
Abstract
Deep-learning models have been successfully applied to fabric defect detection fields. However, due to the lack of available dataset for the digital printing fabric defect detection field, the study is still under-explored. Besides, there are two tough challenges that currently existing deep-learning models cannot resolve well. On the one hand, the actual production requires the models to improve its detection accuracy as much as possible while ensuring real-time detection. On the other hand, the objectives of classification and localization are correlated, so the link between classification and localization should be established for an excellent object detection model. To solve these problems, such Classification-Aware Regression Loss (CARL) is embedded into the YOLOF to correlate the classification and localization tasks so that the model is named CARL-YOLOF. The performance of the proposed model has been trained and evaluated by the self-built digital printing fabric defect detection dataset (DPFD-DET). Experimental results demonstrate that CARL-YOLOF achieves 0.54 AP on COCO metrics, which achieves a gain of 0.04 compared with YOLOF. Besides, CARL-YOLOF maintains the speed advantage of YOLOF, which reaches 42 FPS. Therefore, the proposed model is suitable for the real-time digital printing fabric defect detection.
Introduction
The printing and dyeing industry is an important part of textile industry, and the textile printing is a key operation to enhance the additional value of textiles. 1 Digital printing technology, a new type of printing technology, provides textiles with more realistic, brighter and natural printing effects, and further enhances the additional value of textiles compared with the customary printing technology (e.g. roller printing, screen printing, transfer printing, etc.). 2 At the same time, a series of complex factors in printing process may be harmful for textile quality 3 such as flawed sizing and dyeing for while gray fabrics, 4 instable ink-jet printing system, 5 drips of water from steamer etc. Which will lead to printing defects such as PASS track, PASS tracks, ink leakage, blank, ghost, fluff, water leakage, pulp, etc. Figure 1 visualizes samples of the digital printing fabric defects. Therefore, digital printing fabric defect detection has become an effective yet indispensable link of printing and dyeing quality monitoring.

Some example images in the digital printing defect database: (a) PASS track, (b) PASS tracks, (c) ink leakage, (d) blank, (e) ghost, (f) fluff, (g) water leakage, and (h) pulp.
In recent years, it is still a hot topic that the theoretical knowledge of deep learning is applied effectively to fabric defect detection field. Peng et al. 6 proposed a Priori Anchor Convolutional Neural Network (PRAN-Net) for fabric defect detection to improve the detection and location accuracy of fabric defects. Zhu et al. 7 proposed a modified DenseNet model to better suit a resource-constrained edge computing scenario. Li and Li 8 proposed three tricks to further improve the precision for fabric defect detection based on Cascade R-CNN. However, due to the limitations of the available dataset, the previous research objects of fabric defects mainly focused on white gray fabrics, pure color fabrics, and single-texture color fabrics, while limited research was conducted on digital printing fabrics.
The improvement of digital printing fabric defect detection performance is closely related to the development of detectors. The definition of positive and negative anchors and loss function are two core components of detector, their continuous enrichment in theoretical knowledge has great significance to the development of detector.
In terms of the definition of positive and negative anchors, we simply review the following representative methods such as Max-IoU, 9 ATSS, 10 Uniform-match. 11 First, Max-IoU adopts IoU (Intersection over Union) between anchors and ground-truth boxes as a measure of positive and negative anchor, it has been flexibly applied to SSD, BAGS, and PISA.12 –14 Then, ATSS uses dynamic IoU threshold to more efficiently match a stable number of positive anchors for each object. Unlike the above-mention methods, Uniform-match is based on the center point distance between the ground-truth boxes and the anchor boxes, the prediction boxes corresponding to the anchor boxes to match a fixed number of positive anchors for each ground-truth boxes, which improves the model’s ability to detect each object in a sparse space.
As far as the loss function of object detection is concerned, it is specifically divided into classification loss function and bounding box regression loss function, which cooperate to complete the detection task. For the classification loss function, it often be asked to improve the model’s ability to detect positive samples through hard sampling or soft sampling.9,15 –17 For the bounding box regression loss function, it often considers how to make the bounding box better regression, which is reflected in the development trajectory of the regression loss function.17 –22 However, the above two tasks do not generate a direct connection, so the generation of classification perception regression ideas has aroused widespread attention of researchers. 14
In this paper, CARL-YOLOF is proposed to address the problems as aforementioned, which is inspired by YOLOF 11 and CARL. 14 The main contributions of our study can be concluded into three aspects:
a. The proposed CARL-YOLOF achieves higher detection accuracy compared with YOLOF.
b. We set up a digital printing defect dataset DPFD-DET, which provides research sample for the field of digital printing.
c. Our model is more suitable for the real-time digital printing fabric defect detection compared with other advanced detectors.
The YOLOF baseline
As a representative of the current advanced detectors, YOLOF achieves an effective balance between speed and accuracy compared with other detectors, and its success stems from the objective analysis for feature pyramids networks (FPN) 23 based on a large number of ablation experiments. Therefore, a conclusion can be got that FPN can efficiently improve the accuracy of the detector, which mainly depends on divide-and-conquer strategy instead of multiple level features fusion. In addition, the introduction of FPN will cause the detection speed of the detector to be seriously hindered, because its complex path connection method aggravates the memory access frequency in the forward inference process, not to mention other more complex path connection methods.24 –26 To solve these problems, YOLOF proposed Dilated Encoder with a simple network structure, bridging the accuracy gap between Dilated Encoder and FPN, the structure can be visualized as shown in Figure 2. First, 1 × 1 convolution was applied to channel reduction with rate of 4. Then, 3 × 3 convolution with dilation was used to enlarge the receptive field. In addition, 1 × 1 convolution was adopted to recover the number of channels. At last, shortcut between the input and output was used to explore the model’s perception for large-scale objects, while preserving the original input perception for small-sized objects.

The illustration of the dilated encoder.
CARL-YOLOF
The function of the detector can be summarized as the realization of two specific tasks, classification and regression. However, excellent completion of either one does not directly reflect the accuracy of the detector, the truth can be visualized as shown in Figure 3.

The defect detection results are visualized through two pictures. For picture (a), the black boxes mark the real ink leakage defect, the red boxes correspond to the detection results of the picture, the predict boxes with a confidence score 0.98, 0.97, and 0.96 are judged as True Positive, the other is judged as False Positive. For picture (b), the black box marks the real pulp defect, the red boxes correspond to the detection results of the picture, the predict box with a confidence score 0.99 is judged as True Positive, the other is judged as False Positive.
As shown in Figure 3, the False Positive is reserved by non-maximum suppression (NMS), it significantly affects the performance of the detector. It can be seen that the False Positive’s confidence meets the requirements of positive score threshold, but their boxes obviously does not meet the requirements of positive IoU threshold, so we try to build a loss function that correlated bounding box regression and classification to further improve the accuracy of the detector.
Inspired by YOLOF and CARL, we proposed the CARL-YOLOF, the training pipeline can be visualized as follows:
As shown in Figure 4, the training pipeline of CARL-YOLOF is designed based on YOLOF and CARL Module. For YOLOF, it is composed of three Components: (1) the Backbone, which is selected as ResNet50 for a quantitative study in the paper; (2) the Neck, which consists of four consequent Dilated Encoder; (3) the YOLOF Head, which is formulated according to the number of classes, standard of anchor generator and the number of input channels from Neck. CARL Module establishes the link between classification and regression. Specially, the regression branch gets supervised by the classification loss, the positive anchors with higher predicted probabilities receive large gradients for the regression, which enforces the model to pay more attention to them during the training process. Inspired by YOLOF and CARL, the proposed CARL-YOLOF maintains the streamlined network structure of YOLOF, and the embedded CARL Module strengthened the model’s attention to important samples. Therefore, compared with YOLOF, CARL-YOLOF achieves higher detection accuracy under the premise of not affecting the inference speed.

An illustration of the training pipeline of CARL-YOLOF. The training pipeline can be divided into two parts: (1) the YOLOF; (2) the CARL Module, which can be divided into two processes: the red arrows represent the establish of the loss functions such as Focal loss, CIoU loss, and CARL, the other represents the definition of the positive and negative anchor by Uniform-Match strategy.
CARL module
CARL Module can be visualized as Figure 4, it contains two processes. First, we define the positive and negative anchors according to relation between anchor boxes and ground-truth boxes. Then, we establish loss function to train the model.
For the former, Uniform-Match strategy is used to define positive and negative anchors. Specially, it matches a fixed number of positive anchors for each ground truth box based on the center point distance between the ground truth boxes and the anchor boxes, predicted boxes corresponding to the anchor boxes, which ensure that there are a large number of positive examples in the sparse anchor space.
For the latter, Focal Loss is applied to the classification task to improve the model’s ability for detecting difficult samples. In terms of box regression loss, we introduce CIoU Loss and CARL to construct the connection between classification and regression to improve the performance of the detector. The proposed regression loss function can be donated as follows:
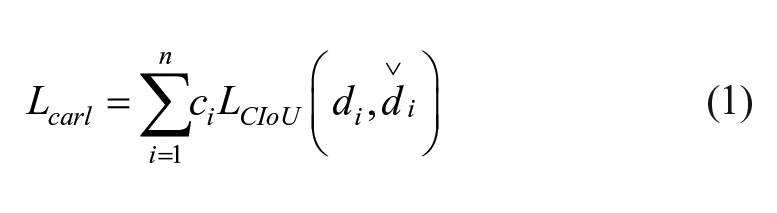

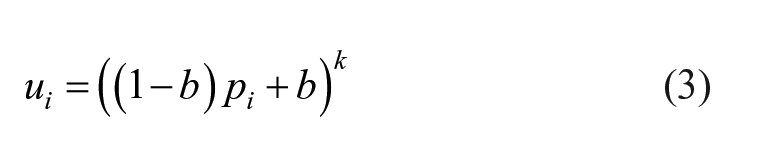
Specially, where degree factor
Obviously, there is a positive correlation between
Experiments and results
Digital printing dataset
In this paper, we set up a comprehensive dataset DPFD-DET for the detection of digital printing defects. To create our dataset, we first collect digital printing defects images containing eight types of defects (PASS track, PASS tracks, ink leakage, blank, ghost, fluff, water leakage, pulp). Next, since high-resolution digital printing fabric defect images aggravate model’s training difficulty, we randomly crop the defect regions into lower resolution including 256 × 256, 384 × 384, 416 × 416, 512 × 512, the cropping operation is showed in Figure 5. Then, we label the collected dataset into eight classes by LabelImg software. Finally, the dataset was divided into training set, validation set and test set in the ratio 8:1:1. The detailed statistics of per class are presented in Table 1.
The detailed statistics of per class of the DPFD-DET.


Examples of collected digital printing fabric defect images. Specially, digital printing fabric defect images (a)−(d) are captured from four different surface regions 1, 2, 3, and 4 respectively in the raw image.
Implementation details and metrics implementation details
The initialization weights of all backbones are transferred from the trained models on the COCO2017 dataset. All other weights are initialized through the “Xavier” paradigm. For the fine-tuning process, we fix the max-epoch as 30, and use SGD as optimizer. For the SGD optimizer, the basic learning rate is set as 0.001, the weight decay is set as 0.0001, and the momenta constant is set as 0.9, batch size is set as 4. All the model trainings are implemented on a deep learning workstation with Intel E5-2680v3 processor(2.5 GHz), 128 GB memory and 1 NVIDIA GeForce 2080 Ti.
Metrics
For our experiments, FPS and COCO metrics (AP,

Where
Overall experiments
We used ResNet50 as the backbone network, and adopted the same configuration to validity our experimental results. The performance of CARL-YOLOF compared with other advanced models is visualized in Table 2. Compared with YOLOF, CARL-YOLOF finishes different degrees of improvement in AP, AP75, APS, APL metrics based on the same inference speed, respectively improved by 0.04, 0.03, 0.03, 0.04. Compared with other models, our model shows the best performance in the comprehensive AP metrics. Besides, our model locates in leading position in AP75 and APL metrics, showing that it can meet more stringent bounding box regression criteria and has excellent ability to detect large-scale defects. However, our model shows the lower performance in the
The performance of CARL-YOF compared with the others on DPFD-DET test set.

In the first two columns, we show the model’s framework and backbone respectively. In the last six columns, we separately show the models’ accuracy in six metrics (AP,
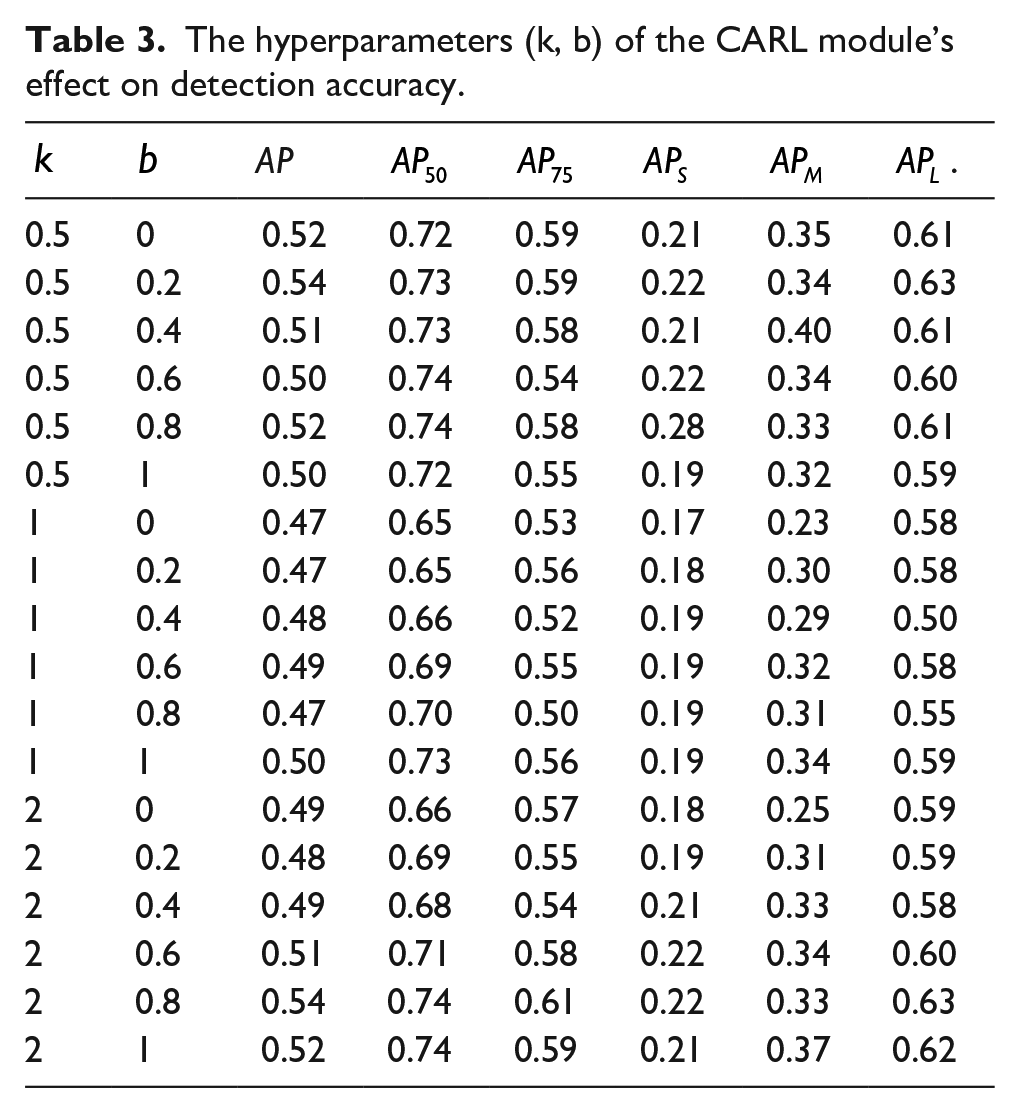
Ablation experiments of hyper-parameters
In order to verify the impact of the hyperparameters (k, b) of the CARL module on the detection accuracy, the degree factor
Through the Table 3, a conclusion can be summarized that object detection task is the unification of the classification task and the bounding box regression task. Specifically, when b is constant, hyperparameter k often dominates the influence of the classification probability on the bounding box regression; when k is constant, the scale hyperparameter b can reflect the proportion of the impact of classification probability on the bounding box regression, so the detector accuracy improves with respect to a good selection of the constant b. A large number of ablation experiments have been verified, hyperparameter setting (k = 2, b = 0.8) in CARL make our model achieve the best detection accuracy. Compared with YOLOF (k = 1, b = 1), the AP metrics improved by 0.04. Figure 6 shows detection examples on DPFD-DET test set with CARL-YOLOF model.
The hyperparameters (k, b) of the CARL module’s effect on detection accuracy.

Detection examples on DPFD-DET test set with CARL-YOLOF model. We show detections with scores higher than 0.5.
Conclusion
In this paper, we propose CARL-YOLOF model for digital printing fabric defect detection. The proposed model efficiently balances the detection accuracy and speed to a certain extent, which has theoretical reference value for the solution that digital printing fabric defects are difficult to detect.
Classification-aware regression strategy can effectively strengthen the link between classification task and regression task in YOLOF model. Experimental results show that CARL-YOLOF with ResNet50 backbone network achieves different levels of improvement in
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (61902302) ,The key research and development program funded by Shaanxi province (2019ZDLGY01-08),The key research and development program funded by Shaanxi province (2021GY-311), the Shaanxi Provincial College of Science and Technology Youth Talent Support Project (20200115), Xi’an Science and Technology Plan Project (21XJZZ0011), Innovation Capability Support Program of Shaanxi (2021TD-29).