
Abstract
An adaptive metamodel-based global approximation (AMGA) method for solving the global approximation problem of black-box models in large design domain is proposed in this study. The method employs the RBF model to compute the Hessian matrix and a heuristic direct search algorithm DIRECT to find the maximum curvature point of the metamodel surface, through which the design domain is split to obtain additional sampling points and to achieve fast update and fast valuation of the metamodel. The initial design domain is split into a series of sub-design domains by continuous iterations, and the metamodels built within the various sub-design domains achieve the global approximate model of the entire design domain. To demonstrate the final effect of the global approximation model and design domain splitting, six common two-dimensional test functions are chosen. The AMGA method is further tested using seven typical test functions and compared to other sampling and metamodel updating methods, with the findings demonstrating the usefulness of the proposed method in the low-dimensional scenario (less than four variables). Finally, the AMGA method is applied to a sophisticated electric car model, yielding good results.
Introduction
Shortening the product design development cycle has gradually become a focus of attention in order to meet the harsh market rivalry as the design of electromechanical devices becomes increasingly sophisticated. The product design cycle can be considerably shortened by building and analyzing the simulation model of electromechanical items. However, as product complexity grows, simulation analysis consumes more and more computational resources. To address this issue, metamodeling approaches were developed and implemented in a variety of industries,1–3 including aerospace, cars, and ships. The computational complexity is effectively decreased by creating a high-precision metamodel of the original complex model and replacing it for simulation analysis and optimization.
The metamodel is built with sampling points. A variety of sampling methods can be used to collect sampling points, which are classified into three types: classical sampling, full-space sampling, and adaptive sampling methods. 4 To complete the collection of sampling points in the design domain, traditional and full-space sampling methods require a single sampling. Traditional sampling, also known as edge distribution sampling, distributes sampling points at the design domain’s boundaries, whereas spatial sampling can sample the whole design domain. In general, it is not acceptable to build a metamodel all at once; if too many points are sampled, the construction process is time-consuming and may affect utilization; if too few points are sampled, the built metamodel is not accurate enough to match the application requirements. Furthermore, because the nature of the source model is unknown, determining the appropriate sampling method is difficult. The adaptive sampling method is used to generate the metamodel as a solution to this challenge. Adaptive sampling is a new sampling method based on classical sampling and full-space sampling, with the key idea being to estimate the sparsity of sampling points based on the extent of the error between the approximation and the genuine value. This strategy divides the sampling procedure into numerous stages rather than completing the entire experimental design in a single sampling phase, and the subsequent sampling is based on the prior one.
Many methods for adaptive sampling and metamodel updating have been proposed in recent years. The Sequential Exploratory Experimental Design (SEED) method 5 is a typical example of such a method, which is an adaptive sampling method primarily for the Kriging metamodel that uses the entropy value method, the mean squared error maximum method, or the integral mean squared error maximum method to obtain additional sampling points and update the metamodel. The literature 6 proposes an adaptive sampling technique based on least squares support vector regression that generates sampling points based on the uncertainty of the metamodel’s local predictive power and constructs the metamodel directly utilizing the old and new sampling points. The revised ARSM method 7 adds new sample points to the subspace using the design domain reduction (shift) and mapping methods, and then constructs the metamodel directly utilizing all of the sampling points.
Although the preceding literature has proposed adaptive sampling methods and metamodel updating methods, how to use the additional sampling points to update the metamodel more effectively is a problem worth studying. At the moment, incremental update approaches can be utilized to build metamodels with extra sampling points.8–10 These methods, however, are difficult for a source function or source model with high nonlinearity and a large design domain. These issues are reflected in two ways: (1) as the algorithm iterates, the process of updating the constructed metamodel becomes less and less effective; and (2) as more and more sampling points are sampled, the constructed metamodel becomes more and more complex, which will cause the valuation of the input points using the metamodel to become slower and slower, turning the original “cheap computation” into “not cheap” anymore.
Meanwhile, many methods for quickly and efficiently updating the metamodel using additional sampling points have been proposed, which naturally avoids the problem of constructing a metamodel using incremental new sampling points. The Kriging model, for example, is adaptively built with a time-varying performance function and a simple sampling technique to extract optimal sampling points, and it is adaptively updated with a time-varying misclassification probability function. 3 The metamodel is built with a loss function and a fixed number of sample points, and the new best feasible point is found on the metamodel and utilized to adaptively update the optimal results. 11 The increased sampling points are obtained using particle swarm optimization (PSO), and the Gaussian process (GP) metamodel is updated to constantly improve the robustness of the optimal results. 12 A method for splitting the design domain (called the ASRS method in this paper) is proposed, in which the design domain is split by a roughness method to obtain additional sampling points, and a full quadratic polynomial fit is performed using the sampling points in the neighborhood of the input point to predict the model output at the input point. 13 This method is also the first to suggest the technology of subdividing the metamodel.
We present an adaptive metamodel global approximation (AMGA) method in this paper, which is based on the concept of design domain splitting and the geometrical features of metamodel surfaces. The method delves further into the geometrical properties of the metamodel surface further, making full use of the metamodel’s geometrical qualities to realize adaptive sampling, quick creation, and valuation of the metamodel, which extends the technology of splitting metamodel to some level. The proposed method in this paper study the curvature features of the metamodel surface by splitting the design domain into a series of sub-design domains and obtaining new sampling points on the sub-design domains using the metamodel’s Hessian matrix and the DIRECT method. Furthermore, the method does not incrementally update the metamodel with the additional sampling points, but rather quickly completes the metamodel construction with a finite number of original sampling points and additional sampling points on the sub-design domain. A quick query is utilized to determine the metamodel position and perform fast estimation when valuing the input points. Although metamodels are built for each of the many sub-design domains, there is some continuity among them. The metamodel data is straightforward and quick for valuing a specific input point, but they also require more storage space, which is a problem that is also present in other methods.
The rest of this paper is structured as follows. In the following section, the metamodeling techniques utilized in the subsequent sections are discussed. In Section “The adaptive metamodel-based global approximation method,” the architecture and method flow of the proposed technique is explained in detail. In Section “Test of the adaptive metamodel-based global approximation method,” the proposed method is numerically tested and applied to an engineering case. Finally, the summary of several important conclusions is discussed in Section “Conclusions.”
Metamodelling technique
Metamodels come in a variety of forms, including PRS, Kirging, RBF, SVR, and other models.14–17 Each of these metamodels has unique traits and can be used to meet various needs. 18 A metamodel must have the ability to access the Hessian matrix with ease in order to study the surface curvature of the metamodel, and the RBF model fulfills this requirement. The RBF model can be polynomially extended to handle low-order and low-dimensional issues, while it is useful for approximating high-order and high-dimensional problems. Therefore, in the following AMGA methods, the extended RBF (ERBF) model based on RBF is primarily taken into account.
Hardy R. L. was the first to apply the Radial Basic Function (RBF) model to analyze geological data. The model, as an interpolation model, is a linear sum of relevant basis functions for a set of sample points. It takes the following specific form:
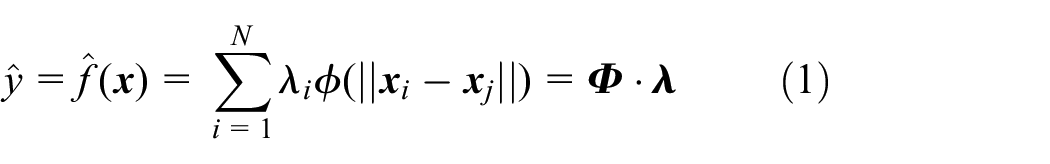
where N is the number of sampling points,
When

where A is the design matrix,
Cubic, Linear, Gaussian, Multi-quadric, and other basis functions are often employed in RBF models. In order to improve computational efficiency, the most often used Linear to RBF function was employed as the basis function in the following study.
Because the RBF method works well for high-order nonlinear models but not well for linear models, a linear polynomial can be added to the model using the extended expression19,20:


where

where Gij = gj(xi)(i = 1, 2, … , n, j = 1, 2, … , p), c = [c1, c2, … , cp]T, and the coefficients λi and ci of the ERBF equation can be obtained by solving equation (5).
The adaptive metamodel-based global approximation method
This section goes into more detail on the proposed AMGA method. Section “Description of the AMGA method” discusses the reasoning and architecture of the new approach, and Section “Framework of the AMGA method” provides the method flow to further understand the AMGA method.
Description of the AMGA method
The design domain corner points and center points are sampled by the AMGA method to create an initial sample set S. The initial ERBF1 model is built using the data set
In the first iteration, a design domain split point is obtained in the initial design domain AREA1 using specific rules, and AREA1 is split into two sub-domains AREA2 and AREA3 based on the splitting point, and AREA2 and AREA3 are then sampled using the design domain corner plus center points sampling method to obtain new sampling points. The ERBF2 and ERBF3 models are built on AREA2 and AREA3 utilizing the old and new sampling locations, respectively, and the ERBF1 models are replaced by the ERBF2 and ERBF3 models. The AMGA method’s stopping condition is checked, and if it is not met, the second iteration is initiated. Determine which AREA2 and AREA3 sub-design domains should be further split. It is possible that only one sub-design domain needs to be further split (the source model lacks symmetry), or both sub-design domains (the source model has symmetry). If AREA2 has to be split further, locate the splitting points inside the sub-design domain and split AREA2 into two sub-design domains, AREA21 and AREA22. Sampling is carried out in AREA21 and AREA22 using the design domain corner plus center points sampling method to obtained extra sampling points to construct the ERBF21 and ERBF22 models, respectively, replacing the ERBF2 model. The initial design domain AREA1 is then split into three sub-domains, AREA21, AREA22, and AREA3, and three metamodels, ERBF21, ERBF22, and ERBF3 models, are constructed in these sub-design domains, respectively. The iterative procedure continues until the AMGA method’s stopping condition is met. Many metamodels are generated by the AMGA method’s continuous iterative computation. An ensemble, that is, RSS (response surface set), can represent these metamodels.
In the preceding process, the AMGA method involves two major problems: first, determining the best place to split the design domain, and second, determining which sub-design domains need to be further split. The AMGA method solves the first problem by combining the DIRECT 21 algorithm with geometric techniques. Because DIRECT, as a heuristic direct search algorithm, is also a global optimization algorithm, the search criteria are as follows:

where
The following is the ERBF model’s first order partial differential:

where

where

Among them, m is 1, 2, … , p,

If
The following equation can be used to calculate the dimensional direction of the strongest nonlinearity and the corresponding position of the maximum curvature point, and the maximum curvature point is then used as the optimal splitting position of the design domain under the direction of the strongest nonlinearity:

The second problem is determining which sub-design domains need to be further split. The AMGA method presents a mechanism for assessing the accuracy of the metamodel. The ERBF model with the biggest error is chosen, and the corresponding sub-design domain is further split, based on the accuracy of the ERBF model constructed for each sub-design domain. In general, the greater the difference in source model values across sampling points, the stronger the model’s nonlinearity and the worse the model’s accuracy. As a result, the ERBF model’s accuracy can be measured directly by the difference between the maximum and minimum source model values between the sample points in the design domain. Equation (12) shows the specific rules.

Where, h represents the difference between the maximum and minimum source model values of the existing sampling points, L1, L2, … , Lp denotes the edge length of each dimension, and p represents the dimension of the problem, as shown in Figure 1 below.

Calculation of h value on a one-dimensional curve.
Using the 2D source model as an example, the gray area in Figure 2(a) depicts the ERBF1 model surface built from the initial design domain AREA1. During the first iteration, the nonlinear intensity along dimensions 1 and 2 is searched on the ERBF1 model surface using equation (11), and the maximum curvature points in two dimensional directions are obtained (e.g. the locations of the two black points a and b, where the direction of the arrow indicates the dimensional direction). If

The first three iterations of the splitting process of the design domain on a two-dimensional surface: (a) initial metamodel surface, (b) the first iteration, (c) the second iteration, and (d) the third iteration.
Following that, some special cases and parameter values are discussed. Due to the global search on the ERBF model surface when employing the AMGA method for adaptive design domain splitting and sampling, the DIRECT algorithm may encounter a circumstance where the maximum curvature point is very close to the design domain boundary. If the design domain split along this point, a very small and narrow part of the sub-design domain is formed. Because of this, the DIRECT algorithm may execute a local search within this sub-domain, resulting in a huge inaccuracy. To avoid this, provide a sufficient distance between the maximum curvature point and the design domain boundary.
Furthermore, the number of sub-design domains obtained by splitting the initial design domain with the AMGA method varies depending on the characteristics and parameter settings of the source model. If the source model is highly nonlinear, more sub-design domains are usually required to meet the approximate model’s accuracy criteria. As stopping conditions for iterative calculation, the AMGA method specifies three parameters, including the minimum edge length δ1 of the sub-design domain, the error δ2 of the ERBF model created from the sub-design domain, and the maximum number of iterations M.
If the initial design domain is large, δ1 should be increased accordingly to avoid the initial design domain being over-split in the strongly nonlinear region and to enhance computing efficiency, but this will diminish the approximation model’s accuracy. Setting δ2 to an acceptable value; however, too small δ2 will over-split initial design domain, reducing computational efficiency but enhancing approximation model accuracy. The purpose of setting M is to limit the call to the source function for calculation. In summary, after selecting δ1 and δ2, M can be selected to balance the number of design domain splitting, computing efficiency, and approximation model accuracy.
Framework of the AMGA method
Figure 3 depicts the AMGA method’s flow chart.
Input: Stopping conditions.
(1) Minimum sub-design domain edge length δ1;
(2) Single approximation model error δ2;
(3) Maximum number of iterations M (Optional).
Output: the RSS model.
Step 1. Generating initial data points using the design domain corner plus center points sampling method;
Step 2. Calculate the source model values for each sampled point and store the data in the S set;
Step 3. Construct the initial ERBF model using data set S.
Step 4. Repeat Steps 4(a)–(d) until the stopping condition is met.
(a) Determine whether or not the iteration meets the exit stopping condition.
(b) Use equation (12) to determine which design domain of the ERBF model in the RSS needs to be further split;
(c) New sampling points are obtained by adaptive splitting of the design domains using equation (11), and new ERBF models are constructed in the sub-design domains;
(d) Add the new ERBF models to the RSS, reorder all ERBF models, and repeat step (a).
Step 5. Export the RSS.

Flowchart of the adaptive metamodel-based global approximation (AMGA) method.
Test of the adaptive metamodel-based global approximation method
Experimental setup
All tests were run in Matlab™ 2022a on a computer with 64 GB of RAM and an Intel i7-12700k 3.6GHz processor. To speed up the creation of the ERBF model, linear basis functions were used as kernel functions in this research.
Numerical tests
The effect of global approximation and design domain splitting for 2D test functions
Six common functions are tested in this part to demonstrate the approximate processing effect of the AMGA method for diverse source functions, the splitting of the design domain, and the distribution of sample points. These functions’ nonlinear strength varies. The basic forms of the six functions studied are depicted in Figure 4. Simple Exponential, Chichinadze, and Himmelblau are simple two-dimensional functions with weak nonlinearity and relatively flat function values. In comparison, the nonlinearities of Easom, Peak, and Trefethen4 are stronger, with Trefethen4 having several peaks and valleys and Easom having a valley with a high verticality.

Test function surface plots: (a) simple exponential function, (b) Chichinadze function, (c) Himmelblau function, (d) Easom function, (e) Peak function, and (f) Trefethen4 function.
The design domain splitting of the six test functions is shown in Figure 5, with the black dots “•” indicating the 100 sampling points created when the test functions are approximated using the AMGA method. When dealing with test functions of varying nonlinear strength, the AMGA method can adaptively split the design domain, as shown in Figure 5(a) to (f). Furthermore, if the test function exhibits strong nonlinearity in some regions, the more the design domain is split in that region, the more intense the sampling points are; conversely, if the test function exhibits weak nonlinearity in some regions, the less the design domain is split in that region, the fewer the sampling points are.

Test model design domain splitting: (a) simple exponential function, (b) Chichinadze function, (c) Himmelblau function, (d) Easom function, (e) Peak function, and (f)Trefethen4 function.
Figure 6 depicts the approximation model shapes constructed with the AMGA method, which are very similar to the shapes of the test functions in Figure 4.

The shapes of the approximate models: (a) simple exponential function, (b) Chichinadze function, (c) Himmelblau function, (d) Easom function, (e) Peak function, and (f)Trefethen4 function.
Comparison with different methods
To evaluate the precision and effectiveness of the AMGA method, seven typical functions are used in this section. Two additional sampling methods are used in addition to the AMGA method to compare with it. The first is the roughness-based adaptive sampling (ASRS) method, which enables adaptive domain splitting to obtain additional sampling points and creates a full quadratic polynomial model using the sampling points nearby the input point. The second method, known as Latin Hypercube Sampling (LHS), directly builds the metamodel using the sampled points. The necessary information regarding typical test functions are listed in Table 1. The parameter settings for the AMGA method are listed in Table 2. To lessen the impact of random errors during testing, 100 trials are conducted for each function. For each approach, the root mean square error and the total number of source model calls are listed in Tables 3 to 6.
Basic information on the test functions.

Parameter settings of AMGA method for different standard test functions.

Comparison of the three strategies for constructing approximate models with a fixed number of sampling points in terms of accuracy (100 trials, R1–R5).
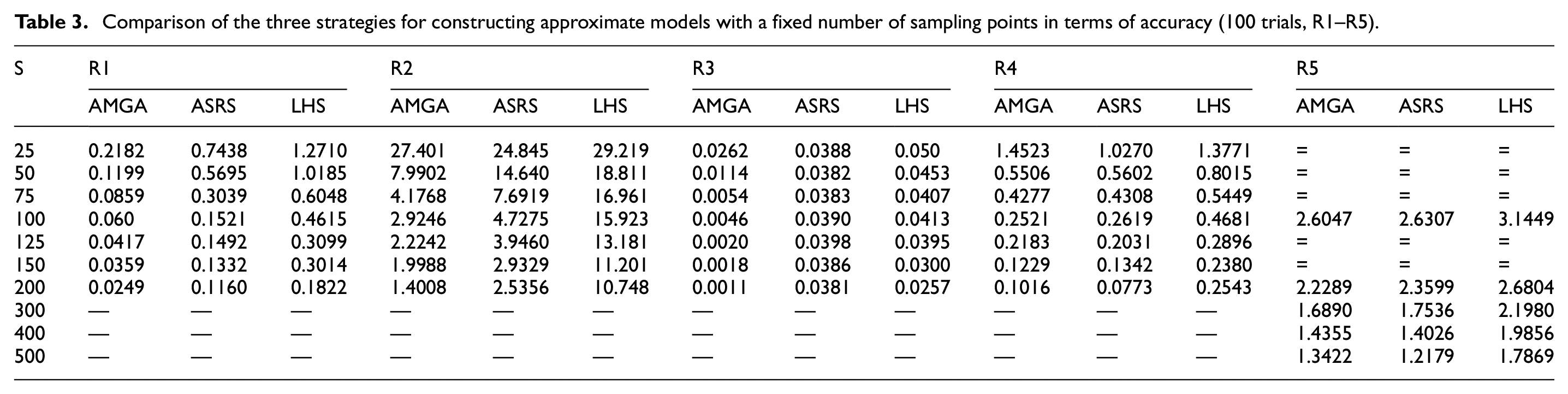
Comparison of the three strategies for constructing approximate models with a fixed number of sampling points in terms of accuracy (100 trials, R6–R7).
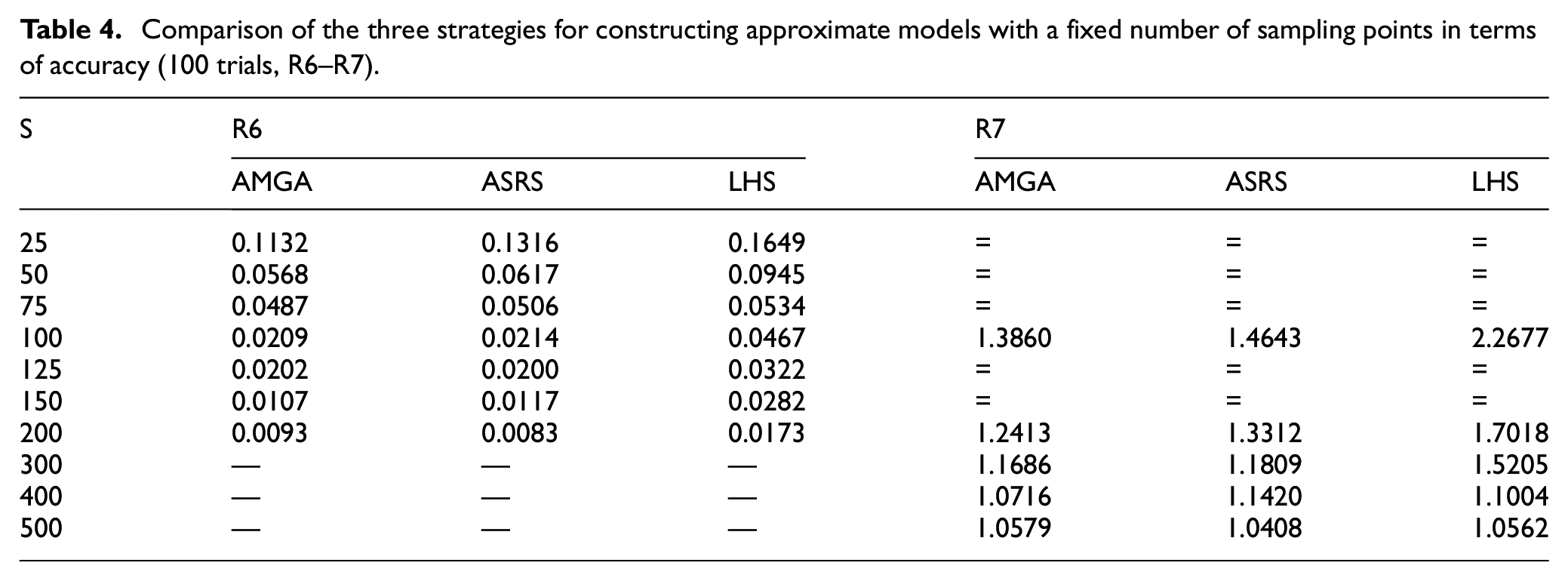
The number of times the source model is called for each of the three methods when constructing an approximate model with a specified level of accuracy (for 100 trials, R1–R4).
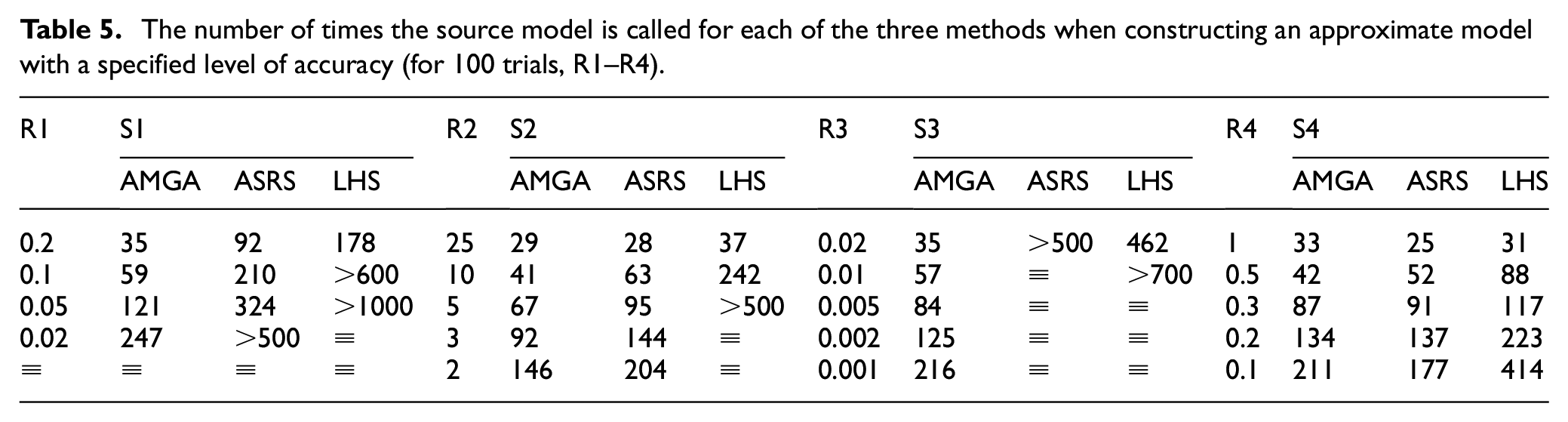
The number of times the source model is called for each of the three methods when constructing an approximate model with a specified level of accuracy (for 100 trials, R5–R7).

Tables 3 to 6 illustrate the test results of constructing the approximation model using the three sampling methods. S, S1–S7 represent the number of sample points, which corresponds to the number of calls to the source function for calculation. R1–R7 is the root mean square error of constructing the approximation model, which reflects the approximation model’s correctness. In Tables 5 and 6, the more calls to the source model necessary for the same root mean square error, the longer the time required, and the less efficient the associated sampling approach. The symbol “
The test results in Tables 3 to 6 demonstrate that the AMGA method outperforms the ASRS and LHS methods for the simple exponential, generalized polynomial, and Easom functions. It rivals the ASRS method on Peak, Apline, Schaffer’s, and Hartmann3 functions.
For the simple exponential function, Table 3 indicates that the AMGA method outperforms the ASRS and LHS methods, allowing a more accurate approximation model to be constructed from the start with fewer sampling points. Table 5 shows that the AMGA method, when compared to the other two methods, can construct an approximation model with some accuracy while using fewer source function calls. The findings in Tables 3 to 6 indicate the efficiency of the AMGA approach for the generalized polynomial and Easom functions.
For the Peak and Schaffer functions, the statistics in Tables 3 to 6 show that the AMGA and ASRS approaches have their own advantages and weaknesses, although both are much better than the LHS method.
For the Apline and Hartmann3 functions, the data in Tables 3 and 4 show that the AMGA method initially constructs a more accurate approximation model than the other two methods. As the number of sample points increases, the accuracy of the approximation model constructed by the AMGA method is slightly lower than that of the ASRS method, but better than that of the LHS method. Tables 5 and 6 indicates that the AMGA method initially produces a high-accuracy approximate model with the fewest source function calls. In terms of the number of source function calls, the AMGA approach is comparable to the ASRS method as accuracy rises.
Engineering cases
Problem description
As shown in Figure 7, the components of the electric vehicle (EV) simulation model are estimated using the AMGA method. The EV simulation model is mainly consists of drive, controller, and vehicle body components. While the vehicle body components include models of the motor, powertrain, battery, and transmission system, etc. The EV simulation model is primarily used for powertrain matching analysis, control and diagnostic algorithm development, and hardware-in-the-loop (HIL) testing, which necessitates a real-time EV model. The vehicle body, on the other hand, has the highest computational complexity, which has a direct impact on the overall computational complexity of the model. A metamodel is employed for simulation instead of the body components to speed up the calculation of the EV model and ensure real-time performance.

Electric vehicle model.
The NEDC22,23 cycle condition is used as the drive cycle of the car on the road in the EV simulation model. As indicated in Figure 8, the NEDC is made up of four cycles: the urban drive cycle condition (ECE-15) and the extra-urban drive condition (EUDC). To simplify the calculation, ECE-15 is chosen as the simulation drive.

NEDC driving cycle.
Process of model approximation
A model processing method based on feedback with fixed step size is provided to achieve the approximation of the car body of the EV simulation model. Generally, three states exist during simulation model operation: the previous simulation model state, the current simulation model state, and the latter simulation model state, as shown in the Figure 9 below.

The three states of the model.
Where Inp is the pth input to the model and OutK is the Kth output of the model. The model states before and after are ignored, and the current state is treated as follows.
Step 1: Create the Independent Simulation Module (ISM).
(1) Add input and output ports to the ISM, including state variable input and output ports.
(2) Using historical simulation data for the entire EV model, generate a range of values for the ISM input variables.
(3) Calculate the time step t0. At different simulation times t0, the ISM will produce varied outcomes. t0 is set to 0.1 s to allow the ISM to run in real-time later on. The processed ISM, as illustrated in Figure 10, contains the input and output ports, as well as the state variables and t0, and the ISM can be represented by the following equation.
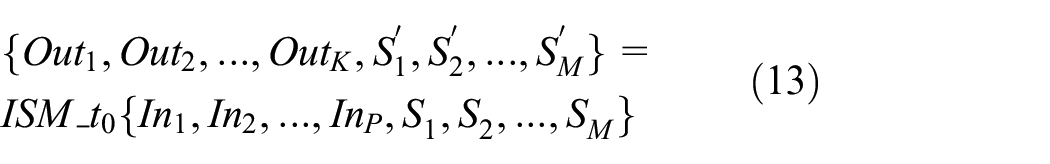

ISM of the simulation model.
Where SM is the Mth input of the state variable, SM’ is the Mth output of the state variable, ISM represents an independent simulation module based on t0.
Step 2: The ISM is approximated using the AMGA method.
Step 3: Confirm the approximation model’s accuracy, which can be measured using R2, as stated in the following equation.

Where f(
Step 4: If the approximation model’s accuracy does not meet the requirements, return to step (2) and continue processing the ISM using AMGA method to further improve the accuracy of the approximation model.
In addition, for the state variables in the simulation model, the specific form is as follows.

where t,
To validate the approximation model’s accuracy, the M state variables (S1, S2, … , SM) are processed so that they are self-looping and can be automatically updated during the simulation, as illustrated in Figure 11. The ISM’s input port is P inputs plus M state variable inputs, and its output port is P outputs plus M state variable outputs. The output of the state variable differs from the input by a time step delay of t0.

State variable processing.
Approximation model test
Create the ISM of the car body model, add three input ports (acceleration command Mcmd, brake command Bcmd, current battery state SOC). Add two output ports (motor rotation angular velocity W, discharge state SOCn for the next time step) with a time step delay t0 of 0.1 s (Figure 12).

ISM of the vehicle body model.
The AMGA method was utilized to construct a three-input, one-output approximation model for W and SOCn, respectively, once the ISM of the car body model was established. The approximation process’s parameters are set to Mcmd∈[0,1], Bcmd∈[0,1], SOC∈[93,100], δ1 = 10−1, δ2 = 10−3.
As illustrated in Figure 13, the procedure of substituting the approximation component for the matching vehicle body component in the original EV simulation model is as follows:
In the Matlab environment, obtain the approximation model’s relevant data: the approximate model’s coefficient column vectors and the sampling point matrix.
Using the From Workspace module, import the approximation model-related data and the input data into the Simulink environment.
Create a data bus in the Simulink environment so that data is transported in the Simulink model via a data bus.
Create a function module and a function valuation module in the Simulink environment. The former collects the data imported in step (2) and provides it as a structure to the following function valuation module; the latter analyzes the structure and uses the input data to perform valuation.
In the Simulink model, the input and output of the state variables are connected first and last, and the fixed-step delay module Memory is added between the input and output connections of the state variables.
Encapsulate the Simulink model and replace the ISM.

Verify the accuracy of the approximation component on the electric vehicle.
The simulation results of modified EV simulation model using the approximation component were compared to the original EV simulation model results, as shown in Figure 14.

Comparison of simulation results between EV simulation model with approximate component and original EV simulation model.
The variable curves obtained from the modified EV simulation model with the approximation component are essentially the same as the original EV simulation model, as shown in the Figure 14. The R2 values of SOC and W obtained by the AMGA method for the modified EV simulation model are 0.8758 and 0.8672, while the R2 values of SOC and W obtained by the ASRS method are 0.9053 and 0.8601. As a result, the R2 values obtained by both the AMGA method and the ASRS method are very close to each other and both are close to 1, which indicates that the modified electric vehicle simulation model has good accuracy. The original EV simulation model’s computation time, on the other hand, differs from that of the modified EV simulation model. The former takes roughly 15 min, whereas the latter takes about 1 min. As a result, the modified EV simulation model is significantly more computationally efficient than the original.
The approximation model can then be constructed by code and imported into the target machine, where a physical controller can be used to operate the running approximation model, enabling a semi-physical simulation experiment (Hardware-in-loop, HIL).
Conclusions
To overcome the black-box model approximation problem in large design domains, this work proposes a global approximation method AMGA based on adaptive metamodels. The method incorporates the following innovations: first, it use the Hessian matrix to determine the surface curvature of the metamodel in a given dimension; second, it employs the DIRECT method in conjunction with the Hessian matrix to determine the maximum curvature point of the metamodel surface; third, the design domain is split using the maximum curvature point to generate more sampling points; fourth, the method adds a novel mechanism for judging metamodel accuracy. The proposed method can split the large design domain continuously and construct new metamodel in the sub-design domain, avoiding the construction of a single, simple approximate model in the large design domain. This substantially enhances the overall approximation accuracy of these large design domain models and avoids the approximation model generation being slowed or even failing due to over-sampling inside the design domain.
This method, however, has several drawbacks. First, the AMGA method calculates surface curvature from a geometric standpoint, and the geometric method has its own disadvantages. As a result, it does not handle problems with more than four dimensions well, and more research is required to solve such difficulties; second, even if the design domain corners sampling points are continuous, the continuity problem of sub-domain boundaries after design domain splitting cannot be handled, and the continuity of all boundaries cannot be guaranteed; third, using the AMGA method to construct approximation models of many objectives at the same time is a difficulty that need to be addressed; fourth, the AMGA method has limited approximation power when dealing with the constraint function problem, and the constructed approximation model has poor accuracy. This problem can be used as a follow-up research point to enable the AMGA method to handle constraint functions with high accuracy and to research the approximation problem of constraint functions in discontinuous regions further.
Footnotes
Handling Editor: Chenhui Liang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the Commonweal Projects of Zhejiang Province of China (number GF20E090020).