
Abstract
While the extant research has provided a recipe for researchers to undertake thematic analysis (TA) in a theoretically and methodologically sound way, there has not yet been sufficient research to map out TA in the age of generative artificial intelligence (Gen AI). Building on and refining my 2020 article Applying thematic analysis to education: A hybrid approach to interpreting data in practitioner research published in International Journal of Qualitative Methods, which provides an example of thorough, end-to-end manual TA in a practitioner inquiry, this paper presents a follow-up example of how human-ChatGPT can work side by side in undertaking a non-positivist, Big Q reflexive TA. Particular attention is given to how ChatGPT can expedite data transcription, code generation, theme development, interpretation and proofreading throughout the research process, while enabling human researchers to articulate their reflexivity, mitigate algorithmic bias, produce nuanced interpretations and uphold research ethics. Following the six phases of reflexive TA outlined by Braun and Clarke, this paper opens up possibilities for AI-assisted TA research and invites reflection on what constitutes ‘good TA’ practices in working together with nonhuman entities in qualitative inquiry.
Introduction
Thematic analysis (TA), despite its variations in different epistemological and ontological assumptions, theoretical underpinnings, coding focus and practices (Boyatzis, 1998; Braun & Clarke, 2006; Guest et al., 2011), has emerged as a foundational data analysis method in qualitative research. Through its theoretical freedom, TA offers an accessible and highly flexible approach that can be tailored to the needs of diverse disciplines, including psychology (Terry et al., 2017), healthcare (Sezgin et al., 2019), sport (Schinke et al., 2013), and education (Xu, 2021), providing ‘a rich and detailed, yet complex, account of data’ (Braun & Clarke, 2006, p. 78). As one of the most widely used qualitative data analysis approach, TA has generated numerous, varied and ongoing discussions concerning its coding and theme development processes (Tuckett, 2005; Xu & Zammit, 2020), rigor and trustworthiness (Fereday & Muir-Cochrane, 2006; Nowell et al., 2017), researchers’ reflexivity, positionality and ethical considerations (Braun & Clarke, 2019, 2021b; Strunel & Cordoba, 2025). While the extant research has provided a ‘craft skill’ (Potter, 1997, p. 189) and a recipe for researchers to undertake TA in a theoretically and methodologically sound way, there has not yet been sufficient research to map out TA in the age of generative artificial intelligence (Gen AI), particularly with the advent of disruptive platforms such as ChatGPT, DeepSeek and Copilot.
Built on large language models (LLMs) – a type of AI model trained to understand and generate human language, Gen AI refers more broadly to AI tools capable of processing and analysing large volumes of linguistic data to carry out tasks such as translating and (re)coding data, generating and comparing themes, producing coherent analytical reports, as well as generating images and video (Bokhove & Downey, 2018; Christou, 2023; Nicmanis & Spurrier, 2025). As such, they could be well-suited for time- and language-intensive tasks, and have recently come into the spotlight within qualitative data analysis, including TA. However, a review of the bourgeoning literature reveals three areas that need further consideration. First, the most existing literature describes opportunities, risks and implications of integrating AI into TA (Christou, 2024; Franzke, 2022), develops prompts (inputs) to train AI to produce responses (Morgan, 2023; Naeem et al., 2025), or zeroes in on specific phase(s) of data analysis (Nguyen-Trung, 2025). These studies have opened up possibilities for AI assisted TA and encouraged creativity and wide-range applications. However, there remains a need for more explicit and detailed guidelines on the process, since simply feeding raw data into Gen AI and ‘chatting’ with it does not automatically lead to ‘themes emerging’ (Taylor & Ussher, 2001) or make ‘a good TA’ (Braun & Clarke, 2021b).
Second, much of the work on the integration of AI into TA has compared human-generated themes and AI-generated themes (De Paoli, 2023; Hamilton et al., 2023; Tai et al., 2024), with a tendency to conclude that AI can produce similar results without the labour-intensive process of manual coding. However, AI’s capacity to analyse qualitative data becomes less valid and meaningful in practice if divorced from researchers’ contextual understanding, interpretative agency and reflexivity – an advantage and key defining feature of qualitative research (Luttrell, 2019), while algorithmic bias and errors have also been noted as important limitations to their use in qualitative analysis (Hitch, 2024; Ozuem et al., 2025). As such, we are supposed to be more vigilant about the role of AI as a ‘substitute’ in TA (Schmitt, 2024), and perhaps more appropriately view it as a ‘research assistant’ that augments human interpretation in querying qualitative datasets (Morgan, 2023; Nguyen-Trung, 2025). This point is anchored in posthumanist perspectives, which emphasise the inseparability and interconnectedness of human and nonhuman entities in social science inquiry (Jackson, 2013), but it still needs to be further unpacked in the full workflow to see how researchers and Gen AI interact to engage with TA deliberately, of whatever variety.
Third, and most importantly, TA is not a singular and homogenous method; instead, it is ‘a spectrum of methods’ (Braun & Clarke, 2021a, p. (1), encompassing different varieties of and procedures for doing TA (details will be discussed later). However, substantial methodological incongruence has been observed in research, reporting and peer review processes (Clarke et al., 2024), including the presence of a quantitative mindset and the tendency to universalise the assumptions, expectations, norms, and values of TA – a pattern that is also evident in recent AI-driven TA studies (Naeem et al., 2025; Wachinger et al., 2024). It is therefore important for us to understand the diverse conventions and practices of varying forms of TA, including their respective philosophical underpinnings and assumptions, and to develop corresponding (AI-driven) data analysis practices to avoid universalising TA approaches and to strengthen methodological integrity, congruence and coherence in TA articles.
Drawing upon Braun and Clarke’s (2022) six phases of reflexive TA, this article aims to provide a vivid worked example of these phases of data analysis when researching the learning experiences of disadvantaged students in an Australian primary classroom, using ChatGPT assisted TA, so as to enhance both the understanding of reflexive TA and the enactment of reflexive TA in the age of Gen AI. Distinct from my previous article Applying thematic analysis to education: A hybrid approach to interpreting data in practitioner research published in International Journal of Qualitative Methods in 2020 (Xu & Zammit, 2020), which details an example of thorough, end-to-end manual TA in a practitioner inquiry, this paper builds on, expands and refines that work by presenting human-AI interacted TA in a reflexive way, with ethical considerations and reflective exercises integrated throughout each phase. The phases, or ‘formula’ outlined, are flexible enough to accommodate different guiding theories, data orientations, coding practices and theme development approaches, and can scaffold reflexive TA researchers and practitioners who are not the proverbial ducks-to-water across wide-range of fields.
Reflexive Thematic Analysis and Its Pre-AI Practices
Thematic analysis refers to a method for identifying and interpreting recurring meanings across qualitative datasets (Vaismoradi et al., 2013). In spite of a shared name, conceptualisations, values and approaches to TA can vary. A key distinction, as introduced by Braun and Clarke (2022), is between ‘small q’ and ‘Big Q’ TA. That is, ‘small q’ TA is situated within a positivism paradigm, where qualitative data collection tools and analysis are applied within a quantitative paradigm that assumes reality can be measured. ‘Big Q’ TA, however, draws on non-positivist values, uses qualitative techniques within a qualitative paradigm and emphasises subjective, situated and contextualised interpretation in data analysis (Braun & Clarke, 2021b; Nicmanis & Spurrier, 2025). In other words, positivist coding reliability TA approaches, such as those proposed by Boyatzis (1998) and Guest et al. (2011), aligns with ‘small q’, while the reflexive version of TA – unmooring any positivist-empiricist assumptions – as developed by Braun and Clarke (2019), fits within the Big Q approach. As a researcher working with minority populations, I resonate more with the ‘Big Q’ approach since my insider positionality, reflexivity and interpretations can enable sensitivity to the context, capture the richness and complexity of data, and amplify the voices and stories of the unheard (Braun & Clarke, 2022).
In their seminal work, Braun and Clarke (2022) developed a six-phase ‘baking recipe’ in working with and making sense of data. • Phase 1: Familiarising yourself with the dataset – immersing ourselves in the dataset through repeated reading and noting preliminary ideas and insight. • Phase 2: Coding – coding the entire dataset at the semantic level (explicit, surface, or overt) and latent level (implicit, underlying, or hidden), and systematically labelling, collating and compiling relevant data segments. • Phase 3: Generating initial themes – clustering codes to develop candidate themes that capture shared patterns of meanings and might ‘answer’ the research question across the dataset. • Phase 4: Developing and reviewing themes – refining candidate themes to ensure they capture important patterns of shared meaning across the dataset. • Phase 5: Refining, defining and naming themes – fine-tuning each theme around a core concept, outlining its story, and assign an informative name. • Phase 6: Writing up – weaving together the analytic narrative and data extracts to produce a coherent report that addressed the research question, while refining and editing all sections.
Of note, the choice of the term ‘phase’, instead of ‘step’, is indicative of a non-linear, blended and recursive analytic process (Braun & Clarke, 2021b), which often requires ‘a continual bending back on oneself – questioning and querying the assumptions we are making in interpreting and coding the data’ (Braun & Clarke, 2019, p. 594). Furthermore, the flexibility of TA allows for an inductive/deductive continuum in coding in Phase 3. Induction in TA involves a ‘bottom-up’, data-driven coding, such as ‘in vivo coding’, which uses participants own terms (Saldana, 2016). In contrast, deduction is ‘top-down’, applying existing theoretical lenses to the data to generate new insights (Willcox et al., 2019), such as Foucault’s notion of ethics as a theoretical framework through which data are coded and interpreted. Thus, Bruan and Clarke’s version of TA can combine elements of both approaches – analysis is grounded in the data while also being informed by existing theoretical positions or explanatory theories, so as to strengthen analytic and interpretative work.
Although the TA approach discussed above is often described as Big Q TA or organic TA, Braun and Clarke have reframed it as reflexive TA since 2018 onwards, not only to ‘demarcate it as a particular TA’, but also to ‘emphasise the importance of the researcher’s subjectivity as analytic resource, and their reflexive engagement with theory, data and interpretation’ (Braun & Clarke, 2021b, p. 3). For them, coding is an inherently subjective process; researcher subjectivity is a flaw or a problem that threatens objectivity, but a key aspect of qualitative sensibility and the primary tool in knowledge production and for doing good reflexive TA (Braun & Clarke, 2021a, 2022). As such, quality reflexive TA is less about sample size, coding reliability, frequency counts, data saturation, member checking and/or adhering to ‘correct’ procedures (Clarke et al., 2024), but more about turning the lens back onto ourself, developing awareness of our own situatedness, and allowing this positionality to shape and inform the research.
Nevertheless, the coding and theme development processes, as theorised by Braun and Clarke (2022), were conceived and introduced prior to the release or widespread use of LLMs and AI in qualitative research and therefore, I refer to them as pre-AI reflexive TA practices. In the age of Gen AI, however, the promise of technological tools cannot automatically unveil what is present in the data or the unspoken meaning behind it, since themes do not simply ‘reside’ in the data nor ‘emerge’ miraculously if looking hard enough or feeding the raw data into AI with little intervention (Taylor & Ussher, 2001). While a few qualitative researchers have started to explore its use in their work, our understanding of how to ‘immerse in the data, read, reflect, question, imagine, wonder, write, retreat and return’ with the aid of AI (Braun & Clarke, 2021b, p. 5), remains in its infancy. Thus, how reflexive TA practices can be enacted, refined and further expanded through an open, exploratory, and iterative human-machine dialogic process, need to be further discussed and theorised in the new times.
ChatGPT in TA Analysis: A Critique of Ethics and Methodological Incongruence
In this article, I use ChatGPT-5, as one of the most recent and widely used LLMs, to undertake AI-assisted TA analysis, because of its ease of use, broad global reach among AI tools, and substantial attention in the qualitative research literature (Goyanes et al., 2025; Nguyen-Trung, 2025). ChatGPT specifically is a generative pre-trained transformer (GPT) capable of producing nuanced, human-like responses to text-based prompts, based on statistics patterns in the training data, including news articles, books and websites (Hamilton et al., 2023). Through some prompt engineering techniques, it can converse unstructured data into organised texts, translate texts, propose potential codes, identify patterns and produce short summaries to assist researchers in TA in practice (Christou, 2024; Turobov et al., 2024).
However, the opacity of ChatGPT inputs and internal processes involving datasets and algorithms, termed as the ‘black box’, has raised ethical concerns (Naeem et al., 2025). The lack of transparency and accountability has led ChatGPT to fabricate false information (Gravel et al., 2023), misread experiences (Urban et al., 2025) and produce highly partial analyses (Rozado, 2023), potentially undermining integrity, equity and validity in research practices. For example, ChatGPT, as mainly trained on Western and English-language data, often reflects the ideologies, assumptions and cultural norms of WEIRD (Western, Educated, Industralised, Rich and Democratic) societies (Nicmanis & Spurrier, 2025). This algorithmic control and programmatically encoded worldviews can thus ‘reinforce dominant cultural narratives and contribute to the homogenisation of knowledge and new forms of digital colonialism’, as noted by Darvin (2025, p. 10).
Also, the use of ChatGPT in TA presents a conflict of value when qualitative researchers plan to use it within the Big Q brand, yielding methodological incongruence at times. For example, I came across claims like: ‘systematic thematic analysis also comprises six steps’; ‘the paper provides guidelines on how to develop a toolkit for AI to reduce bias and improve the reliability of qualitative research’ (Naeem et al., 2025, p. 2). While the authors modified Braun and Clarke’s six phases of TA, their positivist language (e.g. ‘steps’), expectations and practices (e.g. ‘reduce bias’ and ‘improve the reliability’) are antithetical to the Big Q orientation and at odds with its reflexive, interpretive, and subjectivity-oriented values. In another methodological article, Wachinger et al. (2024, p. 961) similarly noted that ChatGPT could ‘serve as another resource in processes of triangulation or thematic synthesis, or in calculations of intercoder reliability’. While this may hold true in some varieties of TA, it is incompatible with reflexive TA, as triangulation, multiple coders, intercoder reliability and other forms of calculations risk universalising norms and practices associated with quantitative or specific TA traditions (Clarke et al., 2024). These two examples illustrate how the integration of AI tools, such as ChatGPT, to reflexive TA can reproduce positivist logics under the guise of innovation and lead to methodological incongruence, suggesting that further concrete efforts need to be undertaken to use ChatGPT in a manner align with Big Q values (Nicmanis & Spurrier, 2025).
Indeed, the possibility of ChatGPT generating probabilistic representations and reflecting algorithmic bias from the existing data it is trained on can constrain the discovery of less frequent or unexpected insights, which is a substantial limitation for the deep, nuanced, and non-obvious themes required in Big-Q qualitative inquiry (Braun & Clarke, 2022). Within reflexive TA, researchers’ continuous, critical self-awareness is essential to their own positionality, as well as to the assumptions embedded within AI technologies in the knowledge production process, as Ozuem et al. (2025, p. 7) put it, ‘there is a risk that AI-generated outputs may overshadow the nuanced insights that emerge from direct, reflexive engagement with participants’ narratives’. In this article, therefore, I am to provide detailed and accessible guidelines on process, exploring how codes, themes, meanings and interpretations emerge and are shaped by the relations of people, machine, discourse, data, and algorithms and how reflexivity can be exercised to manage the new complexities of the Gen AI age, thereby building analytical depth of our analyses.
A Worked Example of Practitioner Inquiry: Engaging Disadvantaged Students in an Australian CFL Classroom
In order to contextualise the data I work with, this section presents a blurb outlining a practitioner inquiry I undertook in Sydney, Australia. Between 2017 and 2019, I worked as a pre-service Chinese as a Foreign Language (CFL) teacher in a primary school in the Greater Western Sydney (GWS) region, while researching my own pedagogic practices and student engagement in classrooms (Xu, 2021). Cultural and linguistic diversity and low socio-economic status (SES) are two defining characteristics of the school’s catchment area, with 67% of students at the school were from non-English speaking backgrounds (Australian Bureau of Statistics, 2016). As a teacher-researcher, I conducted focus groups with students, semi-structured interviews with classroom teachers, and also journal entries documented my observations and reflections after each class. My positionality and reflexivity, as a Chinese woman, international student, non-English native speaker, pre-service teacher in Australian society and school, have been exercised in mundane, and sometimes not very engaging memo writing (Saldana, 2011), and later in providing a nuanced account of the process and complexities in reflexive TA.
For these qualitative data, I adopted a hybrid approach to interpreting, in which codes were driven by both the data per se as well as existing theories, allowing the analysis to be grounded in participants’ voices while exploring evidence for themes in universalistic explanatory theories (Braun & Clarke, 2021b). I have detailed my approach to TA in an earlier article (Xu & Zammit, 2020), which was conducted manually, without the assistance of ChatGPT in the pre-AI era. The theoretical frameworks I drew upon included Bernstein’s (2000) classification and framing, as well as Fair Go Project’s (FGP) engagement framework (Fair Go Team, 2006). Bernstein’s theorisation, including stronger classification (i.e., clear boundaries between subjects), weaker classification (i.e., blurred boundaries), stronger framing (i.e., teacher-centered pedagogy) and weaker framing (i.e., student-centered pedagogy), addresses the ‘pedagogical’ aspect of my research questions. The FGP’s framework, which examines cognitive (thinking hard), affective (feeling good) and operative (involving in activities and following instructions) engagements, was applied to interpret students’ learning experiences.
In this article, I revisit the dataset with the assistance of ChatGPT-5, which I had spent nearly a year and a half transcribing, immersing in, (re-)reading, questioning, writing about, and returning in 2018-2019. The analysis presents a revised hybrid approach to reflexive TA in the age of Gen AI and throws light on how reflexivity – an essential component of doing reflexive TA – can be enacted in human-machine interactions, reconciling reflexive TA and AI tensions within the Big Q spectrum.
ChatGPT-5 Assisted TA: A Human-AI Interactions Approach to Interpreting Data
An Overview of a Reflexive and Ethical Framework for Doing Reflexive TA With ChatGPT

Phase 1: Familiarisation
Familiarisation involves the practices of ‘developing deep and intimate knowledge of your dataset’ and ‘critical engage [ment] with the information as data’, meaning that both text-based and visual data items are (re-)read through a balance of closeness (immersion) and distance (critical engagement) (Braun & Clarke, 2022, p. 42). Methodological incongruities can (unknowingly) arise when raw data are simply fed into ChatGPT, a practice that may be applicable to small q qualitative – such as some of those evidenced practices reported in AI-assisted data analysis (Hamilton et al., 2023; Morgan, 2023), which could be judged as flawed (Clarke et al., 2024). In this phase, therefore, I begin to describe my approach to address this concern and present my solution.
As a teacher-researcher who taught the lessons, conducted interviews and focus groups, and wrote my own journal entries, I came to the analysis with some prior knowledge and was ‘familiar with the depth and breadth of the content’ (Braun & Clarke, 2006, p. 87). However, since the data were collected between 2017 and 2019, quite some time had passed. To re-familiarise myself, I engaged in repeated readings of the interview transcripts and journal entries to recall the teaching, make sense of my student experiences, and enter into a dialogue with the data, while jotting down hand-written or/and typed familiarisation notes inhe margins of the hard copies.
Since ChatGPT also needed to familiarise with the research, I provided the background information, including prompts detailing the research aim, objectives, research questions, the type and number of the research sites and students, as well as the nature of the data. In addition, I also explained the theoretical (i.e. FGP’s engagement framework and Bernstein’s classification and framing) and methodological (i.e. reflexive TA) underpinnings of the research, as these could shape how ChatGPT works with the data. To ensure ChatGPT was fully trained to understand the background information, it was asked to summarise the research and reflexive TA process. When discrepancies or inappropriate responses arose, additional prompts were used to further familiarise ChatGPT with the research. These practices allowed ChatGPT to develop an intimacy of understanding similar to that of the researcher, training it to better assist in selecting the most relevant quotes, interpreting, or critiquing the data in the subsequent phases.
As the ethical concerns may arise with the use of ChatGPT, particularly the issue of data privacy (Turobov et al., 2024), I removed real names of the research site and participants, replacing them with pseudonyms to safeguard the anonymity before feeding raw data into ChatGPT. I had transcribed the audio recordings verbatim myself – a process that also served as a form of familiarisation (Tuckett, 2005) – and the transcripts had already been cleaned manually long ago. However, engaging ChatGPT in proofreading and correcting tasks through prompts such as ‘Please review this transcript for accuracy and highlight any potential errors’ could (further) help identify mishearing, transcription errors, or missing details, particularly for non-native speakers of the language. Given the summarising and proofreading work that ChatGPT performed, such as adjustments of tenses, insertion of the preposition ‘the’, and standardisation of phrasing, I do not agree with Hitch’s (2024, p. 598) argument that it plays only ‘a minor role’ in Phase 1, as its substantially enhanced the readability and consistency of the text-based data, supporting both the researcher and ChatGPT itself in a more accurate familiarisation with the data.
Phase 2: Coding
For Braun and Clarke (2022), codes are the smallest units of analysis. They can be summative and descriptive, or interpretative and conceptual, capturing specific and particular meanings within the dataset that are relevant to the research questions. In reflexive TA, coding is an organic and evolving process of meaning-making, in which codes can be refined, expanded and re-labeled as our understanding deepens through multiple rounds. As Braun et al. (2023, pp. 29–30) observe, ‘the boundaries of a code can be redrawn, the coding label tweaked, two or more codes can be collapsed together, a code can be split into several more focused codes’.
In Phase 2, I initially approached my worked example through ‘deductive’ and ‘theory-driven’ coding, but without a codebook, in order to keep with an overall Big Q qualitative orientation (Clarke et al., 2024). I uploaded my interview transcripts and journal entries and crafted prompts such as ‘This is my … [insert nature of the data], please code it deductively using … [insert the theoretical framework(s)] to answer … [insert the research question(s)].’ For an 84-word transcript, ChatGPT divided it into three segments (Figure 1 shows one of them) with a summary table (Figure 2) within a second. A snapshot of a deductively coded extract generated by ChatGPT A summary of codes developed by ChatGPT

In Figure 2, a teacher-directed pedagogy (e.g., demonstration, reading after the teacher, and pronunciation correction) was initially coded as ‘F-’ (i.e., student-centered pedagogy), which appears to be an error. I prompted and questioned ChatGPT, but its response was focused on ‘classification’ (i.e., curriculum) rather than ‘framing’ (i.e., pedagogy). Moving back and forth between the data as a situated and disciplinarily trained researcher, I revised the code from ‘F-’ to ‘F+’. In other words, as a reflexive TA researcher, I did not automatically assume that ChatGPT’s analysis was better than mine, or could replace researcher reflexivity. Instead, I used it as a tool to facilitate the coding process, while continuously questioning, validating, wrangling, challenging, revising and documenting the ChatGPT-generated codes to ensure accuracy, auditability and transparency of the coding process (Christou, 2024).
After generating theory-driven codes concerning pedagogic practices, I proceeded to create data-driven codes to better interpret students’ CFL learning experiences and identity construction through their own voices. To illustrate this run at coding data, I used a focus group transcript involving students as an example. Initially, I uploaded the transcript into ChatGPT with the prompt ‘This is my … [insert nature of the data]. Please code it inductively to capture … [insert blocks of analysis] and to answer … [insert the research question(s)].’ ChatGPT produced a lengthy inductive coding table, however, these codes were mostly at a semantic and explicit level, capturing the surface meanings of the data, and they failed to establish connections between students’ learning experiences and their identities. To explore their connections, I input a follow-up prompt, ‘Please create a matrix mapping each student’s quote to categories of experiences and identities’, and then ChatGPT generated a matrix (see Figure 3), which helped visualise some patterns. An inductive coding matrix generated by ChatGPT
After gaining a general understanding of the data through ChatGPT assistance, I revisited the raw manuscript for multiple rounds of close reading. This enabled the identification some potentially relevant codes that ChatGPT missed. A major limitation of ChatGPT was its lack of access to students’ socio-cultural and economic backgrounds, which is critical for more ‘reflexive’ interpretations. For example, one student, Ally, is Maltese-Australian, from a single-parent household with a history of family violence and low academic achievement. These ‘insider’ knowledge completely lost in the ChatGPT-generated codes. Her quotes, such as ‘In every job now… Australia has people from all over the world, so you come here, you get the job, you mainly speak Chinese to someone because we speak good English, so it could help you in your future’ reveal discourses around international travel and future career opportunities, implying middle- or upper-class and high-achieving students’ aspirations (Lanvers, 2017), which do not algin with Ally’s actual reality. This suggests the presence of ‘imagined identities’ and ‘imagined futures’ in the CFL classroom (Xu & Knijnik, 2021), which was lost in the ChatGPT-assisted coding. In other words, ChatGPT often stays close to participants’ language and capture meanings at the surface level of the data, whereas the researcher’s reflexivity, insight into participants and phenomenon, and articulation around enable the movement of codes to more latent and conceptual level of meaning.
Within the Big Q framework, ChatGPT-assisted TA may raise concerns about methodological incongruence, as the coding process can appear more ‘truth seeking’ than ‘meaning-making’ when the researcher’s subjectivity wanes. In my approach to reflexive TA, however, I concurred with Nguyen-Trung (2025) in viewing ChatGPT as a ‘research assistant’ that augmented my critical engagement with qualitative data, but never replaced my reflexivity. The purpose of this ‘collaboration’ was to expedite the coding process and gain more insights (Braun & Clarke, 2022), rather than reach coder agreement or enhance reliability (Clarke et al., 2024). Of note, reflexivity itself can also be understood as an ethical practice (Strunel & Cordoba, 2025), as my noticing of errors, discrepancies, or nuances, and the consequent revision of codes, also helped ensure the auditability of the coding process, which was documented for transparency.
Phase 3: Generating Initial Themes
In reflexive TA, a theme captures ‘the patterning of meaning across the dataset’ (Braun & Clarke, 2022, p. 76) and represents ‘something important about the data in relation to the research question’ (Braun & Clarke, 2006, p. 89). Phase 3 is ‘generative’ in nature as it involves an analytic process of moving from smaller meaning units (i.e., codes) to the development of initial themes (i.e., larger meaning patterns). In this phase, I initially uploaded all the deductive, theory-driven codes with data extracts and asked ChatGPT to conflate pedagogic practices with students’ learning experiences, with prompts such as ‘These are deductive codes and data extracts. Please cluster them together, explore meaning patterns and develop candidate themes’. For instance, the code of ‘affective engagement’ in focus groups and classroom teacher’s semi-structured interviews was attached to the codes of ‘C+’ and ‘F-’ in my journal entries, with illustrative data. As a reflexive researcher, I revisited the raw data iteratively to recall my insider experiences in the classroom, reflect on how they were coded, and consider if they fit together well. It was found that a stronger curriculum boundary evoked students’ curiosity and a student-centered pedagogy (F-) allowed them to navigate learning through trial and error. Building on these insights developed in the recursive process, I further prompted ChatGPT to draw a potential thematic map, and Figure 4 presents an example of its visualisation. ChatGPT’s visulisation of an initial thematic map conflating classroom practice with student dis/engagement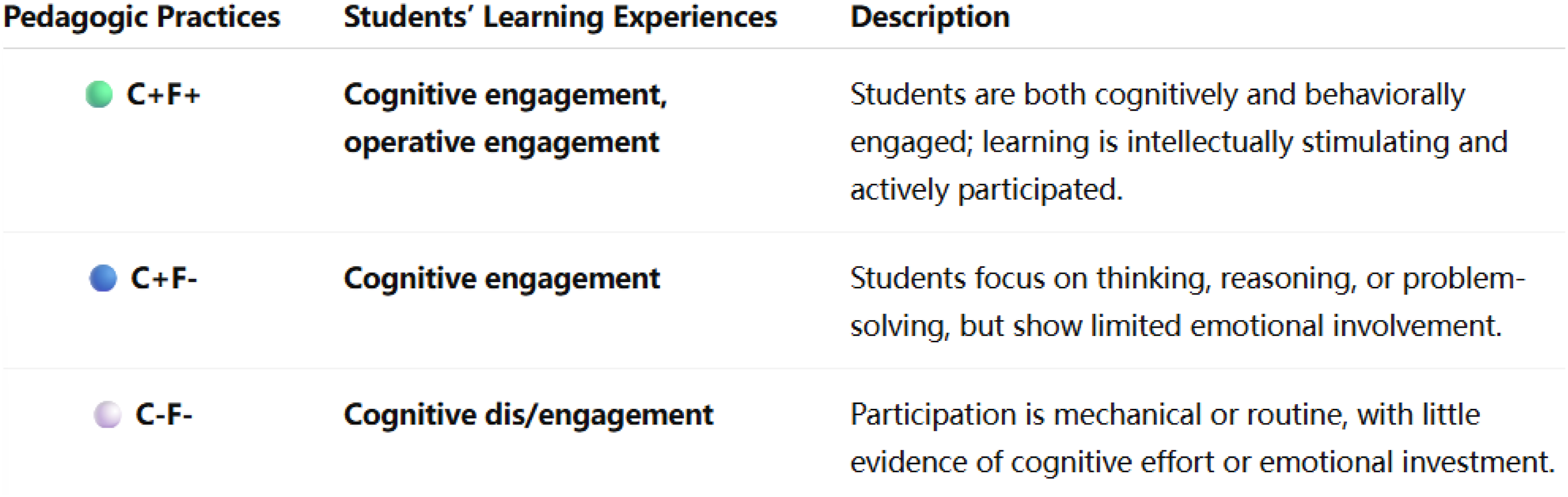
In addition, inductive codes generated in Phase 2 also contributed to the formation of another potential thematic maps with regard to learner identities (Figure 5), with prompts such as ‘These are inductive codes and data extracts. Please cluster them together, explore meaning patterns and develop candidate themes’. An example of an initial thematic map associated with learner identities
As noted by Braun and Clarke (2006), while some codes formed the building blocks of themes, some were discarded in Phase 3. I also observed a set of codes that seemed relevant but could not yet be clustered together to tell a coherent story about a pattern of meaning. As such, I created a ‘miscellaneous’ theme to house these codes temporarily (Braun & Clarke, 2022), which allowed me to revisit them as the analysis developed. At this point, my personal, functional and disciplinary reflexivity was the most important companion in keeping a record of unused codes and themes, considering a few different possible mappings, and attending to the nuances and broader context (Braun et al., 2023), as ChatGPT was not able to account for or make decisions about.
Phase 4: Developing and Reviewing Themes
Phase 4 extends and validates the tentative themes developed in Phase 3 through a recursive, reflexive and thoughtful engagement with the coded data extracts and the entire data set. This phase may involve some revising, refining, clarifying, expanding or narrowing code-clusters, or at times reworking codes generated in Phase 2 (Braun & Clarke, 2022).
In Phase 4, I prepared myself to discard the use of ChatGPT, as the reviewing work at this stage is highly reflexive in nature. It requires a subjective, situated, self-aware and critical researcher who moves back and forth between the raw data, codes, and candidate themes in a process of continual questioning and meaning-making. ChatGPT, however, is not able to undertake such recursive and reflexive tasks, as it lacks sensitivity to context, participants and theoretical nuance.
When performing this phase, I recognised that some codes previously placed under the ‘miscellaneous’ theme were, in fact, related to the candidate themes, and captured important aspects of the research questions (Braun & Clarke, 2006). For instance, some students remarked, ‘If I go to China, I’ll buy No. 4 houses’ and ‘Children are disciplined there. I’ll send my kids to Chinese schools’ in focus groups. These data extracts had been omitted by ChatGPT in earlier phases (Phase 2 and Phase 3), possibly because they appeared semantically irrelevant to either learning experiences or the formation of learning identities. This may also reflect the ‘black box’ nature of AI tools, whose internal processes involving datasets and algorithms remain opaque (Darvin, 2025). However, through re-reading, re-contrasting, and re-thinking these data, I found that such comments were mostly made by girls, revealing low SES girls’ projections of their future selves as entrepreneurial house investors and responsibilised mothers through CFL learning (Xu & Stahl, 2021). These discourses indicated that CFL shapes their aspirations and girlhood, and that the intersection of gender, class and ethnic minority status is something that ChatGPT cannot reflexively and meaningful integrate into analysis. As such, I re-coded the data and slightly expanded the theme relating to ‘identities’.
A Revised Thematic Map Conflating Classroom Practice With Student Dis/Engagement

Note: Boldface indicates the revised elements in this thematic map
Phase 5: Refining, Defining and Naming Themes
By ‘defining’ and ‘naming’ themes in Phase 5, Braun and Clarke (2022) mean writing an abstract with a few sentences for each theme and assigning it a good theme name. As part of this refinement process, the thematic map, including the theme and any sub-themes, can be organised into a coherent and cohesive narrative. As such, I provided ChatGPT with ‘themes-within-a-theme’ and trained it to summarise ‘essence’ and ‘scope’ of each them, using prompts such as ‘This is one of my themes … [insert the theme]. Please write a brief definition in a few sentences, explaining its key take-away point.’
An Example of ChatGPT-Generated Theme Definition and Naming Choices

Phase 6: Writing up
With all the worked-out themes and their corresponding data extracts, the reflexive TA write-up, whether in the form of journal articles, research reports or dissertations, is to re-organise them into a story – a story that engages readers and convinces them of the validity of the analytic claims and arguments (Braun & Clarke, 2022). My insider-outsider positionings as an international student, a Chinese woman, a non-English native speaker, and a pre-service teacher in an Australian school, was acknowledged and articulated in my production of knowledge, bringing both advantages and disadvantages. Over the past five years, I published a monograph and fifteen journal articles under this project and encountered a handful of reviewers with a quantitative mindset or a hostility toward non-positivist qualitative research. As a single coder, a non-positivist researcher uninterested in code frequency counts or data saturation, and an author who referenced literature in the ‘Findings’ section, my work was critiqued as problematic in from time to time. These experiences strongly resonated with what Clarke et al. (2024) describe as methodologically incongruous feedback in peer review’. My strategies evolved over time, from initially acquiescing and yielding to reviewers’ ‘confidently wrong’ comments, to spending time crafting ‘lengthy responses’ and ‘blunt rebuttals’ (ibid, p. 17), to withdrawing manuscripts. Now, however, I have learned to be preemptive – explaining why I use reflexive TA, what it offers and allows me to do in the methodology section (Braun & Clarke, 2022), though such explanations d not always work.
In ChatGPT-assisted reflexive TA, issues of methodological incongruence are perpetuated and even complicated by the joining of a non-human coder, proofreader, and in some cases, co-author. It is therefore important to clarify how the data are analysed, how ChatGPT is used for manuscript preparation and proofreading in the methodology and acknowledgements sections, to ensure ethical and transparent use of ChatGPT for research and academic publishing purposes (Casal & Kessler, 2023).
AI-Assisted Reflexive Thematic Analysis: Methodological Incongruence, Reflexivity and Ethics in the Production of Knowledge
This paper explores the way in which ChatGPT can be integrated into the six phases of reflexive TA within Braun and Clarke’s (2022) brand. The worked example provided in this study contributes to the extant literature in three ways. First, this paper represents a shift from prior AI-assisted TA research that has adopted a small q orientation (De Paoli, 2023; Hamilton et al., 2023) or a medium Q approach that naturally mixes small and Big Q traditions (Naeem et al., 2025; Nguyen-Trung, 2025), to a AI-assisted reflexive TA grounded by Big Q values. By paying close attention to methodological incongruence that might arise amongst researchers who chose to use AI in reflexive TA, particularly the waning of researchers’ subjectivity, I delineate what AI can – and at times cannot – do for us, and how it can augment or complement our analysis. By illustrating my reflexive engagement with AI, my aim is to offer some ‘starting points’ for how researchers and AI might ‘dance’ together in the iterative analytical process, while being mindful and critical aware of some of its caveats. For example, the algorithms available to AI are not currently capable of engaging in the contextual interpretation, cultural sense-making, or nuanced reading of social dynamics that reflexive TA calls for (Braun et al., 2023). In other words, humans remain the only ones able to interpret the latent meanings embedded in complex, substantial datasets and to develop codes and themes that represent participants and phenomena. As such, I do not agree with Wachinger et al.’s (2024, p. 6) observation that ‘ChatGPT was able to produce thematic insights that to a considerable degree aligned with or resembled those produced by an experienced human researcher’, as my findings reveal that AI’s coding and theme development is largely summative and descriptive, and frequently overlooks unique or less frequent, yet thematically crucial codes and themes that are central to a non-positivist, Big Q camp informed reflexive TA.
In addressing the biggest concern of applying AI/LLMs under the reflexive TA (Braun & Clarke, 2022), I propose an expanded form of reflexivity in the age of Gen AI – a routine reflection not only on the researcher’s positionality but also on the affordances, limits, and biases of LLMs, and how they collectively shape data transcription, code generation, theme development and interpretation throughout the research process. While AI can expedite the processing and analysis of large volumes of text-based data (Christou, 2024), its use may distance researchers from the situatedness, interpretative depth, sensitivity to contexts and participants that are central to reflexive TA (Braun & Clarke, 2021b), as illustrated in the above worked example. This flaw encourages us to broaden the scope of reflexivity to include both an identification of the population of study (Strunel & Cordoba, 2025), as well as an interrogation of the assumptions, bias and capacity for errors embedded within AI technologies in knowledge production. Without these dual reflexive practices and critical engagement with both data and tool, AI-generated codes, themes and outputs may risk further marginalising voices from non-WEIRD contexts, undermine the credibility, trustworthiness and ethical standards of TA (Ozuem et al., 2025).
My final note concerns the use of AI tools in academic writing and publishing. In Phase 6, I, as a reflexive thematic analyst, emphasise positionality and contextualised understanding in Big Q qualitative research and hence, I refrain from using AI beyond data processing and language proofreading. However, discussions of ethics surrounding LLMs powered AI chatbots in research are far more complex. Although Casal and Kessler’s (2023) empirical study reveals that reviewers were largely unable to distinguish AI-generated from human-written texts, this does not make AI use in writing and publishing is unproblematic. It is well known that AI is susceptible to invent inaccurate or false content, particularly in longer texts. Its use by students also raises concerns about instances cheating, plagiarism and misconduct in assessments (Jarrah et al., 2023; Shen & Chen, 2025) – issues that extends to researchers as well. Therefore, while some journal editors accept AI as an author, I argue that its use should be confined to data processing and editing, with any AI involvement should be disclosed, in keeping with ethical and methodological conventions.
Conclusion
This article has presented a worked example of AI-assisted reflexive, hybrid approach (i.e., inductive and deductive coding) to TA within a practitioner inquiry, and discussed what AI can – and cannot – do with a Big Q orientation. In each phase, I provided a ‘baking recipe’ that illustrate how AI can help expedite the research process, while enabling insight-bringing researchers to articulate their reflexivity and generate richer, more nuanced interpretations of data. The example follows the six phases of reflexive TA outlined by Braun and Clarke (2022), yet extends them for the era of Gen AI, in which AI chatbot and human researchers can work side by side to achieve methodological congruence. While I offered detailed, phase by phase guidance on ‘what to do’ and ‘how to do’, the example is not intended as a prescriptive or a must-be-followed recipe; instead, my aim is to open up possibilities for AI-assisted Big Q TA research and to explore what constitutes ‘good reflexive TA’ practices in partnership with our new AI friend.