
Abstract
The Gender and Adolescence: Global Evidence programme is a decade long cross-country longitudinal study of adolescents in low- and middle-income countries. The programme’s large sample size and variety of contexts make it an important case study of how to deal with large and complex qualitative datasets. In this methodological article, we explore some of the challenges and opportunities that occur when working with large datasets of longitudinal qualitative research. We provide examples of lessons learnt during GAGE data collection, coding, analysis and data management. This paper also explores the use of the qualitative data analysis software MAXQDA for simplifying the analysis of longitudinal data and providing opportunities for novel analytical techniques. We find that large longitudinal qualitative datasets can provide extremely rich and detailed data; however, there needs to be attention to key processes to ensure rigour and effectively utilise the breadth and depth of the data. These include mechanisms to work effectively with large teams of researchers, strong data management and coding procedures, and using qualitative software to manage and simplify data.
Introduction
Overview of Countries and Data Collection Points.

Literature Review
Large datasets of qualitative longitudinal research (QLR) are extremely useful in understanding the complexity of transitions at different stages in the life course and they allow comparisons of different groups (based on factors such as age, location, citizenship status, education, etc.) across the dataset (Baird et al., 2021c; Banati, 2021; Devonald & Jones, 2023; Thomson & Holland, 2003). Despite these benefits, researchers undertaking QLR highlight that the complexity and quantity of data is a key challenge and requires labour-intensive processes during all components of the research (Thomson & Holland, 2003; Thomson & McLeod, 2015; Tuthill et al., 2020). To address these challenges, methods have been developed to tackle this complexity.
From a data collection standpoint, the long time period of QLR allows researchers to build trust with participants over multiple interviews, resulting in richer data (Solomon et al., 2020). However, there are some ethical challenges to consider when conducting longitudinal research. Although most of the ethical challenges involved in a longitudinal study apply to other qualitative studies, they are heightened in a longitudinal study due to the length of time of the research process, which requires higher levels of reflexivity (Thomson & Holland, 2003). The increasing familiarity and trust that ensues as a result of this longer timeframe can present significant ethical challenges (Holland et al., 2006). For example, there can be challenges maintaining participant–researcher boundaries that can result in emotional dilemmas when the study ends (Batty, 2020; Thomson & Holland, 2003). For longitudinal studies with children and adolescents, the ethical issues are particularly salient. Warin (2011) highlights the importance of gaining and maintaining consent during longitudinal studies as an ongoing process rather than a one-off activity. That same study also shows that researchers need to develop their awareness and capacity for reflexivity and ethical mindfulness during longitudinal processes.
Analysis is a particularly time-consuming part of the research process (Tuthill et al., 2020). Fadyl et al. (2017) describe the risks of inadvertently simplifying the data when working with large volumes, and suggest a number of ways to mitigate this, such as data visualisation techniques and using sub-analysis. Similarly, Sanip (2020) suggests investing in appropriate software and maintaining reflexivity. When managing large amounts of qualitative data, White et al. (2012) recommend using audit trails to keep track of any changes during data analysis, meeting regularly with the research team, carefully developing the coding framework and ensuring sufficient research training.
Researchers have developed many innovative methods to aid the analysis of large qualitative datasets, including multiple phases of data analysis. Abraham et al. (2021) used a three-phased approach. First, data reduction techniques through the use of summary templates were used to summarise the data organised by domains and categories that had been agreed previously. Matrix displays were then used to understand similarities and differences across participants. Finally, summary tabulations techniques identified the frequency of words or phrases pertaining to the conceptual domains, in order to reduce errors in human bias. Additionally, Winskell et al. (2018) used a combination of a narrative-based approach, thematic keywords and thematic qualitative data analysis.
A key challenge when analysing large qualitative datasets is preserving ethnographic richness and trustworthiness of data, while collecting and analysing the research in the available time and within resource constraints. Working with large teams can help analyse large amounts of data in shortened timeframes (Sanip, 2020; Solomon et al., 2020). However, to increase trustworthiness, methods such as reviewing work and meeting as a team regularly are required (Abraham et al., 2021) as well as planning effectively from the outset and including strategies to ensure consistency when coding (Solomon et al., 2020).
In recent years, technologies such as QDAS have offered qualitative researchers useful tools to improve the research process and they are particularly useful when dealing with large samples. The benefits of using QDAS include added confidentiality and streamlining the research process into a single platform (Oswald, 2019). However, others have noted that there is a risk of oversimplification of the data (Leitch et al., 2016) or rigid automated analysis that lacks nuance (Bringer et al., 2004). It also requires researchers to have extensive training in how to use QDAS (Oswald, 2019).
Challenges around data management are also more likely to occur in longitudinal studies, due to repeated interactions and increasingly growing datasets. It is imperative that there are strong data management processes in place to account for this (Corden & Millar, 2007). Neale and Hughes (2020) state that it is an “interpretive process, with ethical and epistemological implications that need to be carefully considered at the outset and addressed as an integral part of a project” (p. 30). They present six areas of good practice: data management planning; archiving informed consent; producing high-quality data files; organising data; ethically representing data; and archiving datasets. Additionally, translation and transcription are two components that are integral to the research process, yet gain limited attention. When working with large datasets, it is important to ensure that procedures are in place to minimise errors in translation and transcription, including robust quality assurance mechanisms (Davidson, 2009; Sutrisno et al., 2014).
Attrition is another key consideration in research that has been conducted over multiple years. To mitigate this, Farrall et al. (2015) suggest building and maintaining strong rapport with participants by making sure that the researcher who locates and contacts the participant is the one who interviews them, and keeping contact sheets for each case. Similarly, Hanna et al. (2014) highlight the importance of fostering positive relationships with participants, having user-friendly data collection approaches, and maintaining contact with participants in between data collection rounds. However, it is important to ensure that measures to minimise attrition do not lead to issues with consent and respecting participants’ wishes should they wish to leave the study at any point (Corden & Millar, 2007). There is generally limited evidence on best practices for managing and analysing large qualitative datasets, and many studies do not publish their analytical methods. This article aims to contribute to the literature by providing a clear account of the methodological procedures of a large, complex, qualitative longitudinal study. It aims to provide insights through outlining challenges and lessons learnt for the broader field of researchers conducting complex qualitative research, and especially longitudinal qualitative research.
Overview of the Gender and Adolescence: Global Evidence Programme
This paper uses examples of qualitative longitudinal research conducted by the GAGE programme. This is a decade long, longitudinal, mixed-methods study of adolescent boys and girls aged 10–19 at baseline, which aims to understand “what works” to support their development and empowerment as they transition into adulthood (Baird et al., 2021a). It spans seven different contexts: Ethiopia and Rwanda in Africa; Bangladesh and Nepal in Asia; and Jordan, Palestine and Lebanon in the Middle East. The mixed-methods sample comprises 20,000 adolescents and caregivers, of which 3,718 are in the qualitative component (2,386 adolescents, 314 caregivers 767 community members and 251 key informants) (See Table 1). This is a very large qualitative research sample, as can be seen in Annex 1, Table 3, which provides an overview of the GAGE sample in comparison with other longitudinal studies that use a qualitative methods component.
The programme includes an evaluation component and assesses what kinds of interventions are more effective in supporting adolescents to develop their full capabilities. For example, in Jordan, the programme evaluates the impacts of UNICEF’s Makani programme, which provides a wide range of education, child protection and life skills support to refugee and host community children and adolescents (Banati et al., 2021; Presler-Marshall et al., 2022).
In line with the 2030 Agenda for Sustainable Development’s commitment to leave no one behind, our sample includes groups of adolescents that are often excluded from research, such as adolescents with disabilities, early married adolescents, adolescents affected by displacement and out-of-school adolescents (Guglielmi et al., 2022).
Conceptual Framing and Analysis
The GAGE conceptual framework (GAGE consortium, 2019) rests on “3 Cs” – capabilities, contexts and change strategies. It builds on theories of capabilities outcomes first coined by Amartya Sen (1984, 2004) and developed by Martha Nussbaum (2011) and Naila Kabeer (2003) to explore the kinds of assets that individuals need to live valued lives. The GAGE framework (Figure 1) focuses on six capability domains: education and learning; bodily integrity and freedom from violence; health, nutrition, and sexual and reproductive health; psychosocial well-being; voice and agency; and economic empowerment. It also highlights the importance of adolescents’ contexts at the individual, family or household, community, state and global levels. Finally, it recognises the importance of a number of change strategies designed to improve adolescents’ outcomes, such as empowering individuals, supporting parents, promoting social norm change and strengthening services (GAGE consortium, 2019). Analysis of the GAGE programme data used a thematic approach, informed by the GAGE conceptual framework, and will be discussed in more detail below. GAGE Conceptual framework.
There are a number of components to the GAGE programme that make it unique and a useful case study. First, it is the largest cross-country dataset on adolescence in LMICs, (see Table 1), and is conducted over a long timeframe (10 years). These unique traits result in rich and complex data; however, they also bring many challenges, particularly for the data analysis and data management stages. While the majority of the GAGE research has been conducted in-person, the Covid-19 pandemic meant that online interviews were conducted during lockdowns in 2020 and 2021.
All examples included in this article are anonymised; informed consent was obtained from adult participants, and informed assent from respondents under the age of 18, as well as informed consent from their caregivers. Ethical approval for the research programme was secured from institutional and regional ethics boards.
Strategies for Dealing with Large, Growing Datasets
Summary of Methodological Challenges During a Large Qualitative Longitudinal Study, and Suggestions/Lessons Learnt on How to Address Them.

Data Collection
The benefits of having a large sample size for longitudinal qualitative data is that it allows the collection of data from a wide range of different groups in order to ensure breadth of the data. The GAGE sample includes a sub-sample of the most marginalised adolescents, including early married girls, adolescents with disabilities, adolescents affected by displacement, and out-of-school adolescents. When collecting such large and complex qualitative data, often under strict time constraints (due to donor and programming requirements), it is vital to have a large team conducting interviews. A key challenge when working in a large data collection team is ensuring consistency during data collection. In order to facilitate this, GAGE conducted detailed training sessions before every data collection round, and researchers were provided with clear and detailed interview guides. The research teams role-played these tools ahead of piloting them in the field, and peers critiqued the role-play and pilot findings. Frequent and detailed debriefings were also conducted with the teams after data collection in each location to explore any emerging findings and to discuss any issues that arose during data collection, as well as approaches to tackling unforeseen respondent reactions or insights.
When conducting research over a long time period, attrition is a major methodological problem, especially where young people are living in diverse contexts, impacted by crisis and rapid changes, and in some cases resulting in high levels of domestic, cross-border and international migration. It is important to build strong relationships between researcher and participant so as to be able to mitigate attrition and to be able to follow young people in such dynamic timescapes. It is also vital to invest in good communication with community facilitators who can help to provide contact information for young people and their families over time, and information on whether they have moved.
Participatory research methods are also a useful tool as they allow participants to be more involved in the research and to develop agency as part of the research. It can also help prevent research fatigue. A girl from Lebanon taking part in participatory research explained her view: “I feel it’s something beautiful [taking part in the programme], I mean, I don’t know, I learnt from it. It develops the person, and lets them learn new things – for example, we were going about the community to take photos and interview peers and family members for participatory photography.”
Sharing research results from previous data collections rounds can also allow participants to understand the results and outcomes of the research, and the value of the research they are supporting. GAGE has emphasised that it is important to communicate research findings in easily digestible formats in local languages, including through the use of short brochures and infographics.
Developing a Codebook and Strategies for Coding Longitudinal Data
Coding can be used as both a first step of analysis and as a tool to simplify and manage large datasets. To allow easier data management, we coded interviews using the qualitative software programme MAXQDA.
The main codebook is informed by the GAGE conceptual framework and codes are broken down per capability domain (education and learning; bodily integrity and freedom from violence; health, nutrition, and sexual and reproductive health; psychosocial well-being; voice and agency; and economic empowerment). Due to GAGE’S cross-capability approach, the codebook is extensive and comprises 18 main codes and more than 200 sub-codes. Initial coding allowed us to easily identify coded segments based on a specific capability; however, further coding is needed for in-depth analysis. For example, our codebook includes codes to capture climatic events that shape adolescents’ lives such as drought, as well as codes to capture caregivers’ parenting of adolescents. We take both a deductive and inductive approach to coding. The codebook is initially set up from the qualitative research tools; before coding, we make sure to test the codebook on the transcripts to get feedback on how well the codebook worked and if any additional codes were needed. The coding framework also remains flexible during the coding process to allow new codes to emerge from the data.
The longitudinal nature of the programme also means that the codebook can shift over time, because particularly as adolescents get older, certain codes become more prominent. For example, for younger adolescents, the “paid work” code focuses on child labour; however, for older adolescents, the focus is instead on how they establish their own livelihoods. Where codes become more prominent in the analysis at later stages, we add sub-codes to further differentiate the data. For example, initially we included a single code for sexual violence; however, in subsequent versions of the codebook, we added sub-codes to differentiate between verbal sexual harassment, online forms of harassment, inappropriate touching, and rape.
The definition of codes can also shift over time. An original code at baseline was “peer pressure/interactions that reasonable adult would judge negative.” However, while coding, we found that much of the discussion for older adolescents focused on anti-social behaviour such as drug dealing and carrying (but not using) guns, which did not fall under any of the key codes (such as actual experiences and acts of violence). As there were not many examples of peer pressure in the data, we decided to broaden this code to also include examples of anti-social behaviour. Any changes to the definition of the codes during the course of the research were recorded clearly and updated in both MAXQDA and in a Word document overview of the codebook to ensure clear audit trails.
In order to capture the longitudinal nature of the research, specific codes were included to track key changes experienced by adolescents based on key events or life-course developments. For example, at midline we introduced “Most Significant Change” codes for each capability domain. This code aims to capture what adolescent participants identify as the event or experience that has made the most difference in their own lives between baseline and midline. We also have an array of “time difference” codes that allow us to capture change over time that the respondent identifies as being due to internal development (e.g. a 16-year-old has different capacities than a 12-year-old) or external events (e.g. the war in Ukraine has led to food price inflation).
It is important to take into account the country context when analysing data (Eakin & Gladstone, 2020). Regional specificities are also defined in the codebook with examples of what to be aware of in each country context. In certain contexts, specific capability sub-themes may be more prominent. For example, in Bangladesh, Jordan and Lebanon, a large proportion of the sample are refugees and so we have added codes for these contexts to capture legal differences in refugees’ access to work and services. In Ethiopia, we have added codes to capture the impact of the conflict, including young people who become internally displaced as a result of it.
The GAGE programme considers the impact of intersecting inequalities (such as age, gender, marital or disability status) on adolescents’ capabilities. In order to explore this, we included a set of “differences codes” to easily identify key differences that are discussed or emerge from the data based on gender, age, location, disability, marital or refugee status. These quotes are always double coded with a main capability code. For example, Figure 2 shows an example of an adolescent refugee discussing the gendered reasons why her father did not allow her to study when she arrived in Jordan, and so it is coded with “education and learning – drop out” and “gender differences”. During the analysis, this makes it easier to select quotes
2
that discuss gender differences for each capability sub-theme. Example of the gender differences code.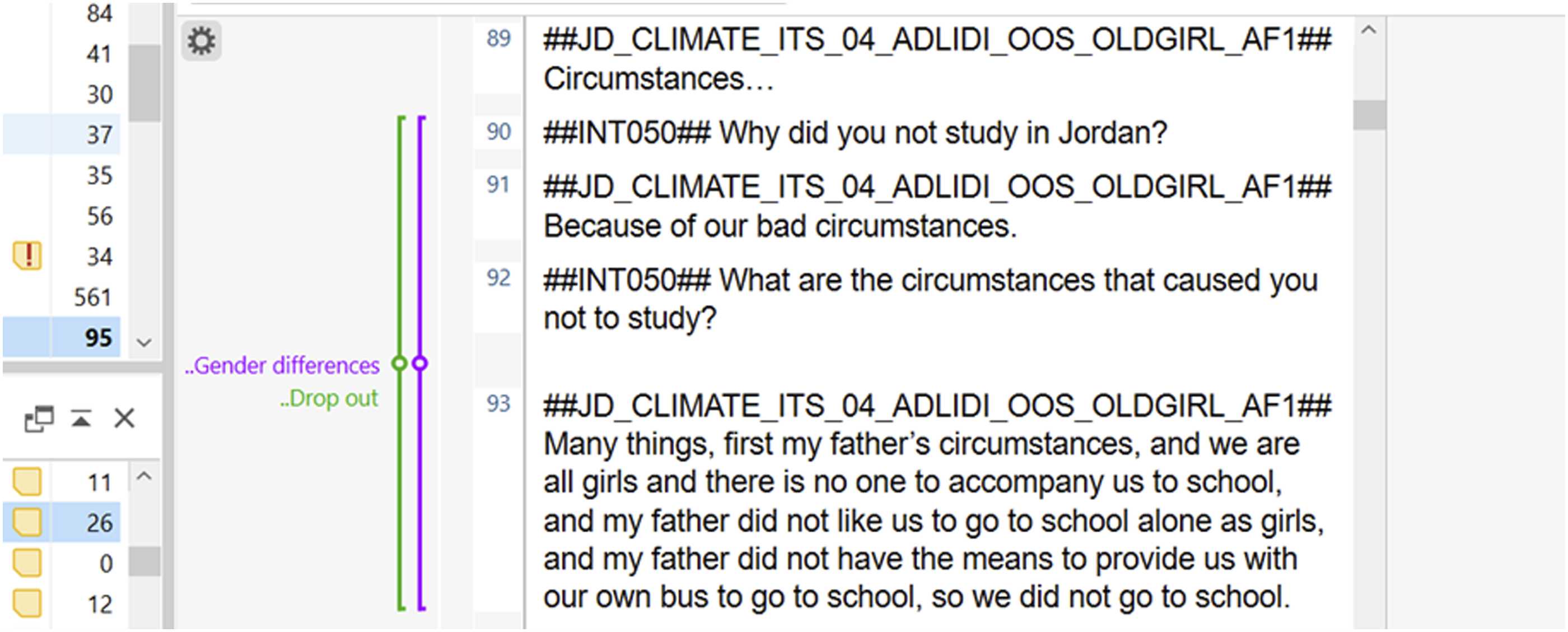
Researchers use a number of strategies to keep track of particularly interesting quotes or interviews. We included a “great quotes” code in the codebook to identify particularly eloquent or powerful quotes that are useful to include in the report writing. Again, they are always double coded with the main capability code. Additionally, after coding each interview, each coder is required to include a short summary of the key themes the interview covers. This is coded with the “interview overview” code, which can also be useful for easily identifying transcripts at later stages and gaining a quick overview of the main topics and findings from each interview. It can be particularly useful for identifying case studies. For example: “
A key component of the GAGE programme is evaluating adolescent-focused programming in our core countries, including UNICEF Jordan’s Makani programme and Act With Her, run by Pathfinder, in Ethiopia. The codebook includes separate codes for these programmes so that we can pull out programme impacts. The codes were again split by capability domain. These codes were kept consistent over the course of the longitudinal research to make it easier to compare longitudinal differences in programming.
Ensuring Rigour and Consistency When Coding
Due to the volume of data and the time-intensive processes of coding and analysis, we work as a team of approximately six internationally based coders. Before we start coding, we send overview documents of context information to the coding team, including analysis from past rounds and debriefing notes from the field (which capture researchers’ impressions of the fieldwork process and context-specific dynamics, especially issues that may not be explicitly discussed in the interview transcripts but that are important to contextualise interpretation), paying special attention to onboarding new members of the team who may not have been involved in previous data coding rounds. Where possible, researchers are given the same type of transcripts to code in the dataset either split by nationality or location, so that they can gain insights into the key themes from that particular sub-set.
The coding team is often different from the data collection team. However, for some countries, researchers are involved in both the data collection and coding. To avoid any inconsistency as a result of this, detailed debriefing notes from data collection are also shared with the coding team to provide additional context. Country-specific terminology that coders might be unsure about are checked with the data collection team to provide context. For example, the term fiema is often used in Ethiopia to refer to a collective of adolescent male peers in Afar culture, and is a grouping that holds particular importance as adolescents transition through puberty and into early adulthood.
While working as a team it is important to ensure consistency during coding. Before coding, members of the coding team receive extensive training on coding in MAXQDA, including interactive training on its use and functionality. Initially, coded transcripts by new coders are reviewed and double coded by a senior member of the research team until they have reached the requisite quality standards.
The complexity of the codebook and its evolution over time also means that it is important to keep track of any changes that are made. To ensure that all team members are clear about what each of the codes represents, full descriptions of each code are included in the codebook and shortened definitions attached to each code as memos within MAXQDA. The codebook also includes concrete examples which are tailored to each context. Because it is vital that team members communicate clearly and effectively to discuss any challenges and emerging findings during the process of coding and analysis, we also conduct weekly coding meetings with senior researchers and the coding team to discuss any discrepancies in the data and to agree on any coded segments researchers are unsure about. In these meetings, key emerging themes and interesting case studies are discussed. Any changes agreed upon are recorded in the meeting log and updated in the codebook.
A key challenge of coding is that it removes the words of the transcript from the original context of the interview. In order to address this, coders are encouraged to use the comment function to add additional context to each quote. This comment can be viewed alongside the quote during analysis both in Excel and MAXQDA to provide vital information to the research team. This can flag to other researchers any useful contextual information that is learnt in earlier parts of the transcript, or to flag why the coder has used this particular code. In Figure 3, an adolescent is talking about why she cannot go to Makani programme classes every day; however, the reason she states is unclear without additional context. The comment provides information to explain why her financial circumstances do not allow her to go to the Makani programme every day (being the sole provider for her family and working long hours). Examples in MAXQDA of using the comment function.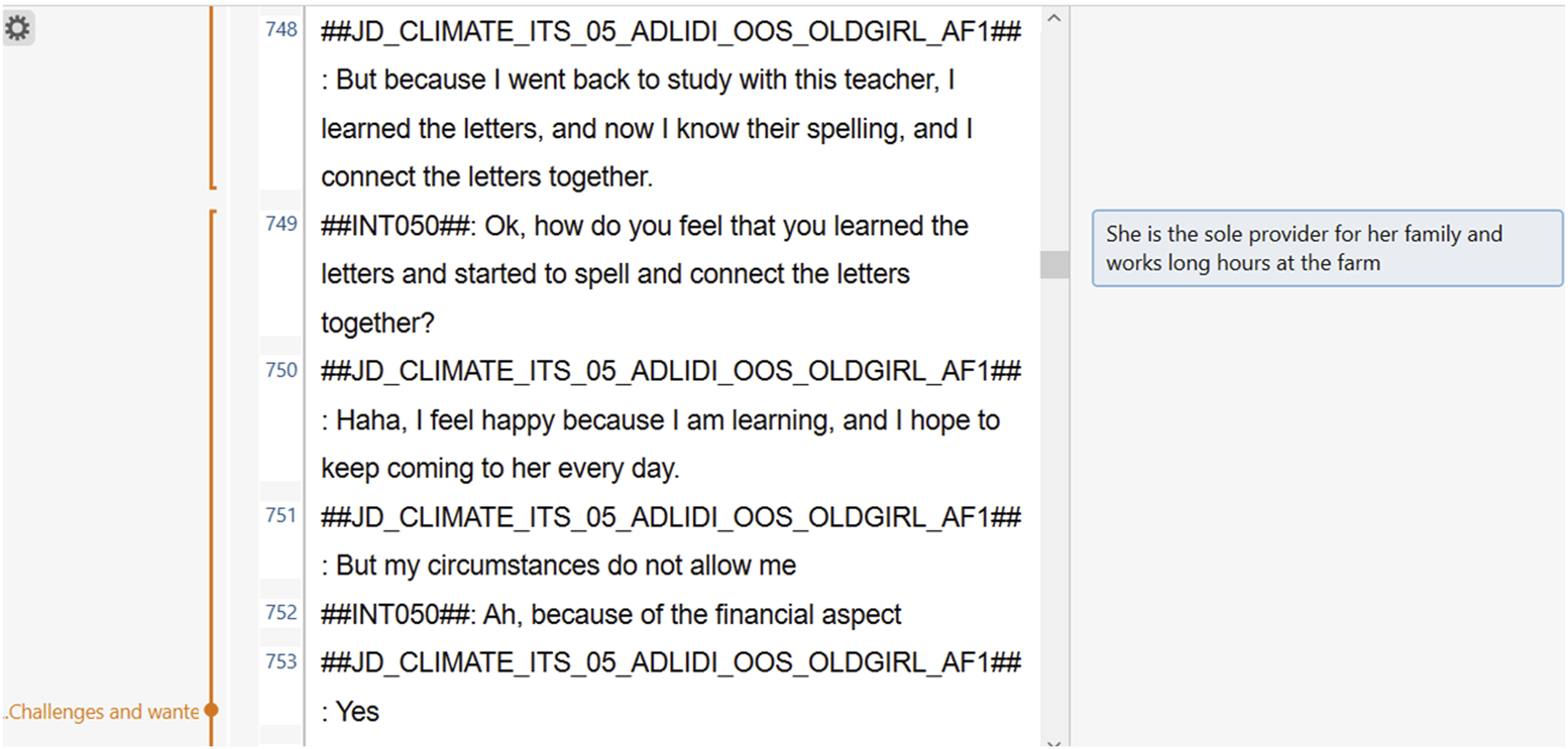
When dealing with very large qualitative datasets, coding can take a significant amount of time. A key lesson that we have learnt is the importance of scheduling enough time to analyse the data. Often, we underestimate the time it will take to code data, especially given the complex and long interviews conducted as part of the participatory research. It is also important to develop clear timelines and ensure that coding progress is closely tracked.
It is particularly important to ensure rigour and accuracy when coding transcripts that pertain to programme evaluations. However, we experienced key challenges during coding when, during the interview, it was unclear whether the participant was referring to the programme that was being evaluated or another programme in the community. Often, participants would use different terminology to describe the programme (for example, in Afar, Ethiopia, participants would refer to the programme by the name of the teacher rather than referring to the intervention by its formal name, Act With Her) or in areas that have multiple types of similar programming, participants would not always specify which programme they were referring to. A group of fathers in Ethiopia explained how in areas where there are a lot of different programming activities, it can be difficult to differentiate: “The other thing is we don’t identify what other teachers and [name of the programme supervisor from Act With Her] teach our children. We know that whoever comes here to the children, we consider it as one, we never think that there may be a difference between what she and others teach our children.” Therefore, it was important to keep consistent communication with the data collection team to confirm emerging results, ensure that interviewers were asking for clarity wherever needed, and to try to differentiate as carefully as possible between programmes. During analysis, it is important to only attribute an impact to a programme if it is clearly stated in the interview.
Thematic Analysis in Excel
Although we use MAXQDA to code the data, due to the volume of data, we often find it useful to export specific codes and participants’ corresponding demographic information from MAXQDA into Excel during thematic analysis using the “export to Excel” function. This allows us to explore coded segments (based on a combination of different codes or transcripts) and any key demographic characteristics in Excel. Using the filters function in Excel allows us to select quotes based on different combinations of demographic characteristics – such as gender, age, location or programme enrolment – quickly and efficiently (see Figure 4). Although working in MAXQDA also allows the selection of different demographic features, due to the size of our dataset we find Excel more efficient to work with at the thematic analysis stage. During this stage, we often conduct additional informal coding of the data, which further categorises it while working on a specific project. The example shown in Figure 4 includes coded segments from the “health during Covid-19” code which have been further differentiated to look at the impacts on menstrual hygiene. Overview of quotes on menstrual health during Covid-19 in Excel.
Data Management
When conducting a large volume of interviews, transcription, translation and data cleaning are also a significant challenge and it is important to schedule enough time to transcribe, translate and quality assure the translation of the interviews. Strong monitoring systems are required to track any data inconsistencies, with clear communication between the data collection teams and the data manager. Clear timelines and planning are also needed in order meet strict deadlines.
When conducting longitudinal studies, it is vital to be able to track each participant across datasets. To make this process more straightforward, each adolescent has a unique respondent identity (ID) number in their file name that can be searched across datasets. Participants in the same family (caregivers and siblings) also have the same household number to easily identify members of the same family. An important lesson we learnt through this process is to include enough detail in the transcript file names. Initially during baseline, transcript file names lacked sufficient information and only included the respondent ID, gender and interview type. This made it challenging to quickly identify key attributes of the participants. To address this, we revised the file names to include participants, data collection round, gender, location, age range (older or younger), and other key attributes (such as being married or having a disability). For example, the file name 2020504030108_ADLIDI_BOY was updated to ET_MQ1_DAL_2020504030108_ADLIDI_YNGBOY.
Although the process of revising the file names was very time-consuming, the end result meant that data management and tracking was significantly easier during subsequent data collection rounds. During our Covid-19 data collection, we also included the date of the interview, due to multiple interviews occurring during a small timeframe, which again made it easier to track the order and time distances between the transcripts. Due to the fast-changing lockdown restrictions and guidance during that time, having the interview date in the file name made it easier to contextualise the interview in the current context.
An additional challenge we encountered was that due to the large amount of data, it can be very time-consuming to track data management issues. To address this, we included a code used to tag errors in the transcript or transcript logfile. This code was extremely useful for data management purposes as it allowed us to quickly identify any discrepancies in the data. Participant information was recorded in the transcript logfile and on the top of the transcripts. Before coding, the coding team reviewed the demographic information for each participant in the transcript logfile. If any information in the transcript does not match this information, that code is applied. At the end of each coding round, this code was reviewed and any key discrepancies noted in Excel and relayed to the data manager to check the correct participant information and update the logfile or the transcript (see Figure 5). This code is also useful for locating any problems in transcription, poor interviewing technique, or ethical issues such as any confidential information that has not been removed from the transcript. Finally, this code is also useful to review for future training purposes for the data collection team. Flag to locate problematic transcript code.
Due to the programme evaluation component of the GAGE research, adolescents’ programme participation is an important attribute to track over time. Many adolescents in our sample dropped out of the programme between baseline and midline so it was important to track previous enrolment in the programme, current enrolment in the study, and how long they attended for.
Due to the sheer volume of data, we experienced many challenges when managing datasets. In some cases, due to the large amount of data stored in one MAXQDA project, files were slow and difficult to open. To address this, we also created smaller sub-projects based on locations that can be used for sub-analysis. As our datasets grew, we produced a large amount of separate MAXQDA files for each country and data collection round. Each of these were uploaded onto an approved encrypted cloud-based content management and file-sharing tool and entered into a tracking spreadsheet. When analysing data for cross-country comparisons, it is useful to create a merged MAXQDA project. One key issue identified was a lack of consistency of the variables across countries. Often, the name of a variable would differ by country – for example, the variable for whether the participant is in school could be called “school status”, “is the adolescent in school?” or “in or out of school?” When merging these files with inconsistent variables, analysis can be challenging, as these variables will present as three separate variables, when they should present as one. In order to mitigate this, variables should be named consistently to allow cross-country datasets to be analysed more easily.
Discussion
In this article, we have outlined some of the key challenges and benefits of working with large datasets of cross-country, qualitative longitudinal data, using examples from the GAGE programme – a decade-long study of 20,000 adolescents across seven contexts. There is a lack of research on how to manage large datasets of qualitative data (Brower et al., 2019; White et al., 2012). To help address this gap, we have critically reviewed our experiences during data collection, coding and analysis, and data management, in order to offer insights to the wider research community interested in qualitative longitudinal research.
Although most qualitative studies have relatively small sample sizes, the GAGE qualitative sample is very large because of its focus on intersectionality and the overriding aim to capture the voices and perspectives of adolescents from diverse sub-national locations and marginalised groups, such as refugees, those with disabilities, out of school adolescents, married girls, adolescent parents, and those living in urban as well as remote rural areas, including pastoralist communities. Such large qualitative datasets can have important benefits, providing more inclusive, collaborative data that has increased transferability (Brower et al., 2019) and which can also more effectively facilitate data saturation. Indeed, we found that working with large samples during qualitative longitudinal research can be useful in providing rich data from a range of participants and contexts, allowing us to explore key differences in the experiences of marginalised adolescents, as well as data on the mediating effects of programme interventions. The large sample size allowed us to have a sufficiently high sample within each of our sub-populations to make robust comparisons between and within groups. For example, in Jordan we have a sample of 40 married girls in our main sample, this allows us to compare and contrast the experiences of different sub-populations of married girls based on nationality (Jordanian, Syrian, Palestinian), locality (camp, host community, informal tented settlement) and parental status.
However, in order to ensure rigour and trustworthiness in the research, our findings underscore the need for some key data management strategies and mechanisms. Aligning with the literature (Sanip, 2020; Solomon et al., 2020), we found that when working with large volumes of qualitative data, a sizeable team of researchers is required at all stages of the research. In order to address any inconsistencies within data collection and coding, GAGE ensures that researchers are appropriately trained; there is regular and clear communication across the coding team and with the data collection teams; robust quality control processes and checks are in place; and any changes are clearly agreed on and recorded in meeting notes that are stored in a shared file for easy access and cross-reference purposes.
When coding large and growing datasets, the codebook itself can become extremely large and complex, and can evolve over time. GAGE has shown the importance of ensuring that these changes are tracked and recorded, and that there is agreement on the meaning of each code, with regular communication with the coding team. For robust data coding, appropriate training of coders in key concepts, quality assurance and double-coding of a subset of transcripts to ensure inter-coder reliability are all critical considerations. Working in large teams can be useful to provide multiple perspectives and interpretation of the data, and increase collaboration (Thomas et al., 2000). However, a significant challenge of working in a large team is the risk of losing contextual richness and emphasis on the cultural outsider perspective in some parts of the research process (Brower et al., 2019). In an effort to mitigate this, GAGE routinely undertakes debriefings after data collection in each sub-national study location and also consistently co-author articles with colleagues involved in the in-country data collection.
Qualitative software can be useful when dealing with large qualitative datasets, however it can bring risk of oversimplifying the data and requires extensive training (Leitch et al., 2016; Oswald, 2019). The use of the qualitative data analysis software MAXQDA is instrumental to the GAGE research, as it allows us to simplify and manage large amounts of qualitative data. We used a variety of functions to aid both coding and analysis, including providing an “interview overview”, using differences codes to make it easy to identify segments that describe key differences by gender, age or socioeconomic status, and exporting quotes to Excel to allow further exploration by document variables. MAXQDA is also vital to our data management process, and including codes to tag any data management issues ensured that we were able to quickly identify any discrepancies in the data.
Programme evaluation is another core component of the GAGE programme and can bring additional challenges such as difficulties in attributing impacts to the programme being studied (especially in contexts where there are multiple types of similar programming) and tracking changes to participants’ enrolment in the programme over time. We mitigated these challenges through detailed training and regular communication across teams, including during the data collection process. In addition, having multiple country contexts adds additional complexity, and it is important to ensure regional specificity in the codebook while simultaneously ensuring that variables are named consistently to allow cross-country comparison.
While this article has predominantly focused on handling large datasets at the coding stage, the approaches discussed can also be applicable to later stages of analysis and write up, such as working with large teams of researchers and using MAXQDA to make the data more manageable to easily shared across research teams. We also utilise sub-analysis of these datasets to ensure the richness of the data is accurately captured (Devonald & Jones, 2023). MAXQDA can have a number of benefits for analysing large data sets at that stage, including the use of visual tools that can provide matrices and maps of the coded data. However, a detailed exploration of this goes beyond the scope of this paper.
It is also worth reflecting on the costs of large-scale qualitative research and ensuring that such work is adequately resourced to ensure quality. Research costs vary depending on the context but given that qualitative research requires deep contextual understanding of the relevant concepts under investigation, it is essential that there is adequate time for training, familiarisation with the tools and piloting of the tools. Where possible consideration should also be made to involve researchers from the local communities and with the necessary linguistic skills to undertake the research, including, for example, persons with refugee backgrounds to undertake research with persons affected by forced displacement. In addition, organising daily and research site-specific debriefings among the research team to discuss and reflect on emerging themes and questions is also very valuable to ensure adequate probing around complex issues.
In sum, large qualitative datasets of longitudinal research can provide extremely rich and detailed data; however, care is needed at all stages of the research process to ensure that the richness of the data is effectively utilised. This article has provided unique insights into the range and complexity of the opportunities and challenges involved with such large qualitative datasets, using lessons learnt through GAGE to suggest approaches that researchers can use to mitigate the challenges.
Supplemental Material
Supplemental Material - Possibilities and Pitfalls for Dealing with Large Longitudinal Qualitative Datasets
Supplemental Material for Possibilities and Pitfalls for Dealing with Large Longitudinal Qualitative Datasets by Megan Devonald and Nicola Jones in International Journal of Qualitative Methods
Footnotes
Acknowledgments
The authors wish to thank Kathryn O’Neill for her copy-editing work, the GAGE qualitative research team for their data collection efforts and Elizabeth Presler-Marshall for her helpful comments on the article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical Statement
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: GAGE is a longitudinal research programme funded by Foreign, Commonwealth & Development Office (FCDO) as part of UK aid.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.