
Abstract
To enhance 3D simulation efficiency for large-scale patterned fabric structures, a GPU-based yarn-level parallel computing framework is developed. individual yarns are adopted as the fundamental units of parallelization. Two key algorithms are devised within this framework: a parallel spline trajectory fitting algorithm and a parallel yarn mesh generation algorithm. Comparative experiments with conventional serial methods show that a maximum speedup of up to 10-fold is achieved by the proposed parallel strategy. Moreover, the speed imbalance across different stages during fabric simulation is effectively alleviated by the method. The algorithms are implemented in OpenCL, demonstrating robust performance across different GPU hardware. The applicability of the method to a wide range of fabric types, including both woven and knitted large-patterned fabrics, is confirmed through simulation case studies, underscoring its substantial potential for real-world deployment.
Keywords
Introduction
With the rapid development of computer graphics and high-performance computing, three-dimensional (3D) simulation has emerged as a key method in both research and industry. 1 In fields such as fabric computer-aided design (CAD), game development, and animation production, fabric-structure simulation has been widely recognized for its value.2 –4 This simulation significantly reduces the need for physical prototyping in the traditional textile industry. It also enhances the visual realism of fabrics in virtual environments. However, in textile design and rendering, achieving an optimal balance between realism and computational efficiency remains a challenge. 5 The simulation of large-patterned fabrics is particularly demanding. The complexity of the motifs and the strict requirements for detail lead to high computational demands. Additionally, conventional methods often result in slow simulation speeds. 6 Therefore, it is crucial to leverage the powerful parallel computing capabilities of Graphics Processing Units (GPUs) for the simulation of large-patterned fabrics.
Due to the limitations of computer hardware performance, two-dimensional color blocks were commonly used in early fabric simulation research to abstract the yarn topology. Simplified lighting models were also employed to simulate the three-dimensional visual effects of the fabric surface. 7 Özdemir and Başer 8 assumed that the cross-sectional shape of the yarns in woven fabrics is elliptical. Real yarn images were captured as the basic unit for fabric simulation, and the yarn centerline trajectories were constructed based on an elastic curve model. The fabric structure simulated by this method was relatively accurate, but the results ignored yarn interaction forces. Li et al. 9 considered this phenomenon and used a spring particle model to simulate the deformation behavior of the Jacquardtronic lace structure. In a subsequent study, 10 they also improved the Blinn-Phong lighting model 11 to capture the appearance features along the yarn axis, further enhancing the realism of the lace structure. While computationally feasible for large-patterned fabrics, these 2D methods have not been able to represent the 3D spatial arrangement of yarns or the microstructural geometry of fabric surfaces. This imposes a realism bottleneck and hinders applications in weaving simulation and virtual try-on. 12
To enhance realism in virtual large-patterned fabrics, simulation must overcome the spatial abstraction limitations of 2D systems through yarn-level solid modeling. 13 Zheng et al. 14 developed a yarn-level spring particle model. Their approach incorporated fabric structural features, achieving accurate relaxation deformation. However, computational constraints limit this model to small fabric areas. Deng et al. 15 created a woven honeycomb model using Rhino/Grasshopper, which significantly enhanced surface texture realism. Yet, due to insufficient simulation efficiency, the approach forced the reliance on texture mapping for large textiles, such as sofas and clothing. Liu et al. 16 and Xu et al. 17 conducted similar research, even considering fiber-scale fabric simulation. Song et al. 18 proposed a Grooved Ribbon Yarn model. They optimized large-scale coil scene computations using a minimal period replication method. This model improved speed by simplifying the yarn’s geometric structure. However, it did not address parallelization issues before fabric rendering, such as yarn trajectory and mesh generation, which are serial processes. As a result, the parallel computing power of GPUs was not fully utilized. 19 A large body of existing GPU-accelerated cloth simulation research is primarily based on cloth-level abstractions, where fabrics are modeled as continuous surfaces to efficiently solve their dynamic physical behavior.20,21 Such methods have achieved significant progress in modeling draping behavior and dynamic responses. Due to the limitations of this abstraction level, yarn-level structures are typically not explicitly represented. As a result, geometric preprocessing stages, including yarn trajectory generation and mesh construction, are still largely performed using serial computation, and relatively limited research has been conducted on parallel acceleration for these processes. Significant acceleration of dynamic simulation has been achieved through the massive parallelization of the solution process of the governing physical laws. In addition, several mature 3D geometric modeling tools and frameworks for textiles (such as TexGen, 22 TexMind, 23 etc.) have been recognized for their effectiveness in generating high-fidelity yarn and fabric structural models. 24 However, serial computation has typically been employed, and the parallelization potential of the geometric preprocessing stage has not been thoroughly explored.
In summary, existing 3D methods are feasible for fabrics with smaller pattern repeat units, but their efficiency falls short of industrial real-time requirements for large-patterned fabrics. To address this limitation, we propose a yarn-level parallel computing framework designed to overcome serial bottlenecks in yarn trajectory interpolation and mesh generation. The framework incorporates two key algorithms: the Spline Trajectory Parallel Construction Algorithm and the Mesh Parallel Generation Algorithm. The former eliminates sequential dependencies across yarns during trajectory interpolation by treating each yarn as an independent parallel unit. The latter removes serialization in the mesh generation stage by enabling parallel processing of yarn cross-sectional discretization and topology construction through dynamic GPU thread allocation. Implemented within a fabric 3D simulation system, the framework efficiently produces highly realistic virtual representations of large-patterned textiles.
Yarn-level parallel computing framework
Yarn-level fabric 3D simulation typically involves the looping or intertwining of yarns to form the fabric, with yarns as the basic unit. It can be divided into three stages: yarn geometry generation, buffer creation, and fabric rendering. While the rendering stage fully exploits the GPU’s highly parallel rasterization pipeline, the yarn geometry generation stage has traditionally been executed serially on the CPU due to strong sequential dependencies in trajectory interpolation and mesh construction. From a computational perspective, this serial paradigm fails to leverage the GPU’s massive parallel architecture, which is particularly efficient for linear algebra and vectorized operations when independent data units are available. 25 In large-patterned fabric scenarios, where thousands of yarns exhibit similar geometric operations but differ only in input parameters, this mismatch between algorithm structure and hardware architecture leads to a severe performance bottleneck. To address this challenge, a yarn-level parallel computing framework is proposed to restructure yarn geometry generation into GPU-friendly parallel workloads, composed of the Spline Trajectory Parallel Construction Algorithm and the Mesh Parallel Generation Algorithm.
In this framework, yarns serve as the fundamental units of parallelism. All parallel algorithms in this work assign one GPU thread to each yarn, allowing trajectory interpolation and mesh generation to be performed independently across yarns. Parallel speedup is obtained by processing multiple yarns concurrently, while the internal computations within each thread follow the same serial procedures as in the CPU-based implementation.
Spline trajectory parallel construction algorithm
During the generation of virtual yarn trajectories, the key control points of each yarn (e.g. interlacing points and contact points) are first determined based on the fabric structure and process parameters. 26 Subsequently, these control points are interpolated or fitted to obtain a smooth trajectory of the yarn centerline. Let P denote the set of all yarn control points, and n the total number of yarns. The subset Pi (0 ⩽ i < n) represents the control points of the i-th yarn. Let p denote the set of interpolated value points. Taking the cubic Cardinal spline as an example, the generation process of these shaping points can be expressed as follows:

In equation (1), t controls the interpolation progress, with its value ranging from [0,1]. The points Pi,j−1. . .Pi, j+2(1 ⩽ j < m-2, where m is the number of control points of the i-th yarn) represent four consecutive control points. The parameter s can be expressed in terms of the interpolation parameter u (with a value range of [0,1]) as follows:

Figure 1 illustrates the generation process of discrete shaping points representing the yarn trajectory. Since the Cardinal spline is a piecewise cubic interpolation, each curve segment is generated from four consecutive control points. Therefore, two virtual endpoints, vs and ve, are added at the beginning and end of the control point sequence, respectively.

Yarn trajectory spline interpolation process.
To ensure that the curve possesses a smooth tangent direction at both the starting and ending points, the construction of vs can be expressed as follows:

Similarly, the construction of ve can be expressed as follows:

Based on the above equations, the yarn trajectory generation process can be represented by Algorithm 1.

The interpolation process in Algorithm 1 is mainly influenced by three parameters: n, m, and K. If the time required for a single interpolation is denoted as ∆ti, the total runtime Ti of Algorithm 1 can be expressed as follows, assuming that the number of control points m is identical for each yarn:

As shown in equation (5), the time complexity of Algorithm 1 is O(n × m × K). Taking woven fabrics as an example, and without applying instancing or duplication algorithms. if the minimum repeating unit of the fabric is replicated λ times along both the warp and weft directions, n increases by a factor of λ, while m increases by a factor of λ 2 (with the control point density kept constant). Consequently, Ti grows cubically. As the fabric size increases, the execution time of the algorithm rises rapidly (for each doubling of the fabric size, Ti increases by approximately eight times). For fabrics with small repeating units, the efficiency of the algorithm remains acceptable; however, it is not suitable for large-pattern fabrics. To address this limitation, the traditional serial spline interpolation algorithm was restructured using GPU acceleration, and a parallel yarn trajectory construction algorithm was proposed, as presented in Algorithm 2.

In Algorithm 2, Ωp denotes the offset array that records the starting position of each yarn trajectory in the global output buffer p. Similarly, Ωτ stores the starting control-point index of each yarn in the flattened control-point array τ. The array τ is a one-dimensional array, in which P is flattened and stored prior to the execution of the parallel algorithm to facilitate efficient GPU access. Within the kernel, each thread processes one yarn independently. Given the starting control-point index startIdx = Ωτ[i] and the number of control points m, the corresponding 3D control points are explicitly reconstructed from τ using a simple indexed loop, as shown in Algorithm 2. Let the time for a single interpolation in Algorithm 2 be denoted as ∆ti′, then the total runtime Ti′ of Algorithm 2 can be expressed as follows:

In the parallel execution phase, each logical processing unit is assigned a unique parallel_id in the range [0, n−1], corresponding to the index of the yarn it processes. The key difference between this algorithm and Algorithm 1 lies in replacing the original serial, yarn-by-yarn trajectory fitting process with the parallel generation of n yarn trajectories.
Mesh parallel generation algorithm
After fitting the yarn centerline trajectory using splines, it is still necessary to generate yarn mesh data—including vertex coordinates, normal vectors, and topological information for subsequent rendering. This process is illustrated in Figure 2.
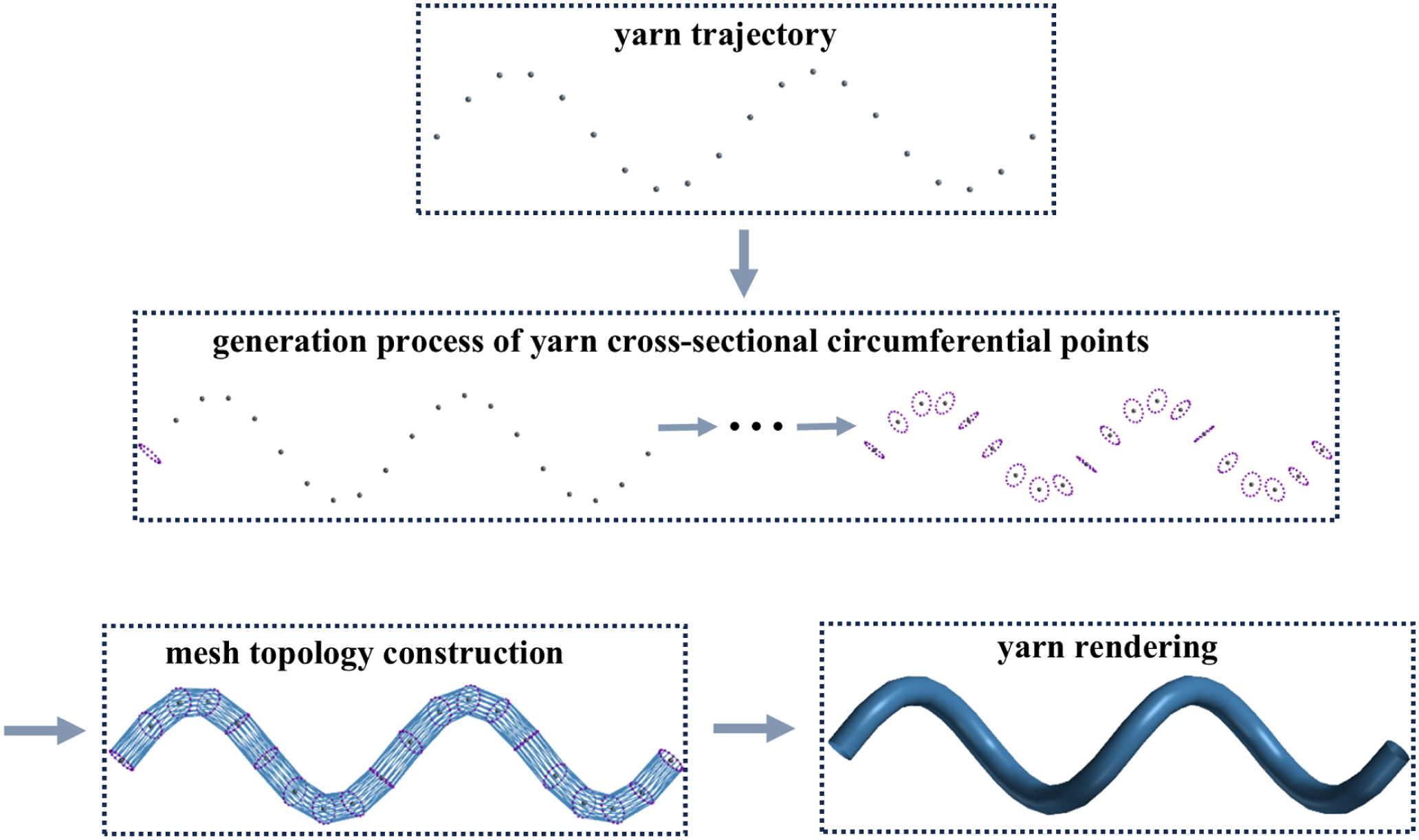
Yarn mesh generation and rendering flowchart.
As shown in Figure 2, the core of the yarn mesh data generation process lies in the computation of vertex geometric coordinates. In this study, the yarn is modeled as a tubular structure with a circular cross-section. The generation of cross-sectional circumference data is computed according to the spatial circle parametric equation 17 :

In equation (7), (cx, cy, cz) represents the coordinate of the center of the circle, (A,B,C) is the normal vector of the spatial circle, r is the radius of the circle, and θ is the central angle. The traditional yarn mesh generation process can thus be represented by Algorithm 3.

Algorithm 3 is influenced by three parameters: n, χ (the number of discrete points along the trajectory), and nc. The number of circumferential divisions nc is a constant factor that does not increase with the problem size, and χ is obtained through interpolation from the number of control points m, essentially making it equivalent to m. Let the time for generating a single mesh vertex be denoted as ∆tm. Then, referring to equation (5), the execution time of Algorithm 3 can be expressed as follows:

Given that its input size is significantly larger than that of Algorithm 1, its performance bottleneck is expected to be more severe in the rendering of large-pattern fabrics. To address this, the algorithm was restructured using a parallelization approach, as presented in Algorithm 4. Similar to Algorithm 2, Algorithm 4 adopts a yarn-level parallelization strategy. During execution, one GPU thread is assigned to each yarn to construct its mesh independently. The input trajectory data are stored in a flattened array τ, and a corresponding offset array Ωτ provides the starting index of each yarn’s trajectory. The mesh data generated by different threads are written to disjoint segments of the global buffer M, as determined by the precomputed offset array ΩM, which eliminates write conflicts and enables efficient parallel execution. Let the time for generating a single mesh vertex in Algorithm 4 be denoted as ∆tm′. Then, the total execution time Tm′ can be expressed as follows:

To provide a comprehensive overview of the implementation strategy, Figure 3 illustrates the schematic comparison between the traditional serial pipeline and the proposed parallel framework.


Schematic comparison of the simulation pipelines: (a) serial CPU pipeline and (b) parallel GPU pipeline.
As depicted in Figure 3, the serial approach (encompassing Algorithms 1 and 3) relies on a sequential CPU execution loop. Crucially, this architecture requires all yarn meshes to be fully computed on the host before a batch transfer of the entire geometric dataset to the GPU buffer can occur. In contrast, the parallel pipeline shown in Figure 3 (implementing Algorithms 2 and 4) leverages the GPU’s massive parallelism. By mapping independent yarns to concurrent compute threads, the proposed framework executes trajectory construction and mesh generation in parallel directly on the device, thereby eliminating the serial bottleneck and minimizing data transfer latency.
Results and discussion
Performance analysis of parallel algorithms
To evaluate the performance of the proposed method in practical applications, Algorithm 2 and Algorithm 4 were implemented based on the OpenCL heterogeneous computing framework using C#. To ensure reproducibility, a yarn-level parallelization strategy was adopted. Specifically, the GPU kernel execution was configured such that each compute thread is mapped to a single yarn, processing its associated control points and geometric primitives sequentially. This strategy aligns with the physical structure of the fabric and effectively reduces memory access conflicts between adjacent yarns. The performance of the algorithms was then assessed using woven fabric as a benchmark.
Performance comparison of parallel and serial algorithms
To quantify the acceleration performance of the parallel algorithms, five virtual woven fabric samples were selected as test samples. These samples have identical organizational patterns but vary in size, as shown in Figure 4. In Figure 4, the parameter K for all virtual woven fabrics is set to 1, and nc is set to 6. It is worth noting that the interpolation density K and the number of cross-sectional circle subdivisions nc play critical roles in the simulation process. The parameter K determines the number of interpolated points between two adjacent control points. A larger K results in smoother yarn trajectories but significantly increases the computational cost. Considering that the density of control points in our model is already sufficient, we set K = 1 to maintain trajectory smoothness while avoiding unnecessary computational overhead. Similarly, nc controls the discretization of the yarn cross-sectional circle. Increasing nc improves the roundness of the yarn cross-section, but also leads to an exponential increase in the number of mesh facets, which burdens memory and rendering performance. Through comparative tests, we found that nc = 6 provides a reasonable trade-off between visual fidelity and computational efficiency, which is why this value is adopted in the simulations.

Virtual woven fabrics in different sizes: (a) 163 × 150, (b) 489 × 450, (c) 815 × 750, (d) 1141 × 1050, and (e) 1630 × 1500.
Let the total number of control points for all yarns be denoted as m′, and the number of shaping points as χ′. The main parameters used in the simulation process are shown in Table 1.
Parameters for fabric rendering at different sizes.

Experiments were conducted on the fabric structure shown in Figure 4 using a device equipped with an Intel(R) Core (TM) i7-8700K processor (clock speed of 3.70 GHz) and an NVIDIA GeForce RTX 5070Ti processor. The experimental results are shown in Table 2, where the execution times of each algorithm are presented in milliseconds.
Comparison of execution time between serial and parallel algorithms.

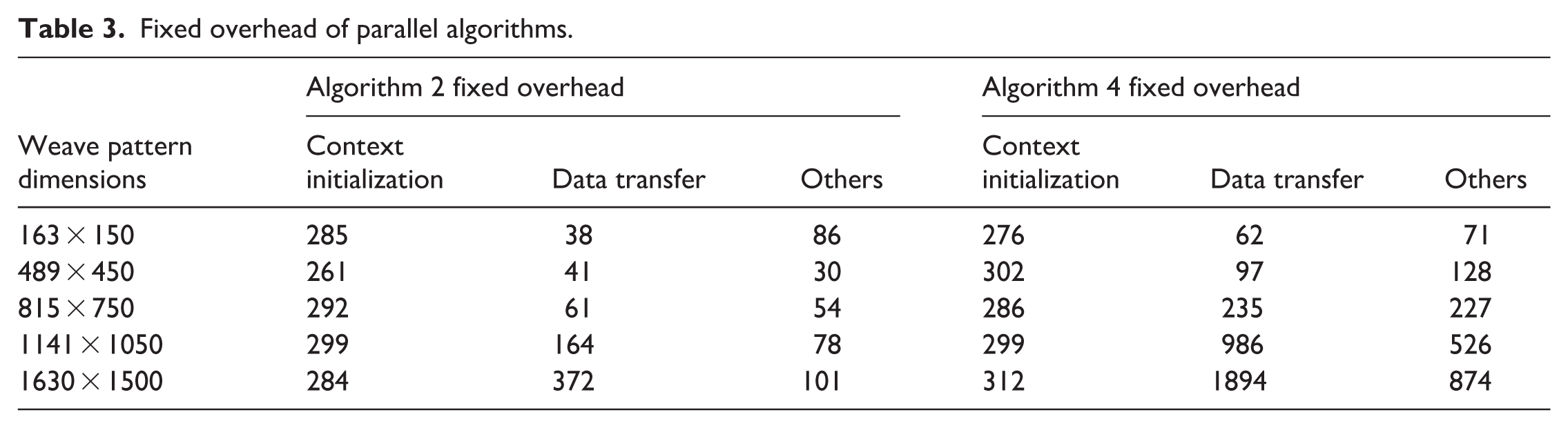
As shown in Table 2, the acceleration benefits of the parallel algorithm are not significantly observed in small-scale fabric patterns, such as 163 × 150. In some cases, the execution time is even higher than that of the serial algorithm. This phenomenon arises because, at small data scales, the fixed overhead of GPU parallel computation (including OpenCL context initialization, data transfer, and resource cleanup) outweighs the computational gains of the algorithm itself. Table 3 presents the fixed overhead of Algorithms 2 and 4 under different weave pattern dimensions. As shown, the execution time of context initialization varies little across scales. However, when the weave size is small, this fixed cost can dominate the total runtime, making the parallel algorithm less efficient than its serial counterpart.
Fixed overhead of parallel algorithms.
Additionally, the acceleration ratio of Algorithm 2 is slightly lower than that of Algorithm 4. This difference is attributed to the variation in input scales. The trajectory points χ processed by Algorithm 4 are generated by interpolating m control points from Algorithm 2. To objectively evaluate scalability and facilitate cross-platform comparison, computational throughput (primitives processed per second) is adopted as a normalized metric. For the largest dataset (1630 × 1500), Algorithm 4 achieves a peak throughput of approximately 37.99 million triangular facets per second. In contrast, the serial CPU implementation saturates at roughly 3.84 million facets per second. This nearly tenfold increase in normalized throughput demonstrates the effective utilization of GPU resources in high-load scenarios, confirming the superior scalability of the proposed method.
Although equations (6) and (9) and theoretically offer an n-fold gain compared to equations (5) and (8), the performance of GPU single-threaded computation is inferior to that of the CPU for tasks with higher computational complexity. Consequently, ∆ti′ and ∆tm′ are much larger than ∆ti and ∆tm, preventing the expected n-fold acceleration. The experiments show that, with adequate computational resources, the proposed parallel algorithm exhibits significant acceleration advantages as the data scale and algorithm complexity increase. The performance gain increases non-linearly with the problem scale.
Verification of the improvement effect of speed imbalance
To verify whether the parallel algorithm improves the speed imbalance between yarn geometry generation and subsequent stages in fabric simulation, tests were conducted. The running times for the three major simulation stages on different virtual woven fabrics were compared, as shown in Figure 5. Both serial and parallel algorithms are shown for the yarn geometry generation phase. The yarn-level parallel algorithm in the geometry generation phase requires complex mathematical operations such as spline fitting, matrix calculations, and iterative computations. Its computational efficiency remains lower than that of the highly optimized rendering pipeline. After targeted optimizations, the execution time of the parallel algorithm for yarn geometry generation has been significantly reduced. The optimized version achieves a speedup of up to tenfold in this phase.
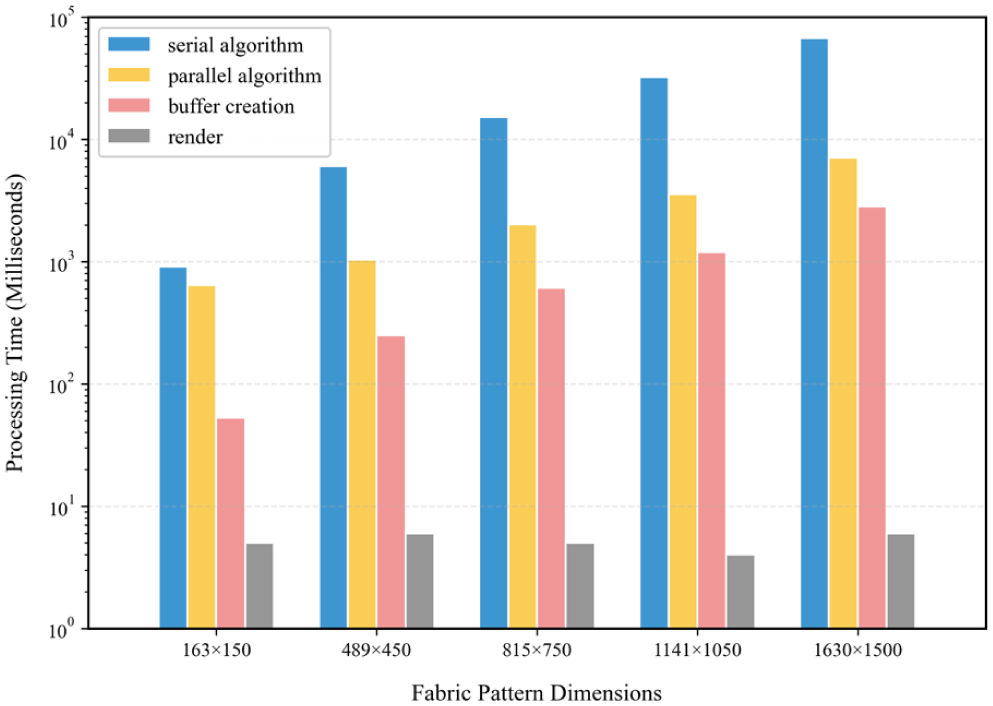
Comparison of execution times for different phases of the simulation process.
Moreover, the optimized parallel algorithm reduced the execution time of the yarn geometry generation phase, bringing it closer to the time required for the buffer creation phase. The magnitudes of both are now comparable, effectively alleviating the speed imbalance issue between different stages. In the traditional serial algorithm, the high computational complexity of the yarn geometry generation phase often results in significantly longer processing times compared to other stages, which in turn affects the overall efficiency of the fabric simulation process. However, through parallel optimization, the computational efficiency of the yarn geometry generation phase has been greatly improved. This has led to a more balanced time consumption across all simulation stages, providing more efficient computational support for fabric simulation.
Performance of parallel algorithms on different GPU hardware
To evaluate the performance of the parallel algorithms on different GPU hardware, four different GPUs were selected for testing. The tests were conducted on the various virtual woven fabrics shown in Figure 4. The results, which represent the sum of the execution times of Algorithms 2 and 4, are presented in Figure 6.
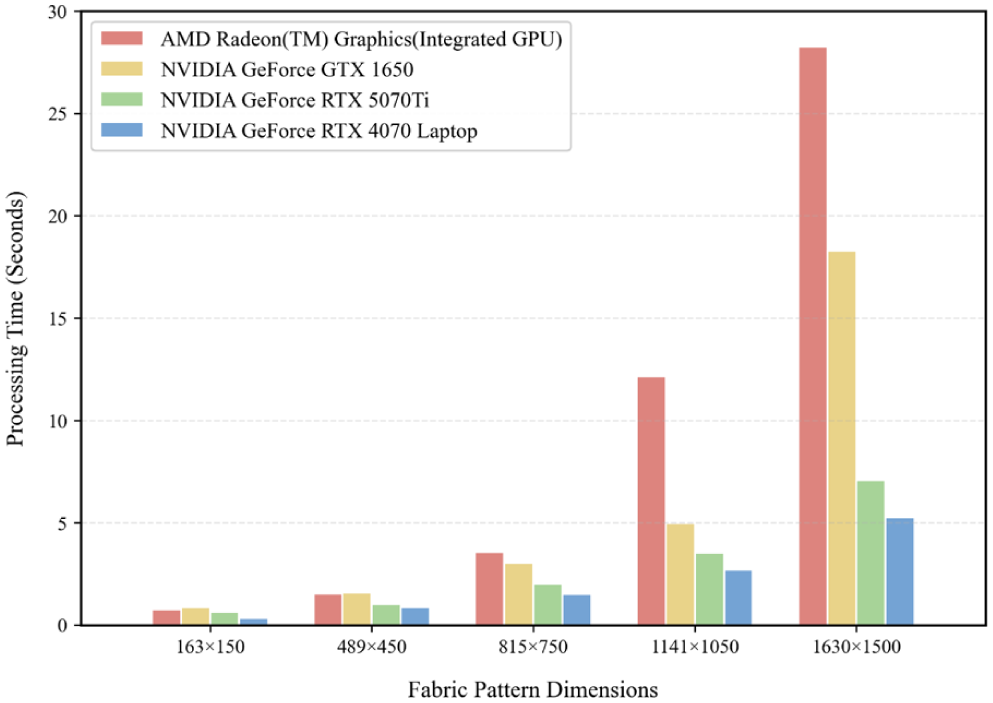
Performance comparison of different GPU.
As demonstrated in Figure 6, the parallel algorithm implemented via the OpenCL cross-platform framework can be efficiently executed across diverse GPU architectures. The computational advantages of parallelism are effectively leveraged on both AMD-based integrated graphics and NVIDIA-based discrete graphics, demonstrating broad applicability in heterogeneous computing environments. The observed performance differences across GPU architectures can be attributed to variations in hardware characteristics, including the number of processing cores, memory bandwidth, and overall parallel throughput. The proposed yarn-level parallel algorithms expose a large number of independent workloads across yarns. As a result, GPUs with higher core counts and greater memory bandwidth are able to benefit more significantly from this parallelism. In contrast, GPUs with fewer compute resources exhibit relatively smaller speed-ups, although acceleration over the CPU-based implementation is still consistently observed. These results indicate that the proposed framework scales with the available degree of GPU parallelism and is able to effectively exploit the underlying hardware capabilities.
For integrated GPUs, although computational capabilities are constrained compared to discrete graphics (particularly when processing large-scale datasets), significant acceleration is still achieved relative to serial CPU computation. Consequently, the proposed parallel algorithm exhibits robust hardware adaptability and is characterized as device-agnostic. This attribute enables widespread deployment across multiple hardware platforms, providing a feasible and efficient solution for 3D simulation technology in the textile domain.
Large-scale patterned fabric simulation
The proposed yarn-level parallel algorithm is focused on the yarn geometry generation phase, exhibiting pronounced scale dependency in acceleration efficiency. Specifically, performance gains are amplified with larger fabric structure dimensions. Consequently, the algorithm’s applicability remains independent of fabric types. To validate its universality, the parallel algorithm was applied to 3D structural simulations of both large-pattern woven fabrics and knitted fabrics. The resulting structural visualization is presented in Figure 7.

Rendering effects of large-scale patterned fabrics: (a) woven fabric simulation, (b) weft-knitted fabric simulation, and (c) warp-knitted fabric simulation.
In this figure, (a) depict woven fabric where the patterned weave segments (green) are structured as 3/1 warp-faced twill weaves, while the ground weave segments (white) feature 1/3 weft-faced twill weaves. The complete fabric is composed of 2880 warp yarns and 1840 weft yarns, generating a total of approximately 254.47 million triangular facets. (b) is weft-knitted single jacquard knitted fabric, knitted in knit stitches and float stitches, with the whole fabric consisting of 2880 yarns, resulting in a geometric complexity of 331.71 million facets. (c) shows a warp-knitted Jacquard knitted fabric, which is knitted by two guide bars. The base tissue of this fabric is a tricot stitch (JB1 (Jacquard guide bar): 1-0/1-2//; GB2: 1-2/13D-0//;), on which the Jacquard guide bar is offset to form a pattern effect (orange part), and the whole fabric consists of 2520 yarns, producing the largest mesh model with 381.71 million facets. When applied, the proposed parallel algorithm reduces the total execution time of complete 3D simulations to approximately 10 s, even for large-pattern woven and knitted fabrics with massive yarn counts. This demonstrates the algorithm’s broad applicability across diverse fabric types and confirms its significant efficiency advantages in processing complex patterned textiles.
Conclusion
In this work, a GPU-based yarn-level parallel computing framework is presented, significantly enhancing computational efficiency for 3D simulations of large-patterned fabric structures. The framework introduces a yarn-decoupled approach and achieves yarn-level parallelization through two key algorithms: the Spline Trajectory Parallel Construction Algorithm and the Mesh Parallel Generation Algorithm. This design eliminates serial dependencies across yarns and enables concurrent trajectory interpolation and mesh generation. Experimental results show that the framework achieves up to a tenfold speedup in yarn geometry generation, reducing the total simulation time to approximately 10 s. By effectively overcoming the computational bottlenecks of the serial workflow, it provides a robust and scalable solution for large-scale, high-precision fabric simulation.
The proposed framework has direct application value in virtual prototyping and woven or knitted structure analysis, supporting rapid evaluation of complex textile patterns and accelerating the design-to-manufacturing pipeline. The current formulation assumes that yarns can be processed independently, which is applicable to scenarios where geometric preprocessing is performed under low deformation and yarn–yarn mechanical interactions or collisions are negligible. Consequently, we explicitly frame the proposed method as a geometric acceleration framework. While it does not yet address yarn–yarn collisions or penetrations, it serves as a critical foundation for future integration with physical or contact-based models. Extending the framework to incorporate such physical coupling effects will be an important direction for future work to further enhance the realism of large-patterned fabric simulations.
Footnotes
Appendix
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This work was supported by the Postgraduate Research & Practice Innovation Program of Jiangsu Province (grant number KYCX25_2689); the Wuxi Science and Technology Development Fund Project (grant number K20241032); the Fundamental Research Funds for the Central Universities (grant number JUSRP202501003).
Data availability statement
The data that support the findings of this study are available from the corresponding author, upon reasonable request.