
Abstract
This paper reviews the disruptive role of ChatGPT in academic writing, focusing on its implications for scholarly practices and emerging ethical challenges. Using document co-citation analysis (DCA), it maps the thematic and intellectual structure of the discourse on ChatGPT in academic knowledge production. Drawing on a dataset of 171 peer-reviewed articles from Scopus, the analysis, conducted using CiteSpace, identified 10 major thematic clusters, including ethical risks, practical applications, and pedagogical innovations. The resulting high-modularity network (Q = 0.8989, S = 0.9466), comprising 866 nodes and 2,274 edges, ensured methodological rigor and thematic clarity. The findings reveal widespread recognition of ChatGPT's value in enhancing writing and supporting innovative educational frameworks, especially for non-native speakers. Concerns persist regarding hallucinated references, plagiarism, authorship ethics, and the reliability of AI-detection tools. Our paper accentuates the need for proactive oversight and policy development to ensure responsible integration of generative AI in research and education.
Introduction
Introduced in late 2022, ChatGPT, OpenAI's flagship innovation, has rapidly become an ineluctable technological tool. The platform has amassed 100 million users in only two months, making it by far the fastest-growing large language model (LLM) to have ever been created (Ray, 2023; Twinomurinzi & Gumbo, 2023). It has been popularized in mass media outlets as well as scholarly literature as a tool that has an unprecedented societal, technological, educational, and ethical impact on how humans will interact with democratized artificial intelligence-based software and what dilemmas LLMs like ChatGPT will cause in the future (Ray, 2023; Rudolph et al., 2023; Wei et al., 2024).
The present research aims to investigate how scholarly literature has perceived ChatGPT in academic publications disseminated on the subject. The choice of this research endeavor is not accidental. On the one hand, a myriad of benefits have been reported regarding the use or application of ChatGPT in education and research. Such benefits include a more accessible, personalized, and interactive learning and writing experience which highly enhanced student's engagement with educational materials (Dahlan et al., 2024; Limna et al., 2023) and theoretical research papers have also lamented that the implementation of ChatGPT may result in the fostering of critical thinking among students as well as more active collaborations due to the active, feedback-based nature of the platform (Bai˙doo-Anu & Ansah, 2023; Jelica et al., 2024; Kasneci et al., 2023). With regard to research, there is a dynamically growing body of literature which notes the positive aspects of using ChatGPT to facilitate data collection, processing, and analysis (Hassan et al., 2023), in helping to proofread manuscripts and assist writing from a technical standpoint (Karakose, 2023; Zhou, 2024) but also in sparking new ideas, coming up with novel hypotheses and finding research gaps (Karakose, 2023). On the other hand, however, a plethora of scholarly outputs have questioned the reliability and integrity of using the platform for educational and academic purposes. Research is growing fast on whether the use of AI-powered tools such as ChatGPT involves increased concerns on data privacy, as there is a substantial risk of sensitive information being accidentally or inadvertently shared through the platform, especially in view of the rather rudimentary legislative measures on artificial intelligence, even in seemingly more progressive legal environments, such as the European Union (Bin-Nashwan et al., 2023; Helberger & Diakopoulos, 2023; Khowaja et al., 2024; Leboukh et al., 2023; Sebastian, 2023; Taktak et al., 2024; Tlili et al., 2023; Wu et al., 2023). Scholars have also noted extensively the already existing and potential biases in working with ChatGPT. Results in this regard have demonstrated there is a burning bias issue with the usage of ChatGPT for professional purposes, as the platform regularly exhibits content and opinions that are diagnostic, educational, cultural, demographic, political and ideological, and in some instances, even gender bias (Gross, 2023; Huang, 2024; Motoki et al., 2023; Qu & Wang, 2024; Rozado, 2023; Schmidt et al., 2024). On a more academic writing-related note, Cotton et al.'s (2023) foundational paper—which also happens to be one of the highest-cited papers in this research subject at the time of writing of this study—highlights the potential misuse of ChatGPT for plagiarism and unauthorized assistance, while emphasizing the need for updated policies, ethical guidelines, and educational strategies. In this regard, Lin et al. (2023) also outlined that the three most significant problems with ChatGPT in research stem from the triad of research ethics, potential plagiarism of others’ work and the lack of integrity. An equally important problem with using the tool in research is its frequent “hallucinations” which arises from the fact that it is always obligated to respond to the user's query even in cases when it cannot access reliable or existing data (Alkaissi & McFarlane, 2023; Emsley, 2023). In academic writing, this often transpires into the creation of fraudulent research materials such as made-up databases or the generation and citation of non-existent literature (Da Silva, 2023; Day, 2023; Safdar et al., 2024b).
Even more importantly, there is a critical question to be asked when using ChatGPT for research: who is the author? Even more so; should we acknowledge it as an author? Does it even matter if ChatGPT was used in the writing of an article if the results itself are sound and valid? The current academic landscape tends to be cautious in answering these questions. Some claim that ChatGPT might even question the very definition of authorship and that critical questions should be asked on future ethical academic research (Nazarovets & Da Silva, 2024), while others reject this notion stating that the program lacks every fundamental skills that are attributed to an author which include knowledge, belief, intention, and accountability (Tang, 2024; Van Woudenberg et al., 2024). Journals, for instance, are slowly adapting to this issue with differing or somewhat naïve policies on acknowledging ChatGPT as an author or an assistant to the research conducted. In their highly cited opinion paper, Dwivedi et al. (2023) as well as Solomon et al. (2023) underline that ChatGPT is a transformative and highly disruptive tool which will most probably have significant benefits in certain research domains and emphasize the importance of integrating transparency, ethics, and effective regulations into the deployment of such AI systems.
The present research aims to analyze the current state of research on ChatGPT and academic knowledge production. As seen above, there are currently more questions than answers—and this is likely to remain the case for a long time. Nonetheless, understanding the interests of researchers in this subject is crucial and highly useful for developing future research agendas, identifying research gaps and reviewing significant literature and thematical topics. Subsequently, our study seeks to systematically map the scholarly discourse on ChatGPT in academic writing by identifying key thematic clusters and intellectual trends with the central objective of answering the question of how academic literature has conceptualized, critiqued, and integrated ChatGPT into knowledge production and scholarly communication.
Material and Methods
The present research employs the research model set forth by Cataldo et al. (2022) which is based on a scientometric assessment of literature with the use of document co-citation analysis (“DCA”). The proposed research methodology distinguishes itself from systematic literature reviews in its primary application in interdisciplinary and “cross-field” research. It uses a unique bibliometric method that focuses on the relationships among frequently cited documents, which effectively allows us to uncover the intellectual framework of a research domain by analyzing the frequency with which pairs of documents are co-cited in other publications (Appio et al., 2014; Mustafee et al., 2013; Trujillo & Long, 2018). The DCA is also an effective method for identifying key papers and authors in a subject. This approach also facilitates the creation of knowledge clusters and is an adequate method to create reliable knowledge networks with accurate results (Appio et al., 2014; Sanguri et al., 2020). As a preliminary limitation, however, it is necessary to note that scientometric analyses, including DCA, may inherit biases from the underlying dataset (such as publication language (English-only), journal selection bias within Scopus, and time lag effects that underrepresent newer but influential work) (Bradley et al., 2019; Worrall & Cohn, 2023). These limitations were taken into account when interpreting the results.
Bibliometric research has already been conducted on ChatGPT in its status and use in knowledge production in different disciplines (Abdelwahab et al., 2024; Baber et al., 2023; Farhat et al., 2024; Oliński et al., 2024; Safdar et al., 2024a; Tian et al., 2023; Yalcinkaya & Yucel, 2024), however, there is currently no comprehensive thematical research summarizing the current state of the art on ChatGPT and academic writing.
Following Cataldo et al.'s (2022) research outline, we used CiteSpace (version 6.4.R1.) to conduct the DCA and identify the key topical clusters. CiteSpace is a visualization tool designed for analyzing and mapping trends and patterns in scientific literature by identifying key research areas, authors, and concepts, and it facilitates the exploration of co-citation networks, keyword bursts, and the evolution of knowledge structures within a given field (Chen, 2004; 2005). We proposed the use of CiteSpace over other tools due to its advanced capabilities in detecting emerging trends, identifying burst terms, and producing high-resolution co-citation cluster maps, which are particularly suited for tracing intellectual structures in interdisciplinary domains (Liu et al., 2022; Ping et al., 2017). As CiteSpace supports time-sliced analysis and structural metrics such as modularity and silhouette scores, we deemed this tool exceptionally valuable in mapping academic discourses surrounding ChatGPT.
Data Collection
We utilized Elsevier's Scopus for data collection as it is one of the most reliable, accurate, and used scholarly repositories featuring rigorous content selection and an extensive coverage of publications (Baas et al., 2020). Data was collected in accordance with the PRISMA guidelines (Moher et al., 2009; Page et al., 2021). We used the following search string “(TITLE-ABS-KEY(“ChatGPT”) AND TITLE-ABS-KEY (“academic writing” OR “scholarly writing” OR “academic authorship” OR “scientific writing”)) on 24 December 2024 and identified 327 records for our search string. We focused on articles as they are more reliable in terms of academic rigor and excluded non-English papers. The final, cleaned dataset consisted of 171 documents.
The keywords selected for this study were chosen to reflect the central themes identified both in the existing literature and during preliminary data screening. Notably, we chose not to include broader terms such as “academic publishing” or “scientific communication,” as following our preliminary screening, these keywords seemed to capture a wider set of literature less directly focused on writing itself and more on editorial workflows or journal policies which are not constituent parts of our scope. Therefore, we aimed to specifically target the writing or preparation tasks to narrow down our focus with the selected keywords. Nevertheless, we have also included several references later in the paper that discuss academic publishing (see Sections 4.1–4.3). Even though the concentrated selection ensured thematic precision, we also underline preliminary limitations. For instance, excluding terms like the aforementioned examples may have filtered out relevant discussions on peer review and editorial policy shifts. Future work may benefit from a more expansive keyword strategy to encompass the broader institutional dynamics of AI in Academia. (Figure 1)
Data collection process (Own edit).
Importing Data on CiteSpace and Setting the Metrics
Data was then imported on CiteSpace. A total of 6294 references were found and the software identified 5875 references as valid with an extremely high success rate of 93% making the research eligible for conduct. When data was loaded into the CiteSpace, the link retaining factor (LRF) was set to 2.5 with maximum links per node set 10 and the TopN set to 1.0—meaning that only the most highly cited node (per time slice) was retained, based on citation frequency. CiteSpace employs a modified version of the g-index, incorporating a scaling factor k to adjust the threshold for selecting nodes or clusters in the analysis. The formula used is g2 ≤ k∑I ≤ gci. In this study, k was set to 125, striking a balance by including a reasonable number of nodes without overcrowding the visualization. For the Top N parameter, we opted to include the top 50 most cited and frequently occurring items from each time slice. Top N% was operationalized so that the top 10% of most cited items were selected for each slice with a maximum N of selected items per slice being set to 100.
The resulting network consisted of 866 nodes and 2274 edges, representing the connections between distinct items scuh as keywords, authors, or documents. The density of the network was 0.0061, indicating a sparse but meaningful structure with focused interactions among the included items. The largest connected component (LCC) comprised 45% of the nodes (391), indicating a substantial cluster of highly interconnected elements. Only 1% of the nodes were labeled, suggesting that labeling was highly selective, likely focusing on the most significant or central nodes. No pruning was applied, allowing for a comprehensive visualization of the network's complexity and relationships. The modularity (Q) and silhouette (S) values, as well as the high harmonic mean (Q, S), all confirmed that the network was meaningful and eligible for scientometric evaluation (Chen et al., 2010). The scores were the following:
Q = 0.8989 S = 0.9466 Q, S = 0.9221.
Generally, a Q value close to 1.0 signals well-separated clusters, while a high S score (for example, above 0.9) suggests internal consistency within clusters (cf. Chen, 2005; Newman, 2006). These values confirm that the network structure is both robust and thematically meaningful. Therefore, in our analysis, both the modularity (Q = 0.8989) and silhouette (S = 0.9466) values indicated strong structural and thematic cohesion.
Results
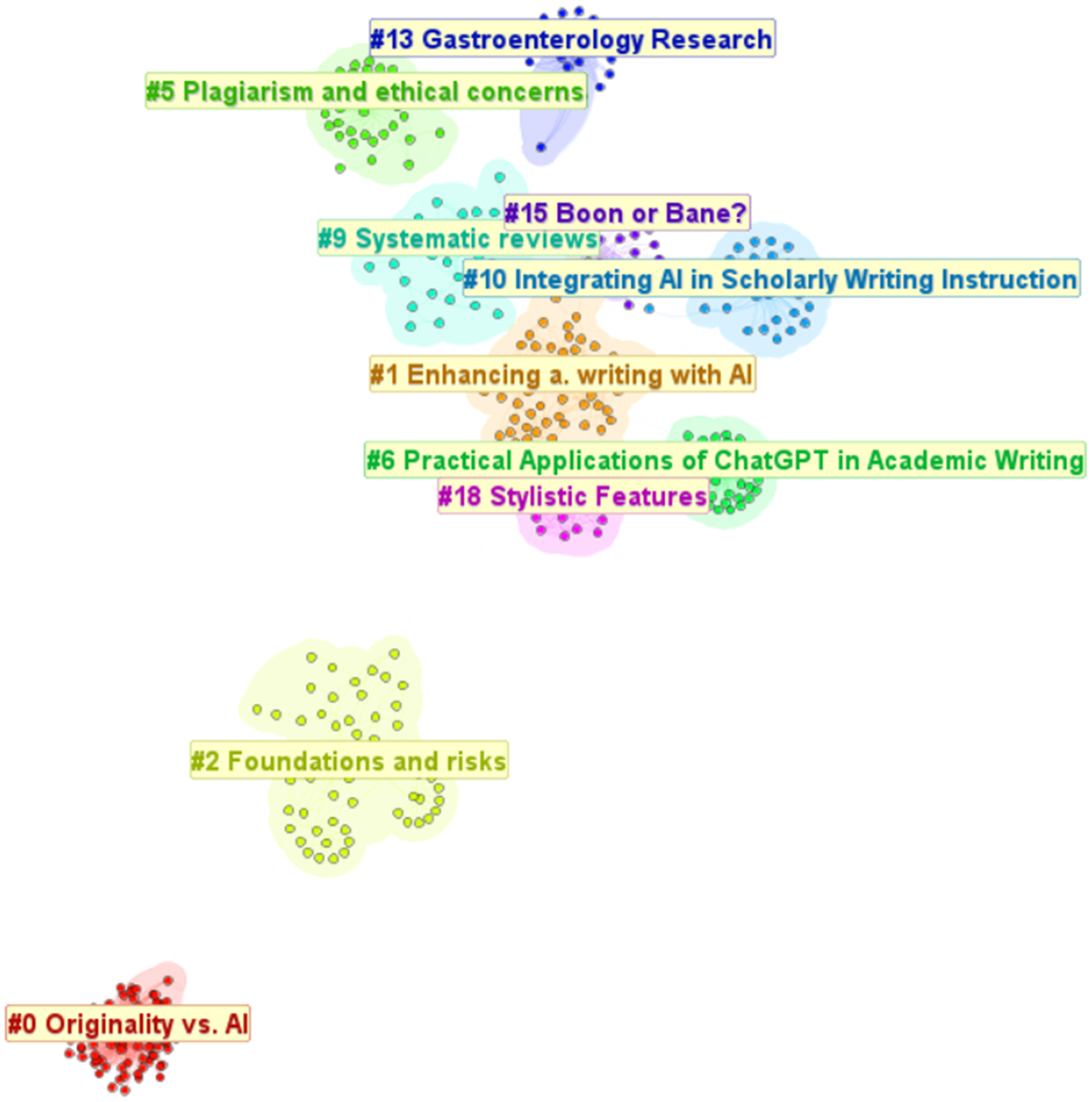
Figure 2 illustrates the co-citation network generated by CiteSpace, where each node represents a document and edges indicate the co-citation strength. Larger nodes denote more frequently cited works, while color-coded clusters reflect thematic groupings. The DCA resulted in the identification of 10 major clusters. Larger clusters represent more prominent topic clusters, while larger nodes on the clusters signify papers with more citations. The analyzed network revealed ten distinct clusters representing various thematic focuses within the realm of ChatGPT and academic writing. The largest cluster, Cluster #0 (“Originality vs. AI”), comprises 80 nodes with a highly cohesive silhouette score of 0.996 and an average publication year of 2022, reflecting its focus on originality and AI in academic writing. Following this, Cluster #1 (“Enhancing a. [academic] writing with AI”) includes 63 nodes with a moderate silhouette score of 0.776, primarily discussing the integration of AI tools to improve academic writing skills. Cluster #2 (“Foundations and risks”), the third largest, contains 57 nodes with a robust silhouette score of 0.977, emphasizing early ChatGPT-related publications and associated risks. Smaller but significant, Cluster #5 (“Plagiarism and ethical concerns”) consists of 39 nodes with a silhouette score of 0.953, focusing on ethical issues such as plagiarism in AI-assisted writing. Cluster #9 (“Systematic reviews”), with 31 nodes and a silhouette value of 0.901, highlights recent systematic reviews from 2023, underscoring GPT's features in research contexts. The remaining clusters, such as Cluster #10 (“Integrating AI in Scholarly Writing Instruction”) and Cluster #15 (“Boon or Bane?”), delve into specific applications and debates surrounding AI, showcasing the diverse scope of the network. (Figure 2)
The ten major clusters of research on ChatGPT and academic writing (Own edit).
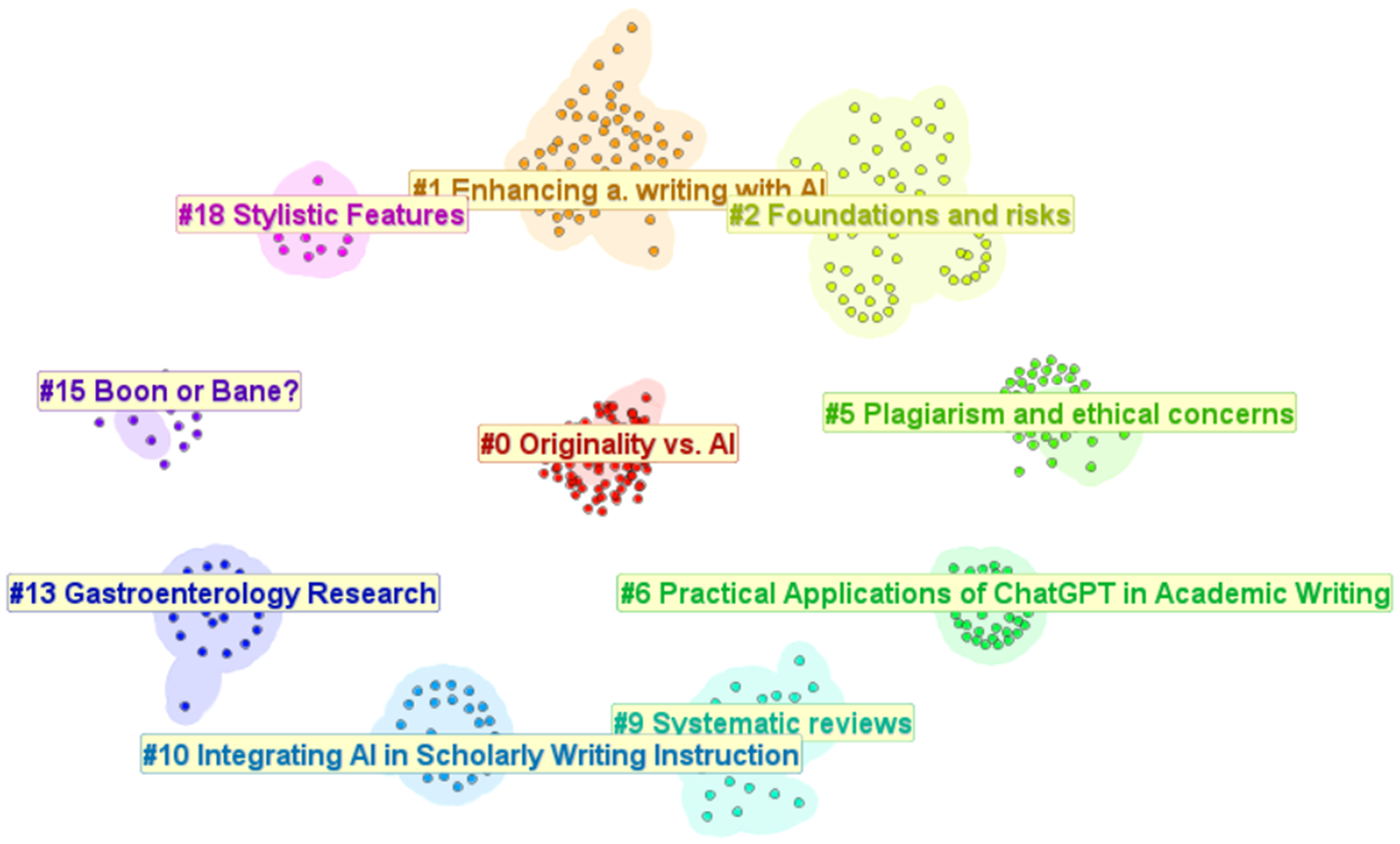
To enhance visual clarity, a circular layout of the network is provided in Figure 3 below. We computed this representation to emphasize the centrality of Cluster #0, which is thematically associated with the question of originality. This circular format also helps illustrate the relative interconnectedness of clusters and supports the grouping approach used later in the discussion. (Figure 3)
Circular visualization of the ten major clusters highlighting the central status of Cluster #0 (Own edit).
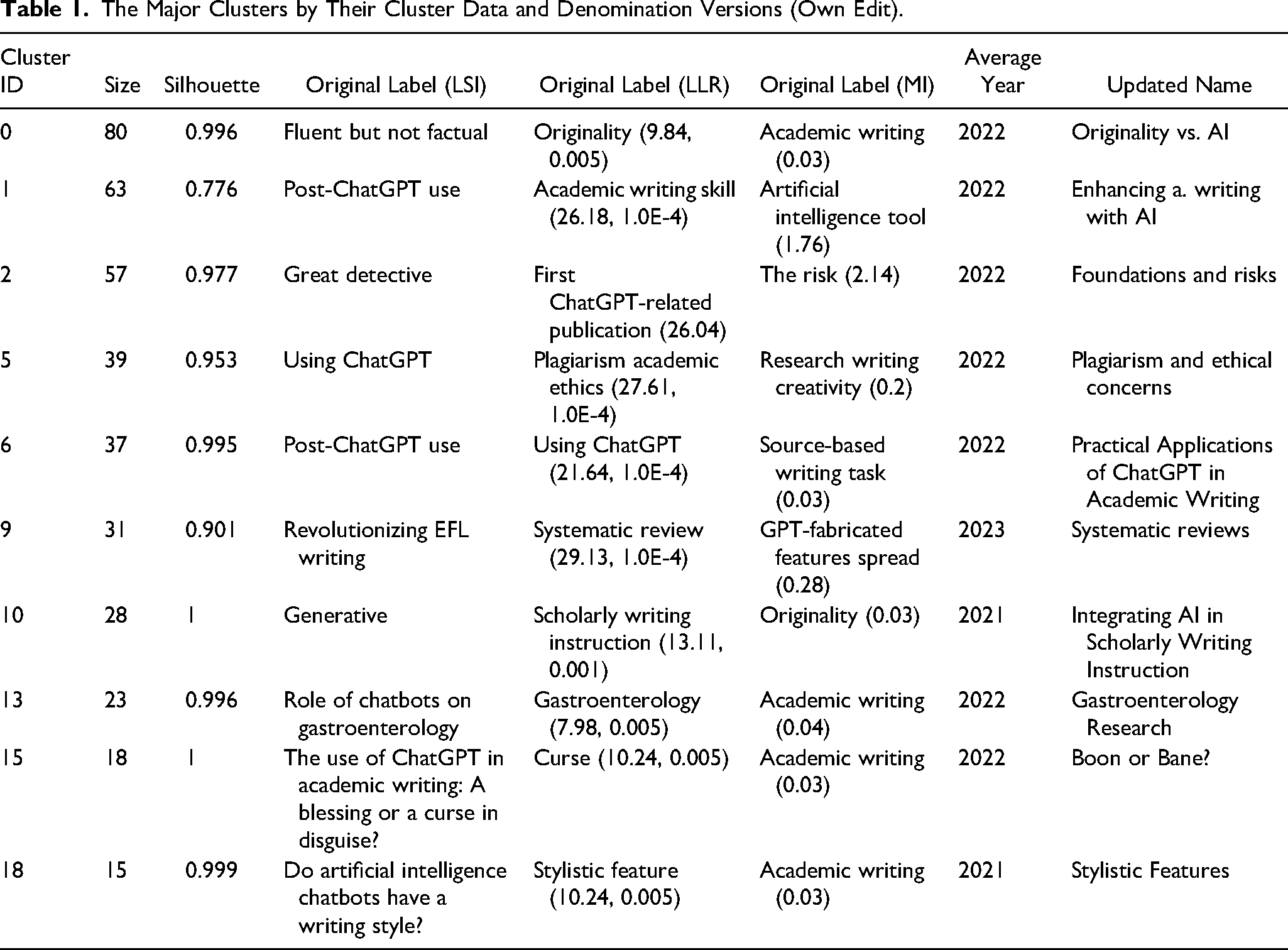
Clusters were renamed due to the rather incohesive auto-naming of CiteSpace. The changes made, as well as the other possible names, are also included. With regard to auto-labels, LSI is generated based on latent semantic indexing, summarizing the cluster's topic using keywords derived from the shared terminology of the articles. Similarly, LLR (Log-Likelihood Ratio) highlights the most statistically significant terms that distinguish the cluster from others, and MI (Mutual Information) identifies additional key terms by focusing on the informational overlap within the cluster. We introduce these new names as they are more descriptive of the papers and themes entailed in the respective clusters.
Furthermore, to enhance clarity, we first provide a brief and general overview of the range of topics represented by the identified clusters. The clusters capture a diverse set of discussions on ChatGPT in academic writing, including concerns about originality and authorship, practical tools and applications in scholarly workflows, ethical risks such as plagiarism and misinformation, and the pedagogical role of generative AI in education. However, it is worth noting that a great number of clusters focus on domain-specific themes. This can be exemplified by clusters related to the applications in medical writing or stylistic features of AI-generated texts. Moreover, although some clusters represent emerging concerns, others reflect established debates. This aspect enabled a comprehensive mapping of the intellectual discourse. (Table 1)
The Major Clusters by Their Cluster Data and Denomination Versions (Own Edit).
Although Cataldo et al. (2022) solely analyzed the larger clusters in more detail—mainly due to a larger dataset and many more references—we intended to outline all clusters and detail them by associative pairings. We investigated all clusters and, based on their descriptive data in CiteSpace, paired clusters according to their connectedness and thematic similarities, allowing us to create separate and distinct topical groups for discussion. For this analysis, we did not take into account the sizes of the clusters but rather focused on qualitative similarities. Our rearrangement of clusters has resulted in five distinct thematical groups presented below in Table 2.
Thematical Groups of Research on ChatGPT and Academic Writing (Own Edit).

We have identified four groups. Group 1 titled “Risks, Ethics, and Challenges” consolidates clusters addressing foundational concerns, such as plagiarism, academic integrity, and the dual nature of ChatGPT as both a tool and a potential threat. Group 2, “Practical Applications and Systematic Use” is distinctly focused on task-based roles, including ChatGPT's practical contributions to academic workflows and systematic reviews. Group 3, the “Innovation and Scholarly Integration” group, emphasizes ChatGPT's transformative impact on originality, writing skills, pedagogical integration, and stylistic features, reflecting its broader potential in academic contexts. There is a fourth group (Group 4), which was so special in theme that we deemed it necessary to make it a “stand-alone group” and titled it “Specialized Applications”. This group specifically focuses on a niche research endeavor, ChatGPT and gastroenterology research, which differs thematically from the broader discussions. Because Group 4 solely consisted of one individual major citing document—which is also included in another group (Group 1) and is accessible in full version online (cf. Li, 2023b)—as well as its extremely specified nature, which mainly concerns a niche segment of ChatGPT and academic writing research, we excluded this group from the discussion. (Table 2)
Following Cataldo et al.'s (2022) model, we first analyzed the DCA results for each cluster, in our case, each group. As CiteSpace has no identified and bursts, we mainly focused on citation data. With regard to specific cluster/group data, it is important to outline CiteSpace's labeling system. Coverage represents the number of articles within a cluster that cites a specific work, showing its influence within that research area. We considered GCS (Global Citation Score) which reflects the total number of citations an article has received across all datasets. In a few instances an individual paper was present in multiple groups. In these cases, we aimed to associate the paper, based on their findings and key thematical point to the more appropriate group and discuss its details therein.
Commencing with Group 1, we identified 23 individual papers with a mean coverage of 6.64 and a GCS of 7.48. It is to be underlined the certain papers, such as Li's (2023) paper on gastroenterology and ChatGTP was so prevalent that it was included in multiple clusters of themes. This group included two papers that we were not able to access in full-text version and they were not included in the discussion (%validity = 91.3). (Table 3)
Papers Included in the Risks, Ethics, and Challenges Group (Only First Author Mentioned) (Group 1) (Own Edit).

Group 2, which is titled Practical Applications and ChatGPT as a Research Assistant consisted of 8 documents. Both the mean coverage (9.125) and the mean GCS (10.125) were higher than in Group 1. We were able to access 7 out of 8 papers in full version (%validity = 88). (Table 4)
Papers Included in the Practical Applications and ChatGPT as a Research Assistant Group (Only First Author Mentioned) (Group 2) (Own Edit).

Group 3, consisting of 4 smaller clusters is titled Innovation and Scholarly Integration, and includes papers on the proficiency of AI chatbots (Lozić & Štular, 2023), stylistic features, and a segment on educational purposes which are closely related to innovative ways of transforming writing with ChatGPT (see Zhao et al., 2024). This group consisted is of 8 papers and had the both the highest mean Coverage (18.9) and mean GCS (12.5). Only one paper was inaccessible and, therefore, not included in the discussion (%validity = 87.5). (Table 5)
Papers Included in the Innovation and Scholarly Integration Group (Only First Author Mentioned) (Group 3) (Own Edit).

Discussion
The findings of our study reveal a rich but also rather fragmented discourse around ChatGPT in academic writing. The fragmentation emerges partly from ChatGPT's practical potential and ethical complexity but also from the different sectoral angles on the issue of implementing such tools in Academia. Having applied a DCA, we were able to identify three major thematic groups: (1) risks, ethics, and challenges; (2) practical applications and the role of ChatGPT as a research assistant; and (3) innovation and scholarly integration. These groupings were chosen based on descriptive findings stemming from citation frequency and also because they reflect the most salient tensions and controversial issues in the academic discourse: the growing concerns over integrity and authorship, the rapid adoption of ChatGPT as a functional tool, and its potential to reshape scholarly writing and education. The present discussion synthesizes these clusters to articulate broader implications for academic practice, institutional policy, and future research, moving beyond descriptive analysis to offer a critical assessment of where the field is heading.
Risks, Ethics, and Challenges
As a general observation, a vast majority of papers, as AI language models seem to expand at an exponential rate and their capabilities tend to develop at an unprecedented tempo, significant polemics and dilemmas arise in terms of how academic writing and knowledge production will change (Alberth, 2023; Carnino et al., 2024; Frosolini et al., 2023; Li, 2023a; Nazarovets & Da Silva, 2024; Popkov & Barrett, 2024). The papers included in this group heavily accentuate these issues in the specific segment of medicine and healthcare (Eppler et al., 2023; Fatima et al., 2024; Flitcroft et al., 2024; Labouchère & Raffoul, 2024; Lawrence et al., 2024; Liu et al., 2024; Pan & Florian-Rodriguez, 2024; Popkov & Barrett, 2024; Wang et al., 2024) and were almost exclusively empirical papers with very few theoretical research.
As for risks, hallucinations are of critical importance, particularly hallucinated references and academic work as well as completely fabricated data used for empirical purposes. Frosolini et al. (2023) and Albuck et al. (2024) tested different versions of ChatGPT and found a great tendency to generate incomplete, erroneous, or nonexistent references, raising concerns about the tool's reliability in scientific writing. Generating corpus is no exception of the above polemic; texts created with AI display a high error rate from a factual aspect which questions its use in certain research areas such as bibliometric analyses (Farhat et al., 2023)—though AlSagri et al.'s (2024) more recent research shows improvements in the latter area, especially in terms of ChatGPT's potential in literature reviews. Quality-wise, it can also be underlined that AI-generated texts are usually of lesser quality and comprehensiveness, however, it is also worth accentuating that it is becoming harder to differentiate between AI-generated and human written texts (Lawrence et al., 2024). Labouchère and Raffoul (2024) in this regard also emphasize the “superficial” statements generated by LLMs (ChatGPT and Bard) which cause concerns on the accuracy of research and the compromise of quality for the sake of productivity. In view of Carnino et al.'s (2024) findings, who noted the rapid increase in AI-generated or AI-assisted research and the positive attitude of researchers in certain segments to include Ai in research more (Eppler et al., 2023), these risks will undoubtedly be significant in research in the coming years.
From an ethical perspective, Nazarovets and Da Silva (2024) raise a critical issue based on their empirical research. The authors identified 14 papers crediting ChatGPT as an author, including cases where it was listed alongside editors-in-chief, and some of these papers have accrued significant citations, which raise concerns about the definition of authorship, accountability, and the enforcement of ethical standards in academic publishing. Read together with challenges of detecting AI in text these ethical concerns become even more burning. Kandeel and Eldakak (2024) highlight the legal side of ethical concerns. These include risks like copyright violations and plagiarism stemming from unverified or incorrect information generated by ChatGPT (Kandeel & Eldakak, 2024). Malik et al. (2024) also make the case that “creativity may no longer be restricted to the ability to write, but also to use ChatGPT or other large language models (LLMs) to write creatively” which eventually questions the very core of authorship and academic writing and may be a leading thought in the age of AI-assisted research.
AI-detection and the lack of reliability of these systems is probably one of the most capital problems. For example, Popkov and Barrett's (2024) experimental study found significant false positive and false negative rates across free and commercial AI detection tools. Free tools identified 27.2% of academic texts as AI-generated, while commercial software performed better (but still with substantial fault rates) when analyzing text from journals between 2016 and 2018 together with AI-generated content. Newer research, however, show different results, with freely accessible tools being more accurate than certain commercial detectors, such as Turnitin, especially when paraphrased texts were analyzed (Liu et al., 2024). Flitcroft et al. (2024), Chaka (2024), and Liu et al. (2024) also underline the high variability of results in different AI detectors indicating an important limitation in their use. Pan and Florian-Rodriguez's (2024) research which compared human reviewers and AI detectors confirmed the above results. Though at the time of the research humans highly outperformed AI detectors when identifying whether an abstract is generated by AI or is written by humans, there seems to be a vivid ongoing debate on the problems of using AI detectors for reviewing research (Pan & Florian-Rodriguez, 2024).
It is also worth noting that a few papers outline important benefits other than risks, ethical issues, and challenges. Scholars noted the increase in productivity, drafting assistance (especially in the case of non-English authors (Fatima et al., 2024; Li et al., 2024)), improvement in efficiency and patient outcomes (Ambrosio et al., 2023; Carnino et al., 2024; Levin et al., 2023; Li, 2023a; Li et al., 2024; Malik et al., 2024; Wang et al., 2024).
In sum, as noted by Levin et al. (2023), research on ChatGPT is still developing with a plethora of research gaps to explore. It can be stated, however, that there seems to be a crucial need to revise AI-related writing and editorial guidelines in academic publishing as they are either not in frequent use, outdated, or just simply easy to circumvent (Ambrosio et al., 2023). It is also to be underlined that using ChatGPT for research entails an increase in AI hallucinations, especially in terms of references (Albuck et al., 2024; Frosolini et al., 2023) which may be alarming in view of the growing problems surrounding the lack of capacity or, in certain cases, rigor, in peer reviewing (Hoffman, 2021; Tennant & Ross-Hellauer, 2020; Tite & Schroter, 2006). To end this segment, the cautious use of AI in scientific literature to preserve publication standards and reliability is advised with rigorous human oversight (Alberth, 2023; Albuck et al., 2024; AlSagri et al., 2024; Eppler et al., 2023; Fatima et al., 2024; Flitcroft et al., 2024; Lawrence et al., 2024). Furthermore, the strict adherence to copyright laws and academic regulations when utilizing AI tools should be more scrutinized to limit the potential harms (Kandeel & Eldakak, 2024).
Practical Applications and ChatGPT as a Research Assistant
As seen from the ending section in the previous section, integrating AI in academic writing is no longer a question of “when” but rather a question of “how” and more importantly, “how not to”. Though ethical dilemmas, and more focally, plagiarism is a key issue discussed in these papers (Jarrah et al., 2023), research conducted in this group and the pertaining clusters presents substantial benefits.
The common attitude towards ChatGPT is dual: it is both a transformative and a disruptive technology. The tool is noted for its important and facilitative role for non-English authors to prepare, and more importantly, enhance the level of writing of their papers (Cai et al., 2024; Kousha & Thelwall, 2025; Nugroho et al., 2024) and language enhancement is the most common acknowledgement scholars make when citing ChatGPT (Kousha & Thelwall, 2025). It can also be highlighted that academic integrity—though endangered by the overuse of abuse of ChatGPT in writing—may be protected, as it is easier to spot or highlight data errors or fake data or results via ChatGPT (Cai et al., 2024), though there is still significant room for improvement (AlSagri et al., 2024). AlSagri et al. (2024) coined the idea of testing an earlier version (version 3.5) of ChatGPT (and Gemini) as a research assistant and showed that though it often fell short in specific areas, in general, these tools are useful in assisting in explaining papers, exploring data and formatting citations.
In view of these results, we propose adopting the concluding thoughts presented in Andrade-Hidalgo et al. (2024) research which suggests that educators should be encouraged to adopt practical strategies by incorporating the reviewed tools and promoting AI literacy, collaborating with AI experts to develop more effective teaching methods, creating controlled environments where students can safely engage with AI, and providing ongoing training for educators on the ethical use of technology, as these efforts aim to ensure responsible teaching practices that uphold core educational principles. Moreover, on a more technical side of practicability, Cai et al. (2024) note that researchers may benefit from improved knowledge retrieval through the conversational interface of the platform, while journal editors can leverage GPT for manuscript classification and review processes.
As the level of integration of ChatGPT varies and “ChatGPT literacy” is rather rudimentary (Tarchi et al., 2024), there seems to be an important research gap in the effective use of ChatGPT in research and possible ways to meaningfully and ethically integrate the tool in writing other than language enhancement. Furthermore, educational research may also focus in the future on academic training opportunities to ameliorate expertise on the usage of LLMs in research.
Innovation and Scholarly Integration
Reflecting on the opening thoughts of Lozić and Štular's (2023) foundational work, as creativity and creativeness seemingly loses its uniquely human nature, research also tends to shift its focus on how the “new creativeness” brought by ChatGPT can be used for research innovation and integration.
Starting with innovation, mixed-method approaches show that among undergraduate students ChatGPT has positively impacted writing skills which was accompanied by a positive attitude towards the tool as well (Mahapatra, 2024). The latter is of critical importance because Sevnarayan and Potter (2024) found that there is a shift towards a more negative attitude among scholars, and in view of the practical benefits enshrined in this new technology, a new, innovative communication of ChatGPT and its positive side is necessary in Academia (also cf. Bin-Nashwan et al., 2023). This is also important as in other uses of ChatGPT, for example in teaching and learning as well as potential innovative opportunities, academics’ attitude tend to be positive (Maphoto et al., 2024). From a technical viewpoint, it can be noted that ChatGPT evolves innovatively, too. Per AlAfnan and MohdZuki's (2023) findings, ChatGPT's newly versions generate texts of average reading ease and rather low lexical diversity and uses more inclusive language (e.g., using “they” instead of singular forms of third-person pronouns). Though the originality of these texts is still questionable (Lozić & Štular, 2023), the rate at which ChatGPT develops, discussion on its innovative nature should also accelerate.
As for scholarly integration, Kong et al. (2024) introduces a 6-phase (6P) program to meaningfully and effectively integrate generative AI in academic writing. This proposed pedagogical framework begins with the Plan phase, where students develop a clear outline of their writing's content and structure, ensuring control over the process by defining the thesis and organizing ideas effectively. In the Prompt phase, students craft and refine prompts to interact with generative AI tools, guiding the AI to generate content aligned with their goals. During the Preview phase, students critically evaluate the AI-generated output for accuracy, coherence, and alignment with their objectives, correcting errors and cross-referencing with credible sources. The Produce phase requires students to integrate the validated AI-generated ideas with academic references and their perspectives to create a coherent and credible piece of writing. In the Peer Review phase, students exchange feedback with peers to improve the quality, clarity, and depth of their work. Finally, the Portfolio-Tracking phase involves reflecting on the entire process, assessing performance, and developing strategies to enhance their use of AI tools for future academic writing tasks. This framework emphasizes self-regulation, critical thinking, and ethical engagement with AI in educational contexts. (Kong et al., 2024).
Regarding a broader understanding of integration, it is worth revisiting the detection-dilemma set forth in Group 1. Chaka's (2024) comprehensive detector-testing research shows that integration should entail a combinative approach to AI-detection which is built on both newer, AI-specific detectors as well as traditional plagiarism detectors with the input and oversight of humans.
Summary of Key Themes in the Literature on ChatGPT in Academic Writing
In order to provide a more accessible overview of the findings discussed throughout the above-detailed sections, Table 6 below summarizes the core thematic areas identified through the DCA. These areas, namely, ethical risks, practical applications, and pedagogical innovation, all emerged consistently in some form across multiple clusters. The goal of this synthesis is to condense a large and diverse body of literature into a comparative format that highlights not only what is being discussed, but why it matters for academic institutions, researchers, and policymakers. Firstly, ethical challenges such as fabricated citations, ambiguous authorship, and unreliable AI detection mechanisms appear to dominate the discourse, particularly in empirical studies from the medical and STEM fields. In parallel, researchers have begun exploring functional uses of ChatGPT, particularly in assisting non-native speakers, improving clarity, and automating low-level writing tasks. Subsequently, there is no clear scientific stance on the direct use of ChatGPT in academic writing as there certainly are useful and practical benefits, however, ChatGPT-enhance works are tempered by concerns over factual reliability and the risk of academic dependency. Secondly, from pedagogical standpoint, a number of studies propose structured integration frameworks that seek to maintain academic rigor while embracing AI as a tool for enhancing learning and scholarly expression. Nonetheless, attitudes among educators remain mixed and there is a growing consensus that responsible use, guided by clear ethical policies and transparent disclosure, is more sustainable than outright bans or unchecked adoption. We propose that the below thematic synthesis helps clarify not only the breadth of ongoing debates but, more importantly, also the emerging areas where more theoretical grounding, policy development, and empirical testing are needed. (Table 6)
Summary of the Discourse on ChatGPT in Academic Writing.

As an ending to the discussion, we also acknowledge that our findings have several limitations. First of all, since drew our data exclusively from English-language Scopus-indexed literature, it may have affected the inclusivity of our research and given Scopus's innate limitations, the findings potentially underrepresent perspectives from non-Western and non-English contexts. Moreover, software constraints in CiteSpace limited the detection of citation bursts, excluding emerging yet uncited work. Future research should address these limitations by integrating qualitative content analysis, and prospectively, expert interviews. Expanding data sources to include preprints and non-English publications.
Research Agenda
Building on our findings, we propose that future research should move beyond identifying risks and begin addressing concrete institutional and disciplinary needs. Although ethical concerns remain undisputed and central, there is limited insight into how journal editors, peer reviewers, and academic institutions are adapting to AI-assisted writing. Research should examine how policies are evolving, where inconsistencies remain, and how detection and disclosure practices can be standardized. Furthermore, studies should explore ChatGPT's role in promoting or complicating scholarly equity, especially for non-native English speakers and under-resourced researchers. Few papers assess whether generative AI narrows global academic inequalities or creates new forms of dependency. These questions are critical as AI tools become more accessible across diverse educational contexts. Lastly, there is a burning need for more developed theoretical frameworks as most current literature remains descriptive or, in some cases, anecdotal. Future work should incorporate ethical, epistemological, or STS frameworks to analyze AI's impact on scholarly norms, authorship, and publication culture. In this regard, longitudinal studies could track how AI reshapes academic writing genres and disciplinary communication over time. Lastly, further bibliometric and scientometric papers would be necessary to better outline research venues for other disciplines.
Educational Implications
In view of the literature, the integration of ChatGPT into educational settings must be addressed with urgency, as the technology presents both transformative opportunities and serious challenges. The problem of integration, however, is a complex issue and should be treated with adequate supervision. On the one hand, ChatGPT can enhance learning by offering personalized, iterative writing support (cf. Oates & Johnson, 2025), particularly for students struggling with language or expression. It may also encourage exploratory thinking when used as a brainstorming tool (see Almumen & Jouhar, 2025). However, concerns over over-reliance and academic dishonesty are valid. An important implication to consider is to help mitigate these risks, institutions through implement structured AI-use policies in coursework, including clear guidelines on disclosure, permitted tasks, and expectations for independent contributions. In this regard, AI literacy programs are essential at both undergraduate and postgraduate levels (Almatrafi et al., 2024; Ng et al., 2023). These programs should go beyond technical use and include ethical reasoning, limitations of generative tools, and practical use cases. For example, the 6P pedagogical framework proposed by Kong et al. (2024) offers a step-by-step integration model for AI in academic writing courses. Universities might also consider incorporating AI-focused modules into academic integrity or digital research skills curricula (cf. Rudolph et al., 2024 and Naznin et al., 2025). Moreover, faculty development is key. Educators require training and support to stay ahead of technological shifts and to design assignments that encourage meaningful engagement rather than shortcutting learning.
Best Practices
Scholars integrating ChatGPT into academic workflows must exercise extreme caution to preserve the integrity and reliability of their work. It is undeniable that ChatGPT offers valuable support in drafting, editing, and language enhancement among a plethora of other benefits, however, its susceptibility to generating hallucinated references, factual inaccuracies, and biased outputs poses significant risks. Banning or restricting ChatGPT in academic knowledge production with the current detection systems is nearly impossible. Therefore, to mitigate these challenges, researchers should always verify AI-generated content against credible sources and should always refrain from using ChatGPT for generating primary research data or references. Transparency is paramount; scholars should disclose their use of AI tools in all academic outputs to maintain ethical accountability. On a more holistic level, there is a clear need for the development of best practices in academic institutions. Employing hybrid AI-detection systems alongside human oversight can ensure that scholarly outputs remain authentic and credible and should be more accentuated in scholarly and editorial guidelines. Lastly, scholars are also encouraged to explore ChatGPT as a supplementary tool for idea generation or language refinement rather than as a primary authoring resource. Adopting these best practices can help balance the benefits of ChatGPT with the need to uphold rigorous academic standards and ethical norms.
Conclusions
Our study aimed at systematically mapping the research landscape of ChatGPT in academic writing through document co-citation analysis with CiteSpace. We identified major thematic clusters as well as emerging intellectual trends. Our findings reveal a dual narrative. While ChatGPT enhances accessibility, especially for non-native speakers and under-resourced authors, it simultaneously raises serious concerns regarding authorship, plagiarism, the validity of the generated content, and the limitations of AI-detection tools. Although some journals have banned AI tools from authorship credit, others lack explicit guidance, leading to inconsistencies in ethical enforcement. We find it critical to emphasize that addressing this issue is urgent as these policy and scholarly ethical gaps in the terms of use of LLM in writing be mitigated through clearly articulated disclosure requirements and institutional policies. Our study also suggests that research on ChatGPT should expand beyond ethical polemics. There is a need to include deeper investigations into disciplinary applications, equity, and the long-term impact on scholarly communication and future research must be both interdisciplinary and cross-cultural, capturing the diverse ways generative AI is shaping academic work. We claim that a proactive and collaborative approach among educators, researchers, and policymakers will be essential in ensuring that AI augments rather than undermines the integrity of academic knowledge production.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Project no. TKP2021-NKTA-51 has been implemented with the support provided by the Ministry of Culture and Innovation of Hungary from the National Research, Development and Innovation Fund, financed under the A TKP2021-NKTA funding scheme.
Data Availability
The dataset used is attached.