
Abstract
Trust development will play a critical role in remote vehicle operations transitioning from automated (e.g., requiring human oversight) to autonomous systems. Factors that affect trust development were collected during a high-fidelity remote uncrewed aerial system (UAS) simulation. Six UAS operators participated in this study, which consisted of 17 trials across two days per participant. Trust in two highly automated systems were measured pre- and post-study. Perceived risk and familiarity with the systems were measured before the study. Main effects showed performance-based trust and purpose-based trust increased between the pre- and post-study measurements. System familiarity predicted process-based trust. An interaction indicated that operators who rated the systems as riskier showed an increase in a single-item trust scale between the pre- and post-study measurement, whereas participants that rated the systems as less risky maintained a higher trust rating. Individual differences showed operators adapted to why the automation was being used, and trust improved between measurements. Qualitative analysis of open-ended responses revealed themes related to behavioral responses of the aircraft and transparency issues with the automated systems. Results can be used to support training interventions and design recommendations for appropriate trust in increasingly autonomous remote operations, as well as guide future research.
Keywords
The Advanced Air Mobility (AAM) concept envisions a diverse set of emerging aerial technologies. These technologies will enable varying mission types in urban and rural environments, with applications ranging from commercial transport and air taxi services (e.g., Urban Air Mobility) to drone surveillance and inspection operations (National Academies of Sciences, Engineering, and Medicine, 2020). To promote the scalability potential for AAM applications, emerging aviation markets are exploring remote vehicle operations that allow fewer human operators (m) to manage more vehicles (N), referred to as m:N (Aubuchon et al., 2022). These types of operations will be supported by increasingly autonomous systems, which will shift authority toward the technology (Pritchett et al., 2018). The term “increasingly autonomous” characterizes technology that spans “the spectrum of system capabilities that begin with the abilities of current automatic systems, such as autopiloted and remotely piloted (non-autonomous) unmanned aircraft, and progress toward the highly sophisticated systems that would be needed to enable the extreme cases” (National Research Council, 2014, p. 2; cf. “increasingly capable automation,” Chiou & Lee, 2023). Because this term encompasses both automation and autonomous systems, providing a distinction between these two classifications is helpful.
We adopt a definition of automation as “a device or system that accomplishes (partially or fully) a function that was previously, or conceivably could be, carried out (partially or fully) by a human operator” (Parasuraman et al., 2000, p. 287). This definition encompasses the notion of level of automation (LOA), which can range from fully manual (i.e., the computer offers no assistance, and the human must take all decisions and actions) to fully automated (the computer decides everything, acts autonomously, ignoring the human; cf. Sheridan & Verplank, 1978). Surpassing automation, Kaber (2018, p. 408) describes an autonomous system (agent) as requiring three characteristics: (1) an autonomous agent is viable in a target context; (2) an autonomous agent possesses independence or capacity for function/performance without assistance from other agents (e.g., humans); and (3) an autonomous agent possesses self-governance in goal formation and fulfillment of roles. From this perspective, even if a system has a high LOA, if it requires monitoring and the possibility of human intervention in a particular operating context, then it is not independent and therefore not an autonomous system (“Tenet 2” outlined by Kaber, 2018). Instead, the technology is automation regardless of technical capacity to act autonomously.
Viable, mature AAM applications will entail a paradigm shift where operations are accomplished autonomously without human intervention or oversight (see Goodrich & Theodore, 2021). Yet, despite the growing interest in developing and implementing autonomous systems, regulators and users often constrain or under-use potentially autonomous capacities because of a lack of trust in systems to operate with greater responsibility and authority over the execution of safety-critical tasks (Kaber, 2018). Instead, although systems may be highly automated, human oversight is often employed to provide a layer of resiliency in case of system failure (cf. Holbrook et al., 2019). Understanding the developmental process of trust in increasingly autonomous technologies will play a critical role in charting the path from remote vehicle operations that leverage automation (e.g., requiring human oversight) to scalable autonomous operations. The objective of the current study was to examine factors that affect the development of operator trust in highly automated (increasingly autonomous) systems across a two-day, high-fidelity remote uncrewed aerial system (UAS) simulation. To frame this objective, however, we provide a brief overview of the developmental process of human-automation trust.
Human-Automation Trust Development
Over the last several decades researchers have used trust to predict and describe behaviors and intentions toward adopting, using, and interacting with automation (e.g., Chancey et al., 2015, 2017; Chiou & Lee, 2023; Hoff & Bashir, 2015; Lee & See, 2004; Muir, 1987; Sheridan, 1988, 2019a, 2019; Sheridan et al., 1983; Sheridan & Hennessy, 1984; Sheridan & Verplank, 1978). Moreover, as with human teams (Salas et al., 2005), trust in human-autonomy teams is a critical coordinating mechanism as well (de Visser et al., 2020; O’Neil et al., 2022; Schaefer et al., 2019). Although appropriate trust facilitates efficient interactive behaviors with automation, if trust exceeds or falls short of system capabilities, then misuse or disuse, respectively, may occur (Lee & See, 2004). Disuse refers to failures resulting from an operator rejecting the capabilities of the automation and disabling, ignoring, or spending excessive time crosschecking the actions and decisions of the technology. Alternatively, misuse refers to failures resulting from an operator inadvertently violating critical assumptions and not monitoring the automation enough or depending on the automation when it should not be used (see Parasuraman & Riley, 1997). Thus, to provide clarity, a definition of trust is required, as it is often identified as the operant variable in disparate human-automation interaction and human-autonomy teaming paradigms.
Lee and See (2004) highlight two important components of the construct. First, the trustee is responsible for advancing the goal(s) of the trustor, in which the trustee performs a particular action on their behalf. Second, the trustor must willingly assume some risk by delegating responsibility to the trustee, which introduces an aspect of risk perception and vulnerability on the part of the trustor (Stuck et al., 2022; cf. Mayer et al., 1995). If an operator does not perceive the risk associated with placing a technology in charge of achieving their goal(s), then trust will not greatly affect intentions (Chancey, 2020) or behaviors (Chancey et al., 2017; see Stuck et al., 2022 for overview of risk in the context of human-automation trust). Reflecting these perspectives, trust is defined as “an attitude that an agent will help achieve an individual’s goals in a situation characterized by uncertainty and vulnerability” (Lee & See, 2004, p. 51).
Researchers often denote goal-oriented information that supports trust along a dimension of attributional abstraction, which ranges from being based on observable behaviors of the trustee to being based on more abstract concepts in reference to the trustee. Similarly, Lee and See (2004; Lee & Moray, 1992) proposed goal-oriented informational bases for trust in automation: performance, process, and purpose.
Performance-based trust describes what the automation does. For this component, observable automation actions that reliably achieve the operator’s goals will lead to greater trust. To illustrate, a remote operator’s trust in an autopilot system will increase in proportion to the successful observed, experienced, and reported flights that are safely completed with little or no unanticipated operator interventions. Yet if the automation fails to execute the task it was designed for, performance-based trust can significantly decrease (see Politowicz et al., 2021, for UAS example).
Process-based trust describes how the automation operates and corresponds to the appropriateness of the automation’s algorithms in achieving the operator’s goals. For this component, automation that is understandable will lead to appropriate trust, which can occur through transparent design (Chen et al., 2014; Lyons, 2013) and/or providing a global explanation for how the technology works (Klein et al., 2021), possibly through training (Cohen et al., 1998). To illustrate, a remote operator is more likely to trust detect-and-avoid automation if they understand (via training or transparency) the general logic of that system causes aircraft to circle back around to missed waypoints after resolving a conflict.
Purpose-based trust describes why the automation was developed and corresponds to how well the designer’s intent has been communicated to the operator. This closely resembles Rempel et al.’s (1985) concept of faith-based trust, where trust is based on the belief that the automation can be depended upon in the absence of behavioral observation of the trustee. For this component, automation that achieves the goals the operator understands it was designed to achieve will lead to appropriate trust. To illustrate, a remote operator is more likely to appropriately trust an autopilot that executes an unplanned course correction if they understand that system is designed to avoid conflicts when navigating between waypoints and is simply deconflicting flight paths with another vehicle before it reengages with the path.
Lee and See (2004) note that all three of these trust bases can mutually affect the development of each other (see Muir, 1987; Li et al., 2019, for recognition of this with similar trust bases). Drawing from the autopilot examples, if the operator observes aircraft avoiding other vehicles during an operation (performance-based), then this could update the operator’s understanding of the autopilot to include detect-and-avoid functionality (purpose-based). Similarly, the operator could have learned in training that the autopilot has detect-and-avoid functionality (purpose-based), which could provide some understanding for how it works (process-based) and be confirmed during operations (performance-based). When trust is based on multiple mutually supportive and confirming dimensions it can be robust, yet when it is based on a single dimension it can be fragile (Lee & See, 2004).
Lee and See (2004) proposed that although these bases of trust are largely influenced by affective processes (i.e., moods, feelings, and emotions), analytical and analogical processes also determine the assimilation of this information. Analytically, trust reflects accumulated knowledge from previous interactions, which are used to evaluate the behavior of the automation rationally and probabilistically. This process, however, may overemphasize the cognitive capability of the decision maker to effectively engage in conscious calculations or exhaustively compare alternatives. Compounding this effect, the nondeterministic algorithms leveraged by increasingly autonomous systems may not allow the operator insight into system behaviors. Analytical processes, therefore, are likely complemented by less cognitively demanding methods such as analogical judgments, which can develop through direct or indirect observations and assumptions based on existing category memberships. Lee and See (2004) propose, however, that affective processes largely influence the effect of trust on behavior, because trust is not only thought about but also felt (Fine & Holyfield, 1996). When a system does not meet expectations of achieving an important goal, then trust is violated, and emotions signal a posture change toward that system is needed. Specifically, emotions guide behaviors when rules do not apply or when cognitive resources are not available to make a rational choice.
Because trust is based on goal-oriented information assimilated via affective, analogical, and analytical paths, this implies it is not static. To this point, recent research has indicated the importance of considering trust as a dynamic construct that can change over time (e.g., de Visser et al., 2020; Guo & Yang, 2021; Yang, Guo, & Schemanske, 2023, Yang, Schemanske, & Searle, 2023). Hoff and Bashir (2015) describe learned trust, which is based on current and past interactions with the target automation and is directly influenced by preexisting knowledge and current performance of the system. Learned trust is separated into two types. Initial learned trust, which represents trust prior to interacting with a system, is based on preexisting knowledge that can be derived from expectations, reputation (e.g., brand and hearsay), experience with the system or similar system, and general understanding of that system (i.e., system familiarity; cf. Bliss et al., 1995). Indeed, Tenhundfeld et al. (2019) concluded that familiarity is essential to trust development, showing that demonstrating the autopark feature in a Tesla Model X automobile led to fewer interventions than simply providing information about the feature. The authors stated this result was consistent with the learned trust concept. Initial learned trust determines the early interaction and dependence strategy that an operator will adopt and is likely supported by purpose-based and process-based information (i.e., existing information the operator has about how the automation works and why it was developed). Dynamic learned trust, however, represents trust formation during an interaction with the automation, which can be impacted by system reliability, predictability, and errors. Because this trust develops during interactions, behaviors of the system are observed and it is more likely supported by performance-based information (i.e., what the automation is doing).
Theoretically, operator trust in systems that are highly automated (or may possess the capacity to act autonomously) should develop as a function of preexisting knowledge and exposure to those systems. It is unclear, however, if these theoretical predictions generalize to expert operators managing increasingly autonomous UAS. Understanding that developmental process will be important to chart how and when increasingly autonomous technologies could be leveraged to support scalable remote vehicle operations.
Purpose and Hypotheses
Human-automation trust has been studied extensively in controlled laboratory settings (though not exclusively, yet see studies reviewed in Hoff & Bashir, 2015, and meta-analysis in Schaefer et al., 2016), which has been useful to evaluate theoretical predictions such as those outlined in Lee and See (2004). In controlled laboratory settings, the experimental task is simplified by omitting factors present in operational environments to maximize internal validity (i.e., concerns whether the relationship between two variables is causal in nature; see Shadish et al., 2002). Yet abstracting away complexities and controlling for extraneous variables to isolate a causal effect raises doubts about the extent to which that relationship generalizes beyond a specific experiment (i.e., concerns of external validity; Shadish et al., 2002), particularly when settings and participants do not resemble the application from which the effect is being studied (i.e., concerns of ecological validity; see Chancey et al., 2023). Evaluations conducted in high-fidelity simulators sampling from an expert population can help determine whether results obtained under controlled laboratory settings are able to overcome the numerous additional factors not addressed or held constant (Vicente, 1997).
Therefore, the purpose of the current study was to examine the factors that affect expert operator trust in increasingly autonomous systems during a high-fidelity remote UAS simulation. We broadly use the term “high-fidelity” because the testing environment and equipment are also used to remotely command and control live vehicles (see Liu et al., 2009, for description of simulation fidelity). Indeed, although not the focus of the results presented in the current work, a parallel goal of this simulation activity was to support integration, testing, and safety risk assessment in a simulated environment prior to live flight operations (see Glaab et al., 2022). Hence, this simulation activity provided an opportunity to investigate operator trust toward increasingly autonomous technologies in an ecologically representative UAS environment.
In the current study, trained and experienced ground control station operator (GCSO) participants directed simulated UAS to complete multiple waypoint-following scenarios designed to exercise and stress-test onboard automated systems (i.e., a parallel hardware-in-the-loop study was also conducted). Participants rated their trust toward two highly automated systems before and after the study. Based on the review of human-automation trust development, we proposed three hypotheses. It should be noted, we did not experimentally manipulate the actual or perceived reliability of the target systems. Therefore, we did not hypothesize directionality in trust outcome measures.
Performance-based trust will change between the pre- and post-measurement times, because it is based on observing the behaviors and actions of automated systems (Lee & See, 2004; Politowicz et al., 2021).
Based on the concept of initial learned trust, operator familiarity and previous times flown with these systems will predict process- and purpose-based trust (Hoff & Bashir, 2015; Tenhundfeld et al., 2019).
Perceived risk of the automated systems will predict subjective trust ratings generally (Lee & See, 2004; Stuck et al., 2022).
Method
Participants
Six male UAS GCSO personnel (M age = 37.33, SD age = 9.27) participated in this study, which included NASA civil servants and contractor employees. Qualified GCSO participants had to have received Crew Resource Management (CRM) training, training for supporting a safety pilot (i.e., the pilot in command located on the flight range), and have supported live UAS operations as a GCSO prior to the current study. Participants self-reported an average of 5.75 hours of video game use per week (SD = 7.57; Min = 0, Max = 20) and 39.67 hours of computer use per week (SD = 19.61; Min = 8, Max = 60). This research complied with the American Psychological Association Code of Ethics and was approved by NASA’s Institutional Review Board. Informed consent was obtained from each participant.
GCSO Role and Apparatuses
GCSO Role
The GCSO is responsible for all preflight, inflight, and postflight activities associated with the communication to an aircraft. The GCSO manages the operation of the aircraft by means of a ground control station (GCS), via a computer interface with an onboard flight management system through a command and control communications link (see LPR 1710.16 5.1.5.4: https://nodis3.gsfc.nasa.gov/npg_img/N_PR_7900_003D_/N_PR_7900_003D__Chapter5.pdf). As a GCSO, the participant was expected to command and control a simulated small UAS, multi-rotor vehicle along a predefined flight path using GCS software. The GCSO could command actions of Takeoff (vehicle will gain altitude from a ground location), Hold (pauses aircraft along the flight path), Return to Launch (vehicle automatically returns to the takeoff location), Land (vehicle descends in altitude until it lands), and Load/Modify new flight plan missions. These actions were commanded while monitoring the health and position status of the vehicle and making standard callouts (e.g., “proceeding to waypoint 5”). Using onboard automated systems, the GCSO could also take actions to perform automated detect-and-avoid maneuvers and execute emergency or contingency landings (see Automated Systems section below).
Remote Operations for Autonomous Missions (ROAM) UAS Operations Center and GCSO Workstation
The study was conducted in the ROAM UAS Operations Center located at NASA Langley Research Center (see Buck et al., 2023). In addition to individual workstations, ROAM is equipped with a large-format video wall at the front of the room (Figure 1). The GCSO workstation was the primary information and interaction location for the GCSO, and consisted of a Dell Precision 7820 Tower, two Dell P2721Q 27” 16:9 4K USB-C Monitors (both portrait presentation), a Dell P2418HT 24” 16:9 10-Point Touch Screen IPS Monitor (tilted at 45° angle), QWERTY keyboard, mouse, phone, and a Tobii Pro Nano eye tracker that was mounted to the touchscreen (Figure 2). The touchscreen was the primary GCSO display and presented the Measuring Performance for Autonomy Teaming with Humans (MPATH) GCS interface (see Politowicz et al., 2023). The GCSOs interacted with MPATH via mouse (note: the touch functionality option was not used by participants). ROAM UAS operations center layout. GCSO workstation layout.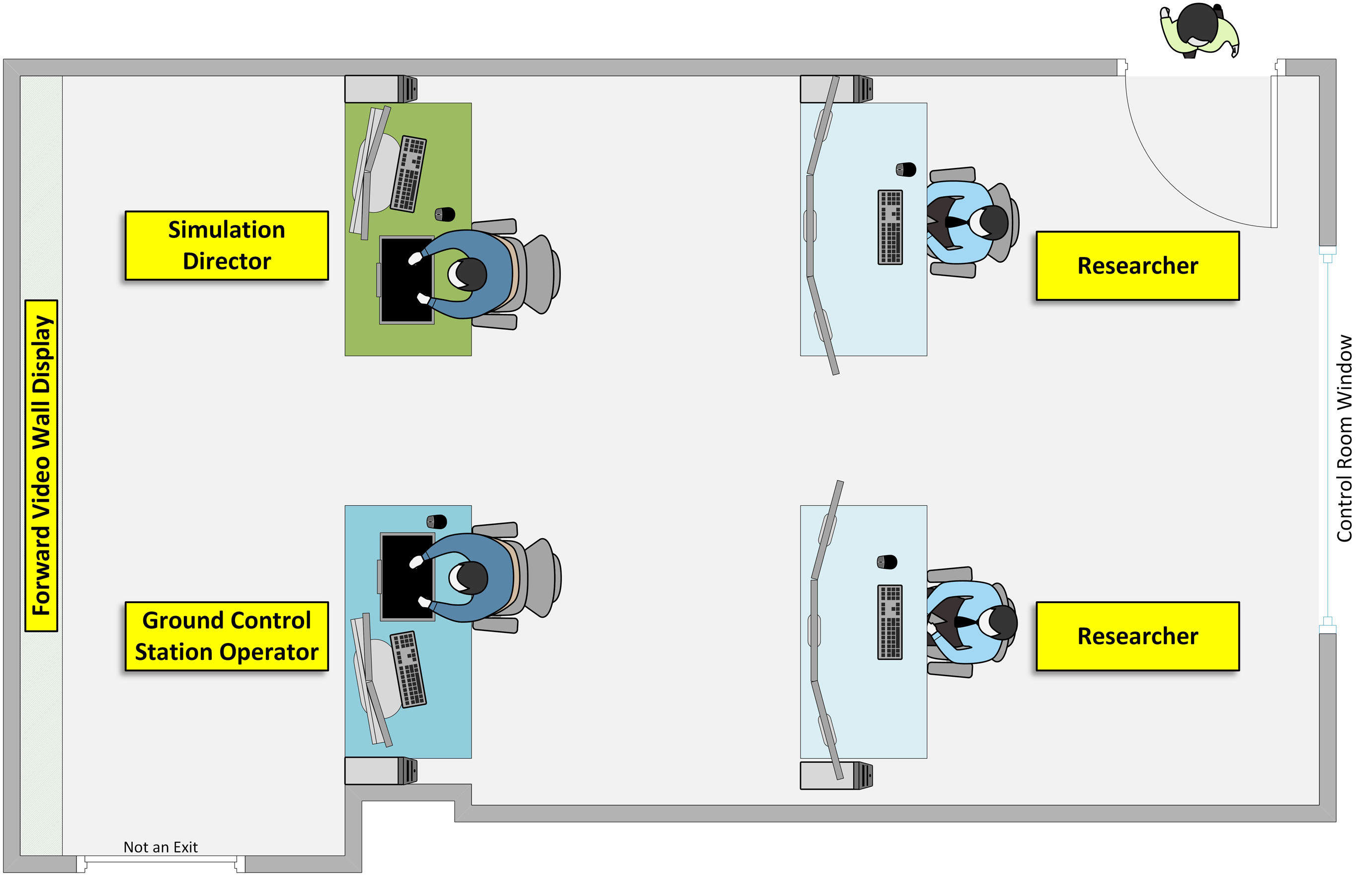
Automated Systems
Two onboard automated systems served as the targets of the human-automation trust questionnaire: Independent Configurable Architecture for Reliable Operations of Unmanned Systems (ICAROUS) and Safe2Ditch. The ICAROUS system is an architecture with a detect-and-avoid capability that enables automated mid-flight reroutes, supporting automated responses to potential traffic incursions and geofence (i.e., pre-established virtual boundaries) breaches (see Consiglio et al., 2016). The Safe2Ditch system is a contingency management tool that contains a pre-loaded (and updatable) set of “ditch site” locations with the position, size, and reliability of each site (see Glaab et al., 2018). During an off-nominal event Safe2Ditch can be activated from MPATH, where Safe2Ditch identifies the location of an appropriate ditch site and then communicates (via ICAROUS) to the autopilot to land the vehicle at the selected ditch site. Although Safe2Ditch was technically integrated with ICAROUS, from a user-perspective the detect-and-avoid and contingency management functions were represented to the participants as independent functions performed by separate automated systems (i.e., ICAROUS and Safe2Ditch, respectively) and each system was represented as two separate user interface elements on the MPATH display. Moreover, participants were not made explicitly aware of the underlying software architecture connecting ICAROUS and Safe2Ditch.
Design
We employed a 2 (System: ICAROUS, Safe2Ditch) × 2 (Time: Pre-Study, Post-Study) within-subjects design, where ICAROUS and Safe2Ditch were the target systems of the trust questionnaires and Pre- versus Post-Study indicated the temporal order of when the trust questionnaires were administered. Trust was the only dependent/outcome variable analyzed in the current study and was measured using the human-automation trust questionnaire reported in Chancey et al. (2017; see online appendix for full questionnaire). The questionnaire is compatible with the Lee and See (2004) theoretical perspective and consists of three factors (five items each) measuring performance-based trust (Performance), process-based trust (Process), and purpose-based trust (Purpose), which has been empirically established using a confirmatory factor analysis approach (Yamani et al., in press). Composite trust was the average of all 15 items. Note that the trust questionnaire for ICAROUS focused on only the collision avoidance functionality and did not reference the geofence avoidance capability. We also included a general trust measure (General Trust), which was a single-item scale for each system (e.g., “I trust Safe2Ditch to safely land my vehicle during an emergency”). The perceived risk of the system (Risk), familiarity of the system (Familiarity), and times flown with the system (Times Flown) were also measured before the study. Risk was measured using a five-item scale developed by Clothier et al. (2015), which targeted both ICAROUS and Safe2Ditch in two separate questionnaires (cf. perceived relational risk outlined by Stuck et al., 2022). Familiarity was measured using a one-item scale that asked participants to rate their familiarity for both ICAROUS and Safe2Ditch with two separate scales (i.e., “How familiar are you with Safe2Ditch/ICAROUS?” 1 = Not at All Familiar, 7 = Extremely Familiar). Times Flown was measured by asking participants to indicate how many times they have used ICAROUS and Safe2Ditch (i.e., “Approximately how many times have you flown a vehicle with Safe2Ditch/ICAROUS on board and engaged [provide a single number]?”: note, these are two separate questions for each target automation). Following the completion of each scenario, participants were given the opportunity to optionally provide any additional comments via open-ended responses on an iPad tablet.
Procedure
We tested participants individually and each session occurred across two business days (approximately 16 hours per participant). Participants received a 1-hour lunch break and three 15-minute breaks each day. Upon arrival, we asked the participant to read and sign an informed consent form, Privacy Act notice, and a demographics and background information form. The participant then completed a series of pre-study questionnaires: Trust (Performance, Process, Purpose, General Trust), Risk, Familiarity, and Times Flown. A 1-hour familiarization session of ROAM, the GCSO workstation, and the study procedures followed these questionnaires. The participant was then asked to act as the GCSO across nine simulated UAS scenarios.
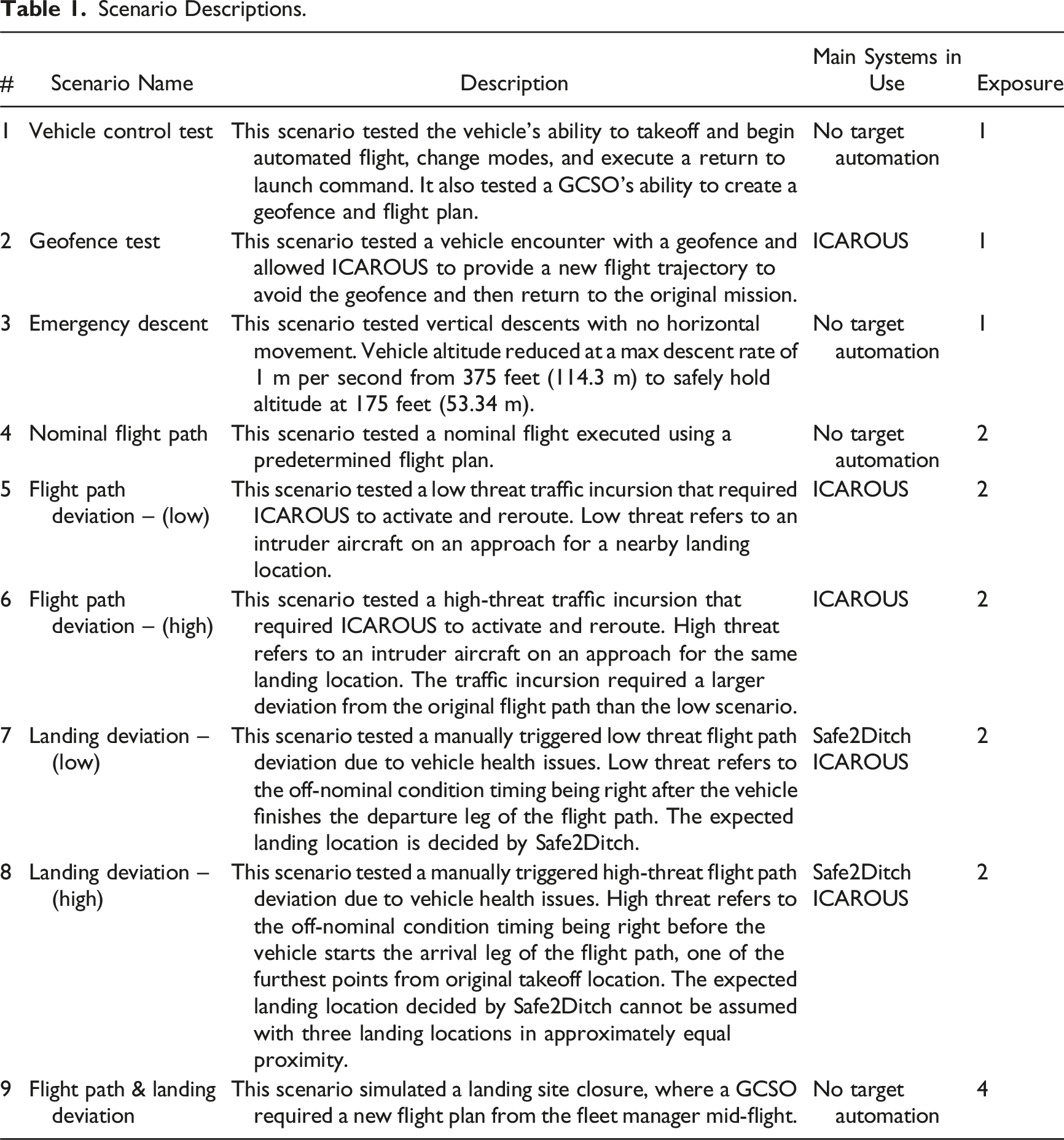
Scenario Descriptions.
Results
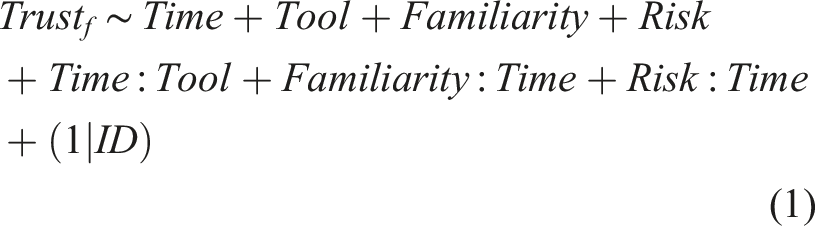
Descriptive Statistics for trust Factors, Familiarity, Times Flown, and Risk Across System and Time.

Note. SD in parentheses. All responses except for Times Flown are on a scale of 1 (low) to 7 (high). Gen. = General Trust, Perf. = Performance-Based Trust, Pro. = Process-Based Trust, Purp. = Purpose-Based Trust, Comp. = Composite Trust, Fam. = Familiarity, TF = Times Flown.
Participant was the only random effect, denoted by (1|ID); all other tested effects were fixed. Mixed-effect modeling allows for explicit modeling of correlated errors that can arise from repeated measures, a better handling of missing or unbalanced data compared to analysis of variance, and extensions to non-normally distributed outcomes if appropriate (Seltman, 2012; Singer, 1998). Familiarity was highly correlated with Times Flown for both systems (ICAROUS, r = .949, p < .001; Safe2Ditch, r = .987, p < .001), indicating these measures were redundant. Therefore, only Familiarity and Risk were included in equation (1).
We treated the trust factor data as continuous rather than ordinal because they are averages of Likert items. Norman (2010) has shown that parametric analysis is robust to skewness and non-normality that may be encountered from this type of data. Additionally, small sample size is not strictly a statistical issue given the robustness (Norman, 2010). However, to address potential issues due to the small sample of six GCSOs, we checked model assumptions and calculated effect sizes (partial η2). We consulted residual plots of the models to check for assumptions of linearity, constant variance, and independent and normally distributed errors.
After applying the full mixed model and checking assumptions, we used a stepwise procedure for variable selection by testing the random effect and the marginal fixed-effect terms until only significant terms remained. Without a random effect for the participant, meaning there is no inherent difference among the participants, the models revert to standard linear regression. The statistical significance threshold (α) was set to p ≤ .01 to compensate for multiple testing (i.e., .05/5 = 0.01; Bonferroni method). We used R Statistical Software to model the data (v4.1.2; https://www.R-project.org/) using the lme4 package (Bates et al., 2015) and the ggplot2 package (Wickham, 2016) to create the plots.
Bayes factors (BF) were also calculated to supplement null-hypothesis significance testing. BFs were approximated using Bayesian Information Criterion (BIC) calculated for models with and without variables of interest. Equation (2) shows the relationship between BF and BIC for a given null and alternative hypothesis, for example, a model of trust based only on Time compared to a model without Time (Wagenmakers, 2007).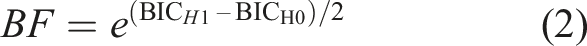
We adopted the terms of Nuijten et al. (2015) to describe each BF, or the strength of evidence supporting a particular model: BF greater than 100 is extreme evidence for the model, BF 30–100 is very strong evidence for the model, BF 10–30 is strong evidence for the model, BF 3–10 is moderate evidence for the model, BF 1–3 is anecdotal evidence for the model, 1 is no evidence for or against the model, and BF less than 1 indicates evidence for the reduced model.
Composite Trust
No predictor or independent variables were found to have statistically significant relationships with composite trust score.
Performance-Based Trust
There was a significant main effect of Time on Performance, F (1, 22) = 12.01, p = .002, partial η2 = .35, where ratings were significantly higher Post-Study (M = 4.72, SD = .93) than Pre-Study (M = 3.10, SD = 1.32; see Figure 3). Confirming this, a BF of 38.08 indicated very strong evidence for the main effect of Time on Performance. Risk and Familiarity did not predict Performance, nor was a significant effect of System on Performance observed. Box-plots for time on performance-based trust.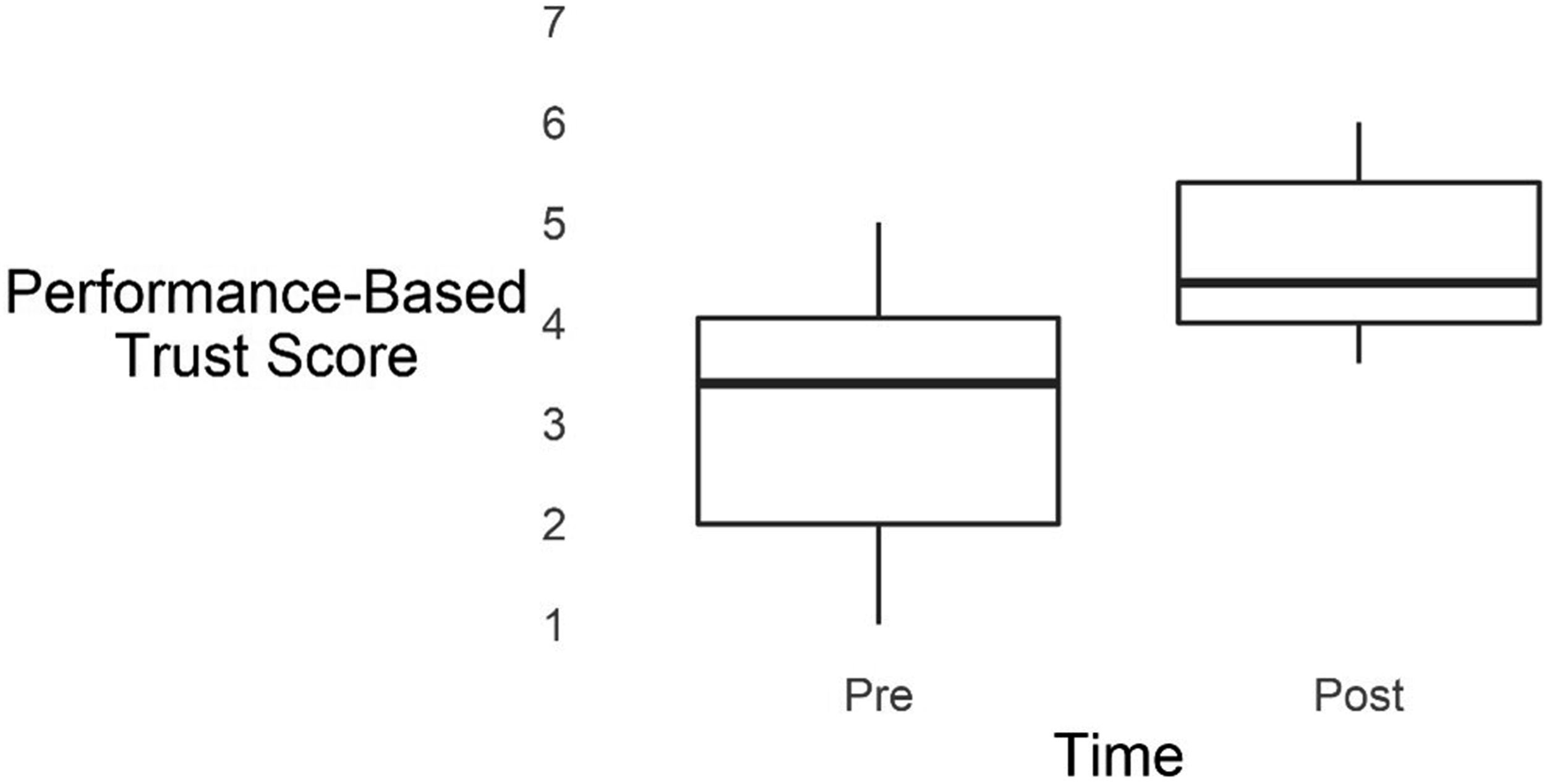
Process-Based Trust
Familiarity significantly predicted Process, F (1, 22) = 33.25, p < .001, partial η2 = .60. Confirming this, a BF of 12,843.44 indicated extreme evidence for the effect of Familiarity on Process. Figure 4 plots the linear relationship between Process and Familiarity with a 95% confidence interval around the regression line. Specifically, an increase in Familiarity rating by one-point leads to an expected increase in Process by 0.62. Risk was not a significant predictor of Process, nor was there a significant effect of System or Time on Process. Positive main effect of familiarity on process-based trust. Note. Linear regression line shown with 95% confidence interval.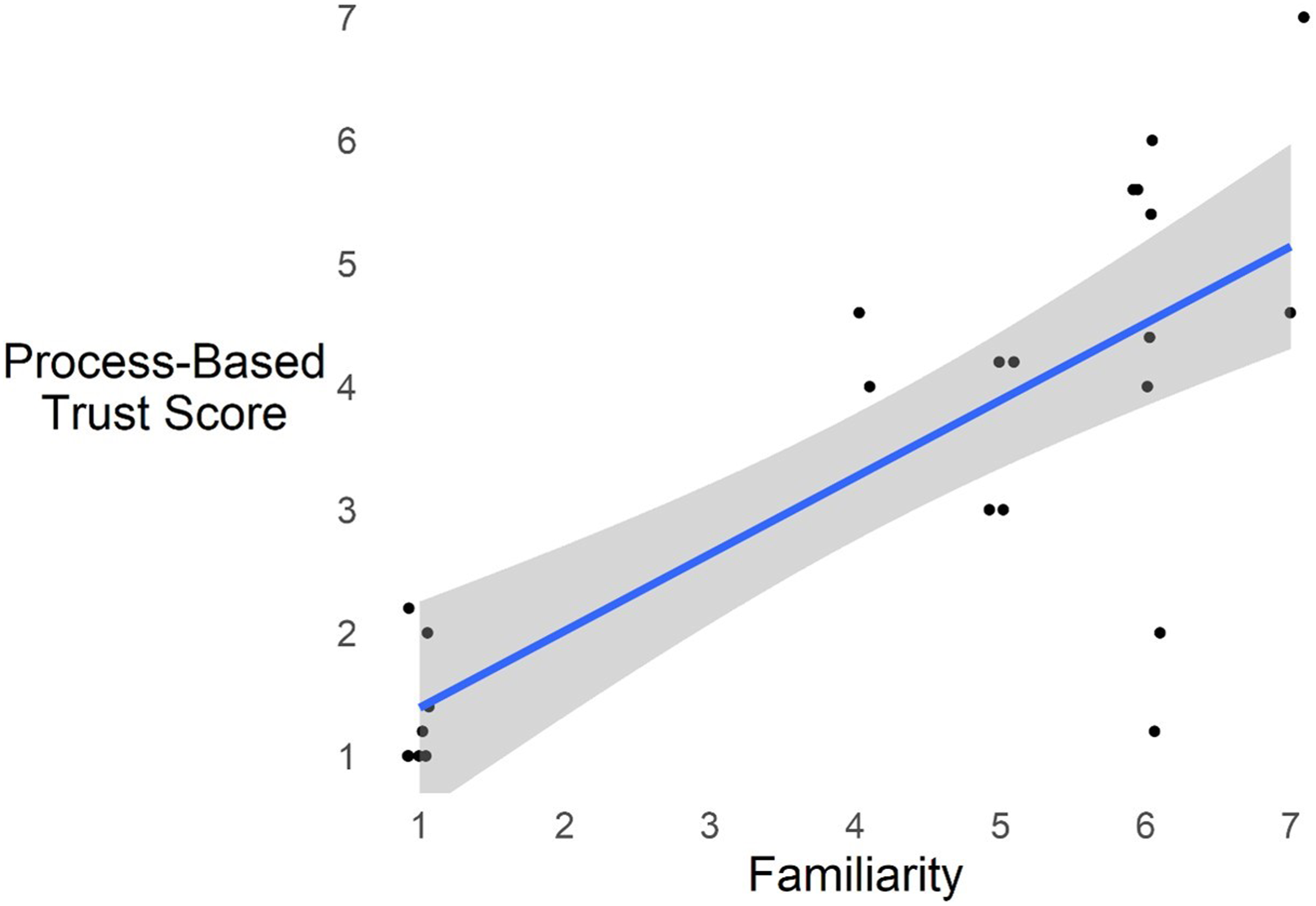
Purpose-Based Trust
There was a significant main effect of Time on Purpose, F (1, 17) = 9.38, p = .01, partial η2 = .36 (BF = 8.58, moderate evidence for this effect). Yet a significant random effect of participant indicated the GCSOs had varying Purpose ratings at the start (BF = 27.28, strong evidence for this effect). Specifically, Purpose ratings started at different points, but that rating increased after the study. Figure 5 shows the Purpose rating changes from Pre-Study to Post-Study across participants. Note that System is differentiated for plotting but are not significantly different. Change in purpose-based trust over time varying by participant.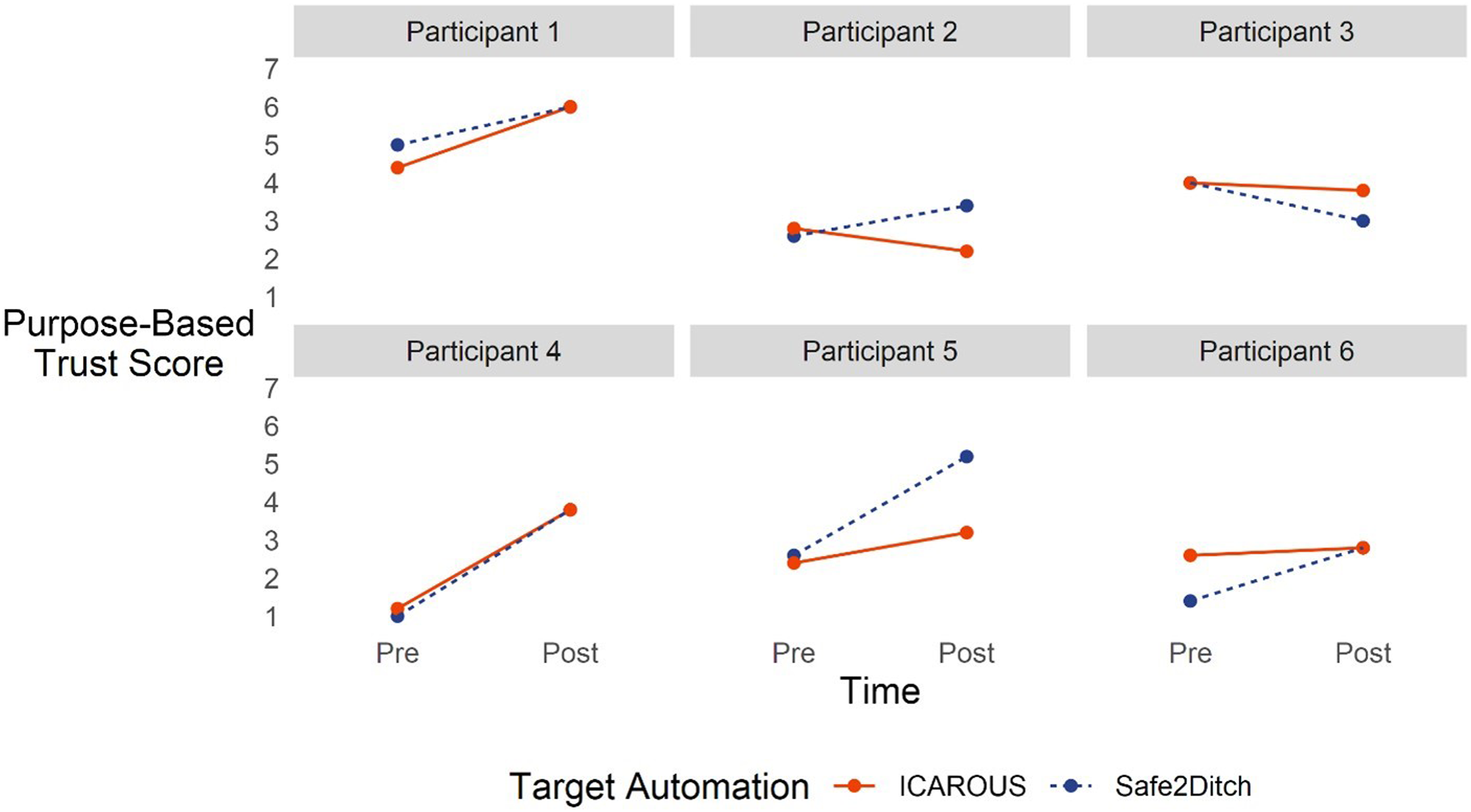
General Trust
A significant interaction between Risk and Time on General Trust was observed, F (1, 19) = 14.30, p = .001, partial η
2
= .43. For participants that gave higher Risk ratings, General Trust ratings before participating in the study were lower and increased after the study. For participants that gave lower Risk ratings, General Trust rating tended to be higher both before and after the study (Figure 6). Confirming this, a BF of 171.24 indicated extreme evidence for the Risk × Time interaction. Additionally, a significant main effect of System on General Trust was also observed, F (1, 19) = 14.30, p = .004, partial η
2
= .37, where trust in ICAROUS (M = 3.50, SD = 1.31) was significantly less than trust in Safe2Ditch (M = 4.33, SD = 1.61). Confirming this, a BF of 49.50 indicated very strong evidence for the main effect of the System on General Trust. Familiarity did not significantly predict General Trust ratings. General trust is impacted by risk differently for pre-study and post-study and differs by system. Note. Shaded bounds represent 95% confidence intervals.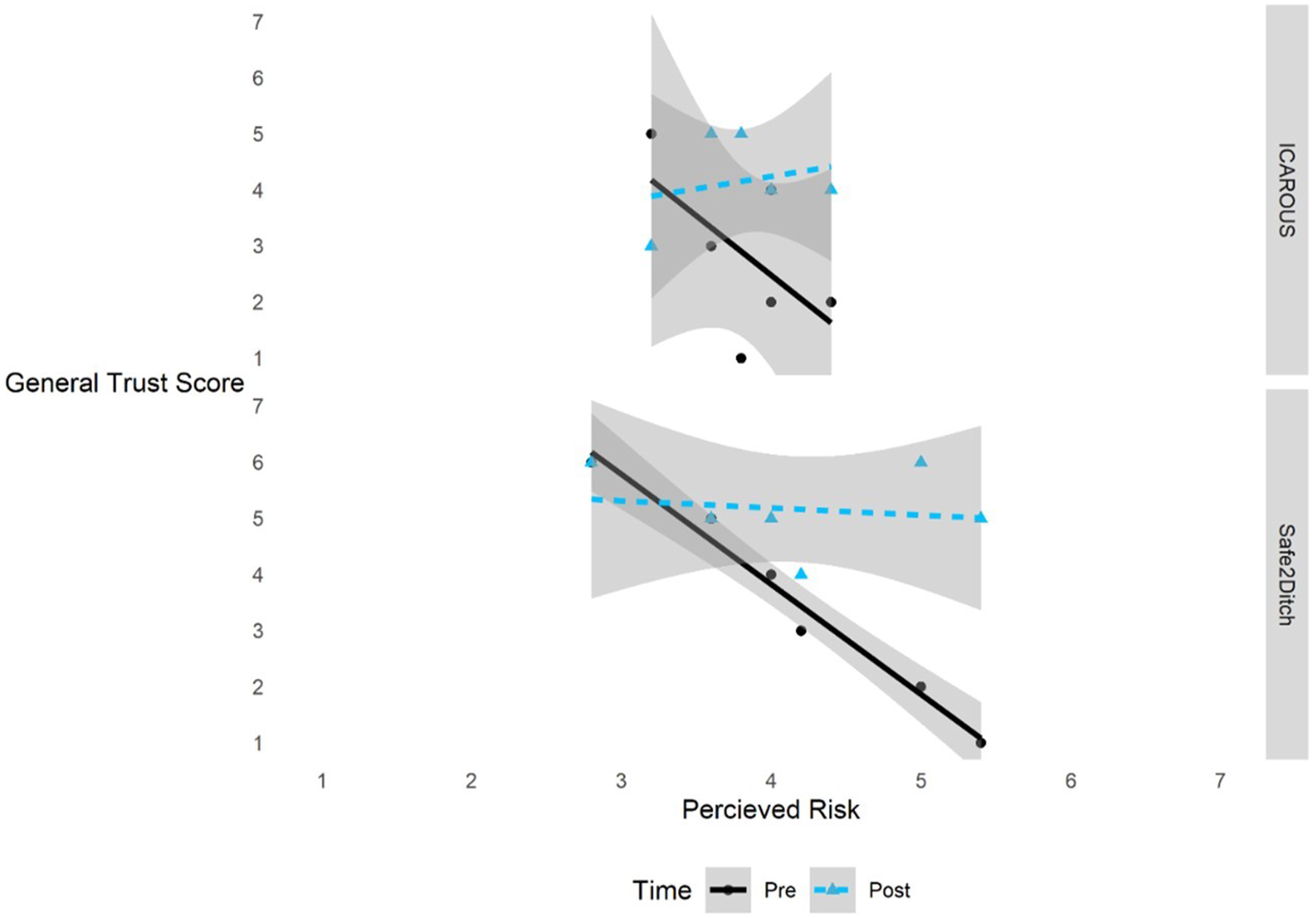
Qualitative Results
Following a similar approach outlined by Carmody et al. (2022; cf. Braun & Clarke, 2006), we conducted a qualitative analysis on the open-ended responses participants provided at the end of each trial to contextualize the quantitative trust ratings. Of the scenarios using the target systems (i.e., scenarios 2, 5, 6, 7, and 8), all participants provided a response following the completion of at least one scenario except for Participant 3. Participant 1 provided a single response after one of these scenarios, yet the response did not relate to either of the target systems: “Time mission start lead me to miss some steps on the test card.” Therefore, qualitative data were generated from Participant 2 (9 responses), Participant 4 (4 responses), Participant 5 (6 responses), and Participant 6 (9 responses). Of the total 28 responses, the average response length was 34.18 words (SD = 26, Min = 6, Max = 107) as counted by the word count functionality in Microsoft Word. Two researchers reviewed the 28 responses, generated codes, and then interactively worked together to compare and consolidate the initial coded data into overarching themes. This resulted in two categories of themes labeled as Operational Themes and Automation Themes.
Operational Themes
Frequency of Participant Responses Related to Operational Themes.

Note. Participant identification number in parentheses (e.g., P6 = Participant 6). Superscript number indicates how many times the participant’s comment was organized into a theme.
Automation Themes
Frequency of Participant Responses Related to Automation Themes.

Note. Participant identification number in parentheses (e.g., P6 = Participant 6). Superscript number indicates how many times the participant’s comment was organized into a theme.
ICAROUS Behaviors
Interestingly, participants commented on the behaviors of only ICAROUS and not Safe2Ditch (i.e., no Safe2Ditch behavior themes were identified). Additionally, there was at least one response for each scenario testing the ICAROUS detect-and-avoid functionality. The ICAROUS Behavior responses were mainly related to the discomfort with the resolution path of the aircraft in proximity to the geofence (e.g., “Was unsure how close [it] would get to the geofence. It appeared as if it may cross fence,” “I was uncomfortable with the track it took trying to acquire the flight path after going around the geofence. It made a wide sweeping right hand turn that almost broke the geofence boundary”) and remarks on the flight characteristics of the vehicle during the resolution (e.g., “ICAROUS appeared to cause the multi-rotor vehicle to behave like a fixed wing vehicle when reengaging waypoint 5/mission path,” “It turned like I would expect a fixed wing plane to. Instead of just stopping and hovering to point back in the correct direction”). Although each of the ICAROUS detect-and-avoid scenarios had at least one behavior-related response, these were mostly for the geofence avoidance scenario (scenario 2). Anecdotally, the proximity of the aircraft to the geofence boundary appeared close, yet never resulted in a breach. This likely contributed to the consistent responses among participants. ICAROUS Behavior responses for scenarios 5 and 6 were related to observations during a single landing sequence and a single delayed ICAROUS message during an incursion. Because the ICAROUS-specific trust questionnaire was focused on the collision avoidance functionality and not the geofence avoidance, it is difficult to know if or how the geofence avoidance responses relate to the trust results.
ICAROUS Transparency
ICAROUS transparency issues were mostly isolated to scenario 6, which was the high-threat traffic incursion that required the system to reroute around an intruder vehicle. The responses were all generally related to wanting more information about how ICAROUS works (e.g., “Need to know the boundaries of ICAROUS during active control”) and how to anticipate behaviors (e.g., “I would want to see the traffic bands to get insight when ICAROUS plans to take action,” “I would like to see a more clear indication that ICAROUS was actively intervening with the flight”). Although some of the responses were similar to the ICAROUS Behavior responses (which also have clear transparency implications), these were categorized as transparency issues because they were focused on wanting some insight (via display or explanation) for what ICAROUS would do (cf. performance-based trust) or how it works (cf. process-based trust) rather than simply reporting on the effects ICAROUS had on the behavior of the aircraft.
Safe2Ditch Transparency
Safe2Ditch transparency issues were noted across both scenarios where the aircraft did not complete the full route and instead Safe2Ditch was triggered, resulting in the aircraft proceeding to a pre-designated “ditch site.” Responses were similar and relatively evenly split across the two scenarios, including four of the six participants. Responses generally referred to being unclear as to which ditch site the aircraft would travel to (e.g., “Desire to see ditch site highlight when S2D [is] active,” “I would like a more definitive representation of what ditch site has been selected when I activated S2D,” “Would request a highlighted area around target ditch site”). Again, these comments were centered around wanting some insight, exclusively via display, for what ditch site it selected rather than comments on the actual aircraft behaviors Safe2Ditch produced.
Discussion
The purpose of this study was to examine factors that affect expert GCSO trust development in increasingly autonomous systems during a high-fidelity remote UAS simulation. Hypotheses were generally supported, which we discuss in turn along with non-hypothesized findings, limitations, and practical takeaways from the study.
Automation Exposure and Performance-Based Trust
Supporting H1, performance-based trust significantly changed (increased) between the pre- and post-study measurements. This is somewhat unsurprising as the major intervention was exposure to the target automated systems, and neither system objectively failed to execute their function. This is consistent with the concept of dynamic learned trust, where observed system reliability more directly impacts performance-based trust (Hoff & Bashir, 2015). Moreover, performance-based trust in ICAROUS did not appear to be negatively impacted by the unusual behaviors displayed when avoiding the geofence. Participant responses indicated that ICAROUS produced behaviors and flight characteristics that were not expected (cf. local explaining activities, Klein et al., 2021). Yet this may be due to the questionnaire targeting the collision avoidance functionality exclusively, rather than also targeting the geofence avoidance functionality specifically. Performance-based trust would have likely dropped from the pre-to the post-study measure if these behaviors were treated as failures of the ICAROUS system as a whole (cf. system-wide trust; Keller & Rice, 2009; Geels-Blair et al., 2013), as negative experiences due to automation failures tend to have a greater influence on trust than positive experiences from automation successes (i.e., negativity bias; Yang, Guo, & Schemanske, 2023). Yet some research suggests a positive correlation between trust and general experience with a target technology (Schaefer et al., 2016) and, counterintuitively, trust can even increase with sustained failures (de Visser et al., 2006). As suggested by Tenhundfeld et al. (2019), this effect could be explained by an increase in understanding of the automation, or familiarity, which may have buffered the effects of a negativity bias.
Automation Familiarity and Trust
Partially supporting H2, familiarity with the systems predicted process-based trust. This is consistent with the concept of initial learned trust, which is based on preexisting knowledge such as understating how a system works (Hoff & Bashir, 2015). These results echo the findings of Tenhundfeld et al.’s (2019) study, which was conducted in a real-world setting. Failing to fully support H2, however, purpose-based trust was not significantly affected by system familiarity, and instead individual differences predicted those ratings.
It is important to note that ICAROUS and Safe2Ditch are research software, which are continuously under development and being used in new ways. ICAROUS is an architecture with a detect-and-avoid capability, yet it is highly configurable to enable modular integration of mission-specific software components (see Consiglio et al., 2016). In a recent study, ICAROUS and Safe2Ditch were tightly integrated (see Duffy et al., 2020) and not functionally isolated for some scenarios as they were in the current study (see Table 1). It makes sense, therefore, that individual differences predicted purpose-based trust ratings, and like performance-based trust, it changed between the pre- and post-study measures as information regarding why the automation was being used in this study was assimilated.
Similarly, automation capabilities in some personal ground vehicles may change based on “over-the-air” software updates. For example, Endsley (2017) noted unanticipated mode interactions and emergent behaviors with a Tesla Model S, where software updates linked the behaviors of previously independent automation modes in certain circumstances. She reported that despite incidences of automation-related issues, her trust in the vehicle automation increased over the period of study, which she attributed to software updates and adapting to what the automation could or could not do. The GCSOs seemed to adapt to why the automation was being used in the current study (i.e., purpose-based trust), and trust improved between measurement times as it was supported by observing stable performance (i.e., performance-based trust) and familiarity with how the automation works (i.e., process-based trust). This is an interesting example for how one dimension of trust (i.e., performance-based) may influence another (i.e., purpose-based) in a high-fidelity simulation with experienced participants. Future research should be conducted to confirm this, however, as we observed only the isolated effects of exposure on two separate dimensions of trust and did not analyze the sequential effects of one base of trust on another.
Perceived Risk and Trust
Although these were simulated operations, we suspected that the professional GCSO participants would feel a level of perceived risk toward the automated systems for two reasons. First, the simulated operations were preparation for a follow-on live flight version, where attention to safety was a critical factor for proceeding to that step. Even though the flights are mostly automated, the GCSO is responsible for safety of flight and is required to takeover for the automation if it fails to function as intended (simulation and live-flight operations). Second, the participants are professional GCSOs hired to perform these types of operations. This study placed participants in a situation where they were asked to display the requisite skills to act as a GCSO, with the associated risk of displaying a failure to meet performance expectations (e.g., failure to takeover for the automation in the event it fails). Supporting H3, participants that rated the systems as being risky before the study tended to also trust the system less, but then rated the systems as more trustworthy after being exposed to the systems. Participants that rated the systems as less risky tended to give higher trust ratings before and after the study. As posited by Stuck et al. (2022), the operator’s subjective trust in the automation was related to their perceived relational risk (i.e., “…belief about the probability and/or feeling that interacting with a specific system…with which a user has a personal history or historical knowledge of, has potential negative outcomes” p. 503). Yet it should be noted that perceived risk of the systems did not predict any of the other theory-based trust factors (Performance, Process, and Purpose) and was isolated to the one-item, atheoretical trust measure. Although this result adds to the empirical evidence highlighting the relationship between automation trust and perceived risk (e.g., Chancey et al., 2017; Lyons & Stokes, 2012; Sato et al., 2020), a more consistent and careful consideration of risk should be pursued in future research (see Stuck et al., 2022, for recommendations).
System-Specific Trust
Though not hypothesized, participants rated Safe2Ditch as more trustworthy than ICAROUS on the single-item measure. Although Safe2Ditch was technically integrated with ICAROUS, we suspected that participants would evaluate each as functionally separate systems. From a user-perspective, ICAROUS and Safe2Ditch are represented as separate user interface elements on the MPATH display, but these systems have not always been integrated or presented as such to GCSOs in previous flight activities. Supporting this, responses for detect-and-avoid scenarios coded to ICAROUS-specific comments and contingency management scenarios coded to Safe2Ditch-specific comments. There was, however, one response that acknowledges the integration of the systems: “I didn’t realize ICAROUS and S2D [Safe2Ditch] were interconnected until this run.” This comment seems to reflect the assimilation of information regarding how ICAROUS and Safe2Ditch were configured for this particular study as the participant was exposed to the automation (see Automation Familiarity and Trust section above). However, we did observe a significant difference in the single-item trust measure between the systems.
The lower trust score for ICAROUS could be because there were more detect-and-avoid scenarios than contingency management scenarios (i.e., there were three ICAROUS-specific scenarios as compared to the two Safe2Ditch-specific scenarios). The effect could also be partially explained by the qualitative results. Participants provided six responses regarding unexpected behaviors ICAROUS produced on the aircraft and five ICAROUS-related transparency issue responses. Safe2Ditch, however, received seven comments concerning transparency issues exclusively. It is possible that the behaviors ICAROUS produced on the aircraft resulted in the lower trust ratings, as both systems had a similar number of transparency issue-related comments. Yet the ICAROUS-specific trust questionnaire targeted the collision avoidance functionality and not the geofence avoidance functionality. Because of this, we are not able to make a clear connection between the geofence avoidance behaviors, which accounted for four of the six responses, and the trust questionnaire results. Interestingly, however, there was not also a significant difference between the two systems on the performance-based trust measure, which might be expected if the geofence avoidance behaviors are driving the difference in the single-item scale (see Automation Exposure and Performance-Based Trust section). Again, this was an effect observed on the single-item trust measure, which does not align with any particular theoretical perspective.
Limitations
This study was not without limitations. First, due to operational constraints, we did not measure trust following individual scenarios using the target automated systems. Moreover, because scenarios were not given in the same order, a trust measure given at the end of the first day would have been difficult to interpret coherently across participants. Because we measured trust at only two points in time (i.e., two “snapshots”), we were unable to investigate the dynamics of trust either building or diminishing during the interactions with the target automated systems (see Yang, Guo, & Schemanske, 2023, for discussion). In controlled laboratory settings, trust in automated systems has been shown to be quite dynamic as participants acclimate to system characteristics (e.g., Bliss et al., 2020; Lee & Moray, 1992, 1994; Yang, Schemanske, & Searle, 2023). As predicted, performance-based trust changed between the pre- and post-study measurement times. Yet without additional measurement points, it is not possible to provide a more nuanced depiction for how trust fluctuated based on interactions with the target automated systems or to what degree trust may or may not have stabilized at the post-study measurement time.
Second, the study lacked behavioral outcome measures. Generally, the purpose for investigating trust (and other predictor variables) is to determine automation use and how that use affects joint human-automation performance (Parasuraman & Riley, 1997). In laboratory settings, it is often easier to experimentally impose event rates that require human intervention, to study the effects of trust on behavior (e.g., Chancey et al., 2015, 2017). For this study, however, the GCSO had minimal performance requirements during scenarios because the automation did not fail. Ecologically, the GCSO as a system monitor will plausibly be one of the favored AAM approaches for pairing humans with increasingly autonomous systems (a task that humans are poorly suited for; Warm et al., 2008). Future research should explore meaningful human control (Smith et al., 2021), scenarios requiring operator intervention in the context of high perceived situational risk (see Stuck et al., 2022), as well as out-of-the-loop unfamiliarity issues (Endsley & Kiris, 1995) that may arise from passive monitoring (Lee & Seppelt, 2012), vigilance (Warm et al., 2008), and complacency and bias in human-automation paradigms (Parasuraman & Manzey, 2010). Designing for the human to be a system monitor is not a new issue, and emerging remote vehicle operations will, unfortunately, likely move toward that “design solution” without input from the human factors community.
Contributions and Practical Takeaways
This study provides one of the more ecologically representative evaluations of human-automation trust in a UAS environment. Results largely confirmed theoretical predictions, such as familiarity and perceived risk were important predictors of trust and exposure to automated systems can impact trust development in even experienced operators that have interacted with a system. Several key practical takeaways can be drawn from the results of this study: • Familiarity with a system, exposure to a system’s behavior, and individual differences of the operator each uniquely and independently contribute to the development of trust in an automated system across the three bases of trust (i.e., performance, process, and purpose). Disregarding any of these factors could lead to inadequate development of at least one of the three bases of trust, which would lead to more brittle overall trust in the automation. The unique effects of these factors can be characterized as follows: (a) Individuals who are more familiar with a system tend to trust it more; (b) Exposure to a reliable system can increase trust in that system; and (c) Individual differences tend to influence trust more before exposure than after. • Trust associated with a specific function/goal within an automated system may continue to increase even as the operator observes unusual behavior from that system while performing a different function/goal. Consideration should be given to ensure appropriate calibration of trust across all of the functions performed by an automated system.
Conclusion
The current study documented factors that affected trust in a high-fidelity remote UAS simulation. Generally, studies investigating constructs such as trust are constrained to tightly controlled laboratory settings (e.g., Chancey et al., 2015, 2017) in which generalizability to the real world can be tenuous if results are not then confirmed to high-fidelity simulations and field studies (i.e., many factors are not controlled for in the real world, see Chancey et al., 2023; see trust theory applied in an operational aviation context elsewhere, Ho et al., 2017, Lyons et al., 2017). The results from this study indicate that human-automation trust develops according to theoretical predictions. Moreover, these results suggest trust may be used to help guide the adoption of increasingly autonomous systems in future AAM applications.
Supplemental Material
Supplemental Material - Human-Automation Trust Development as a Function of Automation Exposure, Familiarity, and Perceived Risk: A High-Fidelity Remotely Operated Aircraft Simulation
Supplemental Material for Human-Automation Trust Development as a Function of Automation Exposure, Familiarity, and Perceived Risk: A High-Fidelity Remotely Operated Aircraft Simulation by Eric T. Chancey, Michael S. Politowicz, Kathryn M. Ballard, James Unverricht, Bill K. Buck, and Steven Geuther in Journal of Cognitive Engineering and Decision Making
Footnotes
Acknowledgement
This work was supported by NASA’s Transformational Tools and Technologies Revolutionary Aviation Mobility Subproject and the Advanced Air Mobility High-Density Vertiplex Subproject. The views expressed are those of the authors and do not necessarily reflect the official policy or position of NASA or the U.S. Government.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was financially supported by 2 NASA projects.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.