
Abstract
Assessing student knowledge based on their writing using traditional qualitative methods is time-consuming. To improve speed and consistency of text analysis, we present our mixed methods development of a machine learning predictive model to analyze student writing. Our approach involves two stages: first an exploratory sequential design, and second an iterative complex design. We first trained our predictive model using qualitative coding of categories (ideas) in student writing. We next revised our model based on feedback from instructor-users. The model itself highlighted categories in need of revision. The contribution to mixed methods research lies in our innovative use of the machine learning tool as a rapid, consistent additional coder, and a resource that can predict codes for new student writing.
Keywords
Introduction
Constructivist theory describes learning as a gradual process of learners connecting new information to their existing knowledge schema (Derry, 2011; diSessa, 2008). Assessment is the process by which instructors make inferences about student knowledge. Valid and reliable assessments rest on three elements of the assessment triangle (National Research Council, 2001): A theory of cognition about how students come to represent their knowledge in a particular domain; observations of student performance on one or more tasks, the design of which are based on the theory of cognition; and a framework for interpretation of the observations within the cognitive theory to draw inferences about student knowledge, since student knowledge is a latent variable that cannot be directly observed. Student knowledge is often probed through qualitative means such as interviews and student writing. However, qualitative analysis is time-consuming and not always free from coder bias. Recent technological advances have allowed for computerized tools (e.g., natural language processing, machine learning) to efficiently identify and categorize important ideas in student writing, which is useful for both researchers and instructors.
The methodological aim of the current work is to present our novel approach to integrating machine learning with more traditional qualitative data analysis of student writing in assessment. Complex application of core mixed methods designs (Creswell & Plano Clark, 2017) facilitates the overall research process. We highlight the benefits of our mixed methods approach: qualitative analysis enables expert identification of the most relevant correct and incorrect ideas in student writing, while quantitative methods provide a consistent, “objective” means of refining and validating the qualitative coding scheme in an integrated process for drawing metainferences about student knowledge that cannot be obtained by qualitative or machine learning alone. The integration of these approaches between human and machine outputs to produce machine learning models allows for quick iterations on rubric development and refinement and a “quality-check” on coding from the human application of the rubric, in a way that cannot be obtained with either approach alone.
There are many assessment types, from multiple-choice (where students are required to choose a correct response from a given set of choices), to open-ended constructed response items (where students must typically write the entire response in their own words (Bennett, 1993; Bennett et al., 1990). Instructors must choose items carefully since different item types may target different types of student knowledge (Birenbaum & Tatsuoka, 1987; Simkin & Kuechler, 2005). Constructed response assessments can require students to go beyond simple recall to write responses (Martinez, 1999). These items may elicit higher-order student thinking better than multiple-choice items, regardless of the thought that instructors put into developing multiple-choice items (e.g., Birenbaum & Tatsuoka, 1987; Simkin & Kuechler, 2005). However, significant time and effort are required to grade constructed response items, and the consistency of resulting grades is often questioned (Simkin & Kuechler, 2005; Stanger-Hall, 2012). To address these challenges, scoring rubrics are used to identify important concepts in student writing (Hogan & Murphy, 2007). Rubrics are also crucial for analyzing student writing efficiently for research purposes.
Recent advances in machine learning facilitate our mixed methods approach. Natural language processing (NLP), a machine learning method which allows computers to extract and analyze text, has been used in educational contexts for a number of years. (We have compiled a list of technical terms used in this paper in Supplemental Table 1, and these terms are italicized throughout the text.). NLP methods have been applied to assist in traditional qualitative analyses by applying codes automatically to text segments after researchers programmed coding rules (Crowsten, et al., 2012). In other work, Guetterman et al., (2018) used NLP to “augment” thematic coding of surveys by humans by using NLP techniques as part of a second coding phase. Such an approach provided several benefits including providing validity for human identified themes and reliably identified cases that may be missed by human coding alone. Such outcomes show the utility of using NLP as one possible approach used to triangulate qualitative analysis of text (Renz et al., 2018). Other recent applications have included NLP as part of a mixed methods design for data sets, in order to identify common topics in text documents and cluster text records based on their similarity (Chang, et al., 2021; Wulff et al., 2022).
Other applications of NLP have followed text extraction by supervised machine learning classification algorithms, which produce a predicted score or classification for each text record. These uses have included predictive scoring of student-generated text (Shermis & Burstein, 2013), intelligent agents for interactive feedback (Chi et al., 2011), and identification of students’ mental models (Lintean et al., 2012). Supervised machine learning uses a variety of statistical algorithms, based on text features as input variables, to learn, then predict, the way human coders would assign codes to text (Kotsiantis, 2007). Until recently, much of this work focused on scoring essays such as those of Educational Testing Service, which developed proprietary systems to predict expert scoring of essays for the Graduate Record Examination (Shermis et al., 1998). Research on essay scoring has demonstrated that essays have a large amount of redundant information and that content and writing style are correlated when raters assign scores to the essays (Burstein, et al., 2013). But in the last decade, supervised machine learning and NLP have found increasing use in scoring and evaluating short answer responses in assessments (e.g., Liu et al., 2014; Nehm, et al., 2012). Short-answer constructed response items, for which students write a sentence to a paragraph of text, present more challenges for automated scoring in comparison to essays, since they have little redundant information and the goal is usually to determine how students understand particular concepts rather than evaluating students’ writing and rhetorical style (Brew & Leacock, 2013). Taken altogether, NLP has become a valuable tool in many mixed method research designs (Chang et al., 2021). For example, a recent study has shown the utility of a mixed methods approach combining NLP, supervised and unsupervised machine learning with qualitative coding to examine student model-based explanations to develop a construct map (Rosenberg & Krist, 2021).
Recent reviews of machine learning in science assessment report expanding usage in a variety of disciplines, grade levels, and assessment types (Zhai et al., 2020b; Zhai et al., 2021). The most common use of machine learning with NLP has been to automate the evaluation of student assessments, although other educational applications of machine learning are reported (Zhai et al., 2020a).
One of the challenges in using NLP for text analysis for assessment is that the outputs should be pedagogically and contextually relevant to the expected use (Litman, 2016), which previous work has interpreted in a variety of ways. Linn and colleagues focused on providing real-time feedback to teachers (Donnelly et al., 2015; Gerard, et al., 2019). The authors applied a NLP tool to perform a rapid mixed methods analysis of student written responses in computerized classroom tasks for qualitative concepts which were then quantized into numerical scores. These scores provided real-time feedback to teachers about the type of help their students needed. In undergraduate biology assessment, Nehm and colleagues studied if automated tools can score student-constructed responses with human-scorer-level accuracy (Nehm et al., 2012; Nehm & Haertig, 2012), which may reduce scoring time. Similarly, Sieke et al., 2019 and Moharrerri and colleagues (2014) and others have developed constructed response items and associated automated scoring models for biology concepts. These studies used scoring rubrics to identify important ideas in student responses and train machine learning models to predict scores (or classifications) of new sets of unscored student responses. These predictive models are able to provide instructors with feedback about broad, discipline-specific categories in which their students’ responses fall.
Study Context
The purpose of this article is to articulate how qualitative methods and machine learning for the analysis of short, student-written explanations are integrated to revise coding rubrics, improve human coding, and generate machine learning categorization models within the context of college science assessment. We use as an exemplar a biology constructed-response item to elicit undergraduate thinking about human weight loss mechanisms (hereafter, the “Weight Loss item”): You have a friend that lost 15 lbs on a diet. Where did the mass go? (adapted from Wilson et al., 2006). This item targets undergraduate understanding of a key disciplinary idea in biology, the transformation of matter and energy (AAAS, 2011). It requires students to consider molecular processes to explain a phenomenon observed at the organismal level (Wilson et al., 2006). We will refer to this item hereafter as a “constructed response” item, and the associated short, student-written responses as “constructed responses.” A mixed methods approach is key to our process: the main categories of student ideas (both correct and incorrect) are qualitatively determined by experts. We integrate supervised machine learning algorithms trained on these categories into our mixed methods approach to guide refinement of these categories to allow for quantitative, consistent, and reliable characterization of student ideas.
General Steps in Machine Learning Model Training of Student Writing.

This article is structured as follows: we begin with a brief overview of our two-stage mixed methods development of a predictive model for our Weight Loss item, followed by detailed descriptions of each phase in our approach. We then provide a discussion of key theoretical and methodological considerations for our work. Lastly, we summarize the current work’s contributions to the field of mixed methods.
Two-Stage Mixed Methods Development of an Automated Scoring Model
We leveraged multiple mixed methods designs to develop our automated model in two stages. Stage 1 was adapted from an exploratory sequential design (Creswell, 2021). This Stage began with Qualitative Data Collection and Design Phases to explore student thinking about a key idea in biology. These stages were followed by Quantitative Machine Learning Model Training, and concluded with Inferences from users who applied the model to new data. Stage 1 followed a typical Model Development process (Table 1), where we collected 1183 student constructed responses (Figure 1, Qualitative Phase 1.1). We generated a coding rubric, which we then used to score student responses (Figure 1, Qualitative Phase 1.2). These scored responses served as a training set to generate a machine learning predictive scoring model (Figure 1, Quantitative Phase 1.3). As Bazeley (2018a) presented, the previous three phases are characterized by an integration of analyses rather than data sources. Instructors were able to use this predictive model to evaluate the new data of their own students’ constructed responses and receive information about the response scoring. Over a period of time, we obtained qualitative feedback from our instructor-users and from examination of new student constructed responses (Figure 1, Inference Phase 1.4), which led us to begin a new phase of mixed methods in Stage 2 (Model Revision). Mixed methods machine learning predictive model development for the Weight Loss item.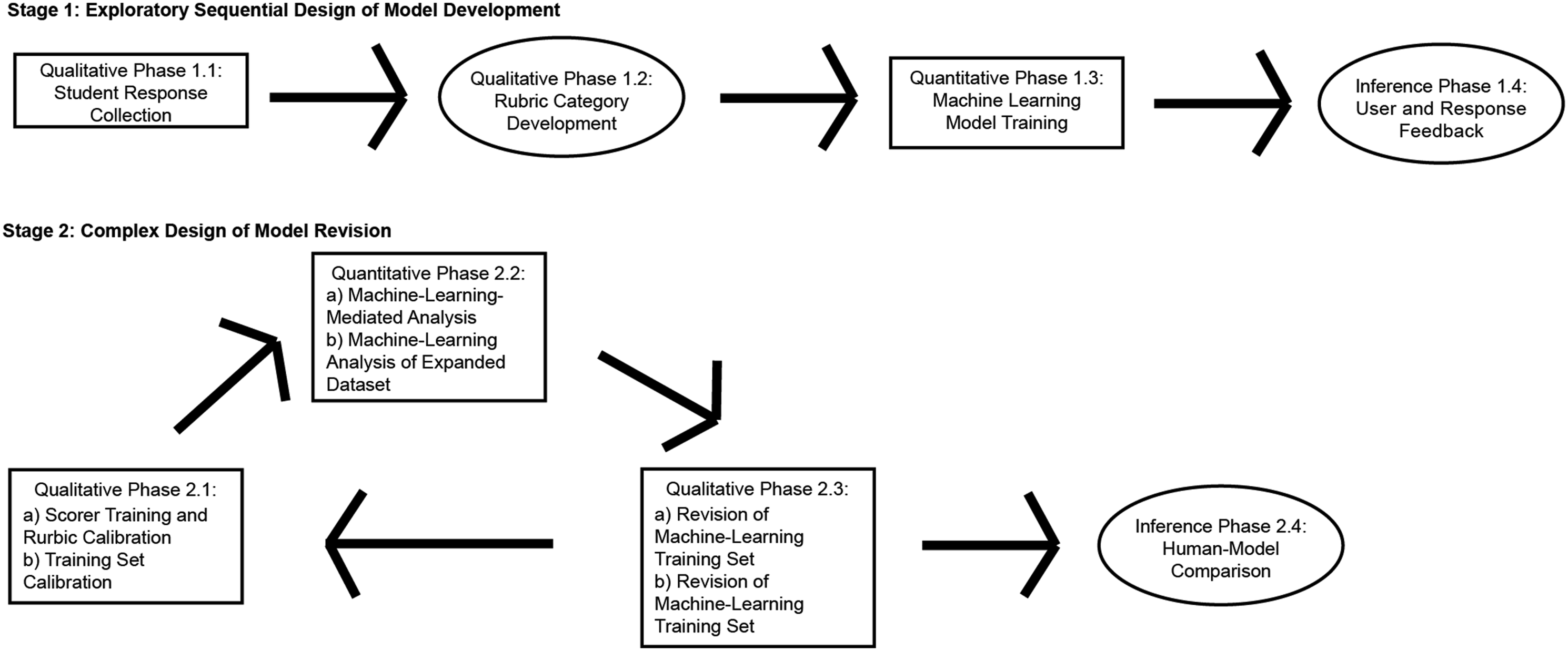
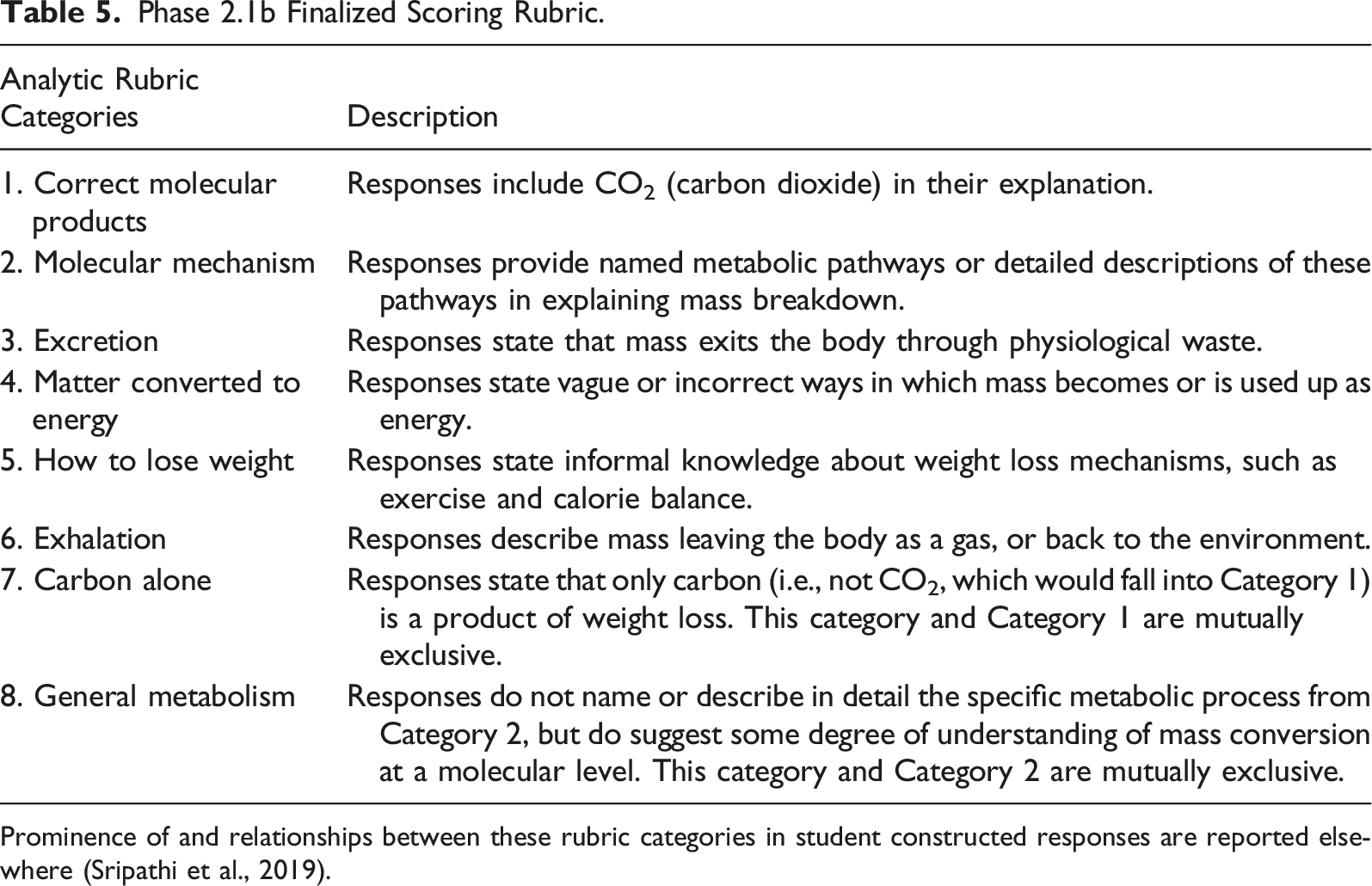
In Stage 2, we wanted to leverage our machine learning model in multiple ways, including examining a larger corpus of new student responses, revising the rubric and improving the performance of the machine learning models for some categories. As such, we integrated iterative qualitative and quantitative phases (as we did in Phases 1.1–1.3 above) in a complex design of mixed methods (Creswell, 2021; Creswell & Plano Clark, 2017). Iterations of Stage 2 are denoted by lower case letters in each phase (e.g., Phase 2.1a and Phase 2.1b). We revised the existing coding rubric from Stage 1 to analyze a new data set of 1210 responses (Figure 1, Qualitative Phases 2.1a and b). We iteratively used outputs from machine learning predictions (Figure 1, Quantitative Phases 2.2a and b) to refine rubric definitions and human scoring, resulting in a final set of agreed-upon human scores (Qualitative Phases 2.3 a and b). These agreed-upon scores were then used as the training set for an updated predictive model, including some redefined and some novel rubric categories. Our approach integrates and leverages the strengths of qualitative and quantitative methodologies: qualitative analysis of student responses defined categories deemed important by subject experts which were later transformed into variables for machine learning, as part of a hybrid approach to mixed methods (Bazeley, 2018b). While subsequent quantitative analysis with our machine learning algorithms a) helped identify qualitative coding categories that needed revision and then b) allowed consistent application of expert-defined categories to student answers.
Stage 1: Exploratory Sequential Design of Model Development
Qualitative Phase 1.1: Student Response Collection
We collected 2544 student responses to our Weight Loss item from undergraduates enrolled in introductory biology courses for life science majors from three large public universities as our corpus. All institutions are classified as “Doctoral Universities: High Research Activity” or higher in the Carnegie classification system (The Carnegie Classification of Institutions of Higher Education, n.d.). Authors’ Institution Institutional Review Board classified our study as exempt (IRB x10-577 and STUDY00001648).
Qualitative Phase 1.2: Rubric Category Development
Phase 1.1 Rubric Categories for the Weight Loss Item Automated Model.

We selected simple random samples of responses for human qualitative coding from our corpus using a random number generator. The process of training human scorers proceeded in two rounds. In Round 1, three scorers (One Ph.D and two graduate students in biology) scored the same set of 75 responses using the analytic rubric in Table 2. Initial Fleiss’ kappa values among the three scorers varied widely (range = 0.07–0.81), with an average value of 0.47 ± 0.29. Disagreements in assigned scores were resolved by discussion among the three scorers until an agreement was reached. Subsequently, one of the original scorers trained the fourth scorer. Scorer training was deemed complete when Cohen’s kappa values for independent scores for each category from pairs of scorers was ≥ 0.6 (range 0.73–1). This threshold value falls into the range of substantial inter-rater agreement as defined by Landis and Koch (1977, p. 165). Hereafter, we will use these defined cut-offs to describe levels of interrater reliability (IRR) in this paper. The trained scorers scored a total of 1183 responses, which were used as a training set for machine learning in the next phase. Categories 2 and 5 were not part of the initial training set for developing a machine learning model, as these two categories had the lowest IRR among human coders (Fleiss’ kappa of 0.07 and 0.22, respectively). Category 2 from the initial rubric was subsequently split into two other categories to capture different physiological processes and more precisely define scoring criteria in later revisions of the rubric (Categories 2 and 7 in Table 3). Category 5 was dropped from the rubric entirely because of its very low occurrence in the initial set of scored responses.
Quantitative Phase 1.3: Machine Learning Model Training
Once sufficient agreement was obtained among human scores, as described in Phase 1.2, the agreed-upon scores were used to train our machine learning algorithms, called the Constructed Response Classifier tool (CRC tool) (see Jescovitch et al., 2020). A training set for supervised machine learning model development consists of a set of student responses, each of which is assigned a dichotomous score for each rubric category, and which allows the machine learning algorithms to determine which features in student responses are required for membership in a given rubric category via different classification algorithms. Briefly, the Constructed Response Classifier tool (CRC tool) Tool uses the R package RTextTools (Jurka et al., 2013) for text processing, including stemming, stop word removal, and feature extraction. This results in a matrix of extracted N-grams from the responses. RTextTools provides support for a bag-of-words classification approach to NLP (Wallach, 2006). The resulting matrix is input for a series of eight machine learning classification algorithms. We employ an ensemble model method (Caruana et al., 2004; Large et al., 2019; Zeng et al., 2014) which utilizes multiple classification algorithms to make a prediction for each response for each category (see Supplemental Materials for more details). In an ensemble method, a series of classification algorithms each independently makes a prediction about the classification of each response; the outputs of the individual algorithms are combined in order to produce a final, single output prediction. The machine predicted scores are compared to the human-assigned score for each item, and Cohen’s kappa, among other agreement measures, is calculated for human–machine IRR. There are a wide variety of metrics that can be calculated to examine machine learning model performance (see Ferri et al., 2009), a subset of which we used to evaluate the outcomes of the machine learning model training. We report Cohen’s kappa values here to represent the agreement between human consensus scores and computer predicted scores since this measure accounts for chance agreements (McHugh, 2012). The machine learning model had a training set of 1175 responses and predicted scores for Categories 1, 3, 4, and 6. Cohen’s kappa values between human and machine for the four categories were 0.96, 0.39, 0.69, and 0.86, respectively. When the research team reviewed the results, both quantitatively and qualitatively, we determined that the low human–machine agreement for Category 3 (Kappa = 0.39) was likely due to low frequency of responses in this category (<10% of the training set). Since Category 3 represents an idea that corresponds with correct responses, the low kappa value for this category was one factor that prompted our Model Revision Stage, described in more detail below.
Inference Phase 1.4: user and response feedback
The resulting model was used to predict whether Categories 1, 3, 4, and 6 were present or absent in each response from new student data sets collected by college biology instructors. The predictive scoring model forms the basis of an interactive web site that uses an instructor’s uploaded data set to generate an online report which provides an instructor with a variety of quantitative summaries indicating students’ performances in each of the four rubric categories specified above. These reports include in-depth qualitative information such as categorization of individual student responses, co-occurrences of responses in pairs of categories, and predominant terms in responses in each category.
We received feedback from some instructors that responses they deemed correct were not being accurately characterized as such by our predictive model. Specifically, our model seemed unable to distinguish two unique uses of relevant ideas in student responses. Another potential cause of reduced model performance was deemed to arise from the inclusion of student-response data sets from an expanded group of institutions compared to our initial sample set. These responses included ideas beyond those defined in our initial rubric (Table 2), as well as different student languages expressing the same ideas captured in the rubric. Because these two aspects are common issues in text analysis, the most effective way to address them was through a comprehensive Model Revision (our Stage 2, below)
Stage 2: Complex Design of Model Revision
Stage 1 provided insight into the multiple ways that our machine learning model could aid in rubric revision, which we were further able to leverage by a complex mixed methods design of machine learning model revision in Stage 2. This led to an iterative interplay between quantitative machine learning analysis that informed qualitative rubric and training set revision, which was then quantitatively analyzed by the predictive model. Although a single sequential pass through Stage 2 shares features with exploratory sequential design, in practice, model revision is very frequently iterative (Stage 2; Figure 1). These iterations allow feedback between the processes of human coding, defining rubric criteria, and adjusting technical settings of the machine learning model, and may occur multiple times. Therefore, we conceive of Stage 2 as a complex application of a core mixed methods design (Creswell & Plano Clark, 2017) in a process to produce aligned assessment items, scoring rubrics, human scores, and predictive scoring models (Urban-Lurain et al., 2015). The phases within Stage 2 were conducted iteratively until Cohen’s kappas between human agreed-upon and machine-assigned scores were ≥0.6 as a benchmark threshold. The training set was then used to build a revised predictive model. For clarity in the text, phases are presented linearly. Phase names from the first iteration are appended with “a,” and those from the second iteration are appended with “b”.
Qualitative Phase 2.1a: Scorer Training and Rubric Revision
Phase 2.1a Analytic Scoring Rubric.

aModified from corresponding category in Table 2 above.
bNew category added based on instructor feedback or trends in student writing.
Example of Pairwise Scorer Assignment for 600 responses.

Note: Individual scorers are indicated by letter.
Cohen’s kappa values were calculated for each pair of human scorers for each rubric category and averaged. All categories except Category 2, about non-relevant physiological processes, (Table 3) had average kappa values of 0.699 or greater, considered as substantial agreement. Category 2 had an average kappa value of 0.167, indicating only “slight” agreement (Landis & Koch, 1977, p. 165). This low agreement persisted despite the scorers’ efforts to define the category for human scoring better, and the category was too broad for scorers to apply consistently. Coupled with the limited disciplinary relevance of this category, the scorers agreed to discard this category for future scoring rounds. This scoring effort also led to the addition of a new category to the rubric about general transformations of matter (Category 9, Table 3), which we felt represented emergent trends in student data that were not captured by previous rubric versions. The set of agreed-upon scores using the rubric in Table 3 for a total of 710 constructed responses provided the training data set for our machine learning model.
Quantitative Phase 2.2a: Machine-Learning-Mediated Analysis
In Phase 2.2a, we analyzed the 710 human-scored responses using our the Constructed Response Classifier tool (CRC tool) Tool. The process for development and application of supervised machine learning models is provided in Figure 2. This represents a key point of methodological integration in our process because it quantizes scores that have, up to the current phase, been based on qualitative codes. A set of student responses in the Training Data set is scored by humans using coding rubrics, such as the ones shown in Tables 3 and 5. Text pre-processing extracts text Features from the Training Data. These extracted features are used as independent variables in the Machine Learning Model Training, which also uses the Human Agreed-Upon Scores for each response as the dependent variables. The supervised machine learning models we employed, iteratively develop, then apply classification algorithms to predict the human-assigned scores using a cross-validation procedure. These scores are compared with the expert scores during Predicted Score Validation. When these validation measures of machine learning model performance, like Cohen’s kappa (≥ 0.6), are acceptable, the resulting Machine Learning Model is considered developed and can be used to predict scores on New Data (i.e., newly collected student responses) for the same question. General workflow of the development of our predictive model to highlight qualitative and quantitative data integration Phase 2.1b Finalized Scoring Rubric. Prominence of and relationships between these rubric categories in student constructed responses are reported elsewhere (Sripathi et al., 2019).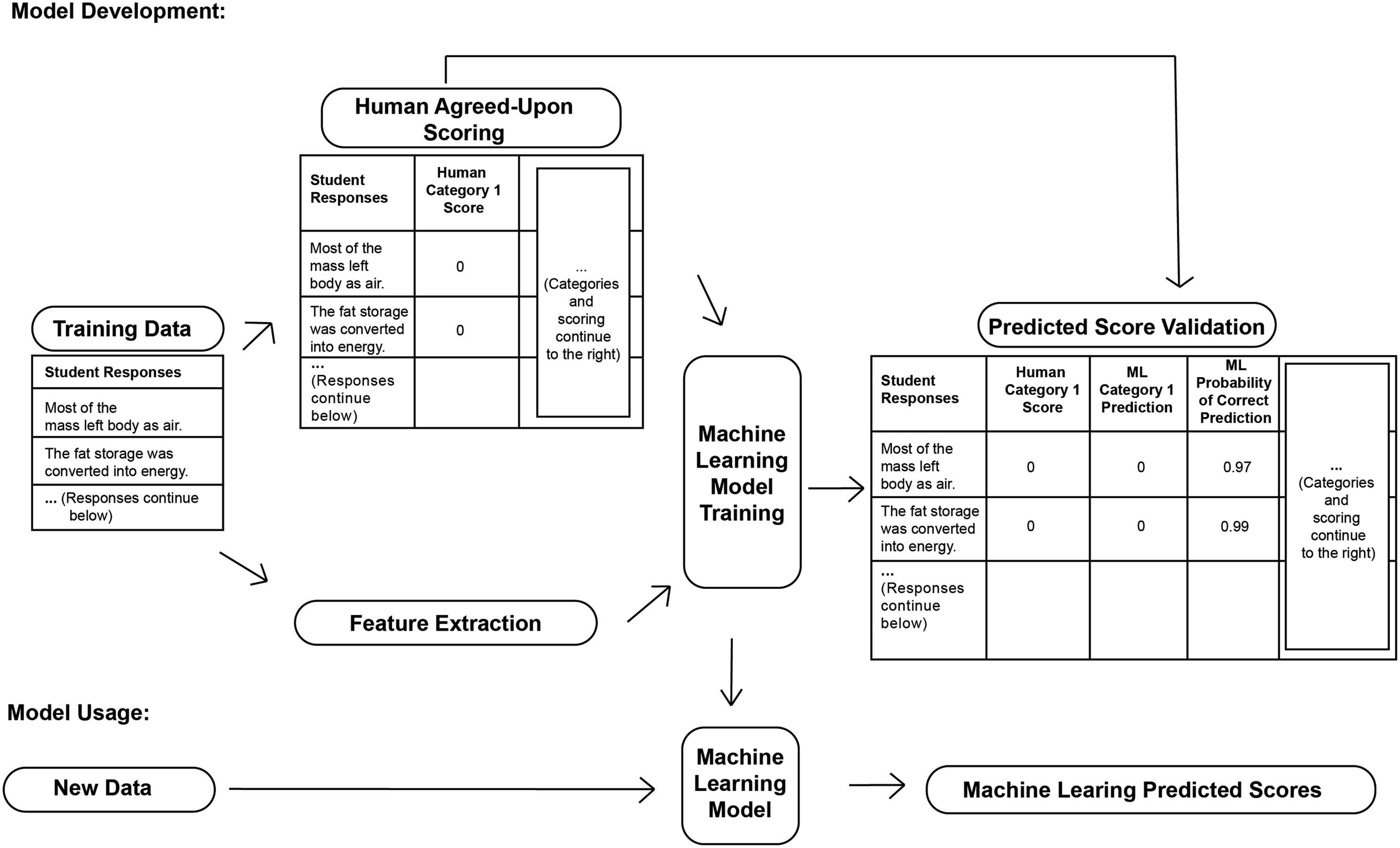
Using this procedure, the Constructed Response Classifier tool (CRC tool) Tool returned predicted scores for each rubric category (Table 3) for each constructed response. Most rubric categories yielded human–machine kappa values of ≥0.6. However, Categories 5, 8, and 9 (Table 3) were the lowest-performing categories (Cohen’s kappa = 0.71, 0.66, and 0.49, respectively). Although Category 5 was well above the ≥ 0.6 Landis & Koch threshold, responses in both Categories 5 and 9 appeared to have significant diversity of student language. We wanted to investigate how the machine learning model handled this diversity.
Qualitative Phase 2.3a: Revision of Machine-Learning Training Set
In Phase 2.3a, we reviewed human scores and rubric categories for each response where human agreed-upon and machine learning predictions differed (Categories 5, 8, and 9, Table 3). For Categories 5 and 9, the lead scorer compared the human agreed-upon and machine learning model scores, leveraging the ability of the machine learning model to be a rapid, consistent third scorer. We used the machine learning predicted scores to draw our attention to two potential issues in the human scoring process. First, a disagreement between human- and computer-assigned scores may indicate that the machine identified something in the response that human scorers had not. Second, more disagreements than expected within the same rubric category may indicate a need to re-examine that rubric category definition. To address the first issue, the lead scorer reviewed all the human–machine disagreements. If she deemed that a response’s machine prediction correctly assigned a classification based on her reading of the response, she changed the human score to agree with the machine learning prediction model. Conversely, the lead scorer did not modify a score for a given response when she agreed with the human agreed-upon score. In cases when the lead scorer was unsure, she contacted the assigned tiebreaker about the response. When the tiebreaker was unsure, such responses were discussed with the entire group of scorers. These efforts were intended to ensure that the human assigned codes were as consistent as possible. Further, to address issue two, categories with many disagreements were brought to the attention of the entire coding group, which then considered if or how the rubric category definition should be clarified. This was an attempt to ensure the coding criteria used by human coders were well-defined and consistently understood and applied by all coders. As such, each scoring discrepancy between human and machine scores went through a multi-stage review and verification process.
The group decided on a different course of action for Category 8 because this category occurred infrequently in the training set of 710 responses. Only 12 responses were scored in this category by humans, and only 9 responses were predicted by the machine learning model. Although rare in the training set, the group decided to continue to score for this category, as this category was developed in response to faculty user feedback (Phase 1.4). As such, the group decided to score another set of 500 responses for all categories, but enriched with responses that might be classified into Category 8. To enrich the new scoring data set, the lead scorer selected a new set of student responses (n = 556) from a subsequent data collection, that had a strong possibility of containing key phrases that scorers used to classify responses in Category 8. She randomized this set of responses with other un-scored responses from the original corpus (total remaining unscored responses, n = 2390), and selected the first 500 responses of this new subset to distribute to scorers.
Qualitative Phase 2.1b: Training Set Expansion
As in Phase 2.1a, the new set of 500 responses was distributed among scorer pairs such that each set of 100 responses was scored by two unique coders with another individual to serve as a tiebreaker, following the same scheme shown in Table 4. These responses were scored using the revised scoring rubric summarized in Table 5. This revised rubric took into account the changes from Phase 2.1a, including removing one category and adding another. Scoring disagreements from any pair that the designated tiebreaker could not solve were brought to the entire group of scorers for discussion. The resolutions of disagreements resulted in a total of 1210 human-agreed-upon-scored responses, taken from a total corpus of 3100 (the new corpus total after the enrichment described at the end of Phase 2.3a above).
Cohen’s kappa values were again calculated for each pair of scorers and averaged, for each rubric category, with all but one value ≥0.6. Category 8, about general transformations of matter (Table 5), continued to have a low average kappa value of 0.37. To improve all categories’ kappa values, but particularly that of Category 8, to ≥0.6 agreement, we next used the machine learning model to predict scores for the 1210 human-agreed-upon responses.
Quantitative Phase 2.2b: Machine-Learning Analysis of Expanded Dataset
In Phase 2.2b, we used our machine learning model to predict scores for our set of 1210 human-scored responses (a combined result of scoring efforts in Phases 2.1a and 2.1b). Human–machine kappa values for all categories (i.e., 1–8, Table 5) were ≥0.6. Category 8’s larger kappa value for a human–machine agreement was an unexpected improvement over the human-human kappa value (Phase 2.1b above) and is likely due to two factors. First, the expansion of the training set increased the number of responses, and consequently the number of unique N-grams, that our machine learning model could analyze for this category. This allowed the machine to “learn” a broader range of text features associated with this category and therefore correctly identify more student responses that belonged in this category. Second, the group made an effort to reconcile discrepancies between human agreed-upon and machine learning model scores for Category 8 in the first training set of 710 responses, as outlined in Phase 2.3a. Since the machine learning model was trained using the entire corpus, which contained consensus scores from pairs of all six scorers, the resulting model identified patterns for score predictions that were shared between multiple scorers. During the review of mis-classifications, the group identified some instances where pairs of scorers agreed on an assigned code for the response but seemed to drift from the group consensus of the category definition, leading to a “mis-score” by the computer. This metainference stems from a key point of methodological integration in that the machine learning model acted as a proxy for the group of scorers to identify when scores assigned by pairs of scorers drifted from the interpretation of rubric criteria applied by other coders. Fixing these mis-classifications by asking human coders to reapply the rubric helped restore a shared understanding of criteria by the entire group. The combination of these two factors likely explains the significant increase in human–machine agreement in Category 8 during this phase.
The group also generated machine learning predictions on a training set excluding 14 responses from the full set (n = 1196) that were deemed edge cases. “Edge cases” were defined by the group as those responses on which even after group discussion, the six coders could not reach agreement for the scores of one or more categories. In all 14 cases, this is because these responses would require the scorers to make assumptions about the student’s intended meaning. Most human–machine learning kappa values increased slightly with this new training set without edge cases, while Category 8’s value remained comparable (0.62).
Qualitative Phase 2.3b: Revision of Machine-Learning Training Set
In Phase 2.3b, the group checked human scores for categories (summarized in Table 5) which had a high number of disagreements between human agreed-upon and machine predicted scores to improve the predictive accuracy of the machine learning model. These categories were: 1) Category 8, about general transformation of matter (n = 121 mis-scorings), 2) Category 4, targeting a common student alternate conception (n = 110), and 3) a near three-way tie between Categories 3, 5, and 6 (n = 86, 89, and 81, respectively). Similar to Phase 2.3a, for these three categories, the lead scorer assigned three scorers one category each to assess disagreements between human agreed-upon and machine learning model scores. Each scorer determined whether they agreed with the human or machine score for each response. After another independent read of the response, if the scorer agreed with the human agreed-upon score for a given response in a given category, the human score was left unchanged. If the scorer agreed that the machine learning model score for a response in a given category was correct based on something they identified in the response, the scorer revised the human agreed-upon score to match the machine assigned score. Those mis-scores that a scorer could not easily resolve were brought to the group for further discussion. This process left us with a training set of 1192 responses after removing some duplicate responses in the data set.
We analyzed this modified training set using the machine learning model to assess model improvement based on our refinement of human scores (for performance measures of the final machine learning model, see Supplemental Table 2). Our revisions resulted in Cohen’s kappa values of ≥0.6 for all categories. Category 7 had the lowest kappa value (k = 0.65). We justify our decision to use this category’s model since so few human-scored responses for this category in our training set (n = 61) still yielded a reasonable agreement between human and machine learning model scores. Additionally, Category 7 was relevant to understand student thinking about the phenomenon of weight loss. Details regarding the frequency of and relationships between rubric categories in student written explanations and their relevance to learning of key ideas in biology is described elsewhere (Sripathi et al., 2019).
Inference Phase 2.4: Human-Model Comparison
Once we had achieved machine learning parameters for a mature model, we conducted Phase 2.4 (Inferences Drawn; Figure 1) using our mixed methods predictive model to draw metainferences about our Model Revision Stage as a whole. Previous work has shown that computer models can exhibit high IRR with human scorers (Ha et al., 2011; Nehm et al., 2012). However, these and other works described computer agreement with human scorers well-trained on the rubric, who have high IRR among themselves. Other work has suggested that coder experience may impact human–computer agreement measures (Powers et al., 2015). Because we had extensively cataloged pairwise kappa values for our six human scorers throughout our Model Revision process (i.e., Stage 2), we investigated relationships between human–human and human agreed-upon-machine learning-model IRR. What associations, if any, were there between high- and low-reliability categories? What might these relationships tell us about the coding process as a whole?
To investigate these questions, we constructed a plot of our average Phase 2.1a Cohen’s kappas for human–human agreement versus machine prediction agreement with human agreed-upon scores of the entire training data set, before revisions in Phase 2.3b occurred (N = 1210). In essence, we treated the machine learning model as another rater and explored whether its agreement is associated with the initial agreement between two human coders in Phase 2.1a. Our results (Figure 3(A)) showed a reasonably strong, positive linear relationship, with categories with high initial agreements between scorer pairs resulting in high human–machine agreements. Notable examples of this case are Category 1 and Category 6 from Table 5, which had high initial human–human IRR (indicated by blue points in Figure 3(A)). These categories likely resulted in a high degree of agreement due to 1) the low diversity of language in student responses (Figure 3(B); similar to trends reported in Ha et al., 2011) and 2) detailed rubric category definitions. Conversely, those categories with lower initial human-human agreement typically resulted in lower human–machine agreement compared to other rubric categories. Although a small sample, we computed Spearman’s rank correlation to examine any possible relationship between human–human kappa during the first round of coding and human–machine kappa from the finished machine learning model. There was a positive correlation between the variables, but not statistically significant, rs(5) Comparison of initial human–human and human-agreed-upon-machine learning-model Cohen’s kappa values. (A) Dotted line represents line of best-fit of the data points. Important categories discussed in the text are colored and labeled with category numbers. The black dots represent the rest of the categories. (B) Examples of responses falling into each of the highlighted categories in Panel A). Relevant portions of the responses that resulted in human scoring into each category are underlined in black.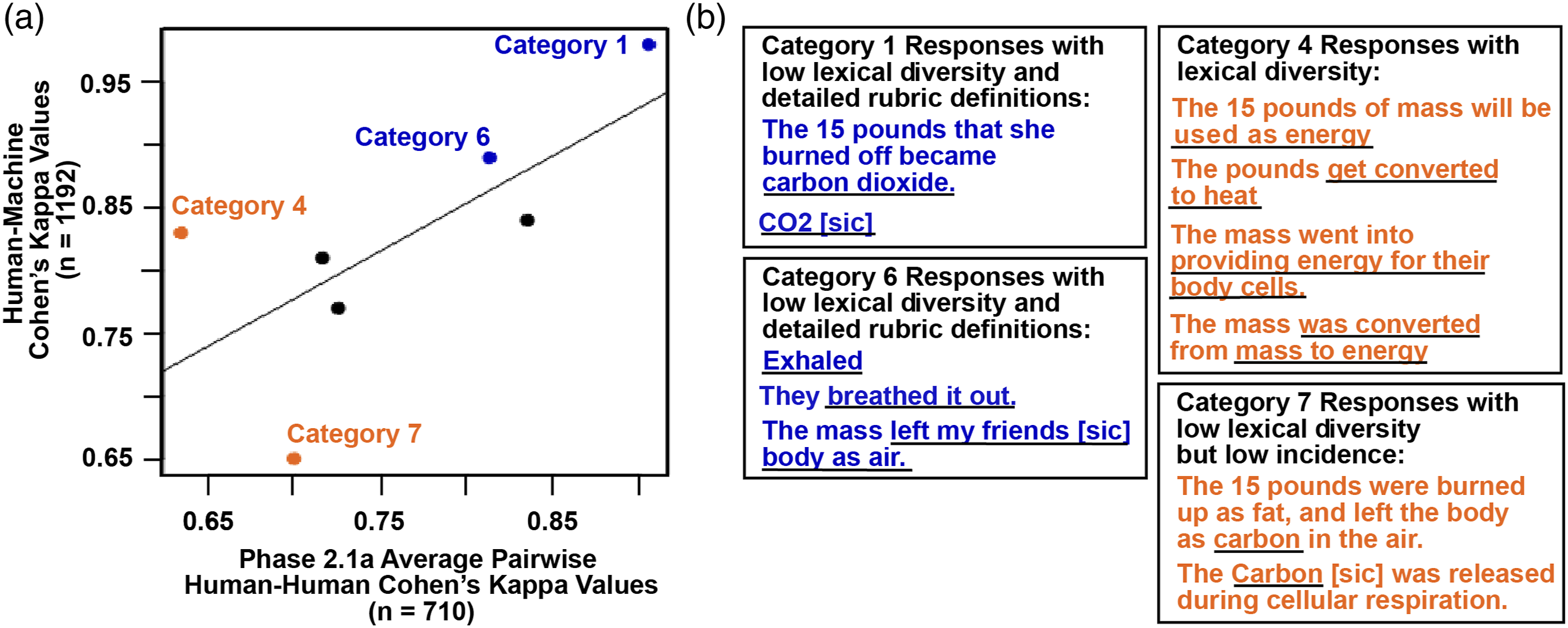
Two examples of a category with low agreement by human–human but different outcomes in the human–machine agreement are Categories 4 and 7 (orange data points in Figure 3(A)). Category 7 fit criterion 1 above in that the category exhibited low diversity of student language. However, we believe the reason for its low human–machine agreement is due to the very small number of responses scored by both humans (final n = 61) and the machine learning model (n = 34) in this category. In contrast, Category 4 from Table 5 had a low initial human–human agreement but ended with high human–machine agreement. The comparatively low human–human agreement (x-value = 0.63) was likely due at least in part to the high degree of diverse language that characterized student responses in this category (Figure 3(B)). The high human–machine agreement (y-value = 0.83) can likely be explained by score revisions for Category 4 as part of Phase 2.3b above. Category 4 is thus an example of how the machine learning tool allowed us to focus on response and category revisions to both clarify a rubric category definition and improve predictive model performance.
Discussion
We have summarized our mixed methods approach to integrating qualitative analysis and with predictive machine learning models to categorize student constructed responses. As an exemplar, we presented our work on an item on human weight loss targeted at introductory undergraduate biology courses. A mixed methods approach was crucial to our procedure: student thinking has traditionally been probed through qualitative means. However, there are many challenges to creating and applying qualitative scoring rubrics in a reliably consistent, unbiased manner. We were able to collect student written data in sufficient numbers that allowed us to integrate qualitative analysis with machine learning to draw metainferences about the nature of the student responses that would not have been possible by using either method alone. Focusing our analyses on a single paradigm would have required us to sacrifice either the breadth or the depth required for our model to accurately categorize new student data. Our approach results in theoretical and methodological considerations for individuals engaging in similar work, which we summarize below.
Scoring Rubrics as Research Tools in Mixed Methods Analysis of Student Writing
Several of the methodological considerations that we encountered may be useful for others’ work on analyzing textual data. As indicated above and in previous work (Haudek et al., 2015), a key component of our mixed methods approach is the development and revision of scoring rubrics which we used to score responses for training our machine learning models, which acted as a rapid and consistent third coder. Examining scoring discrepancies between human- and machine-assigned scores allowed us to quickly identify rubric categories that likely required revision in criteria for human coding.
A critical consideration when designing rubrics to score textual data is how best to maximize initial agreement between raters. In addition to traditional problems presented by low interrater reliability, our methodology reveals the added challenge of low human–machine reliability and, thus, low reliability for subsequent machine learning predictions for those categories (see section Phase 2.3b and Figure 3 above). This highlights the importance of well-defined rubric categories and explicit criteria to characterize student writing, as well as the need for a linguistically diverse data set. These lessons are applicable to many qualitative researchers and should be kept in mind even when not using machine learning. By using machine learning as a consistent “coder,” we have been able to identify when raters drift in their application of rubrics and reduce the tendency to gloss over differences among rater interpretation.
More broadly, our investigations call into question traditional qualitative coding practices. Typically, two or three coders meet to create, apply, and refine codebook definitions, but they may not revisit their process in a rigorous or iterative fashion. Many times, disagreements are resolved either through majority voting or discussion until consensus is reached among coders. Our comparisons here suggest this may be problematic. While categories with initial high human–human agreement tended to stay high (Categories 6 and 1), some categories (Category 7) never recovered from early low human–human agreement despite careful and iterative revisions. Our results thus call into question the reliability of traditional methods of achieving agreement on qualitative codes. We hope readers will take this into consideration when conducting their own analyses.
Limitations of Our Approach
Although we have leveraged machine learning to automatically assess large sets of novel student data, our approach is subject to limitations. The first limitation is the scoring rubrics upon which our model is based. Although our rubrics are robust because they are based on actual student ideas and writing, the rubrics are similarly limited by the language in our corpus. We attempted to address this by collecting data from a variety of universities and classes to maximize lexical diversity. Although we collected responses from undergraduates at research intensive universities, subsequent studies have found little difference in student responses to this item collected from a variety of institutional types (Uhl et al., 2021). However, even a limitless supply of data cannot address the second limitation to our work: that of term occurrence. Our team develops analytic rubric categories based on frequently occurring student language. We encountered many examples of interesting student language that were not incorporated into our rubrics. The reasons for this exclusion are twofold: 1) our aim is to identify broad trends in student language and student understanding; 2) our machine learning-model depends on terms that frequently occur enough to be useful in the predictive algorithms, and terms which occur only infrequently are generally not useful in these models. Despite these drawbacks, we believe our approach is very powerful both in uncovering new trends in student thinking about key scientific concepts during model development and in identifying persistent trends of student thinking in novel datasets. Finally, we acknowledge a relatively small sample size for our examination of the association between initial human coding agreement and final machine learning model-human agreement. A larger data set would lend more confidence to these quantitative findings.
Contribution to the Field of Mixed Methods Research Methodology
Our study contributes to the field of mixed methods research by highlight how to integrate qualitative analysis of student writing with NLP and machine learning to allow us to draw metainferences about not only student knowledge, but as an integral process for creating and scoring assessments. Our contribution complements recent work (e.g., Chang et al., 2021; O’Halloran et al., 2018) by demonstrating another way in which machine learning can be used as a hybrid method of qualitative and quantitative analyses integration. While their work focuses on using machine learning predictions to thematic coding (Chang et al., 2021) and focuses on data of multiple types (O’Halloran et al., 2018), our approach focuses on refining existing codes. Similar to Chang et al.’s (2021) approach, our approach is also inherently a hybrid integration of mixed methods (Bazeley, 2018b): We rely on periodic evaluation of machine–human disagreements in scoring (coding) to refine either our scoring or our rubric definitions. Therefore, our use of quantitative machine-learning-assigned scores forms an inherent portion of our qualitative coding.
Our use of machine learning predictions also has implications beyond the mixed methods community. Although typical qualitative analysis is conducted by agreement between two or three coders, such agreement is not always consistent among segments of coded data or, indeed among individual coders themselves. Intra-coder reliability can “drift” from one timepoint of coding to another (Bierema et al., 2020; Given, 2008). Additionally, coders may be subject to any number of cognitive biases (Kliegr, et al., 2018). For example, a rubric category may have been generated due to the mere exposure effect (summarized in Kliegr, et al., 2018), in which researchers may show a preference for those ideas to which they are more frequently exposed. Even if human scorers subconsciously prefer student data that occurs repeatedly in a dataset, the resulting rubric category must be precisely defined by criteria and revised if it does not perform well in machine learning model predictions. Further, traditional resolution of human–human disagreements may take several forms, including majority voting or consensus discussions. However, these resolutions in code assignment may not always address the underlying problem in the initial disagreement, for example, poorly defined rubric definitions or coder interpretation of meaning. Using a machine learning model as a third coder to attempt to learn and apply classification rules helps identify such issues and promotes rapid iteration of rubrics. Thus, the hybrid mixed method approach described here underlines the utility of using machine learning tools to improve consistency in qualitative coding.
More broadly, our work demonstrates integration in several dimensions of the Integration Trilogy (Fetters & Molina-Azorin, 2017). In the Theoretical dimension, we integrate constructivist theories of learning, modern assessment theories, qualitative analysis frameworks, and quantitative methods that are philosophically grounded in pragmatism (e.g., Dewey, 1948; James, 1907). In the Researcher and Team dimensions, our team is very interdisciplinary (e.g., biologists, discipline-based educational researchers, assessment experts, and machine learning experts). Each team member brings strengths and expertise in some but not all areas. We had to grapple with the challenges that interdisciplinary research teams face in learning to understand, respect, and use the perspectives of other team members so that we could agree on how to approach our work. Each researcher must understand the scope of the project and learn enough about all aspects and methods to communicate and function effectively, and agree upon goals and approaches. All of these feed into the Rationale dimension: why would researchers go to all of this effort? In our experience, we have found that the efforts not only produce results that cannot be obtained by any single methodological approach, but that this work has actually broadened all our perspectives as researchers and academics.
In the Research Design, Data Analysis, and Interpretation dimensions, it is imperative that these elements are all integrated in any well-designed and executed research project, regardless of the method. However, since we are mixing what are often thought to be orthogonal approaches, this requires more meta-integration: not only must the design, analysis, and interpretation be defensible in the qualitative domain (e.g., emergent coding, consensus coding) and in the quantitative domain (e.g., metrics to be used in machine learning, how should algorithms be adjusted) but we must integrate them in the iterative refinement of each method in the context of the other to maintain the integrity of those approaches. This hybrid mixed methods approach and resulting quantitative outputs act as validity and reliability checks on more traditional qualitative analysis and outcomes (Guetterman et al., 2018). The qualitative analysis is an interpretative act that infers meaning about student knowledge from their writing; that inference can be extended by the application of the resulting machine learning algorithms to new student responses. Finally, in the Dissemination dimension, our team has been attempting to broaden the audiences for our work. We have published in biology, chemistry, statistical, and engineering journals for both research and teaching audiences in those disciplines, and educational journals for the education community, both in technology oriented and broader teaching and assessment journals. This is our first foray into dissemination specifically for the mixed methods community. We hope that this effort encourages others to consider some variation of our approach in their own research.
Future Directions
We see several areas ripe for future mixed methods research based on our framework. We mentioned the limitation of the breadth of our scoring rubric above: we would be very interested in trends that other researchers uncover by analyzing data from wider student populations (e.g., students from upper-level undergraduate courses) and how trends in these new data sets compare with those we have described previously. Additional future directions could include the development of machine learning or other automated tools that can identify less frequently occurring but very interesting student language that our model can currently not capture. Lastly, we have described the analysis of student textual data using NLP and supervised machine learning methods; we suggest continued exploration of NLP and unsupervised machine learning of textual data to identify topics and clusters of similar documents (e.g., Wulff et al., 2022) to aid rubric development (e.g., Rosenberg & Krist, 2021) or reduce human coding effort as part of mixed methods.
Summary
Our experience using NLP and machine learning tools to support mixed methods analyses of student writing about various concepts indicates that our methodologies are transferable to core concepts in other disciplines (e.g., Noyes et al., 2020). Our approach combines qualitative analysis with statistical and machine learning analyses of diverse datasets to maximize reliability and generalizability of our predictive models. We believe several aspects of our approach are applicable to similar work in other fields. We have outlined how we generate analytic scoring rubrics as research tools to describe trends in textual data. We have developed predictive models for assessment items in a variety of STEM fields using methods analogous to those described here. Interested instructors and researchers can find items and their predictive models on our research group’s website
Supplemental Material
Supplemental Material-Machine Learning Mixed Methods Text Analysis: An Illustration From Automated Scoring Models of Student Writing in Biology Education
Supplemental Material for Machine Learning Mixed Methods Text Analysis: An Illustration From Automated Scoring Models of Student Writing in Biology Education by Kamali N. Sripathi, Rosa A. Moscarella, Matthew Steele, Rachel Yoho, Hyesun You, Luanna B. Prevost†, Mark Urban-Lurain, John Merrill, and Kevin C. Haudek in Journal of Mixed Methods Research
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: We gratefully acknowledge members of the Automated Analysis of Constructed Response research group for helpful conversations. This material is based upon work supported by the National Science Foundation (DUE 1323162 and 1347740).
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.