
Abstract
The International Network for the Demographic Evaluation of Populations and Their Health (INDEPTH) is a global network of research centers that conduct longitudinal health and demographic evaluation of populations in low- and middle-income countries (LMICs) currently in 52 health and demographic surveillance system (HDSS) field sites situated in sub-Saharan Africa (14 countries), Asia (India, Bangladesh, Thailand, Vietnam, and Indonesia), and Oceania (Papua New Guinea). Through this network of HDSS field sites, INDEPTH is capable of producing reliable longitudinal data about the lives of people in the research communities as well as how development policies and programs affect those lives. The aim of the INDEPTH Data Repository is to enable INDEPTH member centers and associated researchers to contribute and share fully documented, high-quality datasets with the scientific community and health policy makers.
Keywords
Introduction
The International Network for the Demographic Evaluation of Populations and Their Health (INDEPTH) is a global network of research centers that conduct longitudinal health and demographic evaluation of populations in low- and middle-income countries (LMICs). INDEPTH member health and demographic surveillance systems (HDSSs) contribute annually updated individual-level datasets (core micro dataset) representing basic demographic events (births, deaths, migrations) and person years under surveillance (exposure). Data are collected in defined geographic areas through regular household visits following an initial census using either paper-based or electronic questionnaires. In addition, datasets from multi-center studies conducted in INDEPTH member HDSSs are shared on the repository. Every dataset in the repository is documented using an internationally accepted metadata standard by the Data Documentation Initiative (DDI). Digital object identifiers (doi) are assigned to all the datasets to aid citation.
The INDEPTH Data Management Programme (IDMP, formerly known as iSHARE) assists centers and network studies with dataset extraction, harmonization, quality control, and documentation, and administers the INDEPTH Data Repository (http://www.indepth-ishare.org) aimed at sharing the INDEPTH data globally.
INDEPTHStats is a website for visualizing key demographic indicators based on the core micro datasets in the repository (http://www.indepth-ishare.org/indepthstats/).
Key Characteristics of the INDEPTH Data Repository
The INDEPTH Data Repository is a unique resource for complete and detailed longitudinal public health data from geographically defined populations in LMICs.
The datasets available on the repository will grow over time as more member centers provide core micro datasets, and more studies conducted in the INDEPTH network share data on the INDEPTH Data Repository.
At the time of publication, the core micro datasets on the repository have data from 25 centers representing 2 million individuals and 24 million person years of observation.
The repository contains the largest dataset on cause specific mortality in LMICs ever published.
Data contained in the repository have been used to describe the population impact of major infectious diseases such as malaria, HIV, and TB, as well as the impact of relevant interventions.
The data are also suitable for quantifying millennium development goals (MDGs; for example, MDG 5 and 6) in select populations.
Data Resource Basics
INDEPTH Network (Sankoh & Byass, 2012) developed the INDEPTH Data Repository to make data originating from the longitudinal surveillance conducted by its member HDSSs available to the scientific community. Each HDSS maintains a dynamic population cohort, which is regularly surveyed to build up a longitudinal database of individuals and social units in the surveillance areas. INDEPTH encourages its members to release a snapshot of this database on an annual basis as a core micro dataset on the repository. These datasets are in a standard format (Sankoh & Byass, 2012) and represent the basic demographic events (births, deaths, migrations) and person years under surveillance (exposure) of the complete HDSS population. In addition, datasets from multi-center studies conducted in INDEPTH member HDSSs are shared on the repository. Examples of such datasets include the cause-specific mortality dataset (Streatfield et al., 2014) and soon to be released datasets from the Migration and Urbanization working group (Gerritsen et al., 2013). Table 1 lists the HDSSs that have released core micro datasets on the repository.
HDSSs That Have Contributed Core Micro Datasets to the INDEPTH Data Repository.
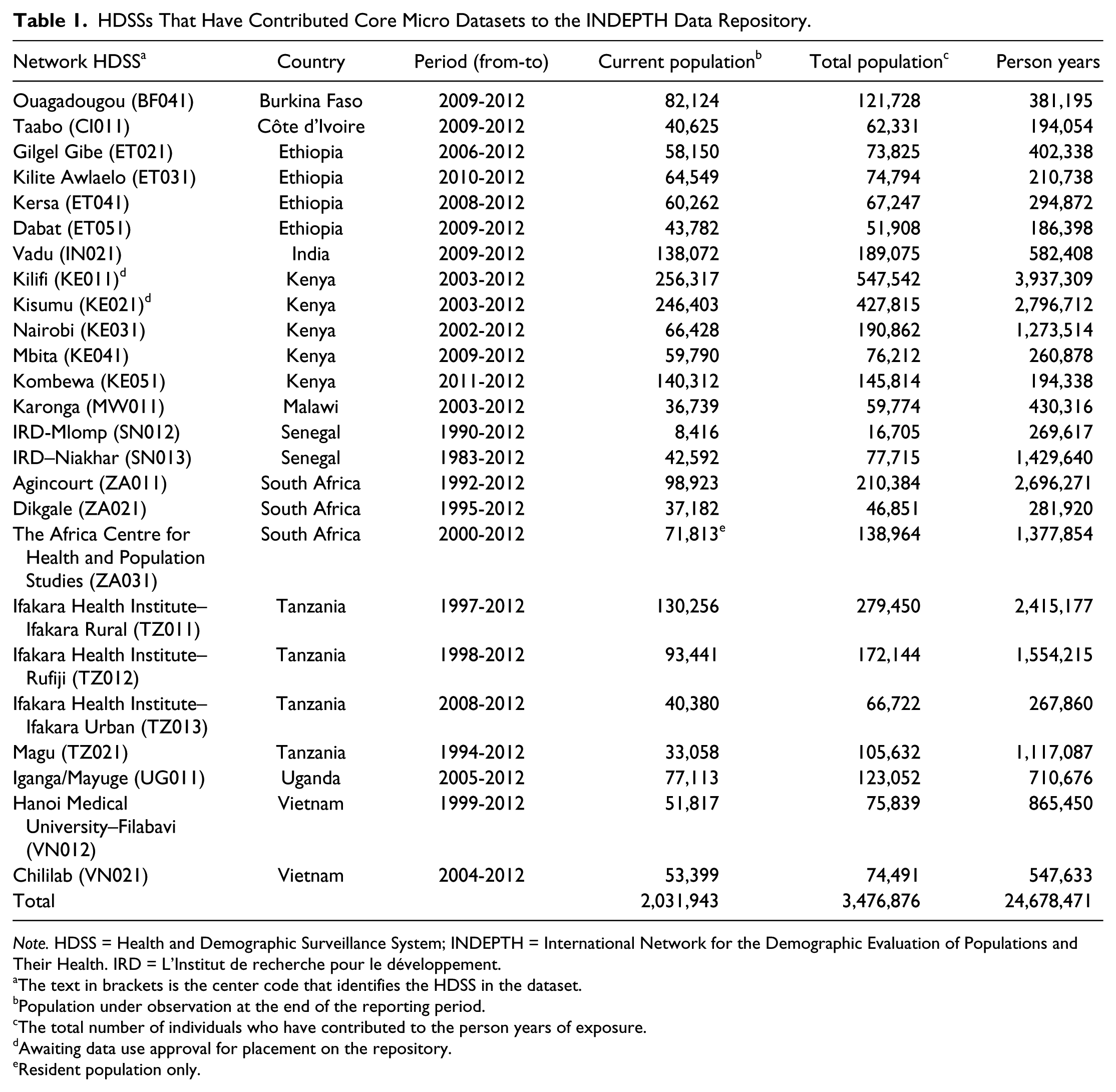
Note. HDSS = Health and Demographic Surveillance System; INDEPTH = International Network for the Demographic Evaluation of Populations and Their Health. IRD = L’Institut de recherche pour le développement.
The text in brackets is the center code that identifies the HDSS in the dataset.
Population under observation at the end of the reporting period.
The total number of individuals who have contributed to the person years of exposure.
Awaiting data use approval for placement on the repository.
Resident population only.
All datasets are documented using a standard DDI (Vardigan, Heus, & Thomas, 2008) document template summarized in Table 2.
Standard Metadata Template for INDEPTH Data Repository Datasets.

Note. INDEPTH = International Network for the Demographic Evaluation of Populations and Their Health; DDI = Data Documentation Initiative.
Dataset Production Support
Datasets hosted on the INDEPTH Data Repository follow a standard procedure to extract, harmonize, quality assure, and document the data. This process is facilitated by an IDMP support team and the provision of a standard all-in-one computer hardware and software environment called the “Centre-in-a-Box” (CiB).
Portable mini server hardware. The hardware hosts an operating environment or hypervisor (http://en.wikipedia.org/wiki/Hypervisor) that supports the virtual operating environments needed for dataset production. Database server. One of the virtual operating environments on the CiB hardware hosts a database system that replicates the operational database of the HDSS to facilitate easy transfer of data from the operational system to the analytical dataset production environment. HDSS uses a variety of database systems, and this arrangement assists in developing common data extraction procedures although database systems may differ from site to site. Data manager workstation. The second virtual operating environment is used to host the software required to prepare and document the datasets that will eventually be shared on the repository. The following free software programs are used: Pentaho Data Integration (Community Edition; Pentaho Corporation, 2014). This program is used to extract data from the different underlying database systems, transform the data into a standard format, and load the data into the repository (Extraction, transformation and loading [ETL]). As far as possible, common ETL scripts are used to ensure consistent processing of the data and to reduce the burden of developing center-specific programming. Nesstar Publisher (Norwegian Social Science Data Services, 2013). This program is an editing tool used to prepare the DDI compliant metadata that documents each dataset on the repository. System server. The third virtual operating environment hosts server components that manage the CiB environment, including system security, the shared file system, and a web server. The key software programs are as follows: Zentyal (Zentyal, 2013). A Linux-based server that manages network security, user authentication, and a shared file system for the CiB. Microdata Cataloguing Tool (National Data Archive, [NADA]); The World Bank, 2013). The CiB provides a local implementation of the World Bank-developed Microdata Cataloguing Tool. This local instance is used to view the data documentation prior to uploading the documentation to the network repository. The INDEPTH Repository is also based on this web-based content management application.
Dataset Production Process
With the exception of the core standard micro dataset, which represents the basic demographic events obtained from the HDSS operations, datasets originate from multi-center research or data analysis efforts by scientists from INDEPTH member HDSSs around a common research theme or question. The dataset production process generally follows a standard process to ensure the consistency and quality of the datasets hosted on the INDEPTH Data Repository (Figure 1).
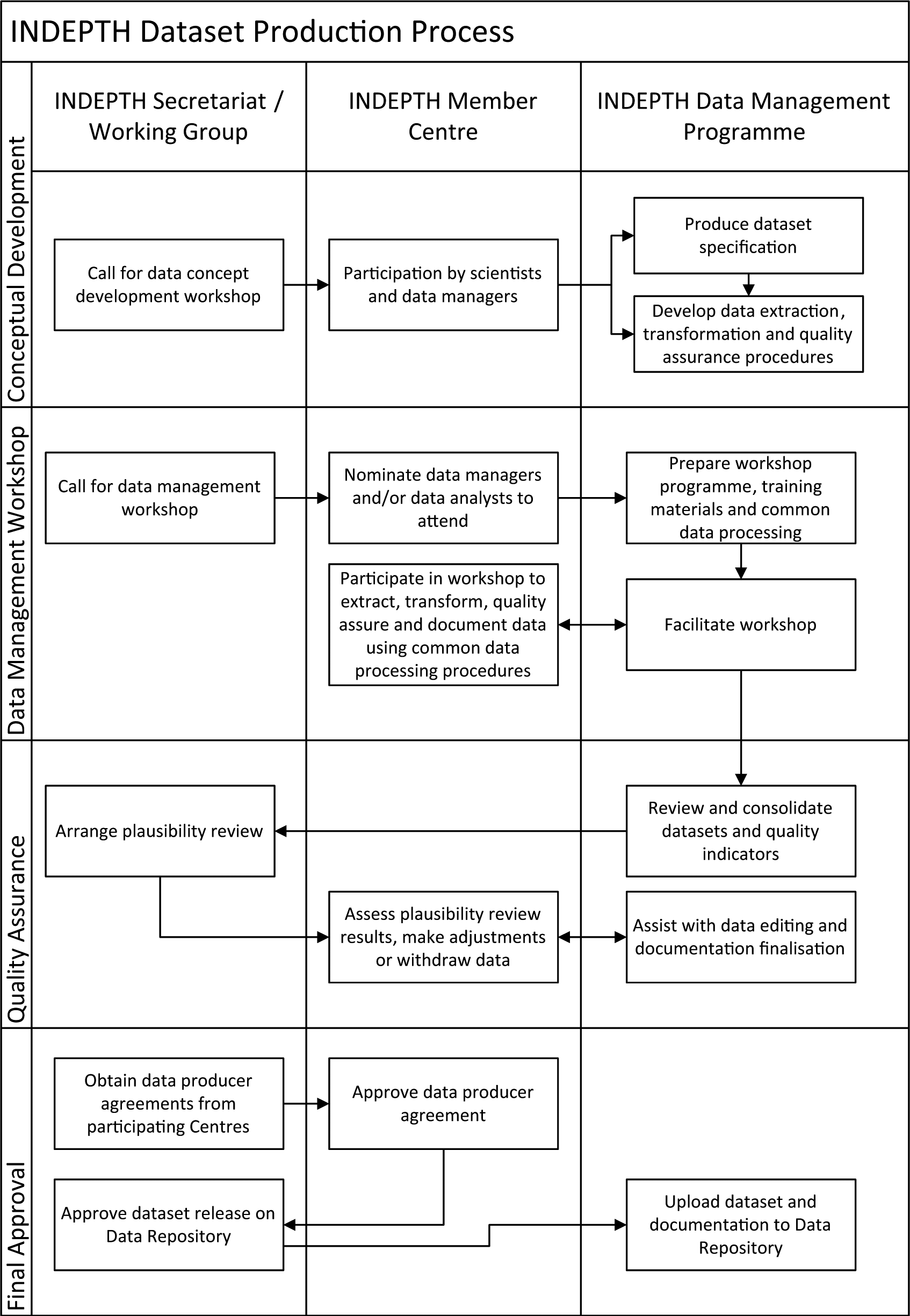
Dataset production process.
Data Resource Use
The INDEPTH Data Access and Sharing Policy (Sankoh & Byass, 2012) identifies the following levels of access to shared network data:
The INDEPTH Data Repository uses different terminology to identify these access levels, and the equivalent access levels are tabulated in Table 3.
INDEPTH Data Access Policy Levels Compared With the Built-In Access Levels on the Repository.
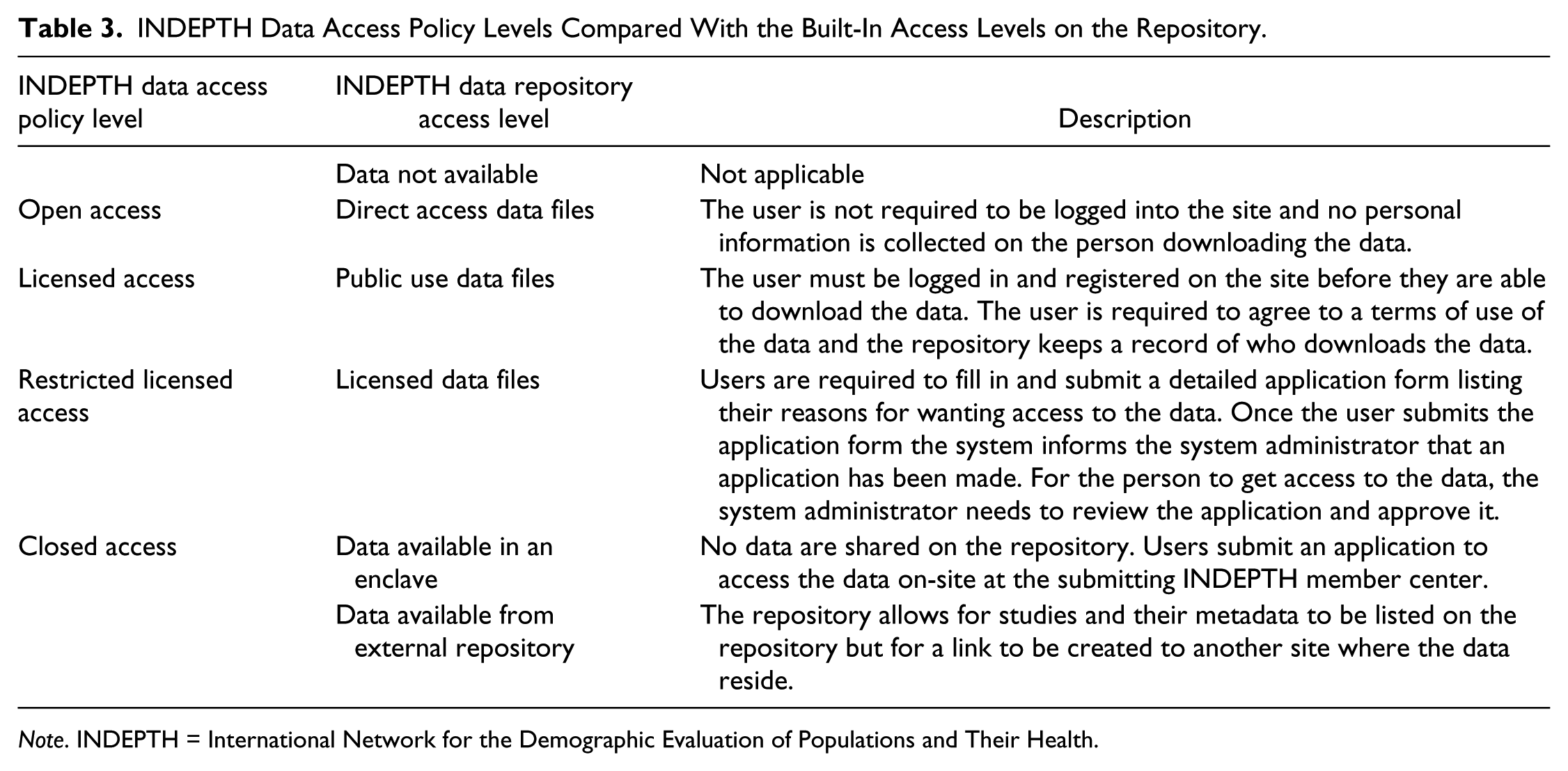
Note. INDEPTH = International Network for the Demographic Evaluation of Populations and Their Health.
When downloading data from the repository, the user agrees, by accepting the click-through data use agreement, to the following conditions:
To not redistribute or sell the data;
In the case of multi-site datasets, to not analyze or report on a single site’s data without permission from the site concerned;
To not attempt to identify individuals;
To not produce links to other datasets that could identify individuals;
To cite the source of the data according to the citation requirement provided with the dataset;
To provide copies of publications based on the data to INDEPTH;
A disclaimer that the original collector of the data, INDEPTH or the relevant funding agencies bear no responsibility for the data’s use or inferences based on it.
The repository records page views by prospective data users as well as dataset downloads. In the case of licensed and restricted licensed access datasets, user details are recorded as well. Table 4 summarizes the region of origin for the 724 downloads that took place between the launch of the repository on July 1, 2013, and at the end of June 2015.
Dataset Download by Region Between July 1, 2013, and June 29, 2015.

The INDEPTH Network is registered with DataCite (2014) through the GESIS–Leibniz Institute for the Social Sciences and has been allocated the 10.7796 doi (Paskin, 2008) prefix. All datasets are registered with a unique doi that must be included when the dataset is cited.
A digital fingerprint (Altman & King, 2007) is calculated using an MD5 (Rivest, 1992) hash function for each dataset. This universal numeric fingerprint (UNF) is stored as part of the metadata describing the dataset, and a data user can use the UNF to verify that the data were not intentionally or unintentionally altered.
INDEPTHStats is a website associated with the INDEPTH Data Repository for visualizing key demographic indicators based on the core micro datasets in the repository. This assists prospective data users and policy makers to obtain a quick overview of the information contained in the detailed datasets on the repository without needing to analyze the datasets first.
Strengths and Weaknesses
Strengths
Detailed data from populations without vital registration
Longitudinal with accurate denominators
Datasets in easy-to-analyze event history format
Dataset published in widely supported UTF8 encoded comma separated text files
Weaknesses
Available data limited both in scope and number of sites, but will expand in future
Not representative in the traditional sense, but still very useful in providing insights into population dynamics and health intervention impact
Footnotes
Acknowledgements
The authors acknowledge the following data managers and scientists from the International Network for the Demographic Evaluation of Populations and Their Health (INDEPTH) Network who participated in the data management workshops and made their data available for inclusion in the INDEPTH Data Repository:
Agincourt HDSS (South Africa): Sulaimon Afolabi and Paul Mee
Chililab HDSS (Vietnam): Pham Viet Cuong and Tran Huu Bich
Dabat HDSS (Ethiopia): Tesfahun Melese and Yigzaw Kebede
Dikgale HDSS (South Africa): Timotheus Darikwa and Ian Cook
Filabavi HDSS (Vietnam): Tran Thanh Do and Nguyen Thi Kim Chuc
Gilge Gibe HDSS (Ethiopia): Muluemebet Abera and Fasil Tessema
Ifakara and Rifiji HDSSs (Tanzania): Advocatus Kakorozya and Eveline Geubbels
Kanchanaburi HDSS (Thailand): Jongiit Rittirong and Sureeporn Punpuin
Karonga HDSS (Malawi): Keith Branson and Menard Chihana
Kaya HDSS (Burkina Faso): Maurice Yameogo and Simon Tiendrebeogo
Kilifi HDSS (Kenya): David Amadi and Marianne Munene
Kilite Awlaelo HDSS (Ethiopia): Fisaha Haile and Gebrehiwot Weldu
Kisumu HDSS (Kenya): David Obor and Christine Khaggayi
Magu HDSS (Tanzania): Baltazar Mtenga
Mbita HDSS (Kenya): Morris Mwangangi and Mohamed Karama
Nairobi HDSS (Kenya): Patricia Elungata and Boniface Nganyi
Nanoro HDSS (Burkina Faso): Adama Kazienga and Karim Derra
Ouagadougou HDSS (Burkina Faso): Bruno Lankoande and Abdramane Soura
Taabo HDSS (Cote d’Ivoire): Laubet Martial and Kone Siaka
Wosera HDSS (Papua New Guinea): Lorna Samol, Stanley Aisi, and Suparat Phuanukoonnon
Kersa HDSS (Ethiopia): Mahlet Mekonnen Gebeyehu and Nega Kassa
Kombewa HDSS (Kenya): Mary Oyugi and Peter Sifuna
Rakai HDSS (Uganda): Joseph Sekasanvu and Tom Lutalo
Iganga/Mayuge HDSS (Uganda): Noah Kasunumba
Niakhar HDSS (Senegal): Djibril Dione and Valerie Delaunay
Mlomp HDSS (Senegal): Ousmane Ndiaye and Valerie Delaunay
Dodowa HDSS (Ghana): Alfred Manyeh and Sheila Addei
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by the Wellcome Trust (Grant 097318/C/11/Z), with contributions from Sida/Research Cooperation and the Hewlett Foundation especially for the participation of Osman Sankoh, Martin Bangha, and Titus Tei.