
Abstract
Social scientists of mixed-methods research have traditionally used human annotators to classify texts according to some predefined knowledge. The “big data” revolution, the fast growth of digitized texts in recent years brings new opportunities but also new challenges. In our research project, we aim to examine the potential for natural language processing (NLP) techniques to understand the individual framing of depression in online forums. In this paper, we introduce a part of this project experimenting with NLP classification (supervised machine learning) method, which is capable of classifying large digital corpora according to various discourses on depression. Our question was whether an automated method can be applied to sociological problems outside the scope of hermeneutically more trivial business applications. The present article introduces our learning path from the difficulties of human annotation to the hermeneutic limitations of algorithmic NLP methods. We faced our first failure when we experienced significant inter-annotator disagreement. In response to the failure, we moved to the strategy of intersubjective hermeneutics (interpretation through consensus). The second failure arose because we expected the machine to effectively learn from the human-annotated sample despite its hermeneutic limitations. The machine learning seemed to work appropriately in predicting bio-medical and psychological framing, but it failed in case of sociological framing. These results show that the sociological discourse about depression is not as well founded as the biomedical and the psychological discourses—a conclusion which requires further empirical study in the future. An increasing part of machine learning solution is based on human annotation of semantic interpretation tasks, and such human-machine interactions will probably define many more applications in the future. Our paper shows the hermeneutic limitations of “big data” text analytics in the social sciences, and highlights the need for a better understanding of the use of annotated textual data and the annotation process itself.
Keywords
Introduction
Depression is a phenomenon inseparable from modernity: it can be viewed as a form of social suffering originating from increased uncertainty and helplessness (Sik, 2018). On the other hand, depression is also a social construction: its ontological status, epistemological accessibility, causal models, and consequent treatments can be framed in several ways. Furthermore, these two dimensions are also interrelated: various discursive framings imply different relations to suffering from both the subject and the social environment. Therefore, it is among the key objectives of the sociology of mental disorders to determine what the various discursive framings of depression are, how they are reproduced, and what kind of identities and reactions they create—since these are likely to orient treatment strategies.
Previous research in this field has been primarily qualitative. Investigators have used qualitative content analysis of offline texts (personal diaries, letters, interviews) to investigate the framing of depression (e.g., Riskind et al., 1989). We believe that there is significant research utility in the application of automated text analysis methods to investigate the framing of depression in online, patient-generated non-clinical texts. This new data source has become available with the rise of web-based online health communities. Online space as an empirical base is of great significance in this context, since (1) participants of discussions try to utilize their peers’ experiences in their everyday praxis: lessons learned are helpful for them; and (2) while texts do not contain elaborated views of their authors, they are part of a dynamic discourse happening in real time. Although there has been previous research which examined the framing of depression in online health forums (e.g., Clarke & Sargent, 2010; Lachmar et al., 2017; Pan et al., 2018), to our knowledge this study is the first which applies natural language processing (NLP) techniques for this purpose.
NLP, which is a subfield of linguistics, computer science, and artificial intelligence, concerns how to build algorithms to understand and analyze large amounts of natural language data. We have chosen NLP methods, because our corpus consists of near to 80 K depression-related posts, a volume difficult for humans to process unaided. In the current phase of our project (which is to be followed by substantive analysis), we also relied on mixed methods, as we aimed at analyzing the discussion of online forums about depression with the help of supervised machine learning (SML). SML is a two-step method including (1) human annotation of a smaller textual sample, which provides basis for (2) the algorithmic annotation of the whole data set. As it turned out, however, the application of SML in case of discourses of depression proved to be methodologically challenging on both levels. As a result of several failures, our own methodological background assumptions had to be revised.
The present article introduces our path of learning from the difficulties of human annotation to the hermeneutic limitations of algorithmic language processing. Firstly, this paper will introduce our research challenges stemming from inter-annotator disagreement, as our initial presumption that the classification of online forum posts would be an unambiguous process turned out to be highly controversial. As a result, we gradually moved from the strategy of relying on more and more detailed classification tools enhancing individual interpretation to the strategy of intersubjective interpretation based on the logic of inter-annotator consensus. Secondly, this paper will overview the challenges of algorithmic annotation: while we, based on our sample annotated by human researchers, initially thought that the algorithm will be able to proceed; it turned out to be incapable of recognizing certain patterns. As a result, we had to start theorizing this failure and reinterpret the unrecognizable pattern as a linguistically less elaborated, discursively subordinated framing. Moreover, our paper provides additional evidence for the importance of human annotation-based machine learning applications. As sociological concepts are generally complex in nature, our results contribute to the discussion on the potential of NLP techniques in sociological knowledge-driven textual analysis.
Data, Methods
We collected depression-related posts from the most popular English-speaking health forums. Most of the posts were downloaded from healthunlocked.com, depressionforums.org, forums.psychcentral.com, psychforums.com, and beyondblue.org.au. We filtered the corpus in two rounds: (1) we selected threads which contained the word “depression” or “depressed” in their title or at least in one of their posts, then (2) we selected posts whose link, topic, or content of which contained a depression-related term, for instance: “unipolar depression,” “mood disorder,” or “depressant.” The data set, collected by SentiOne in compliance with GDPR regulations, contained 79,889 articles posted between February 15, 2016 and February 15, 2019, covering publicly available posts, which were shared willingly by their authors. Technical details of our data collection and descriptive analyses of the resulting corpus are publicly available via an accompanying webpage located at http://ijqm.rc2s2.eu.
A machine learning algorithm enables the computer to “learn” from data without being explicitly programmed. 1 SML on textual data is a kind of automated content analysis, which helps researchers to perform analysis on data sets too large for human processing. A widely used business application of SML is sentiment analysis which tries to evaluate the opinion of users commenting on company posts. A social science example comes from Jelveh et al. (2014), who identified the latent political position of economists based on their scientific papers. Some of the economists’ political position had been known from external data sets like campaign contributions, and the algorithm could expand this knowledge for other non-labeled economists by analyzing the textual patterns of the labeled papers. When external information is not accessible, human annotators are employed to label (or “annotate,” a term coming from the programming community) a sample of the data manually, the same way as in the case of traditional qualitative text analysis. In order to be able to evaluate prediction, a validation phase is part of the process. The annotated set is divided into a training set and a validation set. During the training phase, an algorithm is constructed to predict codes by identifying textual patterns to explain the annotators’ codes. Using the algorithm, we predict codes for texts in the validation set as if we did not know their codes given by the annotators. When evaluating the prediction, we compare these codes with the ones given by the annotators.
Based on the evaluation, we can choose the best one from many different models. If its performance is acceptable, it is used to code the whole unannotated data set. The size of the annotated set is typically about a few thousands, while the whole data set may consist of millions of texts.
Annotation of large data sets is time-consuming and expensive. In everyday machine learning praxis, it is very common to use internet services (e.g., Figure Eight or Amazon Mechanic Turk) that allow businesses to post short tasks and pay workers to complete them. In some cases, the task needs skilled annotators who require detailed guidelines, extensive training, double annotation, and direct control.
Supervised learning on text data has been recently in the focus of information science and has successful industrial/business applications but has been rarely used in sociology (cf. 326 papers mentioned “supervised learning” in the field of business and management in the last two years, but only 6 in sociology 2 ). It is an open question whether the automated method can be applied to sociological problems outside the scope of hermeneutically more trivial business applications. That is why we experimented to use SML for classification of forum posts according to their framing.
From Individual to Intersubjective Annotation
The applied methods of annotation vary according to the type of classification, like mood (e.g., Kiritchenko et al., 2014), or topic (e.g., Basile et al., 2019; Pestian et al., 2010); the length of the unit, like words (e.g., Kiritchenko et al., 2014), phrases, or small texts (Li et al., 2018; Prabhakaran et al., 2014). Also the applied typology may be developed in a deductive (theory driven) way (e.g., by using supervised machine learning, see, Prabhakaran et al., 2014) or inductive way (derived from empirical clusters, e.g. Himelboim et al., 2016). Our starting point was a theoretically elaborated research question. In scientific discourses three major framing dominate the debate about depression: a bio-medical one (referring to depression as a disease of bodily origin), a psychological one (referring to depression as a result of cognitive, affective, or behavioral dysfunctions), and a sociological one (referring to depression as a result of distorted interactive and structural patterns).
An annotation set of 4,500 posts was selected randomly. Despite their fragmentedness, forum posts were considered to be our basic unit of understanding, as they encapsulate enough interpretation for attributing a discursive framing of depression (we considered only posts longer than 20 words). Although they were annotated separately, they hold the potential of aggregation during a future phase of the analysis (e.g., at the reconstruction of the interactive logic of various framings). As the annotation task was expected to be more complex than in everyday praxis, recruitment of non-expert annotators on crowdsourcing platforms was not an option. Instead, we recruited our annotators carefully from social science university students having an interest in the topic and the method. During the pilot phase, the annotators were trained to apply a two-level differentiation: a primary and, if needed, a secondary label was given to each forum posts depending on their discursive homogeneity. 3 A primary label reflects what the annotator considered as the major framing type in the given text, and a secondary label reflects an additional framing type (20% of the posts got a second label.) During the pilot phase, the classification methods were continuously corrected based on the feedback of the annotators. While this initial phase was principally a theory driven coding, it also consisted of elements of grounded theory, as the application criteria of the categories were developed during the collective interpretation of the pilot phase (Holton, 2007). As a result of the discussions, the abstract idealtypical discursive frameworks were gradually filled with empirical indicators. The conceptual clarification was complemented with a list of examples:
– bio-medical: I feel like medication and proper treatment has given me a second chance at living it more fully.
– psy: You have to sacrifice your ego. You have to stop needing to be right about yourself. You have to stop needing to be the victim of depression.
– socio: We aren’t; and this world isn’t perfect. We may be led to believe that by the culture we live in, the TV ads, Hollywood, beauty magazines, etc. but what that does is allow our minds to make comparisons to convince us that we don’t add up.
Interpretation based on these principles was practiced in several individual and collective turns. The actual annotation process started, when the annotators seemed to develop an approximately unified approach.
In similar mixed method research, inter-annotator agreement is of great importance, since if labeling is not reliable, neither can classification models be trusted. Yet, even after extending the pilot phase with several rounds, the inter-annotator agreement remained insufficient (percent agreement of primary labels was below 60%). As the forum posts were generally fragmented, despite every conceptual clarification, several cases still remained ambiguous.
At this point, a revision of our own background methodological assumptions became necessary. Without being aware of it, we initially understood human annotation as an identificatory process, where the specification of the abstract discursive categories was supposed to ensure the subordination of empirical posts under the appropriate categories. However, as it turned out, such association of the general categories and concrete posts remained a too ambiguous task. We had to realize that even at this basic level, a hermeneutic process took place, requiring proper methodological addressing. Following Gadamer’s theory of understanding (2004), we also started to view the formation of meanings as a linguistically mediated, intersubjective, iterative process, wherein the meanings are not originating from matching the abstract and the concrete, but they are constructed in an actual process. Methodologically this intersubjective process was modeled in the transition to cross-annotation.
Instead of assuming that each post belongs to one or two categories that can be identified by an appropriately trained annotator, we concluded that forum posts may be interpreted to fit into more categories depending on the manifest linguistic signs and latent correspondences. In order to minimize the contingency of interpretation, two independent annotators coded each post. Each annotator chose one primary and (optionally) one secondary label, which gave a maximum of four labels together. The most frequent label among the four was chosen as the final integrated label (majority voting 4 ). In other ambiguous cases 5 (12,3%), a third annotator (a senior researcher) adjudicated differences. A secondary integrated label was also assigned if there was an unambiguous second winner of the voting. On the distribution of the final labels see Figure 1.

Distribution of the labels in the annotated corpus.
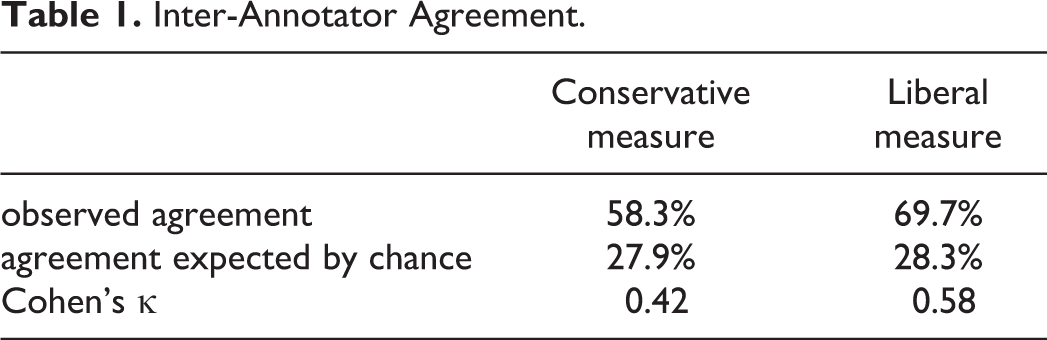
To measure inter-annotator agreement, we used Cohen’s κ (Cohen, 1960). If the annotators are in complete agreement, then κ equals 1. If there is no agreement among the annotators other than what would be expected by chance, κ is 0. The two annotators agreed in their primary tags in 58%, which gave a Cohen’s κ of 0.42. However, if we define agreement as the match of primary labels—simply discarding the optional secondary ones—we would get an overly conservative measure. Beside such perfect consensus, imperfect ones were accepted too. By reframing annotation as a hermeneutic process instead of classification, partial inter-annotator disagreement could also be viewed as multiple labeling instead of misclassification. Therefore, following Flor et al. (2016), we also considered a different criterion of inter-annotator consensus: when the primary label of annotator A agreed with either the primary or the secondary label of annotator B.
Table 1 shows the results. For observed agreement, the criterion of 0.7 is often used for exploratory research. A κ of 0.4–0.6 indicates moderate agreement, while 0.6–0.8 shows substantial agreement (Landis & Koch, 1977). According to the results, we got a moderate, nearly substantial agreement.
Inter-Annotator Agreement.
Bio-medical framing is the easiest one to identify (with a Cohen’s κ of 0.80), 6 while the sociological framing is the most difficult to detect (with a Cohen’s κ of 0.59), although, it is not far behind psychological framing (where κ is 0.64).
To sum up our first lesson learned: by transforming the process of individual classification into intersubjective interpretation, each post could be reassuringly assigned to one or two of the categories. Stepping back from our original methodological design after our failure, a new approach was established with obvious advantages, but during the machine learning phase, unobvious challenges occurred as well.
The Hermeneutic Failure of Machine Annotation
Preprocessing: Converting Texts to Numbers
The first phase of all NLP analysis is preprocessing, which transforms texts into quantitative data. Each of its steps aim to preserve information later to be used by the automated tools and to drop information which will likely be unnecessary or too complex. Decisions made at each step have significant effects on the results (Denny & Spirling, 2018). We decided to choose usual steps (see, e.g. Aggarwal & Zhai, 2012) while considering our specific research question. During our analysis, we used Python’s Natural Language Toolkit, which is a leading platform for writing programs in Python to work with natural language data (Bird et al., 2009).
Most text mining approaches rely on a word-based representation of texts (e.g., Aggarwal & Zhai, 2012). The model assumes that texts are “bag of words,” where order does not inform the analyses. Analytic methods following this approach characterize texts based on the number of occasions a word occurs in the document. Instead of simple word frequency distribution, which would assign large weights to many common but irrelevant words, we used weights proportional to the importance of the given word to the post. These “term frequency-inverse document frequency” (Tf-idf) weights increase proportionally to the number the given word appears in the post but is offset by the number of texts this word appears in. Some words with the largest Tf-idf values were: smile, chronic, grief, kratom, 7 pessimistic, kai, 8 zopliclone, 9 schizoaffective_disorder, eft. 10
To step a bit beyond the “bag of words” concept, we tried to identify and treat the two-word collocations (in NLP-jargon “significant bigrams”) as single terms, i.e. pairs of words which commonly co-occur in the corpus. Among the most frequent bigrams were “Russell Barkley, 11 ” “thai chi,” and “prefrontal cortex.” We also treated the name of the most common mental disorders as bigrams/trigrams. We simplified the vocabulary with lemmatization to identify different forms of the same word (makes → make, worse → bad). We also discarded punctuation, capitalization, very common words (in NLP-jargon “stop words”), deleted URLs, e-mail addresses, and reposts, furthermore, we removed duplicate and too short (<20 words) posts as well. Our final, preprocessed corpus contained 67,857 posts.
These steps may seem to result in a serious reduction of information. Language complexity implies that our models can never provide an accurate representation. However, across different applications, it has been shown that the simple “bag of words” method is sufficient to infer substantive properties of texts (see, e.g. Zhang et al., 2018). Also the simplifying language model itself makes the validation phase highly important.
Automated Annotation Experiments
We used the input texts in several configurations: (1) unigrams, bigrams, and trigrams, ignoring words that have a document frequency lower than 5; and (2) character n-grams (a set of n consecutive characters, n = 2–5), which should make the model more robust to spelling errors. We tested Tf-idf weighting against simple frequency weighting. We tested the effect of stop word removal and different values of the regularization parameter. 12
In order to move beyond word frequencies and to build some background knowledge into the model, we tried to define further variables (“features”) which might help the learner to classify the posts. Table 2 lists the features used. Most of them are general linguistic characteristics of the post possibly related to social status or age of the author. Document features like these are commonly used in NLP classification tasks. Other features are more specific to the topic of depression. There is also an author-level characteristics describing their engagement in forum community. We used these features as predictors, because we assumed they might be related to framing either in a direct 13 or in a rather indirect way. 14 Further details of preprocessing and the features used are provided on the accompanying website.
Features Used in Classification Models.

During the machine learning phase, we used five-fold cross-validation. We divided the annotated sample randomly into a training set and a validation set in a 4:1 ratio. We used stratified sampling in order to assure identical distribution of labels across the five subsamples (“folds”). Out of the five folds, one fold is retained as the validation set and the remaining four folds give the training set. We fitted multinomial logistic regression on the training set to predict their primary labels and compared them to the ones given by the annotators. The process was repeated five times—with each of the five folds used once as the validation set. The five comparison measures could be averaged to give a single estimation.
As we faced a (1) multi-class classification problem with (2) unbalanced classes, instead of standard comparison measures, we used Cohen’s κ. Just like in the case of measuring inter-annotator agreement, we considered a liberal version of the κ accepting a predictive label if it agrees with either the primary or the secondary label. Average of the five κs computed from the five folds, giving the overall performance measure.
We also experimented other most commonly used machine learning classifiers: Bernoulli naïve-Bayes, support vector machine, and random forest models (see, e.g. Aggarwal & Zhai, 2012). The liberal κs (averaged over folds) are 0.41, 0.50, and 0.48 respectively.
The best logistic model gives a conservative κ of 0.45 and a liberal κ of 0.53. The results show that simple logistic regression remarkably outperforms the other (more sophisticated) classifiers. Our best model uses Tf-idf weighted data with features listed in Table 2, character n-grams, and stop-word removal. This result approaches human interrater agreement (liberal κ of 0.58).
A detailed classification report gives a deeper insight to the performance of the best model (Figure 2). Beside the κ, we present also other widely used classification performance measures: precision (probability that a post with the given predicted label was truly annotated with this label) and recall (or sensitivity, which is the probability that a text annotated with a given label was correctly predicted to have the label). Bio-medical framing is the most predictable, psychological is also acceptable, while sociological framing is the least predictable one. Its moderate precision (0.6) and very low recall (0.18) means that the model predicted very few sociologically interpretable posts, although, these predictions were in most cases right.

The best model’s performance results computed in the liberal way and averaged over folds.
Despite all efforts, it seems that while the SML seems to work appropriately in case of bio-medical and psychological labels, it fails in case of sociological framing. This failure directed us back to reflecting on our broader methodological framework. While in the case of humans, the process of annotation is constituted of both the recognition of typical linguistic patterns (including words or ways of expression) and a hermeneutic process of meaning construction (based on the interpretation of latent patterns), in the case of NLP, only the former is relevant. This difference needs to be taken into consideration, when it comes to listing the limitations of NLP in general: it may remain hidden in case of human annotators, while in case of machines, it becomes a source of limitation. While NLP is capable of classifying labels characterized by objective linguistic patterns (such as words or set of words), it fails in those cases, when hermeneutic understanding is required, i.e. the construction of meaning based on latent patterns untranslatable to the level of words.
It is important to emphasize that the limitation we faced is not the same as “subjective coding” (e.g. Zeng et al., 2017) or “noise” (e.g., Astudillo et al., 2015), as inter-annotator disagreement problems are sometimes referred by the machine learning literature. It is not a proof for the emptiness of the sociological label either, as in the case of human annotators, the inter-annotator agreement on psychological and sociological labels did not differ significantly. Instead, what we experienced as the failure of SML may be the consequence of the difference between human and non-human annotators. When it came to identify sociological framing, the annotators could unintentionally rely on subtler, non-automatable hermeneutic processes, which proved to be inaccessible to the algorithms (see also its very low recall regarding the sociological framing).
Conclusions
Our results show that the sociological discourse about depression is not as well founded as the bio-medical and the psychological discourses – a conclusion which requires further empirical study in the future. While these two have an elaborated, institutionalized vocabulary widely used by the public, sociological discourse seems to lack such linguistic framework. This difference could be interpreted as the expression of the hierarchical segmentation of the discursive field of depression. It seems that sociological framing is yet to become as well-known as the other two, which results in linguistic uncertainty when it comes to relying on it by lay speakers.
Machine learning on text data provides new opportunities from business to science. An increasing part of these solutions is based on human annotation of semantic interpretation tasks. Human–machine interactions, like these, will probably define many more applications in the future. As sociological concepts are generally complex in nature, our results contribute to the discussion on the potential of NLP techniques in sociological knowledge-driven textual analysis. Our experiences highlight the need for a better understanding of the annotation process itself and cautious use of annotated textual data.
Even though our project has just stepped into its substantive phase, it is already clear that the potentials of the massive data sets becoming more and more accessible for sociological analysis can only be tapped if being paired with continuous methodological and theoretical self-reflection. It is a common myth shared by many advocates of “big data” that the more massive the data is, the more self-explanatory it becomes. It is enough to refer to the widely cited pamphlet of Anderson (2008), who introduced a new paradigm of empiricism, in which a vast volume of data itself offers objectivity and precision. Our experiences point to the opposite direction: the meaningful interpretation of massive data sets requires the integration of both qualitative and quantitative methodological and theoretical insight—more than ever before.
Proceeding in this spirit, in the future, we plan to combine NLP not only with other analytical tools developed for text mining (e.g., topic models), but also with qualitative discourse analysis. By approaching online depression forums from various angles, we hope to answer not only descriptive questions (e.g., What is the distribution of biological, psychological, and sociological framings?), but also explaining the inner dynamics of the discourse itself (e.g., What are the interactive patterns of these framings?).
Footnotes
Acknowledgments
The authors thank Eszter Katona for coding help and Gergő Morvay for suggestions regarding the organization of the annotation process. We would would like to thank also to the students who participated in the annotation.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors were supported by the Higher Education Excellence Program of the Ministry of Human Capacities at Eötvös Loránd University (ELTE-FIKP).