
Abstract
The bearings faults are reported to be the major reason for centrifugal pump (CPs) failures. Limited literature is available to diagnose the minor scratches in the bearing surface through non-intrusive condition monitoring techniques. Recent research on the analysis of bearing scratches through non-intrusive motor current analysis (MCA) has shown encouraging results where the comparison of machine learning and convolutional neural networks (CNNs) was performed in the classification of healthy bearings and faulty bearings (holes and scratches). The fault classification accuracy of 89.26% through MCA combination with machine learning and CNN algorithm was reported which is very low. The key factors of low accuracies were identified as low amplitudes of the harmonics in the MCA spectrum, the magnitude of environmental noise, and utilization of conventional feature extraction techniques. This problem has been tackled in this paper by developing a novel feature extractor (NFE) that extracts powerful features from the integrated current and voltage sensors data. The NFE has been derived using the threshold-based decision mechanism which has the capability to identify the location of the feature harmonic, feature extraction, measure the amplitude of the fault component, and compare it with the derived threshold. The experimental data has been collected for the bearing balls (BB), bearing cage (BC), inner race (IR) and the outer race (OR) faults, and the performance of the NFE has been tested on an ensemble classifier (CatBoost) and the better classification accuracy (99.2% for an individual feature and 100% with the combination of two or more features) of NFE has been achieved as compared to previously reported methods.
Keywords
Introduction
CPs usually operate in the industrial environment where there are issues of high temperatures, humidity, dust, and noise.1–3 The bearing is one of the critical components of CPs which prone to various faults. The Figure 1 indicates that the CPs maintenance cost is highest in the industry and Figure 2 shows that the malfunction in bearings is highest among other components. 4 Thus, the fault diagnosis of bearings of the CPs has a great importance.5–10 The bearings are the reason for more than 41% of machine breakdowns, thus, this paper investigates various faults in bearings. The bearing structure and its components are shown in Figure 3.11,12 Most of the literature has focused on diagnosing techniques for holes and cracks in IR and OR.13–16 Only two papers are found in the published literature which focuses on the diagnosis of mini scratches in OR.17,18 The diagnosis of mini scratches in IR is not reported in the literature.19–22 Thus, the scope of this study is to examine the mini scratches in IR and OR along with faults in BB and BC.

The maintenance cost of the petrochemical plant.

The statistics of the machine failure due to various components.

The schematic of the bearing.
The typical sensors used in the fault diagnosis of the CPs are accelerometers (vibration sensors), current transducers (CTs), voltage transducers (VTs), noise sensors, temperature sensors, and magnetic flux sensors. 23 The fault diagnosis techniques are usually named based on the sensor type used for data collection. The vibration analysis, thermal analysis, magnetic flux analysis, noise analysis, and acoustic emission techniques are categorized as intrusive techniques as the sensors used in intrusive techniques are installed on the machine surface. Although intrusive techniques are well known in the industry and ISO standards are available to categorize the machine failures based on the sensors data. However, some machines are located in such positions that access to the machine is not easy for sensor fitting and status monitoring. Thus, the intrusive techniques are not suitable for such applications. Furthermore, the high cost of the sensors is another major disadvantage associated with intrusive techniques.24–29 In the past, some researchers had developed a non-intrusive condition monitoring technique through fast Fourier transform of the motor line current data and analyzing the fault-related harmonics. This technique was named motor current analysis (MCA).30–34 Several papers have been published in the past decade to improve the performance of the MCA by developing pre-processing algorithms to make the condition monitoring system reliable, efficient, economical, and to reduce the complexity.35–38 Although MCA is a better alternative to intrusive techniques but harmonics associated with defects are suppressed by the amplitude of line frequency and give a false alarm. Another issue reported with MCA is the high tendency of false alarms in a highly noisy environment.39–41
Fault diagnosis of machines through artificial intelligence (AI) has been the trend in the last couple of years and various AI algorithms such as support vector machine (SVM), Naive Bayes classifier (NBC), k-nearest neighbor (k-NN), and neural networks (NN) have been used in the literature for the diagnosis and classification of bearing faults. However, low classification accuracies have been observed in conventional machine learning models for bearing scratch type of faults diagnostics and classification.17,18,42–47 Furthermore, the capability of individual features has never been tested in the past to determine fault classification accuracy.
The literature review given in earlier paragraphs highlights the limitations of intrusive and non-intrusive condition monitoring techniques and gives a direction for the significant improvements for non-intrusive condition monitoring techniques so that it could be capable of reliable fault diagnosis in a highly noisy environment. The low classification accuracy has been reported to be the main issue in conventional machine learning models. The literature on bearing fault diagnosis gives a potential research direction for reliable fault diagnosis and fault classification for scratches in OR and IR faults. Thus, the contributions of this paper are:
A novel feature extractor (NFE) has been developed which extracts only powerful features from the IPS data with the objective to enhance the classification accuracy of the ensemble classifiers.
The ensemble classifier (CatBoost) algorithm has been developed to identify the effectiveness of the NFE and to test the capability of the individual features as well as a combination of features of IPS for fault diagnosis.
The rest of the paper has been structured as: Section 2 presents the mathematical steps for the feature identification, selection, extraction, and NFE development. Section 3 describes the condition monitoring setup. The results and discussions are provided in Section 4. Finally, the conclusion has been presented in Section 5.
Development of novel feature extractor
The features for bearing ball (BB), bearing cage (BC), inner race frequency (IRF), and outer race frequency (ORF) are shown in Table 1. The derivation of the fault features and the sample calculations are shown in Appendix A.
The harmonic locations for various faults.

In Table 1,
The novel feature extractor (NFE) has been developed using the following steps:
The data has been collected from voltage and current sensors and has been converted into frequency spectrum using IPS algorithm.
The normal bearings data has been used as a benchmark for amplitude calculation and comparison.
The frequencies associated with the faults such as
An algorithm has been constructed to automatically extract the
The amplitude difference between benchmark values and values of
The final comparison of the magnitudes has been performed between the threshold value and those
The flow chart of the NFE development has been shown in Figure 4.
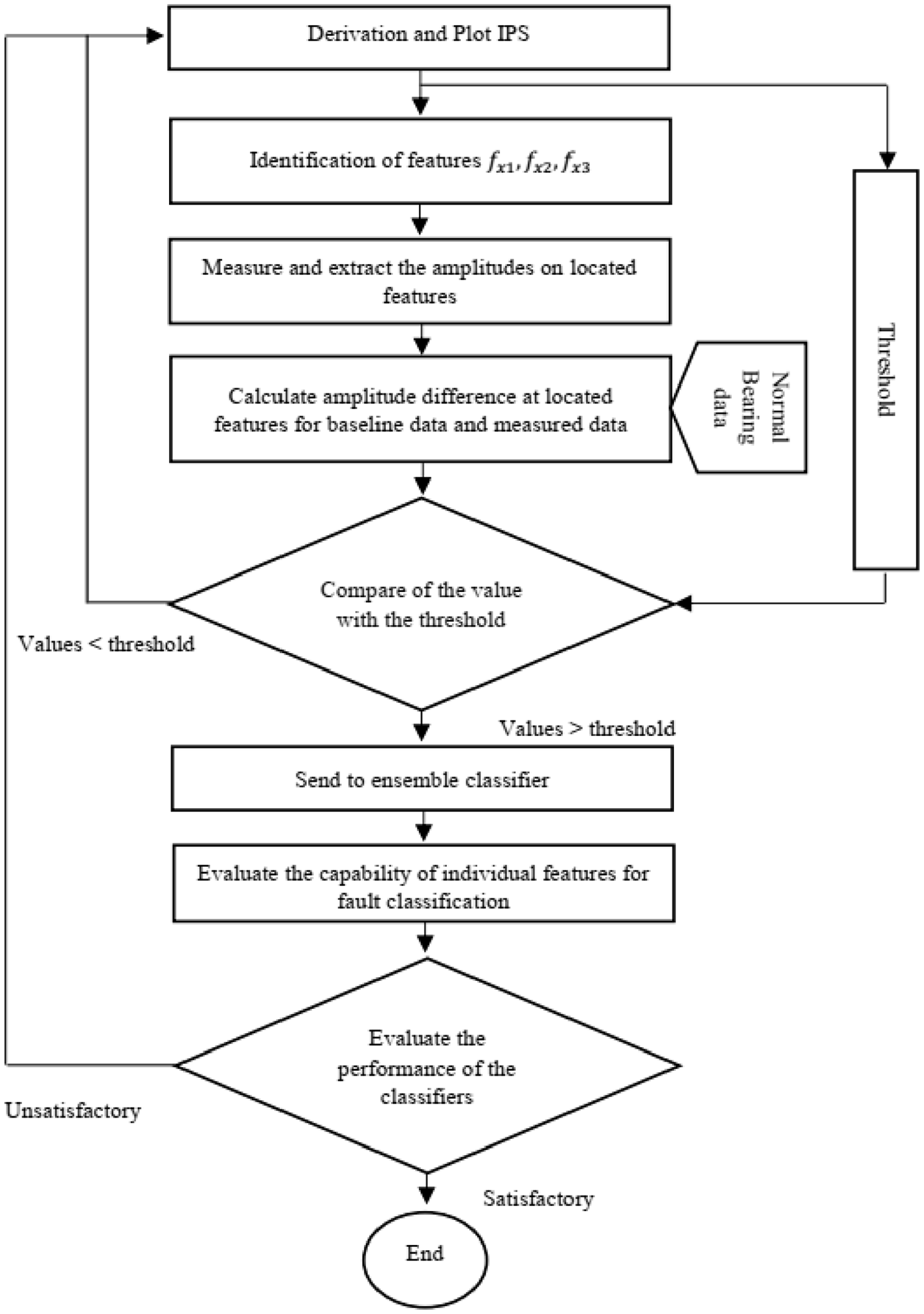
The flow chart of the NFE.
Experimental procedure
The system developed for the performance monitoring of the centrifugal pump has been shown in Figure 5. The current and voltage sensors are placed on the electric power line. The data collected from the sensors is interfaced through NI PXIe 6363 and is examine in LabVIEW. The four faults are simulated in the bearing: Type 1 is ball defect, Type 2 is broken cage, Type 3 is a scratch of 0.5 mm width, 0.5-mm depth, and 5-mm length in the inner surface of the bearing, Type 4 is a scratch in the outer surface of bearing with the same dimensions as of Type 3. The simulated bearing faults have been shown in Figure 6.

The system developed for the condition monitoring of the centrifugal pump.

Faults in bearing: (a) BBF, (b) BCF, (c) IRF, and (d) ORF.
Results and discussions
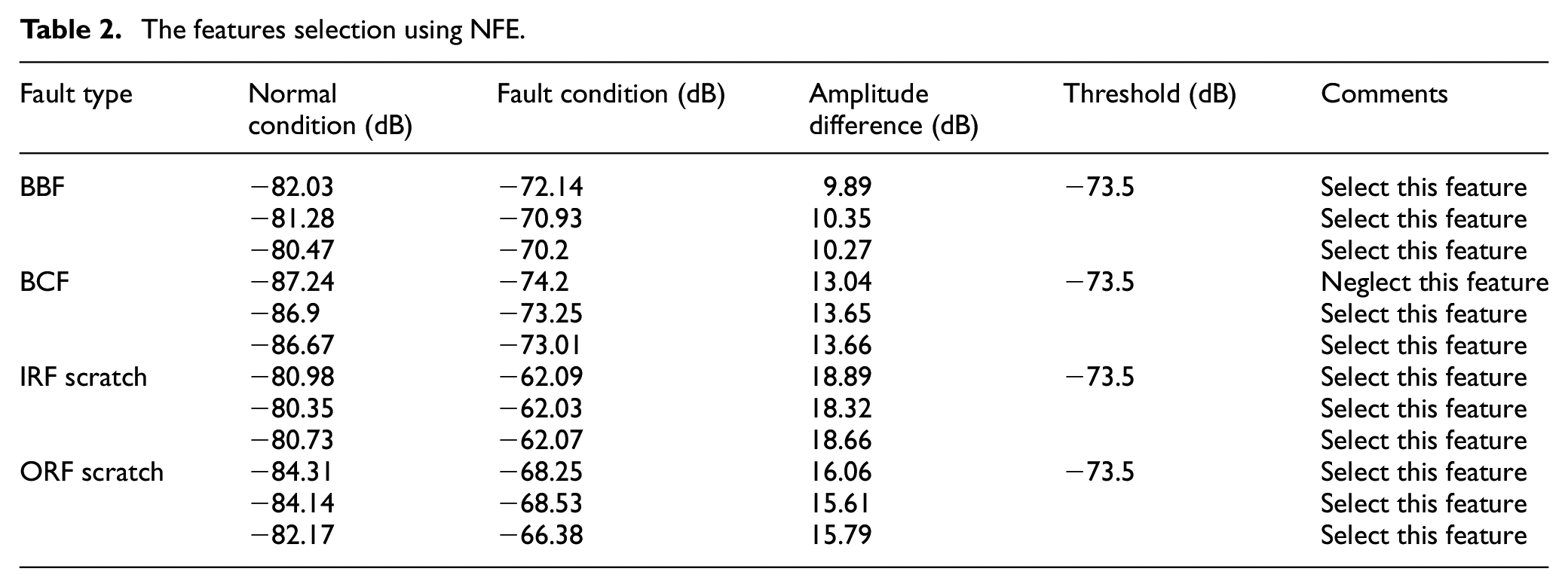
Figure 7 to Figure 10 show the IPS plots. In Figure 7(a) and (b), the amplitude difference of 10 dB has been observed by comparing features (

The IPS of the bearing for (a) normal case and (b) ball fault.

The IPS of the bearing for (a) normal case and (b) cage fault.

The IPS of the bearing for (a) normal case and (b) IR fault.

The IPS of the bearing for (a) normal case and (b) OR fault.
The NFE has been used to extract amplitudes from each feature (
The features selection using NFE.
Performance of fault classification algorithm
The features of Normal Bearing (NB) and four fault classes shown in Table 1 are extracted from the IPS through the NFE algorithm and are utilized by ensemble learning algorithm for the bearing fault classification. The total number of samples is 640 out of which 70% samples are used for training the algorithm and 20% of the samples are used for testing the algorithm and measuring the performance. The total number of features for classification is 3 which are defined as A1, A2, A3. Where, A1 is the amplitude at feature
The CatBoost is a decision tree gradient-boosting method. The uniqueness of the CatBoost algorithm is mainly compromised of three main points. Firstly, it reduces target leaking by modifying gradient boosting with an ordered boosting technique. Secondly, the algorithm works efficiently with small datasets. Thirdly, the algorithm can handle a wide range of data and formats. Since its inception, CatBoost has been used in many other areas, including finance and with many different datasets. These include time-series data and other similar kinds of datasets. Each category gets a new binary feature in place of the original variable. Additionally, the algorithm uses random permutations to estimate leaf values while selecting the tree structure in order to avoid overfitting that is common with conventional gradient boosting methods. When dealing with categorical features during model training, the CatBoost method uses efficient modified target-based statistics that handle them properly, which saves a significant amount of computational time. The CatBoost algorithm’s ordered boosting process is another key feature. A prediction model is built by performing multiple boosting steps on all of the training data in conventional GBTs. As a result of this strategy, the model’s predictions change, creating a new kind of target leakage issue. The ordered boosting architecture used by the CatBoost algorithm overcomes the previously mentioned problem.
For a given feature set F = {f1, f2, …, fN} the feature importance of fi (i = 1, 2, …, N) in the trained CatBoost model has been calculated using equations (1) and (2).


where S denotes the different paths to the leaf nodes in the decision tree, c1 and c2 denote the total weight coefficient in the left and right leaves, respectively, and υ1 and υ2 denote the formula value in the left and right leaves, respectively. The block diagram of the Catboost classifier has been shown in Figure 11. The performance of the Catboost classifier has been shown in Table 3.

The block diagram of the CatBoost classifier.
The performance of the CatBoost classifier.

The accuracies of the individual features and the combination of features fed to the Catboost classifier have been shown in Table 3. The confusion matrix for the various combinations of features has been shown in Figure 12. The Catboost achieves a classification accuracy of 100% for the individual as well as with various combinations of features.

The confusion matrix of the CatBoost classifier for various combination of features: (a) Test 1, (b) Test 2, (c) Test 3, (d) Test 4, (e) Test 5, (f) Test 6, and (g) Test 7.
Performance comparison
Comparison of the performance with other machine learning techniques
The classification accuracy of the Catboost classifier has been compared with other well-known machine classifiers using the same dataset and the summary of the results has been shown in Table 4. It has been concluded that the Catboost classifier is giving better accuracy than the Support Vector Machine, Naïve Bayes Classifier, and Gradient Boost Classifier.
The summary of the performance comparison of various algorithms.

Comparison of the performance with other published papers
The comparison with other published papers indicates that the performance of the XGB and CatBoost have been significantly improved. For example, 17 has investigated the minor scratches in the bearing outer surface. They have used the non-intrusive MCA as a data collection, frequency analysis for feature extraction, and several classification algorithms such as SVM, k-NN, NBC, and CNN were used to measure the classification accuracy. However, they could achieve a maximum of 89.26% accuracy. Vakharia et al. 48 have used minimum permutation entropy based best wavelet feature extraction technique for the analysis and classification of bearing faults. They reported a classification accuracy of 97.5% using ANN and SVM techniques. However, vibration analysis was used which is an intrusive method. Recently, Davo et al. 49 have developed the multi-fusion signal processing and mutual information technique on vibration data for the classification of bearing faults. They have reported the comparison of four algorithms and random forest (RF) has shown better classification accuracies. Yuan et al. 50 have used feature ranking and selection method to classify bearing faults through Catboost classifier. They have reported a classification accuracy of 99.17%. A comparison of SVM and CatBoost classifiers was performed by Gareev et al. 51 to diagnose mechanical faults and they conclude that SVM gives lower accuracy (85.3%) while CatBoost gives higher classification accuracy up to 99.3%. Long et al. 52 has used an improved AdaBoost classifier fed with multi-sensors data for motor fault diagnosis and has achieved a classification accuracy of 92.38%. The multi-sensory data collection setup has a high cost and AdaBoost performance was not satisfactory. Zhang et al. 53 have used time-domain vibrational analysis of gearbox. The wavelet packet decomposition was used as a feature extraction method and AdaBoost classifier was used to achieve a classification accuracy of 96.94%. However, the CatBoost used in the present work has shown better accuracy. This improvement in classification accuracy reflects the significance of the proposed novel feature extractor named NFE. The comparison of the proposed work with other published papers has been summarized in Table 5.
The comparison of various algorithms performance using conventional feature extraction techniques and the proposed NFE method.

Conclusions
This paper has developed a novel feature extractor for the classification of various faults in bearings. The derivation of the location of features (
Footnotes
Appendix A
The mathematical model, values of the parameters, and sample calculations for Table 1 are given below:
Appendix B
The threshold (γ) has been calculated using the following procedure. 19
Where:
k is the design parameter. Its value is selected to get appropriate probability of the false detection. The value of k in this paper is selected at 1.98 with probability of wrong detection 2.3%.
Appendix C
learning_rate 0.1
reg_lambda 0.43
(Coefficient at the L2 regularization term of the cost function.)
depth 7min_data_in_leaf 20 (The minimum number of training samples in a leaf. CatBoost does not search for new splits in leaves with samples count less than the specified value).
Acknowledgements
Authors would like to acknowledge the support of the Deputy for Research and Innovation- Ministry of Education, Kingdom of Saudi Arabia for funding this research through a grant code (NU/IFC/ENT/01/011) under the institutional Funding Committee at Najran University, Kingdom of Saudi Arabia.
Handling Editor: Chenhui Liang
Author contributions
M.I has performed experiments, data analysis, visualization, and paper writing. M.I, A.S.A, A.G have performed project and resource management. K.S.Q, A.A have contributed in algorithm development. A.G, S.R, S.A, F.S.A, F.A, S.M.G, H.A have performed editing, resource management, and data visualization. M.K.A, O.A has performed editing and re-writing of the paper.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Ministry of Education, Saudi Arabia through a grant (NU/IFC/ENT/01/011) under the institutional funding committee of the Najran University Saudi Arabia.