
Abstract
The evolution of industrial systems toward Industry 4.0 presents the challenge of developing robust and accurate models. In this context, feature selection plays a pivotal role in refining machine learning models. This paper addresses the imperative of accurate fault diagnosis in industrial systems, focusing on air compressors. These systems, vital for efficient operations, demand early fault detection to prevent performance degradation. Conventional methods often encounter challenges due to the occurrence of similar failure patterns under comparable conditions. To address this limitation, our approach delves into a more complex scenario, where air compressors operate under diverse fault conditions. This study introduces novel feature selection criteria achieved through a fusion of the Maximal Overlap Discrete Wavelet Packet Transform (MODWPT), the Harris Hawks Optimization (HHO) algorithm, and the Least Squares Support Vector Machine (LSSVM) classifier. The synthesis of these components aims to bolster the multi-fault diagnosis accuracy and stability for each fault class. The evaluation focuses on key statistical metrics—minimum, maximum, mean, and standard deviation. Experimental outcomes underscore the method’s superiority over traditional feature selection techniques. The approach excels in accuracy and stability, particularly across various fault categories, affirming the efficacy and resilience of the new criteria. The symbiotic integration of MODWPT, HHO, and LSSVM within our framework highlights its potential to elevate classification performance in the realm of industrial fault diagnosis.
Keywords
Introduction
Air compressors are an essential tool in many industries, such as manufacturing, construction and chemical processing. They produce compressed air or gas that powers many machines, tools and equipment. However, air compressors can develop faults and breakdown, as can any mechanical system, which can lead to reduced performance and expensive downtime. 1
In order to maintain peak performance, increase the compressor’s lifespan, and reduce maintenance costs, problems in the compressor must be quickly identified and corrected. Visual inspections, manual monitoring, and routine maintenance programs are examples of traditional approaches that are labor- and time-intensive. Also, they might miss some defects, especially those that are still developing. 2
Modern technologies like vibration analysis, 3 thermal imaging, 4 and acoustic monitoring 5 have been developed to get around these constraints. These methods continuously check the compressor’s status and immediately detect any anomalies using a variety of sensors and equipment. These reducing technologies ensure that the compressor stays in excellent working condition for a longer period of time by identifying deficiencies early, which prevents the emergence of more serious and expensive problems. 1
The use of signal processing techniques has made it possible to quickly and precisely identify compressor faults. 6 These methods entail examining the acoustic signal from the compressor to spot distinct patterns or features connected to various kinds of faults. First, the signal is divided into smaller, easier-to-manage signals that can be examined more quickly. Then, different algorithms are used to evaluate these signals to find traits that point to particular faults. Eventually, the features are categorized into several kinds of faults by machine learning algorithms.
In the last years, many methods for signal processing have been introduced for feature extraction, such as discrete wavelet transform (DWT), 7 recursive Empirical Mode Decomposition (REMD), 8 Empirical Mode Decomposition, 9 Variational Mode Decomposition (VMD), 10 Empirical Wavelet Transform (EWT) 11 and Wavelet Packet Transform, 12 can be used to find compressor faults, but these techniques have a certain drawback, especially in acoustic signals of different faults categories. This paper proposed, the Maximal overlap discrete wavelet Package transform (MODWPT) for feature information, the MODWPT is an improved version of the Discrete Wavelet Transform (DWT), 13 it is a multi-resolution analysis has the ability to analyze the signals at different levels of localization by levels in the decomposition of acoustic signals in the time and frequency domains and also has the property of shift-invariance and is very highly capable of decomposing the approximate and detailed signals in the time-frequency analysis. 14 Nevertheless, the obtained results from the MODWPT are complex and too large due to different faults categories in our case, thus, in order to enhance the robustness and efficiency of the feature classification, many methods can be employed for dimensionality reduction and feature selection.
Nowadays, many researchers have been task challenge to develop methods that helps to increase the accuracy of the classification by the decreased in the number of feature entries that have a direct impact on the classification results. In order to obtain these results, many optimization algorithms have been introduced to enhance feature classification through feature selection of the most pertinent and informative features, 15 several optimization algorithms have been applied for feature selection such as Artificial Bee Colony (ABC), 16 Genetic Algorithm (GA), 17 Slime Mould Algorithm (SMA), 18 Generalized Normal Distribution Optimization (GNDO), 19 Manta Ray Foraging Optimization (MRFO), 20 has been developed, which overcomes the limitations of dimensionally reduction algorithms that suffering from higher computational complexity and helping to find the optimal features considering parameters for selection, and it gives satisfactory results in terms of global accuracy without stability calculation. By contrast, our proposed method are based on Harris Hawks algorithm (HHO) 21 to improve the performance, accuracy and stability of each class, and generalization of a machine learning model, as well as to reduce the time and resources required for training and testing the model through the measuring the four keys of each class (Min, Max, Mean, and Standard deviation).
As an alternative to performing and achieving supervised learning of early detection and complex classification tasks, machine learning (ML) is proposed. 22 This type of technique typically consists of two main steps: the first step is a key task for identification and diagnosis based on the feature extraction information and feature selection; the second step is to build a recognition and categorization model of the air compressor health condition. K-Nearest Neighbors (KNN), Support Vector Machines (SVM), Naive Bayes (NB), Extra Tree (ET), Decision Trees (DT), Random Forests (RF), and Least Squares Support Vector Machines are a few examples of machine-learning classifiers (LSSVM).23,24 These techniques have been proposed to extract the best classifier in terms of accuracy and stability of each class.
This research proposes a reliable and improved multi-fault diagnosis of air-compressor. This technique is combined between the MODWPT, HHO, and LSSVM.
The paper is organized as follows: Section 2 introduces the principal diagnosis and feature extraction. Section 3 presents faults selection and performance classification. Section 4 shows the experimental benchmark description. The last section presents the obtained results with comments and conclusion. The contributions and innovations of this research is developing a fault selection and classification approach based on stability and accuracy of each class are as follows:
✓ Firstly, statistical features are extracted from the Maximal overlap discrete wavelet Package transform (MODWPT) in time domain.
✓ During the training process, the features extraction is feed into multiple classifiers based on with and without optimization algorithms by measuring the mean, max, min, and standard deviation to obtain the higher average accuracy and best stability.
✓ Data processing with optimization algorithms, which can reduce the computational time by select the appropriate set of features to predict air compressor state.
✓ Comparison study was done between proposed approach and the existing typical methods in terms of global accuracy and stability versus accuracy and stability for each class.
Our proposed method for detecting air compressor faults can be broken down into a series of steps, as outlined in the flowchart in Figure 1. First, the acoustic signal is processed using MODWPT to extract the various AM-FM modes. Next, time domain features are extracted from these modes. To classify the faults, a LSSVM classifier is used. To further improve the feature selection process, we compare the classification results to those obtained using conventional methods and apply the Harris Hawks optimization algorithm (HHO) to eliminate unimportant parameters. Finally, we train a model using the supervised learning method “LSSVM” to detect faults. Our method has been tested on acoustic signal data, and the results indicate that it has a high performance.

Flowchart of the proposed method.
Signal processing and feature extraction
Maximal overlap discrete wavelet packet transform
Feature extraction is a technique used to reduce the dimensionality of a dataset by generating new features that can effectively summarize the existing ones. This is typically done by combining the existing features in a meaningful way, which can help to improve the accuracy of machine learning models. 25
One popular method for signal decomposition is the Maximal Overlap Discrete Wavelet Packet Transform (MODWPT), which is based on the intrinsic frequencies of the signal. This technique decomposes the original signal into several modes, which are then used to extract features that are combined into a global matrix for machine learning analysis. 26
MODWPT is an advanced version of the Discrete Wavelet Transform (DWT), which is widely used for analyzing signals in the time-frequency domain. The DWT decomposes a signal into approximation and detail coefficients using high-pass and low-pass filters, which are then sampled by a factor of 2. This process is repeated for the approximated signal at each decomposition level until the desired tolerance is reached.
MODWPT is a time-invariant transformation that is similar to DWT, 27 but with some important differences. In particular, the distances between peaks are made equal, and the down-sampling process is removed, resulting in coefficients of the same length as the input signal. As a result, all of the decomposed coefficients correspond to their time-series and are associated with the original signal. 28
To obtain the DWT of a sampled sequence of continuous time data

Where

Where
The wavelet filter coefficients can be obtained from the scaling filter coefficients using the following equation:

Where
Since both provide the quadrature mirror of any non-zero integer, the two filters are related to one another. The

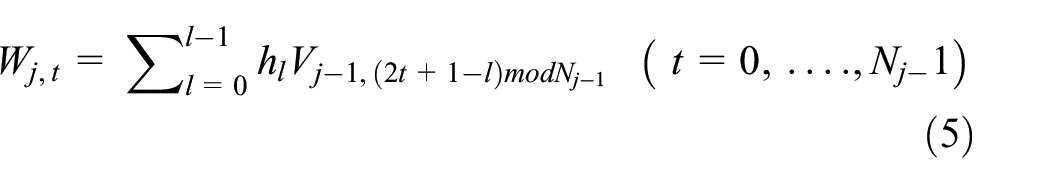
Where MOD stands for the modulus after division.
order to ensure energy conservation, the defining filters can be scaled as follows, as shown in equations (6) and (7):


Equation (1) can be changed as illustrated in equation (8) by using these scaling factors:
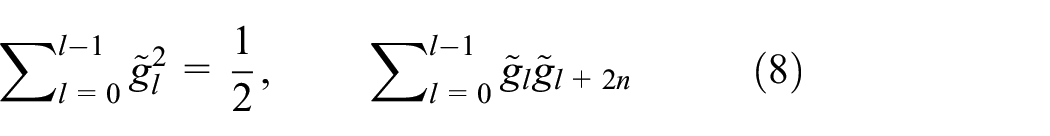
The expressions for the quadrature mirror filters can be updated as per equations (9) and (10):


To address the down-sampling issue, MODWT uses new filters that ensure 2j−1−1 zeros between the elements of

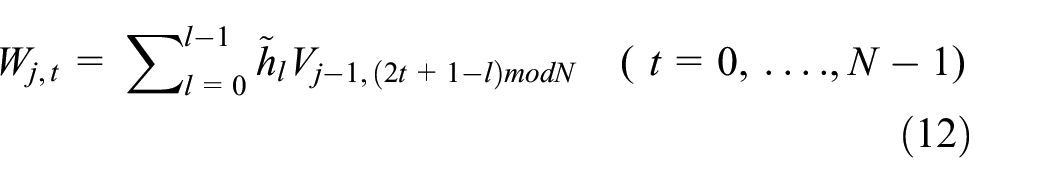
MODWPT is a further developed method that aims to achieve perfect resolution at high frequencies. The sequence of MODWPT coefficients at level j and frequency-index n is denoted as
Here, the summation is over the range of i = 0 to l−1 and t = 0 to
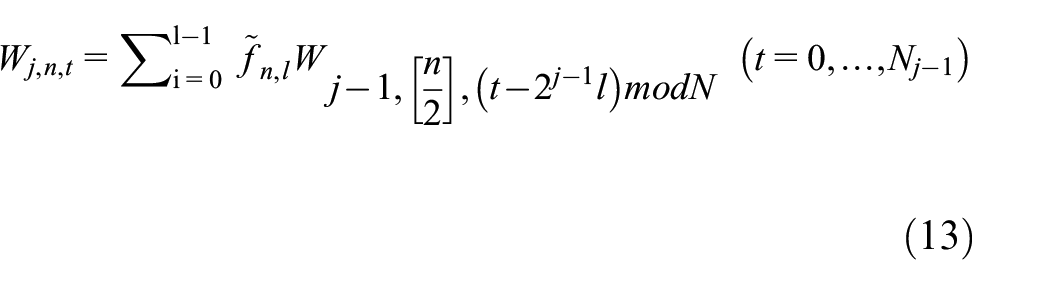

Where
Features selection and classification
Feature selection involves identifying the most relevant input features for a machine-learning task, while ignoring those that are irrelevant or redundant. This can enhance the accuracy of a model, simplify it, and prevent over fitting. 29 Feature selection methods may include filter, 30 wrapper, 31 or embedded 32 approaches.
Using techniques like decision trees, logistic regression, support vector machines, and neural networks, classification involves grouping input data into predetermined classes. 33 The task at hand and the features of the data will choose which algorithm is being used. Several machine learning applications, including image analysis, processing of natural languages, and predictive modeling, require on classification.
The method proposed in the article employs the Harris Hawks Optimization (HHO) algorithm to optimize the objective function of the least square support vector machine (LSSVM) classification algorithm. The goal of this approach is to improve the performance of the LSSVM model through parameter optimization. The HHO algorithm is based on the hunting behavior of hawks and by integrating it with LSSVM, the proposed method aims to enhance the accuracy of classification.
Harris Hawks optimization algorithm
The HHO algorithm was first proposed in 201921 as a new Meta heuristic optimization algorithm inspired by the hunting behavior of Harris Hawks in the wild. The algorithm is designed to solve a wide range of optimization problems, including continuous, discrete, and combinatorial problems. 34
The HHO algorithm uses a population of hawks that hunt for prey in a search space. The population of hawks is randomly initialized with each hawk’s position and velocity. 35 The population of hawks is randomly initialized in the search space. Let N be the number of hawks in the population, and D be the dimension of the search space. Then, the position and velocity of each hawk i are initialized as follows:
Position:
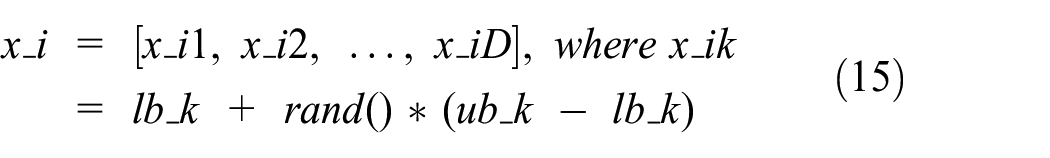
Here,
Velocity:

Based on its own experience and the experience of other hawks in the population, each hawk adjusts its location and velocity during the hunting phase. Equations (17) and (18) update the location and velocity of each hawk by taking into consideration the hawk’s current position, velocity, and the positions of other hawks in the population. The objective is to investigate the search space and identify a viable solution.
Position update:

Here,
Velocity update:

The velocities of hawk I at time steps t and t + 1 are shown here as v i(t) and v i(t + 1), respectively. The best hawk in the local group of hawk I is in position p i, while the best hawk overall in the population is in position p g. Scaling factors A, C1, and C2 regulate the impact of each term in the equation.
Note that the update equation also includes a chaotic term to introduce randomness into the search process. The chaotic term is given by:

Where
The best solutions are chosen from the current population during the updating phase, while the worst solutions are replaced with fresh hawks. The top M% of hawks in the population, where M is a predetermined number, are referred to as the elite group of hawks. The placements of a few randomly chosen hawks in the population are used in a mathematical calculation to create new hawks to replace the population's worst hawks. 36
In general, the HHO algorithm is a recent optimization technique that has demonstrated promising outcomes in a number of optimization problems. 21 The algorithm is simple to implement, and its mathematical equations are easy to understand and modify and the summary of the HHO algorithm’s procedures is presented as the follows pseudo-code.
Least square support vector machine (LSSVM)
The LSSVM algorithm is a variation on the support vector machine (SVM) technique that reduces classification error by using a least squares method. Due to its ability to handle huge datasets and nonlinear classification issues with flexibility and computational efficiency, the LSSVM algorithm has grown in prominence in recent years. 37
The conversion of the input data into a higher-dimensional feature set via a linear combination of kernel functions is one of the key components of the LSSVM method. 38 The kernel function can be any function that turns the input data into a new space, such as a polynomial kernel or a radial basis function (RBF) kernel. 39 As a result, nonlinear classification problems that cannot be solved by a linear classifier can be handled by the LSSVM algorithm. Cross-validation can be used to discover the best kernel function based on the problem’s nature. 40
The LSSVM model can be defined as follows:

Where:
The LSSVM algorithm works by minimizing the classification error while also minimizing the complexity of the model. This is achieved by solving the following optimization problem:
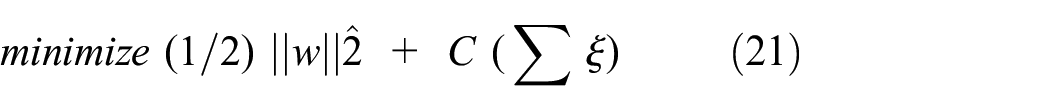

Where:
||w||^2 is the L2 norm of the weight vector w, which penalizes large values of w.
C is a regularization parameter that controls the trade-off between the classification error and model complexity.
The optimization problem can be solved using the dual formulation, which leads to a set of linear equations that can be solved efficiently. The solution of the dual problem involves only the inner products of the feature vectors, which are computed using the kernel function. This makes LSSVM computationally efficient even for large datasets.
The LSSVM algorithm has been applied to a variety of applications, including image classification, text classification, and bioinformatics. It has also been extended to handle multiclass classification and regression problems. One of the advantages of LSSVM is its ability to handle high-dimensional data with a small number of samples. However, it also has some limitations, such as the need to choose an appropriate kernel function and regularization parameter. 41
Results and discussion
Dataset
The proposed methodology consists of a single stage reciprocating air compressor of collected acoustic measurements. These data sets have been obtained from a compressor that has an air pressure range of 0–35 kg/cm3, driven by an induction motor with a power rating of 5 HP, 5 Am, 415 V, 50 Hz and a speed of 1440 rpm and pressure switch type PR-15, range between 100 and 213 PSI. The data sets from this study covered eight air compressor conditions which includes the healthy state and seven faulty states. These faults contain check valve (NRV) fault, leakage outlet valve (LOV) fault, leakage inlet valve (LIV) fault, driver belt fault, piston ring fault, bearing fault and flywheel fault. 42 These data sets were acquired for period of 5 s at a sampling rate of 50 kHz using a microphone and a NIDAQ. The total number of data sets was 1800. Figure 2 shows the 24 positions of microphone placements at air compressor from which the acoustic data sets were acquired.

The positions from which acoustic signals were extracted in the air compressor were: (a) the top of the piston, (b) the side of the NRV, (c) the opposite side of the NRV, and (d) the opposite side of the flywheel. 42
Nishchal K. Verma et al. 42 recorded acoustic data from all 24 sensor positions, and after analyzing the recordings using EMD, SPA, and specific time domain features, they determined that the 8th position was the most sensitive for all compressor states. Subsequently, the researchers took 225 measurements from the chosen position (position 8) for each compressor health condition, with acoustic recordings captured at air compressor pressures ranging from 10 to 150 PSI.
Signal processing and feature extraction
In this subsection, we task challenge between many newest signal decomposition techniques. Therefore, the eight operations condition are decomposed the acoustic signals into set modes using Empirical Mode Decomposition (EMD), Recursive Empirical Mode Decomposition (REMD), Empirical Wavelet Transform (EWT), Variational Mode Decomposition (VMD) and Maximal Overlap Discrete Wavelet Packet Transform (MODWPT).
These methods allowed for the decomposition of the complex signals into simpler components, generating matrices that represented the extracted features from the signal. The number of matrices produced by each decomposition technique varied depending on the mode used.
As an example, firstly, the MODWPT are decomposed the acoustics signal into 16 modes (see Figure 3), each modes consists frequency and temporal information. Secondly, thirteen statistical features are then extracted from the time domain as fault signatures for each mode, resulting in a total of 208 features. The mathematical formulas for these features can be found in Table 1.

Acoustic signal decomposition using MODWPT for 16 modes.

The statistical feature extraction.

Feature optimizations and classifications:
Feature selection is the process of reducing the dimensionality of input parameters during the construction of a predictive model. It is in order to reduce the number of input parameters that can confuse the results both to reduce the cost of modeling computation and, in some instances, to enhance the performance of the model, the optimization step is performed in order to select the efficient information and removing the overlapping parameters. 43
To demonstrate the effectiveness and robustness of this step, a simulation with and without optimization methods is performed and is presented in this subsection.
Unprocessed data without optimization methods
The statistical feature extraction from differ signal processing technique are feed into several machine learning classifiers, such as K-Nearest Neighbors (KNN), Support Vector Machines (SVM), Naive Bayes (NB), Extra Tree (ET), Decision Trees (DT), Random Forests (RF), and Least Squares Support Vector Machines (LSSVM). These classifiers were trained using the extracted features to detect and identify patterns and faults state in the acoustic signal for each classes.
The classification results obtained for each decomposition technique in tandem with classifiers were recorded in a Table 2. As we can see, these comparisons illustrate the performance of different classifiers combined with decomposition methods that lead to the selection of the most effective accuracy combination for different faults occurring in the air compressor.
Classification results using several classifiers with several signal decomposition techniques.
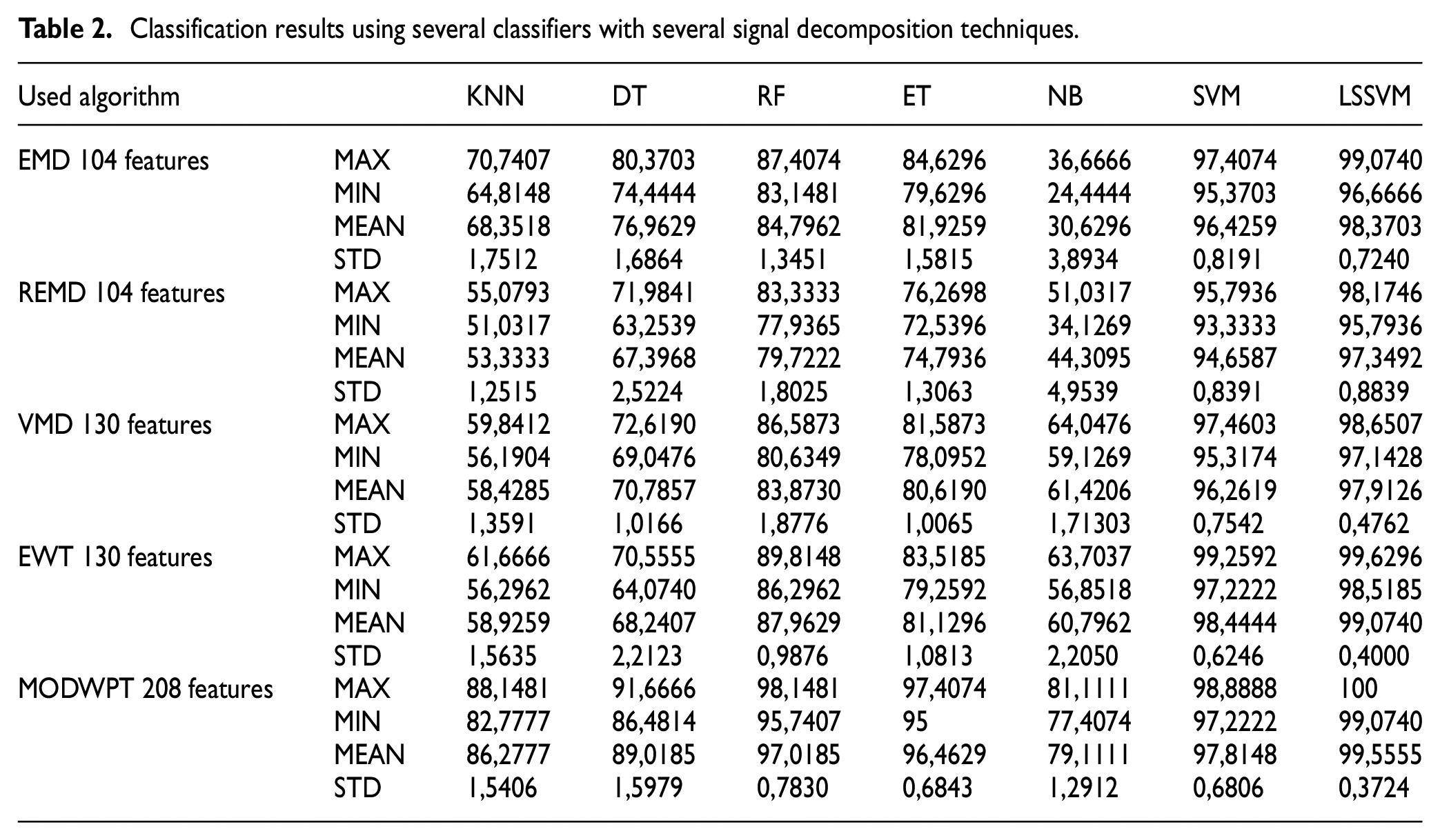
It can be seen from this table that, the highest level of overall accuracy are the combinations (EWT-LSSVM) and (MODWPT-LSSVM). However, to ensure the accuracy and reliability of the results, further analysis was required. To accomplish this, a detailed analysis for each combination was implemented, which allowed for a more accurate assessment of the predictive performance model. By measuring the mean, maximum, minimum, and standard deviation for each class.
To assist in the decision making process, the results for each class were tabulated for both (EWT-LSSVM) and (MODWPT-LSSVM). The Table 3 present a more comprehensive details of the performance of each class, which makes it clearer, which combination is optimal to achieve the desired result.
Classification results for each class using EWT and MODWPT with LSSVM.
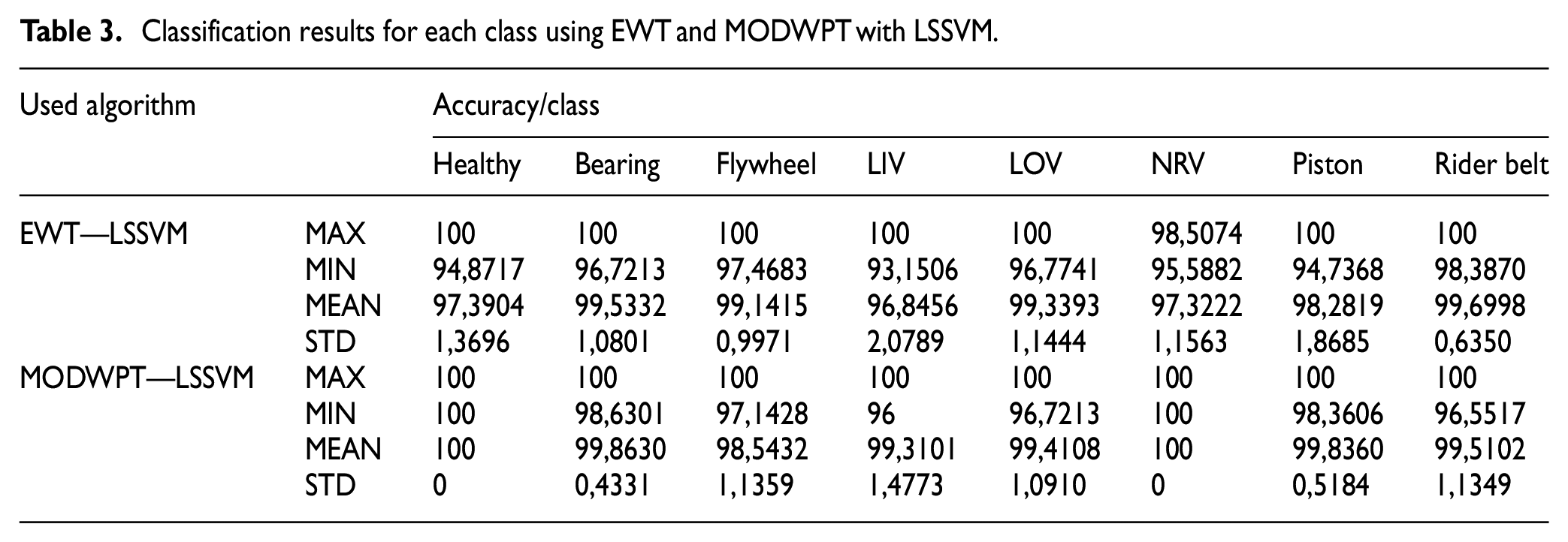
To validate results obtained from the previous table that LSSVM-MODWPT is the better combination for achieving high classification accuracy and stability compared to EWT-LSSVM. The detailed analysis of eight conditions states, as showing from confusion matrix that LSSVM-MODWPT consistently outperforms EWT-LSSVM for different states of air-compressor.
Moreover, as illustrated, form the Figure 4 the accuracy of each class is successfully predicted with higher percentage ranges between 96.6% and 100%. This indicates that the degree of fault differentiation in the same class mode versus the other class fault modes is the highest. On the other hand, we can see that the std stability in the damage cases (flywheel) and (Rider belt) is 1.1359, 1.1349 respectively.

Classification results using MODWPT-LSSVM versus EWT-LSSVM.
We observed that, while achieved the best accuracy classification result, the stability classification results for each class can be significantly different.
For that reason, to improve rating of accuracy and stability simultaneously for each class, the feature selection techniques can be used to identify the most relevant features.
Processed data with optimization methods
To overcome the previous results, the optimization step is suggested to identify the appropriate components and remove the irrelevant alternatives. Therefore, to improve the robustness and efficiency of the proposed model, a comparison was made between several optimization algorithms (GNDO, MRFO, GA, SMA, ABC, and HHO) to identify the subset of features that provide the highest classification accuracy and also the best stability.
With the implementation of feature selection techniques with previous optimization algorithms, the LSSVM-MODWPT model can be homogeneity and improved. This Refinement lead to even higher classification accuracy and more stability, which can make the LSSVM-MODWPT combination a more powerful tool for classification tasks in various fields.
As we can see from this table that, the best results obtained after optimization step and can be considered as valuable information for future experiments to improve the performance of the classifier. The results presented in the Table 4 indicate a clear improvement in classification accuracy and stability through the successful application of optimization algorithms on the LSSVM classifier.
Classification results using several optimization algorithms with MODWPT signal decomposition method.

An important observation in this table is the variation in the standard deviation values, where lower values signify more stability in the classification. These results highlight the crucial role of optimization techniques in order to facilitate reliable and accurate classification results with the LSSVM classifier.
In order to identify the optimal results obtained among different optimization algorithms, a detailed study of four key measurements (mean, max, min, and standard deviation) was implemented for each class. By analyzing these metrics, we can obtain a thorough understanding of the performance of the LSSVM classifier and identify the most efficient optimization algorithm for each class. The inclusion of these four metrics facilitates a more thorough evaluation of the classifier’s performance, allowing us to make informed decisions regarding the optimization process.
It is clear from the results presented in the Table 5 that the HHO optimization algorithm significantly outperforms the other optimization algorithms in terms of the four key measurements - mean, max, min, and standard deviation—for each class. This leads to the conclusion that the HHO algorithm is the most effective approach to optimizing the performance of the LSSVM classifier, as it consistently provides the best results on all four measurements for each class.
Classification results for each class using several optimization algorithms.

To carry out an evaluation of the fault recognition capability of the proposed method for eight different fault modes, a set of fault predictions on eight fault modes of the test set is performed. The confusion matrix of the prediction results is shown in Figure 5.

Confusion matrix of classification results.
It can be observed from figure LSSVM-HHO that, the huge majority of samples for eight fault modes (proposed approach) are successfully predicted with higher percentage ranges between 98.5 % and 100%. This means that the degree of fault differentiation in the identical class mode from other class fault modes is the highest.
We concluded the optimization algorithm that gives the best overall performance for the LSSVM classifier, allowing us to improve its performance and reliability.
Conclusion
The comprehensive exploration of feature selection has unequivocally demonstrated its pivotal role in elevating the accuracy and stability of fault classification. This enhancement is particularly evident when assessing classification outcomes across distinct fault classes, further emphasizing the significance of this strategic inclusion. Notably, our investigation underscores the prominence of the MODWPT-LSSVM fusion as an exceptionally effective approach for fault classification, surpassing alternative methods. Equally compelling is the discovery of the HHO-LSSVM-MODWPT optimization algorithm as the optimal strategy for bolstering both classification stability and accuracy, reaffirming its profound impact on fault diagnosis. The implications of these findings reverberate across industries reliant on air compressors, promising tangible benefits for maintenance practices and operational efficiency. By offering a dependable means of detecting and classifying faults, our proposed approach holds the potential to revolutionize maintenance regimes, mitigate operational risks, and optimize resource utilization. Moreover, this study transcends immediate applications, igniting the spark for future advancements in signal processing. The horizon of signal processing now beckons toward innovative optimization algorithms and signal processing techniques, poised to enhance not only air compressor systems but also broader domains of industrial automation and predictive maintenance. The groundwork laid by this research nurtures the fertile soil for burgeoning developments, propelling decision-making efficiency to new heights in diverse applications.
In summation, our investigation unfurls a new chapter in the realm of signal processing methodologies for air compressor fault detection, particularly in the context of acoustic signal diagnosis. With its multidimensional implications, this study encapsulates a transformative approach that bridges academia and industry, thus illuminating a path towards more dependable, efficient, and proactive fault diagnosis strategies.
Footnotes
Handling Editor: Chenhui Liang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.