
Abstract
Qualitative research data, such as data from focus groups and in-depth interviews, are increasingly made publicly available and used by secondary researchers, which promotes open science and improves research transparency. This has prompted concerns about the sensitivity of these data, participant confidentiality, data ownership, and the time burden and cost of de-identifying data. As more qualitative researchers (QRs) share sensitive data, they will need support to share responsibly. Few repositories provide qualitative data sharing guidance, and currently, researchers must manually de-identify data prior to sharing. To address these needs, our QDS team worked to identify and reduce ethical and practical barriers to sharing qualitative research data in health sciences research. We developed specific QDS guidelines and tools for data de-identification, depositing, and sharing. Additionally, we developed and tested Qualitative Data Sharing (QuaDS) Software to support qualitative data de-identification. We assisted 28 qualitative health science researchers in preparing and de-identifying data for deposit in a repository. Here, we describe the process of recruiting, enrolling, and assisting QRs to use the guidelines and software and report on the revisions we made to our processes and software based on feedback from QRs and curators and observations made by project team members. Through our pilot project, we demonstrate that qualitative data sharing is feasible and can be done responsibly.
Keywords
Introduction
Quantitative research data are often made publicly available and used by secondary researchers, promoting open science and improving research transparency (DuBois et al., 2018; Merriam, 2002; Nosek et al., 2015). A trend is also emerging for researchers to share their qualitative social science data, such as data from focus groups and in-depth interviews (Bishop & Neale, 2011; Campbell et al., 2023; Corti, 2011; Corti & Thompson, 2004; DuBois et al., 2023; Feldman & Shaw, 2019; Mozersky et al., 2022). An increasing number of professional associations, journals, and funding institutions promote qualitative data sharing (QDS) to generate new findings with existing data, bring down costs, reduce participant burden, and enhance qualitative research transparency (Bishop, 2009; DuBois et al., 2018; Hemphill et al., 2022; Kirilova & Karcher, 2017). For one, the National Institutes of Health (NIH), the largest federal funding body of health research in the US, issued a new data sharing policy in 2023. The policy specifically mentions qualitative data and offers some guidance on navigating qualitative data sharing challenges (National Institutes of Health, 2022a; National Institutes of Health, 2022b). The policy requires all NIH-funded investigators to submit data management and sharing plans to “integrate data sharing into the routine conduct of research” (National Institutes of Health, 2020).
Despite this new NIH policy and other data sharing mandates, researchers have expressed myriad concerns regarding qualitative data sharing (Broom et al., 2009; Kuula, 2011; Mozersky et al., 2021; Mozersky, Parsons, et al., 2020; Tenopir et al., 2011; Yardley et al., 2014). Data repositories play a vital role in data sharing as they provide stewardship and discovery of archived data and provide access to metadata that can be useful for understanding shared data (Antonio et al., 2020; Corti & Thompson, 2004; Fenner et al., 2019). To some qualitative researchers (QRs), the very idea of sharing qualitative data in a repository is preposterous (Mozersky, Walsh, et al., 2020). Others find the idea of analyzing another researcher’s data inconsistent with the goals, purpose, and meaning of qualitative research (Broom et al., 2009), where details are gleaned from one-on-one conversations with participants (Carusi & Jirotka, 2009; Dickson-Swift et al., 2006; Guillemin & Heggen, 2009; Guishard, 2018). Because of how qualitative data are gathered, some researchers are reticent to share data out of concern that doing so could negatively affect their relationships with participants (Campbell et al., 2023; Guishard, 2018; Mozersky, Parsons, et al., 2020; Yardley et al., 2014). These concerns are widespread—in a survey of 425 QRs in the US who gather health-related or sensitive data, we found that only 4% of respondents had ever shared their qualitative data in a repository (Mozersky et al., 2021). Their top concerns regarding qualitative data sharing included the sensitivity of the data (85%) and breach of participant trust (82%) (Mozersky et al., 2021).
Aside from new mandates to share data, some research participants may want—and expect—their qualitative data to be shared (Cummings et al., 2015; Kuula, 2011; VandeVusse et al., 2022). We conducted interviews with 30 research participants who had previously taken part in qualitative health research in which they shared sensitive qualitative health data (Mozersky, Parsons, et al., 2020). Our findings indicated that nearly all participants support data sharing so long as data are de-identified and shared with other researchers (Mozersky, Parsons, et al., 2020). Most participants hoped their data would be shared and several expected or assumed this was already happening (Mozersky, Parsons, et al., 2020).
Project Background
In 2017, our research team at the Bioethics Research Center (BRC) at Washington University School of Medicine in St. Louis (WU) received funding from NIH’s National Human Genome Research Institute (NIH) (R01 HG009351; PI James DuBois). Through the project, we wanted to understand the barriers and facilitators of QDS by engaging stakeholders and helping QRs ethically and responsibly prepare and de-identify their data for deposit. The project was inspired by our anticipation that at any time, existing NIH data-sharing requirements might be enforced regarding qualitative data. We believed QRs in the United States were unprepared for this scenario (National Institutes of Health, 2003). In previous work, we examined data repository guidelines for qualitative data sharing from international repositories that archive qualitative data. We found very few repositories provide qualitative data sharing guidance (Antes et al., 2017). We therefore developed guidelines for ethical and responsible qualitative data sharing in the US regulatory context. We also developed the Qualitative Data Sharing (QuaDS) software to support health science researchers in de-identifying qualitative data (Gupta et al., 2021). Here, we report the development and implementation of our pilot project, which demonstrates that qualitative health science data sharing is feasible and can be done responsibly.
Our project had three aims. In the first, we engaged stakeholders to determine current QDS practices, knowledge of QDS repository options, attitudes toward QDS, and perceived barriers and facilitators of QDS. We accomplished this through in-depth qualitative interviews with 120 stakeholders (Mozersky, Parsons, et al., 2020; Mozersky, Walsh, et al., 2020), and a survey of 425 qualitative health researchers (Mozersky et al., 2021).
In the second aim, we engaged QRs in a pilot project with formative evaluation (DuBois et al., 2023). We worked with 28 QRs who had existing qualitative datasets and assisted them with de-identification and sharing their data with the Inter-university Consortium for Political and Social Research (ICPSR) data repository at the University of Michigan (Figure 1). Qualitative Data Sharing Pilot Project Workflow.
The BRC faculty and staff collaborated with programmers in informatics at WU to develop deidentification software. For QRs recruited to the formative evaluation trial the process involved preparing transcripts for upload to WU, using the QuaDS software to remove identifying information in their transcripts, reviewing and validating the de-identified transcripts, and finally, depositing the de-identified research data at ICPSR using the guidelines we developed. The datasets that were de-identified using the QuaDS software and QDS guidelines are available on a QDS project series page (The Inter-university Consortium for Political and Social Research (ICPSR), 2024b).
In addition to working in the software and sharing de-identified data at ICPSR, QRs completed two short user experience surveys to help us refine our process, guidelines, and software.
In the third aim, we developed and systematically disseminated a QDS Toolkit qdstoolkit.org, containing ethical guidance as well as all materials developed during the project.
In this paper, we aim to share key lessons learned through the pilot project. Through formative evaluation—which came from several sources including participant surveys, research team observations, and data curator feedback—we often adapted procedures throughout our pilot project. Below, we describe project procedures, including data use agreements, data preparation, data de-identification using novel software, and data deposit with a repository. At each juncture, we discuss challenges that arose, how the challenges were identified, and how we responded.
Project Procedures
Recruitment to the Pilot Project
The BRC team recruited QRs to the pilot project through three methods. First, we invited participants who completed our survey of 425 US qualitative researchers about barriers and facilitators to sharing qualitative data to take part in our pilot project (Mozersky et al., 2021). Of those, 134 QRs expressed interest. We sent those QRs an intake survey that asked them to upload a blank copy of the IRB-approved 1 informed consent document or consent script so that we could review what, if any, data sharing language was included in the consent document. Of the 134 QRs who initially indicated they were interested in participating, 40 completed the intake form. We also recruited through our professional contacts and by word-of-mouth through presentations, colleagues, publications, and other QR participants. These other sources of recruitment led to 69 additional completed screening surveys, for a total of 109 intake forms.
Our team reviewed all 109 intake forms and prioritized inviting QRs with datasets that included health-related or sensitive data. We excluded datasets that contained photographs or videos and datasets that did not have transcripts available in English. We sent 74 eligible QRs a recruitment email inviting them to participate in the pilot project and 63 QRs responded that they remained interested. Our process required every interested QR to have an institutional official sign a QDS Software Service and Data Use Agreement, permitting the data deposit. The agreement enabled the QRs from outside institutions to upload their data, including identifiable data, for de-identification by the QuaDS software, prior to being shared with the ICPSR. Identifiable data was only shared with WU for the purpose of de-identifying; however, some QRs had already partially de-identified their data prior to using the software (e.g., removing participant names).
The BRC provided each non-WU QR with a template Service Agreement, guidance on how to identify an appropriate institutional signing official, and the contact information for the WU contract specialist. Only 49 of the interested QRs pursued participation by seeking permission from an institutional official to share their data. Twenty of these QRs did not complete the project or move past the phase of trying to get a Service Agreement signed.
Recruitment Challenges
Slow response times from institutional offices were a major challenge for the project. The effort required to follow up with institutional officials was often frustrating to the QRs. Other times, the QR did not know who the appropriate institutional official was at their institution or experienced delays because of staff turnover. In these cases, the time it took to coordinate communication was so burdensome that 7 QRs did not have time to continue with the project. In the case of 6 QRs, the service agreement was rejected because someone (either the QR, the QR’s institutional official, or the QR’s IRB) determined that the data could not be shared due to the original study’s IRB language. Six QRs who were supposed to be executing their service agreements never responded to our multiple attempts at following up. One QR dropped out of the project at the service agreement stage but did not provide a reason.
We were surprised to learn that some institutions would move forward with data sharing even when consent forms said data would be destroyed (n = 4) or when only the research team members would see the data (n = 7). Per federal regulations (45CFR46), many institutions do not consider de-identified data to be human participant data; thus, they permitted de-identified data to be shared (United States Office of the Federal Registrar, 2009).
Out of the remaining 29 QRs who successfully enrolled by completing a service agreement, 28 went on to complete the project by de-identifying and sharing data. (The QR who did not complete was unable to finish their data de-identification before the project ended).
Consent Forms
Informed Consent Form Statements on Data Sharing (N = 28).
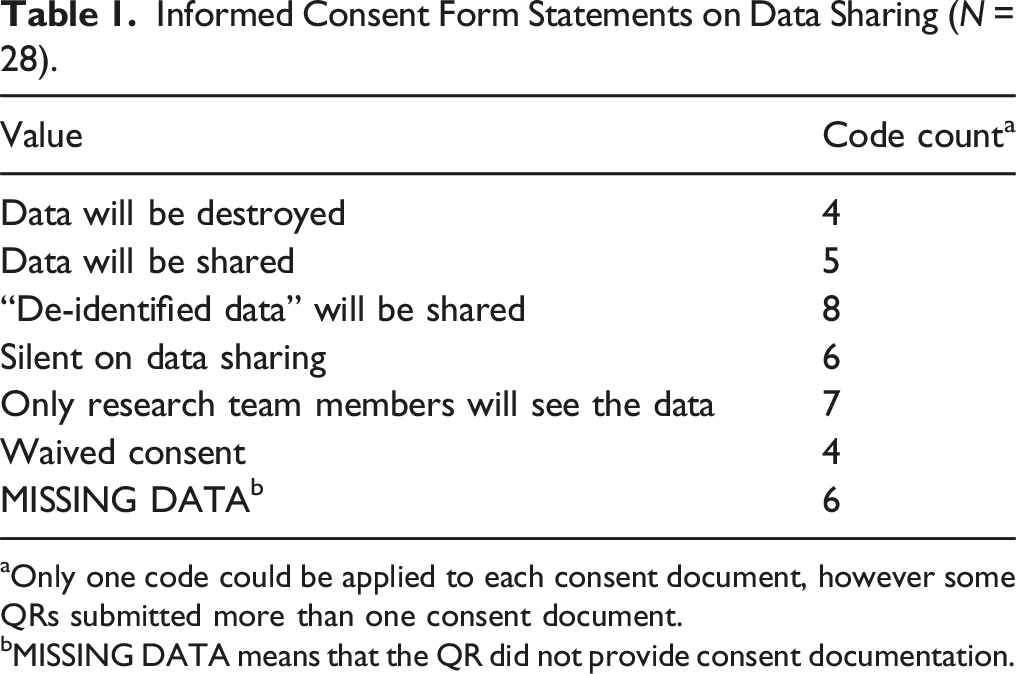
aOnly one code could be applied to each consent document, however some QRs submitted more than one consent document.
bMISSING DATA means that the QR did not provide consent documentation.
Data Preparation
After we received the signed service agreement, participating QRs sent their identifiable dataset to the BRC using WU Box, a secure cloud-based platform, to begin the data de-identification process.
Table S1 in the supplemental files reports the demographics and data set characteristics of the 28 QRs who completed the project. All QRs—and in some cases, their delegates 2 —attended a project orientation call, in which representatives from our team and ICPSR communicated details about participating in the project. During the call, the attendees discussed the QDS project procedures and goals, timeline, the data de-identification and validation process, the deposit process review with ICPSR (e.g., data documentation and formatting, whether an embargo period was necessary, and the appropriate level of access to the data). During the orientation call, QRs relayed any time constraints or requirements to make their data available in the ICPSR by funders or journals. QRs also had the opportunity during the orientation calls to ask questions about participating in the project and about data sharing in general. We provide a summary of questions and concerns that arose during the orientation calls in the Investigator lack of knowledge and unfamiliarity with data sharing section of this paper. After the orientation call, QRs uploaded their identifiable data to a secure WU server.
Data De-Identification
Next, the WU team uploaded the data into the QuaDS software and ran the de-identification pipeline on each QR’s dataset. The QuaDS software automatically highlights both HIPAA safe harbor and non-HIPAA safe harbor identifiers and replaces them with contextual substitutions that may be essential for secondary users (Friedrich et al., 2023). The Health Insurance Portability and Accountability Act (HIPAA) establishes federal standards in the United States for protecting sensitive health information from being disclosed (U.S. Department of Health and Human Services, n.d.). The QRs then reviewed the de-identified files to determine if any identifiers needed to be re-categorized, ignored, or replaced, and if any identifiers were not flagged. Once the QRs reviewed their de-identified files, we asked them to complete the first of two brief user experience surveys and we sent the first participant payment.
User Experience Survey #1: Preparing and De-Identifying Data
User Experience Survey 1: Preparing and De-Identifying Data (N = 28).

Data Deposit
Based on the QR’s prior review and adjudication of the software’s changes, the WU team exported the final de-identified files from the QuaDS software for deposit and sharing at ICPSR. We asked the QRs to review their final de-identified files and approve them. Once the QRs were satisfied with the files, they completed a Restricted-Use Data Deposit and Dissemination Agreement (RUDDDA), and their final de-identified dataset was submitted to ICPSR.
Next, curators at ICPSR went through the de-identified files to ensure that the files were sufficiently de-identified for sharing. The curators' feedback was largely encouraging. “[I am] impressed with how well this tool worked. It was a breeze curating this study!” Another said, “[T]he software seemed to work very well! As a qualitative researcher myself, this type of tool development would be extremely useful for social scientists,” and “[I am] impressed with the extensive de-identification!” The curators also provided some constructive feedback, about the software’s performance, which we report below.
Each dataset from the QDS project was indexed on the ICPSR QDS Project Series page, along with any data-related publications (The Inter-university Consortium for Political and Social Research (ICPSR), 2024b). Principal Investigators with IRB approval, or research personnel approved by the IRB, may request access to the QDS Project Series data for secondary use.
User Experience Survey #2: Overall Satisfaction with the Project
User Experience Survey Data #2: Overall Satisfaction with the Project (N = 28).

Identifying Challenges and Responding to Problems
Responses to Challenges Identified Through Formative Evaluation Processes.

Contracting
In many cases, researchers are able to directly upload research data to repositories. This is commonly the case when data are de-identified and not sensitive. However, in our project we partnered with the ICPSR, which requires the signature of an institutional official when depositing data under restricted access terms.
In User Experience Survey 2, we asked QRs to describe any obstacles they encountered when obtaining a signature on the RUDDDA. QRs cited difficulties identifying the institutional official or coordinating communication with them, creating huge delays in the time it took to complete agreements. Ahead of data sharing, QRs should identify their institutional official and work with them to negotiate and sign data sharing agreements. Institutions vary dramatically in what office is responsible for negotiating and signing data use agreements; however, these typically seem to fall under the purview of such groups as Contracts or the Office of Sponsored Projects. Additional common locations for Data Use Agreement (DUA) review and institutional approval include the Office of General Counsel and Office of Technology Management.
The QDS team observed that contracts were held up when questions were raised about regulatory issues or IRB determinations. A few QRs faced legal and regulatory issues. One QR was required to re-contact their original interview participants to ask permission to share their data. The QR successfully re-contacted 34 of their 39 participants with the goal of re-consenting them to allow sharing. Out of the 34 participants, 19 agreed to data sharing, and 2 requested to review their de-identified transcripts before agreeing. The QR removed the transcripts of the participants who did not agree to share and was able to share the transcripts from the participants who did consent.
If data will be shared under restricted-use, researchers should begin executing data sharing agreements between their institutions and the repository they want to work with before collecting data. These agreements can sometimes take months to negotiate and fully execute with some repositories. Other repositories may have standard agreements that can be more efficiently executed.
Institutions should advertise who is responsible for executing data sharing contracts and communicate any staff changes. Legal and regulatory teams need guidance and training to understand the goals and limitations of qualitative data sharing. Institutions can streamline the process by creating protocols. Repositories could assist by streamlining their process too, and not overly restricting data.
Another problem the QDS team observed is that sometimes consent forms unnecessarily prohibit data sharing. Investigators should include data sharing plans in IRB protocols and in participant consent information. Researchers should check with their IRB to see what template language is recommended for communicating data sharing plans with participants during the informed consent process. By disclosing data sharing plans with participants in consent forms, contract personnel may be less likely to reject data sharing. Consent forms that state de-identified data will be shared are clear, and relay to participants ahead of data collection what will happen with their data. At a minimum, investigators should not include statements in their consent forms that prohibit data sharing by either stating that data will not be shared, accessible only to the research team, or destroyed after a certain time period. IRBs can help assist QRs with consent form language that facilitates qualitative data sharing.
Lastly, a common theme in User Experience Survey 2, was that QRs often find agreement terms in contracts confusing. Repositories can assist by making data security standards clear and easily discoverable on their websites. They can provide answers to FAQs, along with contact information for questions.
De-Identification
We looked at the quality of deidentified text and felt QRs were unnecessarily removing too many identifiers flagged by the software rather than ignoring them. At the other extreme, toward the end of the project one QR ignored nearly all flagged text, leaving in institutional names and other information that we and the ICPSR felt could be identifying. One QR reported in User Experience Survey 2 that they were still unsure what truly qualifies as “de-identified.” These observations led to a revision of the software to include a color-coding scheme and consensus about three kinds of potentially identifying variables (PIVs).
With the color-coding scheme, we created three categories. Variables highlighted in red by the software indicated that the variable is a HIPAA safe harbor identifier and was automatically replaced with a generic replacement such as [NAME 1]. However, QRs could make a new more thoughtful replacement if they wanted. Variables highlighted in yellow were flagged but not replaced by default (e.g., institutions and rare diseases). Yellow variables alerted QRs that they should review the variable and decide if a substitution was needed. Substitutions would have to be manually changed by the QR. Variables highlighted in green indicated to the QR that the variable could likely remain in the data, and no substitutions were automatically made. We added to our guidelines that investigators should remove any identifiers necessary to protect participant privacy and confidentiality but leave enough information to maintain context that secondary users need to understand the original study’s findings. Investigators who are using de-identification support software should not overly rely on the software; the software requires a human to review its work. Removing only HIPAA safe harbor identifiers may not be sufficient for de-identifying qualitative data. Investigators should consider which PIVs are the most identifiable and least relevant to the analysis and remove them.
Some QRs reported that the software’s inability to de-identify transcripts in languages other than English was a drawback. This and other continued improvements to the software, would be an important contribution to future work.
In some cases, it may be impossible for data to be de-identified without cutting important contextual information. Our project team experienced this when preparing data for sharing from our in-depth interviews with stakeholders. In this case, something the participant said pointed to what country they were from, and by way of their stakeholder group, their organization. A quick Google search for the organization name and the participant’s job title, which was known because of their stakeholder group, revealed who the person was. In this case, we shared the transcript with the participant to give them an opportunity to request that anything they deemed potentially damaging or embarrassing be redacted or that the transcript be left out of the data that was shared. In this case, the participant consented to having their full transcript shared.
Technical Issues With the Software
QRs reported two major technical issues with the QuaDS Software. Early on, many QRs encountered issues with their transcripts loading slowly. This mainly occurred when transcripts were in a format in which the software was not used to working. We could not automate uploads because some QRs had data in uncommon formats. It is important to work with a repository ahead of data sharing to understand what formats are best to use. Our team standardized our file format requirements and in so doing, created a streamlined upload process. We also limited the number of QRs working in the software at the same time.
The first two QRs to complete their de-identification in the software participated in quality improvement interviews with two members from the QDS team. Both QRs reported that although the software was easy to use, sometimes it removed words and numbers that were not identifiers (e.g., I will visit there one day). Likewise, ICPSR curators, who sent their feedback to the QDS team after the first three datasets were uploaded to ICPSR, had similar comments. Ages, years, and miles or hours away from a site were masked, but so too were other numbers such as inches of snow, footer page numbers, and participant numbers. To address this limitation, we created the option of replacing a single instance of a word or allowing QRs to replace all, if desired. Additionally, the word “one” is no longer flagged.
Investigator Motivation and Willingness to Share
Participating Researchers’ Stated Motives for Sharing Their Data (N = 28).

Note. Respondents could provide more than 1 answer so percentages exceed 100.
We aimed to recruit 30 people to deposit data using QDS guidelines and de-identification software. We sent 74 eligible QRs a recruitment email inviting them to participate and 63 QRs responded that they remained interested, though only 49 pursued participation by seeking permission from an institutional official to share their data. We offered QRs free curation and a payment of $1,000 to participate. Despite overwhelming interest at the outset of the project (134 QRs initially indicated they were interested), we ultimately struggled to recruit 30 people to complete the pilot project and only 28 QRs completed all project activities. Despite any initial enthusiasm investigators may have for QDS, it seems mandates may be necessary if qualitative data sharing is to become common.
Investigator Lack of Knowledge and Unfamiliarity With Data Sharing
Through our observations and QR responses in User Experience Survey 2, we learned that QRs lack knowledge about the process of sharing qualitative data. Participating QRs had many questions about RUDDDAs, secondary access to shared data, data formatting, de-identification, and what supporting documentation is recommended or required when depositing data. Quite a few QRs commented on the process or time it took to track down all the supporting documentation for depositing data—pointing to the importance of good file management and adhering to project protocols. We added extensive guidance about data management and sharing plans in our toolkit. Our team answered questions during the orientation call and provided each QR with depositing guidelines.
Questions That Arose From Orientation Calls
Several QRs asked us to clarify the difference between the previously-executed QDS Software Data Use and Service Agreement and the RUDDDA that would need to be signed when the QR deposited their data with ICPSR. A RUDDDA allows researchers to share their final restricted-use datasets in a repository for the purpose of archiving and sharing data with secondary users. The RUDDDA covers the transfer, processing, and dissemination of restricted-use data through a repository and would be required in most cases where data is shared outside the QRs institution (Institute for Social Research at the University of Michigan, 2024).
We received several questions about who decides whether a data requestor is allowed to access the data once they are deposited. Our team explained that ICPSR would manage and determine who is granted access. In general, Principal Investigators with IRB approval, or research personnel approved by the IRB, may request access to restricted-use data for secondary use (The Inter-university Consortium for Political and Social Research (ICPSR), 2024a). The team decided qualitative data would be available only by restricted access to ensure privacy and protect confidentiality.
During the orientation call, several QRs wanted to understand how future use or publications created from the data (including their own publications) would be tracked and linked to the dataset. To enhance discoverability, ICPSR generates a citation for each dataset, which secondary users are required to cite in publications arising from the data they use (The Inter-university Consortium for Political and Social Research (ICPSR), 2023). ICPSR’s team maintains a bibliography for each dataset and performs periodic citation searches to ensure that the dataset’s bibliography is up-to-date as long as it is available in ICPSR. Researchers may also want to set a Google Alert for the dataset’s citation to stay informed about how the dataset has been used. Researchers will list any existing publications arising from the dataset upon deposit and can add additional publications as they are published by emailing the ICPSR team (The Inter-university Consortium for Political and Social Research (ICPSR), 2023). Additionally, researchers may include their contact information in the supporting documentation of their dataset if they are open to being contacted by secondary users regarding their data.
We received other questions about disclosing funding sources, data formatting, the use of pseudonyms, and the software’s capability to flag additional identifiers that the software does not find. One QR wanted to know if their data, once shared with the QDS project series, could be cross-referenced with ICPSR’s special collection for disability research, which our team confirmed was possible. Aside from other project-specific questions (e.g., who could help with the de-identification and validation tasks, and inquiries related to project payments), QRs wanted to know where accompanying quantitative data should be deposited. These data were deposited and curated alongside the qualitative data.
Helpful Resources and Services From the Project
When asked what were the most helpful resources or services, QRs reported that the guidelines, orientation call, and continued communication with and support from the QDS team at WU and at ICPSR were integral. This strongly suggests that repositories should be prepared to help researchers with concerns specific to qualitative data with clear guidance. QRs need to understand how the de-identification process for qualitative data differs from de-identifying quantitative data. QRs should seek help from available resources and contact the repository where they plan to share data for additional guidance.
QRs also reported that the ICPSR site for uploading data was difficult to understand at times. Some found that after submitting de-identified data, the next steps were unclear. Repositories should ensure that their deposit dashboard is user-friendly and contains metadata tags specific to qualitative methods. QRs reported that in-person or video guidance from repositories would be helpful.
For future investigators, our team developed the QDS Toolkit (qdstoolkit.org), which provides a map of the key steps and considerations for study planning, data collection and management, and depositing research data in a data repository.
Conclusions
Researchers have expressed many concerns with data sharing (DuBois et al., 2018; Mozersky et al., 2021; Mozersky, Walsh, et al., 2020). In a separate perspective article, we observe several ongoing challenges in the world of qualitative research: Few qualitative research methods textbooks provide instruction on data sharing; few journals offer clear guidelines on what to share or how to share responsibly; institutions lack policies on qualitative data sharing, and provide little oversight as researchers share data—particularly with open access repositories (DuBois et al., 2023). Additionally, our project did not attempt to share some of the more challenging forms of qualitative research data, including video recordings (which contain obvious identifiers) or researchers’ field notes (which are often personal).
Nevertheless, through this project, we found that qualitative data sharing is feasible. Not all data can be shared, but many data can be shared responsibly. Almost all of the QRs reported that they were willing to share data again.
Through the feedback we received from participants and our own observations, we improved our software, improved our processes, and developed a QDS toolkit with guidance. Through the project, we learned that even with de-identification software, researchers need guidance on de-identification or else they uncritically accept too many changes to their data. We advise QRs to remove as much information as necessary to protect participant confidentiality but as little as possible so that secondary users have important context. While resources such as guidelines and software are clearly helpful, we found that QRs benefitted greatly from having a contact person who could answer questions and help them troubleshoot. As qualitative data sharing becomes more common, QRs will need access to people with knowledge and experience navigating ethical, regulatory, and logistical challenges of sharing data that are so unlike the quantitative data repositories normally handle.
While many of the resources we developed will be helpful outside of the US context, some will need to be adapted—e.g., guidance on what counts as de-identified data, on whether de-identified data continue to be regarded as human participant data, and whether specific consent is needed to share data. The QuaDS software currently helps to de-identify only English-language transcripts, but the logic behind the software might offer researchers suggestions on de-identification strategies, particularly on how to balance de-identification with preservation of essential contextual information (Gupta et al., 2021).
As with any new, complex endeavor in research, we will make mistakes. It will be important for researchers to share both what went well and what did not go well as they share qualitative research data, which are often sensitive, challenging to de-identify, and an awkward fit for repositories that were established primarily to handle quantitative data.
Supplemental Material
Supplemental Material - Responsible Sharing of Qualitative Research Data: Insights From a Pioneering Project in the United States
Supplemental Material for Responsible Sharing of Qualitative Research Data: Insights From a Pioneering Project in the United States by Heidi A. Walsh, Meredith V. Parsons, Jessica Mozersky, Aditi Gupta, Albert M. Lai, Annie B. Friedrich, and James M. DuBois in International Journal of Qualitative Methods
Footnotes
Acknowledgments
Thank you to Jen Strosahl, Ian Lackey, Ruby Varghese, and Cami Keahi for their work on the QDS project.
Statements and Declarations
Consent to Participate
The requirement for informed consent to participate was waived by the Institutional Review Board.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by NIH’s National Human Genome Research Institute and the NIH Office of Behavioral and Social Science Research (R01HG009351; PI James DuBois).
Conflicting Interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: J. M., A.G., A.L. & J.M.D. are part of a team of developers of the QuaDS software, which is owned by Washington University, and has been licensed to SocioCultural Research Consultants for commercialization. These authors could receive a percentage of Washington University's royalties from this licensing. All work described in this grant was supported by the NIH.
Data Availability Statement
The data are not available due to their containing information that could identify and compromise the privacy of participants.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.