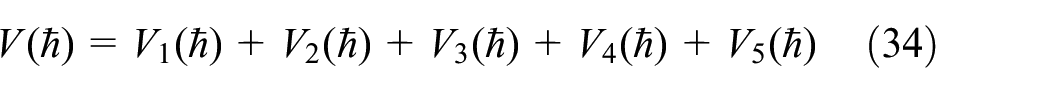
where

where
To proceed further, the derivative of

Invoke the Cauchychwarz inequality as
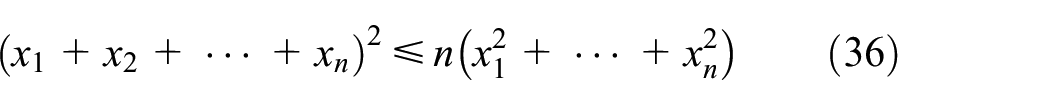
Furthermore, by means of the Young’s inequality and

To continue,
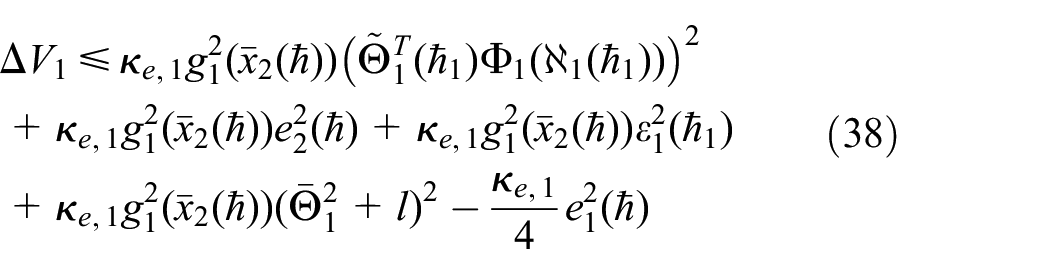
By taking (31) and in mind, combined with (36), the

In what follows, from (25), (33), and (36),

By utilizing the Cauchychwarz inequality (36), it yields

Similarly, by applying the forward difference technique, we can determine the derivative of

By considering the explicit definition of forward difference, we can deduce the following:

Ultimately, the discrepancy of the comprehensive Lyapunov function
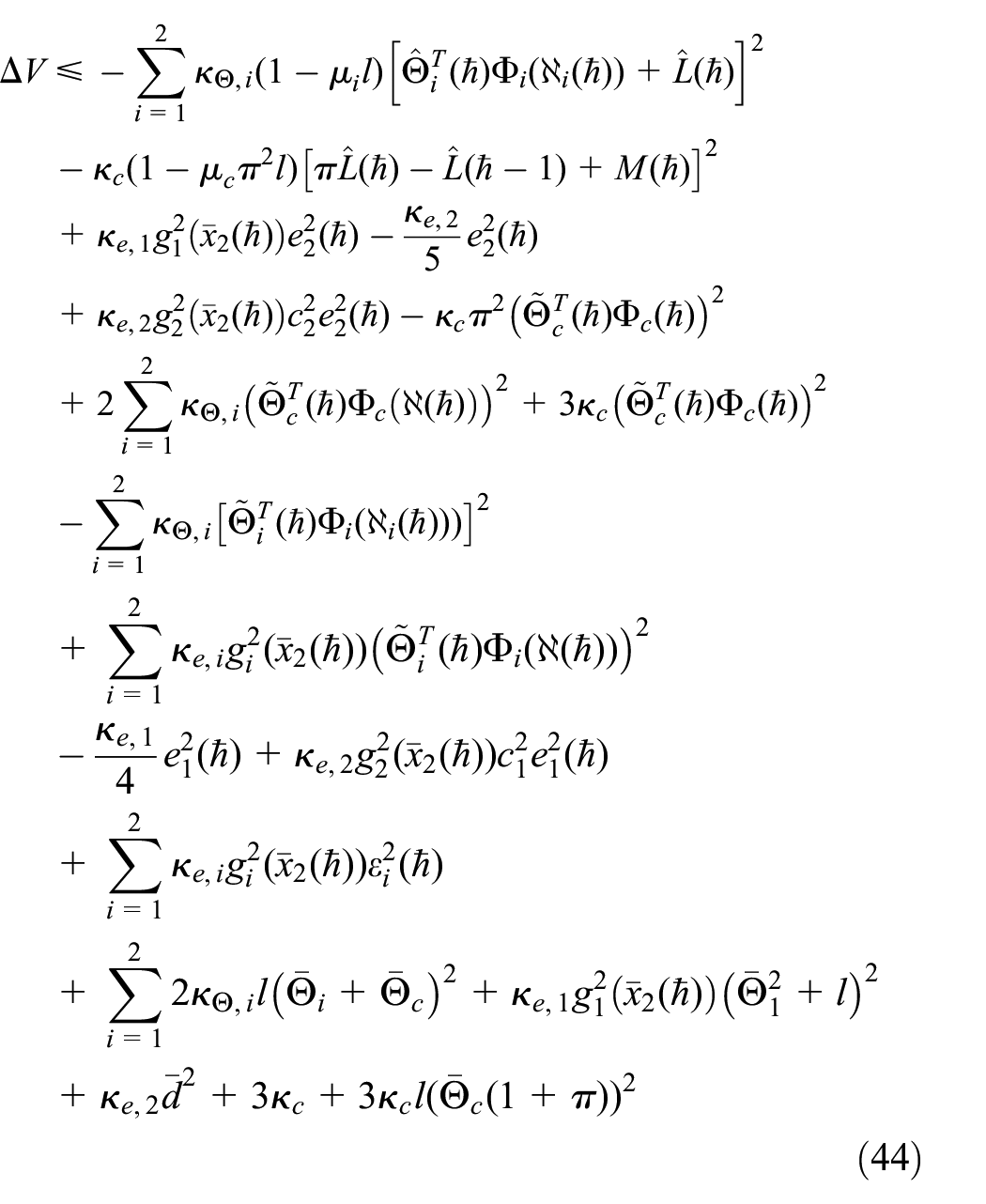
Choose the parameters

By selecting the following parameters:

through meticulous scrutiny and thorough assessment, it can be inferred that the assertion of
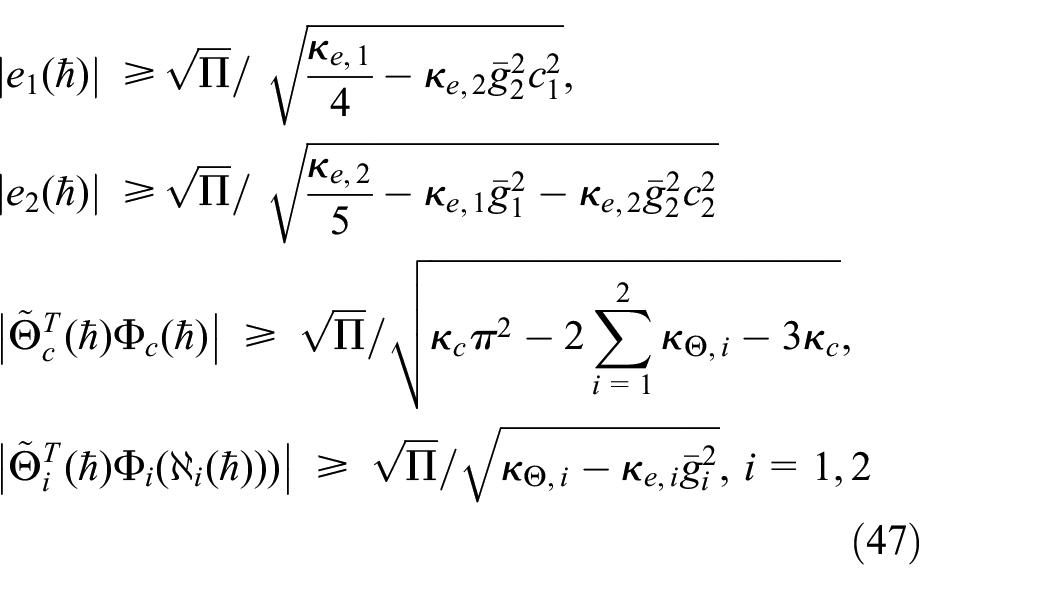
Drawing upon the principles of the established Lyapunov extension theorem, it can be deduced that all signals within the closed-loop system are UUB, thereby substantiating the completion of the proof for Theorem 1.
Simulation
This section presents simulation and experimental results to illustrate the efficacy and resilience of the proposed approach. The simulation is conducted under the following conditions: The initial state vector of the quadrotor is denoted as
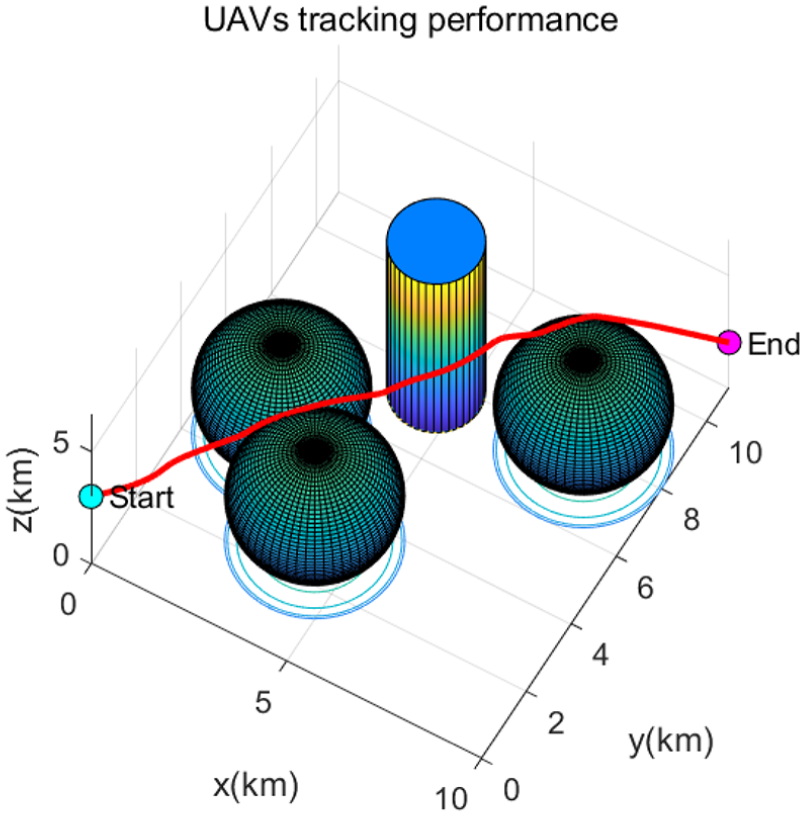
Position tracking trajectory of a quadrotor using the proposed RL algorithm for static obstacle.

Position tracking trajectory of a quadrotor using the proposed RL algorithm for dynamic obstacle.
The simulation results provide compelling evidence of the effective collision-avoidance capabilities exhibited by the attainment of the target, thus serving the purpose of evaluating the health status of large-scale photovoltaic power generation while concurrently minimizing the potential risks of collisions (as depicted in Figures 2 and 3). Illustrated across Figures 2 and 3, the trajectory visualized by the red line demonstrates a remarkable ability to faithfully adhere to the intended path, and the blue line in Figure 3) represents the motion trajectory of dynamic obstacles, thereby ensuring the avoidance of collisions under both static and dynamic conditions. Furthermore, the simulation outcomes presented in Figure 3 substantiate the suitability of the proposed RL control methodology for a diverse array of tracking missions, while upholding compliance with stringent safety boundaries.
Conclusion
This study has made significant contributions to the control of UAVs. The investigation focused on transient performance, highlighting the importance of considering nonlinearities and ensuring stable maneuvering. By combining neural networks and reinforcement learning (RL), an innovative approach was developed for adaptive collision-free RL optimal control of UAVs with discrete-time systems. The introduction of the minimal learning parameter (MLP) reduced adaptive laws, improving computational efficiency without compromising performance. The proposed RL and MLP-based controllers ensured closed-loop system stability, demonstrated through UUB analysis. Overall, this research advances UAVs control strategies, emphasizing transient performance, neural networks, and RL techniques, with implications for safer and more efficient UAVs operations. In the future work, we will adopt the cooperative game indicator design concept to further enhance the control effect. In future work, building upon the autonomous obstacle avoidance control algorithm designed in this paper, further research will investigate autonomous cooperative obstacle avoidance control algorithms for UAVs under nonholonomic information constraints and scale variations.
Footnotes
Handling Editor: Chenhui Liang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Henan Province Science and Technology Research Project (232102240098).