
Abstract
Due to the complexity of fabric texture, the diversity of defect types and the high real-time requirements of textile enterprises, fabric defect detection is faced with considerable challenges. At present, fabric defect detection algorithms based on deep learning have achieved good results, but there are still some key problems to be solved. Firstly, due to the complex construction of deep learning models and high network complexity, it is difficult to meet the real-time requirements of industrial sites, which limits its application in industrial sites. Secondly, in the face of textile enterprises’ requirements for detection accuracy, how to achieve fabric defect detection through a simpler network model, so as to better balance the accuracy and complexity of deep learning models is a major challenge for textile enterprises and academic researchers. In order to solve these problems, a fabric defect detection method based on lightweight network is proposed in this paper. This method takes lightweight network YOLOv5s model as the infrastructure, integrates Convolution Block Attention Module and Feature Enhancement Module in Backbone part and Neck part respectively, and modifies the loss function of YOLOv5s to CIoU_Loss. Compared with the original YOLOv5s, it makes up for the lack of information extraction ability of the network, improves the speed of model inference and the speed and accuracy of prediction box regression. It provides technical support for the application of lightweight network model in industrial field. The performance of the model is tested by using raw fabric and patterned fabric data sets on the deep learning workstation platform. The experimental results show that when the IoU threshold is 0.5, the mean Accuracy Precision mAP of raw fabric and pattern fabric is 86.4% and 75.8%, respectively, which increases by 7.6% and 1.7% compared with the original YOLOv5s algorithm. The average detection speed is as high as 102 FPS, which can meet the real-time requirement of industrial field target detection.
Introduction
Textile industry as a traditional people’s livelihood industry in our country, occupies a large proportion in the national economy. According to the statistics of China National Textile Association in 2021, China’s output of fiber products accounts for more than 55% of the world, textile exports account for more than 37% of the world, and textile GDP accounts for about 10% of the country. In the foreseeable future, China will still become the world’s largest textile production capacity, the highest output of the country. Intelligent detection and control in textile processing is an important relying on the textile industry getting bigger and stronger in our country. How to make our textile enterprises more competitive, among which ensuring textile quality is undoubtedly very important.1 –3 As a raw material for clothing, decoration, medical, industrial, aerospace and military products, fabric is an indispensable raw material in daily life and industrial production. In the process of textile production, the existence of defects plays a decisive role in the quality and price of textile terminal products. At present, most domestic textile enterprises still use manual visual inspection to evaluate the quality of fabric. Due to the limitation of workers’ physiological characteristics, the speed, accuracy and consistency of test results provided by traditional manual cloth inspection cannot meet the needs of modern mass production. At present, fabric defect detection is considered to be the largest and essential operation link in the process of textile industry production. In order to improve the level of textile quality management, reduce the burden of fabric inspection workers and reduce the cost of enterprises, more and more textile enterprises begin to pay attention to the automatic detection of fabric defects. However, the diversity of fabric types and defect types brings great challenges to fabric defect detection. With the rapid development of artificial intelligence, machine vision and pattern recognition4 –6 have been widely used in the field of industrial surface defect detection. They provide efficient, low-cost and high accuracy automatic detection methods, and the detection scope covers a wider range of fabric types. This technology can not only provide a good guarantee for the objective, stable and efficient fabric defect detection, but also conform to the development trend of automation and intelligence in the textile industry.
In recent years, traditional machine learning detection methods have been widely used in the field of fabric defect detection. With the development of deep learning technology, more and more methods attempt to combine neural network technology to realize fabric defect detection. According to whether or not neural network is involved in the model construction stage, the existing fabric defect detection methods are divided into two categories: the traditional method and the deep learning method. 7
The traditional fabric defect detection method is to use visual equipment to obtain industrial images on site and determine whether there are defects by extracting image features.8 –10 By extracting the texture features of the defect-free fabric samples as templates, defects are detected in the detection stage according to the similarity between the image to be detected and the learning template.
Local Binary Patterns (LBP) were first proposed by Ojala et al., 11 and it were initially used for fabric texture classification. LBP algorithm takes the gray value of the center pixel of a sliding window as the threshold to calculate the neighboring pixels around the center pixel, so as to achieve the function of describing the local texture features of the fabric. In addition, when LBP is used to extract fabric local features, it has high computational efficiency. Zhou et al. 12 proposed a fabric defect detection method based on Gabor filtering, and optimized it with the help of genetic algorithm. The optimized parameters were used to obtain the feature map of the image to be tested, and the threshold segmentation was carried out to obtain the defect detection results. Bu et al. 13 proposed a fabric texture analysis method based on time series spectral analysis. They used autoregressive spectral estimation model to conduct one-dimensional power spectral density analysis on fabric images, and extracted features that can effectively distinguish normal texture from defects. The experiments of defect detection on multiple fabric data sets with different texture backgrounds show that this method has low computational complexity and can obtain low false positive rate and false negative rate. Zhan et al. 14 put forward a new learning model, which can be used to distinguish shared dictionaries, so as to extract a group of class-specific features. This method can effectively extract the distinguishing features and shared features of multiple types of fabric textures simultaneously. Kang and Zhang 15 proposed a fabric defect detection method based on sparse dictionary learning. This method can excellently detect the defects of fabric with small period textures, but it is not accurate enough to detect the defects of fabric with large period textures.
In the industrial environment, due to the variety of fabric defects and the uncertainties of the shape, size and type of defects, it is difficult for traditional machine learning algorithms to complete the modeling and migration of defect features, and the reusability is not great, which will waste a lot of labor and material costs. Compared with traditional methods, deep learning method does not require manual feature design, and the methods of feature extraction and positioning provide a better choice than the traditional detection methods of predetermined programs, because they are more robust to changes. 16 So the algorithm has higher accuracy and faster detection speed, and has been widely used in the detection of industrial fabric defects.
Hu et al. 17 proposed an unsupervised fabric defect detection method, which expanded the standard DCGAN (Deep Convolution Generates Adversarial Networks) by introducing a new encoder component. With the aid of the encoder, A given query image is reconstructed, subtracting the reconstructed image from the original image to create a residual map to highlight potential defect areas. Experimental results show that this method has good detection effect. Li et al. 18 proposed a convolutional neural network model to detect fabric defects. The proposed model adopted multi-micro-architecture and multi-layer perceptron optimization network. The experimental results show that the proposed model can achieve better detection accuracy under the condition of small scale. Considering that convolutional neural networks cannot properly handle small sample problems in classification tasks, Wei et al. 19 used the compressed sampling theorem to compress and expand small sample data, and then used convolutional neural networks to directly classify the features of compressed data. Experiments show that this method can effectively improve the classification accuracy of defect samples when the number of defect samples is small. Zhou and Qiu 20 proposed an SSD enhancement method based on interactive multi-scale attention features, which used the attention mechanism to generate multi-scale attention features and added them into the original detection branch of the SSD method, effectively enhancing the feature representation ability and improving the detection accuracy. Meanwhile, each branch in the detection process is a parallel structure, ensuring the detection efficiency. Li et al. 21 proposed a surface defect detection method based on Mobilenet-SSD. On the premise of not sacrificing the detection accuracy, MobileNet optimized the Backbone structure of SSD, adjusted the network structure and parameters, and simplified the detection model. This method can detect surface defects more accurately and quickly than traditional lightweight network and machine learning methods.
To sum up, the defect detection method based on machine learning has been widely used in many scenarios in the industrial field. However, due to the wide variety of fabrics and various defect types, in-depth research on how to balance the accuracy and complexity of the deep learning model is the focus of the application and promotion of fabric defect detection technology.
In view of this, a fabric defect detection method based on lightweight network is proposed in this paper. The main contributions of this algorithm are as follows:
(1) Based on the lightweight network YOLOv5s, the Convolutional Block Attention Module and Feature Enhancement Module are integrated to improve the network information extraction ability, improve the detection rate of the model without increasing the network complexity, and better balance the accuracy and complexity of the model.
(2) The loss function of YOLOv5s was modified to CIoU_Loss to improve the speed and accuracy of the regression of the prediction box.
Related works
In recent years, object detection algorithms have developed to a great extent. Such algorithms mainly include two categories: two-stage algorithm 22 and one-stage algorithm.23,24 The two-stage algorithm divides the target detection problem into two stages. Firstly, the potential candidate areas are extracted by CNN and other methods, and then each candidate box is screened by classifier. After screening, the post-processing is carried out. This process is very complicated and interdependent, each step needs to be trained separately, and if any step goes wrong, the whole process will be ruined. As the two-stage algorithm belongs to fine training, it has high accuracy, but its detection model is slow and difficult to train, which is difficult to meet the real-time detection of industrial production. The first-stage algorithm uses a CNN network to directly generate the category probability and position coordinate value of the object, and the final detection result can be obtained directly after a single detection, namely the end-to-end detection network. Although the accuracy is low, the speed is fast. As industrial production requires higher real-time performance, it is difficult for many two-stage algorithms with complex detection processes and long time consuming to meet the requirements. Instead, a one-stage end-to-end lightweight network model is used. In terms of target detection, classic lightweight network models such as YOLO,25,26 MobileNet,27,28 and EfficientNet29,30 are widely applied to industrial target detection. In 2016, Redmon et al. 31 proposed YOLO (You Only Look Once) algorithm. The core idea of this algorithm is to use the whole image as the input of the network and directly regression the position and category of the preselection box at the input layer. MobileNet algorithm 32 is a deep learning acceleration model proposed by Google team in 2017, which transforms the traditional convolution structure into a two-layer convolution structure network. This new structure can greatly reduce the calculation time and the number of parameters without affecting the accuracy rate. The further EfficientNet algorithm 33 was proposed in 2019, offering more general ideas for the optimization of the current classification network, improving the index by optimizing the network width, depth, and resolution of input images, greatly reducing the number of model parameters and the amount of computation. Because of the smaller number of parameters and higher detection speed, YOLO algorithm is more widely favored by the industry.
Liu et al. 34 proposed a CNN architecture YOLO-LFD with high computational efficiency. This architecture adopted multi-scale feature extraction method to improve the detection ability of the model on objects of different sizes, and adopted K-means clustering method to find the optimal size anchor frame on the fabric defect sample data set. The experimental results show that this method can improve the accuracy of fabric defect detection, greatly reduce the model parameters, improve the detection speed, and realize the real-time detection of fabric defects on embedded devices. Zhang et al. 35 proposed an automatic localization and classification method for color fabric defects based on YOLOv2, which reduced the cost of manual extraction of color fabric defect image features. Experiments showed that this method could effectively detect color fabric defects. Zhou et al. 36 proposed a real-time detection method for fabric defects based on the S-YOLOV3 model. K-means clustering algorithm was used to determine the target prior box, weight parameters were obtained by pre-training the YOLOV3 model, and the S-YOLOV3 model was obtained by pruning the convolution kernel according to the threshold value. Experiments show that the proposed model can accurately detect fabrics with different complex textures. Jing et al. 37 proposed a real-time detection method for fabric defects based on YOLOv3, and combined fabric defect size and K-means algorithm to conduct dimensional clustering for target frames. At the same time, low-level features and high-level information were combined, and YOLO detection layers were added to feature maps of different sizes. So that it can be better applied in fabric defect detection. Experimental results show that compared with YOLOv3, this method can detect and label fabric defects more effectively, and effectively reduce the false detection rate. Sujee et al. 38 trained by the YOLOv2 model and the YOLOv3-tiny model respectively on the ImageNet data set and obtained the convolution weight, which was applied to the fabric data set composed of six types of defects, and analyzed the influence of the two models on the fabric defect detection results. Kou et al. 39 designed an end-to-end defect detection model based on YOLOv3 to detect strip surface defects. Firstly, an ideal feature size was selected for model training, and then specific dense convolution blocks were introduced into the model to extract rich feature information and effectively enhance the characterization ability of the network. The experimental results show that the improved model has higher performance. Yue et al. 40 proposed an improved YOLOv4 target detection algorithm. K-means algorithm was used to cluster the truth frame of the data set, and anchor points suitable for fabric defect detection were obtained. Added a new prediction layer to YOLO_Head for better detection of tiny targets. Convolution Block Attention Module (CBAM) is integrated into the trunk feature extraction network, and CIoU loss function is replaced by CEIoU loss function to achieve accurate classification and location of defects. Experiments show that the improved YOLOv4 algorithm has improved the detection accuracy of small targets. Dlamini et al. 41 introduced a real-time machine vision system, which was composed of image acquisition hardware and image processing software. Firstly, data enhancement was used to generalize the data and enhance its robustness, then defects in the image were marked, and finally YOLOv4 was used for positioning. The system uses the weight of the pre-training model for training. The system can realize real-time automatic location of functional fabric defects and has high reliability. Zheng et al. 42 proposed a fabric defect detection algorithm by adding SE module to the Backbone of YOLOv5 and replacing the traditional ReLU activation function with ACON activation function in YOLOv5. Experiments show that compared with YOLOv5, the proposed SE-YOLOv5 model has improved accuracy and robustness. Wang et al. 43 proposed a fabric surface defect detection method based on the improved YOLOv5. In the algorithm, Convolution Attention Module was added on the basis of the YOLOv5 backbone network, which enhanced the extraction of important information in the feature graph by the object detection network and weakened irrelevant features. An adaptive spatial feature fusion method is introduced to solve the conflict problem caused by inconsistent feature scales in the feature fusion stage. Transfer learning is used to speed up training during training. Experiments show that compared with the original YOLOv5 algorithm, the proposed detection framework can effectively improve the network accuracy and meet the actual industrial requirements.
This paper presents a fabric defect detection method based on lightweight network. Firstly, this method takes lightweight network YOLOv5s model as the basic architecture. In order to improve network information extraction ability and inference speed, Convolutional Block Attention Module and Feature Enhancement Module are integrated into the Backbone part and Neck part respectively. Secondly, in order to improve the speed and accuracy of the regression of the prediction box, the loss function of YOLOv5s was modified to CIoU_Loss. Finally, the performance of the model is tested using fabric database on deep learning workstation platform.
Proposed algorithm
Improved YOLOv5s model
YOLO algorithm directly takes the whole picture as the input, and makes a forward inference through the neural network to output the coordinates and categories of the bounding box. Because all processes are integrated into one neural network, it can be optimized end-to-end. The end-to-end neural network model has a particularly good performance. It does not need to rely on the running process before and after, nor does it need to rely on the cooperation of various processes to directly output the running results. Unlike multi-stage or two-stage, the whole network will be invalid if a problem occurs in one process.
YOLOv5 is the latest version of the current YOLO series architecture, and its superior flexibility and speed make it perfectly suited for the task of real-time detection of objects in the field. The YOLOv5s is the smallest of the four series of YOLOv5, so it is more suitable for real-time inspection tasks in industrial field.
In this paper, the network structure of YOLOv5s is improved on the basis of the original YOLOv5s, so as to better improve the network performance and meet the requirements of industrial real-time detection. In order to improve the ability of object recognition and carry out effective tradeoff between recognition speed and accuracy, the Convolutional Block Attention Module (CBAM) 44 and Feature Enhance Module (FEM) 45 are integrated into the original YOLOv5s network structure, and the loss function of YOLOv5s is modified to CIoU_Loss. The system network structure is shown in Figure 1. In the image of defective fabric, there may be some defects such as holes, which account for a small proportion, some relatively long defects such as broken warp or broken weft, and some defects such as oil stains, which account for a large proportion. In order to comprehensively consider the types of defects and the defect area in the proportion of the defect area of the larger span, the sample size of defect image input in this algorithm is 640 × 640 × 3.
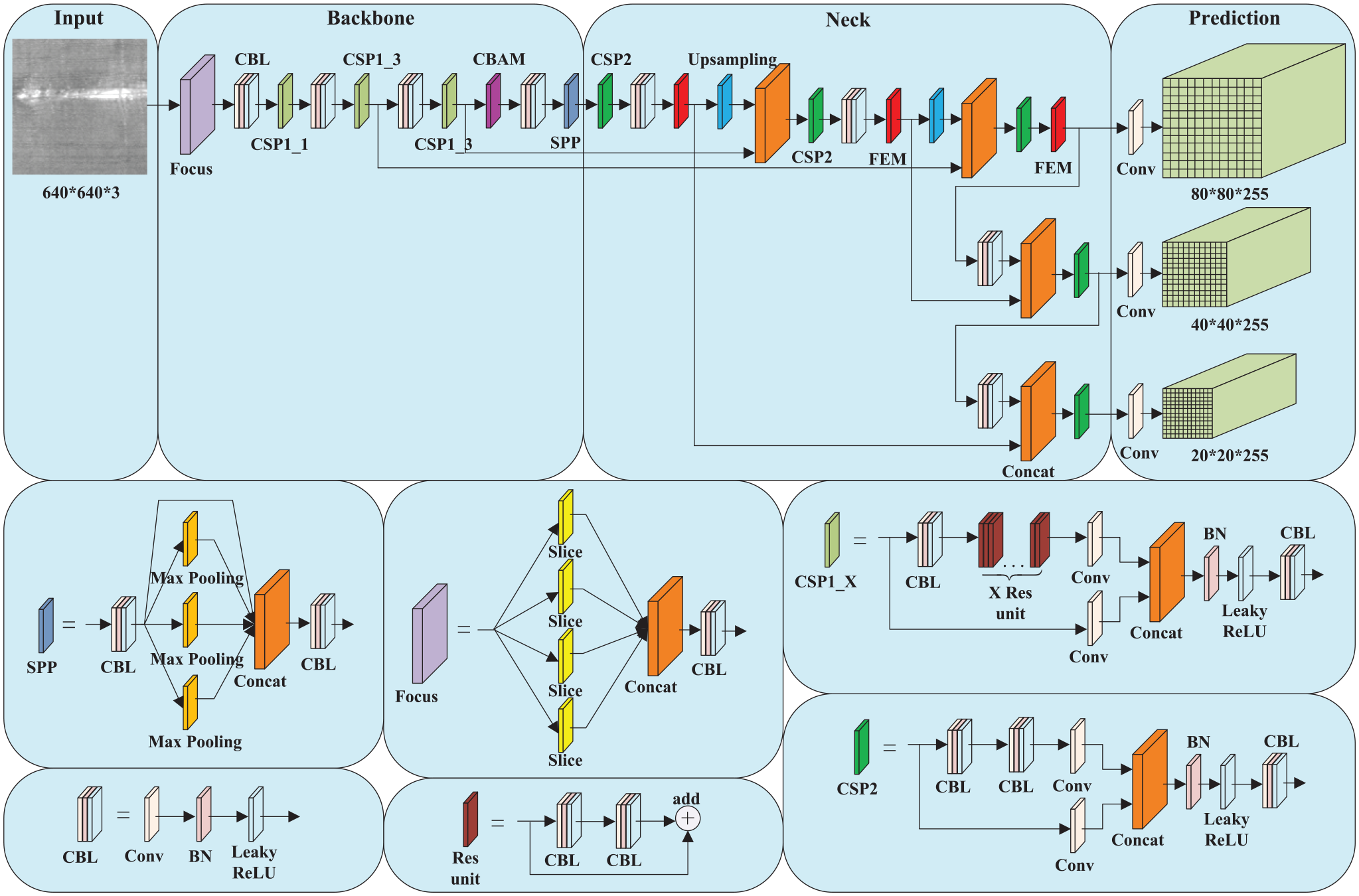
The network structure diagram of the system.
FEM-FPN-PAN module
The Neck part of traditional YOLOv5s is composed of a combination of Feature Pyramid Network (FPN) and PANet network. FPN conveys strong semantic features from the top down, while PAN conveys strongly defined features from the bottom up. The two are combined to carry out feature aggregation from different backbone layers. It is then propagated to the three feature graphs in the output layer. Based on the Neck of the traditional YOLOv5s architecture, the Feature Enhancement Module is added in this paper to enhance the representation of the feature pyramid and improve the reasoning speed of the network. The structure diagram of FPN after adding FEM module is shown in Figure 2.
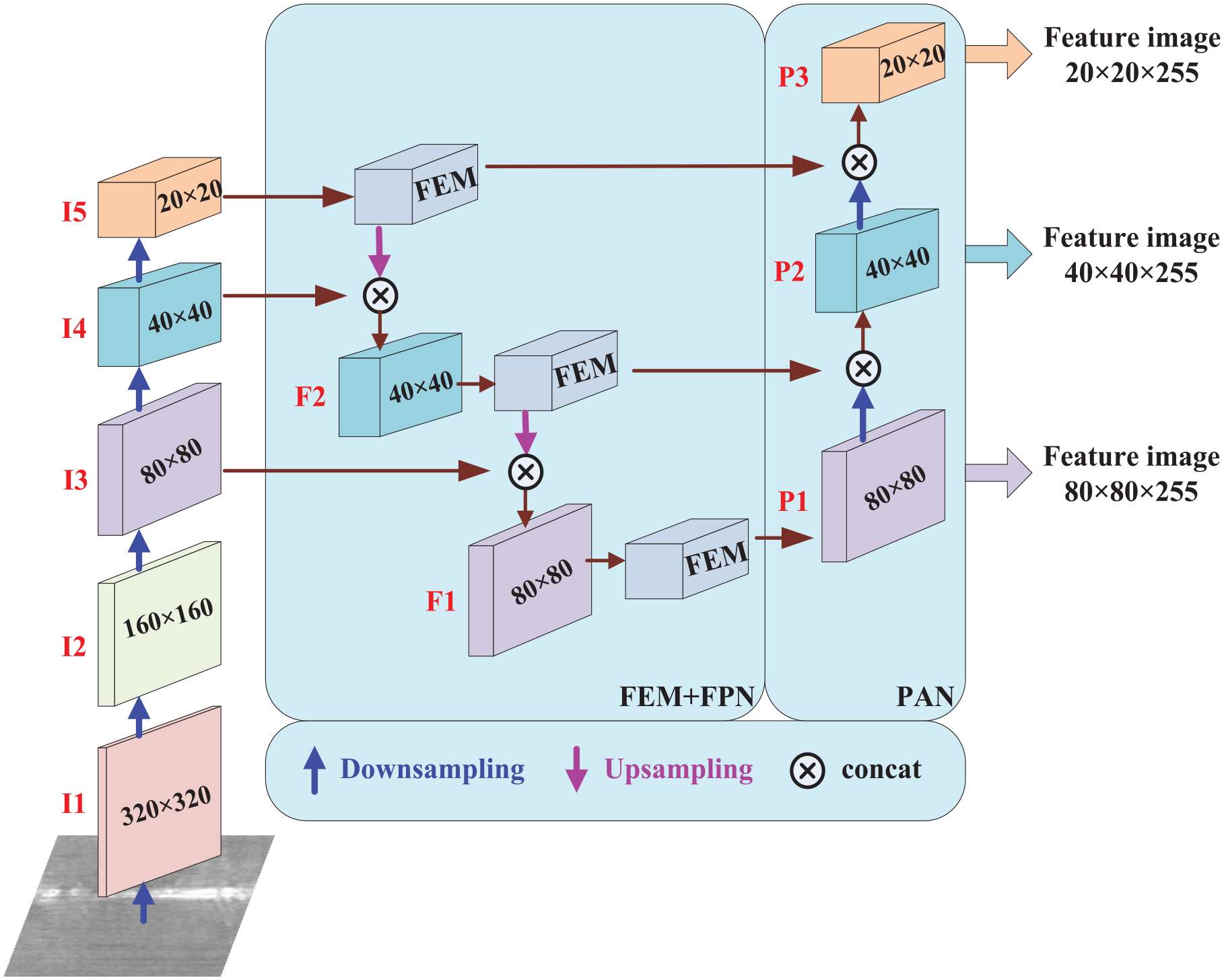
The structure diagram of FEM + FPN + PAN.
After multiple convolution operations, the input image generates the features of I1, I2, I3, I4, and I5, whose sizes are 320 × 320, 160 × 160, 80 × 80, 40 × 40, 20 × 20, respectively. After feature enhancement by FEM module, feature fusion is carried out with lower-level features through concatenation operation. From bottom to top, lower-level features are fused by expanding receptive field.
Convolutional block attention module
Convolution block Attention Module CBAM is to conduct series reasoning between Channel Attention Module (CAM) and Spatial Attention Module (SAM) along two independent dimensions of channel and space. At the same time, global average pooling and maximum pooling are used to obtain the attention map, and the attention map is multiplied by the input feature map for adaptive feature refinement. CBAM module makes up for the lack of information extraction ability of network and reduces the loss of context information in high-level feature map. The structure diagram of CBAM is shown in Figure 3.

The structure diagram of CBAM.
Assume that the input image is mapped to after convolution, F is used as the input of CBAM, and its corresponding weight coefficient Wc is obtained after CAM. Multiply the weight coefficient Wc and F to get the new feature Fc, and send it into SAM to get its corresponding weight coefficient Ws, and multiply the weight coefficient Ws and Fc to get the new feature Fs. The formula can be expressed as:


Where, ⊗ represents multiplying each attention weight coefficient by the corresponding feature map element by element.
The Channel Attention Module is shown in Figure 4. CAM is the compression of global maximum pooling and average pooling on the spatial dimension of the input feature map to generate two different spatial 1 × 1 × C feature descriptions, respectively. The feature descriptions obtained through two pooling operations are sent to a shared network, and the two feature descriptions are summed element by element, and then the weight coefficient Wc of channel attention is obtained by Sigmoid activation function. In the case of a single feature map, CAM focuses on what is useful information on the map.

The structure diagram of Channel Attention Module.
The Spatial Attention Module is shown in Figure 5. The output feature of CAM was taken as the input feature map of SAM, and the global maximum pooling and average pooling based on channel dimension was performed on the feature map to generate two W × H × 1 channel descriptions respectively. The two channel descriptions were concatenated according to concatenation operation, and then after a 7 × 7 convolution operation, the weight coefficient Ws of SAM was obtained by Sigmoid activation function. SAM uses the spatial relationship between features to generate spatial attention mapping, which focuses more on location information and is complementary to CAM.
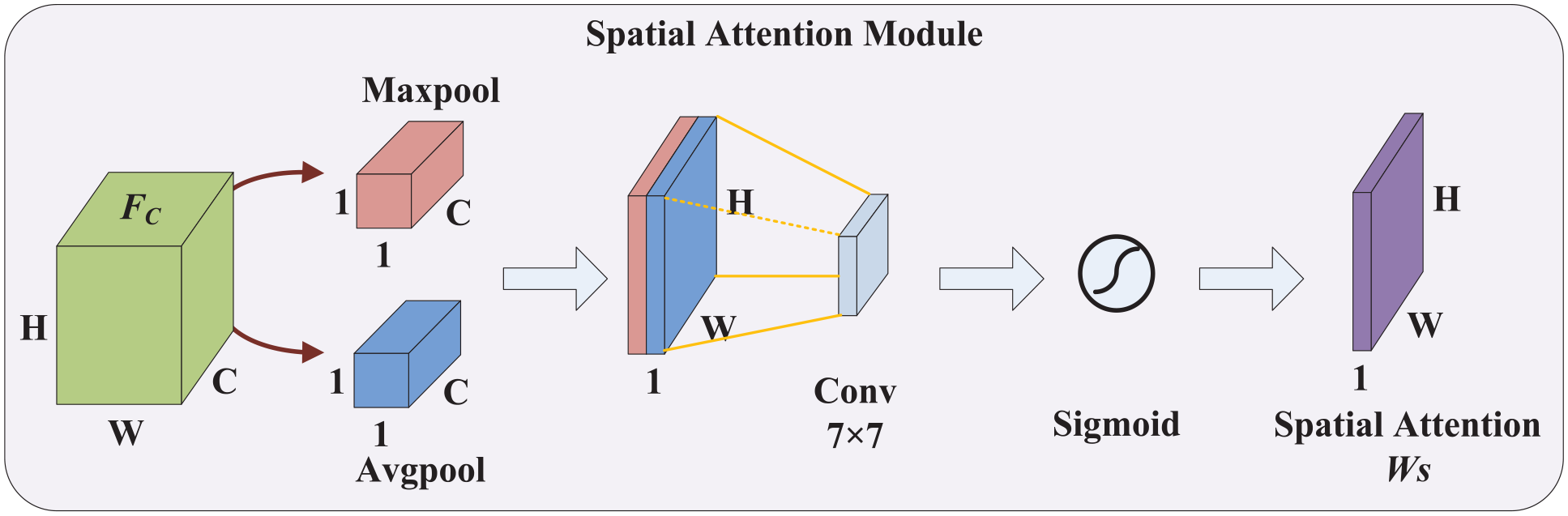
The structure diagram of Spatial Attention Module.
Feature enhance module
The main function of the Feature Enhancement Module FEM is to enrich coarse-grained features by extracting basic information from fine-grained features through a Top-Down information path by using hierarchical relationships. While adopting top-down information fusion between layers, FEM does more enhancement in the same “sensitivity field.” Therefore, more effective contextual and semantic information can be learned in width and depth to enhance the discriminant and robust of features. Dilated Convolution is mainly used to improve the receptive field of feature maps, so as to improve the accuracy of multi-scale target detection. The structure diagram of FEM is shown in Figure 6.
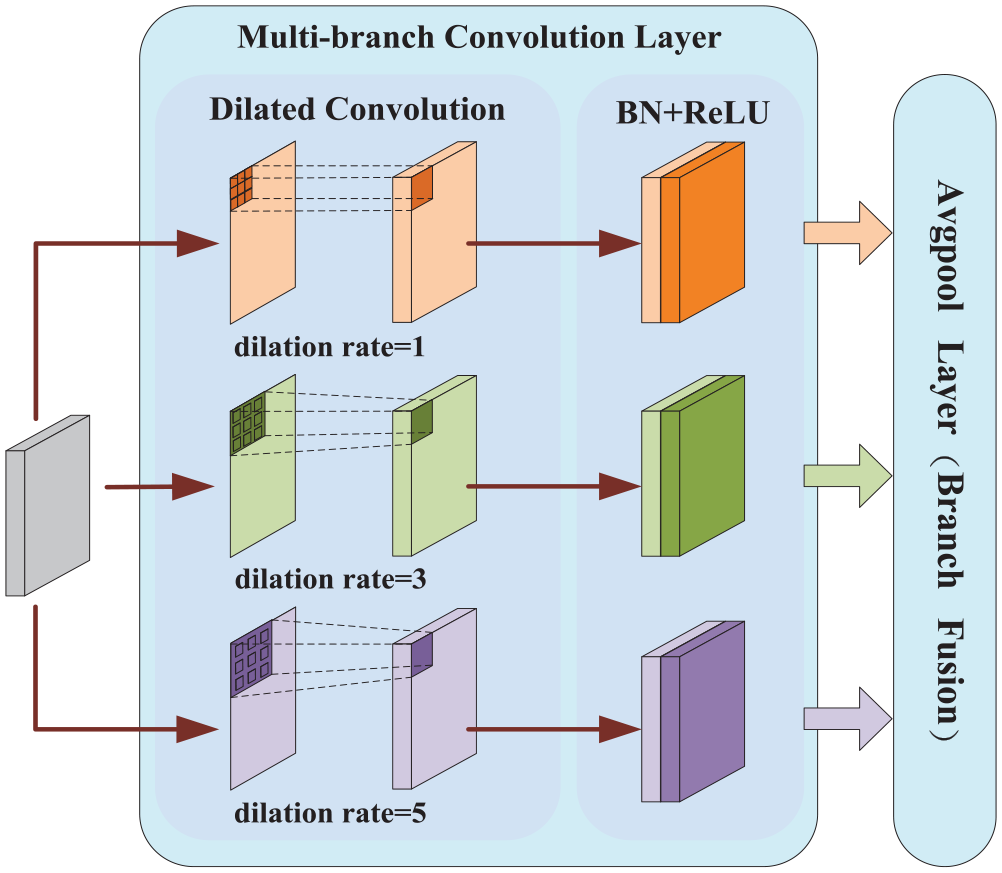
The structure diagram of FEM.
FEM mainly consists of two parts: multi-branch convolution layer and multi-branch average pooling layer. The multi-branch convolution layer provides different sizes of receptive fields for input feature graphs mainly through dilated convolution. It includes dilated convolution, BN layer and ReLU activation function layer. In the three parallel branches, the same 3 × 3 convolution kernel is adopted, and three different dilated rates are adopted respectively, which are 1, 3, and 5. The advantage of this method is that the receptive field is enlarged without pooling loss of information. In the dilated convolution operation, a hyperparametric Dilation Rate is added, and the normal convolution dilation rate is 1. The receptive field of dilated convolution can be calculated by the following formula:

Where, r stands for dilation rate. The expansion convolution inserts spaces between the kernel elements, and the dilation rate indicates how much you want to widen the kernel.
The multi-branch average pooling layer is designed to improve the accuracy of multi-scale prediction by fusing information from three parallel branch receptive fields. The expression of branch pooling fusion is as follows:

Where, Yap represents the output of the multi-branch average pooling layer. b represents the number of parallel branches, in this system b = 3.
Loss function
In forecasting, YOLOv5s uses Generalized IoU Loss (GIoU_Loss) as the loss function of Bounding Box. The expression of GIoU_Loss loss function is as follows:



Where, C represents the minimum external rectangle of the prediction box and the Ground Truth box,

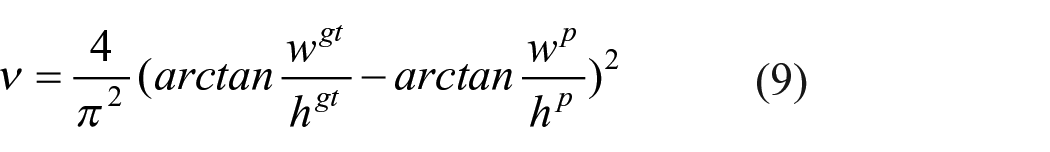
Where,
Detection results and analysis
In this section, a series of experiments are conducted to evaluate the performance of the proposed network structure. All experiments were conducted on a server using an Intel Core i7-6800K processor with a 3.4 GHz dominant frequency, 94 GB of memory, and a GeForce GTX 1080Ti graphics processor (GPU). The software part uses Ubuntu 18.04 operating system and Pytorch deep learning framework.
Evaluation index
There are two main performance indexes to evaluate the results of target detection model: accuracy index mAP (mean Accuracy Precision) and speed index FPS (Frames Per Second). In order to elaborate the specific evaluation method of mAP, two performance indicators mentioned above are needed: Precision (P) and Recall (R).
In object detection, the mapping relationship between Precision and Recall is represented by P(R). Precision and Recall under different confidence thresholds are plotted as a P-R curve, and the Accuracy Precision AP of a certain class is represented by the area below the P-R curve of this class. The evaluation index is used to measure the quality of a certain kind of test results. Its calculation formula is as follows:

Mean Accuracy Precision mAP is a comprehensive evaluation index obtained by averaging AP values of each type of object to measure the quality of detection results of multiple categories. Its calculation formula is as follows:

Where, M represents the total number of categories, and
The real-time evaluation index of the detection model is evaluated by Frames Per Second FPS, and its calculation formula is as follows:

Where,
Defect detection results of raw fabric
In the experiment, TILDA raw fabric sample database is used to test the performance of the algorithm. TILDA raw fabric sample database is a standard defect sample database, which contains two groups of raw fabric samples C1 and C2. Class C1 fabric image has uniform texture, fine yarn, thin texture, high fabric density and simple background texture, including two types of fabric: C1R1 and C1R3. Class C2 fabrics contain visible, grid-grained fabric images with thicker yarns, a grid-like structure, less fabric density and a relatively complex background texture, which also includes two types of fabrics: C2R2 and C2R3. Both C1 and C2 fabrics contain four types of defects: Holes, Oil Spots, Thread Errors, and Objects on the Surface. C1R1, C1R3, C2R2, and C2R3 were composed of 200 defective samples and 50 non-defective samples, respectively. In the experiment, 400 defect samples were respectively taken from C1 and C2 fabric samples in the database. According to different defect types, 720 samples were selected from the image samples as training samples, and the remaining 80 samples as test samples. The defect detection results of raw fabric before and after algorithm improvement are shown in Figure 7. Figure 8 shows the P-R curves of the four defect categories in the raw fabric database respectively under the original YOLOv5s algorithm and the proposed algorithm when the IoU threshold is 0.5.

The defect detection results of raw fabric.

The P-R curve of raw fabric database: (a) the P-R curves of original YOLOv5s algorithm and (b) the P-R curves of proposed algorithm.
Defect detection results of patterned fabric
Patterned fabric is selected as the second type of test object. Patterned fabric is the sample database provided by the Hong Kong Polytechnic University, which includes three types of fabric, namely, Dot-Patterned fabric, Star-Patterned fabric, and Box-Patterned fabric. Star-Patterned fabric and Box-Patterned fabric contain five defect types respectively: Broken End, Hole, Netting Multiple, Thick Bar, and Thin Bar. In addition to the above five defect types, Dot-Patterned fabric also include Knots (Knots), a total of six defect types. Each defect type contains five defective samples and each fabric type contains five non-defective samples. In the experiment, 80 defect images were selected from the patterned fabric samples. According to different defect types, 70 samples were selected from the image samples as training samples and the remaining 10 samples as test samples. The defect detection results of patterned fabric before and after improvement are shown in Figure 9. Figure 10 shows the P-R curves of six defect categories in the patterned fabric database respectively under the original YOLOv5s algorithm and the proposed algorithm when the IoU threshold is 0.5.

The defect detection results of patterned fabric.

The P-R curve of patterned fabric database: (a) the P-R curves of original YOLOv5s algorithm and (b) the P-R curves of proposed algorithm.
Comparative analysis of results
In order to evaluate the performance of this method, representative target detection models Faster RCNN, 46 SSD, 47 EfficientDet, 48 RetinaNet, 49 YOLOv4, 50 and YOLOv5s were selected for comparative experimental analysis. Table 1 summarizes the performance of mean Accuracy Precision (mAP) and Frames Per Second (FPS) by each algorithm in fabric defect detection. The values in bold in Table 1 are the detection results corresponding to the algorithm proposed in this paper. In order to more clearly display the comparison of detection performance of each model, the comparison cluster diagram of each model is shown in Figure 11.
Comparison of different models detection performance.


Cluster diagram for comparing the detection performance of different models.
As can be seen from Table 1, due to the addition of the Convolutional Block Attention Module, the network can more accurately distinguish the differences between defects and backgrounds to achieve better detection effect. Moreover, the Feature Enhancement Module is used to enhance feature discrimination and robustness, which can enrich the extracted feature information, thus improving the accuracy of fabric defect detection. In terms of detection accuracy, the improved YOLOv5s algorithm proposed in this paper can achieve mean Accuracy Precision of 86.4% and 75.8% on raw fabric and patterned fabric data set, respectively, which improves the performance of the original YOLOv5s algorithm by 7.6% and 1.7%. The mAP of Faster R-CNN algorithm on raw fabric and patterned fabric data sets is 91.1% and 88.9%, respectively. Faster R-CNN, as a typical two-stage target detection model, has the greatest advantage over the single-stage model in detection accuracy, so faster R-CNN can achieve a higher mAP value. As one of the earliest single-stage target detection models, SSD eliminates the process of extracting candidate regions, and the mAP of raw fabric and patterned fabric data sets is 73.7% and 25.9%, respectively. Compared with the SSD model, the proposed algorithm improves the performance of mAP by 12.7% and 49.9%, respectively. For the first time, RetinaNet proposed Focal Loss to solve the problem that positive and negative network samples are not easy to balance, which greatly improved the detection accuracy of the network, and realized the mAP of 41.6% and 54.8% in the raw fabric and patterned fabric data sets, respectively. Combined with the weighted bidirectional feature pyramid network and the scale joint scaling method, EfficientDet enable the network to quickly merge the multi-scale features and uniformly scale the trunk, feature extraction and prediction networks. Due to the unique data set, the EfficientDet model shows good performance under the raw fabric data set. mAP value reaches 91.1%, but the mAP value obtained under the patterned fabric data set is not referential, so it is not displayed in the table.
In terms of reasoning speed, Faster R-CNN belongs to the two-stage detection model, and although the best detection accuracy is obtained, the detection speed is not satisfactory, with the detection speed only reaching 14.2 FPS, which cannot meet the needs of practical applications. The model with the highest detection speed in all comparison experiments is YOLOv5s, which reaches 149.2 FPS. The algorithm in this paper is improved on the basis of YOLOv5s algorithm, sacrificing part of the detection speed of the original algorithm and improving the detection accuracy. After testing, the improved YOLOv5s model can reach the detection speed of 102.0 FPS, fully satisfying the real-time detection of industrial field targets, has great application potential.
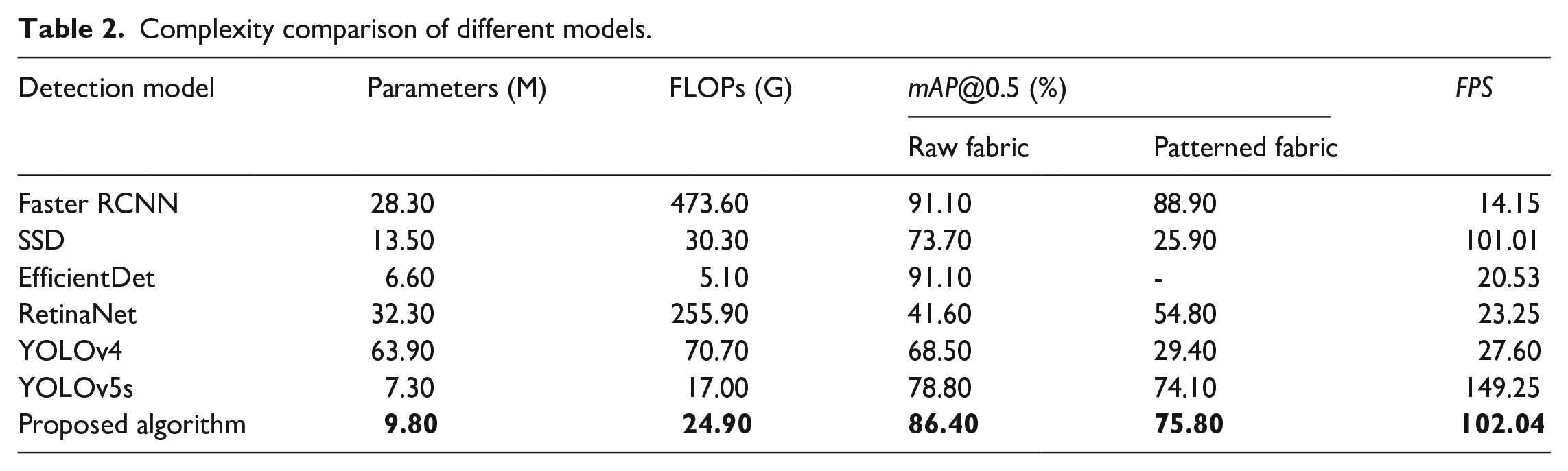
Model Parameters and Floating Point Operations (FLOPs) are two parameters that measure the size and complexity of the model. The size of model parameters is mainly related to the network structure of the model. Generally, the more complex the model is and the deeper the network layer is, the more parameters the model has. Floating Point Operations refers to the number of floating point computation, which is used to measure the complexity of detection algorithm. It describes the number of floating point computation required by the network to detect an image, namely, the computational force required by the model when running on hardware devices. The larger the value of floating point computation, to some extent, indicates that the model is more complex, the model needs more computing power, so the higher the requirements on hardware. Table 2 shows the comparison between the proposed improved YOLOv5s and other detection models in terms of model parameters and Floating Point Operations. The values in bold in Table 2 are the corresponding parameters and detection results of the algorithm proposed in this paper. It can be seen that the proposed improved YOLOv5s has a relatively small number of model parameters and relatively small model complexity. Although the improved parameters and complexity of the YOLOv5s models are slightly higher than the models EfficientDet, they far outperform the models EfficientDet in terms of real-time performance. However, compared with other models, the proposed algorithm has some advantages in terms of the number of model parameters and the complexity of the model. Therefore, the proposed improved YOLOv5s model is more suitable for deployment on embedded edge computing devices with low memory, small storage and weak computing.
Complexity comparison of different models.
Conclusion
In this paper, lightweight network is applied to fabric defect detection, and its network model is tested on deep learning workstation, which provides technical support for the application of network model in industrial field. Firstly, based on the YOLOv5s network architecture, the algorithm integrates the Convolutional Block Attention Module and Feature Enhancement Module, which improves the feature extraction ability and reasoning speed of the network. Compared with the original YOLOv5s, the detection accuracy is significantly improved, which effectively balances the accuracy and complexity of the deep learning model. Secondly, the complexity, detection accuracy and reasoning speed of the improved model and other models are compared, which provides a theoretical reference for the application of lightweight network in industrial field. The deep learning algorithm requires a lot of calculation, and the neural network model training and reasoning are usually completed on the deep learning workstation. However, for the field machines and equipment, the computing power needs to be taken into account, as well as the limitation of installation space and cost, which can not be ignored. The current deep learning model is difficult to be directly applied to the fabric defect detection production line. Therefore, how to design a more efficient network learning method, significantly reduce the model complexity and model parameters while keeping the detection accuracy unchanged, find cost-effective field edge computing equipment, and better realize the real-time detection of industrial sites is the next content to be studied.
Due to the limited computing power of the edge device, the improved YOLOv5s algorithm model can be trained on the local workstation, and the trained model can be transplanted to the edge device NVIDIA Jetson TX2 and NVIDIA Jetson Nano to reduce the training cycle. In order to meet the real time requirement of industrial field, TensorRT is used to accelerate inference deployment of the model. In terms of fabric sample selection, a large number of non-defect fabric samples and a certain amount of real defect fabric samples are introduced into the network model learning to build a semi-supervised deep learning fabric defect detection model to improve the performance of network training.
Footnotes
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Key Project of Shaanxi Provincial Department of Science and Technology of China (Grant No. 2019GY-014).