
Abstract
The autonomous and efficient learning of sewing gestures by robots will bring great convenience to the garment industry. To improve the accuracy of robots in detecting sewing gestures with high similarity, three detection models based on deep learning are proposed in the paper. First, in order to improve the detection accuracy and detection speed of sewing gestures under complex backgrounds, we added a dense connection layer to the low-resolution network layer of YOLO-V3 to enhance the transmission and reuse rate of image features. Secondly, a deeper ResNet50 residual network is introduced to replace the VGG16 basic network in the original SSD model. The feature pyramid structure is used to fuse high-level semantic features and low-level semantic features, which can improve the detection accuracy of small-sized sewing gestures. Finally, the parallel spatial-temporal dual-stream network separately extracts the temporal feature and the spatial feature of sewing gestures. The fusion of time feature and space feature improves the detection accuracy of the coherent sewing gesture. The results show that the suggested three models can effectively detect four sewing gestures with high similarity. Among them, the spatial-temporal two-stream convolutional neural network has the highest detection accuracy. The improved SSD model has faster detection speed than the improved YOLO-V3 model and other mainstream algorithms.
Introduction
In the textile field, the fabric of the garments is soft and extensible, which makes the sewing process difficult. Many factors such as the human body and the environment need to be considered during the sewing process. 1 Cooperating with robot technology and skilled worker technology can achieve better sewing performance. 2 Collaborative robots accurate and rapid understanding of workers’ sewing skills is the key to human-machine collaboration. 3
Scholars have done a lot of research on how to solve the problem of robots’ learning of sewing skills. Takashi 4 applied the variable gain learning control method to automatic sewing trajectory tracking of the robot arm. Panagiotis 5 used fuzzy logic to define the expected environmental feedback, designed a hierarchical control system, and realized the robot’s adaptive sewing function to unknown sewing materials. Paraskevi 6 combined visual servo networks and neural networks to design an adaptive reasoning learning system for curved fabric sewing robots. Huang et al. 7 divided the worker’s sewing actions into segments, each segment was modeled by the GMM model, and GMR was used to obtain the entire sewing action to complete the learning of human sewing actions. The above methods can solve the perturbation of robot parameters and the uncertainty of the contact stiffness of the external working environment to a certain extent.
The sewing action recognition method based on computer vision 8 detects various action categories by extracting detailed feature information in the sewing action. At this stage, human action recognition methods mainly include image samples based on a single keyframe and video samples. 9 The image recognition method based on a single keyframe is fast and easy to implement. It can well detect some actions with representative keyframes. The recognition method based on video samples obtains the information of the action space and time dimension very well. This method is more flexible and scalable. It has a good recognition effect for complex and coherent actions. Generally, characteristics of the action-image are obtained by the method based on artificial design features 10 and the method based on deep learning features. 11 Yilmaz and Shah 12 extracted the specific information of the action according to the change of the space-time volume of the moving target in the time series, which has good robustness against changes in the viewing angle. Gorelick et al. 13 incorporated the structural positional relationship in the time and space of the action into the characteristics. Jiang et al. 14 used the information of key points to construct action descriptors and clustered key points and analyzed actions by establishing judgment rules through Euclidean distance. Dollar et al. 15 found that it was difficult to achieve good results when there are obstacles in the overall thinking methods. Matikainen et al. 16 found that the description of the outline of the action alone cannot well represent the texture features in the middle of the outline. Therefore, the representation method of local features is more important. Liu et al. 17 used spatial-temporal interest point detection methods (STIPs) for target detection, which provides new ideas for local representation methods. Matikainen et al. 16 used the trajectory of the moving target to extract local features and trajectory direction information to represent the local descriptive factor. Jiang et al. 18 and Wang and Schmid 19 optimized and adjusted the motion trajectory captured by the vision sensor, which improved the method of directly using the trajectory speed. The above-mentioned artificial feature design method can only perform well in simple action recognition scenarios.
With the continuous development of deep learning in the field of gesture recognition, Asadi-Aghbolaghi et al. 20 investigated the current methods of gesture recognition in image sequences based on deep learning. The detection algorithm based on deep learning extracts a variety of detailed features of actions from single-keyframe image samples and video samples. Various sewing action categories are detected by describing the posture of the movement feature information. Gesture detection methods based on a single keyframe include region-based target detection network and regression-based target network. 21 The former representative networks include Faster R-CNN, 22 Mask R-CNN, 23 etc. This type of network has higher detection accuracy but a slower detection speed. Another type of regression-based target detection network includes YOLO,24,25 SSD, 26 etc. Narayana et al. 27 concentrated the spatial channel on the hand and used a sparse network for fusion, which improved the accuracy of gestures recognition. The regression-based target detection network uses end-to-end detection, which has a faster detection speed. The image detection method based on a single keyframe has low accuracy and speed in recognizing sewing gestures in complex scenes. The method based on video samples can effectively use context information, which has high utilization, flexibility, and scalability. Zhang et al. 28 used multi-scale feature fusion and pyramid spatial pooling to detect salient target regions of different sizes in the video. Ji et al. 29 improved the formation of three-dimensional CNN based on two-dimensional CNN. This method inputs the spatial information map of the decomposed video action sequence into the spatial stream convolutional network for iterative training. Wang et al. 30 proposed a 3D-CNN combined with an LSTM network model to detect the saliency of behavioral targets, which reduces the model parameters and the difficulty of training. Wu et al. 31 used dual-stream CNN and Long Short-Term Memory to model the spatial and temporal information relationship between video frames. The semantic description of the video generated by the model realizes the classification and labeling of actions, which is significantly improved in public data sets. Simonyan and Zisserman 32 divided the video samples into spatial frames, and the divided spatial frames were sequentially sent to the convolutional neural network for iterative training. In the dual-stream convolutional neural network, the spatial stream CNN network is used to extract the position features of the limbs in the static picture; the time-stream convolutional neural network is used to extract the movement information of the limb trajectory in a series of time series. The fusion of temporal and spatial features greatly improves the accuracy of gestures recognition.
Four sewing gestures of inner overlock seam, hemmed seam, cladding seam, and cut fabric are very similar. Due to the complex environment of the sewing workshop, the robots cannot accurately and quickly understand and recognize the sewing movements of the workers’ hands. Therefore accurately identifying similar sewing gestures in complex backgrounds is the focus of this article.
The rest of the paper is organized as follows: In section 2, the improved YOLO-V3 convolutional neural model is used to detect sewing gestures with complex backgrounds. In section 3, the improved SSD method is used to solve the problem of low accuracy of YOLO for small target sewing gesture detection. In Section 4, the spatial-temporal dual-stream convolutional neural network method is used to solve the problem of poor detection of sewing gestures with high similarity of sewing gestures and strong continuity of motion in independent single-frame images. Section 5 shows the experimental results. Conclusions and future research work are in Section 6.
Sewing gesture recognition based on improved model of YOLO-V3 (You Only Look Once)
YOLO-V3 improved model
The YOLO-V3 target detection network converts some detection problems into regression problems. The network uses the DarkNet53 network as a basic network to extract features. The network divides each picture into multiple grids. Each grid predicts a target bounding box, a confidence score, and a category conditional probability. In the detection process, the grid that falls into the center of a sewing gesture is used to identify the sewing gesture target. When multiple bounding boxes detect the same target at the same time, the non-maximum suppression (NMS) method is used to select the best bounding box. The accuracy of a predicted bounding box is reflected by the size of confidence. The YOLO-V3 network model detection process is shown in Figure 1.

The detection process of YOLOV3 network.
Due to the limitations of the Darknet53 network, simply increasing the network level will cause the gradient to disappear and explore, which leads to low accuracy in detecting sewing gestures with complex backgrounds. The paper adds DenseNet densely connected network to the lower resolution transmission layer of the original YOLO-V3 network, which can enhance the transmission of sewing gesture feature information and promote feature reuse and integration. Each layer in the dense connection of DenseNet can directly access the gradient from the loss function and the original input signal, which greatly solves the problem of gradient disappearance when the number of network layers is too deep. The transfer function in the form of BN-ReLU-Conv (1 × 1) + BN-ReLU-Conv (3 × 3) is used in paper. The 1 × 1 convolution kernel in the transfer function prevents the input feature map from being too large.
The improved YOLO-V3 network model is shown in Figure 2.
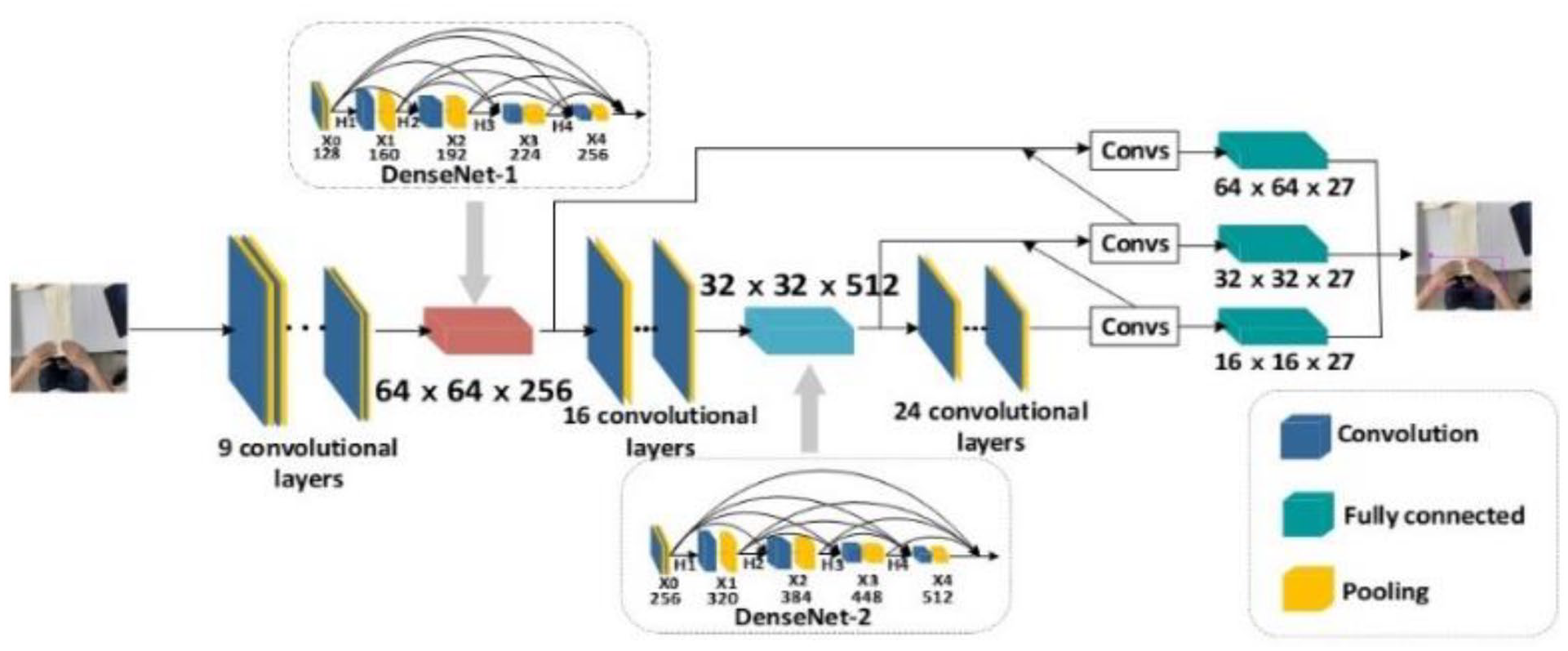
Improved network model of YOLO-V3.
DenseNet-1 and DenseNet-2 composed of four dense layers replace the original 10th layer (the resolution of this layer is 64 × 64) and the 27th layer (the resolution of this layer is 32 × 32) respectively. In the dense structure, the input
YOLO-V3 improved model training parameter settings
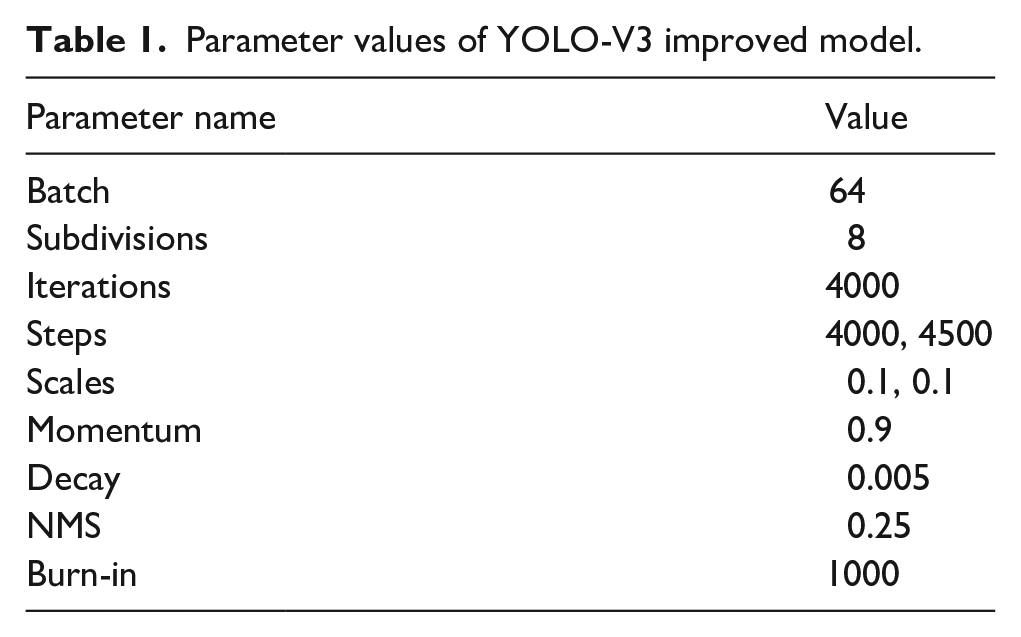
The training of the YOLO-V3 improved model uses the official website pre-training weight file to initialize the network weight parameters, which can speed up the model convergence. Specific training parameter values are shown in Table 1.
Parameter values of YOLO-V3 improved model.
The stochastic gradient descent (SGD) network is used to optimize the network model. The learning rate is adjusted according to the number of iterations. The initial learning rate is 0.001. When the model is iterated to 8000 times and 9000 times, the learning rate decays by 10 times. We set burn-in to 1000 at the beginning of training. When the number of updates is less than 1000, the learning rate strategy changes from small to large. When the number of updates is greater than 1000, the learning rate adopts an update strategy from large to small.
In the bounding boxes of all tested sample data sets, we use the K-means cluster analysis method to find 9 a priori box dimensions suitable for the sample data. The K-means distance measurement formula is shown in formula (1).

Nine sets of prior frame dimensions are used in the training process: (121, 82), (163, 98), (158, 154), (205, 119), (239, 150), (203, 218), (302, 179), (316, 253), (324, 351). Arranging the size of the prior frame from small to large, and it is evenly divided into three feature maps of different scales. Feature maps with larger scales use smaller prior boxes. Finally, these prior boxes are used to detect sewing gestures.
Training of YOLO-V3 improved model
The improved YOLO-V3 model uses 4000 sewing gesture images. The model is trained 5000 times. The dynamic process of training is observed by drawing the loss curve. The corresponding loss value change curve is shown in Figure 3.

The loss curve of the improved YOLO-V3 model.
It can be seen from the curve in Figure 3: the loss value of the model decreases rapidly in the previous iterations, which means that the model fits quickly; when iterative training is 2000 times, the loss value of the model slows down; when the iteration reaches 5000 times, the loss value converges to 0.0025.
The detection performance of the model is further evaluated by calculating the Avg IOU between the predicted bounding box and the true bounding box. The change curve of the Intersection-over-Union is shown in Figure 4.

Change curve of YOLO-V3 improved model Intersection-over-Union.
As the number of model iterations increases, the Intersection-over-Union of the real frame and the predicted frame is constantly improving. When the number of iterations is 5000, the model Intersection-over-Union tends to 0.9.
Determination of optimal threshold of YOLO-V3 improved model
We select the best prediction model from trained models. By calculating the accuracy rate, recall rate, F1 value, and average Intersection-over-Union under different confidence thresholds, the best threshold model is screened out. The result is shown in Figure 5.
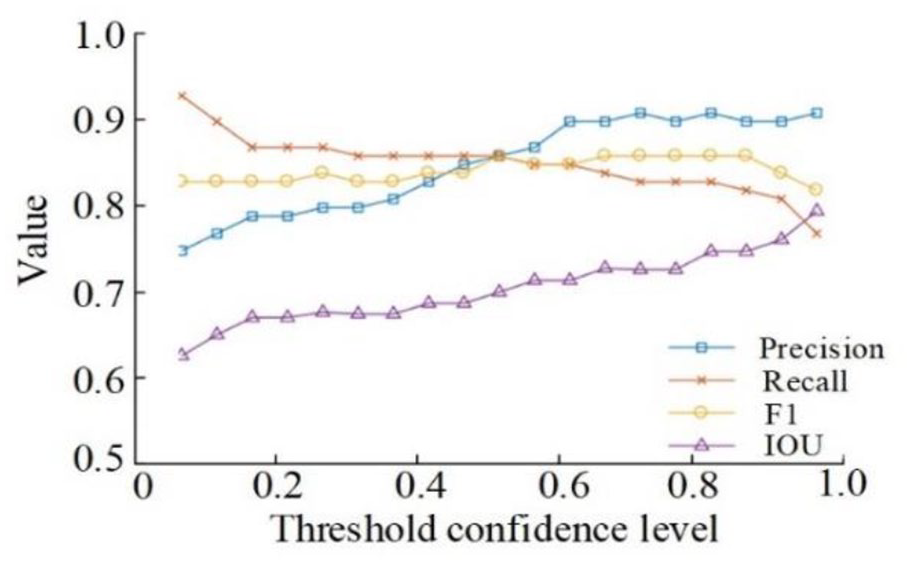
Confidence threshold.
In the threshold interval of (0, 1), the value is calculated once every span of 0.05, and a total of 20 sets of data are calculated. We set the following rules on the priority: accuracy rate > recall rate > IOU. After the threshold reaches 0.6, the accuracy rate gradually stabilizes, and the optimal range is about 0.6–1.0. In this range, the best recall rate is 0.85, the corresponding confidence threshold is 0.6, and the IOU value is about 0.71. Therefore, we choose 0.6 as the optimal threshold.
After selecting the best model, we use the accuracy rate as the vertical axis and recall rate as a horizontal axis to obtain the P-R curve of the best model, as shown in Figure 6.

P-R curve of YOLO-V3 improved model.
By observing the P-R curve, it can be seen that the value of recall rate measured at balance point is equal to the value of accuracy rate at about 0.85.
The improved YOLO-V3 model has a better detection effect on large-size sewing gestures, but the accuracy will decrease when recognizing smaller sewing gestures. The reason is that the single convolutional network in YOLO-V3 easily ignores low-level feature information. The high-level features can only provide a small part of the feature information about a small target to the model, which is not good for sewing gesture recognition with a small size.
Sewing gesture recognition based on improved SSD (Single Shot Multi-Box Detector) model
SSD improved model
The SSD network uses multi-scale target features for target detection, which can improve the robustness of targets of different scales. Compared with the YOLO-V3 network, the SSD network has a higher recognition rate for small-sized targets. The number of deep network layers can reduce the constraints of gradient instability problems such as gradient disappearance and gradient explosion. The SSD model based on VGG16 only deepens the network depth, which leads to the aggravation of network degradation.
We introduce deep residual network (ResNet) and feature pyramid structure (FPN) into the basic SSD model. The deep residual network (ResNet) improves the multiplicative transfer between feature layers to additive transfer, which can enhance the connection between the front and back network layers. While ResNet effectively avoids gradient instability, it does not increase the parameters and complexity of the model. The calculation formula of the deep residual network (ResNet) is shown in formula (2).

In formula (2),
The feature pyramid structure is used to realize the fusion of high-level and low-level feature information (the feature pyramid structure is shown in Figure 7). The down-sampling part calculates the feature level composed of multiple scale feature maps, and the deepest layer has the strongest feature information. The up-sampling part extracts higher-resolution features, and up-sampled features are enhanced by down-sampled features through the horizontal connection. Each horizontal connection part realizes the fusion of feature information of different sizes in high and low layers, which strengthens the detection ability of small-size sewing gestures.

The structure of the FPN model.
The input image of the SSD improved model is a 512 × 512 RGB image. Its backbone superimposes five convolution modules based on ResNet50 to form a deep network. The structure of the improved model of SSD is shown in Figure 8.
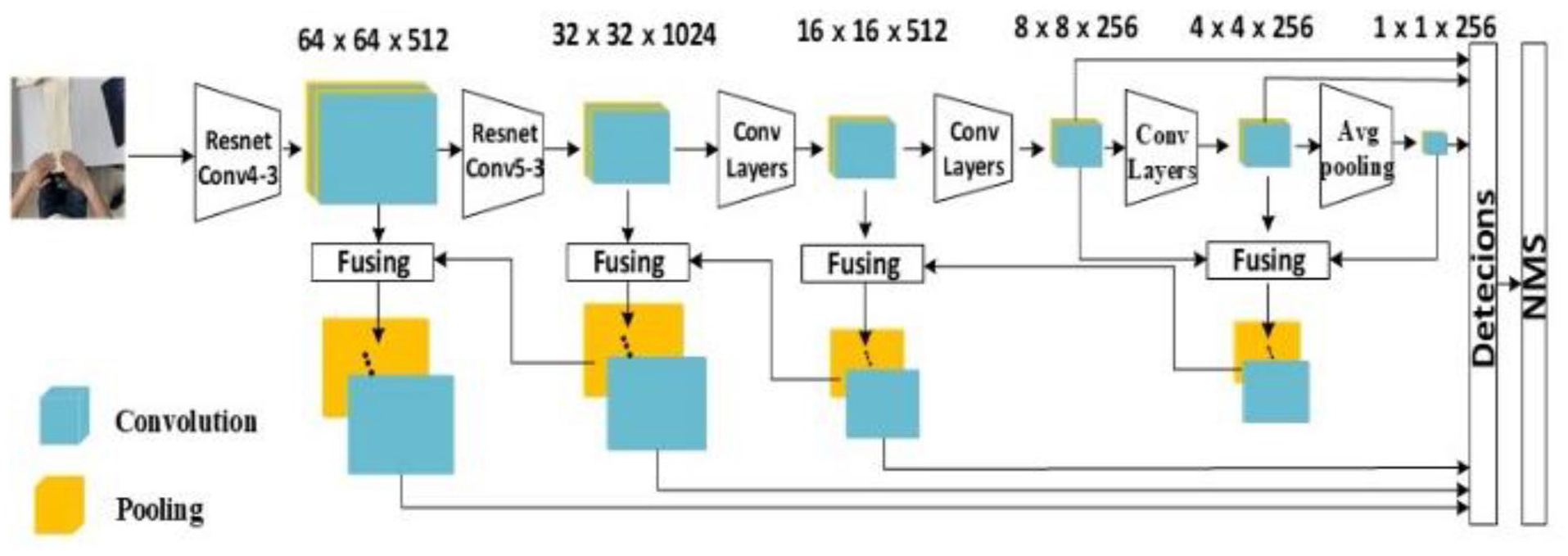
The structure diagram of SSD improved model.
The network of the SSD improved model contains 59 convolutional layers and five maximum pooling layers. The shallow and middle layers of the model extract feature information of sewing gestures, which are used to detect small-sized sewing gesture targets. The deep network extracts the sewing gesture features that contain the full image, and these features are used to detect large-sized sewing gesture targets. SSD network draws feature maps from Conv4, Conv5, three additional convolutional layers, and one pooling layer respectively. Each feature map will generate a priori frames of multiple scales, and generate prediction frames of multiple scales based on different frame ratios to judge sewing gestures of different scales to achieve multi-scale target position and category prediction. The detection result is produced by non-maximum suppression.
Parameter setting of SSD improved model
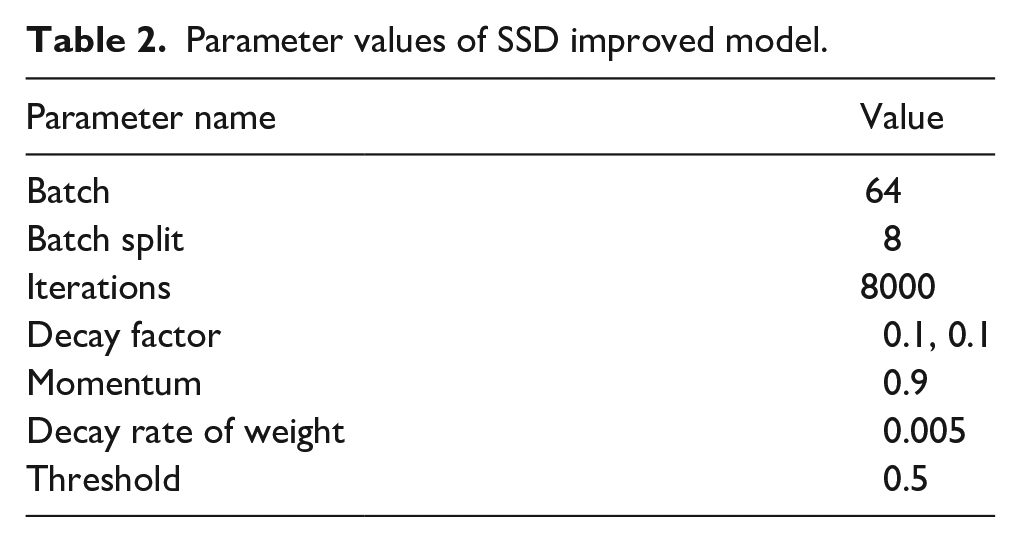
The SSD improved model uses a self-built sewing gesture data set to train the model. In the training process, 64 samples are used as the number of samples in a batch, and parameters are updated once for each batch of samples. The number of samples in each batch is divided eight times, and the divided samples are sent to the trainer. The learning rate adopts a dynamic adjustment strategy, and the initial learning rate is set to 0.001. The real frame and default frame matching strategy adopt the maximum Intersection-over-Union strategy. If the Intersection-over-Union is greater than the threshold value of 0.5, matching is performed. The parameter settings are shown in Table 2.
Parameter values of SSD improved model.
We use the idea of transfer learning to apply the feature extraction capabilities learned by the network on the largest dataset ImageNet to small sample data and fine-tune it to further improve the detection effect of sewing gestures. The training is based on the ImageNet super-large image data set and the trained ResNet50 classification network model. The fully connected layer after the classification network is removed, and the convolution detection module is added to form the target detection network. We migrate the convolution model and parameters in the ResNet50 network, and we freeze the parameters of each layer in the middle of the model. Finally, a deep migration training model based on ResNet50 can be obtained for training and fine-tuning parameters for model category prediction and position regression.
Training of SSD improved model
The SSD improved model optimizes the loss function during training. Regression training is carried out through the location and target category, and the back-propagation mechanism is used to continuously update the model so that the Loss value is continuously reduced. We observe the dynamic training process of the model by drawing the loss function curve. The model loss function curve is shown in Figure 9. The loss function in the model is defined as shown in formula (3).


Loss value curve of SSD improved model.
Formula (3),
It can be seen from Figure 9 that the loss value of the improved SSD model during the pre-training period drops rapidly, and the model fits quickly. After 3000 iterations of training, the model loss decreases slowly. In order to prevent over-fitting, early-stopping is used in training, and the training is automatically ended when the loss value does not decrease for four consecutive epochs.
Both the SSD improved model and YOLO-V3 improved model only use spatial dimension information of a single frame to detect sewing gestures. These methods lack time-series information between adjacent frame sequences, which have great limitations for the recognition of sewing actions.
Sewing gesture recognition based on spatial-temporal dual-stream convolutional neural network
Model of spatial-temporal dual-stream convolutional neural network
The time flow information of sewing gestures is a powerful feature to distinguish similar gestures. Therefore, we use the spatial stream CNN network and time stream CNN network to extract the spatial and temporal features of sewing gestures to improve the effect of gesture recognition. The spatial flow network and time flow network are used to extract the features of the spatial position and temporal motion of sewing gestures respectively. Then, the spatial location characteristics and temporal motion characteristics that reflect sewing gestures are merged. The structure diagram of the dual-stream network model is shown in Figure 10.
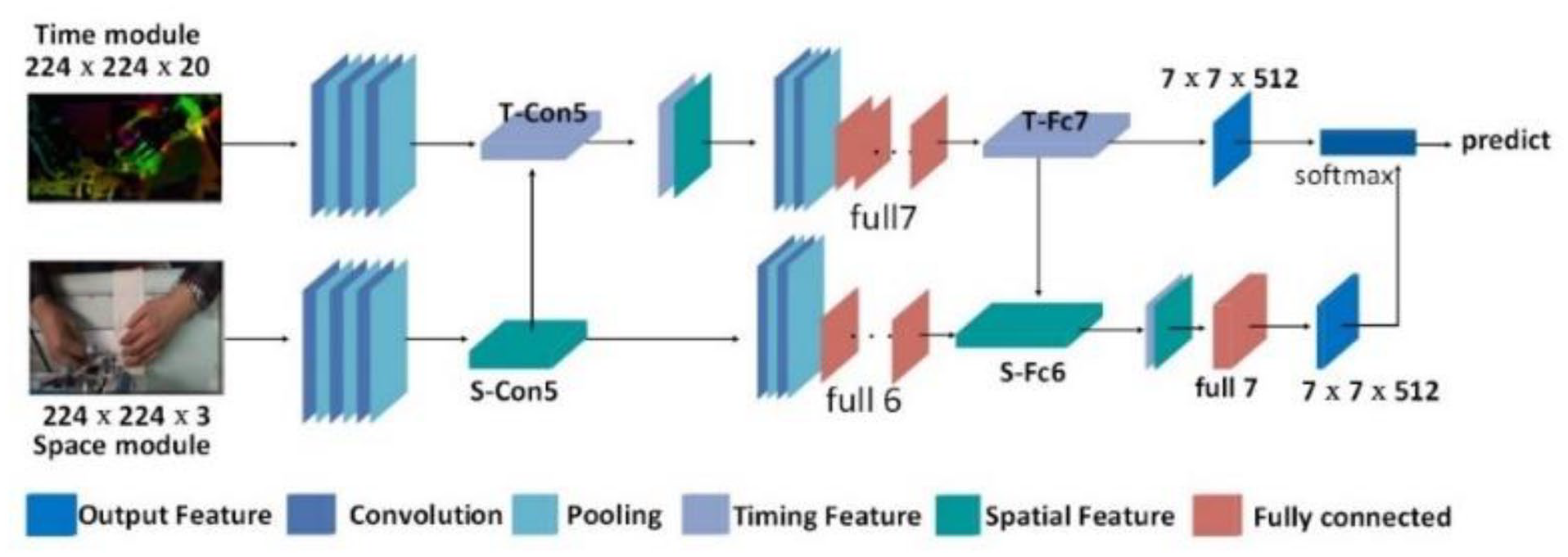
The structure diagram of the spatial-temporal dual-stream convolutional neural network model.
The backbone of the spatial flow network model adopts the VGG model. The model takes a continuous RGB image of 224 × 224× × 3 as input, and the output is the probability distribution of different sewing gesture categories. The dual-stream network is composed of 13 convolutional layers and three fully connected layers. The convolution kernel has a size of 3 × 3 and a step size of 1 × 1, which is stacked into five blocks. The maximum pooling layer has a kernel size of 2 × 2 and a step size of 2, which is connected after the convolutional layer. A fully connected layer maps the sewing gesture feature to the feature vector. Finally, the Softmax classifier is used to output the probability distribution of different sewing gesture categories through four neurons.
The parameters of the temporal flow network model are consistent with the spatial flow convolutional neural network, and the size of the input optical flow graph is 224 × 224 × 2L. To make better use of the motion timing characteristics in optical flow, we superimpose multiple optical flow diagrams, and the optical flow superimposed diagrams are sent to the time flow network model. The optical flow overlay is the “instantaneous velocity” of the pixels of the moving target in the continuous video frame in space. It can clearly and effectively characterize human body motion information, which greatly improves the performance of the dual-stream model. The dense optical flow method is used for the calculation of the optical flow diagram. After inter-frame segmentation is performed on sewing video samples, a set of dense optical flow vector fields between adjacent video frames t and t + 1 is calculated. The two-bit gray-scale optical flow diagram of the previous time is generated by tracking the frame at the next time, and it is decomposed into horizontal and vertical components. A single optical flow graph is compressed to form multiple optical flow groups which are input to time flow convolutional neural network for training. Equation (4) calculates the horizontal component.
Equation (5) calculates the vertical component.



In formulas (4) and (5):
Which layer merges the features extracted by temporal flow network and space flow network is a problem that we need to consider. In the following text, the fusion layer with the highest detection accuracy is taken as the best fusion position.
Parameter setting of spatial-temporal dual-stream network
The dual-stream network initializes the parameters by loading the pre-training weight file, which makes the network parameters in a better position to improve training speed. Some parameters in the training process are set according to experience, and the parameter values are shown in Table 3.
Parameter values of spatial-temporal dual-stream convolutional neural network.

During training, the number of samples is 96 as a batch of samples, and the parameters are updated once for each batch of samples. Continuous 10 frames of RGB video frames are used as the input of spatial stream to achieve a balance between the computational complexity and amount of data information. The size of the input space map is 224 × 224 × 3. The input of the time flow network is the superposition of horizontal and vertical optical flow graphs, and the size of the superposed optical flow graph is 224 × 224 × 2L. According to previous experience, the effect of superimposing the optical flow diagram with L = 10 in the time domain is the best.
The small-batch stochastic gradient descent method is used to optimize the dual-stream network model. The initial learning rate is 0.001, which is reduced according to a fixed schedule. Changing the learning rate to
Training of spatial-temporal dual-stream network model
The training of the dual-stream network model uses 4000 images for a total of 12,000 training times. During the training process, we draw the loss value change curve and detection accuracy value change curve of the dual-stream network model to observe dynamic the training process. The loss value change curve is shown in Figure 11. The change curve of detection accuracy value is shown in Figure 12.

The loss value change curve of the spatial-temporal dual-stream network.
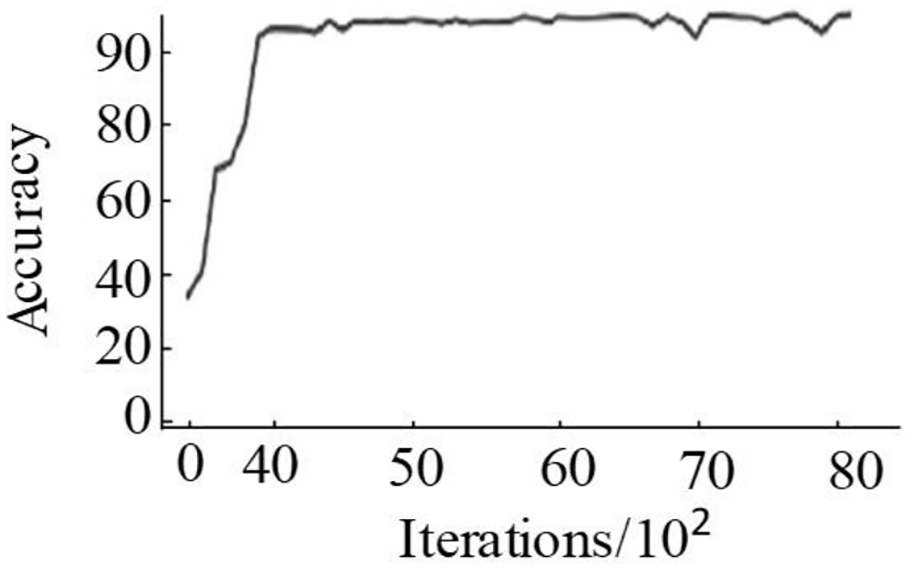
Change curve of recognition accuracy of sewing gestures by spatial-temporal dual-stream network.
It can be seen from the loss value change curve that the loss value of the parallel spatiotemporal dual-stream convolutional neural network model is rapidly reduced in the previous iteration, and the model is quickly fitted. After iterative training 4000 times, the downward trend of model loss is slowing down. After about 8000 iterations, the model converged to 0.3. It can be seen from Figure 12 that the accuracy rate increases as the number of iterations increases. When iterated 3500 times, the detection accuracy rate increased rapidly. After 4000 iterations, the detection accuracy rate remains at 92.6%.
Experiment
Processing of experimental data sets
Collection of sewing gesture data set
The sewing gesture dataset samples mainly come from the sewing workshop. The data set contains more than 1000 sewing gesture motion videos, which include four sewing gestures with a high similarity: inner overlock seam, hemming seam, cladding seam, and cut fabric (as shown in Figure 13). It also includes action videos of gestures at different periods.

Sewing gesture data set: (a) the first line of sewing gesture is for cutting fabric, (b) the second line of sewing gesture is for cladding seam, (c) the third line of sewing gesture is for hemming seam, and (d) the fourth line of sewing gesture is for inner overlock sewing.
In the experiment, we frame 1000 self-built video samples at a frequency of

Time sequence optical flow diagram: (a) inner overlock seam, (b) cladding seam, (c) cutting fabric, and (d) hemming seam.
Enhancement of data set
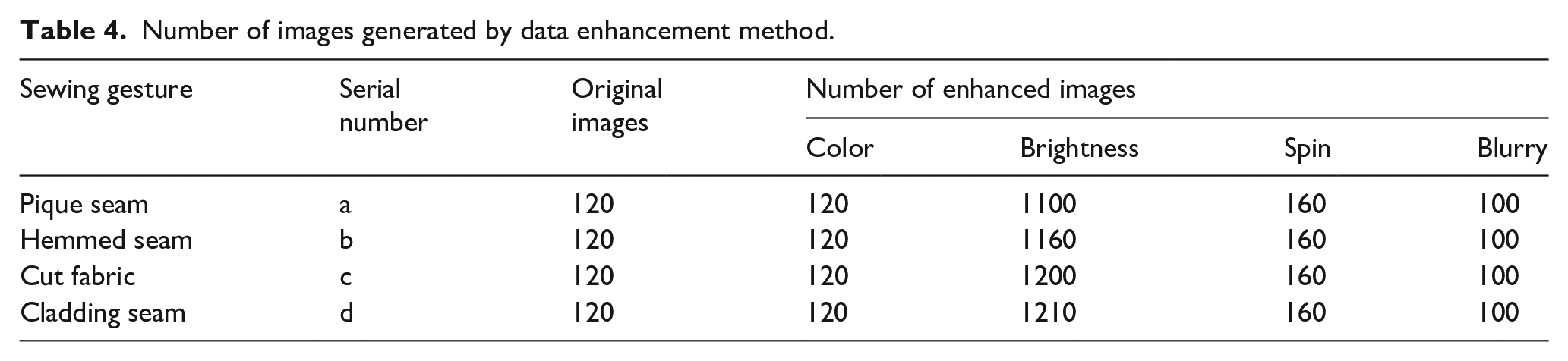
To improve the quality and richness of the experimental data set, we use traditional image enhancement methods to process the color, brightness, and direction of the segmented image. The 6670 video frames of sewing gestures in data set 1 are enhanced, and pictures of the same category are added to data samples of the same category. The time-series optical flow diagram in data set 2 is randomly flipped and cut into the time flow network model of the dual-stream network. The number of enhancements in the data set is shown in Table 4. The enhanced picture is shown in Figure 15.
Color correction: Under different lighting conditions, there is a certain deviation between the color of the collected image and true color. The gray world algorithm is used to eliminate the influence of light on the color rendering, and the processed pictures are added to the train data set.
Image brightness: During 24 h production in a workshop, the impact of different light intensities on the image can be simulated through image brightness conversion. Too much change in brightness value affects the accuracy of manually labeling the bounding box, which inhibits the performance of the model. The range of brightness change should be controlled within 0.6–1.5 times. Therefore, the range of 0.9–1.1 times is used to randomly generate multiple images for training.
Image rotation: To enhance the robustness of the training model to different imaging angles, we randomly rotate the original images in dataset 1 and dataset 2 by 90°, 180°, 270°. Add 160 transformed images to train the image set.
Image blur: Blurring issues such as camera focus and movement can affect the detection results. In the paper, we enhance the model’s ability to detect blurred images by changing the color, brightness, and rotation of the image.
Number of images generated by data enhancement method.

The sewing gesture data sample after image enhancement: (a) cutting fabric, (b) cladding seam, (c) hemming seam, and (d) inner overlock seam.
Experimental results
YOLO-V3 improved model’s detection results of sewing gestures
To verify the performance of the improved YOLO-V3 model, we compare the proposed model with R-CNN, YOLO-V2, and the original YOLO-V3 on the collected sewing gesture dataset. The results are shown in Table 5. The detection result is shown in Figure 16.
R-CNN, YOLO-V2, original YOLO-V3, and YOLO-V3 improved network for the detection results of sewing gestures.


The actual detection effect of different networks on four sewing gestures.
Table 5 shows that the improved YOLO-V3 model has a higher accuracy value than the other three networks. Since the improved YOLO-V3 model has a higher image feature reuse rate than the original YOLO-V3 model. The average accuracy is increased by 2.29% compared with the original YOLO-V3. In terms of detection speed, the improved model has a speed of 43.0 frames/s, which is much higher than R-CNN, and the detection speed is the same as that of YOLO-V2 and YOLO-V3. The model checking effect is shown in Figure 16. It can be seen from the actual detection results that the improved YOLO-V3 model can accurately detect four different sewing gestures compared to the other three models. The improved YOLO-V3 network is more accurate in frame overlap.
The detection results of improved SSD model on sewing gestures
To test the recognition effect of the improved SSD model on sewing gestures, we compare it with Faster R-CNN, original SSD-VGG16, and SSD-Resnet50 networks. The detection results of the sewing gestures by Faster R-CNN, YOLO, original SSD, and SSD improved network are shown in Table 6. The detection result is shown in Figure 17.
Detection results of sewing gestures by Faster R-CNN, YOLO, original SSD, and SSD improved algorithm.


Recognition effect diagram of sewing gestures by different networks: (a) inner overlock seam, (b) hemming seam, (c) cutting fabrics, and (d) cladding seam.
Through the comparison of detection speed and accuracy results: In terms of detection speed, the improved SSD model and YOLO and SSD model are 46, 47, 51 frames/
The detection results of sewing gestures by different fusion layers in spatial-temporal dual-stream convolutional neural network
To analyze the influence of different fusion positions in the spatial-temporal dual-stream convolutional neural network on the detection effect of sewing gestures, we combine the spatial features of sewing gestures and temporal features represented by dense optical flow graphs in convolutional layer and fully connected layer, respectively. We train on the public data sets UCF101 and HMDB51, and test on the self-built sewing gesture data set. The accuracy of the spatial-temporal dual-stream network is used to measure the recognition effect of complex and coherent sewing gestures. Table 7 shows the recognition results of sewing gestures in different feature layers of the spatial-temporal dual-stream network.
Recognition accuracy values of different fusion positions (%).

It can be found from Table 7 that the recognition accuracy is closely related to the location of fusion. With the deeper the fusion location layer, the model can obtain higher semantic information, and the recognition accuracy has a certain improvement. By comparing in the fusion effect of the fully connected layer and convolutional layer, it is found that the dual-stream network can capture more efficient high-level semantic expressions when the fully connected layer is fused so that the recognition accuracy is increased by at least 3.3%. When fusing the space network layer fc7 layer and time network layer fc6 layer, the recognition accuracy rate drops by 0.8%. The reason for the decrease is that the deeper feature fusion cannot closely link the optical flow information with spatial information at the same time. The fusion model of the sixth fully connected layer of space and the seventh fully connected layer of time flow network can closely connect the spatial position information and temporal motion information of sewing gesture.
This layer fusion has very good detection results for sewing gestures and has the best performance on three data sets.
Comparison of detection accuracy of sewing gestures by YOLO-V3 improved network, SSD improved network, and dual-stream convolutional neural network
To verify the recognition effect of the three improved models proposed in the paper on sewing gestures, we use the improved YOLO-V3 detection method and the improved SSD detection network to train the model of video frame pictures with sewing gestures. On the other hand, a dual-stream network detection method is used to train the sewing gesture data set. The detection results of the three detection networks for sewing gestures are shown in Table 8.
Comparison of detection results of sewing gestures by YOLO-V3 improved algorithm, SSD improved algorithm, and dual-stream network algorithm.

It can be seen from Table 8 that the recognition accuracy of the dual-stream network method is better than that of the improved YOLO-V3 model and the improved SSD model, which are increased by 4.08% and 3.81%, respectively. Due to the preprocessing of the time series light flow chart with a large amount of data, the detection speed is slower than the YOLO-V3 improved model and the SSD improved model. The SSD improved model has the fastest detection speed among the three networks. It can be seen that the calculation of optical flow information and fusion of spatial-temporal features have a good reading of action semantics in the time dimension, which improves recognition accuracy. In practical applications, when there is no special requirement for recognition speed, the dual-stream convolutional neural network is the best choice for recognizing sewing gestures. When there is a higher requirement for speed, the improved SSD network has better performance.
Recognition results of sewing gestures by TDD, C3D, TWO-Stream, P-CNN, and three improved models
To further compare the advantages of the model proposed in the paper, we compare the dual-stream network model, the YOLO-V3 improved model, the SSD improved model, and five mainstream models. Five mainstream networks include IDT behavior detection methods that perform best in traditional methods, deep learning-based Time Division Duplexing (TDD), Convolutional 3D (C3D), Two-Stream, and Pose Convolutional Neural Network (P-CNN) methods. The test is carried out on the self-built data set, in which the ratio of the training set to the test set is 8:2. The final results are shown in Table 9.
Comparison of detection results of TDD, C3D, IDT, Two-stream, P-CNN, YOLO-V3 improved model, SSD improved model, and dual-stream network model.
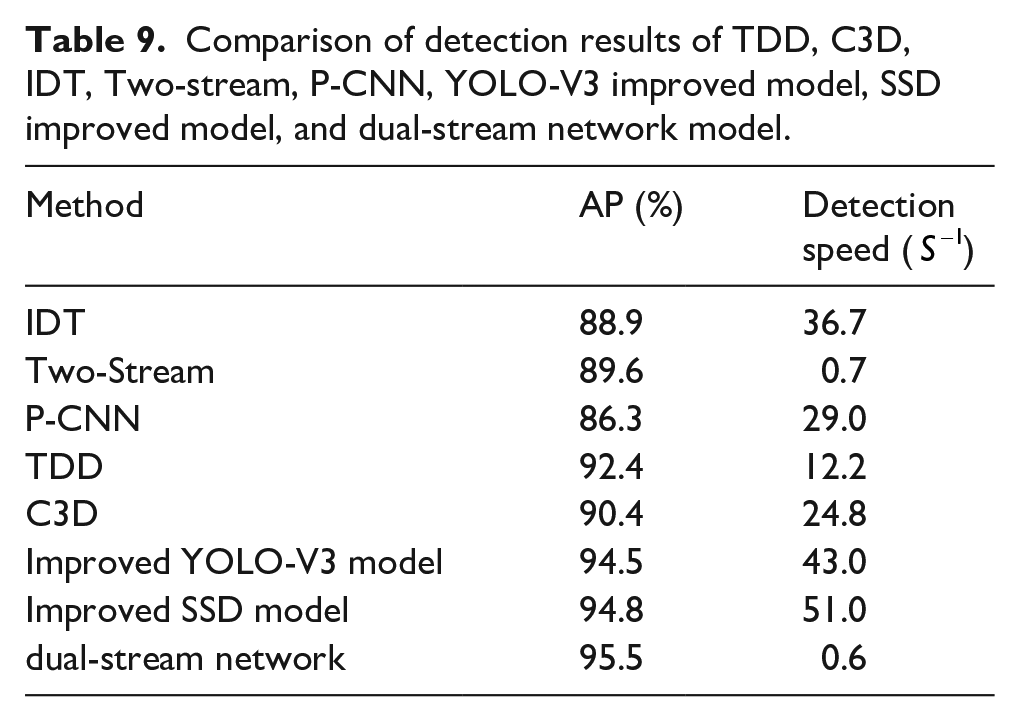
From the results in Table 9, the method based on the deep neural network method can learn the semantic expression of high-level sewing gestures more easily, and the effect is better than the traditional IDT method. The dual-stream network can effectively use time dimension information, and it has better detection accuracy than other detection models. Compared with P-CNN, C3D, and TDD methods, the improved method of YOLO-V3 has improved detection accuracy by 8.2%, 4.1%, and 2.1%, respectively. Compared with IDT, Two-Stream, P-CNN, TDD, and C3D methods, the improved SSD network has improved detection accuracy by 5.9%, 5.2%, 8.5%, 2.4%, and 4.4%, respectively. Compared with the original dual-stream, P-CNN, C3D, and TDD methods, the spatiotemporal dual-stream network has improved recognition accuracy by 5.9%, 9.2%, 5.1%, and 3.1%, respectively. The improved SSD model has the fastest detection speed at 51 frames/s. The improved gesture recognition algorithm can ensure the detection speed while improving the recognition accuracy. Through the analysis of experimental results, the improved YOLO-V3 model, the improved SSD model, and the dual-stream convolutional neural network model are better than other networks in the recognition of sewing gestures. The effect of recognizing sewing gestures is better.
Conclusion
To recognize sewing gestures quickly and accurately, we recognize four gestures such as inner overlock seam, hemming seam, cladding seam, and cutting fabric. The improved YOLO-V3 model embeds a densely connected network in the original transmission layer of YOLO-V3 with a lower resolution to promote feature reuse and fusion. Compared with the original YOLO-V3 model, the recognition accuracy of four similar sewing gestures is increased by 2.29%. The improved SSD model uses the residual network to replace the original SSD backbone network. By combining the idea of a feature pyramid, the original up-sampling structure is improved, which better combines high-level semantic features and low-level semantic features. The overall recognition accuracy of the improved SSD model is 88.79%. The real-time detection speed reaches 51 frames/
The goal of future work is to recognize more and more complex sewing gestures. Besides, we will study how to further improve the recognition speed, and finally realize the real application in the field of human-machine collaborative sewing.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Natural Science Foundation of China [51905405]; Key Research and Development plan of Shaanxi province China[2019ZDLGY01-08]; Ministr of Education Engineering Science and Technology Talent Training Research Project of China [18JDGC029]. Innovation Capability Support Program of Shaanxi[2021TD-29]. Key Research and Development program of Shaanxi province [2022GY-276].