
Abstract
Feedback is a critical aspect of improvement. Unfortunately, when there is a lot of feedback from multiple sources, it can be difficult to distill the information into actionable insights. Consider student evaluations of teaching (SETs), which are important sources of feedback for educators. These evaluations can provide instructors with insights into what worked and did not during a semester. A collection of SETs can also be useful to administrators as signals for courses or entire programs. However, on a large scale as in high-enrollment courses or administrative records over several years, the number of SETs can render them difficult to analyze. In this paper, we discuss a novel method for analyzing SETs using natural language processing (NLP) and large language models (LLMs). We demonstrate the method by applying it to a corpus of 5000 SETs from a large public university. We show that the method can extract, embed, cluster, and summarize the SETs to identify the themes they contain. More generally, this work illustrates how to use NLP techniques and LLMs to generate a codebook for SETs. We conclude by discussing the implications of this method for analyzing SETs and other types of student writing in teaching and research settings.
Keywords
Introduction
Text and speech are essential elements of qualitative data used across many research domains (Miles et al., 2014; Pope et al., 2000). These data, which include interviews, transcripts, reports, social media posts, written answers to open-ended response questions, and essays are traditionally analyzed using methods such as qualitative thematic analysis (Terry et al., 2017). However, these approaches often require significant research investments in both time and cost due to third-party software and revisions (Basit, 2003). Moreover, as the data grow, so does the time needed for analysis, making large and existing datasets progressively difficult to manage. Despite these challenges, thematic analysis remains prevalent in qualitative research because it can extract detailed insights and themes (Miles et al., 2014; Pope et al., 2000; Terry et al., 2017).
During qualitative thematic analysis, researchers scrutinize data to extract or identify salient themes and concepts based on codes they have identified through initial rounds of coding. Under the steps outlined by Braun and Clarke (2006) for thematic analysis, code generation happens in phases one and two of their six-phase process whereas theme identification and refinement happens in phases three through five. In the Braun and Clarke framing, codes denote features of the data that are notable to the researcher. Thus, the thematic analysis process involves identifying codes and then themes based on researchers’ choices, such as theoretical stances and employing an inductive or deductive coding approach (Terry et al., 2017). Inductive coding, a “bottom-up” approach, derives codes (and resulting themes) from the data, allowing data to guide the identification of meaning and interpretation. Conversely, deductive coding leverages existing theoretical concepts or frameworks as a lens to interpret the data – a “top-down” approach. Inductive and deductive processes differ in the extent to which the data and existing theory are informing the researcher’s interpretation of the data and consequent contents of the codebook (i.e., collection of generated codes and their associated definitions). Nevertheless, both processes are subject to researcher subjectivity and positional bias, leading to the common suggestion that multiple researchers should analyze the same data (Miles et al., 2014; Terry et al., 2017).
Qualitative data hold substantial research potential given the density of the information they contain but entail costs and time-consuming processes (Miles et al., 2014). Fortunately, recent advancements in natural language processing (NLP), a subset of machine learning, integrate large language models (LLMs) to automate language understanding and synthesis (Crowston et al., 2010; Katz, Shakir, et al., 2023). These tools offer significant potential for reducing the cost, while enhancing the accuracy and efficiency of qualitative thematic analysis (Bhaduri, 2017; Garman et al., 2021). Current NLP applications leverage LLMs to analyze sentiment, synthesize text, design feedback systems, develop tutoring systems for computer education, and model stances in student essays (Chiu et al., 2023; Ganesh et al., 2022; Kastrati et al., 2021; Mathew et al., 2021; Persing & Ng, 2016; Shaik et al., 2022; Somers et al., 2021; Sunar & Khalid, 2024). These applications highlight the considerable potential for NLP to complement existing human-based qualitative data analysis approaches.
In this paper, we outline the development and utilization of an NLP-based method for inductive qualitative data analysis. We demonstrate this method on a set of 5000 student evaluations of teaching (SETs) and generate a collection of codes (codebook) that summarizes their recurring patterns and concepts. We show that this generated codebook mirrors the codebook produced from a previously completed traditional thematic analysis on a selection of the same dataset (M. Soledad et al., 2017; M. M. Soledad, 2019). While previous approaches have utilized NLP for deductive qualitative coding (Katz, Wei, et al., 2023; Tai et al., 2024), we present a novel method for inductive coding using a robust, iterative process that extracts, embeds, clusters, and summarizes qualitative data into a codebook akin to traditional inductive coding processes. This automated, data-secure method employs open-source LLMs, avoiding proprietary private models that may utilize user data for training (Gemini Apps Privacy Hub - Gemini Apps Help, n.d; Privacy Policy, 2023). Utilizing such open-source LLMs deployed locally on one’s computer also permits a more automated coding process without the need for user interfaces like chatbots. Consequently, we anticipate researchers can employ our approach to conduct meaningful qualitative analysis securely, efficiently, and expediently. When combined with researcher oversight, there is significant potential for this method to broaden existing qualitative data analysis approaches.
Literature Review
This section delves into the use of NLP techniques for analyzing textual data. We explore the growing application of NLP in education research, including for analyzing educational content, generating course materials, and assisting learning processes. Student evaluations of teaching, a form of such educational content, were used to evaluate our approach, which we also describe.
NLP Use in Education
Machine learning (ML) is a growing area in research and industry, with significant potential to transform education through its pattern recognition and decision-making capabilities (Alpaydin, 2021; El Naqa & Murphy, 2015). The ability of machine learning models to analyze and interpret textual and unstructured datasets, like videos and audio, promises to revolutionize learning experiences, instruction methods, and educational systems (Katz, Shakir, et al., 2023; Shaik et al., 2022; Sunar & Khalid, 2024). Natural language processing, a sub-field of ML, uses algorithms to enable computers to understand, interpret, and generate human language data (Bhaduri, 2017; Chowdhary, 2020; Gillioz et al., 2020; Katz, Shakir, et al., 2023). Capabilities of NLP models expand beyond single words to analyze large swaths of text, allowing computers to better approximate contextual understanding, and making responses more coherent and contextually appropriate (Brown et al., 2020; Devlin et al., 2019; Vuong et al., 2021).
Recent advances have enhanced NLP models’ ability to generate text from input prompts and maintain coherence over longer sequences (Brown et al., 2020; Min et al., 2023), as seen in chatbots like ChatGPT (Ansari et al., 2023; Cooper, 2023). While chatbots represent a major advancement in NLP, they are part of a broader field that includes other techniques and approaches for processing and analyzing human language. Research in this area is diverse, encompassing a wide range of applications that utilize both the analytical and generative capacities of NLP (Bhaduri, 2017; Katz, Shakir, et al., 2023; Shaik et al., 2022; Sunar & Khalid, 2024). These applications include tasks such as feature extraction from text, generating summaries, and creating educational content.
When used for text analysis, NLP-generated features, summaries, and categories can serve as the foundation for further analyses. For example, NLP enables sentiment analysis, where NLP models identify the underlying tone of a text and determines whether it is positive, negative, or neutral (Crossley et al., 2018; Kastrati et al., 2021). Such analyses can then be used to gauge overall impressions and attitudes. While this can be useful for tracking changes in sentiment over time or across different groups, sentiment analysis may miss subtle or complex emotions (Wankhade et al., 2022). Further, sentiment is only a single dimension of a text, raising questions about how the detected sentiment interacts with the text’s greater context and meaning. Other approaches for NLP-based text analysis include topic modeling, like latent Dirichlet allocation (LDA), where topics are identified across text documents using word frequencies (Blei et al., 2003). While topic modeling can quickly process and identify latent themes within large volumes of text, results may miss nuance and rich detail (Abram et al., 2020; Johri, 2023). Consequently, topic modeling has been used to assess trends in educational research where less-detailed topics are valuable (e.g., Chen et al., 2020; Johri et al., 2011; Ozyurt & Ayaz, 2022; Yun, 2020). Alternatives to traditional LDA topic modeling include transformer-based approaches like BERTopic (Grootendorst, 2022) which are more adept at general language understanding. While BERTopic and similar transformer-based approaches have been used for text analysis in educational settings (e.g., Bala & Mitchell, 2024; Najmani et al., 2023; Wang et al., 2023), they present standardized techniques that may not be optimized for unique datasets or custom applications.
In addition to text analysis, the text generation capabilities of NLP models have also found applications in education, such as in the design of tutoring systems, the development of educational content, and the creation of personalized learning experiences (Katz, Shakir, et al., 2023; Shaik et al., 2022). These adaptive systems generate personalized recommendations and feedback for users, dynamically adjusting the difficulty, level of support, and content based on individual needs. For example, NLP models have been used to generate feedback for student writing (Madnani et al., 2018; McNamara et al., 2013) and team performance (Sajadi et al., 2023). Systems analyze student responses and generate constructive feedback on various aspects, such as grammar, content, tone, and argumentation. NLP models can also simulate conversations, providing tutoring information about course material (Mathew et al., 2021; Paladines & Ramirez, 2020; Troussas et al., 2023). These systems can provide 24/7 support to students and be tailored to their individual needs and education level.
Given the existing uses of NLP for text analysis and generation, there is potential to leverage these techniques for highly time- and resource-intensive processes, like qualitative thematic analysis. Thematic analysis is a widely used qualitative research method for identifying, analyzing, and reporting patterns or themes within data (Miles et al., 2014). This flexible approach can be applied to various data sources, including interview transcripts, focus group discussions, open-ended survey responses, and other forms of textual data. Notably, many processes inherent to thematic analysis align with the capabilities of NLP (Berdanier et al., 2018; Katz, Shakir, et al., 2023). Previous studies have used NLP for deductive code application (Katz et al., 2021; Tai et al., 2024; Xiao et al., 2023), where models determine whether an existing code applies to a piece of text. However, the use of NLP in inductive qualitative analysis, where the model generates a codebook without relying on a pre-existing framework, has been limited (Katz et al., 2021).
The purpose of this paper is to introduce a method for generating a set of qualitative codes by using NLP techniques, showcased through its application on a dataset comprising written feedback from undergraduate students at a research-focused university. In the next section, we detail these responses, known as student evaluations of teaching, and their significance in educational settings.
Student Evaluations of Teaching
Many institutions facilitate SETs at the end of semesters (Marsh, 1984; Wachtel, 1998). These surveys usually consist of Likert-scale items that are meant to provide students with the opportunity to “rate” an instructor’s teaching effectiveness, as well as open-ended prompts meant to elicit students’ perspectives on their learning experiences, generating quantitative and qualitative data (Marsh, 1984; Sproule, 2000). Quantitative ratings, particularly those meant to measure overall teaching effectiveness, are commonly used by institutions as input into such administrative decisions as salary, promotion, and tenure (Abrami et al., 2007; Hornstein, 2017). Students, however, are more likely to engage in the evaluation process to share their perceptions about their learning experience in the class rather than how their ratings may influence administrative decisions, and they share these perspectives primarily through their responses to open-ended prompts (Hoel & Dahl, 2019). These prompts generate qualitative data that are challenging to comprehensively distill for instructors teaching large class sizes, which results in the underutilization of these data. That underutilization results in a disconnect between how SETs are used in practice and students’ motivation to engage in the process (Abrami et al., 2007; Hornstein, 2017). Evaluations of teaching present one use case for NLP. The following section describes the development of an NLP-based methodology for inductive codebook generation that can be used to analyze SET data more effectively, a process mirroring the initial code generation phases of traditional thematic analysis.
Methods
In this paper, we present a workflow that involves extracting information, embedding the extracted information in a high-dimensional vector space, clustering those embeddings, and summarizing the clusters. The goal of our extract, embed, cluster, and summarize (EECS) workflow is to provide an easy-to-use and effective way to extract information from a large corpus of documents and distill it into a collection of codes. The process mimics common steps for codebook generation in traditional qualitative data analysis (Reyes et al., 2021) but on a larger scale. In this case, those documents were SETs from introductory science and engineering courses at a large R1 university. The data were acquired and used per VT IRB #17-432. Data were not anonymized further because we were using local, open-source language models and therefore adhered to standard protocols when handling data only within a research team. This setup meant that potentially sensitive data never left our local computers (and approved cloud-based storage platforms), which may be different from arrangements other researchers use that involve sending data to third-party language model providers.
In certain research settings, it is common to have tens of thousands of SETs to analyze. The EECS workflow is designed to be scalable so it can be applied to a large corpus of documents beyond education settings. For demonstration purposes here we use a relatively small corpus of 5000 SETs, but in theory, the workflow can be applied to a much larger corpus, depending on computing resources and the nature of the textual units of analysis. To provide readers a sense of the length of the data, Figure 1 illustrates the distribution of the word count for reach SET. The average length of a response was 22 words, and the median length was 14 words. Word count histogram for raw responses.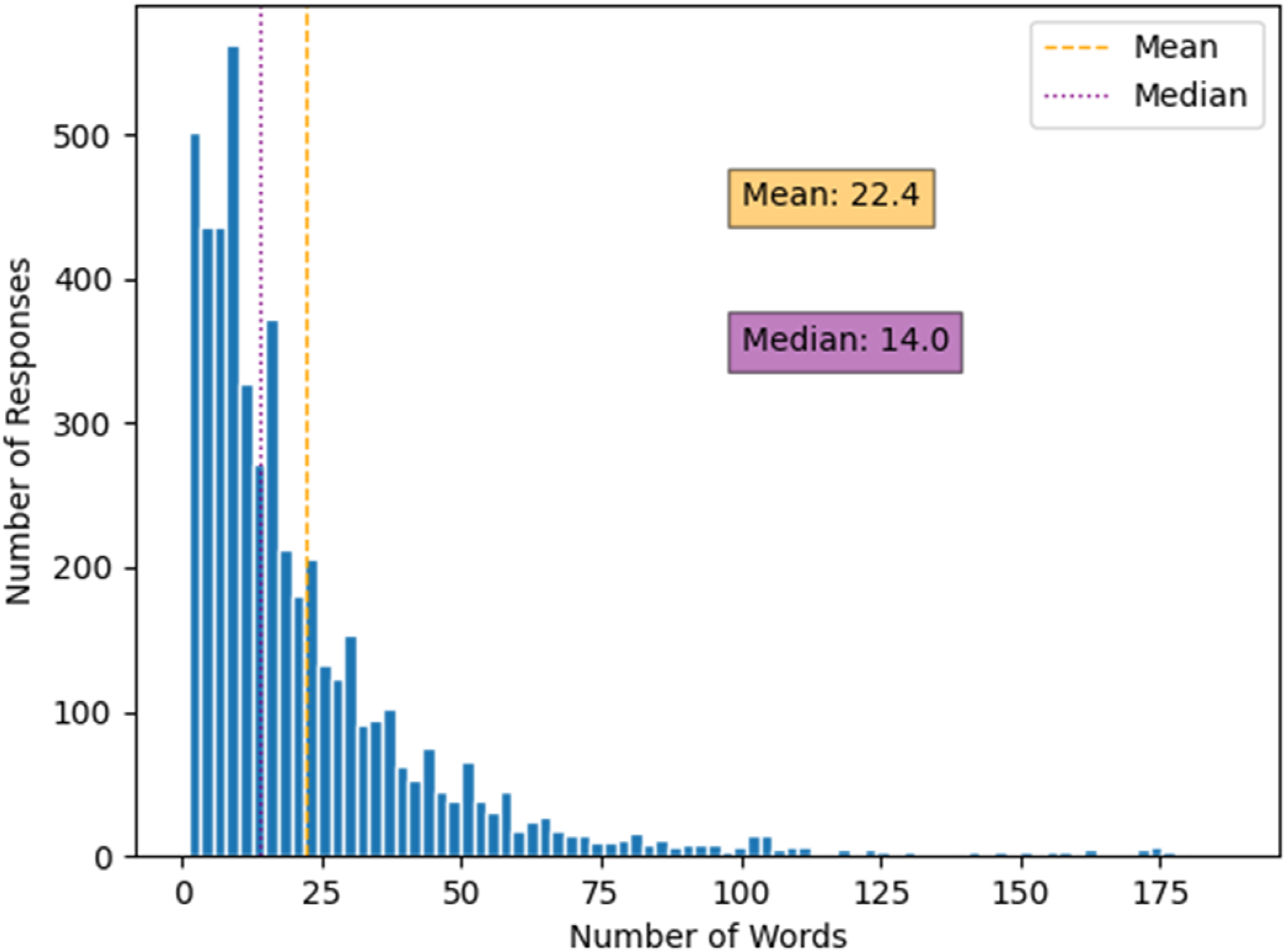
Figure 2 shows a flowchart of the EECS workflow. The workflow begins with the extraction of ideas from the original documents. The extracted ideas are embedded into a vector space and then clustered into groups of similar ideas. Next, those clusters are summarized to create a codebook, which is simplified to remove redundancies and improve usefulness. The overall workflow is designed to be modular so that each step can be modified or replaced with a different technique or language model as needed. Indeed, there is reason to believe that optimizing each step along the workflow would yield better results – a fruitful direction for future work. Finally, we have designed this workflow to use open-source models and tools for the broader research community’s use. These features allow researchers to run the EECS process on their own machine, thereby eliminating the need to send data to third-party providers, such as OpenAI or Google. The following sections describe each step in the EECS workflow in more detail. EECS workflow overview.
Step 1: Extracting Information
The first step in the EECS workflow is to extract the information from the documents we want to analyze. This step is intended to overcome the varied language found in respondents’ free form SET responses because excessive variation could cause larger problems in the downstream analysis. This extraction essentially is a standardization step and a way to isolate each of the ideas expressed in the SETs. In other words, we want to extract the main ideas from the SETs by disentangling them into simpler, discrete ideas.
For the extraction step, we used a lightweight generative text model with the prompt provided in the Appendix. The specific model was the dolphin fine-tuned version of Mistral-7b (Jiang et al., 2023). We used this language model because it is an open-source language model with a permissive license that is sufficiently small to run on common computer hardware at a fast generation rate. The size tradeoff is between larger models that may be more accurate but also may not fit on the average computer or may take too long to generate words. Since this task of summarization is relatively simply for the language models to complete, our initial tests suggested there was no advantage to using a larger generative text model (i.e., one with more billions of parameters). Regardless of the model used, the extraction allows us to analyze each idea separately in subsequent iterations. For example, if a student said, “I liked the in-class demonstrations and availability during office hours,” we would want to extract the two ideas “in-class demonstrations” and “availability during office hours.” The prompt is designed to be a general prompt that can be used for any type of document so that the same workflow can be used for many other contexts.
Step 2: Generate Text Embeddings
The next step in the EECS workflow is to embed the extracted ideas into a vector space. By doing so, we aim to represent each idea as a vector so that ideas can be compared using mathematical operations, such as cosine similarity, or be clustered together to find semantically similar ideas. We used a pre-trained text embedding model available from HuggingFace (Wolf et al., 2020) to embed the ideas. The specific model used here was the UAE-Angle model (Li & Li, 2023), but other models would also work in this step. We used that model because it had the highest performance across a range of performance benchmarks on the Massive Text Embedding Benchmark leaderboard (Muennighoff et al., 2022) at the time among open-source models that could be run locally on one’s machine. This ability to run the model on common computer hardware was important to make the workflow more feasible for researchers without needing special equipment or sending data to third-party vendors.
The embedding model uses the text for each extracted idea as inputs and outputs a vector. The vectors from this UAE-Angle model are 1024-dimensional, representing the text for an idea as a vector (i.e., collection of numbers) of length 1024. The goal behind embedding models is to leverage the theory of distributional semantics, which asserts that words that appear in similar contexts have similar meanings (Boleda, 2020; Erk, 2016). Using distributive semantics, we can represent the semantic meaning of words and phrases as vectors. If two different phrases are semantically similar, as in “used realistic examples” and “gave real-world scenarios” then the vector representations of these should be close to each other in that high-dimensional vector space even though the two strings share no words in common. Working in this vector space allows us to compare the meaning of words and phrases using mathematical operations such as cosine similarity. Cosine similarity measures the angle between two vectors in a high-dimensional vector space (Kenter & De Rijke, 2015). In text analysis, we can use cosine similarity to compare the meaning of two phrases. If the cosine similarity between two phrases is high, then the meaning of the two phrases is similar. This contrasts with older text analysis methods, such as bag-of-words, which do not capture the semantic meaning of words and phrases but rely on the presence or absence of words (Khurana et al., 2023). In that setting, “used realistic examples” and “gave real-world scenarios” would be treated as completely different phrases because they have different words, even though they are semantically similar.
In addition to the ability to calculate semantic similarity between pairs of texts, the embedding model also allows us to calculate the similarity between a single text and a set of texts, as one does when using clustering algorithms. Indeed, clustering is the next step in the EECS workflow because once we have the vector representations of the extracted ideas, we have a new problem: how do we find similar ideas so that we can reduce the information required to represent the SETs into something far smaller, that is, on the order of 50–100 pieces of information/ideas? An alternative way to frame this problem is similar to principal component analysis and the notion of finding the dimensions that explain the most variance in a dataset. In this case, we want to find the dimensions that explain the most variance in the text of extracted ideas. Clustering can help us move in that direction by finding groups of similar ideas.
Step 3: Clustering Text Embeddings
The next step in the EECS workflow is to cluster the extracted ideas. This is important because there are many instances of students commenting on similar ideas, for example, “great notes” or “the notes added online were very helpful.” To find the unique themes within the SETs, the extracted ideas must be collapsed into a more manageable number of observations. This can be accomplished using a clustering algorithm, which groups similar ideas. We used the hierarchical density-based spatial for applications with noise (HDBSCAN) algorithm, which was implemented using the hdbscan Python library (McInnes et al., 2017). We chose HDBSCAN because it is capable of labeling data points as noise if they do not fit within a cluster. This ability is in contrast with other hard clustering algorithms that will force data points into clusters even when their fit is questionable. While clustering, we used conservative parameter settings to encourage many small clusters. The goal was to have many clusters, each with a few ideas (i.e., ideally one). This was done to ensure that when we summarize the clusters later, we have a small number of ideas per cluster to summarize.
Step 4: Finding Representatives for Each Cluster
With the clusters created, we now want to find a single representative member to pass to the next step in the workflow. For example, if we clustered 5000 pieces of extracted information and formed 400 clusters, then we want 400 representatives - one for each cluster - to pass to the generative model. The goal is to have a more manageable quantity of information for the model to remember in its prompt. In essence, this step compresses 5000 pieces of information to 400, assuming each cluster contains a large amount of redundant information. Finding a representative reduces this redundancy without losing information.
To identify a representative, we first embedded a concatenated version of the ideas in each cluster. For example, if a cluster contained entries such as “helpful office hours,” “lots of office hours,” and “good office hours,” we could combine them into a single string like “helpful office hours lots of office hours good office hours,” that we can then embed. These cluster embeddings were then compared with the embeddings for the original extracted information to find the most similar piece of original extracted information. We used the same embedding model as in the prior embedding step and calculated the cosine similarity between the embeddings for each cluster and the embeddings for the original extracted information.
Put another way, this representative identification step selects the extracted information with the highest cosine similarity to the cluster embedding. This “most similar” idea is assigned as the representative of that cluster. Let’s imagine that the 295th cluster had grouped six pieces of extracted information. We concatenate those six ideas into a single string, which we then embed. We then calculate the cosine similarity between the embedding for that string and the embeddings for the extracted information from all the 5000 original documents. Finally, we select the extracted information that had the highest cosine similarity with the cluster embedding and assign it as the cluster’s representative. That representative is passed to the next step in the EECS workflow, initial codebook creation.
Step 5: Create Initial Codebook
Two more steps remain in the EECS workflow: creating the initial codebook and simplifying it to remove redundancies and improve its utility. In the preceding step, we found representatives for each cluster that encapsulated the main cluster themes. Now, the representatives are sequentially given to a generative text model with instructions to summarize it. The aim is to create an initial qualitative codebook with the most common recurring topics in the SETs. This codebook can then be simplified and used in downstream analyses to understand the prevalence of the codes in the SETs. The codebook application step is beyond the scope of this paper and will be described in future work. However, to generate the codebook, we can use the prompt given in the Appendix.
In response to the prompt (detailed in the Appendix), the model generates a summary of the cluster with a code, definition, and example if it determines that a new entry in the codebook is necessary. We subsequently extract the generated text in a short post-processing step. Ultimately, the text generated after the prompt serves as the codebook entry, which is utilized in the subsequent simplification step. Despite its complexity, the process is conceptually straightforward: create a codebook by examining a representative sample of extracted ideas, while striving to keep it concise by adding new entries only when essential. This necessity is determined by evaluating the existing content in the codebook. In essence, the EECS workflow mirrors traditional qualitative data analysis practices.
Step 6: Simplifying the Codebook
The concluding step in the EECS workflow involves the simplification of the codebook. This step is crucial as the initial codebook generated can often be lengthy and redundant, potentially complicating its utility in subsequent analyses. The aim is to streamline the codebook for easier application in downstream processes.
This final step is part of a retrieval-augmented generation (RAG) pipeline. One challenge in generating a codebook is that excessive entries are found, with many being redundant. Consequently, the prompt included instructions for the model to reference an existing codebook (i.e., the one we are inductively creating), and decide whether the extant codes cover the theme(s) in the new text under analysis. If not, a new code entry is warranted because the existing codes are insufficient.
While it might seem logical to provide the entire codebook to the model as part of the prompt, our practical experience has shown that it is more effective to offer the top k codes from the codebook. By “top k codes,” we refer to the k most similar codes based on semantic similarity between the cluster text and existing codes. This approach reduces the memory requirements on the model; rather than memorizing the entire codebook, the model only needs to recall the top k codes that we have provided it in the prompt. This is a tradeoff because the model may not always make an informed decision about the necessity of a new code if it only sees the top k codes. However, in our experiments, the model demonstrated the ability to make such informed decisions, as evidenced by the reasoning steps it provided in the output.
To determine the top k codes, we embed each entry in the codebook using the same embedding model as in the prior steps and calculate the cosine similarity between the embeddings for each codebook entry and the embeddings for the cluster representative. Subsequently, we select the top k entries in the codebook with the highest cosine similarity with the cluster representative embedding as the top k codes. For instance, if the new cluster representative is “gave lots of examples in class,” the top k codes might include “in-class demonstrations,” “real-life scenarios,” and “helpful lectures.” These codes are then included in the prompt provided to the model. As with some of the other steps, we employ a generative text model and prompt outlined in the Appendix. The design of this prompt ensures its adaptability for diverse document types, enabling the use of the same generative text model across various contexts.
Results
Extracting Ideas from the Original Texts
After pre-processing and screening short responses from our random sample of 5000 SETs, we ended up with 4672 unique original SETs. Utilizing the EECS workflow, we initially extracted 12,046 ideas from this set of 4672 original comments. The distribution of the extracted ideas is shown in Figure 3. The average number of extracted ideas was 3.3 with a median value of 3. The right skew of the distribution was expected because most students only have a few things to say while a few outliers have much more that they want to share. Histogram of the number of extracted ideas from the original SET comments.
Extracted Ideas From a Single SET.

Summarizing the Clusters
Example of Summarizing the Clusters.

Simplifying the Codebook
Example of Step 1 for Code Consideration.

Example of the Simplification Step With Accepted Original Code.

Example of the Simplification Step With an Alternative Suggestion.

Comparison with the Human-Generated Codebook
As previously mentioned, a subset of SET data was originally employed in prior studies investigating the teaching and learning dynamics within first-year engineering courses (M. Soledad et al., 2017; M. M. Soledad, 2019). These SETs underwent manual thematic coding, revealing 39 distinct codes.
Elements of the Academic Plan Model Adapted From Soledad (2019).

The initial coding revealed that the analyzed SETs corresponded with these APM elements. However, the 39 human-generated codes fell into only four categories from the APM: one in Adjustments, one in Assessments, 13 in Faculty characteristics, 18 in Instructional processes, and six in Instructional resources.
In contrast, our EECS method generated 80 distinct codes. Five were excluded due to ambiguity or vagueness, yielding 75 useable codes, of which six pertained to Adjustments, five to Assessments, 22 to Faculty characteristics, 25 to Instructional processes, 15 to Instructional resources, and two to Content and Sequence — a category not initially identified through manual coding. Content and Sequence refers to the arrangement and content of subject matter in a course. This difference between the human coding and the EECS process may indicate that the larger number of SETs processed contain information beyond the smaller initial sample used for the human coding – a promising finding for similarly large datasets. The complete list of EECS-generated codes alongside the human-generated codes is provided in Tables 7, 8, and 9 in the Appendix.
Comparing the model’s codes with the APM demonstrates the method’s alignment with traditional human-generated codes. Because the human-generated codebook is aligned with the APM elements, we should expect the model’s codes to align. Once categorized according to the APM, the human- and model-generated codes are more meaningful side-by-side, allowing for a clearer comparison.
Examining the distribution of codes across categories, our method mirrors a similar trend to the manual analysis. Notably, the model’s codes were categorized independently of the original codebook and were cross-checked by someone familiar with the initial coding. Furthermore, there was substantial overlap between the original codes and model-generated codes within each category, indicating that the model effectively captured analogous topics, terms, and characteristics. Following the final simplification step, the model’s codes were largely constructive and informative, facilitating their integration into subsequent analyses or feedback for instructors.
Moreover, the significant concordance between the method’s codes and those manually derived indicates the workflow’s capacity to encapsulate the essence of the analyzed SETs. This finding holds promising implications for the research community, as it suggests that inductive thematic analyses can be efficiently conducted on extensive datasets using the EECS workflow within a relatively short timeframe. These implications will be further explored in the following section.
Discussion
Comparison to Traditional Codebook Generation
These results underscore several key insights. Namely, the EECS workflow effectively replicates the codebook generation process typical of traditional qualitative data analysis. Not only did this process reproduce codes identified in traditional qualitative analysis, but it also identified new codes with greater granularity than those in the original codebook. This increased granularity may be due to the workflow’s ability to detect subtler distinctions in the data than a human coder might perceive, or because the workflow evaluated a significantly larger volume of data. The EECS workflow processed over 4500 unique SETs, far exceeding the scope of the original analyses, which likely contributed to the identification of new codes as patterns that were barely noticeable in the original analyses became detectable with more data.
When compared to traditional qualitative methods, the EECS workflow offers notable advantages, including the ability to efficiently process and analyze larger datasets. This scalability comes at reduced costs because larger datasets can be evaluated faster and with fewer resources than comparable human-based approaches. This large-scale textual analysis can reveal patterns that might be overlooked in smaller datasets analyzed by human coders. Consequently, a promising avenue for future research is to explore how this workflow can apply to longer texts in less constrained environments. For example, it could be used to analyze student essays, research articles, and administrative records where connections and relationships can be drawn between extensive textual data.
Despite this promising opportunity, there are drawbacks to consider. Although models may be able to detect subtle differences, they may lack a nuanced understanding of context and meaning known by a human coder. Some of these aspects may be captured by the prompts provided to models, such as the data type, data collection methods, or study objectives, but human coders can interpret the intricacies of language, cultural references, and underlying sentiments in ways that current models might not fully grasp. For instance, irony, sarcasm, or complex emotional tones may be challenging for models to accurately identify without specific training (Potamias et al., 2020; Weitzel et al., 2016). Additionally, models may introduce biases embedded in their training data and underlying algorithms (Mao et al., 2023; Sheng et al., 2019; Vig et al., 2020). While human coders can reflect on and adjust for potential biases during analysis, automated models may propagate these biases unless carefully monitored and calibrated. This propagation extends to biases within the data corpus itself that could be reflected in the outcomes generated by the EECS workflow. For instance, if the data were not representative of the broader population, the codes and themes identified might be similarly skewed, leading to the overrepresentation or underrepresentation of certain themes. Furthermore, short or ambiguous text analyzed by the workflow could inject uncertainty into the resulting outputs. This could also occur if the texts were too similar, leading to the over-interpretation of minor variations that might not be meaningful in a broader context. Given these considerations, while the EECS workflow provides a powerful tool, it may be most effective when used in conjunction with human oversight, ensuring that the richness, depth, and accuracy of qualitative analysis are preserved.
Comparison to Other NLP Methods
While the EECS workflow successfully replicated and extend human coding efforts, it is crucial to consider its performance in comparison with other popular approaches to computer-assisted thematic analysis. One popular method for analyzing text data is topic modeling. Topic models are statistical models used to identify topics in a collection of documents. One of the most popular topic modeling algorithms is latent Dirichlet allocation (LDA) (Blei et al., 2003). The LDA model is a generative probabilistic model used to discover topics within a collection of documents. LDA assumes that each document is a mixture of topics that are represented as a group of words or related words. These topics, or themes, exist across multiple documents, and each word in a document is assumed to be generated by one of its topics. The goal of an LDA model is similar to the goal in the EECS workflow: identify the latent topics related to the observed words in each unit of analysis (e.g., document, essay, article, SET). In practice, LDA works backward from the observed words in the documents to uncover the latent topic structures. One advantage of this is quick training – LDA models can be trained in a matter of minutes. In one application, Abram et al. (2020) used LDA to analyze nearly 170,000 words from nurse interviews and found it reduced the project time by at least 120 hours and costs by $1500. This analysis was completed in 2 minutes, not including the time required to process the data and write the program. By contrast, the EECS workflow can take hours to complete depending on corpus size and computational resources. Furthermore, while LDA possesses specific metrics to determine the number of topics to extract from the data (Wallach et al., 2009), the EECS workflow does not currently, and instead relies on the user to determine the number of clusters to extract from the data.
On the other hand, the EECS workflow relies more on semantics than syntax. Typical topic models rely on word stems, so words like “homework” and “assignments” are treated differently even though they may be similar in some contexts. In the EECS workflow, this could be remedied using prompts that specify the context or during clustering. Additionally, traditional topic models provide a list of frequent words for each topic, leaving researchers to interpret their meaning. This could create ambiguity and divination in their results. By contrast, the EECS workflow generates coherent labels and accompanying definitions. To illustrate, Abram et al. (2020) noted that their method captured the overall thematic descriptions in the interviews but did not provide rich, nuanced themes mirroring those from traditional qualitative methods. Had the EECS workflow been used, the processes could capture semantic relationships and contextual details better than word frequency-based approaches, like theirs. The text embeddings used in the workflow, when used alongside more advanced clustering algorithms, could identify more subtle thematic groupings that better reflect the meaning in the data, while including elements of the broader context.
Modern variations of topic models such as BERTopic (Grootendorst, 2022) attempt to address limitations of traditional topic models, to varying degrees of success. BERTopic harnesses the power of transformer-based models, the artificial neural network architecture that has revolutionized many NLP tasks (Gillioz et al., 2020). When used with the same SET dataset, BERTopic and LDA produced less discernible topics, and the coherence scores also suggested fewer topics. Interpretability and granularity were two areas where EECS was more useful than BERTopic. On the other hand, BERTopic is a more widely available and better-known approach, and topic modeling is quicker to run. Nonetheless, the reliance on syntactic similarity requires significant assistance from transformer-based models to try to capture semantic similarities.
Transformers, introduced by Vaswani et al. (2017), have become the foundation of state-of-the-art NLP models due to their ability to capture the long-range dependencies in sentences (Gillioz et al., 2020). By weighing the importance of different words in a sequence and processing data in parallel, transformers can learn intricate patterns in language, making them invaluable for NLP applications (Gillioz et al., 2020; Katz, Shakir, et al., 2023). Our method, like BERTopic, employs transformer-based models for the codebook generation process. However, we are not unique in recognizing the potential of transformers for NLP-based qualitative thematic analysis. Ganesh et al. (2022) introduced the response construct tagging (RCT) task to analyze students’ open-ended responses from course surveys, focusing on identifying affective states related to transformative experiences and engineering identity development. Their work showcased the scalability and value of transformer models like RoBERTa (Liu et al., 2019) for qualitative coding in educational research contexts.
While these investigations demonstrated NLP’s supportive role in traditional thematic analysis, Tai et al. (2024) proposed a novel methodology using LLMs for deductive coding in qualitative research. Parallel to our research group’s work (Gamieldien et al., 2023; Katz et al., 2021), they developed a deductive coding scheme with five predefined codes related to scientific identity and input sample interview excerpts and the codebook into ChatGPT to detect code presence and supporting evidence. Comparing the results to human coding, the authors found high alignment for most codes. Interestingly, areas of divergence prompted refinements in code definitions and applications, showcasing how LLMs can serve as external reviewers to identify potential blind spots, a finding we also observed. Transformer-based NLP techniques have shown potential in assisting and guiding qualitative thematic analysis, but research thus far has been limited to a few approaches revolving around ChatGPT and has not ventured far into inductive thematic analysis as our method proposes nor the use of open-source models.
Accordingly, there are several potential reasons our inductive process may work. To start, the initial information extraction step helps to standardize language and disentangle complex ideas into simpler, singular ideas. This is important because it allows us to analyze each idea separately in subsequent steps. Without this step, we would have to analyze the entire SET at once, which would be a much more difficult task. Additionally, the embedding step further helps funnel information into standardized formats because it captures the semantic meaning of words and phrases. Therefore, we have a way to move from the varied original text into an abstract space of ideas, which prior methods using dictionary-based approaches were not able to do. Also, the dimension reduction and clustering steps help to further compress the information more than prior steps. The result is a funnel that takes in a large amount of varied information and outputs a small number of themes.
Humans-in-the-Loop
While our methodology is largely automated and programmatic, human involvement is indispensable. Human expertise and judgment play a pivotal role throughout the process, ensuring the credibility of the analysis and validating the outputs. For instance, our method generated 80 total codes, but five were discarded due to ambiguity or irrelevance. The EECS process yielded a codebook summarizing recurring statements and content of the input data, yet it may include themes and content that are uninformative or misaligned with research objectives. We advocate for researchers to actively engage in the codebook generation process, identifying irrelevant or misleading codes, manually reviewing and rejecting unnecessary ones, and verifying the overall quality and validity of the automated analysis.
Code quality is tightly linked to its usefulness. While the EECS process generates a codebook, the workflow by default is agnostic about how codes will be utilized – a result of embedding, clustering, and prompt designs. Hence, researchers must assess the relevance and applicability of generated codes to research questions, considering the required level of granularity and specificity for meaningful analysis. Establishing criteria for determining the saturation point in code generation is advised, as this varies between investigations. Researchers must monitor the codebook to identify when no new codes or insights emerge from the data. Balancing code granularity and manageability is crucial, as codes become simpler with each iteration. Consideration for potential consolidation or hierarchical organization during code review can help conclude the generation process while maintaining an ideal level of granularity.
The prompts used in the EECS process are detailed in the Appendix and are specifically tailored for this application. If applying this process to a different context, crafting context-specific prompts is essential to guide the generative text model effectively. Prompt design should balance specificity and flexibility to avoid scope limitations or researcher biases (Mao et al., 2023; Sheng et al., 2019). Additionally, there is potential for this method to be adapted to fine-tuned LLMs trained on domain-specific datasets, potentially enhancing accuracy, relevance, and efficiency (Church et al., 2021).
Ultimately, to maximize the utility of the EECS workflow, researchers should actively participate in the codebook generation process, from assessing code quality and utility to designing prompts and selecting models. This method is inherently reflective, requiring researchers to play an active role in code generation and analysis rather than passively relying on method outputs.
Limitations
The current workflow presents several limitations, some of which suggest areas for future exploration. First, granularity levels within the codebook pose a challenge. Instances such as having separate codes for “in-class demonstrations” and “used experiments to show ideas” may exhibit semantic similarity, suggesting potential consolidation into a single code. Similarly, codes like “clarity” and “clarity on syllabus” could be collapsed or treated hierarchically, especially if clarity is evident in other aspects of the course. Addressing this challenge is a focus for future work, necessitating the development of methods to systematically handle semantically similar codes, including refining techniques for consolidation and hierarchical treatment.
Second, the efficacy of codebook generation heavily relies on the language models employed in the process. As models evolve, ongoing evaluation of the method’s efficacy and accuracy, particularly with diverse datasets, is essential. Variations in model size and fine-tuning techniques can significantly impact outcomes, requiring thorough evaluation across different models and datasets to ensure robustness and reliability.
Third, the interpretation of codes exhibits context dependency. For instance, the interpretation of “scaffolding” may vary when analyzing SET data compared to comments from a construction site. Exploring methods to incorporate context into the codebook generation process, whether through prompt adjustments or alternative approaches, is an avenue for future investigation.
Finally, while the process mimics human coding efforts, its superiority over alternative methodologies remains uncertain. Alternative approaches may exist, utilizing different prompts, variations in the RAG pipeline implementation, or alternative methods of codebook simplification. Moreover, advancements in model architectures, such as selective state space models, may mitigate context window limitations and introduce novel possibilities. While our work demonstrates the potential of using generative text models and modern NLP techniques with open-source options to replicate human coding processes efficiently and at scale, there are diverse avenues for exploration in designing processes for document analysis. We encourage further research to build upon this foundation, facilitating a range of options for document analysis across various fields.
Conclusion
Recent advances in NLP and LLMs promise opportunities to analyze text data in new ways. In this paper, we have presented a new analytic method for such analysis. By combining information extraction, text embedding, clustering, and summarizing, we have shown that it is possible to identify themes in a large corpus of documents without the typical time and labor costs associated with manual coding. Moreover, we have demonstrated how to accomplish this using open-source tools, thereby avoiding sending data to third-party service providers and proprietary models. The process we have described is scalable and can be applied to create a codebook that can be used in downstream analyses. We believe that this method has the potential to be useful for analyzing SETs and other types of writing in teaching and research settings. We also believe that this method has the potential to be useful for analyzing other types of documents, such as essays, research articles, and administrative records. The goal is for this paper to inspire others to explore the possibilities of NLP and LLMs for qualitative analysis in their fields.
Footnotes
Acknowledgements
This work used generative artificial intelligence as part of the method that we investigated and reported. This is different from uses of generative artificial intelligence to write the manuscript itself, which we did not use here. We thank the reviewers for their helpful comments and suggestions. We also thank the students who participated in the study.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This material is based upon work supported by the National Science Foundation under Grant No. #2107008 and the Virginia Tech Academy of Data Science Discovery Fund.
Appendix
Note that the curly brackets ({}) are placeholders for text to be inserted in the prompt.