
Abstract
Machine learning techniques (MLTs) are increasingly being used to develop clinical risk prediction models for binary health outcomes but the sample size requirements for developing and validating such models remain unclear. This study investigates whether sample size guidelines that target mean absolute prediction error (MAPE) for logistic regression models can be applied to tree-based ensemble MLTs (bagging, random forests, and boosting). Simulations based on two large cardiovascular datasets were used to evaluate the performance of MLTs in terms of MAPE, calibration, the C-statistic and Brier score, across six data-generating mechanisms (DGMs) and varying sample sizes. When the DGM and analysis model matched, boosting required a sample size 2–3 times larger than recommended; random forests and bagging did not achieve the target MAPE even with a 12-fold increase. For a neutral DGM that did not match any of the analysis models, logistic regression with only main effects and boosting resulted in target MAPE values with a 12-fold increase in the recommended sample size. For external validation, our simulations showed that sample size guidelines to achieve a target precision of the estimated C-statistic were suitable, and thus may be used to inform sample size calculations for MLTs.
Introduction
Clinical risk prediction models can support medical decision-making by estimating the risk of a health outcome such as disease progression, complications, and mortality. Logistic regression is commonly used to predict the risk for binary outcomes using patient-related information such as demographic and clinical characteristics (predictors). Over the past decade, the use of machine learning techniques (MLTs) has gained increasing attention in risk prediction for health outcomes. 1 For example, gradient boosting has been used to predict the risk of death in patients with coronavirus disease 2019 (COVID-19), 2 random forests (RFs) have been applied to predict Type 2 diabetes risk using large-scale health check-up data, 3 and neural networks have been used to improve pre-existing cardiovascular risk prediction models. 4
The development of clinical risk prediction models involves estimating the relationship between the outcome and predictors. In regression-based models this entails estimating the regression coefficients, which can then be used to calculate the probability of the event given specific values of the predictor variables. The performance of the developed model is then assessed through either internal validation using a portion of the development data not used in model development or external validation using entirely new data. In MLTs, the model development step involves building a model to identify patterns in the data and making accurate predictions based on these patterns. Previous research suggests that the benefits of MLTs over conventional logistic regression in clinical prediction modelling arise when complex relationships exist between the outcome and predictors such as non-linearities and interactions. 5 Therefore, MLTs may perform better than regression-based approaches in high-dimensional data with complex structures such as electronic health record data. 6 We note that, complex data structures involving non-linear and interaction effects can be incorporated in regression models by including additional terms in the regression equation. However, fitting such models require larger sample sizes compared to regression models with only (linear) main effects due to the increased number of parameters.
Several systematic reviews have found that studies using MLTs for risk prediction models often lack a justification for the sample size used. Only 17.8% (n = 27/152) of studies provided a justification, with the most common justification being the size of the available data. 1 Dhiman et al. 7 reported that only 8% (n = 5/62) of the studies using MLTs to develop prediction models had justified their sample sizes, with these studies having lower events per variable (EPV) than studies using regression-based models (median: 3.4, interquartile range (IQR): 1.1–19.1 versus median: 8, IQR: 7.1–23.5). The justifications of their sample sizes were either based on regression-based recommendations or the availability of data. Furthermore, Christodoulou et al. 8 reported a median EPV of 8 (Range: 0.3–6697) across 71 studies on risk prediction using MLTs for binary outcomes. Wang et al. 9 reported a median sample size of 475 (Range: 70–3184) with a median number of predictors of 22 (Range: 4–152) in their review of 18 studies using MLTs to predict various health outcomes following stroke. Additionally, Andaur Navarro et al. 1 found that among 19 studies using MLTs for prediction model development with external validation, only three justified their sample sizes for external validation with all justifications based on data availability.
It is crucial to ensure that the sample size is adequate for both the development and validation of prediction models. Using a sample size that is too small is often one of the most common methodological flaws in studies using either logistic regression 10 or a MLT. 7 Recently, practical guidance has been developed for calculating the sample size required for the development 11 and validation 12 of logistic prediction models. Riley et al. proposed formulae to calculate the sample size required to, for example, limit model overfitting or to achieve a sufficiently small mean absolute prediction error (MAPE), among other model performance targets. The required sample size is context-specific and depends on factors such as the event proportion, the number of model parameters and the predictive strength of the model (R2/C-statistic). 11 It has been suggested that these sample size calculations for logistic regression (fitted using maximum likelihood) may also be used to guide sample size calculations when using MLTs for risk prediction. 10 In fact, some studies developing prediction models for binary outcomes using MLTs have applied Riley et al.'s formulae to determine the minimum sample size required for model development.13–15 However, Van der Ploeg et al. 16 suggested that developing a prediction model with MLTs may require more than 10 times the EPV needed to achieve adequate discriminatory ability using logistic regression.
Our work was motivated by the emerging need for sample size guidance for developing and validating MLT-based clinical prediction models. It was important to investigate whether the current sample size recommendations for developing and validating clinical risk prediction models using logistic regression are applicable to or can be adapted for MLTs. Machine learning encompasses a wide range of techniques, and the choice of an appropriate method depends on the specific problem and the nature of the available data. In this study, we focused on ensemble tree-based methods which are commonly used to develop models for binary outcomes. 8 Specifically, we considered bagged classification trees, 17 RFs 18 and gradient boosting machines. 19 We conducted an extensive simulation study to evaluate the applicability of existing logistic regression-based sample size formulae for models using these MLTs. We considered a variety of data-generating scenarios typical in clinical data, including cases where there are interactions between predictors, and non-linear relationships between the outcome and predictors are present.
The datasets which were used as the basis for the simulations are introduced in Section 2. Section 3 provides a description of the ensemble tree-based MLTs. The design of the simulation study and its results are presented in Sections 4 and 5, respectively. Finally, the results from the simulation study are discussed and recommendations on the required sample size for using ensemble tree-based MLTs in the context of clinical prediction modelling are provided.
Datasets
We conducted simulations based on two datasets obtained from the National Institute for Cardiovascular Outcomes Research (NICOR). The purpose of using two different datasets was to examine how different features of the data may influence the sample size requirements for MLTs. One dataset contained non-linear associations between predictors and the outcome, and we introduced interactions between predictors in the other dataset. To handle missing values in predictor variables we applied multiple imputation by chained equations 20 and then selected a single imputed dataset for both datasets for the simulations. The outcomes and predictor variables used from these data sources are listed in Tables S1 and S2 in the Supplemental Material.
Myocardial Ischaemia National Audit Project cohort
The first dataset was from the Myocardial Ischaemia National Audit Project (MINAP) and included 217,216 patients admitted to hospitals following an acute coronary syndrome (ACS). The binary outcome in-hospital death following hospital admission for an ACS had a prevalence of 6.28%. We considered 10 candidate predictors (4 continuous, 5 binary, 1 ordinal). Preliminary investigations using splines suggested that the relationships between the predictors and outcome were approximately linear.
Heart failure cohort
The second dataset included 54,081 patients admitted to hospital with heart failure (HF), where the binary outcome was 30-day mortality with a prevalence of 11.3%. It included 17 predictors (9 continuous, 8 binary). Investigations using splines suggested that a suitable regression model should account for non-linear relationships between the continuous predictors and the outcome.
Methods
In this section, we describe the MLTs used for both generating the data for simulations and model fitting.
Tree-based ensemble MLTs
In the context of binary classification, a classification tree (also known as a decision tree) is a supervised MLT based on an algorithm that builds a tree-like structure to make decisions. These algorithms aim to create a prediction rule based on a sequence of binary partitions of the data (i.e. tree). The partition at each step depends upon the answers to the previous yes/no questions in the sequence (e.g. Age > 66?). In a decision tree, a point where the data are split into two or more branches is called a node. The sequence terminates by predicting the class (event/no-event) label in the last binary partition for the subject (i.e. at the terminal node) when a stopping rule is triggered. 21 Though single decision trees are computationally less expensive and easier to interpret, they may suffer from poor predictive accuracy. 22 Tree-based ensemble methods, which combine the results of several classification trees can offer increased predictive accuracy over a single estimator. We considered bagging of classification trees, RFs, and gradient-boosting machines in this paper.17–19 Bagging (also known as bootstrap aggregating) fits decision trees repeatedly to bootstrapped datasets of the original training data. 17 Each tree in the ensemble is trained independently and simultaneously on its corresponding bootstrap sample using all available predictors, then predictions from the individual trees are averaged. RFs improve upon bagging by reducing the correlation between trees in the ensemble by randomly choosing a subset of candidate predictors when building a tree, instead of using the full set of predictors. 18 In both the bagging and RF algorithms, the final prediction is made through a majority voting scheme, where the predictions of individual trees are aggregated to determine the final predicted class. In other words, the final predicted class or outcome is the one with the largest number of votes across all fitted trees. The probability of a patient belonging to a particular class is estimated by the proportion of trees that predict that class for the patient.
Boosting algorithms construct sequential trees using information from previously grown trees, instead of training them in parallel. There is a range of boosting algorithms and they use different approaches to address the shortcomings of previous trees during the iterative process. We used stochastic gradient boosting machine (hereafter boosting), that takes a random subset with replacement from the original data to train each tree.19,23 For classification problems, boosting typically starts with one leaf node that predicts an initial value of the probability of the outcome based on the log-odds for every subject. The residuals calculated as the difference between the observed and predicted values are then used as the outcome for the following tree. By assigning more weight to misclassified observations with larger residuals, more accurate predictions can be made. The final prediction is made when the sum of the residuals is sufficiently small or when the maximum number of trees is reached.
We used the caret (classification and regression training) package in the R statistical programming language (R version 4.3.1, R Foundation for Statistical Computing, Vienna, Austria) to apply these methods. 24 The caret package allows the user to train the model with a user-defined regression and classification method. We used the treebag, rf and gbm functions in the caret package (version 6.0-94) for bagging, RFs and boosting, respectively.
Hyperparameter tuning for MLTs
Hyperparameters are machine learning model parameters whose values are chosen before training the model and remain constant throughout the training process. The choice of appropriate hyperparameters can significantly affect the performance and behaviour of MLTs, and therefore hyperparameters are often tuned to optimise model performance. 25 Different MLTs often use different hyperparameters according to their own unique characteristics such as model architecture, learning algorithm and assumptions. The choice of hyperparameters can depend on factors such as the type of model being used, model complexity, the distributions of the outcome and predictors, the size of the dataset, and the presence of noise or outliers.
The development and validation of predictive models using MLTs are typically conducted by splitting the original dataset into three subsets: training, validation, and testing datasets. The training dataset is used to develop the model, while the validation dataset is used for hyperparameter tuning. The testing dataset is used to evaluate the performance of a trained model in new data.
The R caret package provides an automated grid search for optimising hyperparameters during model training. We performed hyperparameter tuning using five-fold cross-validation on different combinations of training and validation sets by constructing a grid search of possible hyperparameter values, including the software's default values. For each combination of hyperparameter values within the grid, the training models were fitted to 10 simulated datasets across various simulation scenarios (described in Section 4). We determined the optimal hyperparameter values prior to running the full simulations to reduce the computational time to train the models. Brier scores were used as the primary performance metric with hyperparameter values producing the lowest Brier score considered to be optimal for each method within a simulation scenario. 26 When there were no differences in the Brier score for possible hyperparameter values, we used the values that required the least model training time.
In the Supplemental Material, we provide a description of the hyperparameters, the range of hyperparameter values considered in the grid search, and the optimal values selected for the MINAP and HF datasets (Tables S3–S9).
Strategies for handling imbalanced dataset for MLTs
A dataset is said to be imbalanced when the number of individuals with and without the event are not represented equally. 27 In prediction modelling, the issue of imbalanced data arises when predicting low/high prevalence events. The most prevalent and rarest outcome classes are referred to as the majority and minority classes, respectively. MLTs trained with imbalanced data have a tendency to underestimate the probabilities for the minority class. 28 Therefore, various approaches have been developed to dealing with imbalanced data classification. 29
A popular technique for dealing with imbalanced datasets is to utilise a form of resampling that creates artificial balanced samples for training the models. 30 Depending on the strategy used to balance the class distribution, resampling techniques fall into three main groups: (i) under-sampling by randomly removing observations from the majority class until the class frequencies are equal, 31 (ii) over-sampling by adding observations to the minority class by resampling from the class with replacement until the class frequencies are equal, 31 and (iii) hybrid methods (techniques such as Synthetic Minority Over-Sampling Technique – SMOTE 32 and Random Over-Sampling Examples – ROSE 33 ) by under-sampling from the majority class and over-sampling by generating synthetic new observations in the minority class.
Cost-sensitive learning is another strategy to deal with the class imbalance problem which can yield superior predictive accuracy compared to using standard algorithms. 34 This method relaxes the assumption that the misclassification costs of the events and non-events are the same. To ensure that the model accurately predicts the minority (i.e. events in our examples) class, cost-learning modifies the algorithm's training function by incorporating a hyperparameter which controls the ratio of class weights between the majority and minority classes. 35 Specifically, increasing the weight of the minority class relative to the majority class helps the model to focus more on the minority class during training (e.g. 10:1, 20:1, 100:1, etc.).
Calibration correction is used to refine the predicted probabilities of a classification model, making them more aligned with the actual probabilities of class membership. 36 In clinical prediction models, two main calibration models, namely Platt scaling 37 and isotonic regression are used to obtain the calibrated probabilities. 38 Platt scaling transforms probabilities using a logistic regression model with the estimated probabilities as the independent variable and the binary outcome as the dependent variable. Alternatively, isotonic regression adjusts the predicted probabilities by applying a monotonically increasing transformation to the original probabilities. If resampling techniques are used, calibrating probabilities may become even more important since resampling can introduce bias into the estimated probabilities. 39
Due to the imbalanced nature of the MINAP and HF datasets, we assessed whether different techniques for handling imbalances improved the predictive performance and calibration of the MLT models. We applied a variety of approaches including resampling techniques, cost-sensitive models and probability calibration to 10 randomly generated simulated datasets across different simulation scenarios. No single strategy improved all of the performance measures simultaneously for any given scenario. The results are presented in the Supplemental Material (Tables S10–S27). Consequently, for the sample size evaluations we used the original models without applying any strategy to handle imbalance.
Simulation study
We used simulation to assess whether the existing sample size formulae for developing 11 and validating 12 clinical risk prediction models with logistic regression are appropriate for tree-based ensemble MLTs. The structure of this section is in line with ADEMP, a systematic framework for simulation studies proposed by Morris et al. 40
Aims of the simulations
Aim 1. We assessed whether the sample size formula for targeting a small MAPE when developing a prediction model using logistic regression can be used to determine the sample size for developing tree-based ensemble MLT models.
Aim 2. We assessed whether the sample size formula for studies conducting external validation of prediction models based on logistic regression can be used to determine the sample size for the external validation of tree-based ensemble MLT models.
Data-generating mechanisms for simulating binary outcomes
We compared the performance of logistic regression and three MLTs for predicting binary outcomes using a simulation study. The data-generating mechanisms (DGMs) used to simulate the outcomes were based on each analysis model. 41 In addition to DGMs that aligned with specific analysis models, we considered DGMs that introduced interactions between predictors. All DGMs were used for both aims.
DGMs 1–4: For both the MINAP and HF datasets, we considered each of the four analysis models under investigation as the basis for the DGM, namely (1) logistic regression with main effects (LR-ME for MINAP and LR-NL for HF, the NL indicating the inclusion of non-linear effects), (2) bagging, (3) RFs, and (4) boosting. For LR-NL, natural splines were used to model the continuous variables (LR-NL):
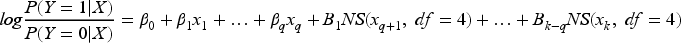
DGM 5: Additionally, for the MINAP dataset, we used a DGM based on a logistic regression model that included all main effects and two-way interactions, after categorising each continuous predictor into five equal-sized categories. There were 320 parameters in this DGM and we refer to it as a neutral model as its data structure does not match any of the analysis models. The purpose of using this DGM was to assess how MLTs perform compared to logistic regression with respect to sample size, when the true DGM has a complex structure that includes interaction terms.
Calculating sample sizes for development and external validation datasets
For Aim 1, the sample size for the development dataset, which will be referred to hereafter as ndev, was determined by the sample size formula proposed by Riley et al.,
11
that targets MAPE (see Section 4.5 for full details), where MAPE is often used to evaluate the predictive accuracy of a prediction model and can be calculated for both logistic regression and MLTs. The sample size formula is given below:
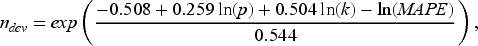
For Aim 2, we used the formula proposed for calculating the sample size required for an external validation study to estimate a C-statistic with a desired level of precision, based on a model developed using logistic regression. This approach assumes that the linear predictor is normally distributed and requires information on the anticipated value of the C-statistic (C) and the outcome prevalence
12
:
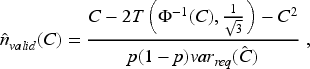
The data-generation process was started by fitting a given model to the original dataset and predicting probabilities of the outcome for each subject (πi, i = 1, … , N). These were considered as the true probabilities and used to simulate binary outcomes as
For Aim 1, each simulation iteration involved drawing a development sample (with replacement) of size ndev from the observed covariates and simulated yi values. The sample size ndev was determined using Formula (1) for a range of target MAPEs. The outcomes were simulated using the five DGMs and five sample size scenarios for MINAP, and four DGMs and three sample size scenarios for HF. We then fitted each analysis model (i.e. LR-ME, LR-NL (only for HF dataset), bagging, RF and boosting) to the development data. The remaining subset of the full dataset that was not used for developing the model was used to validate the performance of the model, and for convenience, we refer to this as the validation sample for all methods considered, with nvalid = N − ndev. The predicted outcome probabilities were calculated for the validation data (
For Aim 2, the true C-statistics and outcome proportion were calculated from the full data with the simulated outcomes. Then, the validation sample size,
Performance measures and targets
Aim 1: Development data
The primary performance measure of interest is MAPE. We assessed whether the MLT models can achieve the target MAPE under a range of development sample sizes, where MAPE quantifies a model's mean predictive accuracy and is estimated as
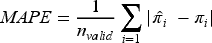
Lower values of MAPE indicate greater predictive accuracy.
Model discrimination was assessed with the C-statistic (C). It is defined as the probability that a random individual with the event has a higher predicted probability than a random individual without the event and is estimated using
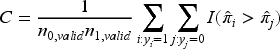
The calibration of the predictions was examined to assess the agreement between the predicted and observed probabilities of the outcome. A variety of calibration measures were calculated; their stringency levels are defined by Van Calster et al.
43
Calibration-in-the-large was calculated as the difference between the proportion of events in the validation data and the average of the predicted probabilities, and should ideally be zero. Values smaller than zero indicate systematic overestimation of the estimated probabilities, whereas values greater than zero indicate systematic underestimation. The calibration slope was calculated by regressing the observed outcome on the log-odds of the predicted probability of the outcome. A slope close to one indicates good calibration across a range of individuals or subgroups, whereas a slope greater (less) than one indicates underfitting (overfitting). The integrated calibration index (ICI) was calculated as the weighted average of the absolute differences between the observed outcome of a subject and the predicted probability for that subject, where the weights are the predicted probability values.
44
The ICI ranges from 0 to 1, where lower values indicate better calibration. Another calibration measure, E90, was calculated as the 90th percentile of the absolute difference between the observed and predicted probabilities. It assesses the calibration of a model specifically in the region of the predicted probabilities where the model is most likely to make errors.
44
The Brier score, which measures the deviation between the true outcome and predicted probability, was estimated as
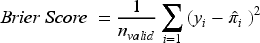
The C-Statistic, Brier Score, E90 and calibration measures were computed using the val.prob function from the rms package in R. 45
Aim 2: Validation data
We estimated the standard error of
Results
R Shiny web application
The performance of the logistic regression and tree-based risk models for different data generation processes and sample sizes are presented in a freely accessible R Shiny web application (available from https://mlsamplesize.shinyapps.io/Sample_size_ML/). The web application provides a comparison of methods across a range of performance measures, assessing predictive accuracy and calibration through easy-to-read boxplots.
Median (25th–75th percentile) of the MAPE (×100) for the MINAP dataset over 1000 simulations.
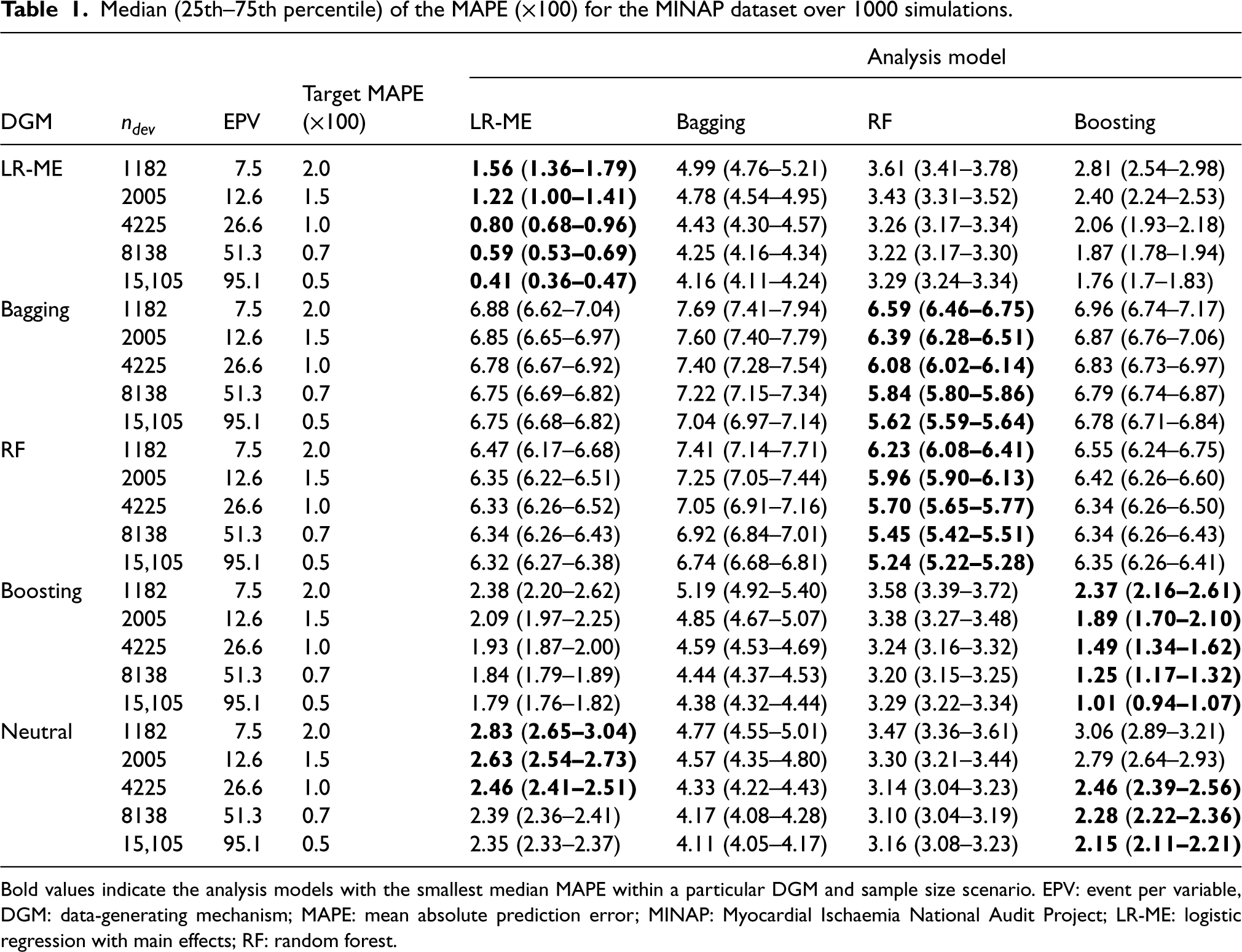
Median (25th–75th percentile) of the MAPE (×100) for the MINAP dataset over 1000 simulations.
Bold values indicate the analysis models with the smallest median MAPE within a particular DGM and sample size scenario. EPV: event per variable, DGM: data-generating mechanism; MAPE: mean absolute prediction error; MINAP: Myocardial Ischaemia National Audit Project; LR-ME: logistic regression with main effects; RF: random forest.
MINAP dataset
The results for the various performance measures for the four analysis models under five different sample sizes and DGMs are reported in Table 1 and Figure 1.
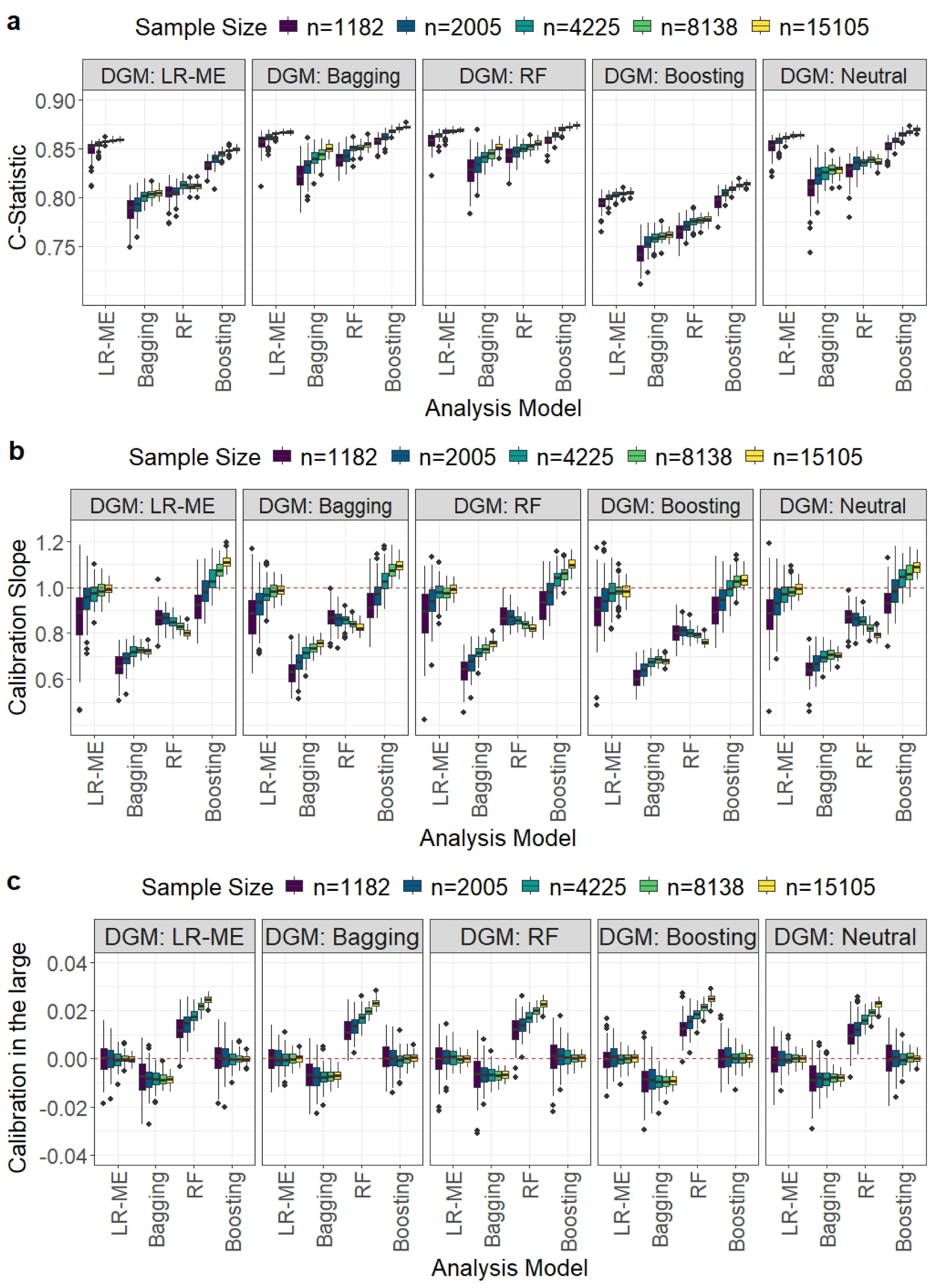
Comparison of model performance in terms of the C-statistic, calibration slope, and calibration-in-the-large for the Myocardial Ischaemia National Audit Project (MINAP) dataset. Each boxplot displays the distribution of a given performance metric across the 1000 simulation iterations for different development sample size scenarios when a particular data-generating mechanism (displayed in header) and analysis model were used.
As expected, the value of MAPE decreased with increasing sample size for all models. With the exception of bagging, the best performance for each DGM was achieved by the matching analysis model. None of the ML models achieved the target MAPE at the recommended sample sizes. Boosting needed at least twice the sample size of LR-ME to achieve the target MAPE of 2% and 1.5%. To achieve a smaller target MAPE of 1%, boosting required approximately 3.5 times more data than the recommended sample size. Bagging and RF were not close to achieving the target MAPE, even if the recommended sample size was increased by 15 times with bagging performing the worst (Table 1).
It may be noted that bagging and RF calculate the predicted probabilities of the outcome as the proportion of trees that voted for the event class to the total number of trees in the ensemble; when none of the trees vote for the event class the predicted probability of the event is zero. In our simulations, bagging and RF predicted most of the probabilities to be zero. This may be due to the low prevalence of events in the MINAP dataset; furthermore, the small number of predictors may have decreased the diversity of the trees. To calculate the C-statistic, we replaced the 0 and 1 predictions with 0.0001 and 0.9999, respectively. We also note that for the boosting DGM, the estimated C-statistic was lower than that for the other DGM scenarios for all analysis models. The calculated C-statistic increased with sample size for all analysis models. The LR-ME and boosting analysis models (true C-statistic of 0.86 and 0.82, respectively) outperformed bagging and RF (true C-statistic values of 0.96) for all recommended sample sizes (Figure 1(a)). However, boosting required substantially larger sample sizes to reach close to the corresponding true C-statistic values.
For the recommended sample sizes, LR-ME and boosting resulted in median calibration slopes close to unity and calibration-in-the-large values very close to zero (Figures 1(b) and (c)). In contrast, both calibration slope and calibration in-the-large were worse for RF and worst for bagging. Observations with estimated probabilities of 0 and 1 were excluded from the calculation of the RF and bagging calibration measures and the exclusion of many data points may have contributed to their poor performances.
The results for the Brier score, ICI and E90 can be found in the R Shiny app. For the recommended sample sizes, the LR-ME and boosting models had E90 and ICI values closer to zero than that of the other methods. Additionally, the LR-ME and boosting models produced smaller Brier scores than the other MLT models for the recommended sample sizes.
Non-matching DGMs and analysis models
For the LR-ME DGM, boosting was able to achieve a target MAPE of 2% with at least four times the recommended sample size. For the boosting DGM, LR-ME approached the target MAPE of 2% when the sample size was more than twice the recommended size. Neither LR-ME nor boosting attained a MAPE value much lower than 2% even when the recommended sample size was increased more than 12 fold. However, both models outperformed RF and bagging for all non-matching DGMs except for the bagging DGM where RF performed best. Bagging and RF failed to achieve MAPE values close to the target even with substantial increases in the recommended sample size. For DGM-Neutral, boosting and LR-ME were only able to achieve a target MAPE close to 2% when the recommended sample size was increased by more than 12 times.
For the C-statistic the LR-ME and boosting performed better than bagging and RF for the recommended sample sizes with boosting showing greater improvement with increasing sample size.
LR-ME resulted in median calibration slopes ≥ 0.9 with an IQR including one and calibration-in-the-large very close to zero for the recommended sample sizes (Figure 1(b) and (c)), with performance improving with increasing sample size. Boosting tended to result in slight underfitting of the model for large sample sizes (>8000), with median calibration slopes ranging from 1.06 to 1.11. However, the calibration-in-the-large values were close to zero. Bagging and RF performed poorly for the calibration measures and increasing the sample size did not improve the results for RF.
While LR-ME produced the lowest Brier scores for smaller sample sizes, boosting produced the lowest Brier scores for the larger sample sizes. Both LR-ME and boosting resulted in E90 and ICI values close to zero.
HF dataset
In contrast to the MINAP dataset, the HF dataset had non-linear relationships between the outcome and predictors as well as a higher number of predictors and outcome prevalence. The performance of the five analysis models under three different sample sizes and four DGMs is reported in Table 2 and Figure 2.
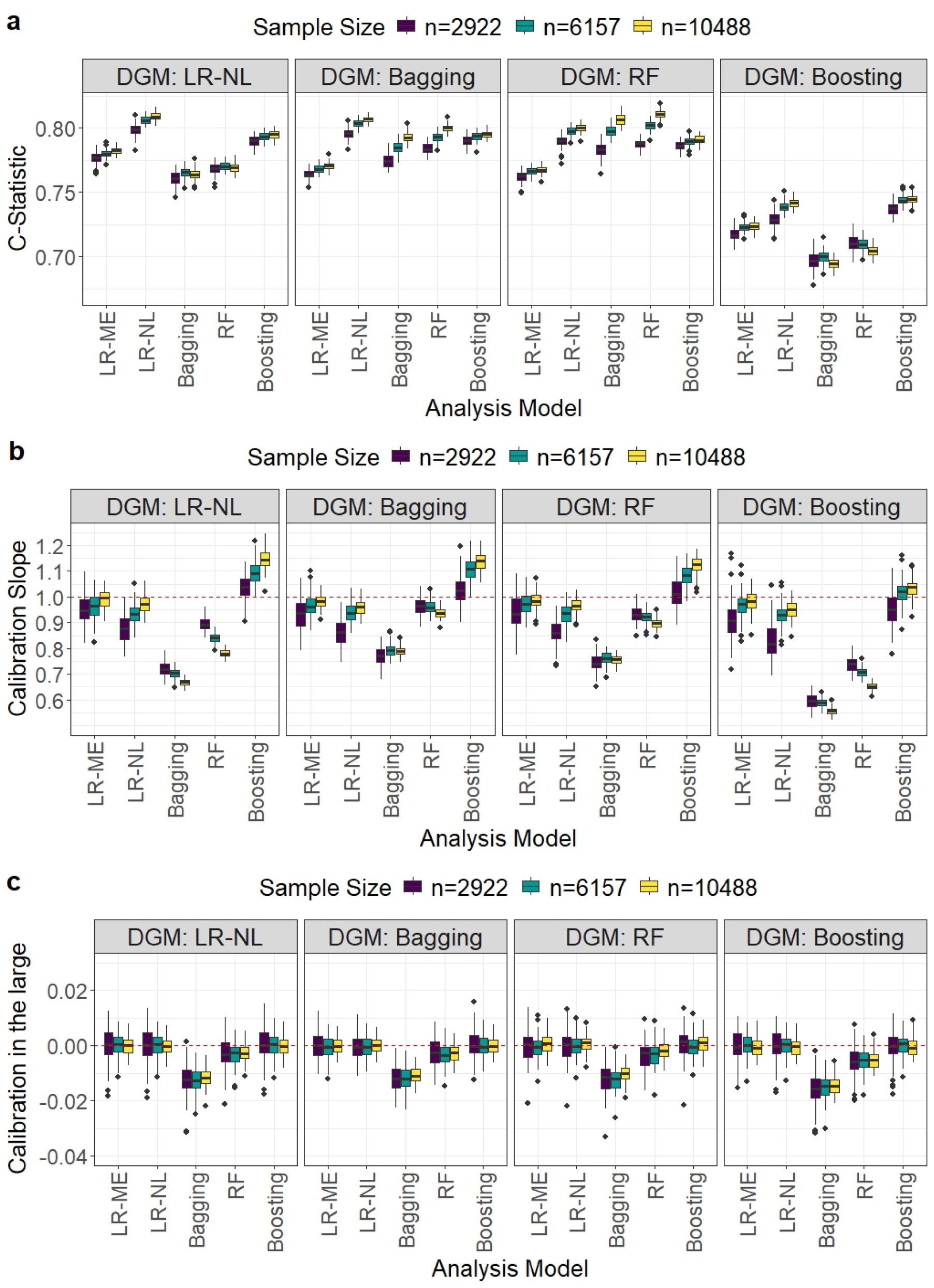
Comparison of model performance in terms of the C-statistic, calibration slope, and calibration-in-the-large for the HF dataset. Each boxplot displays the distribution of a given performance metric across the 1000 simulation iterations for different development sample size scenarios when a particular DGM and analysis model were used. HF: heart failure; DGM: data-generating mechanism.
Median (25th–75th percentile) of the MAPE (×100) for the heart failure dataset over 1000 simulations.
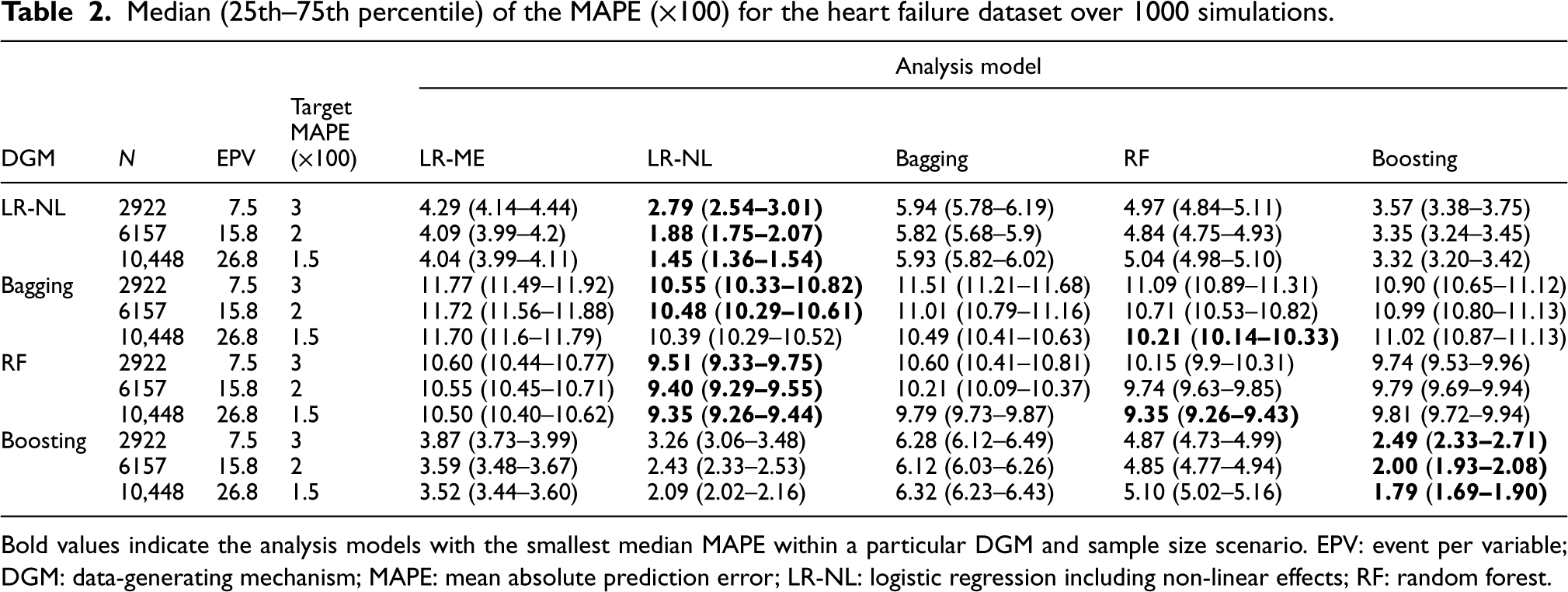
Bold values indicate the analysis models with the smallest median MAPE within a particular DGM and sample size scenario. EPV: event per variable; DGM: data-generating mechanism; MAPE: mean absolute prediction error; LR-NL: logistic regression including non-linear effects; RF: random forest.
LR-ME did not have a matching DGM. For the other matching DGM and analysis model scenarios, LR-NL and boosting achieved the target MAPEs at the recommended sample sizes (based on LR-NL) (Table 2). In the non-matching scenarios, none of the methods achieved the target MAPE values with LR-ME performing similarly to the MLT models and LR-NL producing the smallest MAPE values for all sample sizes.
For matching DGMs, LR-NL achieved the highest C-statistic values, attaining values close to the true value of 0.81 (Figures 2(a)). For non-matching DGMs, LR-NL performed the best followed by boosting at the recommended sample sizes.
For matching DGMs, LR-NL, RF and boosting produced median calibration slopes close to 0.9 with IQRs that include zero and calibration in the large values close to zero (Figures 2(b) and (c)) at the recommended sample sizes. These calibration measures did not improve with increasing sample size for RF and boosting showed some under-fitting for large sample sizes. For non-matching DGMs, LR-ME, LR-NL and boosting performed better than bagging and RF, with bagging showing the worst performance at the recommended sample sizes. It may be noted that RF demonstrated comparatively better performance for the calibration measures compared to that observed for the MINAP dataset.
For matching DGMs, LR-NL produced the smallest Brier score at the recommended sample size. For non-matching DGMs, LR-NL and boosting achieved smaller Brier scores than bagging and RF. The only exception was for the bagging DGM, as RF tended to produce the smallest Brier scores at the recommended sample size.
All analysis models except bagging produced similar E90 and ICI values for all sample sizes and DGMs.
Two different precision levels for the C-statistic were considered to calculate sample sizes for the external validation data for each DGM. The validation samples were randomly selected from the full data for this investigation. It may be noted that these sample size calculations assume normality of the linear predictor. However, it is highly likely that the distribution of the linear predictor from the MLT models will not be normal.
MINAP dataset
The distributions of the linear predictor for the various DGMs are presented in Figure S1 in the Supplemental Material. The boosting DGM showed some skewness, and the bagging and RF DGMs showed considerable departures from normality, while the Neutral DGM conformed to a normal distribution. The validation sample size requirements and the mean C-statistics obtained for the validation samples are presented in Table 3, along with their standard errors for the two target SE(C) scenarios. The sample size for the external validation data depends on the value of the C-statistic with higher values of the C-statistic resulting in smaller sample size requirements. The smallest C-statistic value was obtained for the boosting DGM which is consistent with the results seen for the development data. The true values of the C-statistics were larger for bagging and RF (0.960 for bagging, 0.963 for RF). For all DGMs, the mean estimated standard error of the C-statistic achieved the target SE(C) value with the sample sizes calculated using the proposed formula despite the violation of the normality assumptions.
Summary of the validation sample size results for the MINAP dataset.
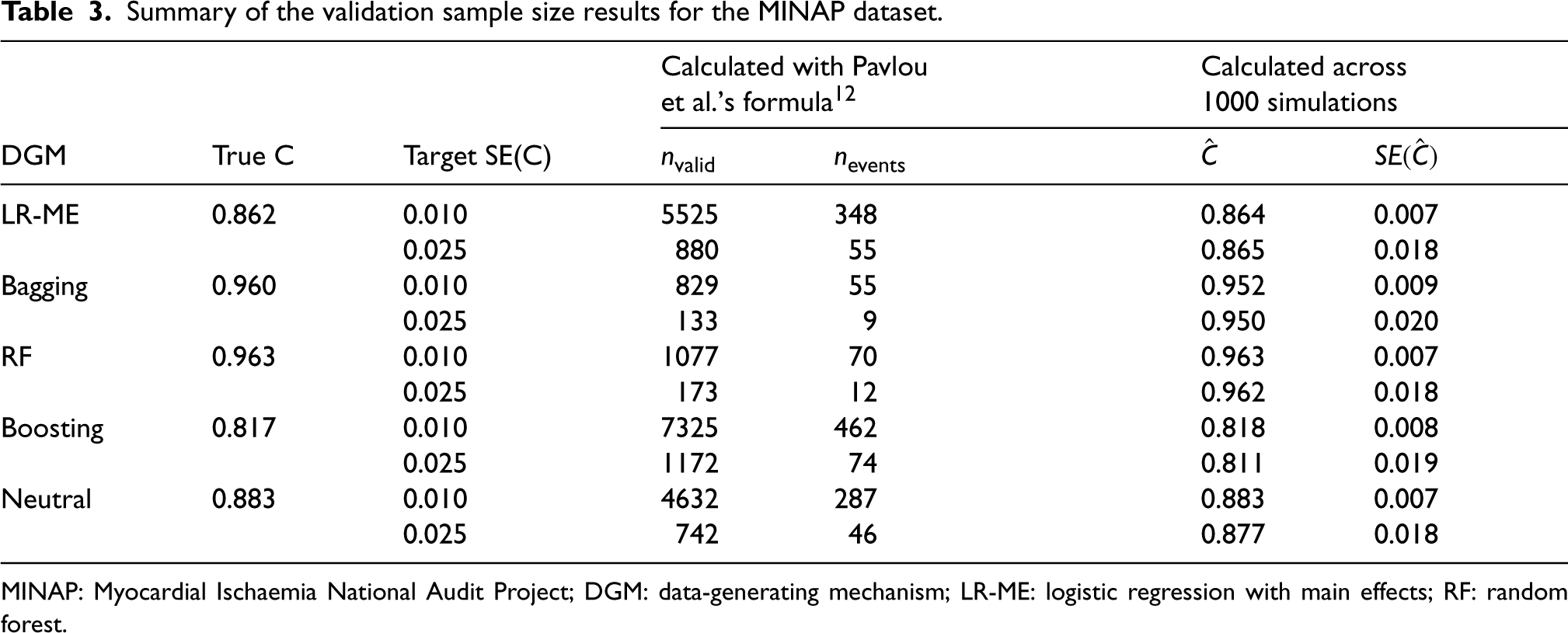
Summary of the validation sample size results for the MINAP dataset.
MINAP: Myocardial Ischaemia National Audit Project; DGM: data-generating mechanism; LR-ME: logistic regression with main effects; RF: random forest.
The distribution of the linear predictor for the boosting DGM was slightly skewed, whereas the bagging and RF DGMs had skewed and bimodal distributions (Supplemental Material Figure S2) for the HF dataset.
Similar to the findings for the MINAP dataset, the target SE(C) was achieved for all the DGMs with the validation sample size calculated using the proposed formula (Table 4).
Summary of the validation sample size results for the heart failure dataset.
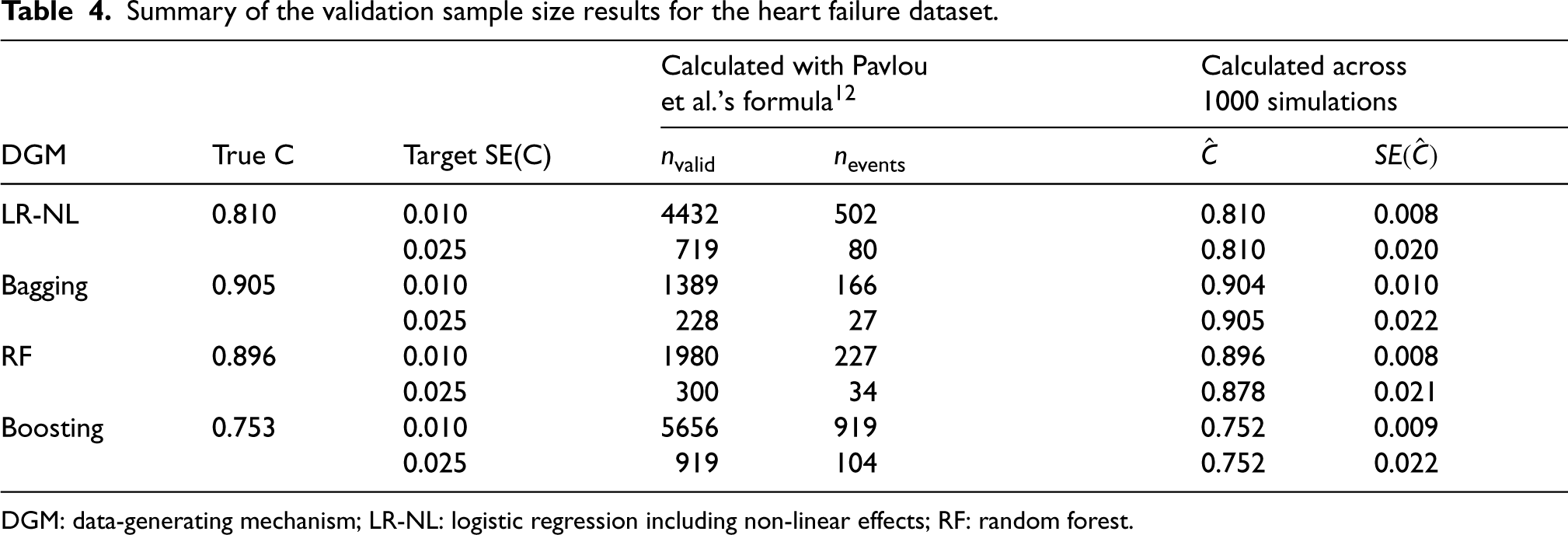
Summary of the validation sample size results for the heart failure dataset.
DGM: data-generating mechanism; LR-NL: logistic regression including non-linear effects; RF: random forest.
Machine learning models are increasingly being used by researchers for clinical prediction modelling. However, many of these researchers do not justify their chosen sample sizes. 1 In this study, we investigated whether the existing MAPE-based approach for calculating the sample size for the development of logistic prediction models10,11 could be used or adapted for ensemble tree-based MLTs. This approach, which uses information on the number of predictors and outcome prevalence, is popular and available in widely-used software. We considered a range of sample sizes corresponding to different target MAPE values and investigated whether bagging, RFs, boosting and logistic regression models could achieve these targets. Additionally, we examined model performance using various metrics that capture different aspects of predictive ability, such as calibration and discrimination. We also investigated whether a precision-based sample size calculation for the external validation of a predictive model with a binary outcome, based on the standard error of the C-statistic, 12 applies to models developed with these MLTs.
Simulation findings and recommendations
We performed simulations based on two large cardiovascular datasets with different outcome prevalences, numbers of predictors and levels of data complexity. In one dataset, interactions between the predictors were introduced, while the other had non-linear associations between the outcome and predictors. Thus both exhibited complex data structures where MLT models might be expected to perform better than conventional logistic regression models.
For the dataset with fewer (10) predictors and a lower prevalence with only linear associations between the outcome and the predictors, bagging and RF did not achieve the target MAPE or satisfactory values of the calibration measures with the recommended sample sizes. That was the case even when the DGM matched the analysis model and the recommended sample size was increased by more than 12-fold. Boosting achieved the target MAPE for a matching DGM with a sample size at least 2–3 times larger than that recommended and attained satisfactory values for the other performance measures. For the neutral DGM representing a complex data structure with all main effects and two-way interactions of the predictors, logistic regression including only main effects and boosting achieved MAPEs values close to the target with a 12-fold increase in the recommended sample size, while bagging and RF failed to achieve the target. For the dataset which had a larger (17) number of predictors, higher prevalence and non-linear associations between the outcome and predictors, the logistic regression model that accounted for non-linearities through natural splines performed the best, followed by boosting, at the recommended sample sizes with matching DGMs and analysis models. Logistic regression excluding the non-linear terms performed better overall than bagging and RF for the recommended sample sizes based on LR-NL. Bagging performed the worst in all scenarios for both datasets even with large sample sizes and matching DGMs.
Consistent with our findings, recent simulation studies have shown superior performance of boosting over other MLTs for developing clinical prediction models with binary 41 and survival 47 outcomes. Austin et al. 41 used six different DGMs and found that logistic regression and boosting generally outperformed other MLTs across a range of performance measures. Their simulations were based on two datasets with EPVs of 56 and 96 but they did not vary the sample size. Infante et al. 47 compared the predictive performance of MLTs relative to regression-based methods for developing a survival prediction model across different sample size scenarios. They reported that boosting algorithms achieved comparable performance to regression-based models using the same sample size. However, RFs needed at least 2 to 3 times the sample size of the conventional regression-based survival models to achieve the same values of the Brier score.
As summarised in Table 5, our study suggests that MLT models may require significantly larger sample sizes than those recommended by the logistic regression-based formula for achieving a target MAPE in model development. However, it might be possible to apply existing sample size formula for logistic regression to boosting if the recommended sample sizes are inflated to some extent. One approach for inflation could be to increase the number of parameters that goes into the calculation of the sample size. This could be achieved, for example, by categorising the continuous predictors into a number of percentile-based categories and adding terms for two-way interactions between all the predictors. Alternatively, one could account for a number of spline terms for each continuous predictor in the sample size calculation. This approach effectively accounts for the fact that boosting aims to capture complex patterns in the data and the number of parameters in an equivalent logistic regression model would be much higher than a regression model with only main effects. These types of inflation should also allow the flexibility of fitting a logistic regression model with nonlinear terms and interactions to a complex data structure and achieve adequate levels of predictive performance. However, one may also opt to use a simulation-based sample size calculation using a suitable DGM analogous to the approach of Pavlou et al. 48 for logistic regression.
Summary of the sample size requirements for model development using MLTs in comparison to the recommended sample size based on logistic regression to achieve a target MAPE.

Summary of the sample size requirements for model development using MLTs in comparison to the recommended sample size based on logistic regression to achieve a target MAPE.
Scenario 1: MINAP dataset (number of predictors: 10, k = 10, p = 0.63, only linear associations). Scenario 2: HF dataset (number of predictors: 17, k = 44, p = 0.113, non-linear associations). EPV: events per variable; MINAP: Myocardial Ischaemia National Audit Project; HF: heart failure; LR: logistic regression with only main effects; LR-NL: logistic regression including non-linear effects; RF: random forest.
The sample size evaluation for external validation of prediction models revealed that the target standard error of the C-statistic was achieved for all DGMs when the sample size was estimated using the precision-based formula 12 even when the assumption of normality for the distribution of the linear predictor was violated for the MLT DGMs. Thus, this formula may be used to calculate the sample size for external validation studies using MLT models with binary outcomes.
This study has some limitations. First, our simulations were based on two real-life cardiovascular datasets with a relatively small number of predictors, all of which were strongly associated with the outcome. Previous simulations that have evaluated the sample size formula for model development that was investigated in this paper have shown that its accuracy decreases for models with high prognostic strength—for instance, when the C-statistic exceeds 0.8, as observed in our datasets. 48 A potential explanation for the relatively poor performance of bagging and RF in our study may be linked to the strength of the predictors, as optimal performance in ensemble tree-based machine learning classifiers requires low inter-tree correlations. 49 This is because one of the key principles behind these ensemble models is to reduce overfitting and improve generalisation by combining the predictions from multiple trees. However, when there are strong predictors in the dataset, bagging tends to generate similar trees. 17 This means that the strongest predictors will be chosen as the root node for the first split, and all of the trees will subsequently follow with similar splits. When these highly correlated trees are aggregated, the reduction in the variance of the predictions is smaller compared to a scenario with uncorrelated trees. RF addresses this problem by randomly selecting candidate predictors for each tree. However, a large number of predictors is necessary to improve prediction accuracy and reduce generalisation error for RF models. 18 Second, the prevalence of the outcome in both datasets was low. In machine learning, having an imbalance in the data where one outcome class is a small minority may distort the predicted probabilities and predictive accuracy.50,51 However, health outcomes with low prevalences are common in many real-world problems. We attempted to address the class imbalance problem using various techniques, but none of them showed a consistent improvement across all performance measures. Further research is needed to evaluate the sample size needs of machine learning models in relation to outcome prevalence and techniques for solving the class imbalance problem. Another limitation was that hyperparameter selection was performed prior to the simulations by training the models on just the first 10 simulated datasets across various simulation scenarios. While this approach may not fully capture dataset-specific optimisations, we aimed to reduce the training time as hyperparameter tuning for MLTs can be complex and computationally demanding.
The RF model showed overfitting (CS < 1) and increasing the sample size did not improve calibration performance. We recommend caution when using calibration measures such as the calibration slope and calibration in-the-large with tree-based MLTs because these models can make predictions of exactly 0 or 1, which is typically not the case with logistic regression. Moreover, the skewed distribution of the linear predictor for bagging and RF may have additionally contributed to the poor performance of these calibration measures. More methodological work is needed to investigate the appropriateness of these calibration measures when using tree-based MLTs. When calculating the sample size for model development with RF, one may need to choose alternative performance measures that would be more suitable for assessing the predictive ability of these types of models.
A practical limitation of this study is that while our findings provide broad guidance on sample size considerations for model development and validation studies using MLTs and suggest ways to adapt the existing sample size formulas for logistic regression to account for complex data features, they do not offer readily applicable, method-specific sample size formulas for practitioners. Thus, it highlights the need for further investigations to establish robust sample size formulae that ensure reliable predictions across different MLTs and datasets. Additionally, the use of more real-world datasets with different characteristics may help in confirming our findings regarding the suitability of the logistic regression-based formulas for determining the sample sizes for model development and validation with MLTs.
Supplemental Material
sj-docx-1-smm-10.1177_09622802251338983 - Supplemental material for Evaluating the sample size requirements of tree-based ensemble machine learning techniques for clinical risk prediction
Supplemental material, sj-docx-1-smm-10.1177_09622802251338983 for Evaluating the sample size requirements of tree-based ensemble machine learning techniques for clinical risk prediction by Oya Kalaycıoğlu, Menelaos Pavlou, Serhat E Akhanlı, Mark A de Belder, Gareth Ambler and Rumana Z Omar in Medical Research
Footnotes
Data availability
The simulated datasets will be made available on request.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: GA, MP and RZO were supported by the Medical Research Council grant MR/P015190/1. RZO and GA are researchers at the National Institute for Health and Care Research University College London Hospitals Biomedical Research Centre. The research was partially supported by the University College London 2023/24 Global Engagement Funds. OK was supported by the Scientific and Technological Research Council of Türkiye (TUBITAK) 2219 Research Programme Grant.
ORCID iDs
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.