
Abstract
Qualitative data analysis, particularly thematic analysis, is a widely used method for uncovering patterns and insights in narrative data but often faces challenges such as being resource-intensive and susceptible to researcher bias. In recent years, Large Language Models (LLMs) have emerged as promising tools to assist human coders in conducting thematic analysis, offering efficiency and scalability in processing large datasets. However, existing work primarily relies on tools like ChatGPT, raising privacy concerns—especially when analyzing sensitive healthcare data—and lacks systematic validation through comparisons with human coders. This study aims to evaluate the potential of open-source LLMs for qualitative data analysis. Semi-structured patient interviews (n = 34) conducted by a trained qualitative researcher provided the dataset, with traditional qualitative (inductive) analysis by two researchers serving as the gold standard. Two open-source LLMs, Gemma2 and Llama3.1, were used to generate codes, and their performance was assessed based on factors such as chunk size, inductive vs. deductive methods, and prompting approaches. Results showed some alignment between LLM- and researcher-generated codes, with the deductive approach yielding higher and more nuanced insights (Gemma2: n = 723; Llama3.1: n = 1,042) compared to the inductive approach (Gemma2: n = 715; Llama3.1: n = 829). Approximately 45% of the LLM-generated codes provided meaningful context, though 22–39% were duplicative. While LLMs demonstrated efficiency in analyzing large volumes of textual data, nearly half of the codes lacked sufficient context or were repetitive. Our findings showed that although combining traditional qualitative analysis with AI presents a promising avenue, future research should explore how pre-trained LLMs could augment qualitative analysis with higher inter-rater reliability to improve patient-provider communication. There is a need for further research or the development of domain-specific LLMs to improve their utility in qualitative analysis.
Keywords
Introduction
Qualitative analysis of text data is a widely used research method in social sciences, humanities, and applied fields, focusing on examining non-numeric, narrative data to uncover patterns, themes, and insights (Castleberry & Nolen, 2018). Unlike quantitative approaches, which prioritize generalizability and frequency, qualitative analysis delves into the complexity and depth of textual data, often aiming to understand the how and why behind participants’ responses. Thematic analysis (Terry et al., 2017), often conducted using focus groups, interviews, or semi-structured interviews, is a core method to code, categorize, and visualize patterns or themes within text data. It relies on researchers’ interpretations to identify explicit and latent meanings in qualitative data. Traditionally, this process involves manually reading and coding data, which can be resource- and time-intensive and influenced by the researcher’s expertise and potential biases. Reliability in qualitative research is often addressed through inter-rater reliability, where multiple researchers independently code data and reconcile discrepancies to ensure consistency. While thematic analysis is inherently flexible and shaped by researchers’ philosophical assumptions (Braun & Clarke, 2019), its traditional manual approach can present challenges, particularly in terms of time, consistency and scalability that modern computational tools have the potential to address.
Recent advancements in emerging technologies, particularly Large Language Models (LLMs), have opened new possibilities for assisting qualitative researchers with data processing and analysis (Manning, 2022). LLMs are advanced deep learning models that represent a significant step toward Artificial General Intelligence (AGI), trained on vast datasets to understand and generate human-like text (Ge et al., 2023). Their impact is rapidly expanding across diverse domains, including education (Ng, 2024), cybersecurity (Chataut et al., 2024), and legal studies (Padiu et al., 2024). In critical fields like healthcare (Thirunavukarasu et al., 2023), LLMs have similarly shown great potential, with researchers exploring their applications for tasks such as medical record summarization (Madzime & Nyirenda, 2024), clinical decision support (Rajashekar et al., 2024), and patient interaction (Johri et al., 2025). By leveraging their ability to process and analyze large-scale data, LLMs are becoming integral tools for innovation and problem-solving in a wide range of fields, including qualitative research.
With the potential to identify patterns and assist in organizing data, LLMs have the potential to streamline and enhance the process, opening new avenues for innovation and problem-solving, including efficient and scalable qualitative research.
Few studies have explored the use of LLMs for qualitative analysis and initial findings indicate promising utility. For instance, Qiao et al. (2024) demonstrated that deductive coding using ChatGPT® 3.0 was comparable to traditional coding when provided with a clear codebook, structure, and contextual information (Qiao et al., 2024). Additionally, research utilizing LLMs for traditional qualitative deductive coding suggests that these models can aid researchers by offering an organized and reliable platform for code identification and analysis (Tai et al., 2024). Recent studies have also shown higher accuracy of AI agents when combined with statistical modeling (Player et al., 2025; Qiao et al., 2025). Player et al. (2025) utilized large-scale text data to fine-tune LLMs in a way that incorporated structural topic modeling and example-based pretraining to create domain-adapted models for thematic analysis. Qiao et al. (2025) evaluated LLM generated themes through inductive qualitative analysis, assessing them against established trustworthiness principles in qualitative research. Their findings demonstrated that assigning distinct roles or identities to LLM coder agents (e.g. coder, aggregator, and reviewer) promotes divergence in coding and theme generation, potentially improving analytical rigor.
Despite the growing adoption of LLMs and AI tools to analyze qualitative data more efficiently and quickly, there remains limited research on their ability to provide accurate context, validity, and interpretation of qualitative data without requiring substantial researcher inference for explanation and understanding. Concerns include reliance on tools (e.g., ChatGPT) that require sharing data over the internet and data privacy/confidentiality issues (Sebastian, 2023) — particularly critical when dealing with sensitive healthcare data. Moreover, there is a lack of systematic evaluation that compares traditional methods of code generation (i.e., human researcher-generated codes) with those developed by LLMs from qualitative data transcripts. Such evaluation is essential to improve the rigor and quality of narrative data analysis as it helps to uncover patterns, themes, and insights more efficiently. This paper addresses these critical knowledge gaps by exploring the use of open-source LLMs to generate meaningful codes for textual data visualization. We conducted an exploratory investigation to determine whether open-source LLMs could effectively perform inductive and deductive thematic analysis tasks. By directly comparing the codes generated by LLM with those produced by expert human coders, evaluations were made of how the LLM-based approach aligns with traditional qualitative research practices during an initial coding task, chunk size (the number of paragraphs analyzed at once), prompting techniques (few shots and zero shots), and analysis approaches (deductive vs. inductive) that influence the performance of the LLM model in the generation of themes.
To achieve this, we replicated a qualitative study that explored facilitators and barriers to diabetes-specific patient-provider communication (PPC) among 34 adults with chronic diseases who participated in a 12-week lifestyle intervention. Using semi-structured interviews, we analyzed themes related to patient experiences with their providers and communication regarding diabetes clinical and self-care. Using open-source LLMs, we explored their benefits in time efficiency and their ability to generate meaningful codes for textual data visualization. By directly comparing LLM-generated codes with those produced by experienced human coders, this study investigates to what extent an LLM-based approach aligns with established practices during an initial coding task. Two prompting approaches were used: (1) few-shots - a technique used in machine learning and natural language processing - where a model is given a small number of examples or “shots” to learn a specific task & zero-shots where the model is asked to perform a task without any prior examples or specific training. The comparison between the deductive and inductive approaches allowed differences in the model’s awareness of the research question. Under the deductive approach, the model began with initial codes informed by the research question or a predefined analytical framework. In contrast, the inductive approach enabled the LLM to generate codes and themes directly from the data, without prior knowledge of the research question or any pre-established analytical structure. (De Paoli, 2024). Findings of this study will improve contextual understanding of how input structure, prompt designs, and analysis approaches affect the quality and relevance of LLM-generated codes as well as validate the need for LLM agent-human coder interactions, thereby informing their use in qualitative research applications (Stojanov, 2023).
Thematic analysis, as outlined by Braun and Clarke (2006), is a method for analyzing qualitative data that provides a structured approach to identifying and defining themes within a dataset. The process typically includes six key stages: (1) familiarization with the data, (2) generating initial codes, (3) searching for themes, (4) reviewing themes, (5) defining and naming themes, and (6) writing the report. This process facilitates both inductive (data-driven) and deductive (theory-driven) analyses, allowing for an in-depth exploration of participants’ narratives and the identification of shared patterns across data. An inductive approach allows themes to emerge directly from the data, often called a “bottom-up” method, with no prior theoretical framework constraining theme development (Patton, 1990). In contrast, a deductive approach, or “top-down” analysis, applies pre-existing concepts or theoretical frameworks to guide the coding and interpretation process. This approach is valuable when the goal is to validate or extend a specific theoretical construct within new datasets (Fereday & Muir-Cochrane, 2006).
Several frameworks and methods can guide thematic analysis, each supporting rigorous and reproducible findings. Notable frameworks include Braun and Clarke’s Reflexive Thematic Analysis (Braun & Clarke, 2006), Framework Analysis (Ritchie & Spencer, 1994), Interpretative Phe-nomenological Analysis (IPA) (Smith et al., 2021), and the Constant Comparative Method (Glaser, 1967). For instance, Reflexive TA emphasizes researcher reflexivity, allowing for flexible theme development in response to the data. Framework Analysis, meanwhile, structures data within a matrix format, facilitating a more deductive approach. IPA focuses on individual interpretations, ideal for examining personal experiences, while the Constant Comparative Method encourages iterative refinement of themes.
LLMs have shown exceptional performance in natural language processing tasks (Hsu et al., 2024; Naveed et al., 2023; Thirunavukarasu et al., 2023). These recent advancements have also enabled applications in qualitative research, including thematic analysis across education, social sciences, health-care, and legal studies (Breazu et al., 2024; Mirzaei et al., 2024; Sabbaghan, 2024). While there has not been extensive research on this topic, LLMs have demonstrated their ability to assist in both deductive and inductive coding. For instance, Sabbaghan (2024) tasked GPT-4 with categorizing YouTube comments and compared its results to human researchers. Similarly, Tai et al. (2024) employed LLMs for deductive coding using predefined codebooks. Ethical concerns, such as hallucinations and data privacy, necessitate techniques like prompt engineering and the use of open-source LLMs for sensitive data (Mathis et al., 2024).
However, challenges remain in applying LLMs to thematic analysis, particularly in their proper validation. This study differs from existing studies in several ways. First, we utilized publicly available open-source LLMs to understand their roles in qualitative data analysis. Second, we analyzed qualitative data from rural Appalachia. Most importantly, this study is among the first to compare LLM-generated codes directly with those created by human researchers on semi-structured and long free-text data. We hypothesized that open-source LLMs will generate codes and themes from qualitative interview transcripts that exhibit a high degree of alignment (code agreement, clear and complete) with those identified by qualitative researchers. We further hypothesized that deductive prompting will generate more nuanced and contextually rich codes than inductive prompting. However, we anticipated that LLM-generated outputs will contain a higher proportion of duplication, incomplete, or less analytically developed codes as compared to researcher-generated codes.
Methods
This research focused on examining the reliability of qualitative textual data coding and visualization performed by two LLMs, validating the results through multiple stages of analyses conducted by experienced human qualitative researchers. We started with LLM-generated initial codes using thematic analysis and methodology outlined in our original study of (Kirk et al., 2023). We used the same participants’ interview transcripts to conduct iterative inductive and deductive coding with two LLMs - Gemma2 and Llama3.1. The two LLMs were intentionaqlly selected to balance accessibility and performance. Gemma2 allowed us to test a lightweight, resource-efficient model, while Llama3.1 represented a state-of-the-art open-source LLM with strong performance on reasoning and qualitative analysis tasks. This contrast ensured that our findings are not tied to a single architecture or scale. The qualitative data collection and analysis have been described in detail elsewhere (Kirk et al., 2023) but briefly described below. We utilized predefined researcher-generated codes derived compared with researcher-generated codes, as shown in Figure 1.
1
Research methodology for LLM based thematic analysis
Analytic Framework
While our analytic strategy was informed by Braun and Clarke (2006)’s six-phase approach to thematic analysis, we did not undertake a full thematic analysis in the traditional sense. Instead, we drew on their framework as a guiding orientation while experimenting with the use of LLMs to support aspects of coding and theme development. Specifically, LLMs were used as an analytic aid in the early stages of data engagement, including summarizing segments of text and surfacing potential codes. The research team then reviewed, refined, and organized these codes into broader patterns, and iteratively developed and interpreted themes through discussion and consensus. This process departed from a canonical thematic analysis in several respects, particularly in terms of prolonged immersion, recursive coding, and theme refinement. We therefore characterize our approach as an adapted analytic strategy that was informed, but not fully governed, by Braun and Clarke (2006)’s framework. Our intent in adopting this hybrid approach was both pragmatic—to explore efficiencies LLMs might offer—and exploratory, contributing to emerging conversations about the integration of computational tools into qualitative research practices.
LLM for Thematic Analysis
We have selected open-source LLMs Gemma2 and Llama3.1, to analyze their performance and suitability for thematic analysis tasks. Additionally, we examined the role of text segmentation and how altering the segment size affects the models’ ability to identify themes by segmenting the text with a varying number of paragraphs. This enabled us to explore the impact of different chunking strategies on the efficiency of thematic analysis.
We systematically compared the outputs of LLMs with human-generated codes, analyzing the codes in terms of total and unique counts, consistency, and relevance to the research question. Beyond assessing performance, we examine the potential of LLMs to augment qualitative research by balancing efficiency and analytical depth while highlighting key challenges, such as maintaining nuance, preserving context sensitivity, and addressing areas where human expertise remains indispensable. This dual focus illuminates the opportunities and limitations of applying LLMs to deductive and inductive coding processes, offering a nuanced understanding of their role in thematic analysis. The comparison across different prompting strategies (few-shot and zero-shot) and analysis methods (deductive vs. inductive) helped us understand the impact of LLM use as a methodological tool for rigor and relevance in future qualitative research.
Thematic analysis was conducted using both inductive and deductive approaches. Given that our dataset included only 34 interview transcripts from patients with similar chronic from the transcripts. The transcripts were then processed by the LLMs to generate initial codes through hallucination and chunking analysis using various inductive and deductive frameworks. The extracted codes were analyzed and conditions, it was insufficient for fine-tuning. Hence, we employed prompting strategies to guide the LLM instead. The prompting used for deductive and inductive approaches can be seen in Appendix Figures 3 and 4, respectively.
Deductive Framework
In this approach, we guided the LLM by providing a research question informed by existing literature. In addition, two predefined transcripts and initial code examples were supplied (few-shot prompting) to assess how well the model aligned with established themes. Few shot prompting involved providing examples to the LLM to mimic the coding patterns of qualitative researchers.
Inductive Framework
In this approach, we defined only the task for the LLM without providing specific examples or predefined categories (zero-shot prompting). It aimed to uncover unique codes and themes that might not have been identified by human coders, allowing for the discovery of novel insights. Zero-shot prompting involved a straightforward prompting approach that did not rely on any examples.
Data
Lifestyle Intervention
The design, context, participants, and data collection of the Diabetes and Hypertension Self-management Program (DHSMP) intervention has been described elsewhere (Kirk et al., 2023). The DHSMP was a community-based, 12-week behavioral intervention implemented in two West Virginia counties. Ninety-one adults with comorbid diabetes and hypertension participated in a wait-listed randomized control trial.
Qualitative Data
All participants were recruited for focus groups and semi-structured interviews after program completion for feedback on program satisfaction, barriers, and facilitators to program engagement and behavior change. Additionally, program effectiveness in improving diabetes self-care and self-efficacy to improve patient provider communication and its domains were assessed. For this study, we used only the semi-structured interviews (n = 34) to compare the codes generated by the researchers versus the two LLMs – Gemma2 and Llama3.1. The semi-structured interviews were conducted by a trained qualitative researcher (approximately 20–45 min) and provided adequate data saturation.
Researcher Generated Codes
The initial phase involved manually coding the transcripts to establish a benchmark. The research question that guided the analysis included “What do patients living with Type 2 diabetes mellitus in rural Appalachia perceive to be facilitators and barriers to discussing their disease with healthcare providers?” The interviews were transcribed verbatim and coded in NVivo by two trained researchers to ensure content accuracy. The coders used an inductive coding approach to achieve the aims of this qualitative study.
Data Preprocessing and LLM Implementation
Transcripts were preprocessed using a reproducible pipeline: filler words, inaudible markers, and speaker labels were removed, whitespace normalized, and spelling/grammar optionally corrected using TextBlob. Text was chunked into sizes of 20 tokens, based on preliminary experiments (Appendix Figure 1), which also helped mitigate hallucina-tions by controlling code output per transcript. LLMs were initialized via LangChain’s Ollama wrapper with default generation parameters (e.g., temperature 0.8), and out-puts were captured directly without manual filtering. Few-shot and zero-shot approaches for deductive and inductive frameworks, respectively, were determined with qualitative domain experts, including the number of examples for few-shot prompting. Minor formatting issues in Python list out-puts (e.g., incomplete brackets, misplaced quotation marks) were resolved using a string replacement algorithm.
Data Analysis Approach
The combined framework of inductive and deductive approaches provided both the flexibility to discover novel themes and a systematic structure to address predefined constructs.
Inductive coding allowed new themes to emerge directly from the data, focusing on capturing nuances specific to the rural healthcare context. Deductive coding applied predefined research questions. We did the following for the LLM data coding and analysis: Code Comparison: The total and unique codes from human and LLM-generated outputs were compared to evaluate consistency and alignment. Overlap Analysis: Thematic overlaps between human and machine-generated codes were visualized using diagrams. Word Clouds: Highlighted dominant themes in both coding approaches. Line Graphs: Examined the effect of chunk size on the number of generated codes.
This analysis provided insights into how inductive and deductive coding strategies, combined with different prompting and chunking techniques, influenced the thematic outputs. The findings contributed to evaluating the efficacy and limitations of LLMs in thematic analysis.
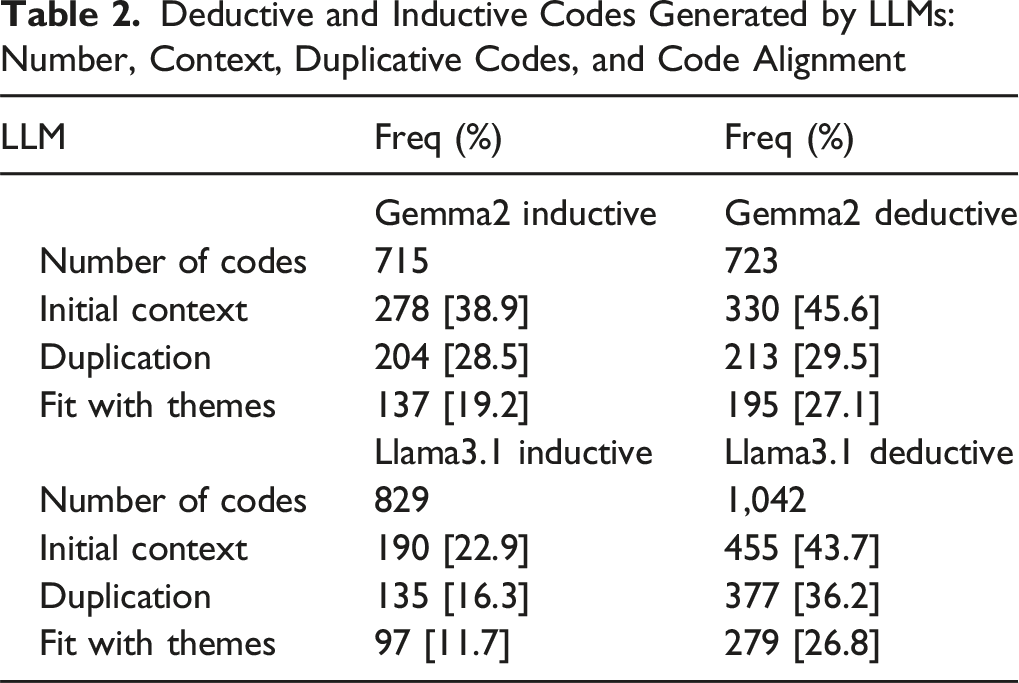
For a comparative analysis, the two qualitative researchers who coded the original transcripts evaluated the codes generated from the two LLMs and grouped them as (a) relevant to patient-provider communication when it provided context or not relevant (binary codes 0 and 1). If a code was ambiguous about the presence or absence of patient-provider communication characteristics, a third researcher applied a conservative interpretation of the codes for a consensus. Secondly, the two researchers evaluated the LLM-generated codes and identified them as (b) duplicative or not duplicative codes (binary 0 and 1) by the two LLMs. The idea was to note how many of the LLM-generated codes were similar to other codes but were listed as a new code by the LLM. For example, a generated code, “positive physician relationship,” was categorized as providing context (coded as 1) but duplicative of another generated code, “positive patient-doctor” relationship. The manual coding was applied for analyzing both LLM’s deductive & inductive codes. Inter-rater reliability between the two coders was calculated as percent agreement during this comparative analysis phase. There was 94% agreement between the two coders for the Gemma2 LLM deductive codes, 74% agreement for Gemma2 LLM inductive codes, 78% agreement for Llama3.1 LLM deductive codes, and 87% agreement for Llama3.1 LLM inductive codes. For codes in which there was initial disagreement on contextuality or duplicity, coders met to discuss until consensus was reached. In instances where consensus between the two coders could not be reached, a third researcher was consulted. We recorded the initial contextual analysis for inductive (n = 715 and n = 829 codes) and deductive (n = 723 and n = 1,042 codes) for Gemma2 and Llama3.1, respectively. We calculated the proportion of initial context versus no context codes for inductive and deductive analyses. The results of sample codes and proportion are shown in Tables 2 and 3 in the Results section. The two independent coders then reviewed all LLM-generated codes that were determined to have initial context for a second time to assess for fit with previously researcher-identified themes. Following this additional review of LLM-generated codes with initial context, the percentage of LLM-generated codes having “poor fit,” “partial fit,” or “good fit” per LLM was calculated. “Poor fit” refers to LLM-generated codes with no initial context; “partial fit” refers to LLM-generated codes with initial context, but no fit or alignment with previously researcher-identified themes; “good fit” refers to LLM-generated codes that do fit/align with researcher-identified themes. The descriptive data analysis for context & code duplication was conducted in the Statistical Package for Social Sciences 29.0 version.
Ethical Consideration
The study was conducted according to ethical guidelines, and the Institutional Review Board approved all procedures for this research study at a large public university. All participants provided written informed consent before participating in the semi-structured interview. In our experimental setup, we excluded ChatGPT to ensure our data remained private and secure without exposure to the internet. Interview data were imported from Microsoft Word into two LLMs – Gemma2 and Llama3.1 for code generation from interview scripts. After data pre-processing, the codes were generated from the interview transcripts for analysis.
Results
Analysis of Unique Codes Across Different Transcripts
We carried out experiments considering deductive and inductive frameworks to understand how codes are generated across different spectrums of prompting and qualitative frameworks. The analysis across different frameworks and models highlights a few distinct patterns in code generation. Comparing the deductive and inductive frameworks on Gemma2 reveals that both frameworks yield a comparable number of unique codes at the transcript level. This is precisely the opposite in the case of Llama3.1, where the deductive framework generates a noticeably more unique number of unique codes than an inductive framework, suggesting that deductive methods generate more insights than the inductive approach (see Figure 2). Table 1 shows some sample codes across different frameworks and LLMs. The count of unique codes and the total number of codes across different frameworks and LLMs are given below: Total number of unique codes Llama3.1 deductive: 1,042 Total number of codes Llama3.1 deductive: 2,040 Total number of unique codes Llama3.1 inductive: 829 Total number of codes Llama3.1 inductive: 1,632 Total number of unique codes Gemma2 deductive: 723 Total number of codes Gemma2 deductive: 1,666 Total number of unique codes Gemma2 inductive: 715 Total number of codes Gemma2 inductive: 1,530 Comparison of the total number of distinct codes for deductive and inductive frameworks across the Gemma2 and Llama3.1 models for chunk size of 20. (a) Gemma2 model. (b) Llama3.1 model Sample Codes for Deductive and Inductive Frameworks Across Different LLMs


Comparison Qualitative Researcher Identified Codes, Themes and Subthemes, versus Researcher Interpreted LLM Codes
Overall, there was alignment of LLM- and qualitative researcher-generated codes. The analysis across different templates and models highlighted a few patterns in LLM code generation. For example, a comparison of the deductive and inductive revealed that the deductive approach yielded more codes, suggesting that inductive methods generated broader or more nuanced insights from the patient interviews than the deductive approach. In addition, when we examined model performance for the deductive framework between Gemma2 and Llama3.1, the distribution of codes were found to be similar. However, in the case of inductive framework, it was evident that LLM codes were dissimilar and inconsistent in their code generation capacity or detail orientation. This suggests that while both the LLM models can capture themes, some LLMs may be more proficient at generating diverse or granular codes within the thematic analysis, particularly in the deductive approach for qualitative analysis.
Deductive and Inductive Codes Generated by LLMs: Number, Context, Duplicative Codes, and Code Alignment
Original Qualitative Research Themes, and LLM Derived Qualitative Researcher Interpreted Themes

aPPC = patient provider communication.
bLLM = large language model.
A comparison of the original study themes and subthemes with researchers’ interpretation of the LLM codes showed a consistent association with the two major themes: barriers and facilitators to patient-provider communication. First, we compared whether the LLM-derived contextual codes aligned with the researcher-identified themes and subthemes from the patient interviews. In the original study, thematic analysis was completed by two qualitative researchers independently coding selected chunks of the data that were relevant to the present study’s objective regarding patient-provider communication, discussed a coding scheme, and categorized codes to identify and define two significant themes – barriers and facilitators – that had emerged. Hence, the same researchers interpreted the LLM-derived codes that provided context to assess alignment with the original study themes and subthemes. The idea was to explore whether the LLM codes fit into the themes and subthemes and can provide saturation. In addition, we examined whether the LLM codes identified any additional theme or subtheme (objective) in addition to those identified by the researchers (subjective) to enhance further our understanding of factors that influence patient-provider communication. Through this next level of comparative analysis, the two independent coders determined that again, deductive frameworks generated a greater number of codes that provided greater alignment or “fit” to the previously researcher-identified themes (27.1% and 46.8% of the total generated codes by Gemma2 and Llama3.1, respectively) as compared to inductive framework codes (19.2% and 11.7% by Gemma2 and Llama3.1, respectively (Table 2). To summarize, codes generated by Gemma2 using a deductive framework were categorized as having poor fit (54.2%), partial fit (18.7%), or good fit (27.1%). Codes generated by Llama3.1 using a deductive framework were categorized as having poor fit (56.3%), partial fit (16.9%), or good fit (26.8%). Codes generated by Gemma2 using an inductive framework were categorized as having poor fit (61.1%), partial fit (19.7%), or good fit (19.2%). Codes generated by Llama3.1 using an inductive framework were categorized as having poor fit (77.3%), partial fit (11.3%), or good fit (11.7%).
Table 3 compares researchers’ derived themes from the original study with researcher-interpreted LLM codes for themes and subthemes. The researchers derived themes used the inductive method of coding the patient transcripts, broadly categorized as: (1) barriers for patient-provider communication (providers are disrespectful & talk down to patients, lack of continuity of care, inattentive and only “focus on the numbers,” lack of adequate time during appointments, inaccessible) and (2) facilitators (i.e., providers were positive and supportive, attentive, partnered with patients for clinical care, providers’ lived experience with diabetes, and participation in the lifestyle program improved knowledge, health literacy and empowerment.
Another objective of our analysis was to identify if there are emerging new themes from the LLM generated inductive codes, in addition to those identified by the researchers to further enhance our understanding of factors that influence patient-provider communication. We identified additional subthemes that supplement the researcher-generated themes and add depth to our knowledge of patient-provider communications. These included additional barriers, e.g., lack of provider’s trust, fear/discomfort/hesitation to discuss their disease, perception of providers’ limited knowledge, understanding, and lived experience, financial barriers, and lack of open communication by providers. Both inductive and deductive codes complemented these new themes. However, a few non-recurring codes that appeared once or twice and disregarded by researchers were identified by the deductive frameworks added (Table 3) i.e., patients feels guilty about burdening provider, fear/hesitation to discuss diabetes, age-related discomfort in discussing diabetes, and feeling abandoned by provider.
Analysis of Extracted Codes and Their Capability to Answer Research Question
We employed a systematic evaluation process to assess whether the codes generated by the Llama3.1 and Gemma2 models effectively addressed our research question. Subsequently, we utilized the Llama3.1 model with a specific prompt (see Appendix Figure 5) to classify each code segment as a “facilitator,” “barrier,” or “unrelated” according to the research question. We experimented on all the codes generated by both the frameworks (inductive and deductive) on both LLMs (Llama3.1 and Gemma2) for a chunk size of 20. This approach enabled us to determine the relevance of each code and the extent to which it contributed to answering our research question.
The plot (Figure 3) shows that there were many codes generated by the LLMs that lacked context and relevancy to address the research question specific to patient-provider communication facilitators and barrier. This may not be as evident initially due to the low proportion of “Unrelated” codes across all settings. In other words, codes generated using proposed coding frameworks should be interpreted with caution. Although a low proportion of “Unrelated” codes was part of the coding accuracy, it incorporated codes unrelated to patients’ facilitator and barrier to PPC (e.g., diabetes distress and self-care) and may serves as a valuable reference for researchers investigating LLM code generation for improving the process. Figure 4 shows wordcloud analysis for Gemma2-based deductive framework. Plot of unique code counts across Gemma2 and Llama3.1 models for inductive and deductive frameworks associated with researcher-identified themes (i.e. facilitators or barriers) or unrelated Wordcloud for Gemma2 model for chunk size of 20 (deductive framework) for barrier (a), facilitator (b) and unrelated (c) respectively

Comparison of LLM Generated Codes and Human Codes
Since our extracted codes using LLMs produced hundreds of codes, we wanted to analyze how close they are to codes generated by human qualitative researchers. For this, we leveraged Llama3.1 (see Appendix Figure 6) to flag those codes related to either of the eleven human-generated codes. Figure 5 shows that LLM generated codes cover 10 of 11 human initial codes. This distribution clearly shows which aspect should be given proper consideration. We could only track 10 of 11 human codes with hundreds of LLM-generated codes. Figure 6 shows sample llm generated codes that fall under respective human initial codes. Likewise, LLM generated codes highlighting additional patterns, including system-level inefficiencies (e.g., “Insurance Company Inefficiency,” “Insurance coverage adequate”), gaps in provider responsiveness and emotional awareness (e.g., “Healthcare provider awareness of emotional aspects lacking,” “Lack of provider knowledge and responsiveness”), and patient-experience nuances (e.g., “Program provided a sense of community,” “Treatment for anxiety”). These illustrative examples demonstrate the LLM’s ability to surface novel or underrepresented themes, adding depth to the qualitative analysis while maintaining alignment with expert-generated codes. Including these examples demonstrates how LLM-assisted coding can enhance qualitative depth without replacing expert judgment. Plot of distribution of LLM generated code across human-generated codes for Gemma2 deductive framework Samples of Gemma2 deductive framework-generated codes categorized under human-generated codes. These illustrate what we consider examples of good LLM outputs, closely aligned with human interpretations

Discussion
This study is among the first to explore the alignment and agreement of open-source LLM-generated qualitative codes with those developed by researchers. Our findings indicated limited code agreement. LLM generated codes provided limited contextual understanding and capability for conducting qualitative analyses of large-scale textual data from patient interviews. Assessment by qualitative researchers indicated that deductively generated codes (i.e., those guided by predefined frameworks) were more effective than inductively generated codes produced by the two LLMs. However, there was a poor alignment between the LLM-generated codes and the themes developed by human researchers. Gemma2 achieved only 27.1% fit with themes while Llama 3.1 achieved 26.8% fit. These low percentages suggest that while deductive approaches show promise, current LLMs still struggle to consistently match researcher-developed codes and themes in qualitative data analysis. Specifically, the LLMs were unable to fully capture the depth and contextual complexity of patient experiences, insights, and deeper meanings of patient-provider communication embedded in interview transcripts. Since we did not use coded data from human annotators as part of the LLM training, the comparison of the LLM and researcher generated codes (considered the gold standard in qualitative research) provides a robust comparison of using open-source LLMs for qualitative analysis in complex, real-world datasets.
Our exploratory investigation, replicating a prior qualitative study that examined facilitators and barriers to patient provider communications among 34 patients allowed a direct comparison of LLM-generated codes with those developed by qualitative researchers as well as assessing LLM model’s performance on initial coding of transcripts, chunk size and deductive versus inductive approaches to derive themes and subthemes. More specifically, an assessment of how LLMs perform the initial coding of qualitative transcripts offers valuable insights into their capability to extract relevant findings from complex qualitative data. We evaluated the models’ contextual understanding of barriers and facilitators by comparing LLM-generated codes with those developed by researchers, the proportion of meaningful versus duplicative codes, and thematic richness across different prompting strategies. These findings contribute to a novel understanding of how AI can support efficient and rigorous qualitative analysis. Our findings indicate that while the intersection of qualitative research and AI offer a promising avenue, future research should explore how pre-trained LLMs and multi-agent architectures for thematic analysis Player et al. (2025) and Qiao et al. (2025) can enhance qualitative methodolo-gies, by improving inter-rater reliability and enable faster, more efficient data analysis, while maintaining the analytical rigor and context sensitivity that is essential to research. Integration of LLMs into broader qualitative research workflows is an important topic, but is beyond the scope of this paper and warrants further investigation in future studies.
Despite the limited capability of LLMs to accurately captures the context, clarity/completeness as well as interpretation of patient-provider experiences, the LLMs generated a few additional codes that were missed previously by the researchers, that could have allowed strengthening themes or developing additional subthemes. This finding highlights the potential use of AI to compensate for potential researcher-bias or blind spots when it comes to qualitative thematic analysis. One of the most widely used strategies used in qualitative research to increase rigor and trustworthiness of the results is the use of multiple coders (Lincoln & Guba, 1986). Having multiple perspectives on the data from different coders helps to identify potential biases that might arise from a single researcher’s interpretation, leading to a more comprehensive understanding of the findings (Lincoln & Guba, 1986). However, this strategy often requires more personnel and time to complete analyses while accounting for additional resources required to train multiple coders, and the coding process. Our finding demonstrates that even LLMs that are not finetuned for domain tasks might be able to assist with this aspect of confirmability in qualitative analysis. Combining traditional qualitative analysis with LLMs as an additional coder (second or third) for generating codes is a promising innovative strategy to improve efficiency, strengthen or add context, reduce potential researcher bias and increase confirmability of results in qualitative research. It could also prove to be an efficient way of adding the reliability of traditional research process.
These observations align with broader literature on AI in qualitative research, which has highlighted both the promise and limitations of computational approaches for thematic analysis. Prior studies suggest that AI-assisted coding can enhance efficiency, provide supplemental perspectives to reduce bias, and identify patterns across large datasets (e.g., Bennis and Mouwafaq (2025); Cook et al. (2025); Christou (2024)), while still requiring human oversight to preserve context, nuance, and interpretive depth. Additionally, Player et al. (2025) and Qiao et al. (2025) showed use of pretrained LLM and multiagent improves accuracy and generates higher inter-rater reliability. Our findings extend this literature by demonstrating these dynamics in real-world interview transcripts focused on patient-provider communication.
LLM performance varies across different generations and is further influenced by the use of engineered, domain-adapted, and multi-agent thematic systems. While studies such as Qiao et al. (2025); Player et al. (2025) have demonstrated that employing multiple, separately trained agents and combined statistical modeling can lead to higher LLM accuracy, our approach for this study was intentionally simpler. It was designed to improve our understanding if the foundational LLM-generated codes from semi-structured interview data are similar to the researcher generated ones. This approach is novel as previous work has often used shorter, free-text data.
We used thematic coding and analysis for our comparison of patterns or themes within the interview scripts since it is recognized for its adaptability (across disciplines) and systematic identification, organization, and interpretation of codes. Applying both deductive and inductive qualitative analytic approaches, with or without predefined categories, allowed patients’ perceptions and experiences to be quantified from the transcripts by counting instances of codes, context and duplications, bridging the gap between structures of language and personal/societal narratives within healthcare or rural contexts. This process could be applied in a variety of fields in order to translate patient experiences for improved health outcomes. Although we experimented with various chunk sizes (i.e., number of paragraphs) and selected the most appropriate way to divide the interviews into multiple paragraphs, the manner in which the text is segmented may still influence how the model interprets the content. For example, our preprocessed transcripts contained interviewer questions and patient responses, were not separated, raising the possibility of confounding some extracted codes and coding accuracy. However, our chosen chunks incorporated many paragraphs at once, reducing this effect. A systematic evaluation of breaking interviews on paragraph-level effects, however, was beyond the scope of this study.
Our study evaluated LLM feasibility in qualitative research using basic indicators such as code, context, accuracy and fit metrices used for data visualization for patterns and themes. While LLMs showed promise, they had a lower inter-rater reliability with researcher generated codes and themes and failed to fully capture code coherence, context or depth. Developing metrics for these aspects of the qualitative research process are important for future explorations. In addition, the gold standard of using researcher developed codes to enhance validity, remains subject to researchers’ philosophical assumptions, bias and subjectivity, which we acknowledge as a limitation. Likewise, this study does not present a novel methodology. Yet, our findings offer valuable insights for biomedical informatics by demonstrating the practical application of thematic analysis and identifying opportunities to refine and enhance existing computational approaches more effectively.
Conclusion
Open-source LLMs show promise in assisting researchers in qualitative data analysis, particularly in generating initial codes for evaluation. Our findings also suggest the potential use of AI to mitigate researcher bias and address blind spots in qualitative thematic analysis. However, nearly half of the LLM generated codes lacked sufficient context, were repetitive, and had poor alignment with the themes developed by researchers underscoring the need for further research and the development of domain-specific LLMs.
Supplemental Material
Supplemental Material - Large Language Models in Qualitative Analysis: Comparing Traditional and Researcher-Interpreted Approaches
Supplemental Material for Large Language Models in Qualitative Analysis: Comparing Traditional and Researcher-Interpreted Approaches by Ranjita Misra, Rajashree Dahal, Brenna Kirk, Raihan Khan, Gizem Dogan, Robin Chataut, and Prashnna Gyawali in International Journal of Qualitative Methods.
Footnotes
Acknowledgements
The authors acknowledge and thank the diabetic patients who participated in this study.
Ethical Considerations
This work has been carried out in accordance with The Code of Ethics of the World Medical Association (Declaration of Helsinki) for experiments involving humans. The parent study was approved by the West Virginia University Institutional Review Board (IRB Approval Number: 1908672206) on 04/12/2021.
Consent to Participate
Informed consent was obtained twice in accordance with the approved IRB protocol. First, participants provided consent for their involvement in the intervention and associated assessments. Subsequently, a second round of consent was obtained for participation in semi-structured interviews and focus groups aimed at gathering feedback on the intervention.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the DARPA AI CRAFT (AWD16069), in part by the National Institute of Nursing Research (1R15NR016549), and by a challenge grant from Research to Prevent Blindness to WVU.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Due to privacy concerns, the interview transcripts from diabetes patients used in this study cannot be shared publicly. Researchers interested in accessing the data may contact the corresponding author, Dr. Prashnna Gyawali (email:
Supplemental Material
Supplemental material for this article is available online.
Note
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.