
Abstract
This article presents a solid color circular weft fabric defect detection method based on AYOLOv7-tiny. The aim of the development of this network is to enable real-time defect detection in the production of large circular machine fabrics. The network has a good accuracy rate, fast detection speed, and a lightweight model. In the YOLOv7-tiny network, a space-to-depth layer followed by a non-strided convolution layer is introduced to enhance the feature extraction capability, improve image sharpness, address issues such as uneven grayscale and difficult detection of minor defects, and simplify the model complexity while reducing computation. Additionally, we combined the Squeeze and Excitation (SE) and Spatial Attention Module (SAM) based on Convolutional Block Attention Module (CBAM) to construct the Hybrid Attention Module (SC), which is integrated into the YOLOv7-tiny network. The SC module increases the weight of important features, enhances the feature extraction capability, improves image segmentation, and enhances the accuracy of the network's location information. Through extensive experiments with a dataset of large circular machine solid color circular weft fabric defect collected from an industrial site, the results show that AYOLOv7-tiny has a detection accuracy (mean average precision) of 98.7%, a detection speed of up to 333 frames per second, and a computational complexity of only 4.4 GFlops, which is better than the current mainstream surface defect detection models. The detection accuracy, detection speed, and model complexity of the AYOLOv7-tiny network all meet the real-time detection requirements of the industry and have been successfully used for real-time detection of large circular machine fabric defects.
In the digitalization and intelligentization transformation of the textile industry, the quality control of fabrics is a key issue, and defect detection is a necessary step in fabric quality control. Among them, solid color circular weft fabric, as a fundamental material in the textile industry, has a wide range of applications and plays a significant role in various fields and purposes. The value of solid color circular weft fabric is evident in its extensive applications, comfort, customization, and decorative aspects, making it an indispensable component of the textile industry. Solid color circular weft fabric surface defects appear during the weaving process and are mainly caused by equipment malfunctions, yarn problems, foreign objects, poor processing, excessive stretching, etc. Such flaws include broken warp or weft, thick knots or warp, weft bars, loose edges, pilling, stains, holes, etc. Solid color circular weft fabric surface defects not only affect the appearance of fabric but also the quality of the end product, causing much waste of resources and economic losses. 1 Therefore, defect detection is essential in the solid color circular weft fabric production process. 2
Automated fabric defect detection is an important approach to ensure the quality of textiles in modern textile manufacturing. 3 However, due to the complex texture background, various and diverse types of defects, and inconsistent sizes, the automatic detection of fabric defects 4 poses a significant challenge. With the development of machine vision and deep learning, 5 the automated detection of fabric defects has become feasible. 6 Traditional machine vision detection models require image preprocessing, segmentation, feature extraction, and other steps and are susceptible to environmental factors such as lighting and dust, have weak generalizability, and poor algorithm stability and universality, making it difficult to meet the needs of online fabric defect detection. Compared with those of traditional machine vision methods, deep learning has powerful feature expression ability, generalizability, and cross-scene ability and has been widely used in defect detection in fields such as solar energy, 7 LCD panels, 8 magnetic materials, 9 and metal materials. 10
Solid color circular weft fabric defect detection requires high accuracy to provide defect location information for labeling. Defect detection methods based on deep learning classification networks 11 can only obtain rough localization, and the localization accuracy is related to the sliding window size, network classification performance, and other factors. 12 Object detection networks can obtain accurate target location and classification information, making them the best networks for solid color circular weft fabric defect detection tasks. 13 Object detection networks can be divided into one-stage and two-stage networks. Two-stage object detection networks first extract boxes based on an image and then obtain detection results based on candidate regions for secondary modification. Although their detection accuracy is high, they are slow. These networks mainly including R-CNN, 14 Fast R-CNN, 15 Faster R-CNN, 16 Mask R-CNN, 17 and Libra R-CNN. 18 Single-stage object detection algorithms directly calculate a target's classification and location in an image. Although their detection accuracy is slightly low, these algorithms have faster detection speeds; these algorithms mainly including the YOLO series, 19 SSD, 20 and RetinaNet. 21 Compared to two-stage object detection networks, single-stage object detection networks are more popular in industrial object detection due to their detection efficiency and accuracy.
YOLOv7
22
is currently one of the best single-stage object detection networks for defect detection. However, directly using the YOLOv7 network for solid color circular weft fabric defect detection is challenging due to the complex texture background of solid color circular weft fabric, the diverse and varied defect types and sizes, and some subtle defects that are very similar to solid color circular weft fabric textures and are difficult for the human eye to distinguish. Based on this, a modified YOLOv7 defect detection network was proposed. This network combines the optical characteristics of solid color circular weft fabric, texture distribution, defect imaging characteristics, and detection requirements with the use of SPD-Conv and a mixed attention mechanism. Additionally, a solid color circular weft fabric defect automatic detection system was developed and successfully applied to the real-time detection of fabric defects on large circular machines. The main contributions of this article are as follows:
Introduce an SPD-Conv module
23
into the backbone network to replace each stride convolution layer and pooling layer. SPD-Conv consists of a spatial-to-depth (SPD) layer and a non-stride convolution (Conv) layer, which can reduce the loss of fine-grained information and improve the learning ability for low-resolution images and small object features, thus enhancing the feature extraction ability and learning efficiency of the YOLOv7-tiny backbone network. Construct an SC hybrid attention module by combining the Squeeze and Excitation (SE) channel attention module
24
and the Spatial Attention Module (SAM) based on the Convolutional Block Attention Module (CBAM).
25
By stacking the output features of the channel and spatial attention mechanisms, the weights of important features are increased, which not only effectively improves the feature extraction ability of the network but also enhances the accuracy of feature extraction and location information. Combine SPD-Conv and SC in a new solid color circular weft fabric defect detection network framework named AYOLOv7-tiny. The new framework can not only improve the accuracy of solid color circular weft fabric defect detection but also greatly reduce the computational cost. It has been successfully implemented on the NVIDIA Corporation (NVIDIA) platform for the real-time detection of fabric defects on a circular loom machine.
Based on the contributions mentioned above, we can understand that AYOLOv7-tiny is built upon the foundation of YOLOv7-tiny. The key distinction lies in the incorporation of the SPD-Conv module into the existing backbone network of AYOLOv7-tiny, leading to a reduction in the complexity of the network model. Additionally, we introduced our own SC module, which combines with Batch Normalization (BN) layer and Leaky Rectified Linear Unit (ReLU) activation function to form the CBL-1 module. Subsequently, we replaced the first two Convolutional Bottleneck Layer (CBL) modules of the YOLOv7-tiny network and the last CBL module of the C5 module with the CBL-1 module. The introduction of the SC module effectively enhances the network's feature extraction capabilities. These improvements collectively constitute the enhanced AYOLOv7-tiny network. Further elaboration on the detailed network architecture will be provided in Chapter Four.
Related work
In recent years, some domestic and foreign scholars have used deep learning to study textile defect detection and have achieved some results.
Liu et al. 26 proposed a fabric defect detection framework based on Generative Adversarial Networks (GANs). By training a texture-conditioned GAN, the framework generates realistic defect patches and seamlessly integrates them into specific locations to achieve better defect detection under varying conditions. It should be noted that this method is only applicable for detecting defects and does not classify the types of defects. Lin et al. 27 proposed an attention-enhanced defect classification system that can address both defect detection and classification. This system enhances the classification ability by zooming in and out over minor defects, but this approach comes with the risk of distortion and loss of surrounding information.
Liu et al. 28 proposed a modified YOLOv4 algorithm by replacing MaxPool of spatial pyramid pooling (SPP) structure with SoftPool. This method efficiently processes the feature maps and increases the defect detection accuracy. However, this method has a slower detection speed and lower real-time performance. Lin et al. 29 proposed a method to detect small objects using a sliding window and a multi-head self-attention mechanism, and introduced the Swin Transformer module into the YOLOv5 algorithm. This approach shortens the distance between different scales and improves the accuracy of small object detection. However, due to the long training time and the large number of model computational parameters, this approach cannot achieve the same effect on a mobile device.
The above mentioned methods all have certain limitations that may affect their wide use in industrial applications.
Solid color circular weft fabric detection system
Solid color circular weft fabric detection apparatus
The solid color circular weft fabric defect detection system developed in this article is shown in Figure 1 and mainly consists of a mechanical driving system, an image acquisition system, and an image processing system. The mechanical driving system is mainly composed of a motor, a turntable, and a lead needle. The motor drives the turntable to rotate, and the lead needle continuously produces the solid color circular weft fabric material. The image acquisition system consists of a 2K line scan camera and multiple angle light sources, which are used for high-quality imaging of the solid color circular weft fabric and capturing defects such as broken warp or weft, holes, and scratches. The image processing system consists of an Artificial Intelligence (AI) computer Jetson NANO, detection system software, and other components to achieve the real-time and accurate detection of various solid color circular weft fabric defects.

Solid color circular weft fabric defect detection system.
Textile imaging analysis
Textile solid color circular weft fabric are manufactured by thread being pulled by the rotation of a loom. Due to the design of the loom, the shape of the fabric area captured by a camera is curved, and thus, an image captured by the camera appears clear in the center but gradually becomes blurry toward the edges. Textile defect detection requires high accuracy, as some defects as small as 100 µm and a variety of defect types and sizes are produced during the production process, some of which are very subtle and resemble the solid color circular weft fabric background. Therefore, we use a 2K area array camera to capture high-quality images of textiles, with a resolution of 2744 × 500. As shown in Figure 2, the top layer shows an original textile image and the bottom window shows five images cropped from the corresponding location of the top layer image, Figure 2(a) and (e) are cropped from the left and right sides of the original image, respectively. Comparing all images, it can be seen that Figure 2(b) and (d) are brighter and clearer than Figure 2(a) and (e), while the clarity and brightness of the image cropped from the middle part of the original image Figure 2(c) is the best. So, the sharpness of the textile image gradually decreases from the center to the edges, and the brightness gradually fades from the center to the edges. Therefore, we collect a suitable number of images at an appropriate time according to the production speed of the loom to reduce missed and false detections caused by unclear image acquisition.

Cropping windows for fabric imaging: (a) left crop picture; (b) left of center crop picture; (c) middle crop picture; (d) right of center crop picture and (e) right crop picture.
The solid color circular weft fabric defects produced by the large circular loom are diverse and include: Broken pick, Slack pick, Slack end, Broken end, Drop stitch, Oil stain, Hole and Smash. Figure 3 shows the main types of defects. Depending on the type of defect and considering the accuracy and efficiency of the defect detection model, defects are classified into three categories: hole defects, long strip defects, and short strip defects, as shown in Figure 4. Holes are classified as Hole defects, as shown in Figure 4(a). Defects with a size exceeding 3 cm, such as Broken pick, Slack pick, Slack end, Broken end and Smash, are classified as long strip defects, as shown in Figure 4(b). Defects with a size not exceeding 3 cm, such as Drop stitches and Oil stains, are classified as short strip defects, as shown in Figure 4(c).

Defect types of circular loom machine.

Imaging of different types of solid color circular weft fabric: (a) hole defects; (b) L_line defects and (c) S_line defects.
Difficulties in solid color circular weft fabric defect detection
According to the imaging characteristics and detection requirements of textile defects from a circular knitting machine, the main challenges of defect detection are as follows:
Textiles have complex textures, which make the texture of some defects appear similar to the texture of the solid color circular weft fabric, leading to missed detections or false detections. Due to the structural issues of circular knitting machines, the clarity and grayscale of the captured images are inconsistent, which poses greater difficulties in defect detection. Due to raw materials and environmental factors, some flying debris objects are inevitably produced during the textile production process. The imaging characteristics of these objects are similar to those of broken warp or weft yarns, holes, and scratches, which can easily result in misjudgments. Textile defects have significant differences in size and morphology, requiring the detection model to have good detection performance for multiscale targets.
AYOLOv7-tiny solid color circular weft fabric defect detection model
AYOLOv7-tiny solid color circular weft fabric defect detection method
With network performance improvements, the complexity of networks has continued to increase, which also increases the demand for device computing power. However, in the current field of automatic solid color circular weft fabric defect detection, it is difficult for industrial sites to provide high-performance hardware platforms to ensure the detection accuracy. Therefore, the value of complex networks in practical applications is relatively small. This requires researchers to conduct more research and apply algorithms in detection systems with limited resources to meet the needs of practical applications.
YOLOv7-tiny is a lightweight model based on YOLOv7. Compared to YOLOv7, which utilizes complex modules such as ELAN, max-pooling (MP), and SPPCSPC, YOLOv7-tiny uses relatively lightweight modules such as C5, MP, and SPPCSP. While the accuracy of YOLOv7-tiny is slightly reduced, it achieves a significant reduction in computational complexity and an improvement in detection speed, making it more suitable for industrial deployment. YOLOv7-tiny uses 3 × 3 convolutional kernels with a stride of two in the network and performs multiple pooling operations to downsample an image, reducing the feature dimension and obtaining positional information, which reduces the number of parameters and simplifies the network computation. However, this also leads to the loss of texture features and object category information. 30 As a result, YOLOv7-tiny's detection performance is not ideal for small targets and low-resolution images, as it cannot effectively extract and fuse object features. Additionally, due to the diversity of solid color circular weft fabric defect types, the network requires a combination of deep semantic information and shallow localization information. 31
Based on this, to achieve high precision and the eff0icient detection of solid color circular weft fabric defects, this article proposes the AYOLOv7-tiny network framework. The network structure of AYOLOv7-tiny is shown in Figure 5 and mainly consists of three parts: input (Input), backbone network (Backbone), and head (Head).
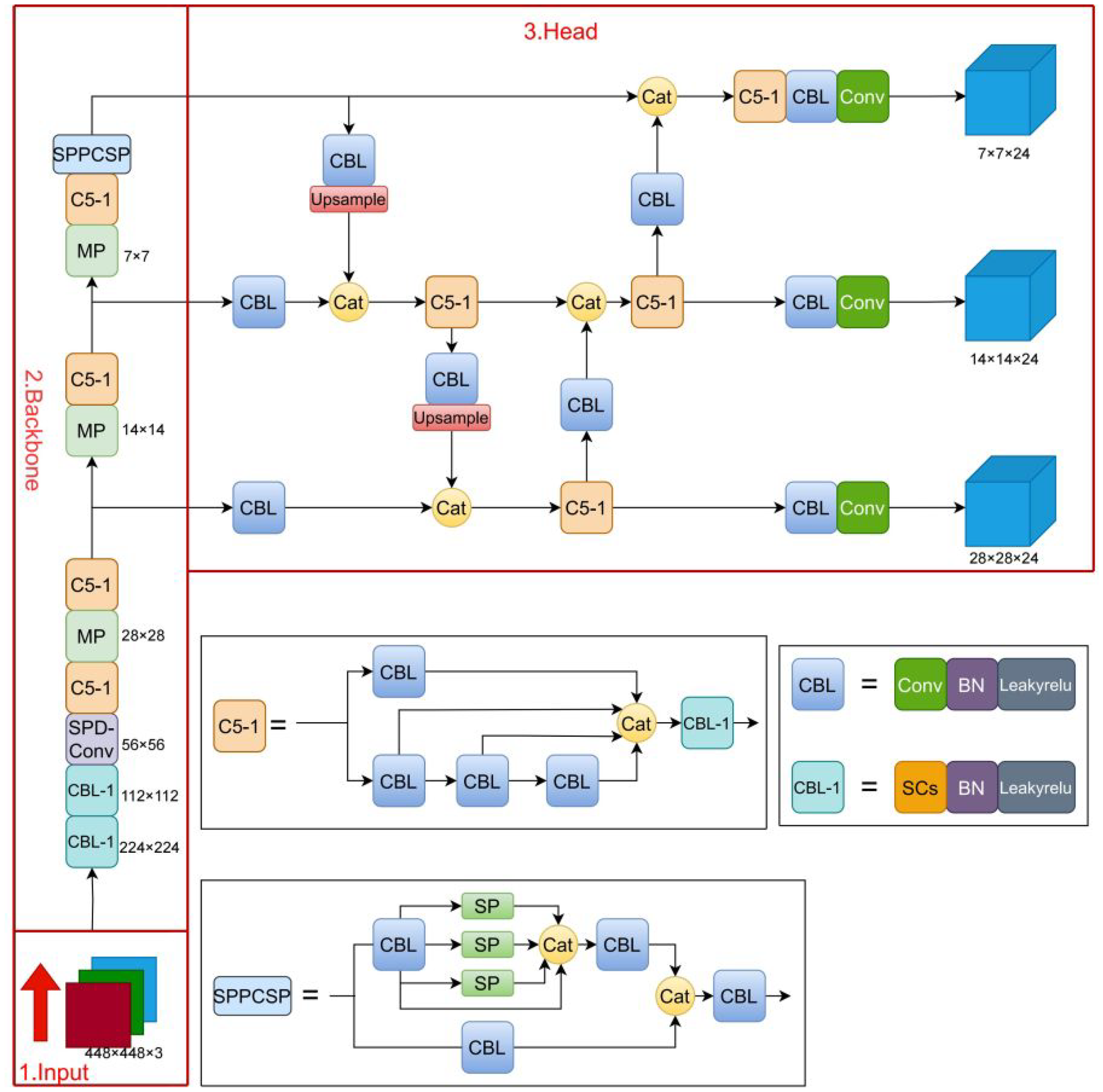
Network architecture of AYOLOv7-tiny.
The role of the input profile is to pass images from the dataset to the object detection network. The backbone network of YOLOv7-tiny undergoes six display stages, resulting in six feature maps of different sizes, so the resolution of the input image must be a power of two to the sixth power. If the size of an input image does not satisfy this requirement, the network uses an appropriate unfolding trick to accommodate the input image. This enlargement method is not just about enlarging the image; instead, the original image is embedded into a larger background with the same aspect ratio as the input image, with black edges to fill in the gaps. This leaves an additional blank region on the background around the original image such that its dimension is consistent with the network input dimension, while retaining important image information. This background is a fixed-sized black image, which ensures that the object proportions in the image are still preserved. This approach prevents cutting or stretching of certain objects in the input image, increases the size of the feature extractor, enlarges the receptive field of the network, learns more spatial information, and improves the model performance.
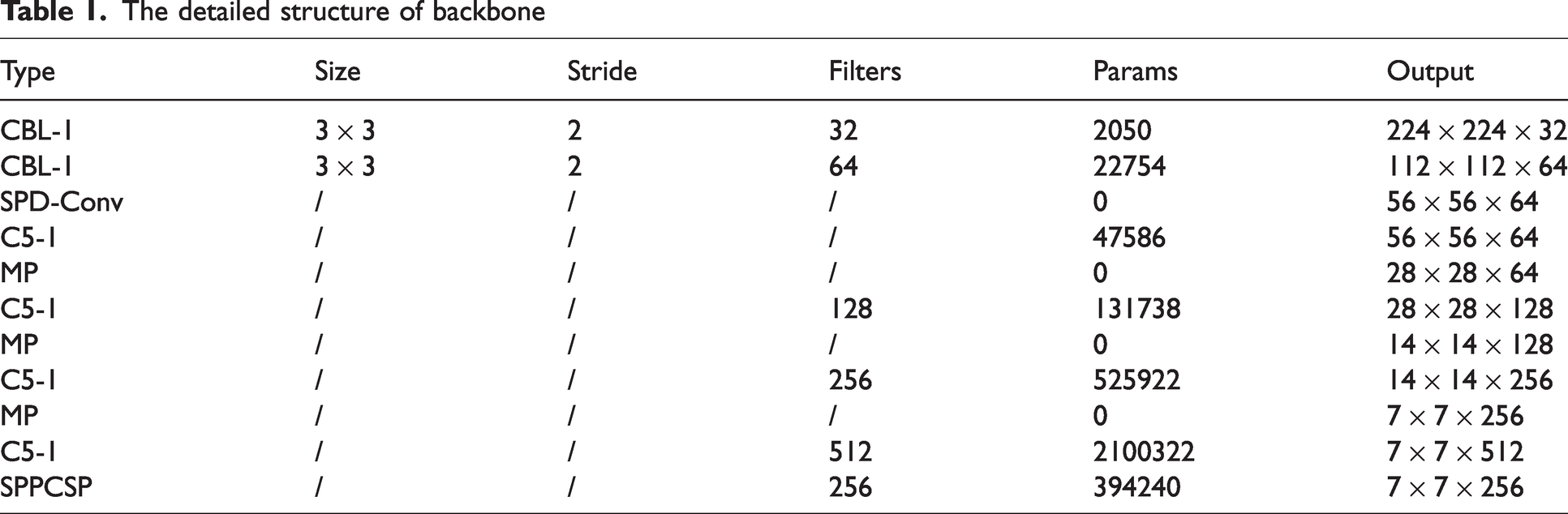
The detailed structure of the backbone network is shown in Table 1. It consists of the CBL-1, SPD-Conv, C5-1, MP, and SPPCSP modules. The CBL-1 convolution module consists of an SC layer, a BN layer, and the LeakyReLU activation function. The SC layer uses a 3 × 3 convolution kernel with a stride of two to downsample an image together with the MP module, generating six different sizes of feature maps, with resolutions of 224 × 224, 112 × 112, 56 × 56, 28 × 28, 14 × 14, and 7 × 7. The SPD-Conv module extracts deep features by downsampling the image once, enhancing the ability to extract features from small targets or low-resolution images. The C5-1 module is an efficient network structure that controls the shortest and longest gradient paths to enable the network to learn more features and have stronger robustness. The C5-1 module has two branches. The first branch performs channel changes using a 1 × 1 convolution. The second branch first performs channel changes using a 1 × 1 convolution module, extracts features using two 3 × 3 convolution modules, stacks the four features together and performs channel changes again to obtain the final feature extraction result. The SPPCSP module uses maximum pooling to obtain different receptive fields and increase the receptive field, making the algorithm adaptable to different resolution images. 32 In the first branch of SPPCSP, there are four branches with a MaxPool layer, allowing the model to handle different objects and distinguish small targets from large ones. In the second branch, regular convolution operations are performed, and the two parts are combined at the end, reducing the computational complexity by half, making the model faster and more accurate.
The detailed structure of backbone
The head network consists of the neck network and the lead head for object detection. The header network structure consists of a dual-pyramid architecture, composed of the feature pyramid network (FPN) 33 and the pixel aggregation network (PAN), known as the pyramid aggregation feature pyramid network (PAFPN) 34 as shown in Figure 6. FPN strengthens the feature extraction network by conveying strong semantic features from top to bottom and fusing high-level features with upsampled low-level features to obtain a feature map for prediction. The three effective feature layers (28 × 28, 14 × 14, 7 × 7) obtained from the backbone network are fused in this section to combine feature information of different scales and continue feature extraction. FPN transfers deep semantic features to shallow layers, enhancing the semantic information for multiple scales but not enhancing the localization information. The PAN structure is bottom-up in the feature pyramid, downsampling the features again, transferring shallow localization information to deep layers and enhancing the multiscale localization capability. The PAFPN double pyramid structure ensures that feature maps of different scales contain both semantic and positional information of an image, ensuring the accurate prediction of images of different sizes.
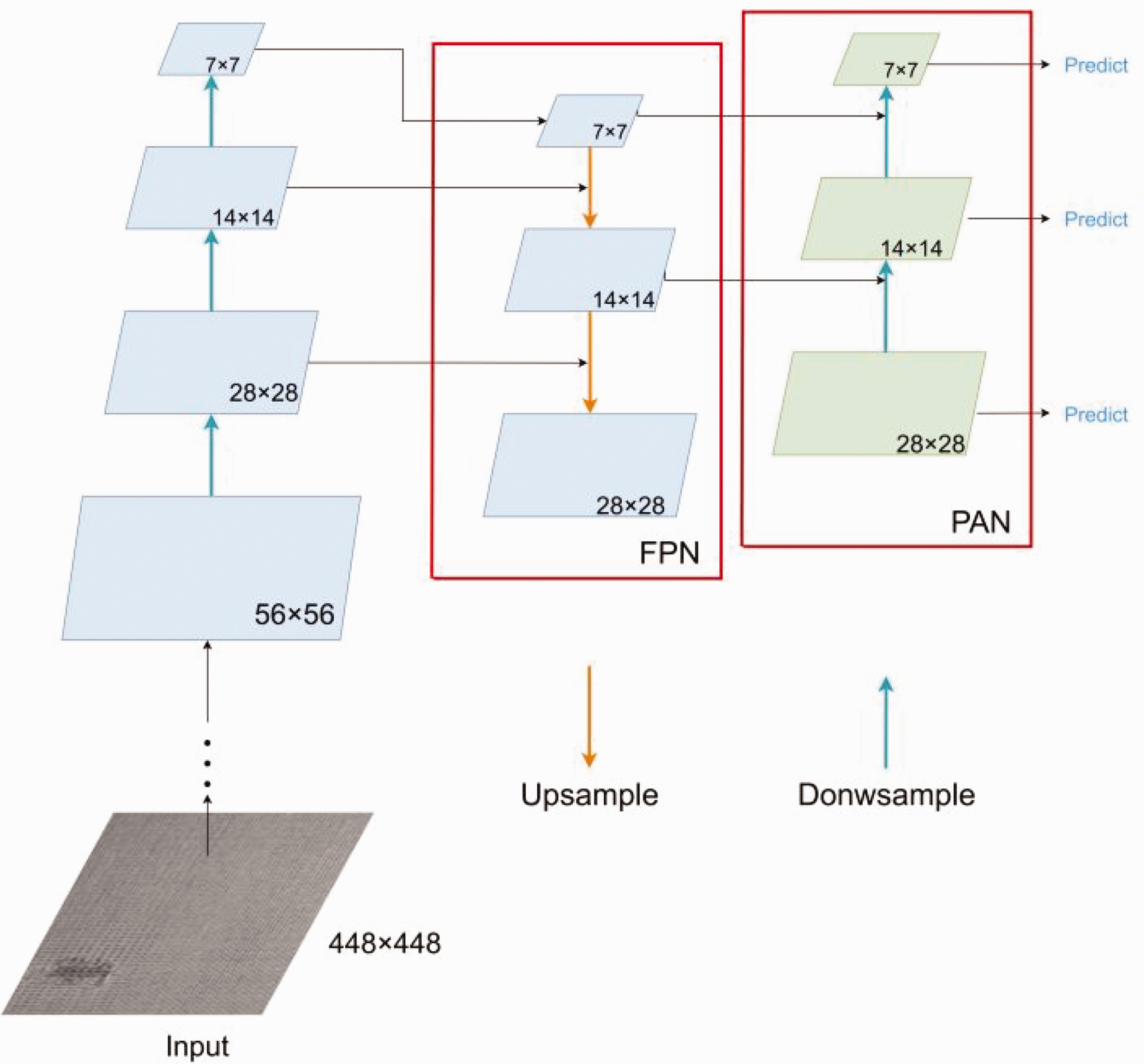
PAFPN structure. FPN: feature pyramid network; PAN: pixel aggregation network.
In this article, a SPD-Conv module is introduced into the backbone network of AYOLOv7-tiny. By combining this module with the proposed SC hybrid attention module, the feature extraction capability can be further enhanced, and the computation cost can be significantly reduced.
SPD-Conv module
In the design of convolutional neural network (CNN) architectures, the use of convolutional strides and pooling layers often leads to the loss of fine-grained information and a reduction in the efficiency of feature representation learning. 35 In particular, for images with low resolution or small objects, the performance of image classification and object detection is significantly reduced. The SPD-Conv module can greatly improve the detection of low-resolution images or small objects. Therefore, in this article, we introduce the SPD-Conv module into the backbone network of YOLOv7-tiny to replace each strided convolutional layer and pooling layer. This can solve the problems of detecting unclear textile images and small defects and significantly reduces the computational cost while enhancing the feature extraction ability.
SPD-Conv consists of a SPD layer and a non-strided Conv layer, as shown in Figure 7. This module can be applied to most CNN architectures. SPD utilizes image transformation techniques to downsample the feature maps within a CNN and the entire CNN network, as shown in equation (1).
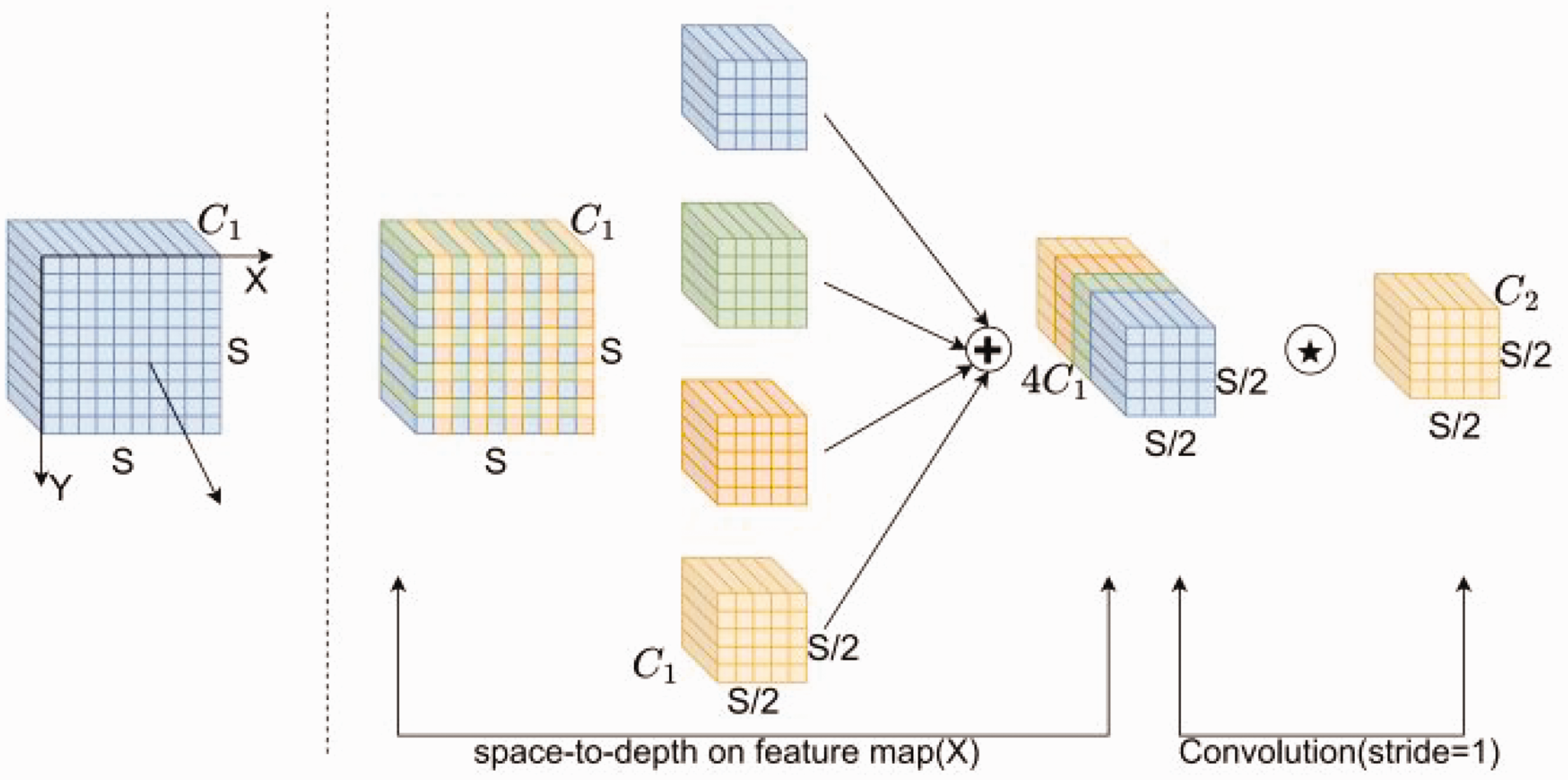
Structure of the SPD-Conv module. Conv: convolution; SPD: spatial-to-depth.
Considering an intermediate feature map 
For a given feature map
After the SPD feature transformation, a non-strided convolution layer is added to preserve as much discriminative feature information as possible. It is a convolutional layer with
Hybrid attention module
CBAM is a lightweight and widely used hybrid attention mechanism that obtains a new feature map by multiplying spatial attention output features and channel attention output features. The channel attention mechanism in the CBAM module extracts high-level features through global average pooling and maximum pooling. Different combinations of pooling can make the extracted high-level features more diverse, but at the same time, it increases computational complexity, and more position information is lost. 36 The SE module only extracts high-level features through one type of pooling, lacking feature richness while retaining little position information loss. Based on this, a new hybrid attention mechanism, SC, was constructed in this article by combining the SE channel attention module and the SAM of CBAM. SCs obtain a new feature map by combining the output features of the spatial attention and channel modules. The channel attention has rich channel information, which can improve the network's feature extraction ability, and the spatial attention can make the position information of defects more accurate, which can effectively enhance the network's feature extraction ability.
SE module
The SE module, as shown in Figure 8, mainly includes four parts: convolution 
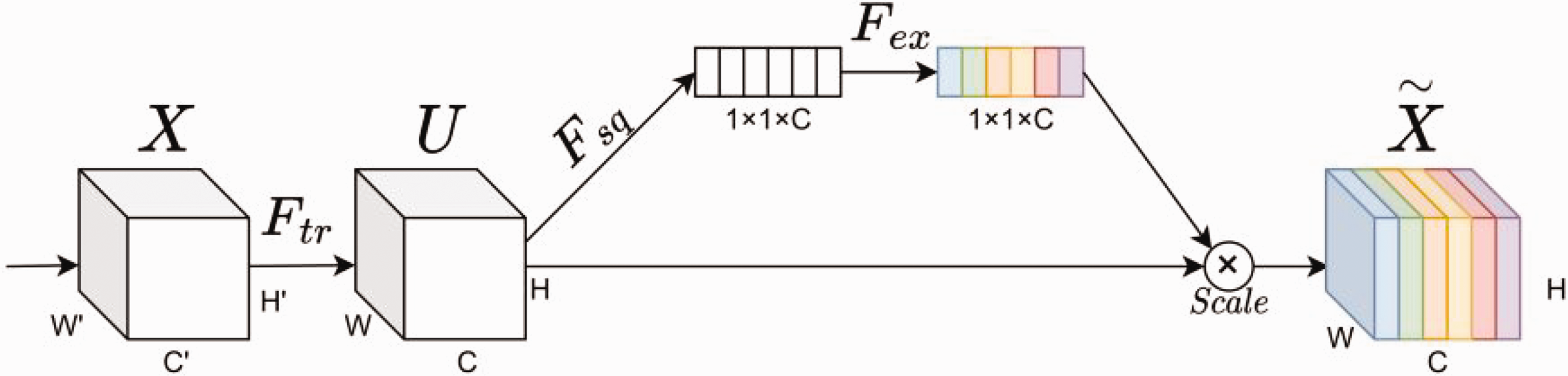
Structure of the Squeeze and Excitation (SE) channel attention module.
In equation (2), * represents convolution,
The 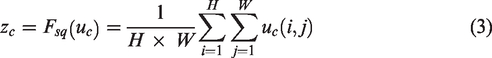
In equation (3),
The 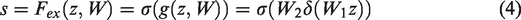
In equation (4),
The 
SAM
The SAM of CBAM, as shown in Figure 9, uses a feature map of size 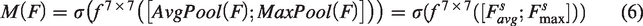
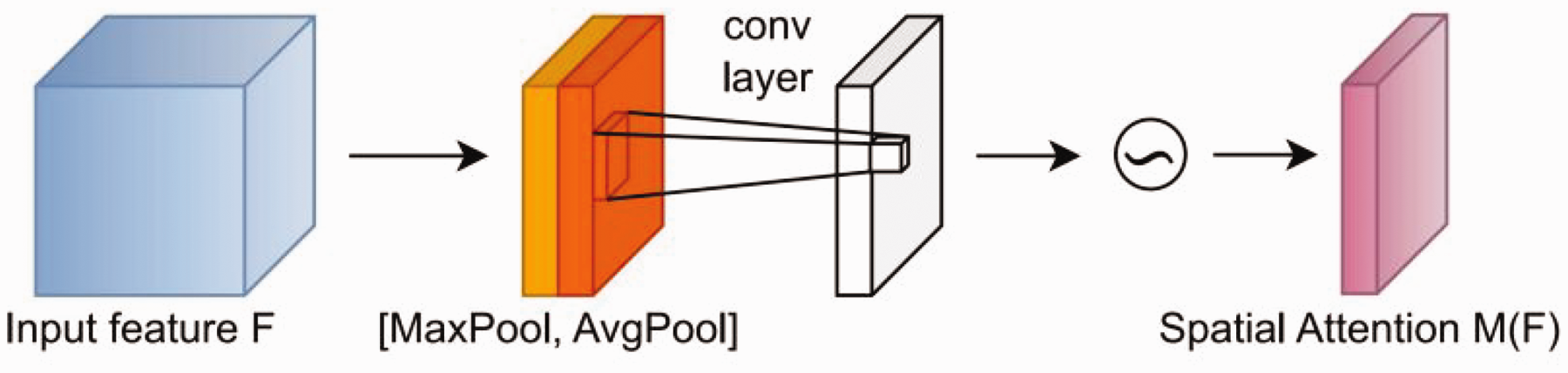
Structure of the Spatial Attention Module (SAM).
In equation (6),
SC module
The structure of the hybrid attention-based SC module constructed in this article is shown in Figure 10. The output features of the SE channel attention module are used as input features for the spatial attention module. The new features output by the SAM are then added to the feature results generated by the SE module to generate the final feature map. Compared with the CBAM module, the SC module can not only increase the weight of important features and enhance features, effectively improving the feature extraction capability of the network, but can also improve the image segmentation results, making the position information of defects more accurate.

Structure of the hybrid attention module.
Loss function
The loss function measures the degree to which the predicted values differ from the true values and largely determines the performance of the model. Its role is to measure the distance between the predicted information of the neural network and the expected information (label). The closer to the expected information the predicted information is, the smaller the value of the loss function. The loss function in this article consists of three parts: classification loss (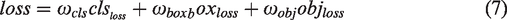
In equation (7), the confidence loss and classification loss use the binary cross-entropy loss function (BCEWithLogitsLoss), and the localization loss uses the
The cross-entropy loss function reduces the weight of missing samples (targets that exist but are not annotated) in the loss, reducing the negative impact of missing samples during backpropagation. The equation for the cross-entropy loss function is shown in equation (8):
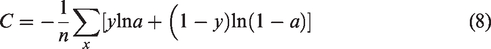
In equation (8),
The 
In equation (9),
The
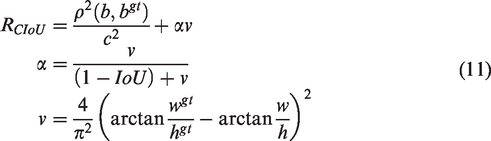
In equation (11),
Experiment validation
Solid color circular weft fabric defect dataset
The solid color circular weft fabric defect dataset used in this article was self-constructed from real industrial circular woven solid color circular weft fabric images, each with a resolution of 2744 × 500, captured by an on-site 2K matrix camera. As the product defect rate is relatively low, images containing solid color circular weft fabric defects were manually selected and cropped by quality inspectors, resulting in 2764 images with a resolution of 400 × 400. Skilled technicians then classified and labeled these images. In order to create a more diverse and enriched training sample set, we employed data augmentation techniques on the collected images, resulting in a substantially increased dataset of 5447 instances. Due to the differing levels of difficulty associated with detecting various defects, the quantity of gathered images varies accordingly, as depicted in Table 2. Among these, the counts for hole, S_line, and L_line defects are 481, 1728, and 3238, respectively.
Solid color circular weft fabric defect dataset

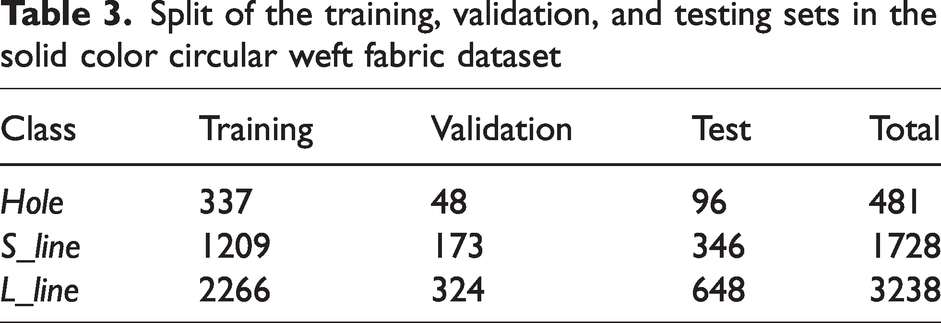
The dataset for the AYOLOv7-tiny network in this article consists of training, validation, and test sets. The datasets for each type of defect were approximately divided into 70%, 10%, and 20% for the training, validation, and test sets, respectively, as shown in Table 3.
Split of the training, validation, and testing sets in the solid color circular weft fabric dataset
Software version and hardware environment setup
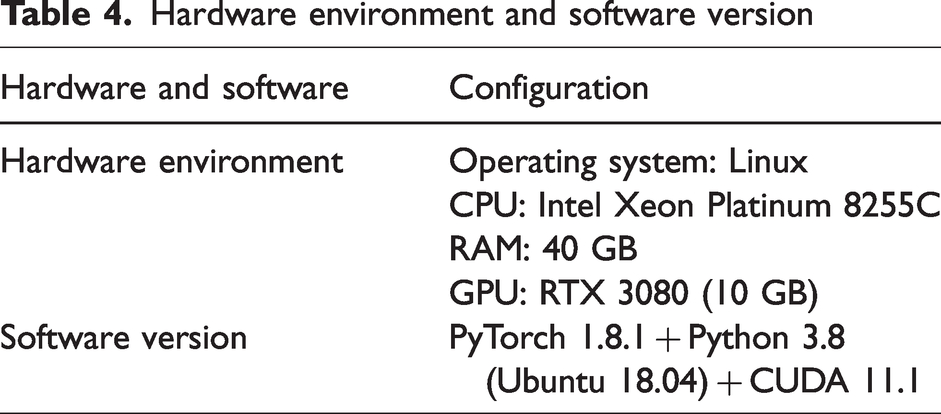
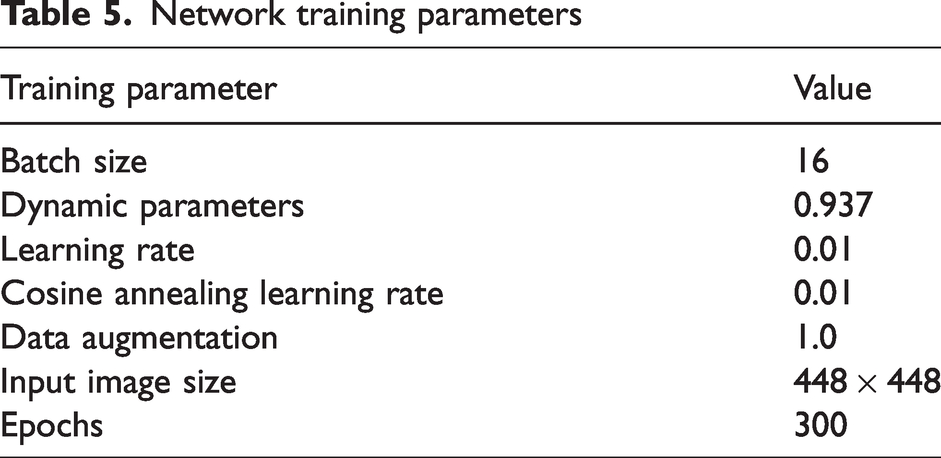
The software version and hardware environment of the experimental platform in this article are shown in Table 4, and the network training parameters are shown in Table 5.
Hardware environment and software version
Network training parameters
Data augmentation
In order to increase the amount of data and improve the robustness of the network during training, data augmentation techniques are used. Specifically, three methods are applied: Mixup, Cutmix, and Mosaic. In the Mixup method, two images are randomly mixed at a certain ratio, and the classification result of the mixed image is assigned to the original image at the same ratio. The Cutmix method splits an image into two parts and randomly interpolates the non-original pixel values to generate a new image. The Mosaic method randomly selects four images from the training set, applies random rotation and flip transformations to them, and then merges them into a larger image for training. At the same time, random scaling is used to increase the fraction of small targets in the training set. Due to the similarity between broken warp and slack weft after a 90-degree rotation, if the rotation angle exceeds the range of (–45, 45), it may impact the training effectiveness. Therefore, we have constrained the rotation angle of mosaic data augmentation within (–30, 30) to ensure that the similarity between broken warp and slack weft does not affect the training process. The principle is shown in Figure 11. These methods can enrich the training data and hence improve the accuracy and generalization ability of the model.
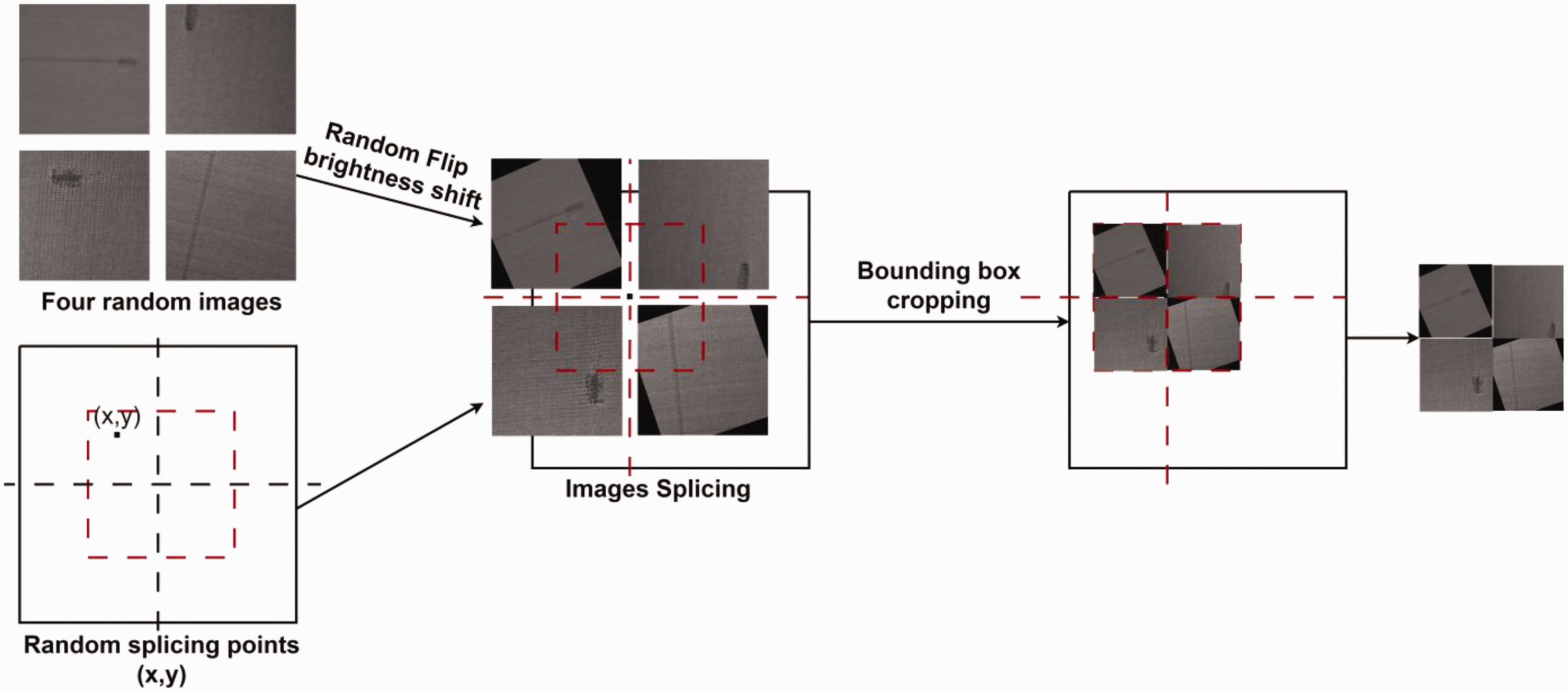
Mosaic data augmentation.
Performance metrics
To evaluate the performance of the AYOLOv7-tiny network, performance evaluation metrics such as the mean average precision (mAP), average precision (AP), floating-point operations per second (GFlops), and frames per second (FPS) were selected in this article. The AP represents the area between the precision-recall (P-R) curve and the coordinate axis and is used to evaluate the prediction accuracy of each type of defect. The mAP is the average of the AP values for each category. The FPS value is used to evaluate the detection speed of the model, and the higher it is, the more images the network can process per second.
The formulas for calculating precision and recall are shown in equations (12) and (13), respectively:


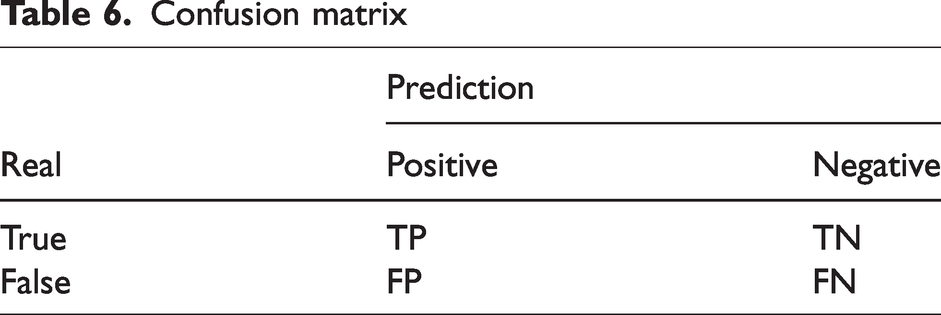
In these equations, TP represents the number of true positive samples, which are correctly predicted as positive. FP represents the number of false-positive samples, which are incorrectly predicted as positive. FN represents the number of false-negative samples, which are incorrectly predicted as negative. TN represents the number of true-negative samples, which are correctly predicted as negative (Table 6).
Confusion matrix
The formulas for precision and mean average precision are shown in equations (14) and (15), respectively:


Ablation experiments
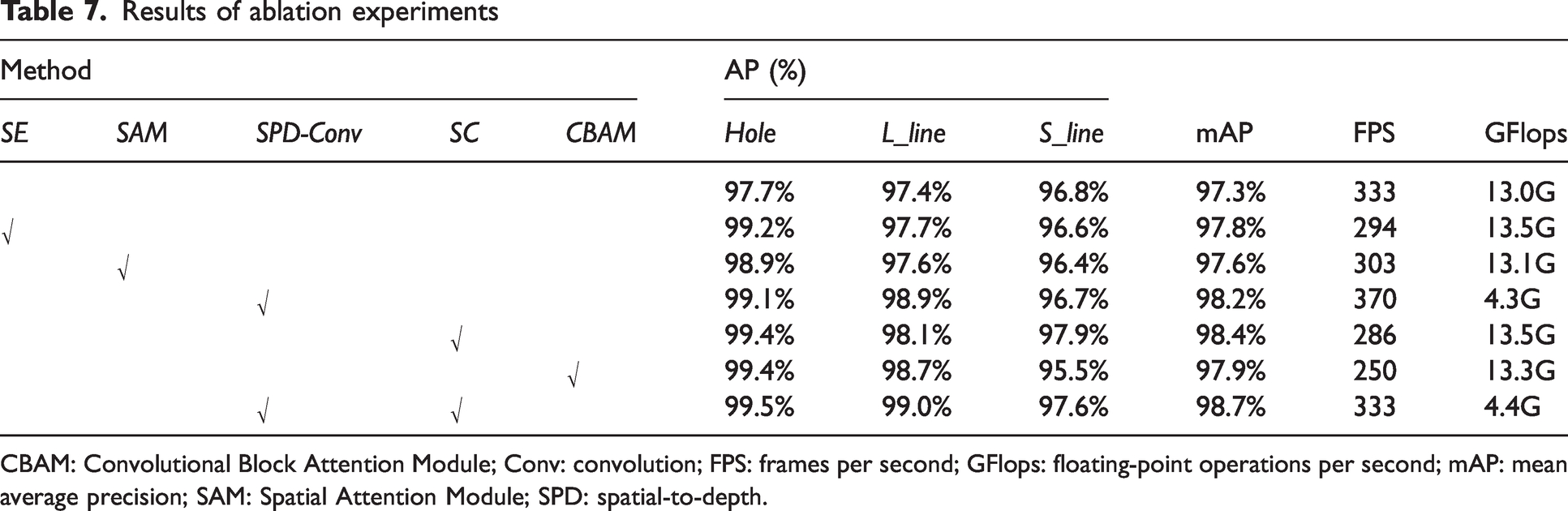
To verify the effectiveness of the AYOLOv7-tiny network architecture and analyze the impact of the SPD-Conv module and SC module on the network performance, ablation experiments were conducted in this study. Five different combination modes were set, and the detection results of each combination on the solid color circular weft fabric defect dataset are shown in Table 7.
Results of ablation experiments
CBAM: Convolutional Block Attention Module; Conv: convolution; FPS: frames per second; GFlops: floating-point operations per second; mAP: mean average precision; SAM: Spatial Attention Module; SPD: spatial-to-depth.
From Table 7, it can be seen that the detection accuracy (mAP) of the YOLOv7-tiny network is 97.3%, and the detection speed (FPS) is 333. With the addition of SE and SAM modules in the network, the detection accuracy as measured by mAP is 97.8% and 97.6%, respectively. When the CBAM attention mechanism is added, the mAP increases to 97.9%, but the FPS drops to a minimum of 250. In comparison, the addition of the SC module increases the mAP by 1.1%, reaching 98.4%, and the FPS reaches 286, indicating that the SC module is superior to the CBAM module in terms of feature fusion and representation. When using only the SPD-Conv module, the mAP increases by 0.9%, and the detection speed slightly increases. In terms of model complexity, compared with those of YOLOv7-tiny, the calculation cost (GFlops) of adding the CBAM and SC modules increases by 0.5 and 0.3, respectively, while adding the SPD-Conv module reduces the calculation cost by 8.7. When the SPD-Conv module and the SC module are added simultaneously, the mAP value increases by 1.4%, reaching 98.7%, and the calculation cost is significantly reduced from 13.0 to 4.4. At the same time, the detection speed remains unchanged. This indicates that the SPD-Conv module and the SC module are effective, and their combination improves the feature extraction of the backbone network, retains more semantic information in the feature fusion stage, and reduces information loss during transmission. Moreover, without reducing the detection speed, it effectively improves the accuracy (mAP) and reduces the calculation cost (GFlops), greatly enhancing the ability of solid color circular weft fabric defect detection.
Comparative experiment
This study uses the Jetson NANO embedded platform to realize the detection of solid color circular weft fabric defects. Jetson NANO has some limitations in terms of performance compared with that of mainstream industrial computers, so it is crucial to ensure that the calculation is as small as possible while improving the accuracy.
To evaluate the accuracy and real-time performance of the AYOLOv7-tiny network, the training loss, validation loss, and mAP during the training period are shown in Figures 12 and 13. At the same time, experiments were conducted with a self-built solid color circular weft fabric dataset to compare with mainstream networks such as YOLOv5, YOLOv6, YOLOv7, and YOLOv7-tiny. The experimental results are shown in Table 8.
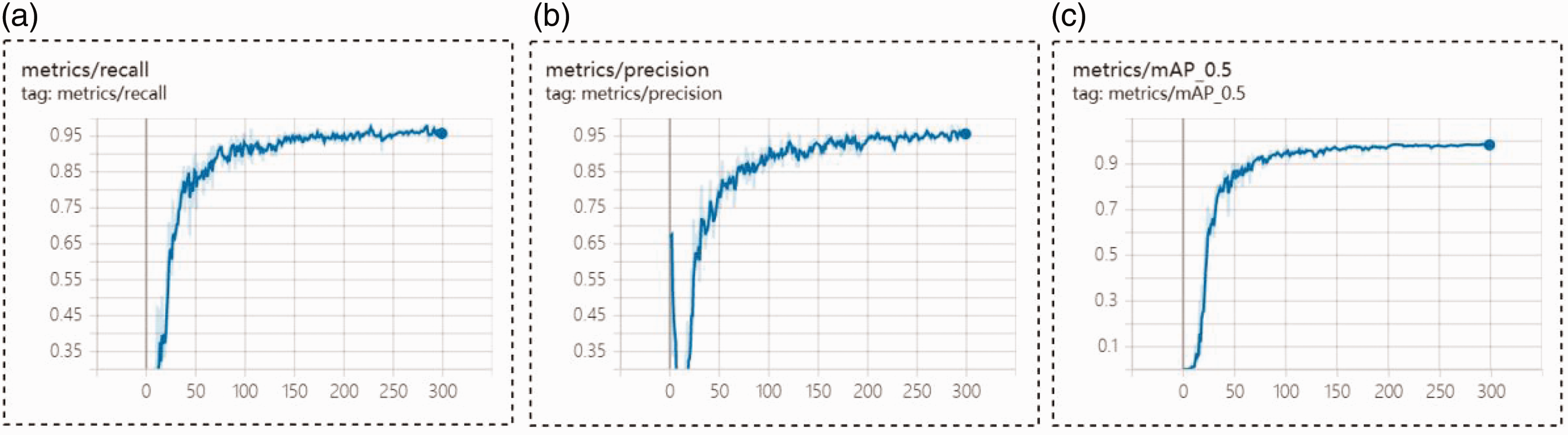
(a) Mean average precision (mAP) curve; (b) precision curve and (c) recall curve.
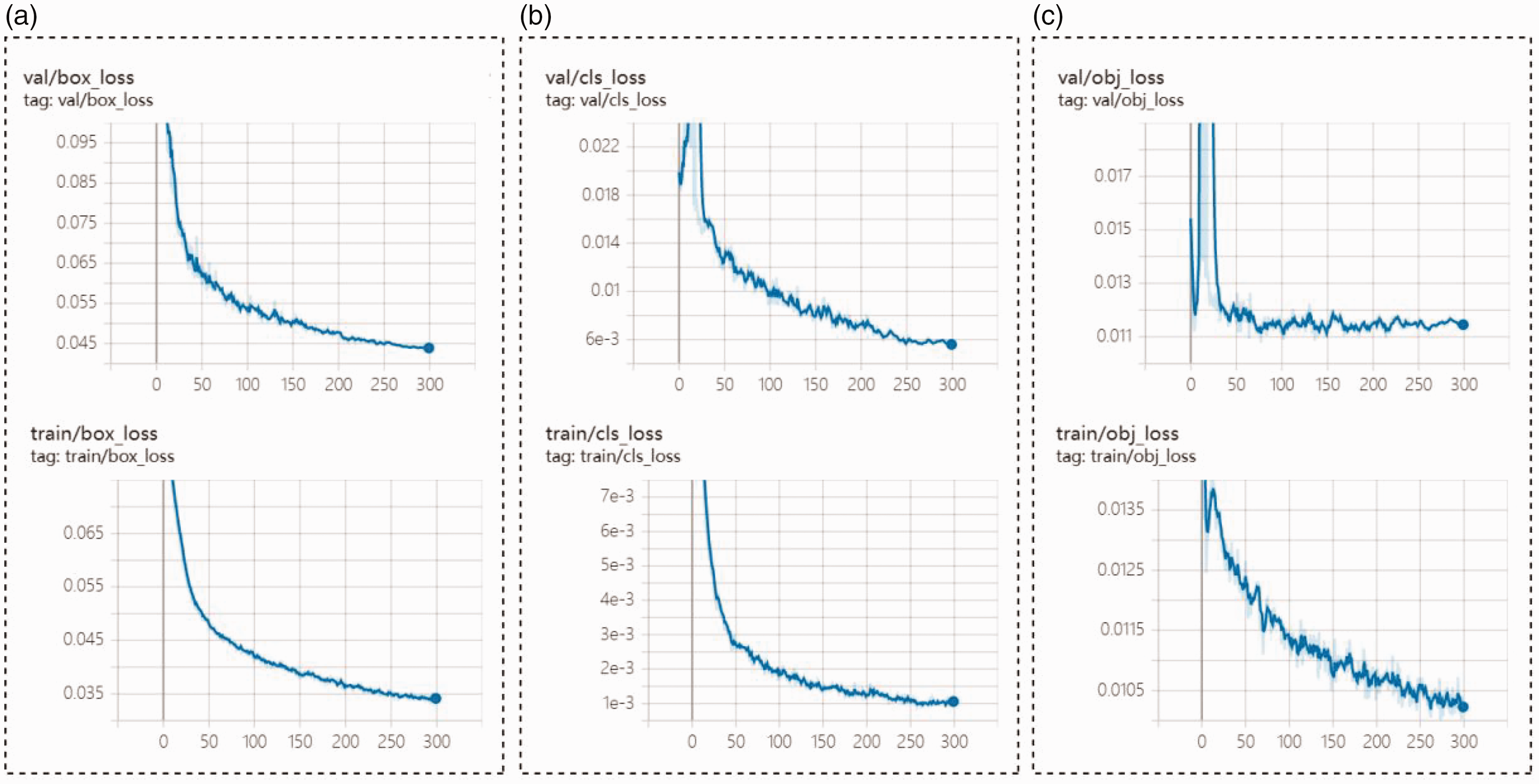
Training loss and validation loss.
Detection results of the solid color circular weft fabric defect dataset with different networks
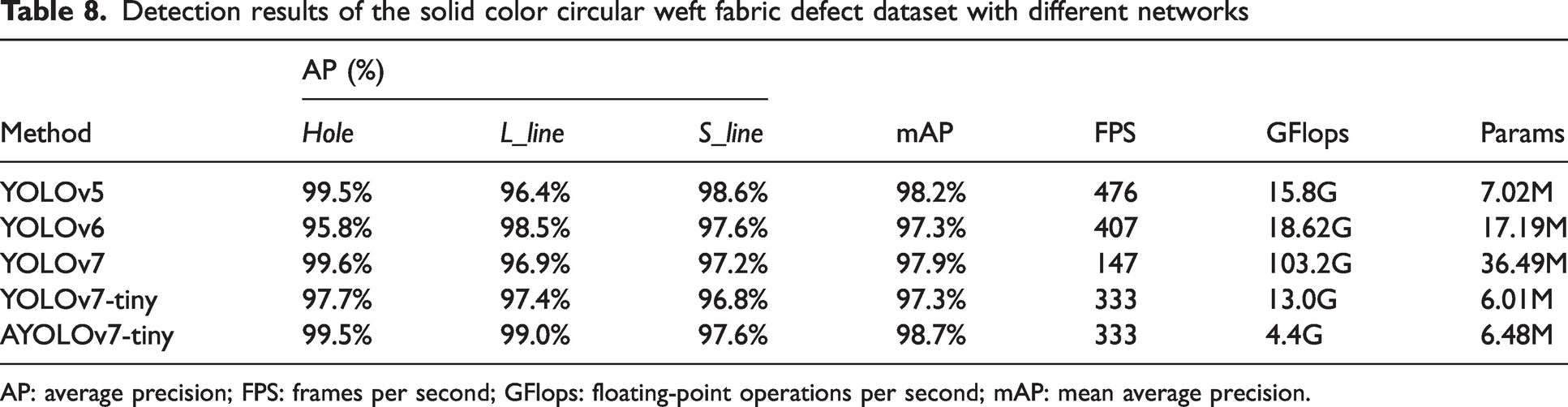
AP: average precision; FPS: frames per second; GFlops: floating-point operations per second; mAP: mean average precision.
As shown in Figures 12 and 13, the training and validation loss function curves rapidly converge within the first 50 epochs and converge completely when the number of epochs reaches 300. The mAP curve, precision curve, and recall curve also show increasing trends as the number of training epochs increases.
As shown in Table 8, the proposed AYOLOv7-tiny defect detection network outperforms the other object detection networks. In terms of the detection accuracy, the mAP value of the proposed AYOLOv7-tiny defect detection network is the highest (98.7%), which is an improvement of 0.5%, 1.4%, 0.8%, and 1.4% compared to YOLOv5, YOLOv6, YOLOv7, and YOLOv7-tiny, respectively. In terms of the detection speed (FPS), YOLOv5 achieves the fastest detection speed of 476. In terms of the computational cost (GFlops), AYOLOv7-tiny has the lowest computational cost, only 4.4. Compared to those of YOLOv5, AYOLOv7-tiny has advantages in detection accuracy (mAP), computational cost, and parameter quantity while meeting the real-time requirements for detection speed.
As shown in Figure 14, four windows were randomly selected to test the YOLOv5, YOLOv6, YOLOv7, YOLOv7-tiny, and AYOLOv7-tiny networks. The test results of different detection network models are shown in Figure 14.

Test results of the solid color circular weft fabric defect dataset with different models.
As shown in Figure 14, different models have different detection results with the solid color circular weft fabric defect dataset. Obviously, AYOLOv7-tiny has better detection performance than that of the other models.
In this study, the SPD-Conv module can improve the difficulties in detecting low-resolution images, inconsistent grayscale, and small defects. To effectively verify the effectiveness of the SPD-Conv module, we selected YOLOv7-tiny and YOLOv7-tiny with only the SPD-Conv module added (SPD-YOLOv7-tiny) to conduct experiments on images with clear or obvious defects, as well as images with poor image clarity or unclear defects. The detection results for images with clear or sharp defects are shown in Figure 15, while those with poor image sharpness or unclear defects are shown in Figure 16.

Validation 1 of the SPD-Conv module. Conv: convolution; SPD: spatial-to-depth.

Validation 2 of the SPD-Conv module. Conv: convolution; SPD: spatial-to-depth.
As can be seen from Figure 15, the detection results of YOLOv7-tiny and SPD-YOLOv7-tiny are almost identical when the image is clear or the defect is obvious. However, from Figure 16, it can be seen that the detection performance of SPD-YOLOv7-tiny is significantly improved when the image is blurred or the defects are not obvious.
In textile production, the imaging of flying debris is similar to that of solid color circular weft fabric defects. To test the false positive rate of the network for flying debris, YOLOv5, YOLOv7, and AYOLOv7-tiny, which have higher mAP values in this study, are compared in a test and their results are shown in Figure 17.

Detection of flying debris.
Flying debris is caused by the factory environment, as shown in Figure 17, where Figure 17(a)–(c) are images of different flying debris falling on solid color circular weft fabric. For Figure 17(a), YOLOv5 mistakenly detects it as a long strip defect, while YOLOv7 mistakenly detects it as a short strip defect. For Figure 17(b), YOLOv5 mistakenly detects it as a long strip defect and a hole defect, while YOLOv7 mistakenly detects it as a long strip defect. For Figure 17(c), YOLOv5, YOLOv7, and AYOLOv7-tiny all mistakenly detect it as a long strip defect. AYOLOv7-tiny also has false detections, but its detection performance for flying debris is better compared to the other models.
During the validation of the AYOLOv7-tiny model, it was found that there were some missed and false detections in a small number of test images, as shown in Figure 18. Figure 18(a) and (b) show false detections, with the true label being S_line, but the detected result being L_line. Figure 18(c) shows a missed detection, where the defect is S_line, but it was not detected. There are still some shortcomings in the detection of S_line defects, and the detection process may have missed and false detections. The main reason is that this type of defect is similar to the solid color circular weft fabric background texture or L_line defect, which can make it difficult to distinguish differences.

Typical false detection, missing detection: (a) S_line; (b) S_line; (c) missing detection.
Experimental results of the glass fabric defect dataset
In order to further validate the effectiveness of the AYOLOv7-tiny network, the glass fabric defect dataset is collected on a real industrial flat weaving machine. The dataset is divided into nine categories: Wave selvedge, Coarse pick, Slack end, Sand mark, Torn selvedge, Slub , Double pick, Broken end and Harness skip. The defect types are shown in Figure 19. A comparison experiment was also performed, using the same experimental method as the fabric defect dataset experiment on a large circular machine. The experimental results are shown in Table 9.

The types of defects in glass fabric.
Comparative experiments with the glass fabric defect dataset
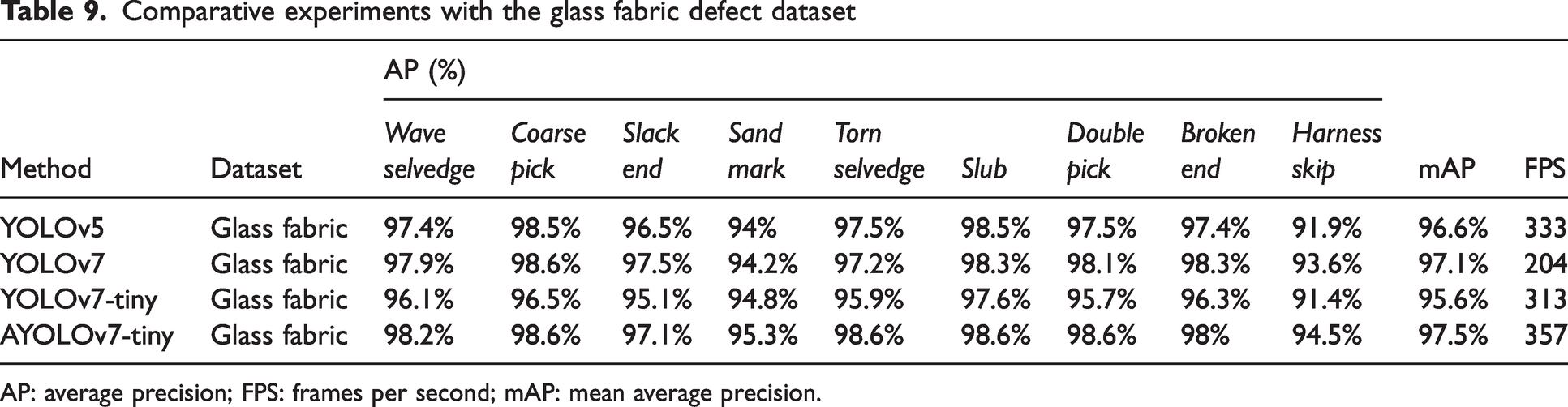
AP: average precision; FPS: frames per second; mAP: mean average precision.
According to Table 9, the mAP of AYOLOv7-tiny reaches the highest value of 97.5% and the detection speed FPS can also reach 357. Moreover, AYOLOv7-tiny has low network complexity and small computational load, which makes it easier to deploy on embedded platforms at industrial sites. In this study, six randomly selected images are taken from different types of defects to test the YOLOv5, YOLOv7, YOLOv7-tiny, and AYOLOv7-tiny networks, and the test results of the different detection network models are shown in Figure 20.

The test results of the fiberglass fabric defect dataset on different models.
As shown in Figure 20, different models have different detection results on the fiberglass fabric defect dataset. Clearly, AYOLOv7-tiny has better detection performance compared to other models. Therefore, it can be seen that AYOLOv7-tiny also performs well in detecting other types of textile defects.
Applications of AYOLOv7-tiny in Industry
AYOLOv7-tiny has been deployed on the Jetson NANO embedded platform and has been successfully applied on the large circular knitting machine industrial site, as shown in Figure 21. Figure 21(a) shows the large circular knitting machine industrial site, Figure 21(b) shows the Jetson NANO device, and Figure 21(c) shows the real-time detection interface for fabric.

Applications of AYOLOv7-tiny in industry.
Conclusion
In this article, we proposed a solid color circular weft fabric defect detection method based on the AYOLOv7-tiny network to address the challenges of complex texture backgrounds, inconsistent brightness and clarity, diverse types and sizes of defects, and difficulties in applying models on edge computing devices with solid color circular weft fabric images. First, we introduced the SPD-Conv module into the backbone network, which improved the receptive field for low-resolution images and small objects, enhanced the feature extraction capability of the network, and effectively reduced the computational cost during the detection process. Second, we constructed a hybrid SC attention module by combining channel attention and spatial attention, which increased the weight of important features while enhancing the accuracy of feature extraction, preserved more semantic information during feature fusion, and reduced the information loss, thereby effectively enhancing the overall feature extraction capability of the network. Finally, we constructed our own solid color circular weft fabric defect dataset using large circular knitting solid color circular weft fabric images collected from industrial on-site settings and conducted extensive experiments. The experimental results showed that the proposed AYOLOv7-tiny network achieved the best performance, with a detection accuracy of 98.7% with the solid color circular weft fabric defect dataset and a 66% reduction in computational cost. Moreover, the AYOLOv7-tiny network has been successfully deployed on the Jetson NANO embedded platform, meeting the solid color circular weft fabric detection requirements for production enterprises.
Footnotes
Acknowledgements
Availability of data and material: all data used in the experiments are from the public database. The datasets generated during the current study are available from the corresponding author on reasonable request. Code availability: the codes generated during the current study are available from the corresponding author on reasonable request.
Declaration of competing interests
The author(s) declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Key R&D Program of Zhejiang (No. 2023C01062) and Basic Public Welfare Research Program of Zhejiang Province (No. LGF22F030001, No. LGG19F03001).