
Abstract
Fabric defect detection is a pivotal step in quality control in the textile manufacturing industry. Due to the diversity and complexity of defects, manual visual inspection and traditional fabric defect detection methods suffer from low efficiency and accuracy. To address the issues, a saliency model capable of mining local and global information from CNN and vision Transformer is proposed for fabric defect detection in this paper, named ACCTNet. Specifically, to enhance the feature interaction of different scales, an adjacent context coordination module composed of one local branch and two adjacent branches is proposed. Meanwhile, a contrast-aggregation module is proposed to highlight the defects from low contrast background using pooling and subtraction operations. In addition, vision Transformer is adopted to capture global contextual information with long-range dependencies, which can guide local information to further refines the defect detection results. Experimental results demonstrate that the proposed method can accurately inspect the defects from plain and patterned fabric surfaces, achieving Em values of 78.49% and 97.19% respectively, which significantly surpasses the existing state-of-the-art fabric defect detection methods.
Introduction
During the textile manufacturing process, it is inevitable to generate various kinds of defects such as warp breakage, stains, yarn removal, etc., caused by textile materials or machine malfunctions, and consequently resulting in the significant resource waste and economic losses. Early fabric defect detection generally relied on the manual visual inspection, which is always seriously affected by light intensity, fatigue and inspector’s experience, making it difficult to provide reliable and stable detection results.1,2 With the development of computer vision technology, automatic visual inspection approaches have become a promising solution for fabric defects detection. 3 The traditional automatic fabric defect detection methods can be broadly categorized into five main groups: statistical-based methods,4–7 structure-based methods,8,9 spectral-based methods,10–13 model-based methods,14–16 learning-based methods,17–22 and hybrid methods.23,24 Meanwhile, fabric defect detection methods can also be classified into supervised and unsupervised methods, according to whether training samples are required. These traditional methods can generally produce favorable defect detection results for some specific fabrics. However, they rely heavily on the hand-crafted low-level features and heuristic cues, such as color, texture, intensity, background prior and orientation, and fail to exploit high-level semantic information, thus lacking of adaptability and generalization for detecting defects.
Visual saliency can quickly localize the salient targets or regions by simulating the human visual system. 25 Although the texture of the fabric image is complex and the defect type is diversity, the defects are prominent in the complex texture background. Therefore, it is a promising solution to detect the fabric defect using visual saliency which is calculated by simulating human visual perception mechanism and combing the characteristics of the fabric image. For the past few years, with the breakthrough of deep learning in the field of computer vision, saliency object detection (SOD) model has gradually replaced from the traditional method in fabric defect detection and achieves significant performance improvement.26–30 Nonetheless, most of the existing SOD models are based only on convolutional neural network (CNN) that cannot explicitly learn global contextual information with long-range relationship, which plays a crucial role in object detection from the cluttered and complex backgrounds. Recently, visual Transformer 31 can model the long-distance dependencies using a self-attention mechanism in image classification task. However, only a few studies have applied Transformer to SOD, especially in fabric defect detection.
To address the above problem, this paper proposes a novel saliency model ACCTNet for fabric defect detection by integrating the advantages of CNN and visual Transformer in local spatial details and global contextual information respectively. Specifically, four contributions are shown as follows:
(1) An adjacent context coordination module is proposed, which utilizes the cross-attention fusion of a local branch and two adjacent branches to realize the mutual coordination of contextual information at different scales.
(2) A contrast-aggregation module is proposed to capture contrast information through pooling and subtraction operations.
(3) The global information is mined via vision Transformer and fused with the local features for accurate prediction of fabric defects.
(4) The proposed saliency model achieves 78.49% and 97.19% Em on the plain and patterned datasets, which are significantly better than other existing fabric defect detection algorithms.
Related work
Deep learning technology has led to the proposal of a variety of CNN-based computer vision methods. The gradual improvement in the performance of these methods has greatly contributed to the development of SOD. Among them, the most significant is visual saliency models based on fully convolutional network (FCN), 32 aiming at solving the semantic segmentation problems. They allow end-to-end spatial saliency representation learning and have the ability to preserve spatial information, thus allowing for effective saliency prediction during the feed-forward process. Therefore, a series of fabric defect detection algorithms have been devised utilizing the visual saliency of FCN.
Liu et al. 33 proposed a FCN-based saliency model with attention mechanism to achieve accurate segmentation of fabric defective regions. The model firstly extracts multi-level and multi-scale features using FCN to enhance the characterization of fabric texture. Then, the attention mechanism is integrated into the backbone network to assign different weights to different feature maps, further improving the effectiveness of feature extraction. Finally, the multi-level saliency maps are generated by de-convolution and fused through a series of short connection layers to better detect defective regions. Liu et al. 34 proposed a two-branch balanced saliency model based on FCN for automatic fabric defect inspection to enhance quality control in textile manufacturing. The model can address the scale variation and contextual information fusion issues through the two-branch network, thereby improving the performance of defect detection. Furthermore, Liu et al. 35 developed a novel saliency model for detecting fabric defects. This model is able to accurately identify defects even under low contrast, due to its multi-scale attention mechanism and two-way information interaction. Jing et al. 36 proposed an efficient Mobile-Unet model by introducing the depthwise separable convolution and addressed the data imbalance problem in the fabric defects dataset by introducing a median frequency loss function. Wang et al. 37 proposed an enhanced encoder-decoder network with hierarchical supervision for surface defect detection, which produce satisfactory region consistency and boundary localization of defects. Cui et al. 38 developed an autocorrelation-aware aggregation SOD network for identifying surface defects from background with clutter and low contrast. To obtain the fine edge prediction of defect regions, a semantics guided detection method is proposed in Sun et al., 39 which includes the guided atrous pyramid module and query context module that enables semantic features to be learned throughout the inference phase. However, the above CNN-based methods cannot fully utilize contextual semantic information and ignore the effective coordination between them, resulting in limited detection performance.
More recently, Transformer structure originally used in natural language processing has made great progress in image recognition. 31 It can utilize the self-attention mechanism to model the long-term dependency of images explicitly, thus significantly improving the recognition ability. To overcome the issue of lacking global semantic information in CNNs, some efforts have begun to introduce Transformer into defect detection. Shang et al. 40 replaced Transformer with convolution in the encoder module to learn long-range dependencies and constructed a dynamic graph to implicitly encode position information. Wang et al. 41 explored the advantages of Transformer and CNN for defect detection and proposed a simplified yet effective hybrid model DefT to accurately identify defective regions. However, there is still limited research on high-precision and high-efficiency detection methods specifically designed for fabric surface defects.
Methodology
In this paper, we propose a saliency model based on adjacent context coordination and Transformer, named ACCTNet, for fabric defect detection. The network architecture is illustrated in Figure 1, which consists of three main parts: encoder network, adjacent context coordination module, and contrast-aggregation module. The encoder network is used for multi-scale feature extraction. The adjacent context coordination module is to realize the coordinated fusion of features from adjacent levels with each other. The contrast-aggregation module is adopted to capture the difference between each feature and the local neighborhood; meanwhile, its output is fused with contextual semantic information learned from vision Transformer to enhance feature representation. Finally, all side outputs are supervised by a loss function to guide the model to generate more accurate defect prediction maps.

Saliency model based on adjacent context coordination and Transformer.
The encoder network
The basic encoder network of our model is VGG16 without the last pooling layer and three fully connected layers, which is shown in Figure 2. More concretely, the encoder network consists of five convolutional blocks, denoted as

The encoder network.
Adjacent context coordination module
The high-level features from deeper convolutional layers provide abundant semantic information, while the low-level features from shallower convolutional layers offer detailed information. Therefore, the interactions between features at adjacent levels is able to capture complementary information across different levels, facilitating the determination of defect regions and refinement of defect details. To accomplish this, the adjacent context coordination module is proposed in this paper, which can coordinate the cross-scale features of previous, current and subsequent blocks in the encoder network. Generally, the adjacent context coordination module consists of three branches, namely, the local branch located in the middle and the two adjacent branches on the both sides (as illustrated by A2, A3, and A4 in Figure 1). In particular, A1 and A5 contain only two branches: a local branch and an adjacent branch. Concretely the processing of adjacent context coordination module can be defined as F (∙), and its output feature can be formulated as follows:

where
Local branch: The local branch is used to operate on the current feature

Then, we further refine

where
Adjacent branches: There are two types of adjacent branch: previous-to-current branch and subsequent-to-current branch. The output of the former


where
Branch fusion: After effective feature coordination as described above, the output features of multi branches are fused with the input

where ⊕ is an element-wise summation operation. As a result, a large amount of valuable contextual information is used for the detection of defective regions.
Contrast-aggregation module
In fabric images, defects often exhibit low contrast with the background texture, making it difficult to generate accurate boundary localization of defects. To overcome this problem, the contrast-aggregation module is proposed in our model, which can capture sufficient contrast information. Inspired by Achanta et al.,
45
the contrast feature

where
Then, to further incorporate global contextual information into fabric defect detection, the last four side outputs of the encoder network


where
Finally, the feature

where
Experimental results and analysis
Experimental configuration
Datasets
A series of experiments and evaluations of the model are carried out on the plain and patterned datasets, and some examples of the dataset are shown in Figure 3. The plain fabric dataset comprises 2200 images for training and 500 images for testing, encompassing five primary types of defects: indentations, creases, detachments, stains, and holes. This dataset includes numerous elongated defects and tiny defects with low contrast. The pattern fabric dataset contains 5948 images for training and 500 images for testing with more complex background textures and irregular defects. It contains six main types of defects: stripped yarns, broken yarns, yarns, cotton balls, holes, and stains.

Sample fabric image dataset (the first two rows are plain fabric and the last two rows are pattern fabric).
Evaluation indicators
The proposed fabric defect detection model is evaluated in terms of six commonly adopted metrics, that is, Precision-Recall (PR) curve, F-measure curve, Maximum F-measure (Fβ), Mean Absolute Error (MAE), S-measure (
Precision-recall (PR) is calculated based on the binarized saliency map and the ground truth map. Precision represents the proportion of defect pixels correctly identified among the predicted saliency map, and recall represents the proportion of predicted pixels that are correctly identified in the ground truth map, as represented below:


where TP, FP, and FN denote the true positive, false positive, and false negative pixels, respectively. A set of thresholds from 0 to 255 is applied, each of which produces a pair of Precision-Recall values to form the PR curve for performance comparison.
The weighted harmonics of Precision and Recall is to compute Fβ for evaluating the overall performance. The maximum Fβ is noted as the top value in the F-measure curve. And the larger the area under the F-measure curve, the better the performance. Fβ is defined as:

where
The MAE 46 score is calculated as the average absolute difference between the predicted saliency map S and its ground truth G. The lower the MAE score, the better the performance. MAE score is computed as:

where H and W denote the height and width of G respectively, and
The S-metric (

where
The E-measure (

where
Implementation details
The proposed saliency model for fabric defect detection is implemented with PyTorch on NVIDIA V100 GPUs. During the training and testing phases, the input fabric images are resized to
Comparative results with state-of-the-art methods
We compare the model proposed in this paper with 12 current state-of-the-art saliency object detection methods on two fabric datasets in terms of both qualitative and quantitative results.
Quantitative Analysis: From Table 1, it can be observed that all the evaluation metrics scores of our method ACCTNet are the highest except for the MAE and
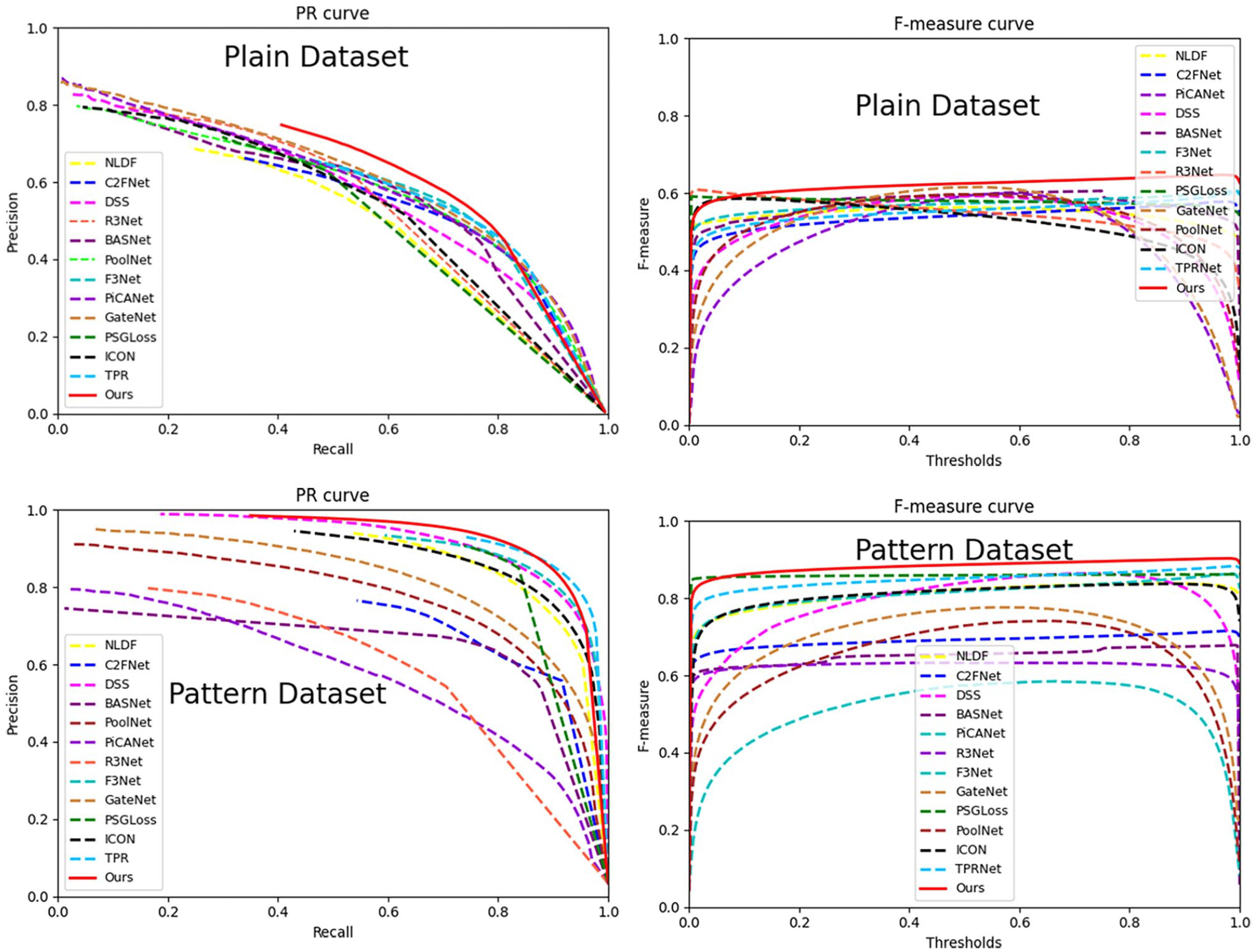
Comparison of PR curves and F-measure curves.
Quantitative comparison of different methods.

The bold entries mean the best performance.
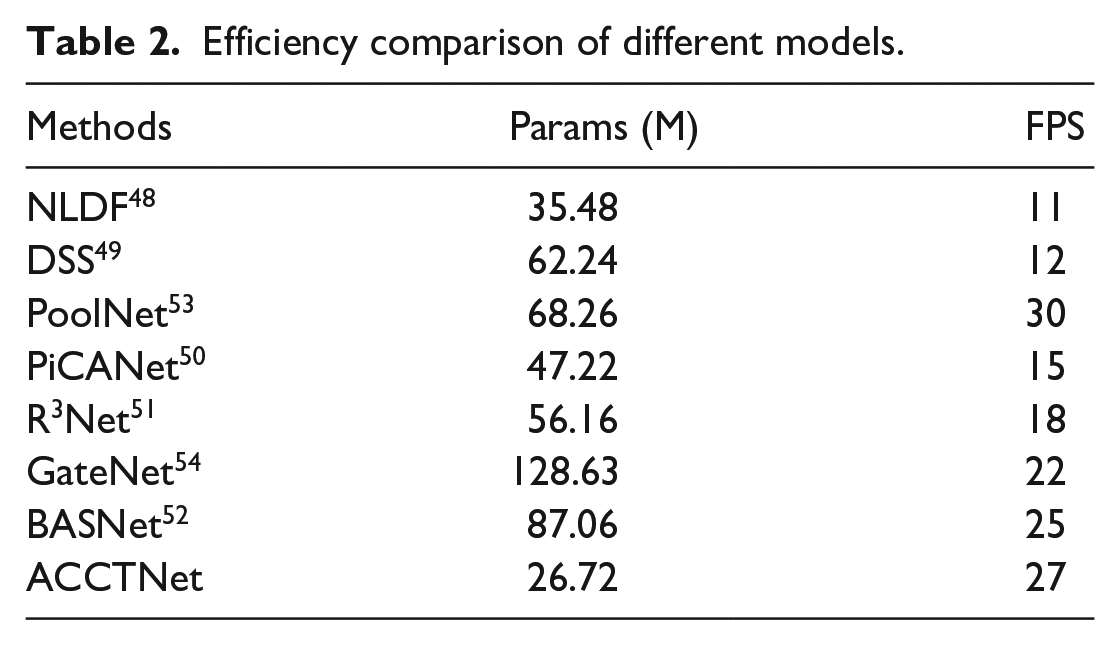
We also compare the number of parameters and running speed of each model in Table 2. From Table 2, we can see that compared to other methods, our method ACCTNet has the lowest number of parameters 26.72 M while ensuring faster running speed 27 FPS, which proves the high efficiency of our method.
Efficiency comparison of different models.
Qualitative analysis: To better visualize the validity of our method, the partial saliency maps generated by the different methods are shown in Figure 5. Various scenarios such as tiny defects, line faults, dot defects, slightly larger defects, irregular defects, and defects with low contrast to the background on different fabric textures are included. It can be seen that our method performs well in detecting dot defects with more complete region segmentation results and clear contours compared to most models. The line defects are also inspected with clear and noise-free contours. In the case of large defects, the detection maps are more accurate and closer to the ground truth maps. Meanwhile, for the irregular defects and defects with low contrast, our method is able to locate them more accurately and segment them more integrally. For example, as shown in the seventh row of Figure 5, the comparison methods are unable to detect the defective regions accurately. BASNet has the worst performance with a high false detection rate, and the contours of other methods appear blurred and rough. Our method can generate defective regions with high region consistency and clear boundary localization on different fabric textures.

Visual comparison of different methods.
Ablation experiments
In this section, we perform a series of ablation studies on the plain fabric dataset to investigate the effectiveness of the three main components proposed in our approach. We first perform an ablation study of the encoder network by replacing the VGG16 with ResNet50, and Res2Net, 60 and the results using different encoder networks are shown in Table 3. It can be seen that the model achieves the best performance when using VGG16 as the encoder network. Moreover, the results with different encoder networks show little variation, indicating the proposed method is highly robust.
Comparison results of different encoder networks.

The bold entries mean the best performance.
The specific comparison results using different components of our method are reported in Figure 4 and Table 4. From Table 4, we can observe that the method with only the adjacent context coordination module is much better than the other two modules alone, which shows the effectiveness of the adjacent context coordination module. In addition, the network with only the Transformer blocks perform the worst, indicating that relying solely on global information without local texture information is insufficient for achieving satisfactory performance. The networks with other two components outperform the network with Transformer blocks, which suggests the importance of local texture information over global contextual information. And since the network with three components can make an efficient combination of both local and global features, its performance is significantly better than in scenarios where only one type of feature is considered, which proves the necessity of three components we designed. In brief, both local texture information and global contextual information play equally important roles in enhancing the model performance.
Comparison results with the different components.

A denotes the adjacent context coordination module, B denotes the contrast-aggregation module, and C denotes the Transformer block.
To demonstrate the effectiveness of each component more intuitively, Figure 6 shows the different output feature maps in the proposed method. From Figure 6, it is evident that the adjacent contextual coordination module is able to capture more discriminative features, enabling increased attention to the defective regions, thereby making defects more salient. Following the contrast-aggregation module, the feature map has less background texture interference, facilitating a more distinct visual representation. Additionally, under the global guidance of Transformer blocks, the output feature map of the last layer is highlighted more obviously, leading to a clearer and brighter representation of defects. The final prediction map confirms that the proposed method can generate precise fabric defect detection results.

Visual comparison of different output feature maps in the proposed method. (a) Fabric image, (b) ground truth; the output maps of (c) encoder, (d) adjacent context coordination module, (e) contrast-aggregation module, (f) the last layer of model, and (g) prediction map.
We also investigate the effect of the number of Transformer blocks on the defect detection performance and conduct a series of experiments by setting the number of Transformer blocks to
Performance comparison of different numbers of Transformer blocks.
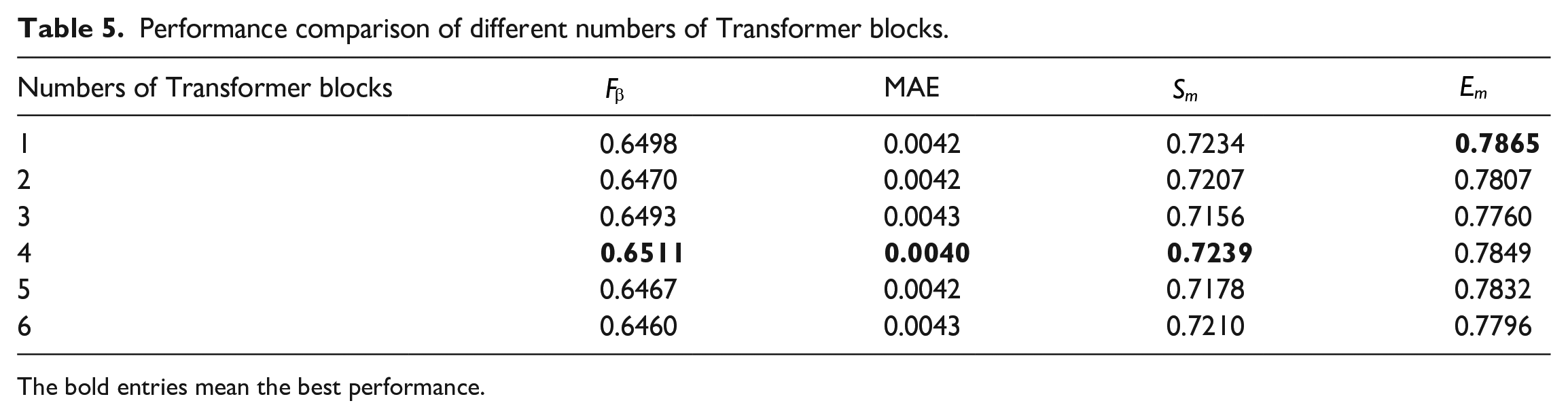
The bold entries mean the best performance.
To show the effectiveness of the adopted deep supervision strategy, we compare two supervision learning strategies: multi-level supervision strategy and single-level supervision strategy, and the comparison results are reported in Table 6. We can observe that the multi-level supervision strategy can achieve the best performance, with a 6.98% decrease in MAE and the 1.89%, 0.21%, 0.78% increase in
Performance comparison of different supervision learning strategies.

The bold entries mean the best performance.

Visual comparison of different supervision learning strategies. (a) Fabric image; (b) ground truth; (c–g) feature maps of the five side outputs; (h) prediction map.
Conclusion and future work
In this paper, we propose a saliency model based on adjacent context coordination and Transformer for high precision and high efficiency fabric defect detection. First, an adjacent context coordination module is adopted to coordinate the adjacent features effectively, thereby enhancing the interaction of features at different scales. Then, a contrast-aggregation module is proposed to explore the discriminative information to highlight salient defective regions from the background with low contrast. Finally, vision Transformer is used to capture long-range relationships with global contextual semantic knowledge, which is able to guide the model to focus more on defective regions. Extensive experiments on the plain and patterned fabric defect datasets demonstrate that our method can generate the complete defective regions with well-defined boundaries, outperforming the existing saliency detection methods. Meanwhile, the model parameter is only 26.72 M and the detection efficiency is at 27 fps on a single GPU.
As a supervised fabric defect detection method, our ACCTNet requires a large number of labeled defective samples for model training, which limits its applicability in textile industrial scenario where defective samples are scarce. Therefore, to reduce reliance on defective fabric images with pixel-level annotations, we will explore semi-supervised fabric detection methods based on the theory of graph signal processing61–63 in the future.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by NSFC (No. 62072489, No.61873293), leading talents of science and technology in the Central Plain of China (234200510009), Henan province key science and technology research projects (222102210008, 232102211002, 232102211030).