
Abstract
Major depressive disorder is often treated with medication. These antidepressants can cause side effects affecting health and lifestyle. Dietary interventions can support traditional treatments, enhancing overall health. However, current food recommendation systems lack personalized menu options for those with mental health issues. This research focuses on designing a dietary recommendation model for depression. The main theoretical implication is a novel food menu inferring process using a food knowledge graph with semantic rules called FONDUE (FOod kNwleDge graphs with semantics rUlEs). The design of the food knowledge graph focuses on dietary restrictions in both mental and physical conditions. The semantic rules are created using descriptive logic and the SPARQL query language to infer diets appropriate for patients with depression. The FONDUE was evaluated by analyzing thirty common patient case studies, each representing different physical conditions in patients with depression. The evaluation results revealed that the accuracy of the retrieved relevant menus was high, with an average precision of 0.86. However, the completeness of the retrieved relevant menus was moderate, with an average recall of 0.67. The lower recall observed can be attributed to the numerous menus within the model, which results in many relevant options still needing to be extracted. The average F-measure, which reflects a balance between precision and recall, scored 0.74. Compared with ChatGPT and Google Gemini, FONDUE demonstrated superior performance. Consequently, the personalized dietary recommendation model effectively suggests food menus tailored to address patients’ physical and mental health needs, instilling confidence in its efficacy.
Introduction
The depressive disorder has become an increasingly pressing issue, affecting approximately 300 million individuals worldwide, with a prevalence rate of 3.8%, as reported by the World Health Organization (World Health Organization, 2024). In Thailand, the incidence of depression rose from 270 to 345.1 cases per 100,000 individuals between 2009 and 2019 (Wongpiromsarn, 2020). By 2023, it is estimated that around 1.5 million people were at risk of developing depression, with 78% not seeking treatment. While regular medication is crucial for managing depression, side effects—such as increased appetite associated with atypical antipsychotics and dry mouth linked to selective serotonin reuptake inhibitors (SSRIs)—frequently result in non-compliance with treatment (Lakhan & Vieira, 2008). These side effects can contribute to nutritional issues; for instance, decreased appetite can result in weight loss and malnutrition, while sedative overdoses may cause weight gain, leading to chronic diseases like obesity and diabetes (Chokka et al., 2006). Additionally, symptoms of depression can lead to neglect of personal health, further exacerbating malnutrition.
Diet and nutrition play a crucial role in supporting individuals with depression by strengthening the nervous system and brain, as well as enhancing physical health in preparation for ongoing treatment. Although nutritional therapy for depression has not yet gained widespread recognition and is not explicitly included in the guidelines for depression management issued by national and international health organizations, psychiatrists, or multidisciplinary teams may tailor nutritional supplementation based on individual patient assessments (Malhi et al., 2021). Current dietary recommendation systems for individuals with mental health conditions often fail to provide personalized options that address both psychological and physical needs. While some studies consider the impact of specific nutrients on mental health, the suggested menus may not always suit patients due to changes in the food’s nutritional content and sensory resulting from the preparation or cooking methods. This study aims to create tailored food recommendations by integrating evidence-based dietary interventions for mental health while also considering cooking methods that influence sensory properties and nutrient content. It introduces a food menu recommendation system specifically for malnourished patients with depression. It serves as a decision-support tool for nutritionists to overcome the healthcare provider’s poor adherence to clinical guidelines, one of the health system challenges of the WHO Classification of Digital Health Interventions (World Health Organization, 2018).
Research on dietary recommendation systems can be divided into two categories: systems focused on health conditions, including recommendations for diabetes (Agapito et al., 2018; Espín et al., 2016; Maimone et al., 2018; Rawte et al., 2021), obesity (Kitwatthanathawon et al., 2024; Mckensy-Sambola et al., 2021; Taçyıldız & Çelik Ertuğrul, 2020), hypertension (Agapito et al., 2018; Bianchini et al., 2017; Clunis, 2019; Gyrard & Sheth, 2020; Mckensy-Sambola et al., 2021), chronic kidney disease (Agapito et al., 2018), psychiatric disorders (Gyrard & Sheth, 2020; Kitwatthanathawon et al., 2024), the elderly (Espín et al., 2016), and diabetes recipes (Bianchini et al., 2017; Mckensy-Sambola et al., 2021). systems not focused on health conditions, which provide menus (Boscarino et al., 2014) and recipe recommendations (Elahi et al., 2015; Yokoi et al., 2015) based on available ingredients. This work is closely related to the first category. Related research in dietary recommendation systems concerning health conditions can be summarized in Table 1. The table summarizes the health and additional information criteria, recommendation methods, and related work in personalized dietary recommendation systems. This work focuses on individuals with depression and non-communicable diseases (NCDs), leveraging ontological reasoning for dietary recommendations considering cooking methods and swallowing ability, where the primary output is a personalized food menu.
Comparison of Research Studies on Dietary Recommendation Systems.
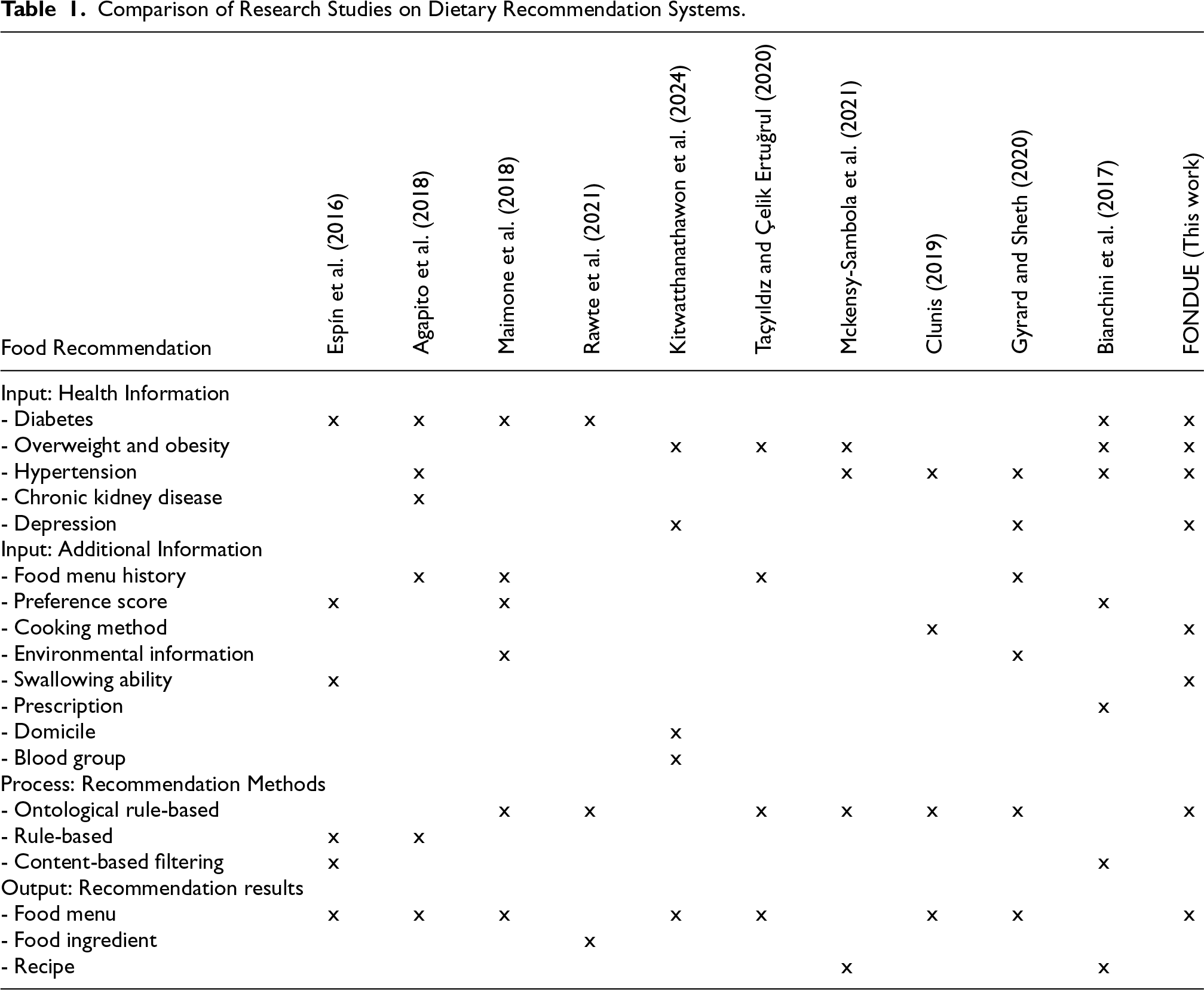
Espín et al. (2016) proposed a food menu recommendation system for older adults, integrating insights from nutritionists and caregivers to address factors like swallowing ability and diabetes using rule-based and content-based filtering. Agapito et al. (2018) developed a Calabrian food recommendation model for NCD patients using decision tree techniques, incorporating clinical parameters like blood pressure and glucose levels. Maimone et al. (2018) introduced “PerKApp,” an ontology-based model promoting a healthy lifestyle to prevent non-communicable diseases, recommending meals through semantic reasoning based on behavior and food history. Rawte et al. (2021) created the “Diabetes Tracker,” which provides self-health management advice using semantic technology and data from the USDA National Nutrient Database. Kitwatthanathawon et al. (2024) introduced NUTRI, a system for psychiatric patients that suggests menus based on symptoms related to medications and other personal data.
Taçyıldız and Çelik Ertuğrul (2020) developed a decision support system to promote healthy lifestyles for preventing childhood obesity, using an ontology to infer lifestyle suggestions from health expert rules. Mckensy-Sambola et al. (2021) proposed a knowledge-based diet recommendation system for overweight and obese individuals, utilizing semantic technology and OWL 2.0 to recommend recipes based on BMI, blood pressure, and food allergies. Clunis (2019) created a food ontology for hypertension patients, recommending diets through a rule-based method that considers food allergies, nutrient needs, and medical history. Gyrard and Sheth (2020) created the IAMHAPPY system to recommend a healthy lifestyle for well-being, considering various health aspects like hypertension and depression using real-time data from IoT devices. It employs semantic technology for recommendations based on an integrated health and weather ontology. Bianchini et al. (2017) developed a recipe recommendation system for individuals with diabetes, obesity, and hypertension, utilizing personal and food information in an ontology and applying content-based filtering for recommendations.
The above research highlights two food recommendation systems that consider nutritional factors for individuals with depression, as shown in Table 1: NUTRI (Kitwatthanathawon et al., 2024) and IAMHAPPY (Gyrard & Sheth, 2020). IAMHAPPY is designed to enhance mood through dietary suggestions. However, its recommendations do not adequately consider health factors related to depression or the side effects of medications. For instance, while chocolate is often recommended for individuals with depression due to its magnesium content, IAMHAPPY might suggest a hot chocolate drink. This recommendation poses a risk; hot drinks may be unsuitable for patients suffering from oral ulcers.
In contrast, NUTRI incorporates knowledge about the side effects of psychiatric medications in addition to information on food, nutrients, and digestion-appropriate options. Nonetheless, NUTRI has its limitations. For example, it excludes beef from its recommendations due to its classification as difficult to digest despite boiling it until tender. This issue occurs because the system only accounts for the innate digestibility of the meat, overlooking how cooking methods can alter the texture and digestibility of ingredients. Furthermore, NUTRI does not consider other physical issues affecting a patient’s nutritional status, such as oral health problems and appetite loss. The distinctions between NUTRI (Kitwatthanathawon et al., 2024), the most closely related system, and FONDUE (this work) can be found in Table 2.
The Distinctions Between NUTRI and FONDUE.

This study aims to develop a novel food menu recommendation model called FONDUE designed to generate meal suggestions for patients with depression who also have physical ailments impacting their nutritional status. FONDUE is built using food menu inference rules, established through a food knowledge graph embedded with description logic. Then, SPARQL query language searches for food menus tailored to depressive patients.
This research aims to develop a dietary recommendation model for depressed patients suffering from malnutrition called FONDUE. The FONDUE is created by using a food knowledge graph with semantic rules. The key performance indicators focus on the accuracy of the food menu recommendation model.
The FONDUE development process involved constructing a knowledge base or ontology and developing a user interface. An ontology formally represents knowledge as a set of concepts within a domain and the relationships between those concepts. It provides a structured framework for knowledge representation and enables reasoning and inference (Horridge & Patel-Schneider, 2012). Figure 1 shows the actors and use cases for the FONDUE.

A use case diagram of the FONDUE system.
The ontology framework developed in this study outlines several practices to assist ontology developers working in complex, data-rich domains. This approach focuses on modular design, domain-driven inference, and end-user integration, rather than merely on definitional elements. The designed ontology development process consists of four steps, which can be summarized as follows.
Step 1 Designing a Multi-Component Ontology Framework: The FONDUE framework is depicted in Figure 2, which consists of three components—data acquisition, an inference engine, and a user interface—ensuring modularity and scalability. This modular architecture allows for clear interfaces and incremental development without compromising system stability.
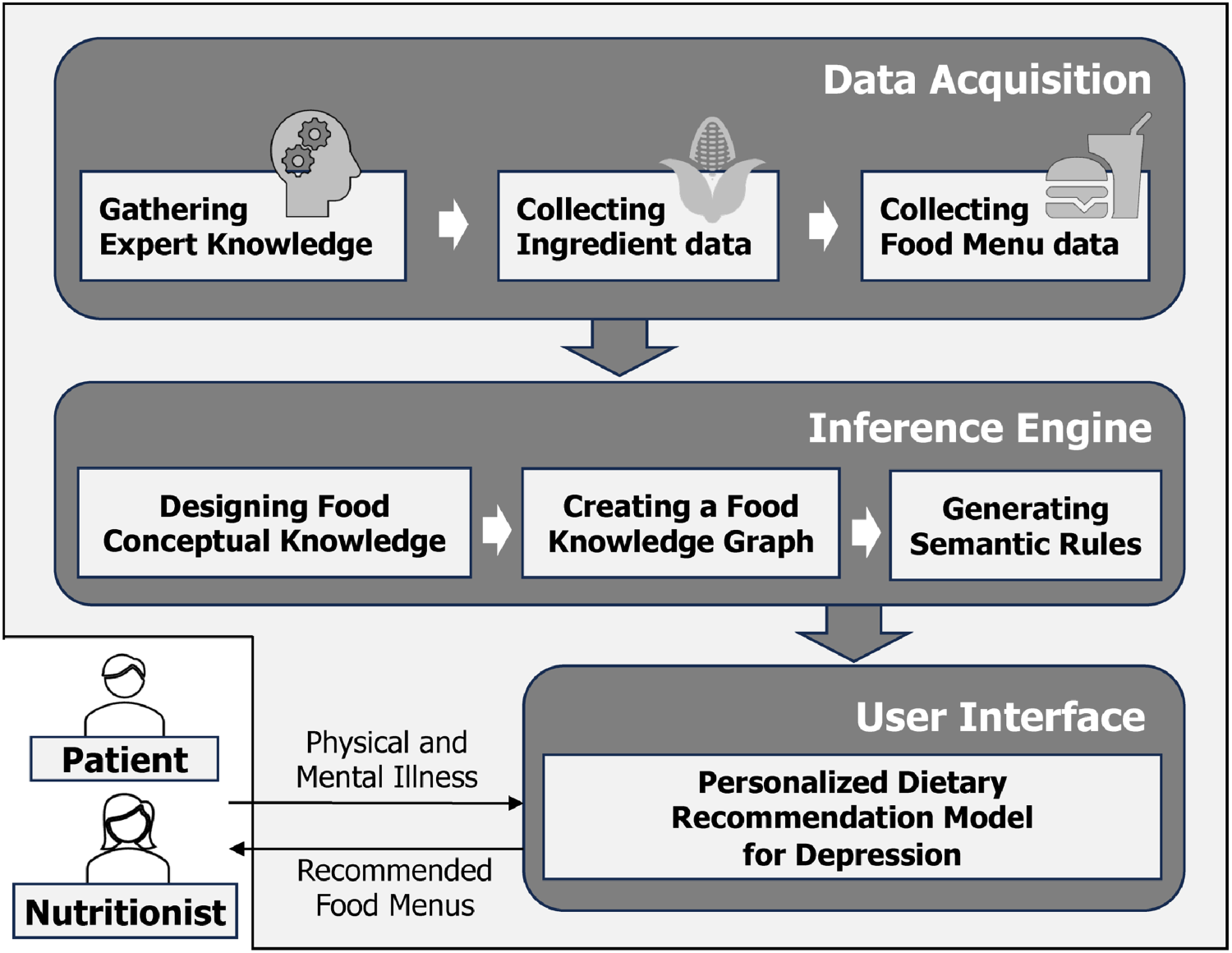
FONDUE framework.
Step 2 Data Acquisition as a Structured Input Layer: Effective ontology development relies on robust data sources. This process used standardized terminologies and data about food-depressed patients with malnutrition to enhance interoperability.
Step 3 Developing a Knowledge Graph and Rule-Based Inference Engine: This process involves creating a domain-specific knowledge graph aligned with the designed food ontology for automated reasoning. Semantic rules must be established using description logic and the SPARQL query language to generate patient-specific menus.
Step 4 User Interface Driven by Ontological Reasoning: An interface driven by ontological reasoning converts inferred knowledge into actionable guidance. In this ontology framework, recommendations consider physical and mental health, demonstrating the value of personalized decision-making and the importance of feedback loops in refining the ontology.
The FONDUE framework enables ontological developers to create adaptable solutions that provide tangible benefits. Additional information on all components is provided in the following sections.
The research aims to integrate interdisciplinary knowledge from nutrition science, food ontology, and medical research to create a comprehensive framework for diet therapy tailored to specific health conditions. There are three steps in the data acquisition phase.
Gathering Expert Knowledge
This first step uses thematic analysis to explore patterns within nutrient data and their physical and mental health effects (Braun & Clarke, 2006). The thematic analysis comprises four processes. The first process is coding, which identifies nutrient and food characteristics. The second process, theme development, is grouping coded data into themes (e.g., nutrient impact on depression, cooking methods). In the third step, we validated the emerging themes through collaboration with a licensed nutritionist to ensure domain accuracy. This expert was not among the seven nutritionists who later evaluated the final recommendation outputs to maintain independence between the knowledge construction and evaluation phases. The last process, documentation, summarizes insights illustrated in the FoodDataset in Saengsupawat et al. (2024a), providing nutrient-specific effects and dietary recommendations.
Collecting Ingredient Data
This second step collects detailed data on Thai food ingredients (Department of Health, 2018, n.d.; Institute of Nutrition, Mahidol University, 2018). There are three processes. The first process is to extract data from food nutrition tables. Then, document ingredient names, descriptions, nutrient content, and amino acid composition. The last process categorizes data by food type and nutrient profile per 100 g. For example, an entry such as “Coconut milk, canned, per 100 ml” offers detailed nutrient profiles well-suited for semantic modeling.
Unlike many existing food ontologies that categorize ingredients as classes, this ontology treats each ingredient as an instance of the class. This approach facilitates a direct connection between ingredients and menu items through object properties like has_ingredient, has_main_ingredient, and has_seasoning_ingredient. Furthermore, by representing ingredients as individuals, the ontology becomes more flexible and easier to maintain. New ingredients and menu items can be introduced without modifying the core class hierarchy, ensuring structural stability while enabling incremental updates in the assertional component.
Collecting Food Menu Data
The final step captures detailed menu information for personalized recommendations. There are three processes. The first process is to gather traditional Thai menu data from four regional cuisines (Thai Food Heritage, 2016). Then, document dish names, ingredient lists, proportions, and cooking methods. The last process is to map dishes to corresponding ingredients and nutritional attributes.
These menu items are connected to the ontology through explicit object properties that link individual “MenuFood” items to their respective “Ingredient” components. These relationships highlight the functional roles of each ingredient, whether it serves as a primary component, a flavoring agent, or a complementary side dish. For instance, “M_TomKhaGai” is associated with “Coconut milk, canned, per 100 ml” through the “has_oil_and_fat_ingredient” property. This structural framework facilitates logic-based queries that allow the retrieval of menus tailored to meet specific dietary restrictions or therapeutic requirements.
This semantic representation provides a foundation for reasoning-based inference in subsequent stages, where particular food properties, ingredient combinations, and preparation constraints are utilized to generate personalized menu recommendations.
Inference Engine
This process constructs an inference engine using a semantic food knowledge graph. The inference engine is developed by designing food conceptual knowledge, creating a food knowledge graph, and generating semantics rules.
Designing Food Conceptual Knowledge
The previous section summarizes the relevant knowledge of the data to create an analytical table. The table yields a set of food vocabulary and descriptions that describe the food as a set of rules. The rules are to link the food ingredients to the recommended food menu. Then, the vocabulary table will be transformed into a conceptual knowledge diagram to guide the ontology process. An example of conceptual knowledge about food for depression and physical illness is shown in Figure 3. The conceptual diagram visualizes the relationship between various nutrients and their effects on depression. The diagram highlights essential nutrients like Chromium, Zinc, Magnesium, Omega-3 fatty acids, Iron, and Folate, which work best with vitamins C and E. These vitamins retain their effectiveness through non-heat processes, but sodium and potassium can affect vitamin E’s efficacy.

An example of conceptual knowledge about food for depression.
The conceptual knowledge diagrams are guidelines for developing ontology, finding relationships between nutrients and food ingredients, and establishing semantic rules. According to Figure 3, for instance, sweet potato (Ingr6) contains an ingredient known as vitamin B9, which has been linked to improved depressive symptoms. Its effectiveness increases when the food preparation method avoids heating processes, as indicated by the “Preserved under” relationship to non-heat process. One of the inference rules derived from this conceptual structure can be articulated as follows: “If a menu includes a main ingredient that is a source of Vitamin B9, and the preparation method is classified as Non Heat Process, then the menu is associated with alleviating depression.” This example demonstrates how the conceptual framework has been operationalized into formal rules to enhance inference for menu recommendations. A corresponding rule can be expressed as: menu_high_vitamin_b9_food
Subsequently, we established a higher-level class to represent menus deemed beneficial for those suffering from depression explicitly. Specifically, the class menu_relate_depressive was defined as follows:

The knowledge gained from the research was used to develop a food knowledge graph focusing on dietary restrictions in both mental and physical conditions. This research uses ontologies to help define the structure of the food knowledge graph. Creating an ontology for a knowledge graph can be extended to several established ontologies. The extended existing ontologies aim to identify and define relevant concepts for the knowledge graph, focusing on Thai cooking methods, food descriptions, and ingredient taxonomies. There are three processes; the first is collecting data from existing ontology-based systems (Clunis, 2019; Maimone et al., 2018; Mckensy-Sambola et al., 2021; Rawte et al., 2021; Taçyıldız & Çelik Ertuğrul, 2020) for patient menu recommendations, assessing their focus on nutrient content, patient biodata, and gaps in addressing broader food and medical factors. Then, the second process gathers data from FoodOn ontology (Dooley et al., 2018) and integrates terminology from sources like CDNO, CHEBI, DOID, and NCBITaxon to address the intersection of food, chemical, and medical science.
Instead of importing external IRIs, we opted to maintain internal control over term naming and class hierarchy for practical implementation. Specifically, for ingredient items derived from biological sources, we incorporated taxonomy classes from NCBITaxon to accurately represent their organismal origins. Rather than importing the entire taxonomy, we selected terms up to the genus level to serve as OWL classes (e.g., Glycine, Oryza, Brassica). Ingredients with established scientific names (e.g., “Soybean” identified as Glycine max) were modeled as individuals and assigned to the corresponding genus-level class. This design approach enables the grouping of ingredients based on biological characteristics using a taxonomic hierarchy, thus facilitating semantic inferences such as allergen detection (e.g., legumes from the Fabaceae family) or nutritional categorization (e.g., leafy greens from the Brassica genus). It also aligns with how expert-curated Thai food composition data frequently provide Latin binomial names, ensuring consistent cross-referencing. However, some processed or composite food items in the dataset, such as flavored or condensed milk products, lack explicit scientific names or taxonomic annotations. In such cases, class membership could not be determined reliably based on biological hierarchy. Therefore, to avoid speculative modeling, subclass relationships such as milk_and_products
Additionally, for ingredient instances featuring descriptive modifiers (e.g., “Coconut milk, canned, per 100 ml” or “Cassava, tuber, fresh, raw”), we parsed these comma-separated descriptors to inform class membership. These descriptors were mapped to existing FoodOn classes representing preparation state, maturity level, and physical condition (e.g., Fresh, Raw, Dried, Boiled, etc.).
For example, an ingredient labeled “dried, roasted, ground” was linked to food particles, while “roasted” mapped to Roasted Food Products; both subclasses were derived from or adapted from FoodOn. This parsing methodology enabled us to systematically assign semantic meanings to food items using structured ontology terms, enhancing the precision of class definitions and facilitating reasoning about preparation-sensitive nutrients (e.g., heat-sensitive vitamins). Moreover, it ensures that localized food data aligns with internationally recognized vocabulary standards. A complete list of reused classes can be found in the FONDUE’s GitHub repository (Saengsupawat et al., 2025).
The last process is to collect additional food and medical factors. Food-related factors include cooking methods, patient preferences, physical activity, chewing and swallowing abilities, food–drug interactions, diet prescriptions, and religious beliefs. Medical factors (Sathyanarayana Rao et al., 2008) include depression, emphasizing its impact on appetite, nutritional status, and treatment via diet therapy.
The FONDUE food knowledge graph creates a comprehensive ontology populated with instance data, resulting in a rich and interconnected dataset. This knowledge graph addresses issues related to depression and malnutrition. The ontology comprises 862 classes, 7 objects, and 6 data properties. The main classes include food menus and four categories of ingredients from the Thai food database: main ingredients, seasoning ingredients, flavoring ingredients, and side dishes. Main ingredients are the foundation of each recipe, providing the bulk of its substance and primary nutritional value. These include meats, seafood, eggs, tofu, and staple carbohydrates such as rice and noodles. Seasoning ingredients adjust the overall flavor profile of a dish, contributing elements of saltiness, sweetness, sourness, or pungency. Common seasoning ingredients include fish sauce, oyster sauce, soy sauce, palm sugar, salt, and chilies. Flavoring ingredients give Thai cuisine its signature aroma and depth. These typically consist of herbs and spices like lemongrass, kaffir lime leaves, galangal, garlic, shallots, coriander root, and various curry pastes. Finally, side dishes or accompaniments complement and balance the main dish by offering fresh textures or cooling elements. Examples include sliced cucumbers, small salads, fresh vegetables, or dips, enhancing the overall dining experience. Each food menu has properties that reflect its characteristics, and the relationships between menus and their ingredients are crucial for classifying menu items and making inferences about them. In the food knowledge graph, the food menu class includes 106 instances, while the ingredient classes consist of 595 instances.
A key object property, has_ingredient, is divided to has_main_ingredient, has_condiment_ingredient, and subdivided to has_seasoning_ingredient, has_flavoring_ingredient, and has_oil_and_fat_ingredient. Although oil and fat are classified as ingredients based on culinary conventions, their health implications are inferred through co-analysis with cooking methods, such as deep frying (in oil). Additionally, side dishes (has_side_dish) are represented as co-consumed components, contributing extra nutritional or sensory value. This modeling approach allows for more granular reasoning and enhances the interpretation of the generated food recommendations.
To address performance and traceability concerns, the ontology design adopted a two-stage approach: nutrient-related classes were initially defined using OWL-DL axioms, and individuals were reasoned over in modular segments to infer membership. The reasoning strategy emphasized a forward-chaining approach, where rules were applied to infer menu-level classifications based on ingredient roles (e.g., has_main_ingredient) rather than backtracking through nested ingredient hierarchies. These inferences were subsequently asserted for stability and efficient querying. Moreover, inverse roles such as is_ingredient_of were omitted due to the lack of compositional data for processed foods. The ontology integrates asserted and inferred class membership using equivalence axioms (DL-based). For consistency and reasoning, these axioms were directly encoded into the OWL representation using Protégé. While exact ingredient quantities (such as grams) are not included, the structure of the object properties reflects relative amounts: “has_main_ingredient” indicates major nutritional contributors that are typically used in larger quantities, whereas “has_seasoning_ingredient” and “has_flavoring_ingredient” point to ingredients that are used in smaller amounts primarily for taste or aroma.
To accurately reflect culinary realities, the ontology models ingredient roles through context-dependent object properties, specifically has_main_ingredient and has_flavoring_ingredient, rather than relying on mutually exclusive categories. This approach allows an ingredient, such as lemon basil, to serve as either a subtle flavoring herb or a key vegetable component, depending on the regional dish (e.g., Thai Isan-style soups). Such modeling ensures semantic flexibility, enabling the same ingredient to fulfill various roles across different menu instances without logical inconsistency. The asymmetric application of the has_ingredient and has_main_ingredient properties effectively captures distinct culinary mechanisms that create a crispy texture. For deep-fried menu items (categorized as crispy-crunchy_menu), the has_ingredient property is employed, reflecting the technical understanding that even a small quantity of starch can achieve crispness when cooked in oil. In contrast, for uncooked dishes like salads, the has_main_ingredient property is utilized, as the crispness is primarily derived from the predominant raw vegetable or fruit component rather than a minor ingredient. This modeling approach ensures that the ontology accurately reflects the semantic subtleties of texture production as recognized in culinary science. This proxy approach captures the semantic nuances of texture production as understood in culinary science. It allows for inferences about the nutritional content of each menu based on the functional roles of its ingredients.
The hierarchical diagram of the ontology in Figure 4 provides a visualization of the food knowledge graph. This graph includes the entities, relationships, individuals, and food items relevant to FONDUE’s food knowledge graph for depression and malnutrition.

A visualization of the food knowledge graph.
After developing the food knowledge graph, the next step was to create semantic rules for generating patient-specific menus using description logic (DL) and SPARQL query language. The descriptive logic rules consist of logical operators such as “and,” “or,” and “some.”
For example, some physical conditions, such as soy allergies, are challenging to distinguish between menus containing a soy-allergenic ingredient and other menus for further food inference. In the menu_contain_soybean class, a descriptive logic “has_ingredient some (Glycine)” is created, which means that a menu that contains glycine will be considered a menu that includes soybeans because the glycine is found in soybeans. After that, to query for menus that are appropriate for patients with a soy allergy, the SPARQL query language uses a command “SELECT ?x WHERE {{?x rdf:type ment:menu_food } minus {?x rdf:type ment:menu_contain_soybean}}” to eliminate the soy-containing menu items by applying menu_contain_soybean classes derived from the descriptive logic.
An example of a SPARQL query is presented in Table 3, while examples of description logic (DL) that are associated with the query are shown in Table 4
An Example of a SPARQL Query.

An Example of a SPARQL Query.
Examples of Description Logic (DL).

A complete list of semantic rules, that is, 311 DLs and 48 examples of SPARQL queries, can be found in Saengsupawat et al. (2024b), where all semantic rules were based on food descriptions from the open food database and reviewed by experts.
Designing an ontology for dietary recommendations presents unique challenges under the open-world assumption (OWA), particularly when dealing with incomplete ingredient metadata. In OWL-DL, the absence of a statement does not imply its negation, meaning that just because a menu does not explicitly state that it includes a cooked ingredient, we cannot infer that it is uncooked. This limitation can affect semantic classification when missing or underspecified ingredient or process data.
To address this, the FONDUE ontology adopts a two-layered reasoning architecture:
Layer 1: Core reasoning is implemented in OWL-DL using equivalence class axioms (e.g., menu_high_iron_food
Layer 2: SPARQL filtering is applied on top of these inferred classes to enforce exclusion criteria and contextual logic (e.g., eliminating menu_high_simple_carb_food from menu_relate_diabetes_type_2). This approach allows for expressive queries using constructs like MINUS, which are unavailable in OWL-DL.
A concrete example is the class non_cooked_menu, defined as: non_cooked_menu
However, if a menu lacks the has_menu_main_process property entirely (which may happen with incomplete entries), OWL reasoning cannot infer non_cooked_menu, even if the menu is indeed uncooked. This ambiguity is a direct consequence of the OWA and motivates our layered design. Furthermore, we represent menus and ingredients as individuals, rather than classes, to support instance-level reasoning and modular querying. This choice enables the model to efficiently infer properties over dynamically added menu items without altering the TBox schema. Although this sacrifices some class-level inheritance benefits and compatibility with specific external ontologies (e.g., FoodOn), it significantly improves the practicality of SPARQL-based recommendations. By separating logical reasoning (OWL-DL) from application-specific filtering (SPARQL), FONDUE ensures robustness in incomplete data and supports explainable, context-aware decision making. To operationalize this two-layered architecture in practice, the model performs OWL-DL reasoning over modular data segments to infer menu classifications (e.g., menu_relate_depressive, menu_high_iron_food) and then materializes (i.e., asserts) these inferred types. This step ensures that SPARQL queries can reliably operate over an ABox with explicit class memberships, even in OWA-induced incompleteness. The SPARQL layer then executes over these materialized types to enforce exclusion criteria, user preferences, or application constraints using constructs such as FILTER, MINUS, and aggregation. This separation between inference and retrieval preserves both reasoning rigor and query efficiency. Furthermore, this strategy aligns with a forward-chaining approach, starting from asserted facts (e.g., has_main_ingredient) and applying inference rules to derive classifications, rather than reasoning backward from target classes or property inverses (e.g., is_ingredient_of), which is impractical under missing data conditions.
User Inference
The user interface considers the patient’s physical and mental condition and suggests suitable menus. Figure 5 shows the process for a service user to request a food menu for a patient. This figure features a graph that helps infer suitable food menus based on the user’s dietary requirements. The nodes in the graph represent food items (e.g., beef, lime, spicy red curry) and dietary categories (e.g., weight loss, depression, dry mouth). The edges indicate the relationships between these nodes (e.g., “has a main ingredient,” “belongs to,” “is equivalent to”).

The process for a service user to request food menus for a patient.
The model queries the knowledge pre-reasoned by OWL-DL and a reasoner. For example, the menu item Spicy Red Curry with Beef includes Beef as the main ingredient and Leech lime leaves as a flavoring ingredient. Beef is categorized as a high-protein food, making the dish suitable for individuals experiencing weight loss. Additionally, it is rich in zinc, which provides therapeutic benefits for patients with depression. Leech lime leaves are classified under the Citrus class due to their botanical characteristics. In Thai culinary culture, citrus-based aromas such as those from Lime or Leech lime are commonly perceived as refreshing or “cool-scented” and are associated with the desirable attribute of aroma in food. Based on the expert-derived semantic rules encoded in the ontology, dishes that include citrus-based ingredients are inferred to possess aromatic qualities. Specifically, the class Fresh_Aroma_Menu is logically defined using an OWL equivalent axiom that states:
Fresh_Aroma_Menu
This axiom means that any menu containing at least one ingredient from the Citrus class is inferred to be a member of the Fresh_Aroma_Menu class. Furthermore, the ontology includes a semantic rule stating that menus suitable for patients experiencing dry mouth are equivalent to those in the Fresh_Aroma_Menu class. As such, Spicy Red Curry with Beef is automatically classified into menu_relate_dry_mouth and other relevant classifications such as menu_relate_weight_loss and menu_relate_depression. This example illustrates how OWL-DL equivalence definitions, semantic rules, and cultural interpretations enable multi-axial, logic-based reasoning over menu foods. The approach supports explainable and adaptable recommendations grounded in both nutritional science and culinary domain knowledge. Following OWL-DL reasoning, the ontology classifies food menus into appropriate semantic categories based on their ingredient composition and preparation methods. These class definitions were deliberately constructed under the open-world assumption as aforementioned, which acknowledges that the absence of information does not imply negation. This modeling approach prevents incorrect inferences due to incomplete data in complex domains such as food, where certain ingredients may or may not appear across different menus. Consequently, instead of defining classes using strict negative constraints (e.g., “not recommended for X”), we adopted naming conventions that reflect positive semantic relevance, such as menu_relate_diabetes, menu_high_iron, or menu_relate_dry_mouth. These indicate that a given menu possesses properties relevant to specific health needs without asserting exclusivity or exclusion of other traits. The filtering of menus based on application-specific requirements is then handled at the query level using SPARQL. For instance, if a menu is classified under both menu_relate_diabetes and menu_high_simple_carbohydrate, the querying process can be designed to eliminate such results using clauses like MINUS or logical filters. This two-layered design semantic classification via OWL-DL and conditional selection via SPARQL ensures flexibility, avoids logical conflicts during reasoning, and supports robust decision-making aligned with clinical dietary recommendations.
The current system features a graphical user interface (GUI) tailored for nutritionists to query appropriate food menus for patients with specific health conditions. This interface enables users to input pertinent patient information, such as symptoms or dietary restrictions, and receive customized menu suggestions generated by the underlying ontology and inference rules. However, it currently lacks support for dynamic ontology editing. When new dishes or ingredients need to be added, ontology engineers must manually define these as new individuals in Protégé or a similar OWL editor. Each new menu must be linked to its component ingredients using properties such as has_ingredient and its sub-properties (e.g., has_main_ingredient, has_flavoring_ingredient). Semantic reasoning is then applied using the Pellet reasoner to update inferred classifications. After reasoning, the user interface retrieves the updated recommendations through predefined SPARQL queries.
Evaluation Environments
The model evaluation focuses on the accuracy of the food menu recommendation model. The food menus used in this experiment consisted of 102 Thai food menus taken from the Thai Food Institute, which comprised Thailand’s regional food, including Central, Northern, Northeastern, and Southern (Thai Food Heritage, 2016). The food menus are recommended according to the patient’s various conditions. Seven nutrition experts thoroughly evaluated the recommended menus for patients using the Delphi technique (Rowe & Wright, 1999). The Delphi technique is an iterative and anonymous method that enabled the experts to reach a consensus on the suitability of the menus for the thirty most prevalent patient case studies, including individuals experiencing depression, weight loss, and dry mouth. The experimental evaluation maintained its reliability by selecting leading experts in the field and focusing on the most prevalent case studies despite having a limited number of cases and experts. Each of the seven experts was provided with a condition-specific dataset that included the model’s recommended and non-recommended menus, complete with detailed ingredient lists and preparation methods. To maintain focus, biodata such as age and gender was omitted. The dataset specified 30 distinct clinical conditions to facilitate consistent and targeted evaluation. The scenarios were crafted without any accompanying medical history to ensure that the evaluation concentrated solely on the dietary suitability for the specified conditions. Experts were requested to assess the appropriateness of each menu based on their professional understanding of nutritional therapy related to each condition rather than on the characteristics of individual patients.
Performance measures of the recommendation results used precision, recall, and F-measure as equation (1)–(3).



The evaluation was processed when the model recommended food menus. Then, each nutrition expert assessed whether the suggested menus were appropriate. If experts consider the menu the model recommends to be appropriate, the evaluation concludes that the recommendation is correct. After that, the performance metrics were calculated using
The data used in the test cases is derived from medical records, that is, secondary data. All data has been anonymized or de-identified to ensure patient privacy and confidentiality. No personally identifiable information is included, making the data suitable for analysis while adhering to ethical research standards. There are 30 prevalent cases of depression, as shown in the Experimental Data Set in Saengsupawat et al. (2025), evenly split between males and females aged 20 to 49. Seventeen patients have non-communicable diseases: three with type 2 diabetes, five with hypertension, and eight with weight gain and obesity. Ten patients have food allergies, and eighteen display other symptoms like dry mouth and tooth decay.
The evaluation results showed that the accuracy of retrieved relevant menus was good, with an average precision of 0.86, as shown in Table 5. However, the completeness of retrieved relevant menus was moderate (average recall
FONDUE Performance Metrics Tested on Thirty Patient Case Studies.

FONDUE Performance Metrics Tested on Thirty Patient Case Studies.
Table 5 presents the performance metrics, including true positives (
According to all nutrition experts who commented on the reasons for disagreeing with the menus suggested by the model, the opinions can be summarized as follows. Inference rules derived from the information source cover only some cases. For instance, the collected knowledge indicates that the recommended menus for individuals with constipation should be water-based. However, it fails to mention that bitter ingredients can help alleviate constipation. As a result, the model does not recommend menus with non-watery bitter ingredients, such as bitter gourd stuffed with minced pork soup, for depressed patients with constipation, despite its recognized laxative effects in Thai dietary practices. This false negative outcome can be attributed to two factors. First, although bitter gourd (“Gourd, bitter, mixed variety, raw”) is widely recognized in Thai dietary practice for its laxative effects, the food composition data lacked anatomical descriptors (e.g., fruit part), which are required by the semantic rule for classifying water-insoluble fiber foods. Second, the knowledge base used to construct inference rules was derived from standardized clinical nutrition sources, which did not include culturally embedded heuristics such as the digestive effect of bitter taste. This oversight stems from gaps in the knowledge base and the fact that the main ingredient was categorized simply as “Gourd, bitter, mixed variety, raw,” lacking specific anatomical details. The semantic rule for classifying water-insoluble fiber necessitated identifying plant parts (e.g., stem, shoot, leaf), which was absent from the food composition entry. As a result, the ingredient could not be classified as a high water-insoluble food, leading to its exclusion during the inference process. Future work will incorporate culturally specific heuristics, such as the laxative effects of bitter taste commonly acknowledged in Thai dietary practice, into the knowledge base. This would involve extending the rule set to include non-nutrient-based food properties (e.g., taste profile) and mapping those to their physiological effects, where supported by domain experts. Moreover, the knowledge base may also need to include specific information about Thai food. For example, it is widely known that individuals who experience bloating should avoid consuming gassy foods like beans. However, while general dietary knowledge extracted from standard dietetic textbooks used in clinical nutrition education explicitly states that individuals experiencing bloating should avoid legumes or other gas-producing foods, it does not mention coconut milk. Coconut milk is not typically included in general knowledge sources or international food databases, as it is rarely featured in non-Thai menus. As a result, although coconut milk is widely used in Thai cuisine, it was not flagged as problematic in the initial rule definitions. Consequently, some recommended Thai dishes containing coconut milk were not excluded from the output, even for patients who may experience bloating.
Large language model (LLM) chatbots have recently revolutionized health informatics (Yu et al., 2024) and various systems, including recommendation systems (Bao et al., 2023; Trichopoulos et al., 2023). This study also compared the performance of FONDUE with food menu recommendations generated by LLM chatbots. This experiment assessed an LLM chatbot’s ability to answer questions requiring specialized knowledge in dietetics by comparing ChatGPT, Gemini, and FONDUE. The chatbot was presented with 102 Thai food menus, each consisting of various ingredients, and asked to determine whether a menu was suitable for depressed patients suffering from physical illnesses. The questions included scenarios based on a range of mental and physical symptoms experienced by previous patients.
In the assessment process, the chatbot’s first response to a question was considered its final answer. To avoid hallucinations, ChatGPT required a “re-login,” while Gemini needed a “New chat.” The evaluation defined “Yes” as a recommendation of the corresponding menu and “No” as a non-recommendation based on the given conditions.
If the chatbot did not provide a clear answer, the researcher had to rely on the wording of the response to recommend the menu. A response containing negative phrases such as “may not be suitable for” or “avoid” indicated a “No,” meaning the menu was not appropriate for the patient with a specific health condition. Conversely, if the response did not contain any negative phrases, it could be inferred that the answer was “Yes,” suggesting that the menu suited the patient.
After identifying the “Yes” or “No” classifications for all cases, seven human experts assessed the correctness of each menu’s results using the FONDUE assessment method. A confusion matrix was then calculated to determine the true positive (
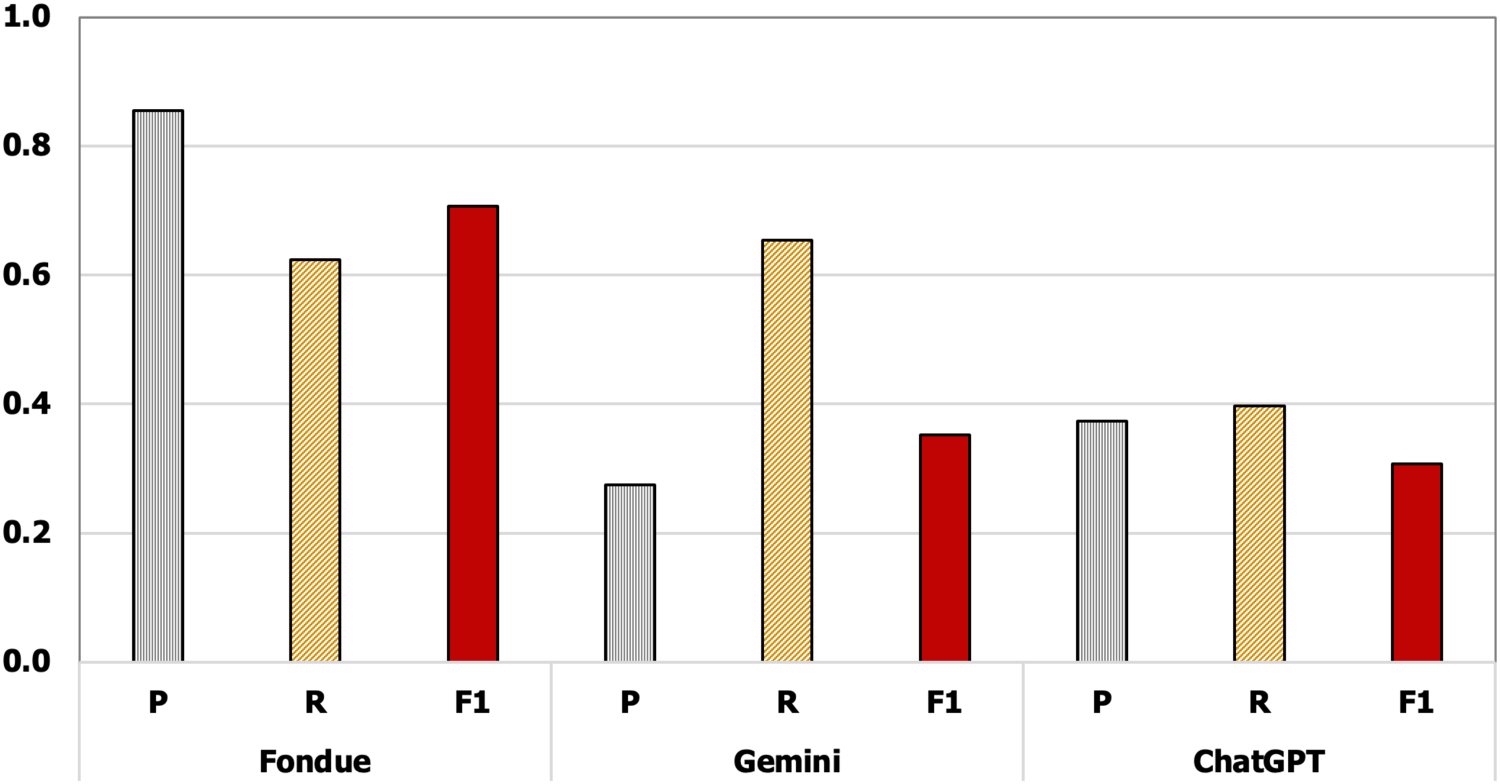
FONDUE performance comparison with LLM chatbots.
Current food recommendation systems for individuals with mental health conditions frequently fall short in providing personalized menu options that address both psychological and physical well-being. This study presents a specialized food recommendation model tailored specifically for individuals suffering from depression and experiencing malnourishment. By integrating evidence-based nutritional interventions to improve mental health and incorporating cooking methods that enhance sensory appeal and nutrient content, the proposed model can assess the appropriateness of customized menus that align with individual physical health profiles.
The evaluation of this model shows it to be both innovative and practical, offering a wider variety of menu options. For example, the model takes into account preparation techniques that improve digestibility. It might recommend slow-cooked beef dishes for patients with digestive sensitivities while avoiding hot dishes that contain mood-boosting substances for individuals suffering from oral ulcers. In contrast to previous recommendation models like NUTRI (Kitwatthanathawon et al., 2024) and IAMHAPPY (Gyrard & Sheth, 2020), which failed to consider physical health factors or the side effects of medications for depression, this new proposed model provides a more comprehensive approach. For instance, while previous models suggested hot chocolate for patients with depression—due to its magnesium content that can help improve mood—they overlooked that those with oral ulcers should avoid hot drinks.
It is important to note that the completeness of the model hinges on the dietary knowledge sources utilized. This study extracted rules from widely accepted clinical dietetic textbooks; however, these resources primarily reflect generalized guidelines that are relevant internationally. Consequently, the initial knowledge base did not encompass certain culturally specific or empirically practiced relationships, such as using bitter ingredients to alleviate constipation or the adverse effects of coconut milk on patients with bloating. For example, while Thai cuisine often values citrus aromas for their benefits in alleviating dry mouth, similar dietary reasoning regarding bitter foods and digestion is absent in standard references and, as a result, missing from the model. Likewise, coconut milk is seldom included in international food ontologies or diet therapy sources and, therefore, was not flagged despite its familiar presence in Thai menus. As a result, some potentially problematic menus were not excluded for specific symptoms.
Additionally, the overall performance should be considered based on weighted recommendations that distinguish between high-risk classifications, such as allergen-related false positives, and low-risk classifications, like mildly disagreeable menus. This approach will yield more clinically relevant insights. Future iterations of the system will incorporate these weighted recommendations to address this significant concern.
Conclusions
This article discusses the development of a food menu recommendation model called FONDUE, specifically designed for patients with depression who are also experiencing malnutrition. The FONDUE aims to suggest food menus that cater to the nutritional needs of individuals suffering from depression, particularly those whose physical illnesses impact their nutritional status. The recommended menus are composed of nutrients known to affect depression positively. The FONDUE was designed using a food knowledge graph embedded with description logic rules and the SPARQL query language to infer the food menus. The FONDUE was evaluated by selecting thirty prevalent case studies of depressed patients with various physical ailments. Seven nutrition experts assessed the recommended menus for each case, focusing on the alignment between the menus and the patient’s specific conditions. The experimental results indicated that FONDUE could recommend menus consistent with the patient’s physical and mental health needs, achieving an overall performance score (F-measure) of 0.74. When compared with ChatGPT and Google Gemini, the evaluation results indicated that it outperforms others.
Nevertheless, this research has several limitations. First, the number of food menus used as experimental data is limited because these menus must contain specified ingredients and nutrients. Second, although the ingredient and menu data sources used in this study (as specified in Sections 2.1.2 and 2.1.3) provide information on the nutrient components, they do not cover all the nutrients that are relevant to a particular menu or ingredient, especially nutrients that are relevant to depression, such as omega-3 fatty acids and folate. Therefore, further clinical studies and consultation with experts are needed. The above limitations of this research are that updating the ingredient or menu data within the ontology requires a thorough search of additional literature to determine whether the new menu or ingredient contains nutrients that are beneficial to depression, as this information is not available from existing data sources. Therefore, data analysis requires considerable time and resources. Finally, although the quantity of nutrients may influence the severity of diseases, a thorough clinical examination is necessary for a complete analysis. In this study, the recommended menu for patients with depression solely concentrated on the types of nutrients included, which represents another limitation of our research.
The present study compared FONDUE with the baseline performance of LLMs. Future research could delve into hybrid architectures that seamlessly integrate explicit rule-based reasoning into LLMs. Providing these models with the same ruleset utilized in FONDUE can enhance their consistency, transparency, and domain-specific accuracy. The existing ruleset was crafted manually, drawing on domain expertise and established guidelines. However, further efforts are necessary to formalize, validate, and expand these rules to address more complex or nuanced scenarios. Utilizing expert consensus methods, ontology engineering, or semi-automated rule extraction from relevant literature could facilitate this enhancement. A more comprehensive ruleset could significantly improve both FONDUE and rule-augmented LLM models. Future enhancements could significantly refine the model by adjusting the menu to feature new food options for individuals with depression. In addition, providing more comprehensive information on ingredient details, including nutrient quantities, preparation methods, and potential side effects across different regions, would be beneficial. Lastly, integrating more Thai-specific knowledge and expert insights would improve the model’s accuracy. Upcoming developments may include a recommendation model that focuses on the nutritional content of the menus. Additionally, by expanding the number of inference rules, these improvements will enable the model to recommend more appropriate dietary options for depressed patients who face malnutrition in real-world settings.
This study underscores the significance of enhancing ingredient metadata to facilitate more accurate reasoning. For example, the lack of detailed descriptors such as plant part, preparation method, or functional classification can hinder the appropriate classification of a menu as beneficial. A notable example is a bitter gourd, which was not recommended for patients with constipation due to incomplete metadata that omitted information about the plant part, thus preventing its identification as high in water-insoluble fiber. Similarly, culturally relevant dietary patterns, such as coconut milk’s adverse digestive effects or bitter ingredients’ therapeutic role, were overlooked because they were not included in international dietary knowledge sources. Future model versions could achieve greater completeness and cultural relevance by addressing these gaps, incorporating localized dietary knowledge, and refining the granularity of ingredient classification.
Footnotes
Ethics Approval
The study was approved by the Ethics Committee of the Suranaree University of Technology (Application number EC-62-88) and complies with international guidelines for human research protection, including the Declaration of Helsinki.
Consent to Participate
All participants provided informed consent before inclusion, and study data were anonymous or de-identified.
Author Contributions
J.A. formulated the research question, while P.S. and A.T. performed data manipulations. Figures were generated by J.A., P.S., and T.A. Data analysis was performed by J.A. and P.S. Writing and reviewing were done by J.A. and T.A. All authors read and approved the final manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Suranaree University of Technology (SUT), Thailand Science Research and Innovation (TSRI), and the National Science Research and Innovation Fund (NSRF) (NRIIS fiscal year 2025).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability
The data sets generated and/or analyzed during this study are available, with the complete ontology, in the FONDUE GitHub repository (Saengsupawat et al., 2025).