
Abstract
This study investigates differences in torture-related witness statements during the Khmer Rouge Tribunal. It follows a three-phased sequential mixed methods design to identify disparities between testimonies of former detainees and interrogators and to examine how different methods complement each other for a comprehensive perspective on witness accounts. This includes training a natural language processing (NLP) model, sentiment analysis (SA), and qualitative content analysis (QCA). The qualitative and NLP-based analyses showed apparent differences between witness groups; a significant difference in sentiment values could not be detected. This study presents the first mixed methods approach based on court transcripts in genocide research. Its digital approach contributes to mixed methods research (MMR) by showing how NLP and data transformation can contribute to integration.
Introduction
Witnesses play a critical role in genocide-related trials. Through their testimonies, they provide crucial evidence but also tell personal stories of their survival. However, recounting experiences that might have been traumatic poses a significant challenge for individuals who have experienced extreme violence during a genocide. Consequently, protocols for witness support and psychological assistance are standard practice in most genocide tribunals (e.g., International Criminal Court, n.d.). While researchers have acknowledged the emotional difficulties of testifying about genocide and torture (Ciorciari & Heindel, 2016), there is limited research on how emotionally difficult experiences manifest in statements of different witness groups and the subsequent impact on individual testimonies.
To close this gap, this study analyzes how individual witnesses recount their experiences with torture in court by analyzing witness statements from Case 001 of the Extraordinary Chambers in the Courts of Cambodia (ECCC) against Kaing Guek Eav, who oversaw the torture prison S-21 during the Cambodian genocide between 1975 and 1979. S-21 is particularly relevant in this context since its primary purpose was to extract confessions from perceived enemies of the state (Chandler, 1999).
Generally, post-atrocity trials, such as the ECCC, involve a diverse range of witnesses, including direct victim survivors, family members of deceased victims, civilians, experts, as well as individuals involved in the atrocity, such as guards, soldiers, and political figures. We specifically examine the testimonies of two distinct groups directly involved in the act of torture: survivors who were imprisoned and interrogators who were stationed at the prison. Comparing the statements of these two witness groups potentially identifies differences in their discourse on torture. It potentially informs considerations on whether distinct approaches should be employed when examining different witness groups in court.
This study aims to detect such differences in testimonies of former detainees and interrogators through an exploratory sequential mixed methods design (Fetters et al., 2013; Moseholm & Fetters, 2017) with three phases. The first stage of the study consists of a natural language processing-based (NLP-based) classification task, followed by three different sentiment analyses (SAs) and a qualitative thematic analysis. Natural language processing generally refers to utilizing algorithms to process human language (Jurafsky & Martin, 2021). In the context of a classification task, such an algorithm is trained to assign text segments to predefined categories. While the algorithm gives details about how clear a distinction between different categories can be made, it can be seen as a black box that does not explain which characteristics led to the classification. Therefore, further analysis is needed. Sentiment analysis, an NLP technique that identifies subjective information in text like emotions, shows promise: Diving deeper into group differences, it allows for a more nuanced understanding of the emotional content of the witness testimonies. Finally, the qualitative analysis provides a more profound understanding of the contextual factors that may have influenced the statements. By integrating methods involving the convergence of multiple approaches, we aim to overcome the limitations of individual methods, providing a multi-perspective and more robust view of witness statements (Creswell & Plano Clark, 2018; Tashakkori et al., 2021).
To the best of our knowledge, this type of study design has not found its way into genocide studies so far and thus presents a novel approach to this field of research. Simultaneously, it contributes to mixed methods research (MMR) by addressing the issue of integration (Bryman, 2007; Fetters et al., 2013) on design, methods, and interpretation levels. With digital data transformation being a key aspect, we are presenting an alternative version of a digital mixed methods design (O’Halloran et al., 2018) involving transforming qualitative data into quantitative data and comparing patterns across different data dimensions through data mining. Consequently, this study follows recent advances in MMR to combine NLP and machine learning with qualitative analysis (Guetterman et al., 2018; Sripathi et al., 2023). More specifically, both quantitative text mining methods and qualitative content analysis (QCA) are applied to transcripts from ECCC Case 001 to address differences in witness statements between former detainees and former interrogators of the S-21 prison (see Figure 1 for an overview of the study design). First, we follow up on whether speech- and content-based differences between the testimonies of former detainees and interrogators can be identified, and if so, which methods are appropriate for detecting such differences (Research Question (RQ) 1). This is done by answering three subordinate questions of how accurately an NLP-based model can classify text segments as either belonging to a former detainee or interrogator (RQ 1.1, quantitative), whether sentiment values in witness testimonies of former detainees and interrogators exhibit significant differences (RQ 1.2, quantitative), and how thematic patterns in statements of former detainees and interrogators differ (RQ 1.3, qualitative). Finally, this paper synthesizes previous findings by analyzing how the results of the different methodological approaches of RQ 1 complement or challenge each other regarding the differences in witness statements made by former detainees and interrogators (RQ 2).
Background
Trauma and Torture as Part of the Testimony
The American Psychological Association (
How torture was applied in the S-21 prison in Cambodia has been studied by numerous authors (Chandler, 1999; Hinton, 2016). When it comes to testifying in Case 001 of the ECCC, however, only a few works have been published. Among them are studies that mainly focused on the prison leader’s role and the situation of individual witnesses in court (Hinton, 2016) or applied a more quantitative approach by applying a software-based text analysis of testimonies (Brönnimann et al., 2013). Addressing the psychological impact of testifying before the ECCC, Ciorciari and Heindel (2016) concluded that the participation of traumatized persons in the court proceedings represented an “emotionally difficult process” (p. 184) and consequently called for sensitivity training of court professionals to provide support for traumatized testifiers and avoid re-traumatization. Apart from the mentioned examples, there is a lack of studies specifically examining how the content of accounts of torture differs between former detainees and interrogators, leaving a gap for further research in this area.
Detainees’ Versus Interrogators’ Accounts of Torture
Still, there is evidence suggesting that accounts of torture could differ significantly between detainees and interrogators. First, speechlessness can present in cases of experienced trauma, especially in the context of genocide (Sandick, 2012). Experiences of torture and other forms of extreme violence are processed in a complex way, making it especially difficult for victim survivors to verbally express such events from their past. Closely connected to the phenomenon of speechlessness is the impact of genocide and torture on memory: Individuals who have undergone traumatic experiences may either remember them vividly or experience memory repression, where the memories of torture are not consolidated, resulting in an inability to recall the event in detail (Lehrner & Yehuda, 2018). Similar psychological effects were found in perpetrators of genocide, who experienced high levels of post-traumatic stress symptoms in the aftermath of the genocide (Barnes-Ceeney et al., 2019). Especially torture methods involving sexual violence or degrading techniques can create feelings of shame for victim survivors. This shame may affect the witnesses’ statements in court, potentially resulting in the omission of uncomfortable details (Sharratt, 2016). At the same time, however, the tribunal might serve as a catalyst in the processing of traumatic experiences: several witnesses stressed their relief and happiness about contributing to justice through their testimony, making it a “cathartic courtroom experience” (Ciorciari & Heindel, 2016, p. 124). While some witnesses might experience this positive outcome, the testimony can have opposite effects on victim survivors and might even lead to re-traumatization (Brounéus, 2008). Lastly, legal implications could impact the testimony of former interrogators. Although it was improbable that former interrogators would face repercussions for testifying, the prospect of being charged for participating in torture may still have impacted their testimony and could have led to denying responsibility (Holness & Ramji-Nogales, 2016; Kanavou & Path, 2017). Altogether, these findings on speechlessness, memory, shame, emotional processing, re-traumatization, and legal implications as potential factors influencing witness testimony imply that former detainees and interrogators talk about torture differently in court.
Combining Mixed Methods, NLP, and Trauma Research
To shed more light on these potential differences, this study applies a mixed methods design to trauma and genocide research, incorporating NLP techniques. Natural language processing-based approaches are used more and more frequently in both mixed methods and trauma research, with authors from different backgrounds repeatedly emphasizing the great potential that NLP brings to MMR (Chang et al., 2021; Guetterman et al., 2018; Reinhold et al., 2022) and discussing the incorporation of big data into mixed methods designs (Bazeley, 2018; O’Halloran et al., 2018). Within the broad range of NLP tools, topic modeling (Ho et al., 2021) and SA (Colditz et al., 2019) have been popular methods applied in the context of mixed methods. Applying these methods in the context of trauma and violence research seems promising, especially with violence being a “too complex and pressing social problem to be subjected to methodological puritanism” (Thaler, 2017, p. 70). Similarly, Creswell and Zhang (2009) highlight the suitability of mixed methods in trauma research, as it allows for the inclusion of qualitative data in a traditionally more quantitative field, such as patient interviews, bridging the gap between research and practice. Several studies have further explored the intersection of violence and trauma using mixed methods, such as investigations into domestic violence and abuse (Bacchus et al., 2018) or childhood trauma (Boeije et al., 2013). Specifically for genocide research, however, mixed methods designs are scarce. For instance, focusing on World War II, Békés et al. (2021) analyzed survivors’ narratives through a sequential mixed methods design, combining an interpretative phenomenological approach and quantitative comparison of codes drawn from interview material. Addressing more recent cases of mass atrocities, other studies discussed gender and genocide in Darfur (Kaiser & Hagan, 2015) or sexual violence in the Democratic Republic of the Congo (Kelly et al., 2011) with mixed methods designs. However, these studies did not discuss their contribution to MMR or address MMR-related challenges, such as integration. Additionally, NLP techniques have not yet found their way fully into genocide research except for individual papers that focused on topic-based classification or topic modeling in genocide-related court transcripts (Keydar, 2020; Schirmer et al., 2022; Schirmer et al., 2023). Therefore, the study’s value lies in synthesizing state-of-the-art methods in NLP and MMR-specific questions, such as integration, applied to the analysis of transcripts of genocide tribunals. It tackles the challenge of preserving witness accounts of genocide survivors in historical documents (Keydar, 2020) while providing a concrete example of combining computational, statistical, and qualitative methods.
Methods
We follow an exploratory sequential design (Moseholm & Fetters, 2017) to identify differences between former interrogators and detainees when recounting experiences of torture during the ECCC. This is done in three stages, using NLP techniques and QCA (Mayring, 2015) to complement each other. Starting with a broad analysis, an NLP-based language model is applied for binary classification to distinguish between statements made by the two witness groups (Phase I). This serves as a starting point for obtaining an overview of the differences in statements between the two witness groups. Given that the language model does not explain its classification decision, this step can only provide a general sense of how well an algorithm can distinguish between the two groups. In the second step, three different SAs are conducted to look for differences in witness accounts on a sentiment-based level (Phase II). Sentiment analysis is a valuable tool for analyzing the emotional content of witness statements, especially in the sensitive context of trauma and torture. By examining the sentiment expressed by each witness, we can gain a deeper understanding of the emotional aspects of their experiences. Concretely, SA could reveal that one witness group uses more negative language in their statements, offering valuable insights into the psychological impact of torture on both groups. Although current research suggests that trauma can successfully be detected through SA (Sawalha et al., 2022), it is essential to acknowledge that SA primarily provides insights into the overall sentiment expressed, which does not necessarily equate to trauma or an actual emotional state experienced by the witness. However, despite its limitations in capturing the full extent and complexity of traumatic experiences, analyzing the emotional tone and general sentiment expressed in the testimonies still provides a valuable understanding of the affective impact of traumatic experiences on individuals. Lastly, the statements are subjected to QCA, laying out differences between the two witness groups that go beyond automatically detectable patterns (Phase III). Aligned with this research design, the primary focus of this study is to demonstrate the effective utilization of the three methods within an MMR framework. We further provide a concrete application example from the field of genocide studies, illustrating how the MMR framework can be effectively employed in practice.
Material and Data Transformation
Overview of Witnesses Who Were Either Imprisoned in S-21 or Were Part of the S-21 Staff.

Note. Due to the topic’s sensitivity, witnesses are referred to by their initials. However, the witnesses' full names can be found in the openly published court documents for a comprehensive historical perspective, including additional individual details. Only testimonies that were transcribed in English are included.
The transcripts used for this study contain organizational details about the case, the date, and the names of the witnesses to be heard. They provide a verbatim record of all spoken proceedings, covering witness testimonies, lawyer arguments, and judge rulings. Non-verbal information, such as physical reactions, is not included. All transcripts of the court proceedings are available to the public on the ECCC Web site in both English and French, 1 with Khmer also being used as an official language during the court proceedings. This study relied on the English versions of the transcripts for the analysis. Despite the possibility of translation biases and inaccuracies, NLP techniques can provide insight into the emotional content and language patterns by detecting patterns between words and phrases. Considering that professional court translators did the translation, a certain quality of the translation can be assumed. 2 Biases are thus likely to affect both groups of former detainees and interrogators equally. Hence, the relative differences between the two groups should remain valid, especially when including the context of the witness statements during the qualitative part of the analysis.
The original transcripts were subjected to an elaborate transformation process to make the data suitable for NLP analysis. In this case, transformation refers to changing qualitative data into quantitative data, also referred to as quantitizing (Sandelowski et al., 2009). While quantitizing commonly includes the numerical representation of qualitative data, this study aims to show how quantitizing goes beyond merely assigning numerical values to qualitative data, for example, by including word frequencies. Instead, we created a new data format from the original transcripts, segmenting the transcript documents and assigning meta-variables, such as the witness role (detainee vs. interrogator), witness name, and the sentiment value of the respective statement. Due to its pre-structured form, this leads to a new dataset suitable for NLP and statistical analysis.
Diverging from the originally proposed design, our data transformation approach can be seen as a variation of the digital mixed methods design (O’Halloran et al., 2018) that expands data integration to encompass the conversion of qualitative data into quantitative data. However, while O’Halloran et al. (2018) start their approach with a qualitative discourse analysis and build the data transformation on that, this study starts with the data transformation as a first step. By incorporating transformation and data mining as critical components in our study to analyze patterns and trends across diverse data dimensions, we argue that our approach can be classified as a digital mixed methods design.
Transformation from qualitative to quantitative data → NLP exploration → Sentiment analysis and statistical models → Qualitative analysis
Assuming that transcripts provide appropriate insights into how various witness groups discuss torture, they served as data for all three steps of analysis. Therefore, the original documents had to be transformed into a form suitable for computational analysis. This was done by dividing each of the transcripts into text chunks of approximately 250 words each, leading to 439 text chunks in total. These text fragments were subsequently labeled according to whether the statement was made by either a former detainee (label “0”) or a former interrogator (label “1”) (ndetainees = 204; ninterrogators = 235), resulting in a new dataset for training an NLP model. 3 For the SA, the transcripts were also analyzed in this paragraph format. However, the text was split into individual words to include a word-based SA, which is required for assigning sentiment values through the word-based lexicon. Before finalizing the datasets, preprocessing was conducted. As a regular technique in NLP, preprocessing involves cleaning and transforming the raw text to make it suitable for further analysis. This step is crucial because it helps remove irrelevant text information that can affect the accuracy of the model’s predictions. In our case, this involved the removal of punctuation and stop words (i.e., words that are irrelevant to the analysis, such as pronouns). For the qualitative phase, transcripts were analyzed in their original format.
Phase 1: Explorative NLP Classification
One of the state-of-the-art language models used in NLP is called Bidirectional Encoder Representations from Transformers (BERT; Devlin et al., 2019). Bidirectional Encoder Representations from Transformer is a pre-trained neural network that can predict outcomes based on the relationships between words and their surrounding context. In the first step of this study, BERT was trained on a labeled dataset to predict whether text passages could be automatically classified as either interrogator or detainee testimonies, aiming to identify potential differences between these groups on a general level. In line with standard practice, accuracy and F1 scores are reported. The accuracy score indicates the total number of correctly identified text segments, while the F1 scores depict the weighted average of precision and recall values. 4 It is important to note that BERT can classify text paragraphs into different categories. However, it does not provide further information on specific text characteristics to help distinguish between the two categories of interrogators and detainees. Nonetheless, the classification is still useful for distinguishing between interrogator and detainee testimonies, as it relies on the inherent differences in language use between these two groups.
Phase 2: Sentiment Analysis
Due to the emotional sensitivity of the analyzed material, SA was selected as a tool to measure specific sentiment values for each witness. This technique categorizes semantic structures according to their underlying emotional content (Liu, 2020). Generally, two types of SA can be distinguished: On the one hand, SA is performed by supervised machine learning, where a text corpus already labeled with different sentiments is used to train an algorithm. On the other hand, lexicon-based SA is based on specific lexicons whose individual words have already been assigned sentiment values. In this study, lexicon-based SA was chosen since a suitable training corpus for this type of text material is not available, and the amount of text used in this study is comparatively small for machine learning approaches.
Three different SAs based on numerical sentiment values were conducted to yield more comparable and generalizable results. The first lexicon used is AFINN (Nielsen, 2011), which assigns a numerical value between −5 and +5 to each word. Negative values indicate a negative emotion, whereas positive values indicate a positive emotion. SentimentR (Rinker, 2019) was used as the second lexicon to detect sentiment values for complete sentences. Accounting for valence shifters and similar modifiers, such as negators or amplifiers, SentimentR makes it easier to calculate sentiment values according to neighbor-word context. The third lexicon applied, VADER (Hutto & Gilbert, 2014), also identifies sentiment values on a sentence level by calculating positive, negative, and neutral sentence components and combining them in a compound value. After assigning sentiment values using all three SA tools, linear hierarchical models were estimated to see if the witness group significantly influenced the sentiment value. Despite the limited number of witnesses, a statistical analysis of this nature remains reliable as the model examines individual words (AFINN) or paragraphs (SentimentR and VADER) to compare sentiment values, thereby utilizing an adequate number of data points.
Phase 3: Qualitative Content Analysis
To prevent a “loss of depth and flexibility” (Driscoll et al., 2007, p. 25) as a disadvantage of quantitizing, witness statements underwent QCA to ensure contextual considerations. As computational emotion analysis has been criticized for not detecting multiple or implicit emotions (Poria et al., 2019), the qualitative phase is crucial to obtaining a comprehensive understanding of the witness testimonies. A qualitative approach also allows us to analyze individual testimonies in detail, identify frequently occurring themes, and avoid overlooking important nuances (Creswell & Plano Clark, 2018; Tashakkori et al., 2021). Since no framework for categories regarding the reconstruction of torture experiences in court exists, categories were inductively developed (Mayring, 2015), closely examining the data and deriving categories from the content itself.
The transcripts were coded using MAXQDA Analytics Pro 2020, analyzing them for each witness individually by reading through each page and establishing categories of recurring topics. This process involved identifying significant words and phrases in the statements that gave insights into how witnesses talked about their experiences of torture, including content and form. For instance, special attention was given to noticeable signs of emotional distress, such as pauses, interruptions, or any coping strategies mentioned by the witnesses during their testimony in court. With this focus in mind, roughly one third of the material was examined in a first step. Categories were developed through an open coding process, which involved two rounds of coding to allow for adjustments. After a meaningful set of codes was established from transcript samples, a second researcher independently went through the same third of the material using coding instructions. The resulting inter-rater reliability of κ = .82 indicates a high degree of agreement between the two researchers. After establishing these categories on a sample of the transcripts, we used them to code the remaining transcripts. Coded categories and themes were then analyzed and interpreted to provide a deeper understanding of the contextual factors that may have influenced the emotional content of the testimonies. Overall research design. Note. This study consists of three sequential phases, with each methodological approach informing the others.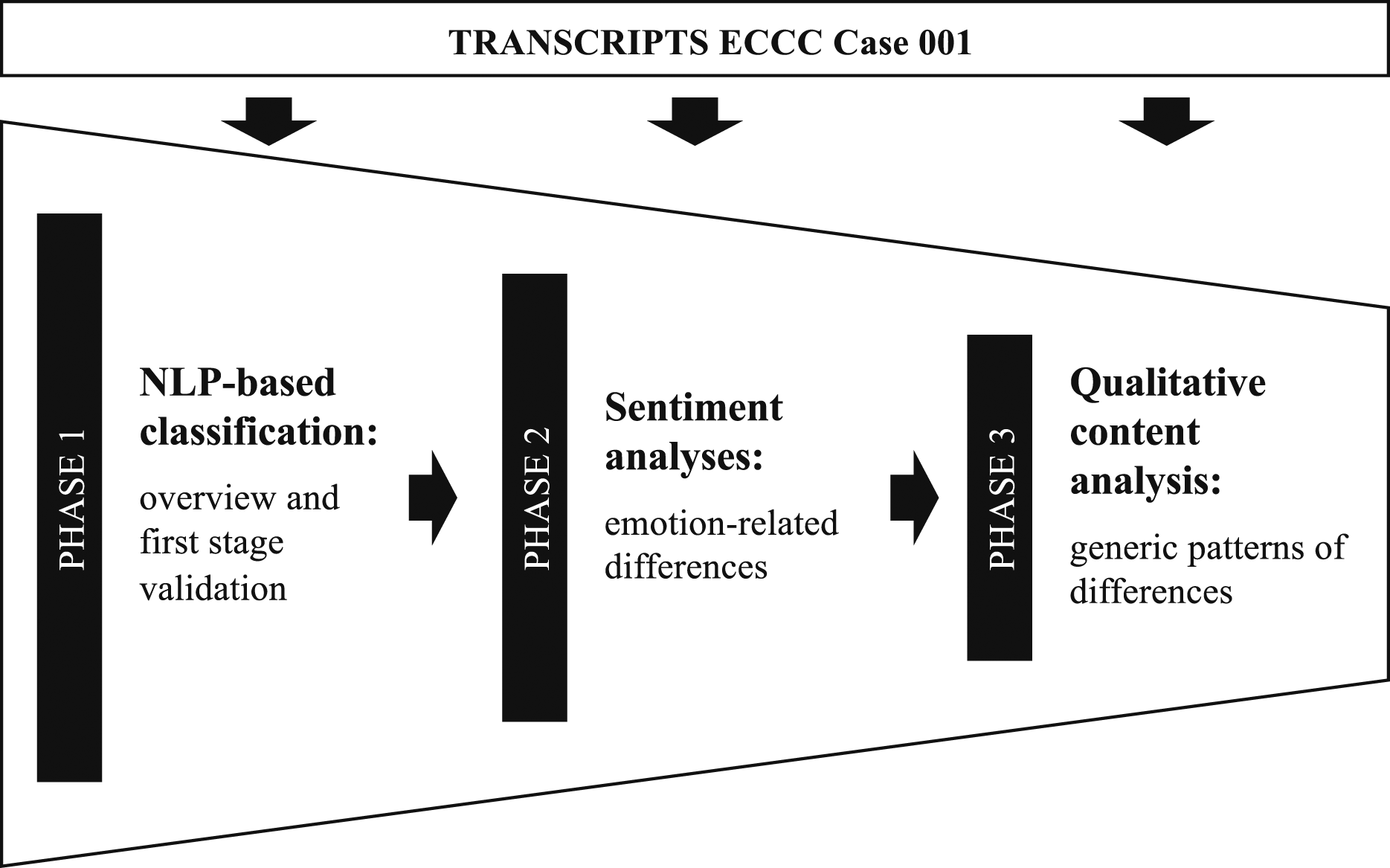
Results
BERT-Based Binary Classification
Applying BERT to predict the witness group of individual testimony passages yielded an accuracy and an F1 score of .95 each. Accordingly, the model correctly classified 95% of the text segments. Considering that the amount of text segments used to train BERT in this study was comparatively low, it is even more remarkable that a high percentage of correct classifications were reached, especially compared to benchmark studies in this field (Zhang et al., 2021). Differences in the accounts of former detainees and former interrogators regarding their testimony in court appear to exist on a speech-based level. Research question 1.1 about whether an NLP-based model can classify text segments according to the respective witness group can thus be positively answered, emphasizing the model’s high accuracy.
Sentiment Analysis
None of the three conducted SAs showed statistically significant differences in sentiment values between former interrogators and former detainees. Nonetheless, all three analyses yielded descriptively lower mean sentiment values for the group of interrogators (see Figure 2): The word-based SA with AFINN revealed a mean sentiment value of −1.64 for former interrogators (SD = 1.46) and −1.28 for former detainees (SD = 1.74). In the SA conducted with SentimentR, former interrogators had a sentiment value mean of −.21 (SD = .31), while former detainees’ values were at a mean of −.10 (SD = .26). The VADER SA led to similar results: While the interrogators’ mean sentiment value was −.58 (SD = .61), the detainees’ mean sentiment value of −.33 (SD = .69) was close (possible sentiment value range for SentimentR and VADER: −1 to +1). Notably, all mean sentiment values were negative. Boxplots of all three sentiment analyses conducted.
Overview of the Three Sentiment Analysis Models.
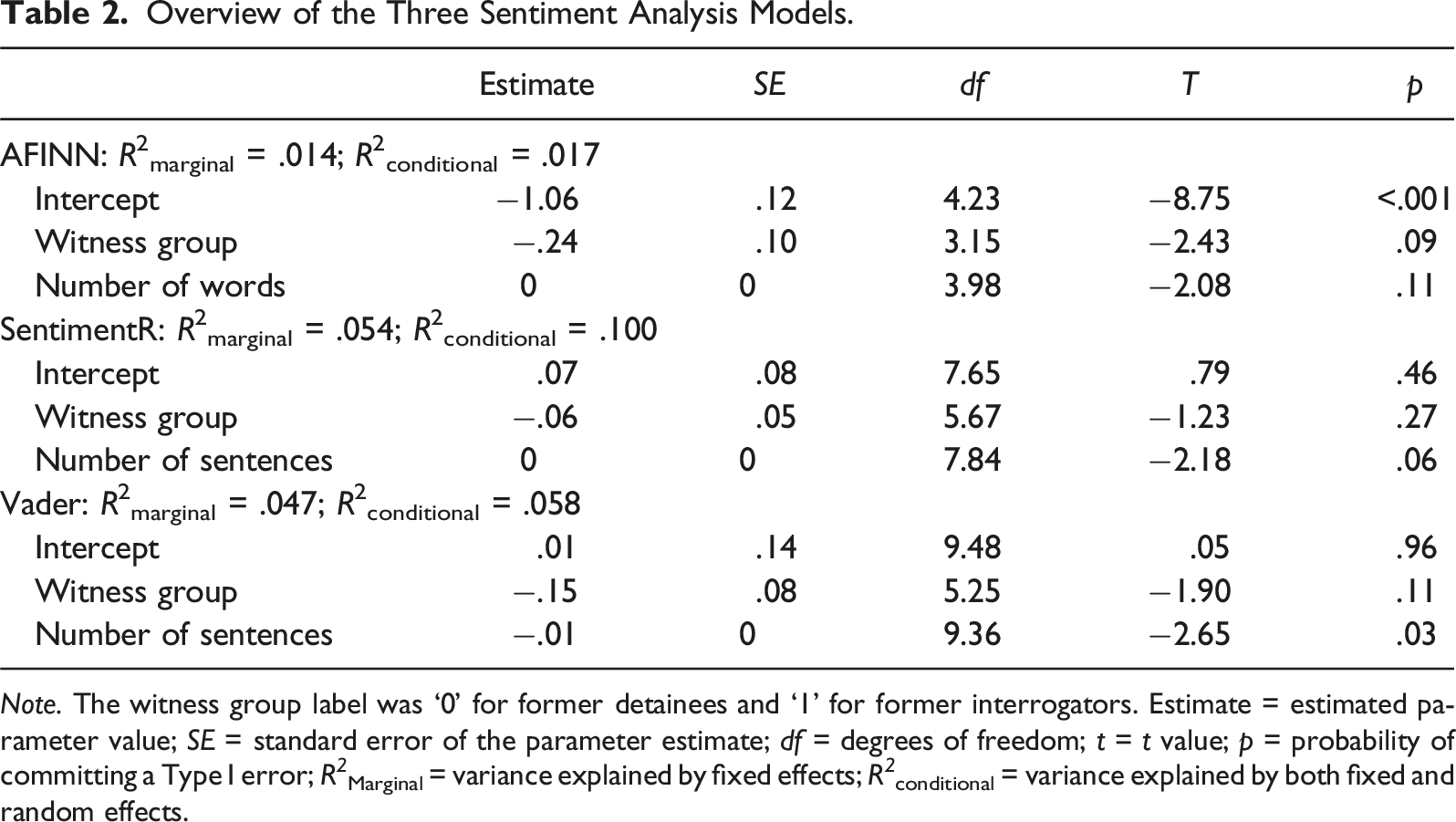
Note. The witness group label was ‘0’ for former detainees and ‘1’ for former interrogators. Estimate = estimated parameter value; SE = standard error of the parameter estimate; df = degrees of freedom; t = t value; p = probability of committing a Type I error; R 2 Marginal = variance explained by fixed effects; R 2 conditional = variance explained by both fixed and random effects.
To illustrate the descriptive differences more clearly, we explored samples of sentiment values in more detail. As the AFINN analysis is based solely on individual words and lacks contextual information, we focused on SentimentR and VADER. The highest positive and negative sentiment values obtained for both groups are shown in Figures 3 and 4, respectively. Highest negative sentiment values. Note. Highest negative sentiment values for SentimentR and VADER analyses for both groups of interrogators (first row) and detainees (second row). Each text is an excerpt of a paragraph that has been assigned a sentiment value (bold). Witness initials and the sentiment value for the statement are depicted below each text block. The most negative detainee text segment was identical for both the SentimentR and VADER analysis (Example 3). The text has been preprocessed, that is, punctuation and capitalization have been removed. Highest positive sentiment values. Note. Highest positive sentiment values for SentimentR and VADER analyses for both groups of interrogators (first row) and detainees (second row). Each text is an excerpt of a paragraph that has been assigned a sentiment value (bold). Witness initials and the sentiment value for the statement are depicted below each text block. The text has been preprocessed, that is, punctuation and capitalization have been removed.
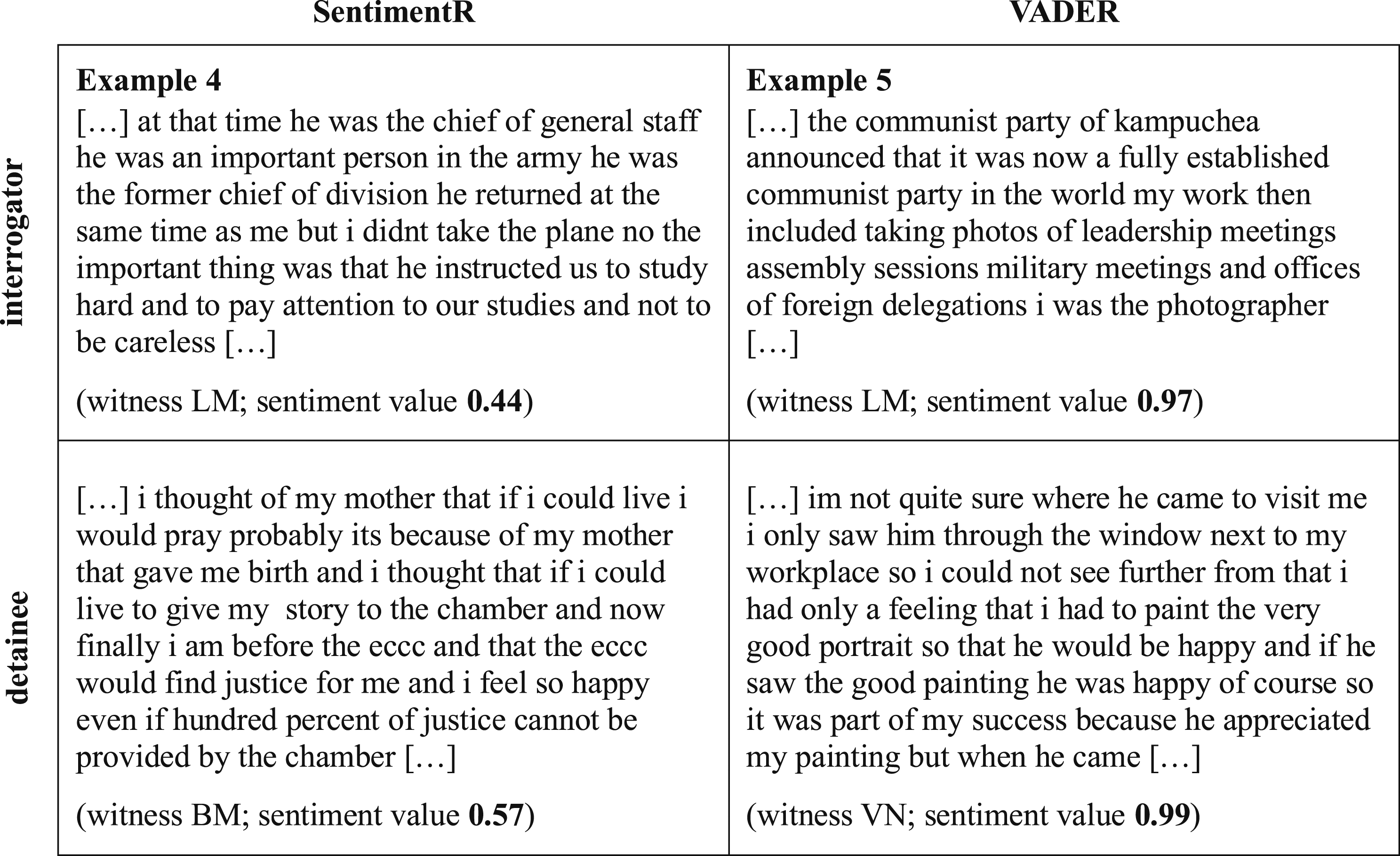
These examples confirm the descriptive trend of interrogators having more negative sentiment values assigned to their statements. In Examples 1 and 2, interrogators describe torture and executions in detail, leading to high negative sentiment values. Example 3 contains a detainee description of the living conditions in S-21 that involved the permanent threat of physical violence and death. Interestingly, the highest positive sentiment values were assigned to detainee statements: One statement describes positive emotions about testifying in court (Example 6), while the other draws positivity from painting tasks (Example 7), with the latter not necessarily being connected to actual positive emotions. The statements with the highest positive sentiment values for interrogators both describe political developments (Examples 4 and 5). Again, they are not directly linked to positive emotions experienced by the witnesses and refer to experiences made by the witnesses prior to their work at S-21.
In response to research question 1.2, which investigates whether differences in sentiment values between former detainees and interrogators exist, the study found no statistically significant differences. Nevertheless, the provided examples shed light on how such distinctions are established, descriptively illustrating that interrogators exhibited slightly more negative sentiment values than detainees.
Qualitative Analysis
Even though the SAs showed only limited differences between both witness groups, differences in how they talked about experienced violence become clearer by analyzing relevant text passages qualitatively. Through an inductive approach that involved identifying recurring thematic patterns in an open coding process, we identified three main patterns: expressions of emotional distress, technical expertise, and motivation to testify. Expressions of emotional distress referred to statements in the testimonies that conveyed feelings of anxiety, sadness, or trauma. Typical subcodes of this category include the witness needing a break or talking about lasting health problems. Technical expertise, on the other hand, encompassed statements that demonstrated the witness’s knowledge and understanding of technical details related to the events they described, such as locations or procedures. A witness describing what kind of torture methods they were taught is an example of this category. Finally, motivation to testify refers to statements that reveal why the witnesses decided to testify in court, such as seeking justice or wanting to contribute to the historical record. Subcodes include references to justice and personal feelings toward the tribunal itself.
Emotional Distress
The first important factor deals with the emotional stress during the testimony, which was visible during the former detainees’ accounts. Each of the former detainees described their own experience of being tortured, from being beaten by arrival or specific torture during interrogation. They all describe being tortured with their hands tied and by being beaten with bamboo or rattan sticks (BM, 41.1, p. 29; CM, 40.1, p. 13)
5
or being electrocuted regularly (BM, 41.1, p. 30; CM, 40.1, p. 73). Testifying about past experiences of torture in court can be emotionally challenging (Ciorciari & Heindel, 2016), as seen in transcripts where the presiding judge reprimands BM to “control [his] emotion” and “please recompose [him]self” (NN, 41.1, p. 94) while discussing the psychological effects of torture. Similar text passages can be found during the other detainees’ testimonies. Also, accounts of experienced torture were described vividly, including descriptions of the emotions felt at that time: He asked me to count the lashes, and when I counted up to 10 lashes, he said, “How come you count to 10 lashes? I only beat you for one lash.” I felt so painful at the time. There were wounds many wounds on my back and the blood was on the floor flowing from my back. Whips were also used to torture me. (BM, 41.1, p. 13)
Such experiences belonged to the everyday life of detainees at S-21, making both violence and the threat of violence omnipresent and inescapable for them. The detainees further report having scars that constantly remind them of their suffering. No similar examples were found in the statements of former interrogators.
Technical Expertise
Former interrogators described the torture rather technically, focusing on specific methods and training. In that context, the witnesses explained how interrogations were accompanied by torture if the detainee did not confess (PK, 53.1, p. 21). For that purpose, the interrogators received special training: Regarding the techniques of torture, we were taught how to torture the prisoners and to avoid that the prisoners died, otherwise, the confessions would be broken and we would be punished. And we were trained on how to whip the prisoners with the stick, on how to electrocute, on how to use the plastic bag to suffocate them. (PK, 52.1, p. 17)
According to the testimonies, interrogators were trained by more experienced prison staff while watching them interrogate and apply torture techniques, such as electrocution and beating with sticks. Only those who proved to be successful in training were later allowed to use torture on detainees themselves (LM, 57.1, p. 51, p. 88). Notably, former perpetrators’ use of collective pronouns like “we” when discussing their training and torture techniques creates a technical, impersonal tone. In contrast, former detainees speak for themselves individually, sharing personal experiences. The witnesses also describe the killing of detainees. One of the former interrogators explains that “the executioners were instructed to kill the prisoners by asking the[m] to kneel down near the rim of the pits” (HH, 50.1, p. 68). Subsequently, the prison staff “would use an oxcart axle to strike the back of the necks and later on they would use a knife to slash the throat, […] then they would untie or remove the cuff and remove the clothes” (HH, 50.1, p. 68). The description of how detainees were killed at S-21 demonstrates clearly that violence is stated in a more factual manner by former interrogators, contrasting the more emotional way in which former detainees recounted their experiences with torture and violence.
Motivation for Testimony
Another factor differentiating testimonies of former detainees and interrogators is closely connected with this observation: the motivation behind the testimony. While former detainees expressed their wish to contribute to justice through their testimony, interrogators might fear being charged for having applied torture. When asked about details on specific torture techniques, the former interrogator HH frequently answered that he “prefer[s] not to answer that question” (e.g., HH, 50.1, p. 68). Former detainees, however, replied openly and in detail, hoping their accounts could contribute to finding truth and justice, as one witness explains: What I want is something that is intangible, that is, justice for those that already died. Whatever way the justice could be done is my only hope that can be achieved by this Chamber. And I hope by the end of the Tribunal that justice can be tangible, can be seen by everybody, and that it is something that I expect as a result (VN, 39.1, pp. 55–56).
Following this perspective, former prisoners report to be “happy” testifying in court, “even if 100% of justice cannot be provided by the Chamber” (BM, 41.1, p. 14). Another witness reported being relieved to finally speak about the suffering in front of a court since he “wanted to get it out of [his] chest” (CM, 40.1, pp. 66–67).
The study’s qualitative section provides more content-based insights into witness accounts and uncovers differences between both witness groups. Looking at differences in thematic patterns in statements of former detainees and interrogators (research question 1.3), our findings indicate that former interrogators provide more detailed information about procedures. In contrast, former detainees primarily focus on recounting their personal experiences, highlighting disparities in emotional distress, technical expertise, and motivation to testify.
Combining the Results: Differences in Testimonies of Torture
In Phase I of the study, we used the language model BERT to classify witness statements as either belonging to former detainees or interrogators. The findings demonstrate the model’s ability to effectively differentiate between these two groups based on language. However, the exact differences remain unclear in this phase. Therefore, drawing on the NLP results as a first confirmation of existing differences, we employed SA, focusing on emotional intricacies in the context of torture-related witness statements. The absence of significant differences in sentiment values between both witness groups can be attributed to several factors: First, detainees used strongly negatively weighted words when reporting their torture (e.g., “torture” and “painful”), while interrogators focused more on general procedures associated with less negatively connotated words. Second, the different roles and knowledge of the witnesses in S-21 can be cited as an explanation for differences in their choice of words and their function in the trial. The fact that the court context might play an important role is substantiated by the similarity in sentiment values within witness groups. Although both groups are questioned for reliable information in different areas, the strictly structured legal framework might limit the variety of statements, potentially neutralizing differences in sentiment values (Chlevickaitė et al., 2020). Examples showed that the most negative statements were made by interrogators describing torture, while detainees also expressed hope for justice, further explaining why, descriptively, interrogators’ sentiment values were more negative. Phase II of this study thus dives one step deeper into identifying differences in witness statements through SA, complementing the results of Phase I. Finally, building on the previous stages, Phase III uncovers emotional and motivational factors that distinguish the witnesses' statements through its qualitative approach.
This study demonstrates that using a portfolio of NLP and qualitative methods enhances the comprehensive understanding of differences in witness testimonies between former detainees and interrogators, as opposed to using these methods individually: Applying an NLP classification task merely confirms that there is an algorithm-based way to differentiate witness statements, which serves as a justification for investigating those differences further. If we had solely relied on SA, we would not have identified significant differences between the two groups, thereby missing out on non-sentiment-based distinctions. The SA on its own provides us with information on which text segments were the most positive and negative regarding their sentiment value—shedding more light on the relation of sentiment values and witness group. On the other hand, we identify differences by exclusively using QCA without quantitative support but cannot substantiate them on a broader scale. The results challenge each other by providing different insights, particularly when the SA does not show statistically significant differences. This illustrates that NLP classification and QCA prove to be suitable methods to detect differences in testimonies of former detainees and interrogators, while SA might not be an ideal fit (research question 1). Still, the study highlights how the three applied methods can complement each other by compensating for their limitations (research question 2; see further Section Contributions to the field of mixed methods).
Discussion
In a mixed methods exploratory sequential design, this study demonstrated how mixed methods can contribute to analyzing witness statements to find out if and how accounts of torture differ between former detainees and former interrogators in the S-21. We show how using an NLP classification task can serve as a valuable tool to support further analyzing steps and provide an exemplary 3-stage framework for comprehensively analyzing text data from court documents.
Contributions to the Field of Mixed Methods
Addressing the Integration Challenge
This study approaches the integration challenge (Bryman, 2007; Fetters et al., 2013) on different levels. Regarding the research design, this study establishes connections between all three phases. For that purpose, the NLP classification task (Phase I) was set up to approach differentiating between the two witness groups on a speech-based level. The high accuracy of the algorithm in classifying text segments into either former detainees or interrogators served as a baseline for the subsequent phases (Phases II and III), laying the ground for subsequent analyses. The high accuracy score further suggests that the statements from both witness groups exhibit distinct content and narratives, indicating that they can be treated as separate text corpora. This validates the significance of individually analyzing the differences in testimonies between the two groups. Since BERT alone could not provide insights into the content of the testimonies, the study incorporated both SA and QCA to illuminate aspects that could not have been identified by a single approach, allowing for a more thorough understanding of the differences between the witness groups and how contextual factors may have influenced their testimonies. This goes hand in hand with integration on a methodological level, as each method served to inform and justify the concrete selection of the subsequent method in the analysis. By leveraging the insights gained from each method, we were able to make informed decisions regarding the subsequent stages of our analysis. Finally, on an interpretation level, results were integrated following a contiguous narrative approach, reporting findings of each phase separately at first and bringing everything together in the end (Fetters et al., 2013). In this case, the NLP-based classification of text paragraphs could not be replicated through SA, leading to discordance as one of the possible outcomes of MMR (Fetters et al., 2013; Moseholm & Fetters, 2017). The insights provided by the examples in Figures 3 and 4, combined with three different SA techniques, support the validation of the study’s results. The qualitative analysis further elaborates on these examples and provides a broader illustration of the study’s findings—in this case, complementing the other phases by bringing personal motivations and attitudes of the witnesses into light that could not have been discovered by quantitative approaches alone. That the qualitative findings are supported by the NLP classification and descriptive trends in the SA further underscores the importance of this methodological combination.
Data Transformation and NLP for MMR
This study further highlights opportunities from data transformation, where one type of data is converted into another (Fetters et al., 2013). Quantitizing text (Sandelowski et al., 2009) enabled the use of witness transcripts across all three phases of the study. By creating a dataset out of court transcripts amenable for further NLP-based processing, we went beyond classic content analysis (Krippendorff, 2004), where codes of qualitative analyses are mainly counted. Instead, we created a data source that kept most of the original context by separating the original documents into smaller text segments.
Applying NLP techniques to the transformed data confirms some of the advantages of using NLP to “accelerate” MMR (Chang et al., 2021). The NLP classification conducted in this study highlights the usefulness of establishing that differences between the testimonies of former interrogators and detainees exist. This can serve as a potential validation strategy (Chang et al., 2021; Crowston et al., 2012) for the use of further models, enabling researchers to focus on more specific characteristics that set the groups apart, such as distinct emotions or language patterns. Furthermore, our results show the potential to automatically classify witnesses into different groups with similar narratives, allowing for a more accurate individual analysis that uncovers characteristics that are unique to that group and would otherwise have remained hidden. The absence of differences revealed by the SA does not necessarily diminish the value of NLP. In fact, the sentiment values obtained from the analysis offer insights into which paragraphs were associated with more negative or positive sentiment values, allowing for comparison on an individual level and adding a quantitative perspective (Guetterman et al., 2018). Further, results indicate that any differences that may exist are not reflected significantly on a sentiment level, leaving space for the qualitative component to explore other possible sources of distinction. In this study, we selected SA due to the emotional nature of torture-related statements. However, it is important to note that SA is just one of many NLP methods that can be used to identify these differences. For future analyses, techniques such as topic modeling or named entity recognition could also be employed.
Limitations and Future Research
Interpreting the results, some limitations should be acknowledged. First, it must be addressed that the trial transcripts were translated from the original Khmer language into English for analysis. Since the SAs are based on comparing two groups whose statements have been subjected to translation in the same manner, the translation should not have a relevant impact on the analysis. It can be assumed that the translation corresponds to official standards and was performed by professional court translators, ensuring a certain level of translation quality. Hence, comparing the SA results between the two witness groups of former detainees and interrogators can still be meaningful, as any potential translation biases or inaccuracies would likely affect both groups similarly. However, considering that the language itself underwent analysis, it cannot be ruled out that disparities in the original languages were leveled out or amplified during translation, potentially explaining why sentiment values did not differ significantly.
Second, with its highly structured Q&A procedure, the court context may have imposed limits on the variety of statements and subjects, which could have neutralized potential differences in sentiment values. Therefore, exploring the relationship between specific questions and answers, for example, on the emotional impact of the torture for both witness groups, might provide further insights into the differences in language use between the two witness groups.
Third, the SAs have certain methodological limitations. Since AFINN attributes sentiment values per word, contextual information is not included. Further, words that are not categorizable as positive or negative are excluded. This can introduce biases, as certain words like “beat” may be excluded while variations like “beaten” and “beating” have different ratings. While SentimenR incorporates context by assigning values to amplifiers and negations, its scope is limited to direct word neighbors and may not capture relevant context. In contrast, VADER includes positive, negative, and neutral sentence components, making it the model that best incorporates overall context. Finally, for all SAs, it should be noted that while the number of words and sentences was relatively high, the sample size was restricted to 8 witnesses, thus limiting the statistical power of the SAs. On a broader level, it is important to distinguish between trauma and sentiment as separate concepts. While SA can provide an understanding of the general sentiment expressed in witness testimonies, it is crucial to recognize that trauma encompasses a broader range of experiences and has a distinct psychological impact. Therefore, while SA can be informative, it may not capture the full depth and complexity of traumatic experiences and their associated psychological aspects.
Regarding the qualitative analysis, the subjective categorization and selection of text segments should be mentioned as a possible point of critique. However, considering that the SAs include context only in a limited and numerical way, an additional qualitative framework is even more critical. Especially when analyzing sensitive material, such as court testimonies of detainees and interrogators of a torture prison, maintaining the original context cannot be given too much weight.
That differences in the statements of former detainees and interrogators could not be replicated through SA suggests that lexicon-based SAs might not be the best-fitting approach to address our research questions. However, within this 3-stage process, SA still offered valuable quantitative insights, and the absence of significant differences in sentiment values itself is a noteworthy finding. Ultimately, the methodological framework applied in this study is meant to serve as an example of how to combine NLP, statistical, and qualitative methods—its application in practice should be adapted based on the specific research question and the nature of the data.
Conclusion
This paper presents a mixed methods approach for analyzing court transcripts of genocide tribunals, with a specific focus on accounts of experienced torture in different witness groups. By integrating computational and qualitative methods, this study offers new perspectives on analyzing torture-related content in court transcripts. It is worth noting that this design is not exclusively tailored to genocide research but can be applicable to other fields that also seek to examine variations in emotional content within textual data.
The differences found in the last phase of this study provide a starting point for further analysis and the application of a different set of methods for finding out more about emotionally distressing accounts of witnesses in court. Providing a novel approach by bringing together QCA and NLP techniques in an MMR framework, this study leads the way to further research, encouraging the use of mixed methods in genocide research and building bridges between historical analyses and computational methods.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.