
Abstract
In the fault diagnosis of high-pressure common rail diesel engine, the problem of low accuracy of fault diagnosis is caused by the inability to classify untrained state problems and training sets. To solve the above problems, an anti-interference classification model for fault diagnosis of high-voltage common rail system based on alpha shapes algorithm and K-means algorithm is proposed in this paper. This model can improve the anti-interference ability and training set updating ability of the fault diagnosis model. Using the anti-interference classification model composed of anti-jamming device and classifier, the samples for fault diagnosis are screened in advance, and the singular values of untrained state and trained state are classified. By constructing an anti-interference classification model composed of anti-interference device and classifier, the fault is diagnosed, and then the dependency of singular values is obtained through cluster analysis, which improve the anti-interference ability and training set updating ability of the fault diagnosis model. By comparing the diagnosis results of the fault diagnosis model with and without anti-interference classifier, we can found that the addition of anti-interference classifier makes the fault diagnosis model of high-voltage common rail system obtain the anti-interference ability to the untrained state and the ability to update the training set of the singular value of the trained state, and can slightly improve the accuracy of fault diagnosis.
Keywords
Introduction
High-pressure common rail system is a complex system composed of high-pressure oil pump, common rail pipe, electronically controlled injector and high-pressure oil pipe, which is prone to various types of faults in operation. In order to improve the fault diagnosis accuracy of high-voltage common rail system, in the single fault state, a new fault diagnosis mode is often used to extract state parameters, construct feature vectors and classify them by various classification algorithms, which can ensure high diagnosis accuracy for the single fault state. In terms of fault diagnosis of high-voltage common rail system, the time-frequency fault diagnosis method can be carried out by using signals such as vibration, vibration sound or rail pressure, which can solve various problems existing in practical application, such as difficulty in rail pressure signal extraction and post-processing, insufficient number of signal samples and so on.1–8 However, the anti-interference ability of these methods is very poor, the trained fault diagnosis model can only classify it into a known state when facing an unknown signal. The assumption that researchers usually make is: training set
However, in practice, for any unknown state signal ω, it may belong to any of the following situations:
This signal is a training set
This signal is a training set
This signal is not a training set
The first is that all kinds of fault diagnosis models can handle well, but for the second and third cases, the existing fault diagnosis models can not handle well. The ability of a fault diagnosis model to deal with an untrained eigenvalue vector, that is, the anti-interference ability of the fault diagnosis model of high voltage common rail system described in this paper; The ability of a fault diagnosis model to deal with a known state singular value and update the training set accordingly, that is, the updating ability of the training set of the fault diagnosis model of high voltage common rail system described in this paper. The existing research has not conducted in-depth discussion on this issue. After deeply studying the anti-interference ability of fault diagnosis model of high-voltage common rail system, this paper divides this problem into two aspects: the first is the problem of identifying untrained state by fault diagnosis model of high-voltage common rail system; The second is the singular value problem of identifying the trained state by the fault diagnosis model of high pressure common rail system.
In order to solve the above two problems, an anti-interference classification model is added to the fault diagnosis model, which is composed of two parts: the first part is an anti-jamming device for screening singular values of trained state and untrained state; The second part is the classifier used to classify the filtered singular values. The complete fault diagnosis model of high-pressure common rail system is shown in Figure 1.

Fault diagnosis flow chart of high voltage common rail system.
In order to build an anti-jamming device, it is necessary to establish a layer around the boundary of the eigenvector of each state in the fault diagnosis model training set. The training set of fault diagnosis model is composed of eigenvalue vectors of various states. In this training set, the eigenvectors of each state are relatively concentrated together. When the number of eigenvectors of a state is infinite, that is, when all eigenvectors of this state are collected, a boundary can be found to wrap all eigenvectors of this state. The eigenvectors outside the boundary must not belong to this state (but the eigenvectors inside the boundary do not necessarily belong to this state due to mixed signals). However, due to various factors, it is impossible to collect all the eigenvectors of a state. At this time, it is necessary to rely on limited eigenvectors to build a boundary that can complete the above mission, which needs to meet the following conditions:
This boundary needs to completely cover the known eigenvector of this state.
The wrapping normal space of this boundary should not be too small, which will miss some eigenvectors obviously belonging to this state; nor should it be too large, which will wrap some eigenvectors obviously not belonging to this state.
In solving the boundary problem of discrete points, there have been mature methods such as meshing, row column method, rotating boundary, Delaunay algorithm and so on, but their space utilization efficiency is very poor when facing concave boundary, which will cover some unnecessary space. In the field of image recognition, the boundary is mainly constructed by color difference, which has no reference value to solve the problems faced in this paper. Considering comprehensively, this paper selects alpha shapes algorithm to construct the boundary of discrete points, which is a boundary extraction method based on rolling, which can construct the boundary with moderate size and allow fine-tuning of some details. After establishing the boundary of each state feature vector, the boundary fusion is carried out for the intersecting or too close boundary. Finally, several regions composed of different state feature vectors are obtained in the whole feature vector space. Considering the number and distribution of samples in a certain area, in order to solve the possible problems such as insufficient sample distribution of training set, the boundary relaxation variable is set to increase the range of the boundary. At this time, there are two sets in the whole eigenvector space: the wrapped set wrapped by the relaxed boundary (including all eigenvectors in the fault diagnosis training set) and the uncoated set outside the relaxation boundary. In the uncoated set, several eigenvectors and all eigenvectors in the known state are randomly selected to form the anti-jamming training set, and a bisection model is constructed based on SVM. This bisection model and the regional boundary together form an anti-jamming device for the known state and the known state Singular values and unknown states are classified.9–21
In order to detect the possible classification of singular values, it is necessary to classify the exact attribution of singular values. Common classification methods such as SVM, random tree forest and neural network will distinguish them according to the feature relationship, and the effect is poor when distinguishing samples not included in the training set such as singular value. In this paper, cluster analysis is used, which is a method to classify according to the similarity of different classification features, and singular values are classified to update the training set and as a reference basis for fault diagnosis.22–31
Based on the above methods, in order to improve the anti-interference and training set updating ability of the fault diagnosis model of high-voltage common rail system, alpha shapes algorithm and relaxed boundary variables are used to construct the covering sets of various states in the fault diagnosis model training set, Randomly generate the point set that does not belong to the covering set, and input it with the training set of the fault diagnosis model into the binary model constructed by SVM for training. Before fault diagnosis, the anti-interference model composed of binary model and regional boundary is used to classify, so as to improve the anti-interference ability of the fault diagnosis model of high-voltage common rail system. For the singular values obtained by classification, the possible subordinate states are obtained through cluster analysis to assist in judging the fault state and updating the training set, so as to improve the updating ability of the training set of the fault diagnosis model of high-voltage common rail system.
Decomposition of rail pressure signal, construction of eigenvector, and establishment of fault diagnosis model
In order to fully demonstrate the anti-interference ability of the fault diagnosis model of high-voltage common rail system proposed in this paper, the improved EEMD (ensemble empirical mode decomposition) is used to decompose the rail pressure signal of high-voltage common rail system, and the energy method is used to obtain the eigenvector. The fault diagnosis model of high-voltage common rail system is built by SVM (Support Vector Machine) to classify and diagnose the four states.
In this paper, the high-pressure common rail system of 10 cylinder diesel engine is taken as the research object. In order to simplify the calculation, a bench of high-pressure common rail fuel supply system of 5 cylinder monorail diesel engine is built for research. The relevant parameters are shown in Table 1. The operating conditions are as follows: the engine speed is 3800 rpm, the circulating fuel injection quantity is 220 mm3, and the fuel injection pulse width is 0.398 ms. The average rail pressure in one working cycle is 185 MPa, and the fluctuation is less than 5%. The injector is named a–E. according to the injection sequence. The test bench adopts Bosch rail pressure sensor with sampling frequency of 1000 Hz and dewe43 signal acquisition module as data collector. This paper uses MATLAB R2016b to build various mathematical models. The operating environment is win10, and the workstation is configured as Intel c621 series chipset; Intel Xeon gold 6145 processor, 40 cores, 80 threads, main frequency 2.0 GHz, maximum Rui frequency 3.7 GHz; 128 GB memory; NVIDIA gt1030, 2 GB graphics card. The fuel injector is shown in Figure 2 and the test bench is shown in Figure 3.
High pressure common rail system parameters.


Fuel injector.

Common rail system test diagram.
According to the common faults and classification of oil supply system of high pressure common rail diesel engine, four operating states are selected, one of which is normal operation state, and three are fault state. The four states are: normal state, delayed injection state of injector C, oil leakage state at the inlet of common rail pipe and oil leakage state at the inlet of injector C, respectively. The above four states are named state 1–state 4 respectively. In this paper, the rail pressure data is pre processed with reference to the method proposed by Li et al. To improve the quality of rail pressure signal. The rail pressure signal is shown in Figure 4. 8
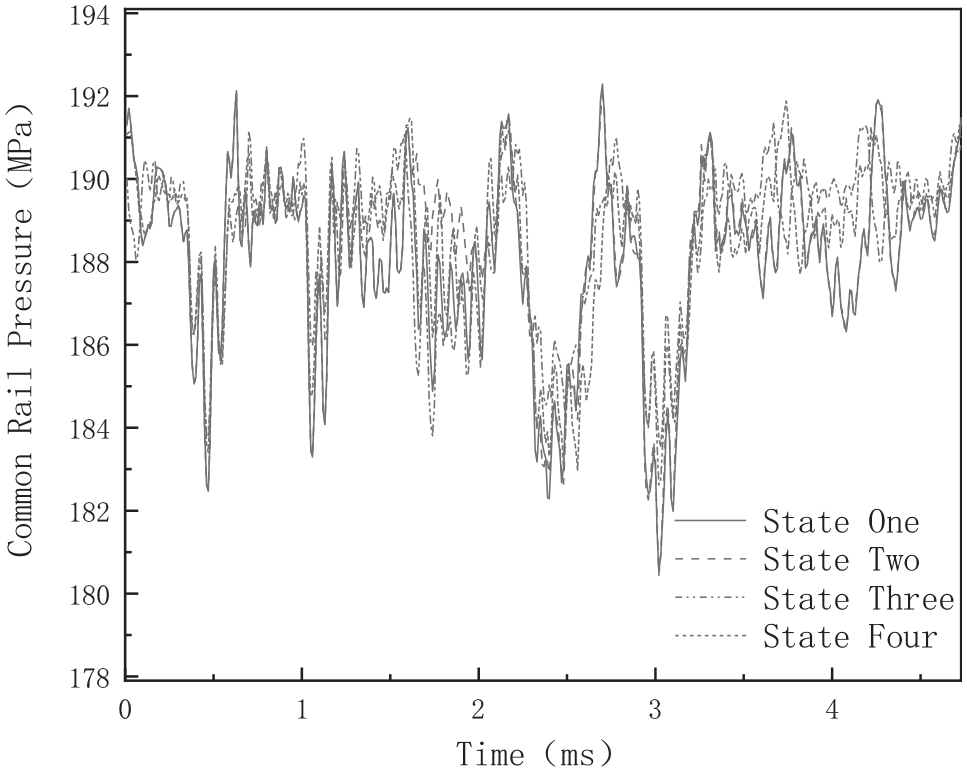
Rail pressure signals in different operating states.
In order to accurately extract the eigenvalues of rail pressure signal, the rail pressure signal is decomposed into different IMF by EEMD, and the extracted multiple energy eigenvalues are constructed as energy eigenvectors for fault diagnosis.
EEMD is a method based on EMD to decompose signals into intrinsic modal functions. By adding white noise signal to the original signal, the signals of different time scales are distributed to the appropriate reference scale. After several times of averaging to offset the noise, the final result is obtained by integrating the mean value. EEMD solves the mode aliasing problem of EMD by using the uniform distribution of white noise signal spectrum, further improves the decomposition accuracy, and accurately retains the characteristics in the original data.
The purpose of EEMD is to decompose a signal into n IMF and a residual. Among them, each IMF needs to meet the following conditions:
In the whole data range, the number of local extreme points and zero crossings must be equal, or the difference number must be at most 1.
At any time, the average value of the envelope of the local maximum (upper envelope) and the envelope of the local minimum (lower envelope) must be zero.
If a signal meets the following characteristics:
The signal has at least one maximum and one minimum.
The time scale characteristic of signal is determined by the time scale between two extreme points.
Then this signal can be EEMD.
Set M as the total number of expected EMD, m as the current number of EMD, and construct m different white noise signals for use. After all m times of decomposition are completed, the mean value of IMF corresponding to each stage obtained by m times of EMD is the final IMFs obtained by EEMD. The decomposition flow chart is shown in Figure 5.

EEMD flow chart.
In the process of fitting the curve to get the upper and lower envelope, this paper uses cubic spline interpolation curve to construct the envelope.
11
Set interval
For all internal nodes, the left and right limits of the interpolation function are equal and fixed.
For all internal nodes, the left and right limits of the first derivative are zero.
The interpolation function value of the head and tail nodes is fixed and the first derivative is zero.
According to the decomposition steps in this section, EEMD is performed on the rail pressure signals from state 1 to state 6 respectively, as shown in Figure 6(a)–(b) is the sixth order IMF component and spectrum decomposed from state 1 to state 6. It can be clearly seen that the frequency of each order IMF component is clear and the signal aliasing is not serious.

Sixth-order IMF components and frequency spectrum of the state one rail pressure signal: (a) IMF and (b) spectrum.
In this paper, the IMF component with the largest zero crossing slope ratio of adjacent curves is selected as the separated IMF, which means that the signal contribution of this IMF component decreases suddenly. Compare the zero crossing rates of the sixth order IMF components from state 1 to state 6 respectively. As shown in Figure 7, the slope ratio of the number of zero crossings of imf1 to imf6 components of state 1 to imf1 to imf5 components is shown. It can be seen from the figure that the maximum slope ratio can be obtained at imf3. The slope ratio of the number of zero crossings of imf1–imf6 components and imf1–imf5 component signals in the other three states is similar to that in state 1, and the maximum slope ratio appears at imf3. Therefore, imf1, imf2, and imf3 components are used to extract eigenvalues. 12

The number of zero-crossing points and slope ratio of each IMF component.
The energy of each IMF component represents the energy of the signal within this frequency, so there is a mapping relationship between the signal and energy, which can be used as the basis of fault diagnosis. Here, the corresponding energy is extracted for imf1 and imf2 to construct the feature vector. Energy of each IMF component

In equation (1)
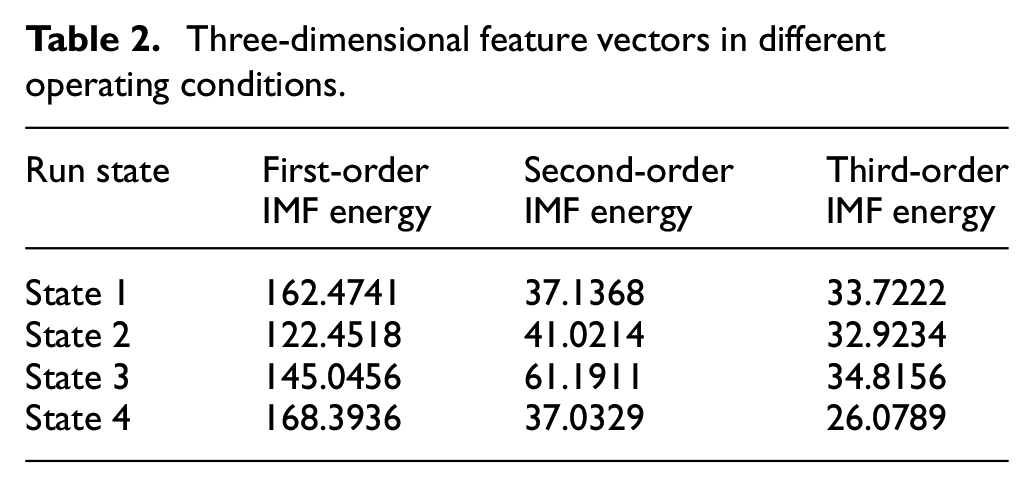
Table 2 shows the three-dimensional eigenvectors composed of the first three order IMF energy of rail pressure signals in four states after EEMD processing.
Three-dimensional feature vectors in different operating conditions.
In order to verify the accuracy of the anti-interference model proposed in this paper, multiple groups of data need to be collected for classification training and testing. According to the above, 40 groups of rail pressure signals are collected as training samples for four operating states: normal state, delayed injection state of injector B, oil leakage state at the inlet of common rail pipe and oil leakage state at the inlet of injector B.
In order to construct the contour, it is necessary to reduce the discrete points of high latitude to two dimensions. In this paper, principal component analysis (PCA) is used to reduce the dimension of three-dimensional feature vector to two-dimensional eigenvalue vector, which is a common linear dimension reduction method. It maps high-dimensional data to low-dimensional space through some linear projection, and expects the maximum variance of data in the projected dimension. In this way, fewer data dimensions are used and more original data points are retained. PCA is a linear dimensionality reduction method with the least loss of original data information. After dimensionality reduction, the distribution is closest to the original data, and it can reduce the dimension of discrete points to any dimension.
The steps of dimensionality reduction using PCA can be expressed as follows:
Select a feature, average each feature, and subtract the average value from the original data to the new centralized data.
Find the characteristic covariance matrix.
According to the covariance matrix, the eigenvalues and eigenvectors are obtained.
The eigenvalues are arranged in descending order, the corresponding eigenvector is given, and the principal component is selected to calculate the projection matrix.
The reduced dimension data is obtained according to the projection matrix.
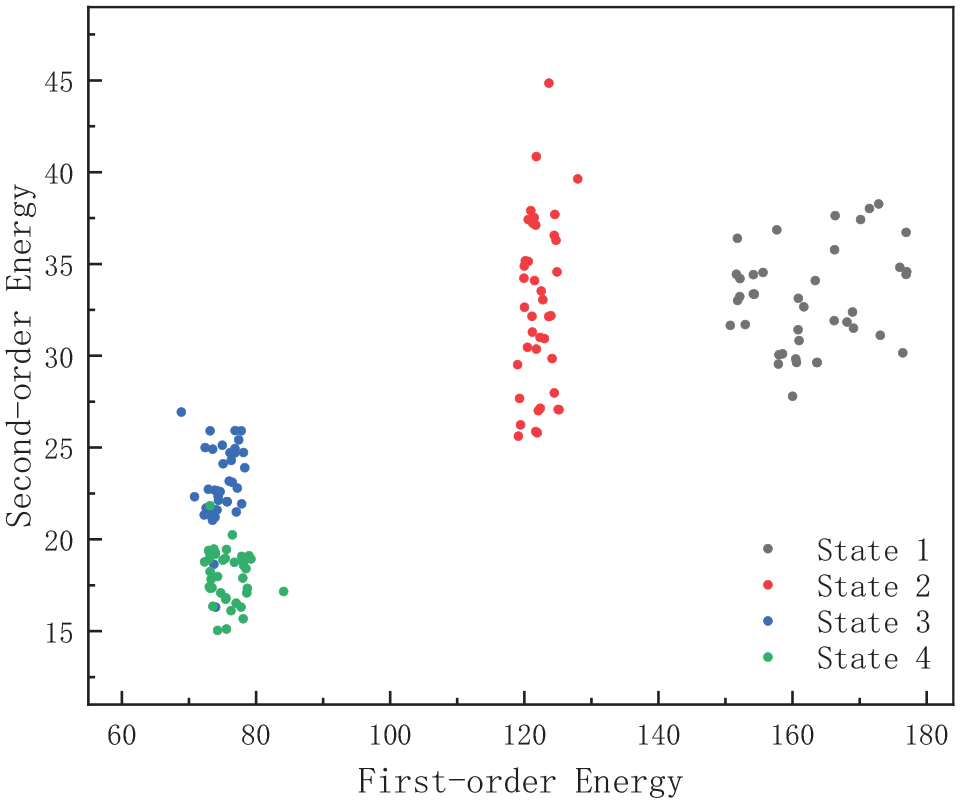
Extract the first three order IMF energy from the rail pressure signal of the training sample to form a three-dimensional feature vector. After dimensionality reduction, the box diagram is obtained, as shown in Figure 8, the abscissa in the figure represents state 1 to state 4 from left to right, and the two-dimensional diagram of energy distribution is drawn, as shown in Figure 9. It can be seen from the above figure that after EEMD decomposition, energy eigenvalue extraction and dimension reduction, the energy eigenvectors of the four states are clearly distinguished. The fault diagnosis model based on SVM is shown in Figure 10.

Two dimensional eigenvector box diagram.
Schematic diagram of two-dimensional feature vector.

Fault diagnosis model based on SVM.
This paper will build an anti-interference classification model based on 160 groups of training samples in four states and the fault diagnosis model.
Construction of anti-interference classification model
As can be seen from Figure 8, the distribution of eigenvalues of state 1 and state 2 is relatively independent for other states, while the eigenvalues of state 3 and state 4 cross together. It is expected that after complete fusion, three regions A, B, and C as shown in Figure 11 can be formed, in which a is composed of state 1, B is composed of state 2, and C is composed of state 3 and state 4. This section will show the whole process of constructing the anti-interference classification model: establishing the independent boundary of each state – boundary fusion to form the region – establishing the regional relaxation boundary – establishing the anti-interference classification model.

Schematic diagram of expected fusion area of two-dimensional feature vector.
Construction of state boundary
In order to extract the boundary points of each state, this paper adopts the alpha shapes algorithm proposed by Edelsbrunner H. which is a simple and effective method to extract the boundary points quickly. It overcomes the disadvantage of the influence of the shape of the boundary points of the point cloud, and can extract the boundary points quickly and accurately. For two-dimensional discrete points of arbitrary shape, make a radius of

Schematic diagram of 2D discrete point boundary extraction.
The calculation steps of the algorithm are:
When the rolling radius is
Pick point

Where:

3. If for a point set
4. If for a point set
After the above steps, the two-dimensional discrete point set
Each state boundary constructed by the above method is shown in Figure 13.

Schematic diagram of state boundary construction.
Boundary fusion and construction of relaxed boundary
As can be seen from Figure 13, the boundaries of state 1 and state 2 are relatively independent of other states, while the boundaries of state 3 and state 4 are intertwined. Therefore, the boundaries of state 3 and state 4 are fused here. In addition to the states where the boundaries intersect, the states where the boundaries do not intersect but are too close are also fused. For any state

Schematic diagram of regional boundary construction.
At this time, if a point is not in the state
For any state

This problem can be solved by genetic algorithm and other optimization algorithms. The solution and optimization process of this problem will not be repeated in this paper.
Select
1. Set of line segments at boundary
2. Through segment
3. Calculated

4. Loop from step 1 to step 3 until you traverse the set Medium
The two-dimensional feature vector set is constructed by the above method

Schematic diagram of relaxation boundary.
Construction of classification model
In order to obtain the point set samples that do not belong to the known state, it is necessary to generate random points in a certain range. In order to make the generated points more evenly distributed, the fixed sized candidate set art (fscs-art) algorithm is used to generate random points. This is an adaptive random testing algorithm based on Art (adaptive random testing). Its core idea is to generate a candidate test set first. The shortest distance set is composed of the shortest distance between each individual in the candidate test set and each individual in the test set, and then the maximum distance in the shortest distance set is updated to the test set. It can be represented by equation (6).
The distance between a and b is representative by

Comparison of randomly generated two-dimensional arrays: (a) art and (b) randomly generated.
In order to make the point set evenly distributed in the non covered area, when initializing the candidate test set V, filter the points in the test set and eliminate the points in all covered areas. The steps are as follows:
For each candidate test set point, for a certain state, select a random direction to construct ray a, and construct ray b in the opposite direction at the same time.
When the rays on both sides do not pass through the endpoint of the state boundary. If there are odd intersections between ray a or ray b and the boundary of a state, the point is considered to be within this state, and the point is removed from the candidate test set. Return to step 1, reselect the state and build a new ray until the points of the candidate test set are determined.
When a side ray passes through the endpoint of the state boundary, return to step 1 and reconstruct the ray for this state.
The SVM dichotomy model using Gaussian kernel function is constructed for the obtained covered area point set and non covered area point set. This is a kernel function mainly used in the case of linear indivisibility. Its parameters are many and the classification results are very dependent on the parameters. Good results can be obtained when solving the classification problem with small feature dimension and normal sample number. The disadvantage is that finding the appropriate parameters often takes a lot of time and depends on manual selection. Thus, the trained anti-interference model can be obtained.
Cluster analysis
After classification by anti-interference model, for a certain area

Schematic diagram of relationship between area and boundary.
For any data, there are only three situations: p
Through the corresponding steps in Section 3.3, any feature vector can be classified in the above three cases. For 1 and 3 cases, the specific status of the data will be accurately classified. For the second case, it is only marked as possible
In order to further accurate the possible state of data, this paper uses k-means algorithm to process data and state p and a. This is a hard clustering algorithm, which can strictly classify the identified objects into a specific category, and can better solve the data p either or problem faced in this paper. The calculation steps are as follows:
Set the number k of cluster centers and initialize the location of cluster centers
Calculation
After classifying all points in the data set, calculate the center point of all points in each class as the new clustering center of this class
If the iteration conditions are met, the clustering results are obtained. If not, repeat the second step.
In this paper, the iteration stop condition shown in equation (7) is used.

Experiment and result analysis
At present, multiple groups of signals are collected for four operating states: normal state, delayed injection state of injector C, oil leakage state at the inlet of common rail pipe and oil leakage state at the inlet of injector C to form a verification set; In order to verify the anti-interference ability of the anti-interference classification model constructed in this paper, Add several signals of the fifth state and several meaningless signals (named state 6) to the verification set; in order to verify the classification ability of the anti-interference classification model constructed in this paper, select several singular values of four states to the verification set. State 5 is the wear state of the oil pump plunger, and its rail pressure signal is shown in Figure 18.

Rail pressure signal in state V.
Thus, 20 state one signals (including two singular values), 20 state two signals (including one singular value), 20 state three signals (including two singular values), and 20 state four signals are obtained (including a singular value), 10 state five signals and 10 randomly generated meaningless signals constitute a verification set. The signals are numbered as 1–100 in sequence, in which the singular values are numbered as 19, 20 (state I), 40 (state II), 59, 60 (state III) and 80, respectively (state 4) the two-dimensional feature vector is constructed by the method in the second section above, and its eigenvalues are shown in Figure 19.

Schematic diagram of characteristic values.
Input the above training set into the fault diagnosis model without anti-interference classification model to classify the operation state. The classification results are shown in Figure 20. The abscissa in the figure is the signal number of the training set, and the ordinates 1–6 represent state 1–state 6 respectively.
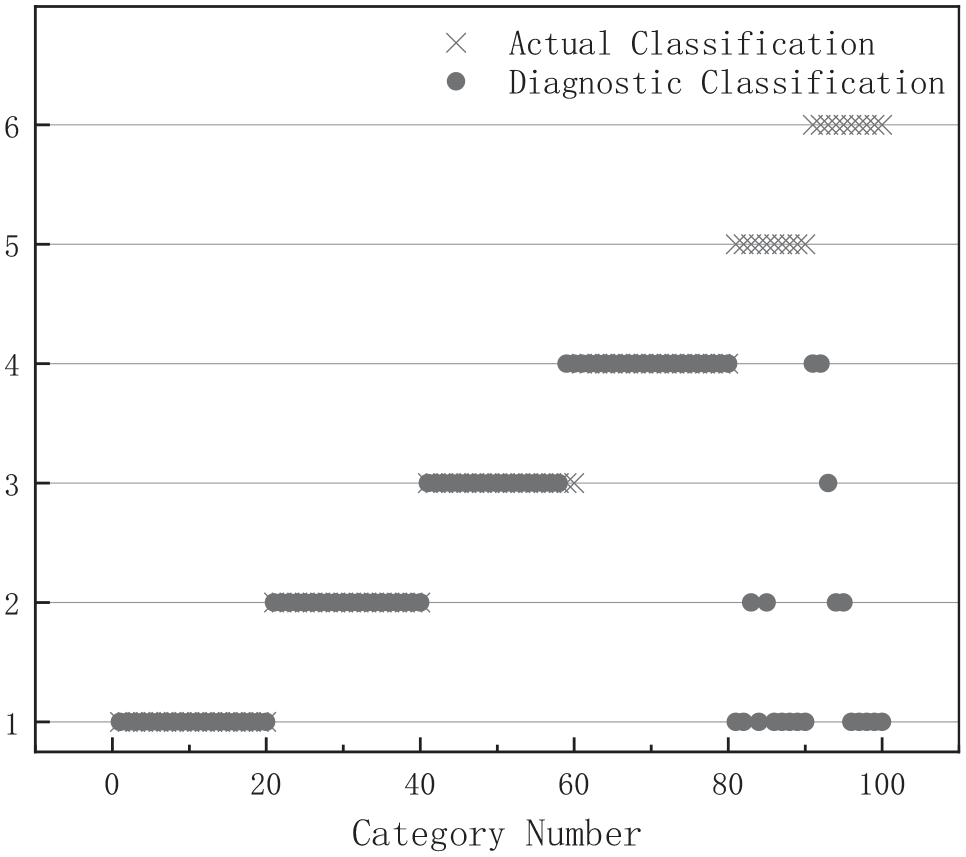
Classification results.
As can be seen from the above figure, the fault diagnosis model classifies all States into trained States, which leads to the classification of state 5 and state 6 to state 1 to state 4, respectively according to the set hyperspace plane. In state 5, two signals are classified in state 2 and eight signals are classified in state 1. In the face of the trained state, due to the existence of singular values, the signals of two state three are classified into state four.
As a comparison, input the above training set into the fault diagnosis model including the anti-interference classification model to classify the operation state, as shown in Figure 21, the abscissa in the figure is the signal number of the training set, and the ordinate is the screening result, where 1, 2, and 3 represent trained, singular value and untrained respectively. As shown in Figure 22, the diagnosis results combined with cluster analysis are shown, and the abscissa in the figure is the signal number of the training set; Ordinates 1–5 represent state I, state II, state III, State IV, and untrained state respectively; Red represents the singular value signal judging that it is in the trained state, which should be added to the training set for updating.

Screening results.

Classification and clustering results.
It can be seen from the figure that the fault diagnosis model with anti-interference classification model judges five of the six singular values correctly; 18 of the 20 interference states (state 5 and state 6) are judged correctly. Table 3 shows the accuracy analysis of the two fault diagnosis models.
Accuracy analysis.
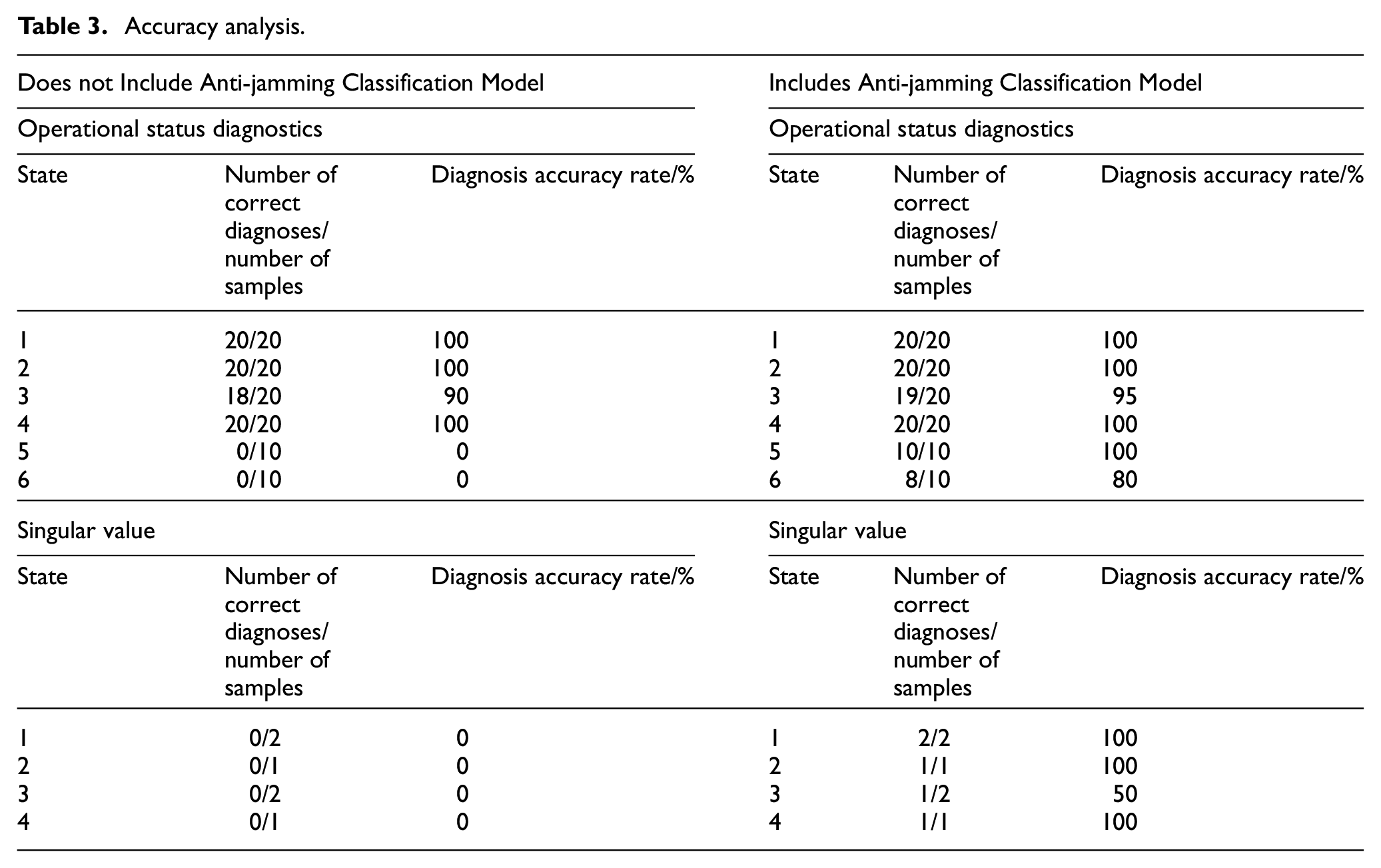
It can be seen from the Table 3 that the fault diagnosis model with anti-interference classification model has strong anti-interference ability and strong troubleshooting ability for untrained States, and its classification accuracy can reach 90%. It has strong classification ability for the singular values in the trained state, and at least 50% of the singular values can be selected to update the training set. At the same time, screening the samples in advance also helps to improve the diagnostic accuracy of the trained state, and the diagnostic accuracy is increased from 97.5% to 98.75%. From the experimental results, the addition of anti-interference classification model helps to improve the accuracy of fault diagnosis model of common rail system, and brings strong anti-interference and training set updating ability to the fault diagnosis model.
Conclusion
In order to improve the anti-interference ability and training set updating ability of the fault diagnosis model of high-voltage common rail system, the rail pressure signals under different operating states of high-voltage common rail system are obtained through bench test. The fault diagnosis model of high-voltage common rail system based on SVM is established through EEMD decomposition, energy eigenvector construction and dimension reduction processing. Based on alpha shapes algorithm and K-means algorithm, an anti-interference classification model composed of anti-jamming device and classifier is established. Compared with the fault diagnosis model without anti-interference classification model, the following conclusions can be obtained.
Compared with the fault diagnosis model without anti-interference classification model, the fault diagnosis model with anti-interference classification model has an ability to classify the untrained state. In the face of four trained states: normal state, delayed injection state of injector C, oil leakage state at the inlet of common rail pipe and oil leakage state at the inlet of injector C, and two untrained states: worn state and meaningless state of oil pump plunger, the fault diagnosis model with anti-interference classification model can classify the untrained state with a correct rate of 90%, most untrained states can be excluded.
Compared with the fault diagnosis model without anti-interference classification model, the fault diagnosis model with anti-interference classification model has an ability to update the training set. In the face of six singular values of four trained States, the fault diagnosis model with anti-interference classification model classifies five of them, and correctly classifies their possible subordinate states. The accuracy rate is 83.3%. It can be added to the training set of fault diagnosis model to update the training set.
Compared with the non-interference fault diagnosis model, the fault diagnosis accuracy of the fault diagnosis model with anti-interference classification model is slightly improved, which is due to the classification of singular values of trained states and cluster analysis.
To sum up, the anti-interference classification model for fault diagnosis of high-voltage common rail system proposed in this paper can effectively improve the anti-interference ability and training set updating ability of the fault diagnosis model, and can slightly improve the diagnosis accuracy of the fault diagnosis model for the trained state. Because it does not need to change the structure of the original fault diagnosis model, it can be added in front of any fault diagnosis model relying on eigenvector to improve its anti-interference ability and training set updating ability.
Footnotes
Handling Editor: Chenhui Liang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.