
Abstract
Programs via the Internet are uniquely positioned to capture qualitative data. One reason is because the Internet facilitates the creation of a community of similar individuals who can exchange information and support related to living with a chronic illness. Synchronous conversations via the Internet can provide insight into real-time social interaction and the exchange of social support. One way to analyze interactions among individuals is by using qualitative methods such as content, conversation, or discourse analysis. This manuscript describes how we used content analysis with aspects from conversation and discourse analysis to analyze synchronous conversations via the Internet to describe what individuals talk about and how individuals talk in an Internet-mediated interaction. With the increase in Internet interventions that facilitate collection of real-time conversational data, this article provides insight into how combining qualitative methods can facilitate the coding and analysis of these complex data.
Keywords
Introduction
Programs via the Internet are uniquely positioned to capture qualitative data (Keelan et al., 2015; McElhinney, Cheater, & Kidd, 2014; Mitchell et al., 2014). One reason is because the Internet facilitates the creation of a community of similar individuals who can exchange information and support related to living with a chronic illness. These Internet-based programs facilitate social interaction among similar others and providers (e.g., diabetes educators, physicians, nurses) for disease-specific interaction and support and can either be asynchronous (e.g., delay in response; e-mail, discussion board post) or synchronous (e.g., real-time response, virtual environments [VEs], Skype; Beard, Wilson, Morra, & Keelan, 2009; Johnson et al., 2014; McElhinney, Kidd, & Cheater, 2018; Pal et al., 2014; Rosal et al., 2014).
Synchronous VEs (programs that enable real-time conversation) make possible the observation of real-time interactions among individuals who interact with each other (Keelan et al., 2015; McElhinney et al., 2014). These real-time conversations among individuals who interact with others via a VE provide valuable insight into a specific phenomenon such as type 2 diabetes (T2D) self-management (Keelan et al., 2015; McElhinney et al., 2014; McElhinney et al., 2018). The words that participants use in conversations with others become an index for their experiences living with, and self-managing their T2D, in addition to providing information on their experience in the VE (Dickinson, 2017; Dunning, Speight, & Bennett, 2017). A researcher can then use these real-time conversations to examine how individuals relate to others while obtaining T2D-specific information and support in a VE.
Selection of Appropriate Qualitative Methods
One way to analyze interactions among individuals is by using qualitative methods such as content, conversation, or discourse analysis. Content analysis has been used to analyze VE-mediated conversations and interactions among individuals (Keelan et al., 2015; McElhinney et al., 2014; Peterson, 2005, 2012), and conversation and discourse analysis have been used to analyze naturally occurring Internet conversations (Hutchby & Barnett, 2005; Meredith, 2017). Separately, these methods can describe an individual’s interaction behaviors, content of discussion, or opinions in a specific situational context, by examining the content and structure of the conversation or an individual’s behavior. However, to our knowledge, no qualitative method addresses real-time conversations in a VE, as well as how the VE mediates, or influences, the interaction. Our interest went beyond separately examining the interactional behaviors (e.g., turn-taking), the content (e.g., topic of discussions), and opinions (e.g., responses to interview questions) in sequential interactions because we also wanted to describe the influence of the VE on a social interaction. Therefore, we used content analysis, with insight from conversation and discourse analysis, for our study.
Content analysis
Content analysis enables one to gain understanding about a phenomenon of interest, such as T2D self-management, using a systematic analysis approach with visual or textual data (Graneheim & Lundman, 2004; Hsieh & Shannon, 2005; Sandelowski, 1995). With content analysis, the coding and analysis process is iterative as the researcher gains insight by reading the transcribed text, creating and applying codes to the text, and then developing themes (Graneheim & Lundman, 2004; Hsieh & Shannon, 2005; Sandelowski, 1995). We chose content analysis to examine what individuals discussed in an interaction with others because we wanted to describe the self-management topics, or content, exchanged in interactions and support.
Conversation/discourse analysis
Conversation and discourse analysis are two distinct qualitative methods that examine how individuals engage in specific turn-taking behaviors and how these behaviors are used in sequence during a conversation (Drew, Chatwin, & Collins, 2001; Gale, 2000; Hodges, Kuper, & Reeves, 2008). These two methods both describe how an individual composes her or his communication when in a group of individuals. While these methods approach turn-taking, topic, and conversational responses differently, we considered these two methods to be similar in how they enabled us to describe how an individual composes their communication when in a group of individuals. The description of conversational practices provided information on how individuals communicated with each other in the VE and showed how the VE mediated these interactions. Thus, we were able to analyze how, if at all, real-time conversations and interactions in the VE differed from face-to-face interactions.
Rationale for building upon these methods for VE-generated qualitative data
This study used qualitative methods that drew upon content analysis (what individuals talk about) and conversation/discourse analysis (how individuals talk in a VE-mediated interaction) thus creating a new way of examining real-time interactions in the VE. This novel method provided a more nuanced description of real-time, VE-mediated interaction and support than a single qualitative method alone. Additionally, the development of methods to code and analyze real-time conversations provided a different view of the phenomenon than traditional qualitative (e.g., focus groups, interviews, or observations) and quantitative (e.g., surveys) methods.
Purpose
This article describes the development of a novel qualitative method that drew upon three existing qualitative methods to analyze real-time conversations that occurred in VE-mediated, T2D education and support sessions (Lewinski et al., 2017; Lewinski et al., 2018).
Research Approach
Framework
We developed a guiding framework (Lewinski et al., 2017) for this secondary analysis of qualitative data. The concepts in social penetration theory (Altman & Taylor, 1973) and strong/weak tie theory (Granovetter, 1973, 1983) guided us in describing interactions in a VE focused on self-management education and support.
Origins of the Qualitative Data
We analyzed data previously collected from the Second Life Impacts Diabetes Education & Self-Management (SLIDES; 1R21-LM010727-01) study. A full description of the SLIDES study is found elsewhere (Johnson et al., 2014; Vorderstrasse, Shaw, Blascovich, & Johnson, 2014). Briefly, the SLIDES study provided T2D self-management education and support to adults living with T2D who interacted with peers and diabetes educators in the SLIDES site on the Second Life platform (Linden Labs, Inc., San Franciso, USA; Johnson et al., 2014; Vorderstrasse et al., 2014). Results from the SLIDES study indicated increases in self-efficacy, social support, and foot care (p < .05; Johnson et al., 2014). Participants interacted with others in the VE as avatars (e.g., computer representations of a human; Figure 1). Education and support sessions contained various numbers of participants. Most conversations in the VE contained between two and eight participants, including the diabetes educator, and most conversations occurred when the diabetes educator was present. Conversations in the VE focused on living with T2D, engaging in T2D self-management behaviors, and learning self-management techniques (Lewinski et al., 2018). Additionally, most of the interactions among the participants and diabetes educators occurred via synchronous conversations, although there were a few instances of e-mails, discussion-board posts, and text chats exchanged among the diabetes educators and participants.

Participants, diabetes educators, and investigators interacted as avatars during a synchronous education session in the virtual environment. The avatars of the participants and diabetes educator are in the restaurant and discussing healthy options when dining out.
Preparation of Data From VE-Mediated Synchronous Conversations
We prepared the conversational data over a period of several months; this attention to detail enabled a rich description of social interaction and support in a VE. One author (A.A.L.) worked closely with two authors (A.A.V., C.M.J.) to systematically clean, transcribe, and organize the files. This secondary analysis received institutional review board approval (Pro00022132) and did not collect any new data or recontact participants.
Description of the raw conversational data
Synchronous conversations among participants and diabetes educators in the SLIDES VE were recorded by robots (“bots”) in the site and saved to MP3 files and stored on a secure server at the university. How the voice conversations were recorded is fully described elsewhere (Johnson et al., 2013; Johnson et al., 2014). Files used for this secondary analysis (n = 861) ranged in length from 3 seconds to approximately 10 minutes and were collected during the study duration. Additionally, the synchronous text-chat conversations and asynchronous e-mails and discussion board posts were copied from the VE site and pasted to MS Word files and stored on the secure server at the university.
Getting the feel of these data
To become familiar with the VE, and gain insight into the participants’ experiences interacting with others in the VE, the first author (A.A.L.) took several steps. First, she created an avatar and walked around to the various locations and interacted with the embedded features in the SLIDES site with the last author (C.M.J.). Then, she worked with the SLIDES study investigators (A.A.V., C.M.J.), one of the diabetes educators, and a SLIDES study research assistant to learn about the VE, the interactions that occurred among participants, and the structure of the education and support group sessions. Two authors (A.A.L., R.A.A.) then interacted with another author (C.M.J.) in the VE, so that they could gain firsthand experience on synchronous interactions with others in the VE. Combined, these actions enabled all authors to have a “feel” of the SLIDES VE (McElhinney et al., 2014).
Preparation, transcription, and organization of the raw conversational data
Two authors (A.A.L., A.A.V.) worked together during the transcription phase to identify the social norms within the VE, the common terms that the participants used, and other situational factors that provided insight into the interactions among participants and diabetes educators. While one author (A.A.L.) transcribed several files, a professional transcription service transcribed the majority of the MP3 files. This simultaneous immersion in these data and discussions with the other authors enabled the first author to become knowledgeable about social interactions and identify intriguing patterns over time.
Verifying and cleaning group conversations
The first author simultaneously listened to the MP3 files and read the transcribed text to verify accuracy. Then, she made corrections to the transcribed text as necessary and double-checked any questionable text with the third author (A.A.V.). The authors did not have access to nonverbal behaviors (e.g., visuals of the avatars in the VE) in the SLIDES VE during the transcription of the conversational data for this secondary analysis. Therefore, the authors made the analytical choice to note as much detail as possible in the transcribed conversations (e.g., pauses, sighs, laughter) in addition to the spoken words.
Linking conversations to participants
The first author systematically linked each spoken word to a SLIDES participant by voice recognition or reference to avatar names to determine which participants contributed to, and participated in, a conversation in each MP3 file. Simultaneously, all personal identifying information was removed. The avatar names were pseudonyms for each participant to protect the participant’s privacy during the SLIDES study.
The education and support sessions typically included several participants who conversed with each other. To address the synchronous interactions among participants, the first author noted when one participant or the group stopped talking or paused before resuming the conversation. Additionally, she noted instances when participants talked over each other, interrupted one another, or followed along (e.g., uh-huh, mmmhmm) when they interacted with others. Then, the first author noted signs of emotion (e.g., laughter, sighing) and linked these to the correct participant when possible to add further context to the interaction.
Unintelligible conversational data
In a few MP3 files, the conversations were unclear. In these instances, the first author noted when audio feedback occurred which prevented her from hearing or accurately understanding the words spoken. She also noted participant-related reasons that prevented her from accurately hearing the conversation (e.g., participants talking over one another, participants sneezing/coughing/laughing into their microphone, and participants mumbling or talking softly). The authors chose not to transcribe, nor did they attempt to fill in, missing words in conversations where the spoken word could not be heard. Additionally, several lines of text-chat could not be linked to a specific participant and those instances were left unlinked to specific participants. As the unintelligible portions of conversations were usually small snippets of replies, and not entire conversations, the impact of the unintelligible sections was minimal on the overall corpus of conversational data.
Organization of conversations by time and location
We organized conversations by date and time in which they occurred (i.e., afternoon, evening) and location in the VE. The diabetes educators led sessions that typically lasted between 30 and 60 minutes. Recordings were made every time someone spoke in the VE, and the MP3 files recorded data in 10-minute intervals (Johnson et al., 2013). The first author organized these exchanges sequentially, so that the transcribed conversations accurately depicted the actual real-time dialogue that occurred. The first author verified date and time of conversation using participant log-in time, spoken words (i.e., good morning or evening), and spoken references to time (e.g., 3:15 p.m.).
Organization of conversations to facilitate data storage and organization in computer-assisted qualitative data analysis software
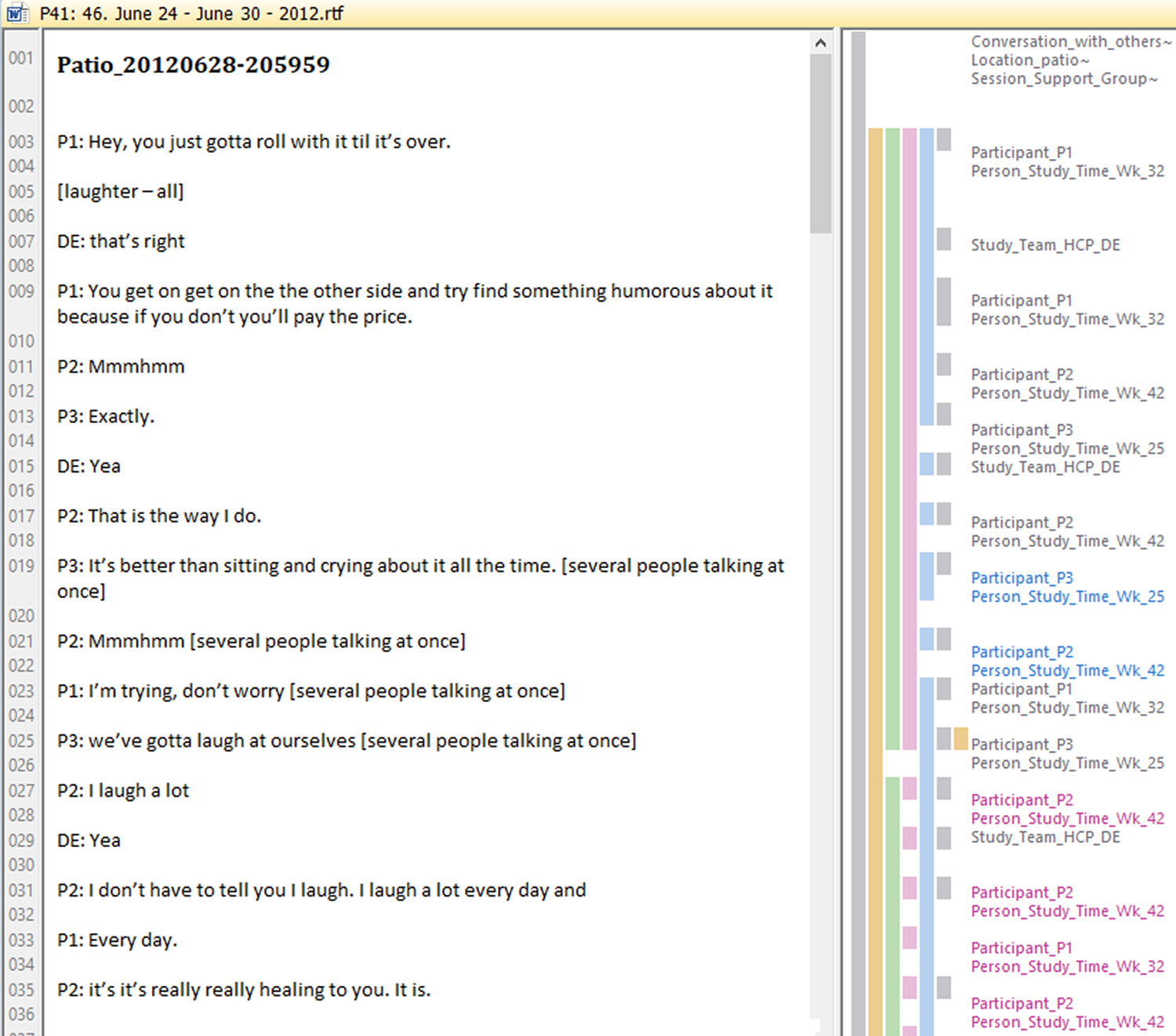
The master document was 1,537 pages at the completion of cleaning and comprised 42 distinct Microsoft Word files. We used Atlas.ti Version 7.5.16 (Berlin, Germany) to support coding and analysis of these data. We created one hermeneutic unit in Atlas.ti (62,237 text lines), and then each Microsoft Word file containing 1 week of conversations was imported into Atlas.ti as a separate primary document (p-doc). Table 1 is an example conversations from one MP3 file in the Master Document.
Master Document Example.

Note. [DE] = diabetes educator; [P#1-2] = unique participant; [SS] = study staff member.
Content Analysis Coding and Analysis for Synchronous Conversations
We developed codes iteratively during the coding process in addition to those codes developed from social penetration theory (Altman & Taylor, 1973) and strong/weak tie theory (Granovetter, 1973, 1983). As social interaction is a multidimensional concept, we used collective expertise about social interactions in face-to-face environments and human–computer interactions during coding. Once coding was completed, we analyzed these data using the theories to describe synchronous interaction and support among adults in a VE (Lewinski et. al., 2018). Table 2 provides examples of how insights iteratively developed during the coding process.
Development of a Priori Codes.

Note. VE = virtual environment.
Coding styles and sampling units
The various codes had different sampling units, which necessitated the use of several coding styles that were determined prior to beginning coding. We used a variety of coding styles (e.g., descriptive, attribute) and coding strategies (e.g., splitting, lumping) as outlined in Saldaña (2013) and listed in Table 3.
Coding Styles and Strategies.

Source. Coding styles and strategies adapted from Saldaña (2013).
This combination of coding styles and techniques enabled us to describe social interaction and support at the aggregate level (e.g., by class, calendar date, note when the entire group laughs) and at the participant level (e.g., personal statements about living with T2D, signs of emotion). Due to the multidimensional nature of these analyses, we did not place limits on the number of times a section could be coded.
Several codes had large sampling units to comprehensively describe social interaction and support. First, we defined a conversation as a bidirectional, verbal exchange between two or more participants in the VE at the same time (Lewinski & Fisher, 2016). A conversation began with at least two people, consisted of statements and responses, and ended when an participant left the VE. Therefore, the conversations in this secondary analysis consisted of large chunks of transcribed conversations in which participants conversed with each other (e.g., lumping, attribute, and descriptive coding styles). Similarly, the codes for session type used similar coding styles to differentiate where interaction and support were exchanged (e.g., education class with predetermined content, or support class with free-talk).
Most codes had small sampling units, which enabled the description of the interaction behaviors used by participants; therefore, we used a splitting technique. Table 4 provides examples of how we used these various styles and strategies to code these data. Figures 2 –5 depict our coding scheme in Atlas.ti; specifically, these figures display how we used Atlas.ti (e.g., the family manager) to support the coding these data. Several of these codes developed iteratively based upon the third author’s prior experience coding social interactions in face-to-face environments (e.g., “being” codes; Anderson, Toles, Corazzini, McDaniel, & Colon-Emeric, 2014). For example, the coding team noted discrete instances when participants greeted each other, welcomed each other by avatar name, responded to questions, and expressed enthusiasm during the education and support sessions. This attention to detail enabled the coding team to identify and describe the participant-specific, and collective, behaviors that promoted and inhibited interactions, and the subsequent exchange of support in the VE.
A Priori Codes and Coding Methods for Concepts in the Guiding Framework.

Note. Coding style and strategy guided by Saldaña (2013). VE = virtual environment; T2D = type 2 diabetes.
Descriptive characteristics in Atlas.ti (e.g., splitting technique).

Social interaction codes in Atlas.ti (e.g., lumping and splitting).

Social support codes in Atlas.ti (e.g., lumping).

Level 4 depth code in Atlas.ti (e.g., lumping).
One code, depth, necessitated the use of both techniques. We used both splitting and lumping techniques in order to capture the extent of personal information shared by the participant during conversations with others in the VE (Lewinski et al., 2018). Then, during conversations among the coding team, we sorted the coded sections into the levels of depth. Through discussion, we identified four levels of depth that ranged from “Level 1: minimal personal information shared” to “Level 4: substantial personal information shared” (Lewinski et al., 2018).
Social support is recognized as an integral component of self-management and living with a chronic illness. However, to our knowledge, little research has focused on the words used when individuals exchange social support in synchronous interactions. Therefore, we were faced with the question: How do individuals exchange support in real time and what constitutes these exchanges? To address this question, we searched for literature that described the exchange of social support in Internet and face-to-face environments via (1) asynchronous interactions (e.g., discussion-board posts, text-chat messages) and (2) synchronous interactions (e.g., support groups, telephone calls, and peer-to-peer interactions). This led us to see how previous researchers operationalized social support in their research studies and ways we could define support for our study (Table 5). Thus, the coding of the four types of social support necessitated the use of Saldaña’s (2013) lumping technique. By capturing large chunks of text around a social support exchange, we obtained information on who elicited the social support, how they elicited the support, and how others responded to these elicitations of support.
Development of Social Support Codes With Exemplar Quotes.

Note. [P# 1-3] = each number indicates a participant in a synchronous conversation; [P] = participant; [DE] = diabetes educator; T2D = type 2 diabetes.
Analysis
These qualitative data were coded by consensus. In biweekly meetings, the authors (A.A.L., R.A.A., C.M.J.) reviewed all codes, the codebook, and emerging themes. In total, the second and last author reviewed 25% of the first author’s coding to ensure reliability and validity of the codes. Throughout coding and analysis, these authors identified patterns in these data and discussed the patterns and coded segments until consensus was reached among the three researchers. Following the identification of patterns, they created matrices in Atlas.ti to further describe the sessions in which the codes occurred. For instance, by creating a matrix, the coding team identified that education sessions provided primarily informational support and the support sessions provided both emotional and informational support (Lewinski et al., 2018). Additionally, the matrices enabled the identification of who (e.g., diabetes educator, peer) provided social support and where (e.g., education or support session) the social support occurred (Lewinski et al., 2018).
Discussion
The methods used in this study facilitated a comprehensive description of synchronous conversations among a group of individuals who interacted with each other in a VE. While content analysis, conversation analysis, and discourse analysis have been completed with participants in VEs before, this study expands on the use of these qualitative methods. Prior qualitative content analysis studies have focused on user experience within the VE, have been semistructured interviews with participants (Keelan et al., 2015; McElhinney et al., 2014; McElhinney et al., 2018; Sutcliffe & Alrayes, 2012), or used conversation analysis in text-chats in VEs (Peterson, 2005). In synchronous, face-to-face environments, conversation or discourse analysis research focuses on the verbal practices in an interaction; the primary focus is the structure of the talk and the turn-taking actions by the individuals involved (Barton et al., 2016; Chatwin, 2008; Messina Dahlberg & Bagga-Gupta, 2013; Peterson, 2005). Our research addressed a methodological gap, as we examined both the content and the interaction behaviors during real-time conversations among several individuals who interacted primarily by voice in a VE.
This study’s approach is novel due to the focus on the participant’s interaction behaviors in the VE and not solely on the participant’s experience about interacting with others in the VE or the verbal interactions among participants. In the SLIDES study, the diabetes educators and participants directed the conversations—there were no predetermined questions or a format to follow to guide the conversation or responses. Our methods enabled us to describe how interactions in the VE are comparable to, and not inherently different than, interactions in face-to-face support groups (Lewinski et al., 2018). The results from this secondary analysis show that within the VE, participants shared personal information, asked questions, and provided information in order to obtain T2D self-management information and support (Lewinski et al., 2018). Our close attention to detail and the use of several qualitative methods, in addition to the use of theory, from these data-cleaning processes until final analysis, facilitated the ability to closely describe social interaction and support among participants who interacted with others in a VE (Davidson, 2009; Poland, 2016).
We developed methods to analyze synchronous conversations in a VE to capture not only how individuals communicate with each other and what they discuss in these interactions but also how the medium influences these exchanges. These methods expanded current knowledge on interactions in VEs because they were grounded in literature on computer-mediated communication (Walther, 1992, 1995, 1996, 2012; Walther, Loh, & Granka, 2005), interactions in VEs (Blascovich, 2002a, 2002b; Blascovich & Bailenson, 2011), relational maintenance (Burgoon & Hale, 1984, 1987), online social support (Wright, 2000, 2002, 2012), and peer-to-peer support (Fisher et al., 2015; Fisher et al., 2012) among other topics salient to T2D self-management education and support. As the use of Internet interventions is increasing in health care, an understanding of how the Internet facilitates interactions may provide valuable insight into how individuals interact in real-time, disease-specific programs.
Unstructured, Synchronous Conversations
The methods used in this secondary analysis enabled the description of social interaction and support in a VE and provide evidence that VEs can facilitate the study of interaction and support among individuals. The conversations in the SLIDES VE were not guided by predetermined interview questions or probes, and participants interacted similarly to how one would interact in a group setting in a face-to-face environment. Our coding methods enabled us to notice the behaviors that promoted and inhibited interactions similar to behaviors noted when using conversation analysis methods (Chatwin, 2008; Drew et al., 2001; Gale, 2000). For instance, we observed how the diabetes educators provided emotional support to participants when the diabetes educators explicitly stated concern for participants and cared for the participants’ well-being (Thoits, 2011). Additionally, our coding techniques enabled us to see how participants validated the experiences of others, especially when other participants expressed frustration or challenges with T2D self-management (Thoits, 2011).
The analysis of unstructured, synchronous conversations enabled us to describe how the types of social support are interwoven in real-time conversations. This is similar to social support research, which describes how emotional support emerges over time and is provided via implicit and explicit behaviors (Kowitt et al., 2015). Participants in the SLIDES study may have received implicit support through the presence of the other participants and the shared activity of being in the VE together (Kowitt et al., 2015; McElhinney et al., 2018). This secondary analysis expands upon current research by describing how social support is exchanged in real-time conversation. Conversations in the VE transitioned from one topic to another based on participants’ questions and responses. This natural flow in conversations enabled the exchange of support as it occurs similar to a face-to-face group setting. Typically, conversations in which support was exchanged, began with a participant sharing personal information such as a personal self-management challenge or problem. This led to a conversation in which the diabetes educators and/or other participants provided the needed information and support, and all the participants involved could ask any follow-up questions if they wanted further information or clarification. During analysis, we observed no instances of negative social interaction and support and minimal occurrences in which the participant living with T2D and/or the diabetes educators corrected misunderstandings about T2D self-management. The delivery of this correct information was not a critique of a participant’s behaviors but rather the feedback helped the participant discern between correct and incorrect information. Therefore, individuals may have participated more because they felt they could discuss any topic that they were concerned about at that moment and obtain desired support and information.
The identification and coding of instrumental, appraisal, and informational support proved to be easier than the coding of emotional support. Those three types of support were identified with discrete pieces of conversational text. For instance, when a participant asked a question about the nutritional value of a piece of food (e.g., they elicited support) and another participant provided the nutritional value of that food (e.g., they responded with support), this was an easily identifiable piece of text that could be coded as informational support. We identified appraisal support as affirmational comments such as “good job” or “way to go” in response to a statement or question. Unsurprisingly, we identified few instances of instrumental support in the VE; these instances included website links, recipes, and other pieces of information exchanged among the diabetes educators and participants (Lewinski et al., 2018).
The coding of emotional support proved to be more challenging and led to a conceptual discussion about emotional support. Specifically, we discussed whether emotional support was the words that an individual said to another individual or whether it was the presence of another individual in the VE. To address these questions, we drew upon the relational communication and interaction literature (Burgoon & Hale, 1984, 1987; Walther, 1994, 2012) and literature on verbal utterances (Chatwin, 2008; Drew et al., 2001; Gale, 2000) to help describe interactions, and the exchange of emotional support, among participants in the VE. Therefore, we conceptualized social support as both the words exchanged among participants (e.g., “I’m sorry”) and the verbal utterances that participants made (“Mmmhmm”) in order to capture emotional support being exchanged in synchronous conversations.
Limitations
By drawing upon three different qualitative methods, we may not have identified and accounted for the weaknesses inherent to each of the qualitative methods we used to code, analyze, and interpret these data. Our methods to address this limitation is an inherent strength of our methodological approach. We addressed this limitation by using theories to guide the study from transcription and cleaning, coding, analysis, and data interpretation; grounding the research in a diverse literature base; and obtaining an understanding of each of the three qualitative methods. This secondary analysis was a descriptive study; therefore, we did not analyze the relationship between a participant’s engagement, her or his social interactions, and her or his social support exchanged in the VE. Thus, future research should examine the relationship between a participant’s engagement, interactions, and support in the VE as doing so can provide data on the types of interactions that may be most beneficial in supporting T2D self-management. Additionally, we did not contact study participants for further information or to verify our conceptualization of social support, specifically emotional support. Therefore, future research should examine (1) how participants perceive verbal utterances in the VE and (2) what types of verbal utterances demonstrate emotional support. Overall, we believe that this secondary analysis of synchronous, conversational data collected in a VE provides valuable insight into social interaction and support among individuals living with T2D.
Conclusion
Disease-specific Internet programs are valuable modalities to study the synchronous exchange of social support among individuals. This approach showed how individuals converse, what these individuals say, and when in an interaction they exchange support in synchronous conversations. Synchronous conversations more accurately depict real-time social support elicitation behaviors and the social support provided among individuals who discuss challenges with T2D. This method has the potential to be used by others to describe real-time interactions in synchronous Internet environments in order to gain insight about synchronous interactions among participants and providers.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study is funded by a grant from the National Institutes of Health, National Institute for Nursing Research (F31-NR016622-01; principal investigator [PI]: Lewinski). The parent study, Second Life Impacts Diabetes Education & Self-Management, was funded by the National Library of Medicine (1R21LM010727-01, PI: Johnson). Support for Dr. Lewinski was provided by the VA Office of Academic Affiliations (TPH 21-000), and publication support was provided by Durham VA Health Services Research Center of Innovation funding (CIN 13-410).