
Abstract
This study contributes to the domain of explainable AI (XAI) by examining how uncertainty in an AI agent’s diagnosis affects human decision-making in high-stakes, time-critical environments. We conducted a randomized controlled experiment in which participants diagnosed simulated spacecraft anomalies with the help of an AI agent named Daphne. Each participant completed two sessions with different levels of explainability: one in which Daphne provided Basic explanations (qualitative likelihood scores) and another in which it offered Advanced explanations (quantitative likelihood scores with detailed justifications). Each session included a balanced set of scenarios featuring high and low diagnostic uncertainty. We evaluated the participants’ task performance, trust in the AI agent, reliance on its recommendations, satisfaction, and self-reported confidence. Across all measures, the participants’ performance declined significantly under high uncertainty conditions. However, Advanced explanations were particularly effective in improving performance when uncertainty was high, suggesting that explanation depth plays a key role in mitigating the negative effects uncertainty. These results highlight the importance of transparency in AI systems designed for decision-making. Our findings offer practical insights into the design of XAI tools that can better support human operators, especially in safety-critical domains like spaceflight, where managing uncertainty is a key challenge in effective human-AI collaboration.
Keywords
Introduction
Artificial Intelligence (AI) has been defined as an abstract computing machine that can mimic human decision-making capabilities (Turing, 2009). Today, AI has been deployed to help humans make decisions in a number of critical real-world problems, such as providing personalized recommendations, detecting the spread of false information, autonomous vehicles, and even on the International Space Station (Amazon’s Alexa voice assistant is due to ride on NASA’s moon ship, 2022; CIMON: astronaut assistance system, n.d; Rayner et al., 2010). While AI can offer highly personalized services and content, the effectiveness of AI systems is limited by their current inability to explain their decisions to users (Shin, 2021). AI agents have the capability to improve operator performance, but the potential gain in performance is sometimes not fully realized due to miscalibrated trust and lack of reliance on the AI agent. Agent transparency, or the degree to which the inner decision-making processes of an AI system are visible and understandable to humans, has been seen to increase trust in the AI agent. However, the effect of agent transparency on task performance and trust under uncertainty in the agent’s recommendations is not well understood particularly for time-critical tasks. In order to overcome the black box problem of AI agents, various types of Explainable AI (XAI) methods, techniques in AI that aim to make the decisions of AI systems understandable to humans, have been developed to enable operators to understand the underlying models and their assumptions (Adadi & Berrada, 2018; Goldstein et al., 2013). However, factors that can influence the effectiveness of these explanations, such as the uncertainty in the agent’s recommendations and how that uncertainty is communicated to the user (e.g., agent confidence), are largely overlooked in literature (Alipour et al., 2020; Buçinca et al., 2020; Kenny et al., 2021; Schmidt & Biessmann, 2019; Zhang et al., 2020). The rapid development of XAI raises a few key questions—Does the user’s task performance, reliance, confidence, and trust in the AI agent’s explanation depend on the agent recommendation’s uncertainty level? How effective are the explanations under uncertainty? Do explanations improve user’s satisfaction and understanding of the task under uncertainty? To answer these questions, we start by reviewing the existing literature in trust, uncertainty, and XAI methods and summarize the desirable properties of effective explanations for an ideal AI agent in a human-AI collaborative decision-making task. These properties are stated mainly from the perspective of a human decision-maker who is assisted by an AI agent and are certainly not comprehensive. However, they provide an initial set of concrete standards upon which we can compare the strengths and weaknesses of different XAI aids. Then, we present a human-subject experiment which tests how the AI agent’s explanations affect these properties in a spacecraft anomaly diagnosis task under different levels of uncertainty. Our findings have important implications on designing and selecting effective XAI techniques for future AI agents, particularly to support astronauts during long-duration exploration missions (LDEM).
Literature Review
Trust and Uncertainty
The concept of trust has been studied in the context of human social interaction for years (Estelami & de Maeyer, 2002; Mayer et al., 1995; Rousseau et al., 1998). But since then, it has been found useful in the domain of human-computer interaction as well (Jian et al., 2000; Kunze et al., 2019; Lewis et al., 2018). In both contexts, trust is defined as “the attitude that an agent will help achieve an individual’s goals in a situation characterized by uncertainty” (J. D. Lee & See, 2004), which highlights the critical role of uncertainty in trust. For users to comply with decisions made by an AI agent, or in order to accept an AI agent’s recommendations, they first need to be able to trust it. Research in social science and computer science shows that reduction in uncertainty is fundamental to the development of trust in both, inter-human and human-computer relationships (Jian et al., 2000). Uncertainty arises when operators lack sufficient predictive or explanatory knowledge about their interaction partner to predict positive outcomes (Berger & Calabrese, 1975). Most interactions, whether human-human or human-computer, involve uncertainty since having perfect knowledge about each other is impossible. This uncertainty is especially substantial in the first few initial interactions between 2 partners, since the interaction pairs know little to nothing about each other and therefore cannot accurately predict each other’s behaviors (Berger & Calabrese, 1975; Liu, 2021). Given how complex and opaque AI systems can be, human-AI interactions can also involve high uncertainty. According to Uncertainty Reduction Theory, or Initial Interaction Theory, people tend to reduce uncertainty in the interactions by collecting more information about the interactions that can enable them to predict behaviors to achieve their final outcomes through communication (Berger & Calabrese, 1975; Clatterbuck, 1979). This motivation to collect more information in order to reduce uncertainty is inherent in humans and guides them to become more competent against their environment (White, 1959). As such, in human-AI interaction, since the decisions made by the agent can influence the user and the outcome of the interaction, the user will be expected to be motivated to reduce the uncertainty about the decision-making AI agent.
In human-AI interaction, uncertainty builds up either on human side, resulting from a lack of knowledge about the AI’s workings, or on AI’s side, due to the inability of the system to explain its decisions to the user. The effects of uncertainty in such interactions can be partially resolved if we can make the AI’s reasoning transparent to the users. Uncertainty reduction is crucial for developing trust in human-AI interactions. Research has found that explanatory knowledge about the AI agent or the interaction can increase the trust of the user (Jian et al., 2000). This is true even if the AI system has made errors. The user will still be more likely to trust the agent if the agent provides a logical explanation as to why the error might have occurred (Dzindolet et al., 2003). Understanding and being able to predict an AI agent’s decisions can reduce the uncertainty and improve user’s trust in the AI agent.
Transparency as a Remedy for the Effects of Uncertainty
Lack of transparency is often cited as a major reason to cause a user to doubt an AI agent’s decisions (Hoffman et al., 2018; M. K. Lee, 2018; Roloff et al., 1987). The users may often lack the knowledge about the AI’s decision-making process, making it difficult for them to understand and explain why the AI made a certain recommendation (Roloff et al., 1987). Previous research in the area of XAI suggests that to alleviate the effects of uncertainty on user’s trust, AI systems must be designed such that they can explain their decisions to the users (Haque et al., 2023; Laato et al., 2021; Tiainen, 2021). Some research has also found that enhancing AI transparency can improve not only trust but also user satisfaction (Shin, 2021). There is recently a growing line of literature on evaluating the effectiveness of XAI methods (Carton et al., 2020; Cheng et al., 2019; Lai et al., 2020; Yang et al., 2020; Zhang et al., 2020). Yet the principles required for an explanation to be perceived as helpful by a user in AI-assisted decision-making, arguably still remain to be precisely articulated and comprehensively assessed. It is also unclear to what extent the transparency of an AI’s decisions will enhance user’s overall performance and how much impact the uncertainty in the agent’s recommendations has on the effectiveness of the explanations.
Guidelines for Effective XAI
Previous studies in XAI have explored various techniques for communicating uncertainty in an AI agent’s decisions (Jiang et al., 2022; Lim & Dey, 2011; Lim et al., 2009). More recently, growing interest in AI system transparency has driven the development of methods aimed at explaining not only the AI’s decisions but also the reasoning behind them (Adadi & Berrada, 2018; Chiaburu et al., 2024; Doshi-Velez & Kim, 2018; Du et al., 2018). However, despite the rapid advancement in XAI methods, our understanding of what makes an AI explanation effective remains limited. Research indicates that the effectiveness of an AI agent’s explanations should be evaluated based on user behavior, specifically, whether explanations enhance the user’s ability to perform the task at hand (Doshi-Velez & Kim, 2017; Poursabzi-Sangdeh et al., 2021). For this literature review, we focused on tasks where users are expected to rely on AI agents for decision-making, or human-in-the-loop tasks, with applicability across various decision-making contexts. Based on the reviewed literature, key guidelines for effective AI explanations can be summarized as follows: 1. Trust calibration: Explanations of an AI should help the operators trust the AI appropriately. 2. Appropriate reliance: Explanations of an AI should help the operators recognize the underlying uncertainty in decisions and nudge them to rely on the AI agent appropriately. 3. Improve user confidence: Explanations of an AI should improve the operators confidence in their decisions. 4. Enhances understanding: Explanations of an AI should improve people’s ability to interpret and make sense of the system’s reasoning (interpretability). 5. Enhances satisfaction: Explanations of an AI should provide value (usability) to the operators in their decision-making process and improve their overall satisfaction with the interaction.
Guideline 1 is the goal of any human-AI collaborative decision-making process—to enable effective trust calibration between human and AI partners for improving the performance of the team (Bansal et al., 2021; Buçinca et al., 2020). Using explanations to help the operators trust the AI agent when it is correct and distrust the AI when it is incorrect in the decision-making process is a crucial step towards this goal. With explanations, the operators are better equipped to calibrate their trust in the AI agent as and when necessary (Yang et al., 2020; Yin et al., 2019; Zhang et al., 2020). Note that if an explanation increases operators trust in the AI agent, that does not mean that this guideline is followed, since they could trust an AI agent inappropriately and achieve a low task performance by blindly trusting a high performing AI agent’s incorrect recommendation or by trusting it more than their own judgments. This is why it is crucial that explanations should also fulfill Guidelines 2 and 3. Guideline 2 is simple—the explanations should help the operator appropriately rely on the AI agent. The operator should rely on the agent in situations where the AI agent has high confidence in its decisions. If there is uncertainty in the agent’s decisions, the explanations should make it transparent and allow the operators to also rely on their own judgment and weigh both appropriately to make the decision. Guideline 3 makes sure that the operator has confidence in their own decisions, particularly when agent confidence is low. Just as the agent can be wrong, the operator can also be wrong. This makes sure that the relative accuracy of the agent versus the operator changes depending on the specific task context. In situations when agent confidence is low, under uncertainty, the operators should rely more heavily on their own decisions and reject the decisions of the AI agent if it is likely to be inaccurate. Guidelines 2 and 3 ensure that the uncertainty in an AI agent’s predictions is appropriately communicated to the users (Zhang et al., 2020). Ideal explanations will inform people when the agent is confident in its decisions and will provide insights into when it is uncertain, thereby allowing the operators to act on the decisions differently. The explanations should provide cues to the operators to infer the model’s accuracy and uncertainty in each interaction and adjust their reliance and confidence in their own judgments for each interaction accordingly. Guidelines 4 and 5 have to do with transparency providing an overall explanatory value to the user in such a way that it improves the operators’ understanding of the task as well as their satisfaction with the explanations provided to them by the AI agent. Researchers have proposed various methods to assess people’s understanding of an AI model (Binns et al., 2018; Cheng et al., 2019; Goldstein et al., 2013; Hohman et al., 2019; Miller, 2019; Poursabzi-Sangdeh et al., 2021; Ribeiro et al., 2016). While an explanation by the agent might be deemed good a priori from the designer’s perspective, it may not be useful or satisfying to operators who use the AI agent’s explanations in the decision-making process (Doshi-Velez & Kim, 2017; Poursabzi-Sangdeh et al., 2021). Guidelines 4 and 5 ensure that the operators sufficiently understand the process being explained to them by the AI agent.
A growing number of studies have recently investigated whether and how explanations provided by the AI agent can be useful to the operators in the process of making decisions. Few studies were found that fully investigate Guideline 1 (Lai et al., 2020; Yang et al., 2020), not sufficiently looking into the operators’ ability to calibrate their reliance in the AI model as in Guideline 2, or vice versa (Cau et al., 2023; Lammert et al., 2024). A few studies investigated various types of explanations enhancing user’s understanding, but not fully looking into the satisfaction aspect from the user’s perspective (Cheng-Hsing et al., 2020). Note that the effect of explanations in AI-assisted decision-making may also be moderated by the properties of the decision-making task itself and with respect to the user. For example, time criticality may affect people’s perception of the usefulness of explanations. And people with different backgrounds and levels of expertise in the decision-making task may perceive explanations as more or less useful (e.g., novices may not fully understand them). All these factors can affect how operators utilize the explanations to infer the uncertainty and correctness of the AI agent, and eventually influence the effectiveness of AI explanations. Similarly, not many studies in literature investigated how agent uncertainty in human-agent teams can impact operator confidence, ultimately impacting their trust and reliance in the agent.
Summary of Research Gaps
Effectively communicating an AI agent’s uncertainty—or its lack of confidence—is essential for both non-expert end-users and XAI practitioners. For novice end-users, explanations that omit uncertainty can lead to undesirable consequences. They may foster overconfidence and encourage overreliance on the system (leading to misuse), or, alternatively, evoke mistrust and lead to disengagement or disuse. Explanations presented with unwarranted certainty—despite being clearly formulated—can misrepresent the true capabilities and limitations of the model. Users may blindly accept such explanations, especially when they align with their preexisting beliefs, or may dismiss them altogether if the logic appears flawed or inconsistent with observable reality. In contrast, explanations that clearly convey uncertainty can enable users to make better-informed decisions by exposing the boundaries of the AI’s reasoning. For XAI researchers and developers, incorporating and quantifying explanation uncertainty is equally critical. It provides insights into potential flaws in the AI’s decision-making and supports efforts to improve system robustness and reliability.
In our review of existing literature on explanation evaluation in XAI systems, we identified several significant research gaps that inform the direction of our work. First, there is limited research investigating the impact of uncertainty on users’ trust and reliance on AI systems. Most prior studies have focused predominantly on user confidence (Cau et al., 2023), often evaluated through simplified proxy tasks (Alipour et al., 2020), rather than through collaborative decision-making in complex, uncertain environments. Second, there is a lack of comprehensive studies examining how uncertainty and levels of explainability jointly affect decision-making. Our study seeks to address this gap by analyzing how these factors influence both task performance and user reliance on AI recommendations. While some prior research touches on these dimensions, it is often constrained either by a narrow set of metrics or by task limitations, such as focusing on image or text classification tasks.
Since uncertainty in explanations is often closely tied to a system’s predictive confidence, evaluating this uncertainty is a necessary step toward determining whether XAI systems meet key interpretability and usability guidelines we discussed before.
Current Study
Our study is motivated by the research gaps described in the previous section, where some of the guidelines have not been studied in literature while the ones that have been studied had mixed results. We set out to conduct a study to gain understanding of whether and to what extent uncertainty in the agent’s explanations impacts human performance and if explanations can bring about desirable human behavior in AI-assisted decision-making. Hence, the research questions pertaining to this study are as follows: • RQ1: How does uncertainty impact the operator’s task performance, trust (Guideline 1), confidence (Guideline 3), satisfaction (Guideline 5), and reliance (Guideline 2)? • RQ2: Does explainability influence operator’s capability to understand an AI agent’s predictions under uncertainty (Guideline 4)?
To answer these research questions, we set up a controlled human experiment in our lab. In this study, we investigate the impact of providing different levels of explainability (Basic with only qualitative explanations and Advanced with quantitative explanations) to the user about an AI agent’s recommendations in an ECLSS (Environment Control and Life Support System) anomaly diagnosis task. We carefully designed various anomaly scenarios so they would lead to different levels of accuracy and uncertainty in the agent’s recommendations. Anomaly accuracy is characterized by whether the agent provides a correct diagnosis to the user and anomaly uncertainty is the degree of uncertainty in the agent’s diagnosis given the current anomaly signature and the known or possible signatures, which is related to agent confidence, that is, how confident the diagnosis provided by the agent is. In this study, we use Daphne—an AI agent developed by our team and currently being tested at NASA’s Human Exploration Research Analog (HERA) facility (HERA Research by Campaign, NASA, n.d)—as a representative AI agent for anomaly diagnosis in the context of spacecraft ECLSS (Dutta et al., 2020). Prior work has demonstrated that AI agents like Daphne can effectively support ECLSS anomaly resolution tasks (Josan et al., 2025). For this study, we implemented two distinct versions of Daphne—one that provides Basic explanations for its recommended diagnosis (qualitative likelihood scores for the most likely root causes of the anomalies) and a second one that provides Advanced explanations (knowledge-driven explanations based on expert knowledge and data-driven explanations based on a database of past anomalies). We tested these two versions of the agent within the context of diagnosing 16 time-critical ECLSS anomalies. In this paper, we study the role of agent uncertainty and transparency of diagnosis (through explanations) on user’s task performance, satisfaction, trust, confidence, and reliance. Drawing on our literature review and the research gaps identified in the preceding sections, we propose the following primary hypotheses: • H1: Uncertainty will have a significant effect on (a) task performance, (b) trust, (c) satisfaction, (d) user confidence, and (e) reliance. Specifically, low uncertainty in AI agent’s recommendations will result in higher levels of task performance, satisfaction, trust, user confidence, and reliance compared to those with high uncertainty. • H2: In high uncertainty conditions, the presence of AI-generated explanations will lead to significantly greater improvements in (a) task performance, (b) satisfaction, (c) trust, (d) user confidence, and (e) reliance, compared to explanations provided under low uncertainty conditions.
The subsequent sections describe the AI agent we used, our experiment design and protocol, the participants, measures we collected, and the results of our hypotheses testing. This is followed by a discussion of our major findings, the limitations and future research possibilities, and the theoretical and practical implications of our work. We end with conclusions.
Methods
Experimental Design
A visual representation of our experimental design is depicted in Figure 1. Participants were randomly assigned to one of three agent accuracy conditions: (1) low accuracy (50%), (2) medium accuracy (75%), or (3) high accuracy (100%). Each participant completed 16 anomaly diagnosis tasks across two sessions—one with Basic explanations from the AI agent and one with Advanced explanations. Details about the explanations presented to the participants in these two sessions are presented in the following sections. Each session included eight anomaly scenarios: four high uncertainty cases, where the AI agent identified multiple root causes with equal likelihood scores and expressed low confidence in its recommendations, and four low uncertainty cases, where the AI agent expressed high confidence in one unequivocal root cause. The order of the explanation sessions and the anomaly scenarios within each session were randomized. Experimental design.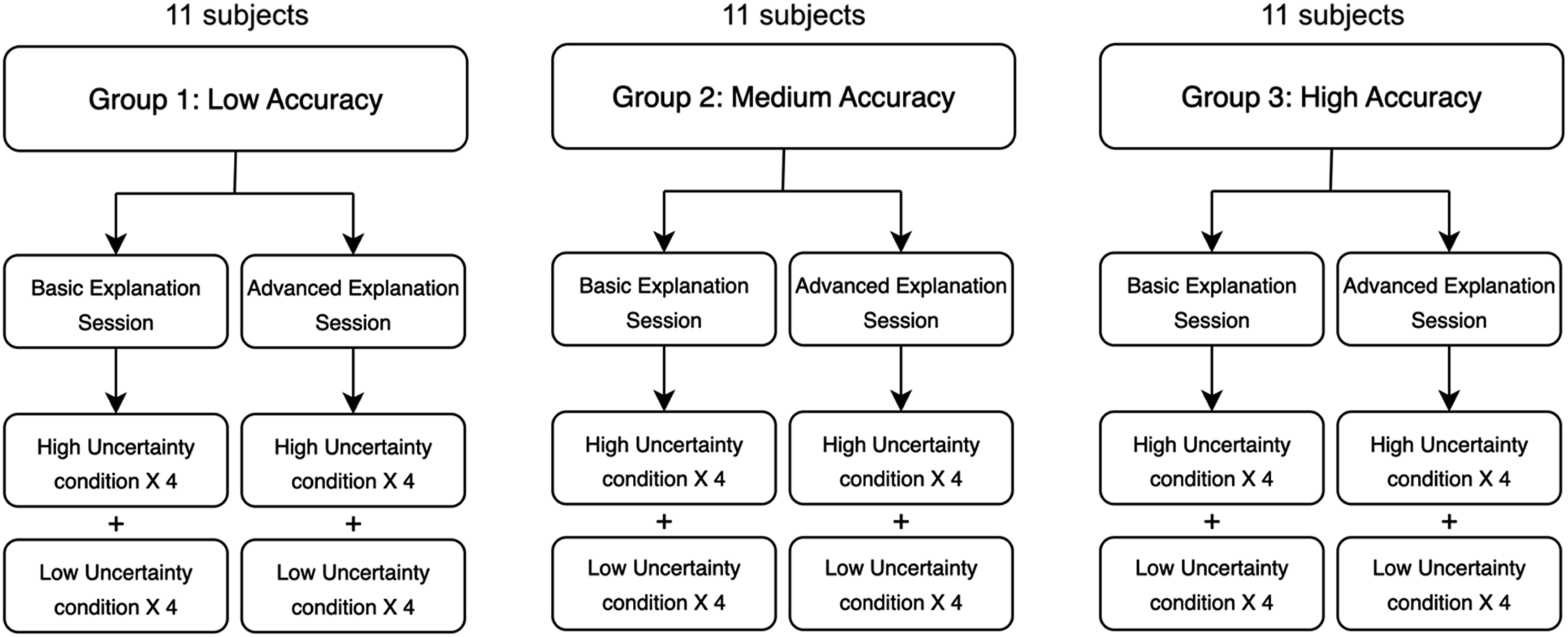
Although agent accuracy manipulation was a component of the experimental design, a comprehensive analysis and interpretation of its effects are presented in prior work (Dutta et al., 2024), so that analysis is not presented here to avoid redundancy. The current analysis focuses specifically on the impact of uncertainty on task performance, trust, satisfaction, user confidence, and reliance, using trial-level (per-anomaly) data across all 3 groups. We also look at the potential of explanation as a countermeasure to mitigate the negative effects of uncertainty. This work enables a more detailed examination of how uncertainty and explanations influence user understanding and decision-making during time-critical scenarios, which merits focused investigation.
Subject Criteria and Controls
An a priori power analysis was conducted using G*Power ((Faul et al., 2007) to determine the required sample size for detecting a statistically significant difference between two related means using a paired-samples t-test. Based on a medium effect size (d = 0.50 (Cohen, 1988, 2013)), an alpha level of 0.05, and a desired power of 0.80, the analysis indicated that a minimum of 33 participants would be required. Therefore, thirty-three participants (19M and 14F, 29.4 ± 9.7 years) were recruited for this study through a university-wide email. The eligibility criteria required that the participants be 18 years or older, have working knowledge of English language, be comfortable in using standard computer and mouse, and have at least a college degree in a STEM field. Those participants who had prior professional experience following procedures as well as working in an operational environment were preferred as they would likely be more similar to astronauts. The participant pool included 5 people with a PhD degree, 8 people with a Master’s degree, and 17 people with a Bachelor’s degree in either Physical Sciences, Engineering, or Mathematics. Most of the participants had some previous or current professional experience. Examples include teaching a course at the university level, working as a software, chemical, structural, petroleum, or supply chain engineer, in the medical field as a phlebotomist, US military, private pilot, and certified SCUBA instructor. None of the participants had any previous knowledge of or experience working with Daphne.
Experimental Materials
AI Agent: Daphne
In this section, we briefly describe the AI agent used in this study, Daphne. A more detailed description of Daphne’s architecture can be found in our previous works (Dutta et al., 2020). Daphne is an on-board intelligent agent developed to support crewmembers in treating anomalies that may occur in the ECLSS of the spacecraft. Daphne has 3 “skills”: Detection (real-time monitoring and analysis of telemetry data), Diagnosis (identifying the root cause of the anomaly), and Recommendation (providing a procedure for resolution of the root cause). Daphne has 3 major components to serve these skills: • Graphical User Interface (GUI): a web-based front-end that consists of the Anomaly Detection Window, the Sensor Data Window, the Anomaly Diagnosis Window, the Anomaly Response Window, and a Chat interface, as shown in Figure 2. • Question Answering System: a chatbox that answers natural language questions from the user. Developed before the advent of large language models, it uses a Convolutional Neural Network (CNN) system that classifies the input request from the GUI as being relevant to one of the three skills mentioned above and responds to each question type using a pre-defined answer template associated with it, such that the agent inserts the result from the query in that answer and returns it to the user. The chatbox is intended to help users quickly access specific parameter or procedural or anomaly details without having to manually navigate the GUI. • Data Sources: there are 3 types of data sources that support Daphne’s skills mentioned above: (1) a real-time telemetry feed from the Habitat System Simulator (HSS) developed at NASA Johnson Space Center. The HSS is a software tool that simulates the values of various ECLSS parameters inside the habitat. These parameters and their lower and upper thresholds can be setup manually by the experimenter to simulate off-nominal, or anomalous, conditions within the habitat. The resulting rising and falling of off-nominal measurements can be plotted by the user on Daphne in the Sensor Data Window. (2) A graphical database, knowledge graph, containing domain-specific information about commonly occurring and known ECLSS anomalies along with their signatures, recommended procedures, necessary equipment, risks, etc. (3) A historical anomaly database that contains information about anomalies that were previously encountered in ECLSS systems, along with their root cause, start and end dates and times, their signature, and the procedures that were used to resolve them. Daphne’s front-end displays all the windows related to the anomaly resolution process. A countdown timer at the top indicates how much time the participant has remaining to diagnose and address the anomaly.
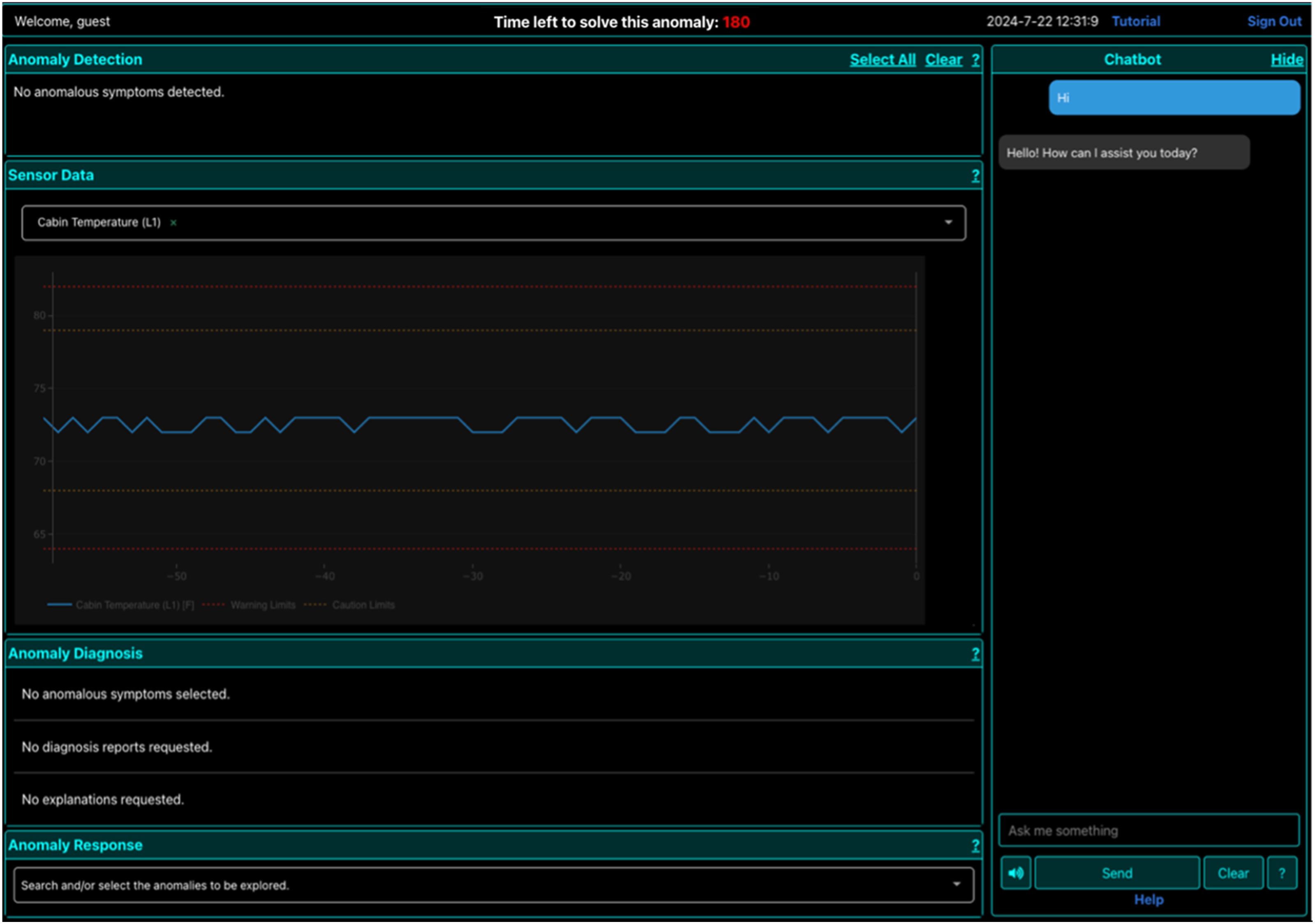
Daphne also has a web application that essentially mirrors the Daphne screens of any logged in users and thus allows the experimenter to monitor the participant’s interactions with Daphne in real time. This GUI also allows the experimenter to evaluate the participant’s performance without interrupting or communicating with them. This interface enables the experimenters to simulate the high levels of autonomy required of LDEM conditions, whether this is done in a research analog facility or in a university lab.
Daphne AI’s Explanations
Daphne was implemented in two versions, differing in the type of explanations provided to support diagnostic decision-making. The first, a baseline version, offered only Basic explanations—providing qualitative likelihood scores for each diagnosis, as illustrated in Figure 6. The second version featured Advanced explanations, incorporating two types of enhanced, or enriched, explanations: (1) Knowledge-driven and (2) Data-driven. This enhanced version offered participants additional context and insights about Daphne’s reasoning and decision-making process.
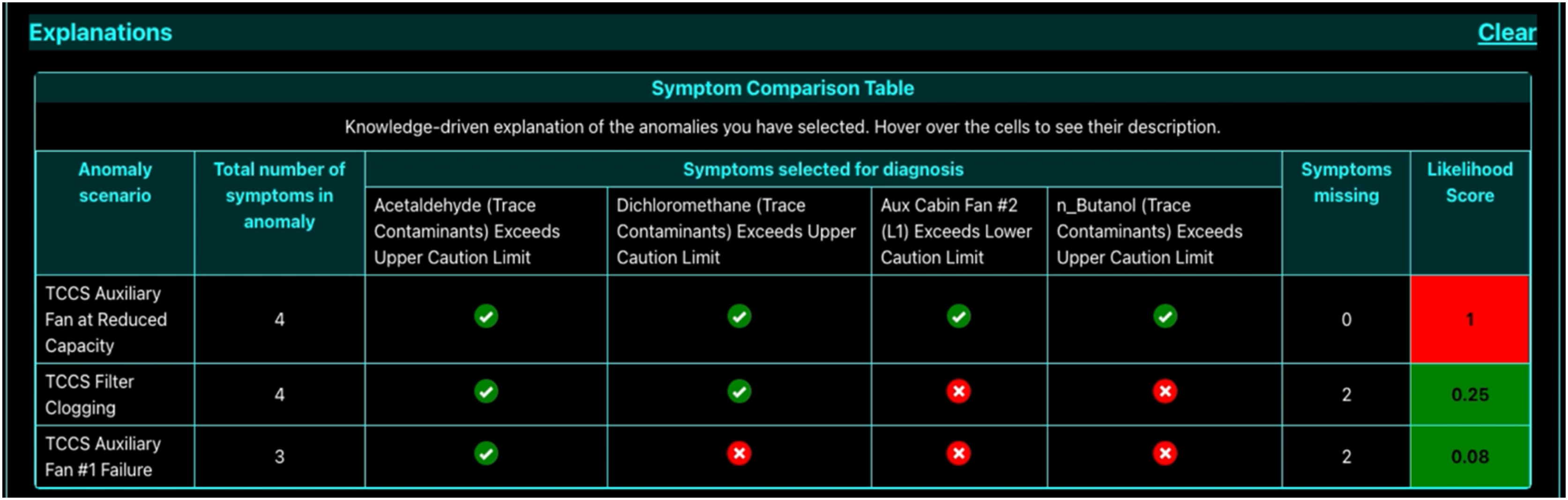
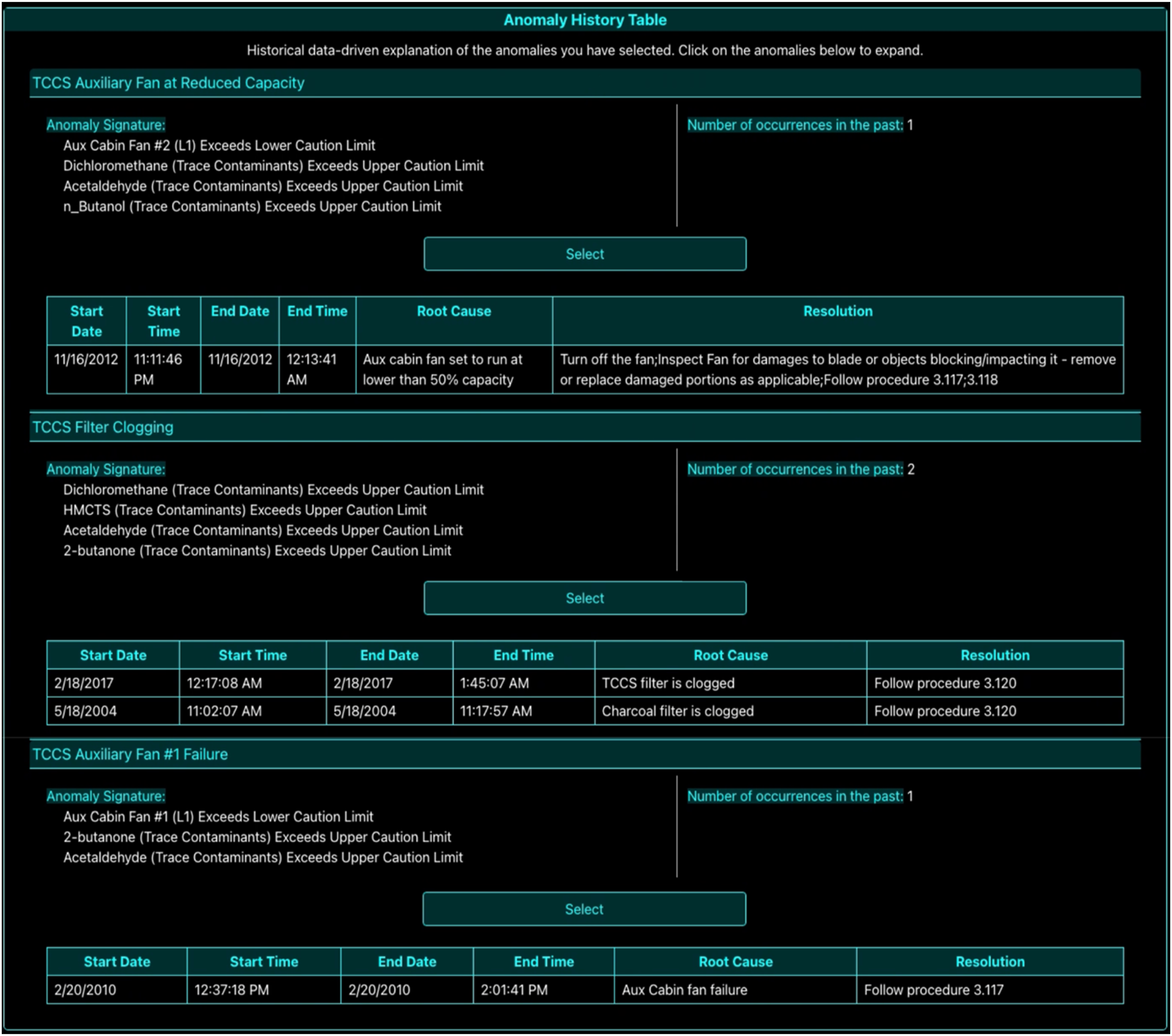
Knowledge-driven explanations were based on information embedded in Daphne’s knowledge graph, which included characteristic patterns (or “signatures”) of commonly known anomaly scenarios. This was the information provided by domain experts—hence the term knowledge-driven. These explanations were presented to the participant in the form of a Symptom Comparison Table as shown in Figure 7. When an anomaly was detected, Daphne compared the observed measurement thresholds against the Caution and Warning thresholds stored in the knowledge graph. It then calculated a likelihood score indicating the probability of a specific anomaly being present. The method for computing this score is detailed in a prior study (Dutta et al., 2022). If multiple anomalies yield the same likelihood score, this was what we call a high uncertainty scenario; in this case, Daphne cannot confidently identify the root cause and labeled the diagnosis as low confidence. However, when one anomaly stood out with the highest likelihood score, this was a low uncertainty scenario and Daphne considered this a high-confidence diagnosis. Data-driven explanations, on the other hand, are derived from a synthetic historical database containing records of previously observed anomalies. This Historical Anomaly Database included details such as the number of times each anomaly had occurred, their start and end times, root causes, and the resolution steps taken. An example of this explanation format is shown in Figure 8.
Since the study did not aim to compare the effects of knowledge-driven versus data-driven explanations, both types were aligned and consistent in how they supported the diagnosis process.
Anomaly Scenarios
Several anomaly scenarios were developed within the HSS environment in collaboration with the HERA team (HERA Research by Campaign, NASA, n.d) for use in this experiment. These scenarios varied systematically in both diagnostic uncertainty and accuracy. Uncertainty was manipulated by designing cases where Daphne could not determine a single clear root cause. In high uncertainty conditions, multiple anomalies produced identical likelihood scores, prompting Daphne to deliver a low-confidence diagnosis, which was communicated via the chat interface. Accordingly, the two levels of uncertainty were as follows: (1) High uncertainty – Daphne identified multiple possible root causes with equal likelihood, and (2) Low uncertainty – One root cause was clearly more likely than the others. Diagnostic accuracy was determined by whether Daphne’s top-ranked root cause matched the actual anomaly. Inaccurate diagnoses occurred when the correct anomaly had a different signature than what Daphne expected, resulting in an incorrect top-ranked suggestion. Combining these two factors yielded four experimental conditions: 1. High accuracy, low uncertainty 2. Low accuracy, low uncertainty 3. High accuracy, high uncertainty 4. Low accuracy, high uncertainty
Examples of each condition are illustrated in Figure 3. For instance, if Anomaly A is the actual issue in the ECLSS, a high uncertainty, inaccurate scenario would involve Daphne presenting multiple incorrect top-ranked candidates (e.g., Anomalies X and Y) with equal likelihoods (Figure 3(b)). In such cases, participants were expected to rely on their training and data provided by Daphne to determine the correct root cause. The order of these anomaly conditions was randomized for each participant. Each session—Basic or Advanced explanations—included an equal number of high and low uncertainty scenarios (four of each per session per participant). Anomaly scenarios with varying degrees of accuracy and uncertainty where Anomaly A has been introduced in ECLSS system and is the correct answer for diagnosis. The anomaly scenarios shown in the figures are provided as examples. In practice, the likelihood scores can range from “Very Likely” to “Least Likely,” depending on the specific anomaly scenario being simulated and the symptoms selected by the participant during diagnosis.
Experiment Protocol
The study was conducted remotely via Zoom and took approximately 2 h per participant. Participants were provided with a 10-page ECLSS manual 1 day prior to the experiment to help them familiarize themselves with its subsystems and their associated habitat parameters.
On the day of the experiment, participants began by signing a consent form. This was followed by a 20-min tutorial, which included a short video explaining Daphne’s functionality and the anomaly resolution process. Participants then completed two test trials, each lasting about 3 min, without any external assistance. These trials featured low uncertainty scenarios with Advanced explanations, where Daphne provided high-confidence, unequivocal diagnoses. This approach was intended to minimize early exposure to diagnostic uncertainty. Participants were also advised to make their decisions carefully and to rely on their training, as Daphne is not always infallible. They then completed a short quiz to assess their understanding of both Daphne and the ECLSS. Only those who scored at least 8 out of 10 were permitted to proceed to the experimental phase.
Each qualified participant completed two experimental sessions—one with Basic explanations from Daphne and one with Advanced explanations (see Figure 1). The order of these sessions was counterbalanced across participants. Each session lasted approximately 40 min and consisted of 8 anomaly scenarios that varied in uncertainty levels. Anomalies were randomized and counterbalanced to mitigate any learning effects. Participants had up to 3 min (180 s) to diagnose each anomaly, simulating the time constraints of real-life spacecraft operations such as time-sensitive maintenance and repair tasks. The timer (visible on Daphne’s GUI as shown in Figure 2) started when the experimenter introduced the anomaly from the HSS.
The anomaly treatment process using Daphne consisted of the following three phases:
Step1: Detection
As the anomalous parameters associated with the anomaly scenario are initiated by the experimenter, they appeared on the Anomaly Detection Window. An example scenario with 4 anomalous parameters occurring in the “habitat” are shown in Figure 4. The participant then selected the symptoms that they would like to diagnose by clicking on them individually in the Anomaly Detection window. As selections were made, the chosen symptoms appeared in the Anomaly Diagnosis window (Figure 5). Step 1 Detection: Anomalous parameters associated with the anomaly scenario “TCCS Auxiliary Cabin Fan Failure” appear in the Anomaly Detection window as the simulation starts. Step 2 Diagnosis: The Anomaly Diagnosis window displaying all the symptoms that appeared in Figure 4 selected by the participant for diagnosis.
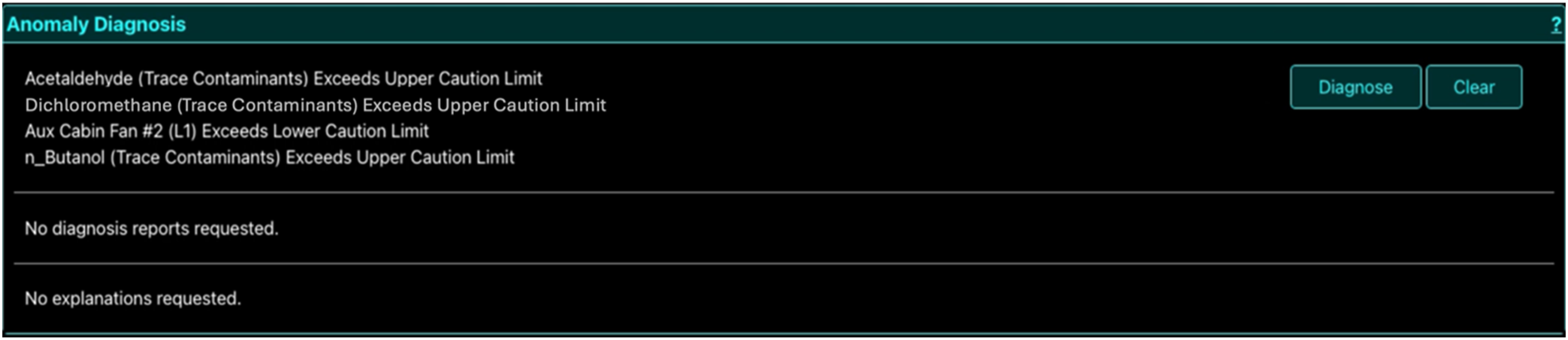
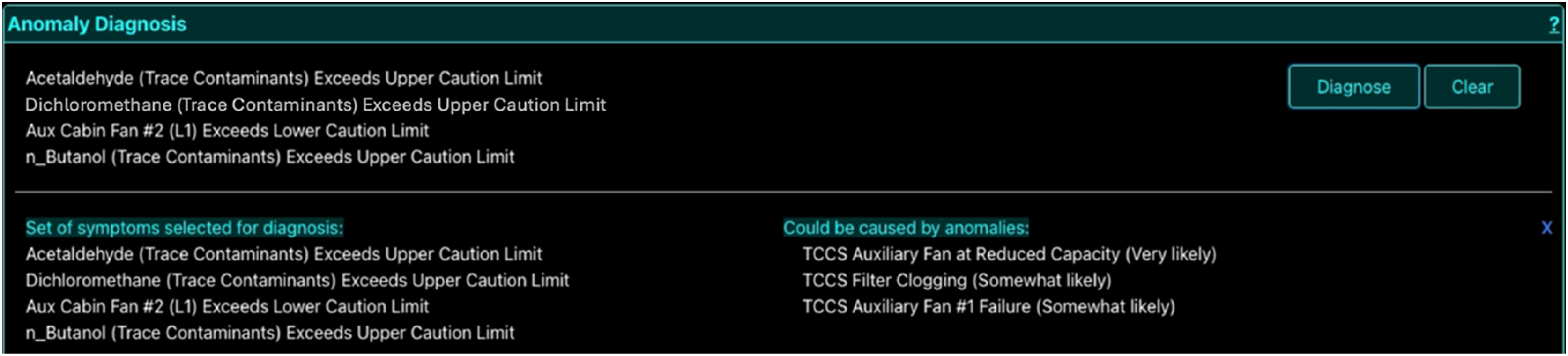
Step 2: Diagnosis
After participants had selected all desired symptoms on the Detection window, they appear on the Anomaly Diagnosis window along with a Diagnose button, as shown in Figure 5. Clicking this button prompted Daphne to generate a diagnosis report by integrating information from its data sources. Daphne then provided a ranked list of possible anomaly scenarios, sorted by likelihood. The two explanation conditions differed at this stage: a. Basic Explanations: The list included only the anomaly names and qualitative likelihood scores, as shown in Figure 6. These scores ranged from Very Likely to Least Likely, based on the likelihood of each anomaly being the true root cause. Participants clicked on the anomaly they wished to view, and the corresponding remedial procedure appeared in the Anomaly Response window as shown in Figure 9. b. Advanced Explanations: In addition to the qualitative likelihood scores, the display included extra information: knowledge-driven explanations as shown in Figure 7 and data-driven historical explanations as shown in Figure 8. Participants could review the tabular information for both explanation types and then click the Select button corresponding to the anomaly they believed to be correct, as shown in Figure 8. This action revealed the remedial procedure in the Anomaly Response window, as shown in Figure 9. Step 2 Diagnosis: The Anomaly Diagnosis window displaying the names and qualitative likelihood scores for all probable anomalies based on the participant’s selected symptoms from Figure 5. The information in this window is same for both basic and advanced explanation sessions. Step 2 Diagnosis: The Anomaly Diagnosis window displaying knowledge-driven explanations for each probable anomaly scenario in advanced explanation session. Step 2 Diagnosis window: The Anomaly Diagnosis window displaying data-driven historical explanations for each probable anomaly scenario in advanced explanation session.
Step 3: Recommendation
After the procedure was revealed, the participant then marked the selected procedure as Complete by clicking on all the steps of the procedure and then clicked on the Submit Anomaly button to submit their final decision, as shown in Figure 9. Step 3 Recommendation: The Anomaly Response window showing the remedial procedure for the anomaly selected (TCCS Auxiliary Fan at Reduced Capacity) by the participant.
The submitted procedure may or may not resolve the anomaly depending on whether the corresponding selected anomaly was correct or not. Once the selected procedure was submitted for Daphne’s response, Daphne prompted the participants to rate their confidence in their diagnosis on a scale from 1 to 7 as shown in Figure 10. After submitting their confidence rating Daphne indicated to the participants whether the anomaly had been successfully resolved (as shown in Figure 11) or not and presented the survey link. If, instead, the participants ran out of time, after the 3-min window elapsed, Daphne told the participants that the resulting scenario was a failure and provided the survey link to fill out the surveys. Clicking on the Survey Link button opened a new window that displayed the post-anomaly surveys that the participant needed to complete. These surveys consisted of the Trust in Automation survey (Jian et al., 2000) and the Satisfaction Survey (Hoffman et al., 2023) and were administered in the same order for every participant across all trials. Once the surveys were completed, the participant closed the survey window and returned to the Daphne interface (Figure 2). A short, randomized wait time of no more than 15 s was introduced before the next anomaly scenario began. After all eight trials in a session were completed, participants moved on to the second session, which followed the same protocol but used the alternative explanation condition in the Diagnosis phase. Throughout the experiment, participant activity and screen interactions were monitored by the experimenter to ensure no unintended assistance—such as participants consulting the ECLSS manual, searching online for information about ECLSS anomalies, or using other decision support tools—was received. Daphne prompt asking the participants to select their confidence rating after clicking the Submit Anomaly button in Figure 9. Daphne providing feedback to the participant after successful diagnosis and a link to fill out surveys.
Analysis Methods
Independent Variables
The main independent variables for our analysis are the explanations (Basic explanations vs Advanced explanations) and the level of uncertainty in the agent’s recommendations (high vs low). Each participant experienced 4 anomalies in each of the 4 resulting blocks (Basic explanations/high uncertainty, Basic explanations/low uncertainty, Advanced explanations/high uncertainty, Advanced explanations/low uncertainty). Please see Figure 1 for more details.
Dependent Variables
The dependent variables were Task performance, Satisfaction, Trust, Confidence, and Reliance. These measures were collected through a combination of objective and subjective measures. For each of these metrics, in each session (see Figure 1), the values of the metric for the high uncertainty and low uncertainty anomalies were summed separately, yielding 4 numbers for each metric and participant, one for each of the 4 accuracy/uncertainty combinations. Task performance was measured using 2 metrics: (1) the number of anomalies correctly diagnosed within the 3-min limit, and (2) the mean time to diagnose the anomalies. For every correctly diagnosed anomaly, the participant was given a score of 1. If the participant ran out of time or submitted an incorrect anomaly, they were given a score of 0. The total was then added to get a final score for the number of anomalies diagnosed by a participant. The time to diagnosis was measured by how long it took for the participants to confirm their procedure selection by clicking on the Submit button and was recorded using an internal script in Daphne’s code. The mean time to diagnose was calculated by averaging the total time to diagnosis for all the anomalies in an explanations/uncertainty level. Satisfaction in Daphne was measured using Hoffman’s satisfaction survey (Hoffman et al., 2018) which consists of 8 questions on a 7-point Likert scale. The overall satisfaction score was measured by averaging the score of individual questions on the survey. Trust in Daphne was measured using Jian’s Trust in Automation survey (Jian et al., 2000) which consists of 12 questions. The first 5 questions in this questionnaire are negative prompts that measure the participant’s distrust in the system and the next 7 questions are positive prompts that measure the participant’s trust in the system. Each question can be rated on a 7-point Likert scale. The overall trust score was measured by inverting the scores on the distrust questions and summing them, and then adding the total distrust score to the total trust score. Confidence was obtained using a 7-point Likert prompt “How confident do you feel in your anomaly diagnosis?” post-anomaly diagnosis varying from “Not confident at all” to “Very confident.” For calculating reliance, the participant was given a score of +1 if they accepted Daphne’s recommendations and a score of −1 if they rejected Daphne’s recommendations, regardless of whether the recommendations were correct or incorrect. These scores were averaged over a session in high and low uncertainty conditions to get an overall reliance score.
Statistical Methods
Statistical tests were performed using the R Statistical Software (version 4.3.2; R Foundation for Statistical Computing, Vienna, Austria). Data were tested for normality using the Shapiro-Wilk test. To investigate the effects of uncertainty on the metrics, one-tailed paired t-tests were implemented when normality was satisfied. One-tailed pairwise t-tests were also performed on the differences of the metrics in the 2 sessions (value with Advanced explanations—value with Basic explanations) to investigate which of the two uncertainty conditions had the largest change in metrics between the sessions. In all cases, significance was taken at α = 0.05 level. Data is presented as mean ± SE. For all measures, Cohen’s d effect size was calculated.
Results
Overall, the results indicate that participants demonstrated significantly higher task performance, trust, satisfaction, confidence levels, and reliance when supported by the AI agent under low uncertainty conditions compared to the high uncertainty conditions, supporting our hypothesis H1. This highlights the impact of uncertainty in AI-generated recommendations on operator outcomes during time-sensitive diagnostic tasks. Furthermore, in high uncertainty conditions, the inclusion of quantitative explanations led to notable improvements across all measured variables, supporting hypothesis H2, suggesting that such explanations meaningfully enhance the effectiveness of AI support in diagnosis tasks. Our findings are presented in the next few sections in more detail to enable a comprehensive presentation of the results.
Task Performance
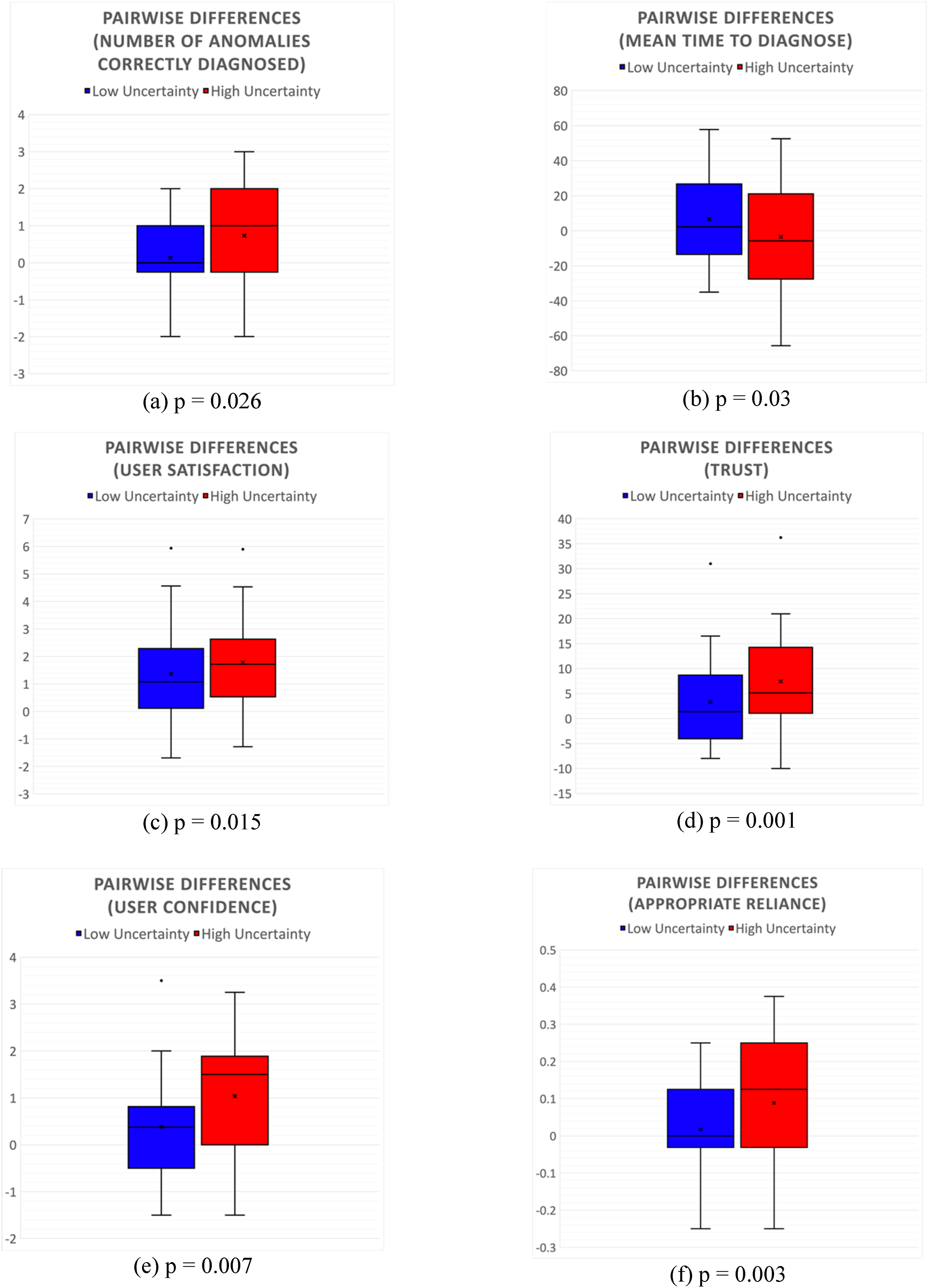
The total number of anomalies correctly diagnosed by participants under high and low uncertainty conditions is shown in Figure 12(a). Results indicate that, on average, participants solved more anomalies correctly under low uncertainty (3.53 ± 0.06) vs high uncertainty (2.00 ± 0.17). These results are statistically significant (t (32) = −8.79, p < .001). The effect size for this analysis, d = 2.09, was found to be large, indicating a substantial difference between the high and low uncertainty conditions. The total time taken by the participants to complete all anomalies (out of the max 180 s) is shown in Figure 12(b). Analysis indicates that the participants on average spent 76.45 ± 5.15 s in diagnosing anomalies under low uncertainty conditions compared to 112.76 ± 4.88 s high uncertainty conditions. This difference was found to be statistically significant (t (32) = 10.63, p < .001). The effect size for this analysis, d = 2.0, was also found to be large. Figure 13(a) shows the pairwise comparison of the total number of anomalies correctly diagnosed by the participants in the two sessions. Pairwise differences of the number of anomalies correctly diagnosed between the two explanation sessions were low under low uncertainty (0.13 ± 0.16) conditions compared to high uncertainty (0.73 ± 0.26) conditions. This result was found to be significant with (t (32) = 2.01, p = .026) satisfying H2 for task performance with respect to the number of anomalies correctly diagnosed. The effect size for this analysis, d = 1.96, was also found to be large. Figure 13(b) shows the pairwise comparison of the mean time to diagnosis for the participants in the two sessions. Pairwise differences of the mean time to diagnoses between the two explanation sessions were higher under low uncertainty (6.51 ± 4.70) compared to high uncertainty conditions (−3.53 ± 5.42). This result was found to be significant with (t (32) = −1.89, p = .03) satisfying H2 for mean time to diagnosis. This analysis also showed a large effect size, d = 1.42. Results (n = 33) in each experimental session Basic and Advanced explanations for both, low and high uncertainty conditions: (a) Number of anomalies correctly resolved (out of 8 anomalies) (b) Mean time to diagnose an anomaly (out of 180 s) (c) Satisfaction (d) Trust in automation (e) Confidence (f) Appropriate. Results (n = 33) for pairwise differences (Advanced explanations - Basic explanations) in each experimental session for low and high uncertainty conditions: (a) Number of anomalies correctly resolved (out of 8 anomalies) (b) Mean time to diagnose an anomaly (out of 180 s) (c) Satisfaction (d) Trust in automation (e) Confidence (f) Appropriate Reliance.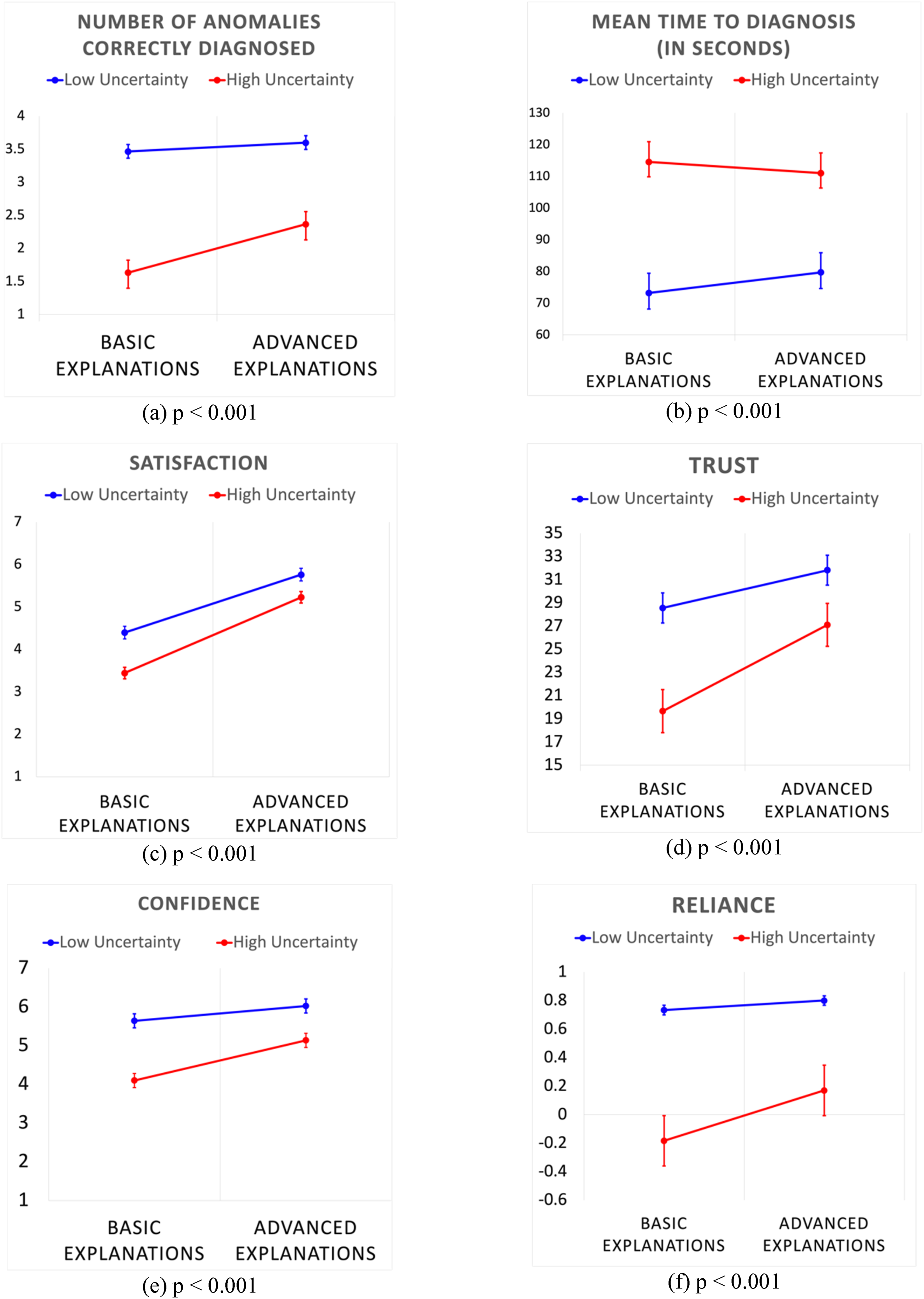
Satisfaction
Figure 12(c) summarizes the results of the Hoffman’s satisfaction survey score. The anomalies with low uncertainties (5.07 ± 0.15) on average had a significantly higher satisfaction score compared to high uncertainty anomalies (4.33 ± 0.13) with p < .001, satisfying H1. This analysis showed a large effect size, d = 0.91. Moreover, the overall satisfaction score was found to be significantly higher in sessions with Advanced explanations for both low (5.76 ± 0.15; t (32) = −4.28; p < .001) and high uncertainty (5.22 ± 0.16; t (32) = −6.09; p < .001) anomalies. Figure 13(c) shows the pairwise differences of the satisfaction scores for the participants between the two explanation sessions. Pairwise differences in satisfaction scores, on average, were significantly lower in low uncertainty conditions (1.36 ± 0.31) compared to high uncertainty conditions (1.78 ± 0.29) with t (32) = −2.26; p = .015), satisfying H2. This analysis showed a small to medium effect size, d = 0.42. Further analysis of pairwise comparison of individual questions of the satisfaction survey, as shown in Figure 14, revealed that the participants’ “understanding” (t (32) = −2.59, p = .007) and “perceived usefulness” of Daphne (t (32) = −2.65, p = .006) was significantly higher in high uncertainty conditions. Pairwise differences (Advanced explanations - Basic explanations) for individual questions on Explanation Satisfaction Survey.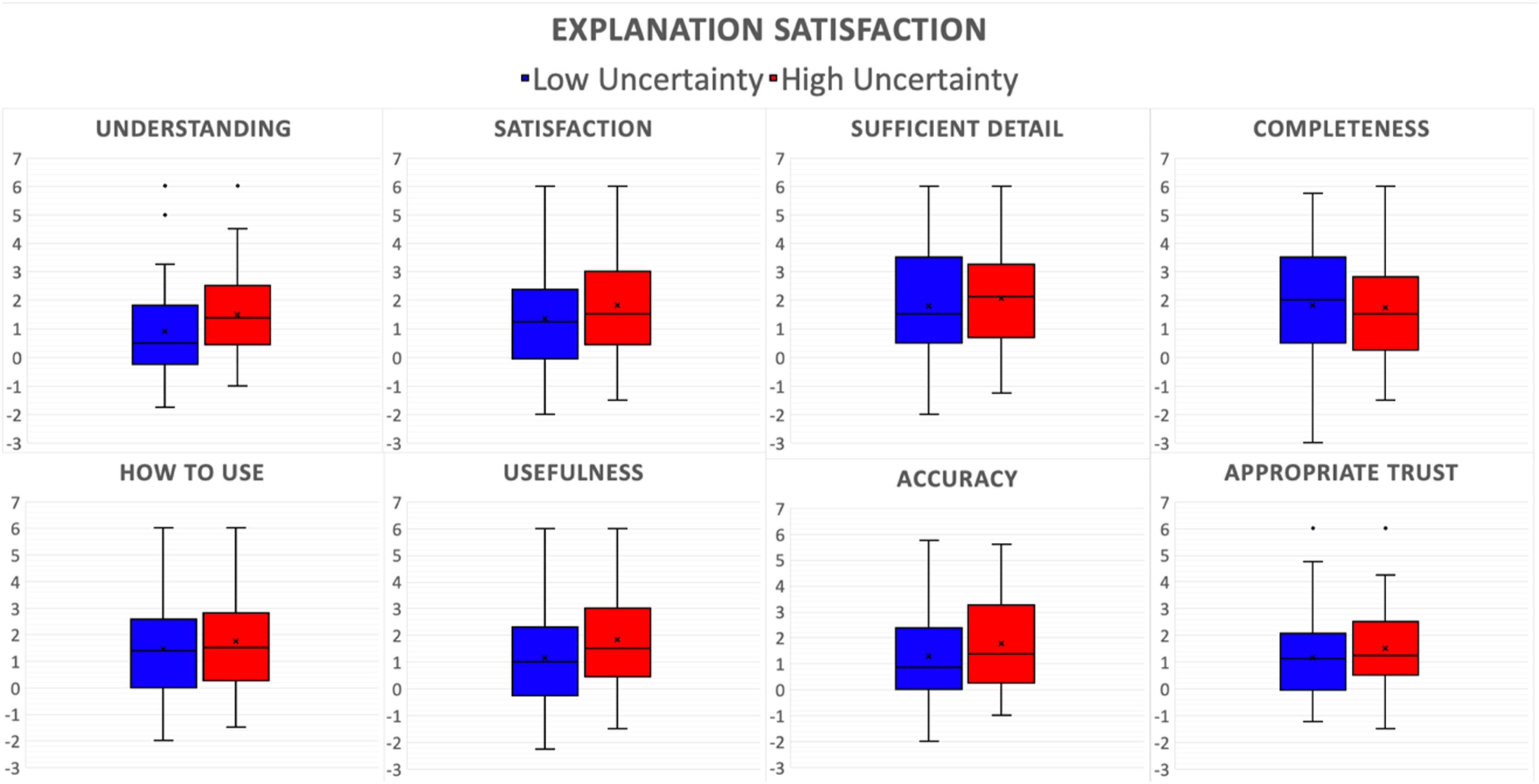
Trust
Figure 12(d) summarizes the results of the Jian’s trust in automation survey score. The overall trust score was found to be significantly higher under low uncertainty (30.18 ± 1.29) conditions compared to high uncertainty (23.37 ± 1.85) with t (32) = 5.71, p < .001 supporting H1. This analysis showed a large effect size, d = 0.96. Figure 13(d) shows the pairwise comparison of the trust scores of the participants in the two sessions. Pairwise differences in trust, on average, were significantly lower in low uncertainty conditions (3.25 ± 1.61) compared to high uncertainty conditions (7.44 ± 1.72) with t (32) = −3.20; p = .001) satisfying H2. This analysis indicated a medium to large effect size, d = 0.68.
Confidence
Figure 12(e) summarizes the aggregated score of every participant’s self-reported confidence score post-anomaly diagnosis for low and high uncertainty anomalies for each session. Participants showed an increase in their confidence level post diagnosis under low uncertainty (5.83 ± 0.16) conditions compared to the anomalies with high uncertainty (4.62 ± 0.15) with t (32) = −8.21, p < .001) satisfying H1. This analysis indicated a very large effect size, d = 2.0. Figure 13(e) shows the pairwise comparison of the confidence scores of the participants in the two sessions. Pairwise differences in confidence, on average, were significantly lower under low uncertainty conditions (0.38 ± 0.19) compared to high uncertainty conditions (1.036 ± 0.24) with t (32) = 2.58; p = .007) satisfying H2. This analysis indicated a medium to large effect size, d = 0.75.
Reliance
Figure 12(f) summarizes the results of participants’ reliance in Daphne for low and high uncertainty anomalies for each session. Participants’ total reliance score was found to be significantly higher in sessions with Advanced explanations compared to Basic explanations for high uncertainty (t (32) = −2.77; p = .004) anomalies, but not for low uncertainty (t (32) = −0.8; p = .21) conditions suggesting that Advanced explanations improve operator reliance when uncertainty is high. On average, the participants had higher reliance in Daphne under low uncertainty conditions compared to high uncertainty conditions. This result was found to be statistically significant, satisfying H1. Figure 13(f) shows the pairwise comparison of the reliance scores of the participants in the two sessions. Pairwise differences in reliance, on average, were significantly higher in high uncertainty conditions (0.088 ± 0.031) compared to low uncertainty conditions (0.0167 ± 0.02) with t (32) = 1.92; p = .003) satisfying H2. This analysis indicated a very large effect size, d = 2.26.
Discussion
This paper began by asking the question “Are explanations helpful under uncertainty?” Results suggest that they are and even more so under high uncertainty. The results reveal detrimental effects of uncertainty on performance. Participants not only resolved fewer anomalies correctly under high uncertainty, but they also took longer to resolve anomalies. This result is consistent with some other studies (Cau et al., 2023; Tomsett et al., 2020) that explore effects of uncertainty in human-AI teams. Explanations seemed to improve the number of anomalies correctly resolved by the participants in both high and low uncertainty cases. However, under low uncertainty, the explanations seemed to increase the mean time to diagnose the anomalies. This could be explained by participant behavior that expects the explanations to reveal the agent’s underlying uncertainty. For high uncertainty conditions, the participants were able to quickly observe the uncertainty through the agent’s explanations and its cause. Moreover, explanations had a much higher effect on task performance under high uncertainty than under low uncertainty suggesting that the explanations can act as a countermeasure for deleterious effects of uncertainty on human performance. Results also suggested an improvement in participant satisfaction with Advanced explanations for both high and low uncertainty anomalies, although the improvement in satisfaction was significantly higher in high uncertainty conditions. Moreover, the participants’ understanding and usefulness of Daphne was significantly higher in high uncertainty conditions, further supporting the argument that explanations can help counteract the negative effects of uncertainty. Trust scores were also found to be higher under low uncertainty as hypothesized in H1. This result is consistent with previous studies (B. Liu, 2021; Siegling, 2020). Moreover, pairwise differences in trust show that the improvement in trust is significantly higher under high uncertainty suggesting that explanations have a larger effect on participant’s trust under high uncertainty than low uncertainty conditions. Previous studies have shown that agent transparency can help repair mis-calibrations in user trust in AI systems under uncertainty (Zhang et al., 2020). A common way for AI systems to convey underlying uncertainty to the human operators is by being transparent about its confidence (Corvelo Benz & Rodriguez, 2023; N. F. Liu et al., 2023). Explanations make it easier for the operators to decide on AI system’s correctness and calibrate their trust accordingly. Participant confidence was also found to be significantly higher with Advanced explanations in low uncertainty conditions compared to high uncertainty as hypothesized in H1. These results are in line with influential existing theories on human-computer interaction (Hoff & Bashir, 2014; J. D. Lee & Moray, 1994; J. D. Lee & See, 2004). The pairwise differences in confidence scores between the two sessions was found to be significantly higher under high uncertainty than under low uncertainty supporting H2. An operator’s trust in AI agent lies in its ability to understand how it works and why it works in certain ways (Hoff & Bashir, 2014). And in building this trust in AI agent’s performance, the user builds its own confidence in the task as well. This is further emphasized by appropriate reliance scores. Participants had a higher appropriate reliance score with Advanced explanations and overall, a significantly higher appropriate reliance score in low uncertainty conditions as hypothesized. Further, pairwise comparisons results reveal that the change in appropriate reliance between the two explanation conditions was much higher under high uncertainty. The explanations improved participants’ self-confidence so that they were able to rely on their own judgments more and reject Daphne’s recommendations when they felt like Daphne was incorrect, thus appropriately calibrating their trust in Daphne. These results are in line with previous literature on the intricacies of the relationship between trust, confidence, and reliance (J. D. Lee & Moray, 1994). Just as the users’ trust in automation may influence their reliance in automation, so too their self-confidence may influence their reliance on manual control. Users’ self-confidence may interact with their trust in the system and mistrust and low self-confidence may lead to an inappropriate allocation strategy.
Our findings provide empirical support for the guidelines outlined earlier in the Introduction section: 1. Trust calibration: Trust in Daphne was significantly higher when Advanced explanations were provided, suggesting that transparency can help calibrate operator trust more appropriately to the AI’s capabilities. Pairwise differences in trust scores between Basic and Advanced explanation conditions were larger under high uncertainty suggesting that richer explanations can help operators calibrate their trust in scenarios where AI’s recommendations were less certain. This suggests that explanations were helping participants adjust their trust in Daphne depending on the context of the scenarios. This finding reinforces that explanations should be designed to promote appropriate trust, not just increase operator trust in AI. 2. Appropriate reliance: Advanced explanations increased appropriate reliance under high uncertainty conditions. The largest improvement occurred under high uncertainty, showing that transparency about the AI’s reasoning and confidence enabled participants to better judge when to defer to the AI and when to trust their own judgment. These results suggest that explanations can serve as a mechanism for aligning user reliance with AI capability, a key requirement for effective human-AI teaming. 3. Improve user confidence: Participants reported higher confidence in their decisions when provided with Advanced explanations, especially in high uncertainty conditions, indicating that richer explanations can bolster user’s self-confidence even when the AI is less certain. Such confidence is particularly important in operational settings of human-in-the-loop systems where human operators must ultimately take responsibilities for making final decisions. 4. Enhance understanding: Pairwise differences of individual satisfaction survey questions revealed that participants’ understanding, and perceived usefulness of Daphne were significantly higher with Advanced explanations. The qualitative and quantitative likelihood information, arranged in easy to peruse tabular format, likely helped participants form a more accurate mental model of Daphne’s decision-making process. This underscores the importance of providing explanations in a format that makes it easy to convey why the AI behaves as it does. 5. Enhance satisfaction: Overall satisfaction scores were higher with Advanced explanations in both low and high uncertainty conditions, indicating that richer explanations add value to the decision-making process and improve user experience. Insights into Daphne’s reasoning were perceived as more useful and engaging, ultimately improving the overall user experience. This emphasizes that operator satisfaction is not just a secondary outcome—it affects whether users accept and continue to use AI systems in the long term.
Overall, these findings show that well-designed explanations can simultaneously promote trust calibration, appropriate reliance, confidence, understanding, and satisfaction—the five guidelines we proposed earlier. These results also highlight that these guidelines are interconnected: for instance, improved understanding can strengthen confidence, which in turn can influence reliance and trust in AI.
Implications for Designing AI Agents
Overall, the results suggest that more thorough explanations should be added to AI agents in cases where there is high uncertainty in the decision-making process and users have limited knowledge of the task. Conversely, for low uncertainty tasks, it may be acceptable to have more succinct or on-demand explanations. We anticipate that this effect would be exacerbated with level of expertise, so that more expert users (in both the tool and the agent) would prefer succinct explanations unless the particular decision is very complex and/or has very high uncertainty. Considering the ineffectiveness of existing XAI methods, better explanations should be designed for decision-making context under uncertainty and when people have limited knowledge in the tasks. Admittedly, providing too much information in the explanations may also lead to information overload (Sanneman et al., 2023). Thus, the designer must strike a balance between providing more information for better understanding and keeping the cognitive load low. To this end, techniques for presenting explanations visually and selectively or incrementally, and adaptive methods for incorporating the consideration of cognitive load into the explanation generation process should be explored. These approaches can be developed to increase people’s ability in making full use of the information carried out in AI explanations. For example, providing the confidence of the AI agent in the recommendations can help people in inferring the underlying uncertainty even without having much domain knowledge. Our study also suggests five guidelines for AI explanations that may each capture distinct aspects of people’s usage of AI explanations but are intricately linked. Further studies are needed to systematically understand the relationships between these requirements. AI agents should also carefully and adaptively select the type of explanations to present to the users based on their specific needs.
Limitations and Future Work
While our research suggests how impactful the role of uncertainty in explanations can be in diagnostic decision-making tasks, there are several limitations of our study. First, we used only two specific types of explanations in our experiment. Other approaches, such as graphical representations, charts, or example-based explanations, may also be effective and warrant systematic evaluation in future work. Because our study focused narrowly on the presence of explanations under uncertainty and used two explanation formats tailored specifically for this experiment, our results may not generalize to other explanation types.
Another limitation is that based on the design of the anomaly scenarios it is hard to know if these results would hold for other, more complex anomaly scenarios in real-life. We designed scenarios for this study to the best of our ability, to be of equal difficulty levels for each participant and for each level of uncertainty and accuracy. This judgment was based primarily on the number of symptoms of the anomaly signatures. That said, judging the difficulty of a scenario in real anomalies would require considering other attributes such as the urgency and consequences of the anomaly.
Applications
This study adds evidence of the potential of agent transparency (in the form of explanations) to alleviate the negative impacts of agent diagnostic uncertainty. We also provide design recommendations for AI systems in human-agent decision-making tasks. While the results were obtained for spacecraft anomaly diagnosis tasks, we believe these results can generalize to other types of human-AI decision-making tasks such as healthcare anomaly diagnosis. Findings from this study can inform standards and guidelines for the development of future diagnostic AI agents that can improve human-agent interactions under uncertainty.
Conclusion
We conducted a study where we simulated uncertainties in the diagnosis of an AI agent and collected participants’ responses to those uncertainties using various objective and subjective measures. Our results show that uncertainty can lead to reduction in human performance, trust, satisfaction, and confidence. We further compared conditions where the AI agent provided either Basic explanation (only qualitative likelihood scores for its diagnosis) and another in which it offered Advanced explanations (quantitative likelihood scores with detailed justifications that included knowledge-driven and historical data-driven explanations) to the participants for its decisions. We found that even though explanations improve human performance metrics in low uncertainty conditions, this improvement with Advanced explanations is much higher in sessions with high uncertainty. Critically, we found that Advanced explanations are especially valuable in a human-AI team when decisions cannot be made with absolute certainty. We also found that providing explanations in low uncertainty conditions can increase the participant’s reaction time. This finding has important implications for the design of AI agents that need to operate in environments such as LDEMs. Future human spaceflight missions will require increased autonomy and can benefit from an on-board AI agent that provides effective explanations for uncertain scenarios. These explanations should help the users appropriately calibrate their trust and reliance, improve confidence, and enhance understanding and satisfaction, ensuring that crewmembers can collaborate effectively with the AI agent to diagnose anomalies in both routine and novel situations.
Footnotes
Acknowledgments
The authors would like to thank all the participants for their time and commitment to this study. We would also like to thank the anonymous reviewers for their efforts to improve this manuscript.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is a part of the Human Capabilities Assessments for Autonomous Missions (HCAAM) Virtual NASA Science Center of Research (VNSCOR) funded by the NASA Human Research Program, Grant Number 80NSSC19K0656.
{kind=link}