
Abstract
Encouraging a certain number of users to participate in a sensing task continuously for collecting high-quality sensing data under a certain budget is a new challenge in the mobile crowdsensing. The users’ historical reputation reflects their past performance in completing sensing tasks, and users with high historical reputation have outstanding performance in historical tasks. Therefore, this study proposes a reputation constraint incentive mechanism algorithm based on the Stackelberg game to solve the abovementioned problem. First, the user’s historical reputation is applied to select some trusted users for collecting high-quality sensing data. Then, the two-stage Stackelberg game is used to analyze the user’s resource contribution level in the sensing task and the optimal incentive mechanism of the server platform. The existence and uniqueness of Stackelberg equilibrium are verified by determining the user’s optimal response strategy. Finally, two conversion methods of the user’s total payoff are proposed to ensure flexible application of the user’s payoff in the mobile crowdsensing network. Simulation experiments show that the historical reputation of selected trusted users is higher than that of randomly selected users, and the server platform and users have good utility.
Keywords
Introduction
Mobile crowdsensing (MCS) network usually includes a cloud-based server platform (SP) and numerous users with smart sensor devices. 1 When the SP publishes a set of sensing tasks, several users will be selected to participate in performing the sensing tasks. MCS is recently used in various fields, such as traffic information, 2 noise pollution, 3 WiFi coverage information, 4 and water pollution. 5 However, the selected users need to spend their time and limited resources (such as energy, internal storage, and CPU computing power) when they perform sensing tasks. Thus, voluntarily participation of users in sensing tasks may be unsustainable. The SP provides users with rewards to compensate for cost in the sensing tasks for encouraging users with smart devices to actively participate in the tasks.
Designing justifiable incentive mechanism is challenging in the MCS network. The collected sensing data’s information amount will be insufficient when the reward given by the SP is less. However, the utility of the SP will reduce and its cost will increase when the SP gives more rewards to users. Therefore, the core problem of the MCS network is designing a rational and valuable incentive mechanism. 6 The existing incentive mechanism can be roughly divided into the platform-centric and user-centered incentive mechanisms.7,8 The platform-centric incentive mechanism is designed to improve the information increment of the SP and reduce the reward to users. 9 The user-centered incentive mechanism mainly increases the motivation of users to participate in sensing tasks and encourages users to collect sensing data initiatively. 10 Therefore, this study designs an incentive mechanism that considers the SP and the users. In this mechanism, the SP receives high-quality sensing data while the users acquire considerable payoff.
The users can randomly submit sensing data to obtain more rewards at the lowest cost in the MCS network system. 11 However, dishonest users may deliberately send some false sensing data to mislead the network system, and this event causes inaccuracy of the sensing task’s result. Therefore, the reputation of the users is a crucial parameter in the MCS system. 12 The users need to spend time and limited resources of the sensors device to complete the sensing task. Thus, no rational users will upload the sensing data actively if the reward given by the SP is less than the cost that the users use in collecting sensing data.
The reputation constraint incentive mechanism algorithm (RCIMA) is proposed. This study aims to design an incentive mechanism for maximizing the utility of the users and SP, and the users with high reputation will be encouraged to participate and collect high-quality sensing data in the sensing task. The primary contributions of this study are summarized as follows:
A resource contribution game algorithm (RCGA) based on Stackelberg game theory is proposed. The SP and users choose their optimal strategies to maximize their utility, and the existence of the Nash equilibrium point is proven in the Stackelberg game.
A reputation update method for the users is proposed. After the users upload the sensing data, the expectation–maximization (EM) algorithm is applied to evaluate the quality of sensing data collected by the users, and the SP updates the historical reputation of the users participating in the sensing task.
Two methods of reward conversion are proposed to select reward application for the users. The first method uses the user’s total payoff as the total reward when he needs to publish tasks in the MCS. The second method converts the user’s total payoff into real currency. Thus, the payoff of users will be more flexible circulation in the MCS.
The rest of the article is organized as follows. Section “Related works” presents various incentive mechanisms proposed in recent years. The MCS system model is introduced in section “System model.” Section “Details of RCIMA” describes RCIMA, which has four parts: selecting trusted users, RCGA, updating the reputation of each user, and incentive allocation. Section “Simulation results and analysis” presents the performance evaluation. The conclusion is presented in section “Conclusion.”
Related works
In recent years, incentive mechanisms have become a research hotspot in the field of MCS. 7 Several researchers have applied distinct game models to design incentive mechanisms in the MCS system.13,14 The auction model is a universal mathematical method for designing incentive mechanisms. Good auction model needs to satisfy individually rational, incentive-compatible, feasible budget. 15 A long-term dynamic quality incentive mechanism is proposed to capture the dynamic nature of users’ data quality in Wang et al. 16 The incentive mechanisms based on the auction model are studied considering privacy protection and social cost minimization in Lin et al. 17 The SP selects users using a predefined scoring function, and the computational efficiency, individual rationality, and truth and differential privacy of the algorithm can be guaranteed. The incentive mechanism based on Sybil-proof auction is studied to prevent Sybil attacks in Lin et al. 18 A reverse auction-based incentive mechanism (RAIN) is proposed in Ji et al., 19 which considers participants’ potential contributions when recruiting new workers. An online auction algorithm is studied combining multi-attribute auction and reverse auction to dynamically select users in Wang et al. 15
Different game models have distinct goals for designing the incentive mechanism in addition to the auction model. Some scholars design incentive mechanisms based on Stackelberg game in MCS. The incentive mechanism considering the social network effect based on Stackelberg game theory is applied to analyze the relationship between users and service providers in Nie et al. 1 Stackelberg game theory is applied to design the incentive mechanism with user resource requirements as parameters, and the dynamic incentive mechanism based on the deep reinforcement learning method is studied without learning the user’s private information in Zhan et al. 20 A delay-sensitive MCS network technology is designed based on the Stackelberg game in Cheung et al. 21 A three-stage Stackelberg game is proposed in the continuous time-varying scene of the MCS incentive mechanism in Li et al. 22
Most of the traditional incentive mechanisms only consider the utility of the SP and users. However, other factors also affect the sensing task results, such as interests and history reputation of the users. The reliability of the collected sensing data in the MCS system is also a concern. 23 According to reports, users can submit some random sensing data to obtain more payoffs when performing the sensing task at the minimum cost. 11 Moreover, users with low reputation may upload some false sensing data to affect the result of the sensing task. 12 Therefore, the SP should select trusted users to collect sensing data. The MCS system considers the contribution quality and reputation level of the user in the social network to obtain the reputation level of each user in Amintoosi and Kanhere. 24 The author uses the Gompertz function to evaluate the contributions of participating devices, and the reputation system calculates the new reputation based on the location and time of the users in Huang et al. 25 However, the incentive mechanism, which is the core of the MCS network system, is ignored in Amintoosi and Kanhere 24 and Huang et al. 25 The historical reputation of a user reflects its previous behavior, 26 which is used as parameter for selecting the users to minimize the threat from dishonest users. Therefore, the historical reputation of users is combined to design the algorithm in our incentive mechanism.
In addition, scholars have also proposed some multi-attribute incentive mechanisms. A hybrid incentive mechanism based on blockchain technology is proposed, and this mechanism integrates data quality, reputation, and money factors to encourage users to collect sensing data while preventing malicious behavior in Wei et al. 27 However, the application problem of the reward obtained by the users when they perform the sensing task is always ignored in the MCS system. The users obtain the reward accordingly after performing a sensing task. The reward application of the users can enhance the flexibility of the MCS system.
On the basis of the abovementioned analysis, this study designs an RCIMA incentive mechanism based on the Stackelberg game in the MCS network. The SP selects trusted users to ensure the quality of the collected sensing data. Then, the Stackelberg game is employed to analyze the balance problem of the SP and the users. The EM algorithm is also utilized to evaluate the quality of the collected sensing data by users, and the SP updates the reputation of each user. Finally, two conversion methods of users’ total reward are proposed.
System model
The MCS network is mainly composed of the task publisher (TP), the SP, and the users. As shown in Figure 1, the execution process of the sensing task is as follows. First, the TP publishes the sensing task information and total reward R to the SP. The SP broadcasts the sensing task information to users equipped with the smart sensor device. The users interested in the task sign up for the sensing task, and the users’ set is U = {u1, u2, …, un}. Then, the SP selects some trusted users to participate in the task, and the selected users choose the optimal strategy to perform the sensing task. After the users complete the sensing task, they upload the sensing data to the SP. Finally, the SP updates the reputation of each user; the users are allocated reward in the sensing task. Besides, each user chooses a conversion method of reward to deal with the obtained reward.

System model of crowdsensing.
The detailed process is presented as follows:
TP published a sensing task and total reward R to SP;
If the users with a mobile smart device sensor are interested in the sensing task, then they will sign up to participate in the sensing task. The users’ set is U = {u1, u2, …, un};
SP uses users’ historical reputation to select the trusted users W = {w1, w2, …, wm} (m ≤ n);
The SP and the users choose their optimal strategies by RCGA. The users will perform the sensing task and submit data to the SP when user selects the optimal strategy and utility of user is greater than zero;
SP evaluates the quality of the sensing data, and the SP updates the reputation of users;
The users receive the reward allocated by SP, and users select a method to convert virtual currency.
The relationship between the SP and the users is constructed as a Stackelberg game model. The selected users’ set is W = {w1, w2, …, wm}, and each user wi∈W selects its resource contribution level Xi, where Xi ≥ 0. The user wi chooses an optimal strategy Xi* according to the total reward R provided by the SP in the sensing task. The resource contribution level strategy set of users is X = (X1, …, Xm), and X− i = (X1, …, X i − 1, Xi + 1, …, Xm) represents the strategy excluding wi. The resource contribution level Xi of user wi is defined as follows.
Definition 1
The resource contribution level Xi is determined by the resource contribution coefficient βi of the user wi and the energy consumption ratio Ei.’. That is

Definition 2
The energy consumption ratio Ei’ is the ratio of the consumed energy of the user wi in transmitting the sensing data to the SP and the remaining energy

where

where k*Eelect represents the energy consumed when sending and receiving k bit sensing data. d0 is the distance threshold equal to 87 m. εfs and εamp represent the amplifier power consumption of the free-space and multipath attenuation models, respectively. The free-space model is employed when the distance between the user and the SP is less than d0, and the transmission power is attenuated to d2. Otherwise, the multipath attenuation model is used, and the transmission power is designated as d4.
The utility function of the user wi is defined as

The utility of user wi is composed of two parts. The first part is the user’s payoff, which is determined by the resource contribution level Xi. The second part is the user’s cost function, which is the cost spent by the user in performing the sensing task, and αi is the unit cost of the user wi.
The resource contribution level of the users in performing sensing task is converted into the SP’s payoff function φ(To). The SP’s utility is the payoff subtracted by the total reward R, that is
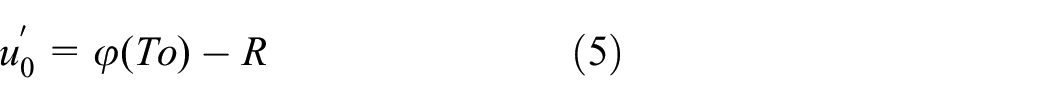
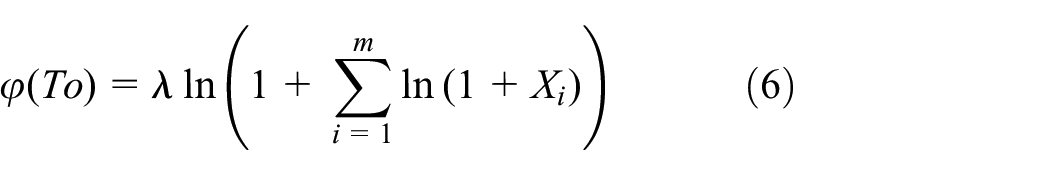
The function φ(·) is utilized to convert the user’s resource contribution level into the SP’s payoff, which reflects the law of diminishing payoff. The payoff of the SP increases with the resource contribution level of the user. However, the marginal payoff decreases. λ is a system parameter, which represents the equivalent monetary value of contributed resource by users.
The game theory model is employed to construct the relationship between the SP and the users as a non-cooperative game. 29 The strategy of the user wi is to determine the resource contribution level Xi, and the strategy of the SP is to determine the total reward R to maximize their utility. The Stackelberg game can solve the benefit conflict between the SP and the users and find their optimal strategy.29,30 Therefore, a two-stage Stackelberg game is applied to solve the incentive allocation problem of the relationship between the SP and the users.
Definition 3
Two-stage Stackelberg game
The first stage of leader game (SP). The SP determines the total reward R to obtain more utility, that is

The second stage of follower game (users). Each user chooses his strategy according to the total reward R by the SP and the resource contribution level of other users, and the purpose is to ensure that his utility reaches the maximum, that is

The second stage is regarded as a non-cooperative game and is called RCGA. This study analyzes the Nash equilibrium of the Stackelberg game, as discussed in section “Analysis of RCGA.”
Details of RCIMA
Publishing sensing task and selecting users collect sensing data
The sensing task is published by the TP, and the TP uploads task information (such as name, function, number of users m, and total reward R) to the SP. The SP broadcasts the sensing information to the users, and the users U = {u1, u2, …, un} with smart devices sign up for the sensing task. The SP selects m users with the highest historical reputation in the n registered users to ensure the quality of the collected data. The user will be deleted when the user’s initial energy cannot complete the sensing task. Finally, the selected users’ set is W = {w1, w2, …, wm} (m ≤ n). Furthermore, the selected users choose the optimal response strategy based on RCGA to decide whether to continue to participate in the sensing task and to collect sensing data.
Analysis of RCGA
The relationship between the SP and the users is modeled as the Stackelberg game. The SP is the leader, and its strategy is to announce the total reward R of the sensing task. The users are the followers, and their strategy is to choose the resource contribution level. Each user looks for his optimal response strategy by the SP’s strategy, and the SP further adjusts its strategy to maximize its utility. Each user is rational in performing the sensing task. Thus, the user uploads the sensing data when the utility is greater than zero. If the utility obtained by the users is less than zeros, then no users will participate in the sensing task.
Follower game
Once the users participate in the sensing task, the total reward R given by the SP will be allocated to users according to the weight of each user’s resource contribution level. The utility of user wi by equation (4) is
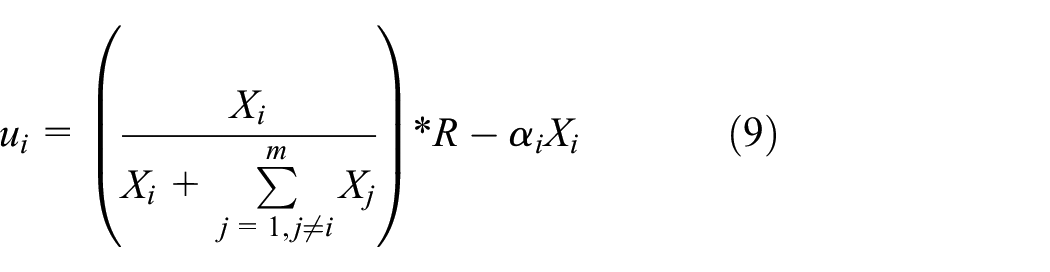
When all users choose the optimal strategy, a steady state will be achieved in the RCGA. As a result, all participants cannot change the strategy to obtain more utility, which is the Nash equilibrium in non-cooperative games. 31 The following defines the Nash equilibrium and optimal response strategy in RCGA.
Definition 4
Optimal response strategy
Given X − i, a strategy Xi ≥ 0 is the optimal response strategy if it is maximized ui (Xi, X − i), which is denoted by Xi*.
Definition 5
Nash equilibrium
X * = (Xi*, X − i*) is the Nash equilibrium in the RCGA when each user wi satisfies ui (Xi*, X − i*) ≥ui (Xi, X − i), where Xi ≥ 0.
Theorem 1
A unique Nash equilibrium point exists in the follower game when the SP provides the total reward R to users in the RCGA.
Proof
To study the optimal strategy to maximize the utility of the user wi, the first and second derivatives of the utility function ui about its resource contribution level strategy Xi are calculated by equation (9)

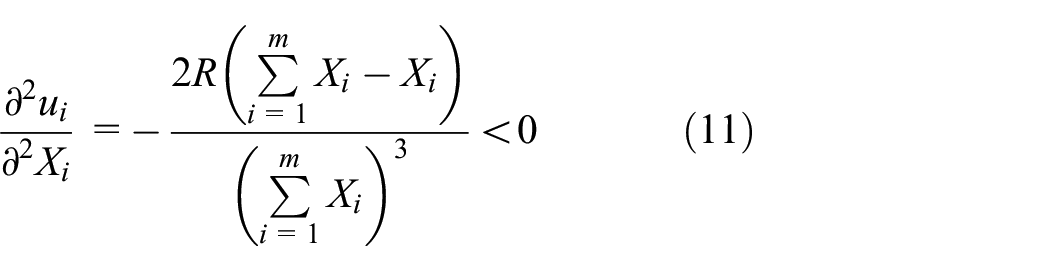
The utility function is strictly concave with respect to the strategy of the user wi because the second derivative is negative. The SP provides the total reward R > 0 and other users’ strategy X − i. If an optimal strategy Xi* exists, then the optimal response strategy of user wi is unique.
The first derivative is set to zero using equation (10)

Once the user wi uploads the sensing data, user wi is the winner and Xi > 0; otherwise, Xi = 0. The selected users are defined as W. The set of winners is defined as

By summing all the elements of

By solving

Substituting equation (15) into equation (13) yields

The strategy Xi* is the optimal strategy for the user wi when Xi* is positive in equation (16). If Xi* is negative, then the user wi does not participate in the sensing task. Therefore, the optimal strategy for user wi is

Theorem 2
Given the total reward R > 0, if the optimal strategy set of all users X∗= (X1∗, X2∗, …, Xm∗) is the unique Nash equilibrium of RCGA, then the following conditions are met.
if
Sort the user’s costs in a non-decreasing sequence such that α1 ≤ α2 ≤···≤ αm, and set h as the largest integer of
Condition (a) is proven as follows. If
We also prove Condition (b). The user wi participates in the sensing task when
Condition (c) is proven as follows. When

In addition, the following conclusions are drawn

We suppose

Therefore, the user wk can improve the utility by unilaterally changing the strategy to Xk > 0, which contradicts the Nash equilibrium.
Condition (d) is proven as follows. The costs α1, α2, ···, αm of the m users are sorted in a non-decreasing sequence. From Conditions (a) and (c), an integer k in [2, m] exists such that W = {1, 2, …, k}. k ≤ h given that h is the maximum positive integer that satisfies

Therefore, user k + 1 can obtain more utility by increasing the resource contribution level of the sensing task, and this condition contradicts the Nash equilibrium.
In Algorithm 1, the SP first initializes the set of users

RCGA: resource contribution game algorithm.
The time complexity of Algorithm 1 is O(nlogn). The time required for all users to sort is O(nlogn), while the time required for while loop (6–8 lines) and for loop (9–12 lines, 14–17 lines) is O(n).
Leader game
The SP and the users are participants in the RCGA, and the SP is the leader and the users are the followers. All users have a unique Nash equilibrium point when the SP provides the users with the total reward R. Therefore, the SP can determine the value of R to maximize its utility.
Theorem 3
An optimal strategy R∗ exists in the RCGA and constitutes a unique Stackelberg equilibrium point (R∗, X∗), where X∗ is the optimal strategy set for all users. The utility of the SP is the maximum when the total reward is R∗.
Proof
By substituting equation (15) into equation (13), we obtain

Substituting equation (22) into the utility function of the SP yields
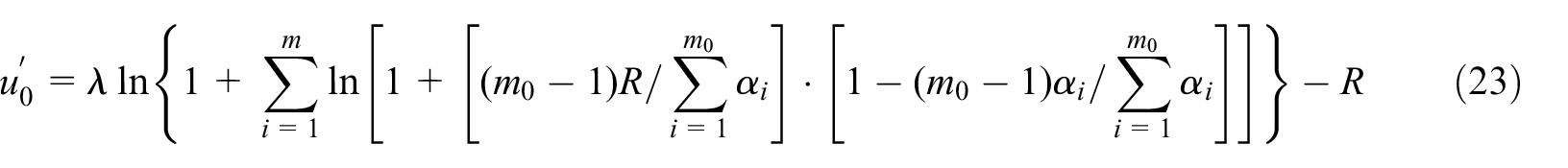
The second derivative of the SP utility function is determined

where
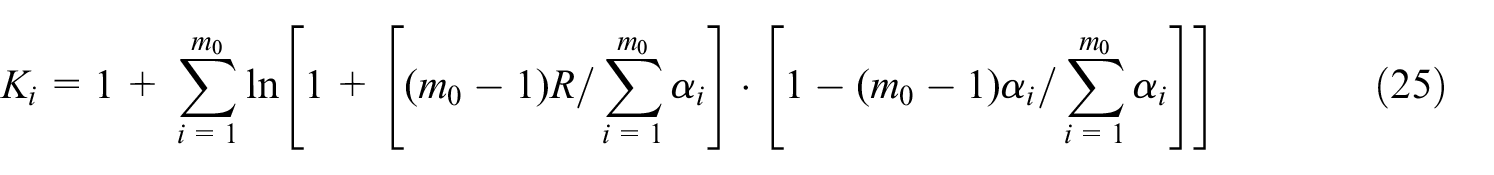

Therefore, the utility function of the SP in the RCGA is strictly concave as obtained by equation (24), and there is only Stackelberg equilibrium in the RCGA. A unique R∗ exists such that the SP’s utility function u 0 ’(R, X∗) reaches the maximum under the condition of (R∗, X∗). The unique R∗ is calculated by utilizing the Newton method. 32
Evaluating reputation
After the users upload the sensing data, the SP will evaluate the reputation of the selected users. First, the EM algorithm 33 is employed to evaluate the quality of the upload sensing data by the users. Then, the SP evaluates the selected users’ reputation based on the sensing data quality result. Finally, the user’s historical reputation is updated after the user’s reputation is evaluated.
Quality evaluation
The quality of the submitted sensing data by the users reflects the quality of the sensing task they completed. Here, the user wi collects urban noise sensing as an example in Peng et al.,
34
and each user wi estimates the quality evaluation matrix

To find the maximum likelihood estimate of

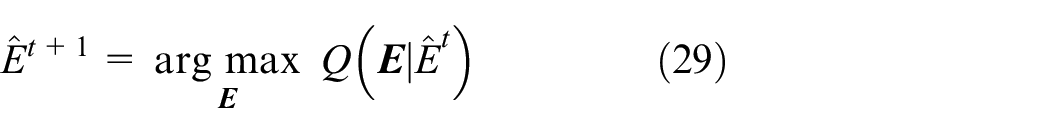
The specific steps are given as follows:
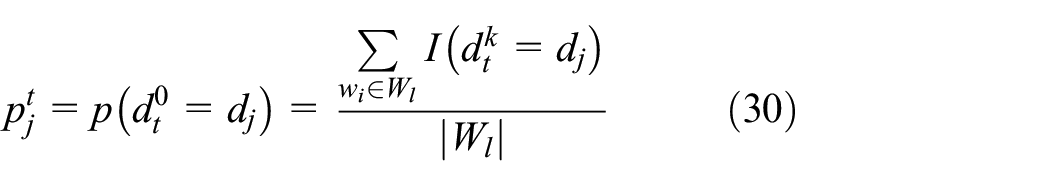

The real noise interval distribution is estimated as



Updating reputation
Through the abovementioned quality evaluation process, the quality of the collected sensing data of user wi is qwi. Then, the reputation value of user wi will be normalized and converted to [0,5]. Thus, the reputation value of the user wi is

where qmax is the highest data quality value in the sensing task. The user’s historical reputation is updated as

where o is the number of historical tasks in which user wi participates, and Repi0 is the historical reputation value of user wi.
Reward distribution
The reward provided by the SP to user wi is expressed as Rei, and the user wi chooses the optimal resource contribution level Xi through the RCGA. Thus, the final reward is

The total payoff ReTi of the user wi is the reward for performing one task or several tasks in the MCS network system. When the total payoff ReTi is greater than a certain threshold Vmin, the virtual currency (ReTi) is converted and applied to the following two methods.
In the first method, the user wi regards the virtual currency of total payoff ReTi as the reward for publishing sensing task. The total reward R is also distinct when the user wi publishes different sensing tasks. However, when the total payoff of user wi must not be less than the reward R required for publishing a sensing task, he can successfully publish the sensing task. When the user wi’s total payoff is insufficient as a reward in publishing the sensing task, he will convert real currency (do) into virtual currency (Vp) to publish the sensing task by equation (38). Then, user wi will publish the sensing task that he needs

In the second method, the total payoff ReTi of user wi directly converts virtual currency into real currency. The SP will convert virtual currency into real currency successfully when the total payoff of user wi is greater than the threshold Vmin, which is

where Vp > Vmin, Vp and do are virtual currency and real currency, respectively. c and c’ are system parameters determined by the MCS network system, and c’ is slightly larger than c. Therefore, if the user wi needs to publish a sensing task, then he will be more willing to convert virtual currency into the total reward of the sensing task.
Simulation results and analysis
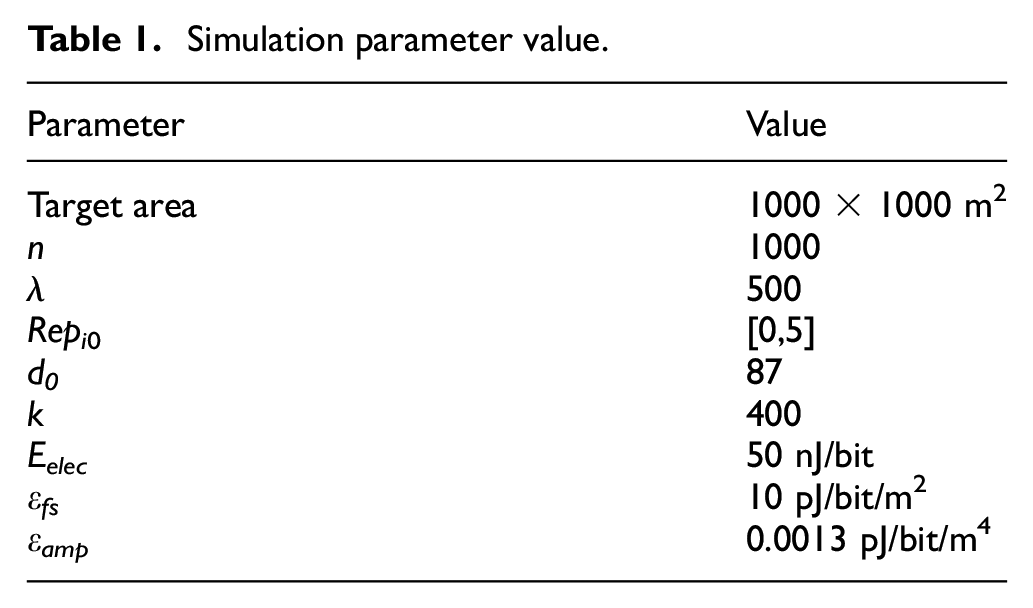
Simulation experiments are conducted with MATLAB R2016a and the following network topology is established to evaluate the performance of RCIMA. One TP, One SP, and 1000 users are randomly distributed in the target area with the range of 1 × 1 km2, and the TP can be successfully published tasks to the SP. The parameters and experimental values in this study are shown in Table 1.
Simulation parameter value.
Average payoff of users
Figure 2 shows the relationship between average payoff obtained by the users and the total reward R given by the SP in RCGA. The reward given by the SP to the user is the user’s payoff when the user completes the sensing task. The users’ payoff is related to the total reward R of the SP and the users’ optimal resource contribution level. As shown in Figure 2, the average payoff of the users will be more when the number of selected users is less. The average payoff increases with the R when the number of selected users is fixed. Therefore, it is more beneficial to users that the number of selected users is small when the SP provides a fixed total reward. It is more favorable for the users when the greater the total reward given by SP given the number of users.
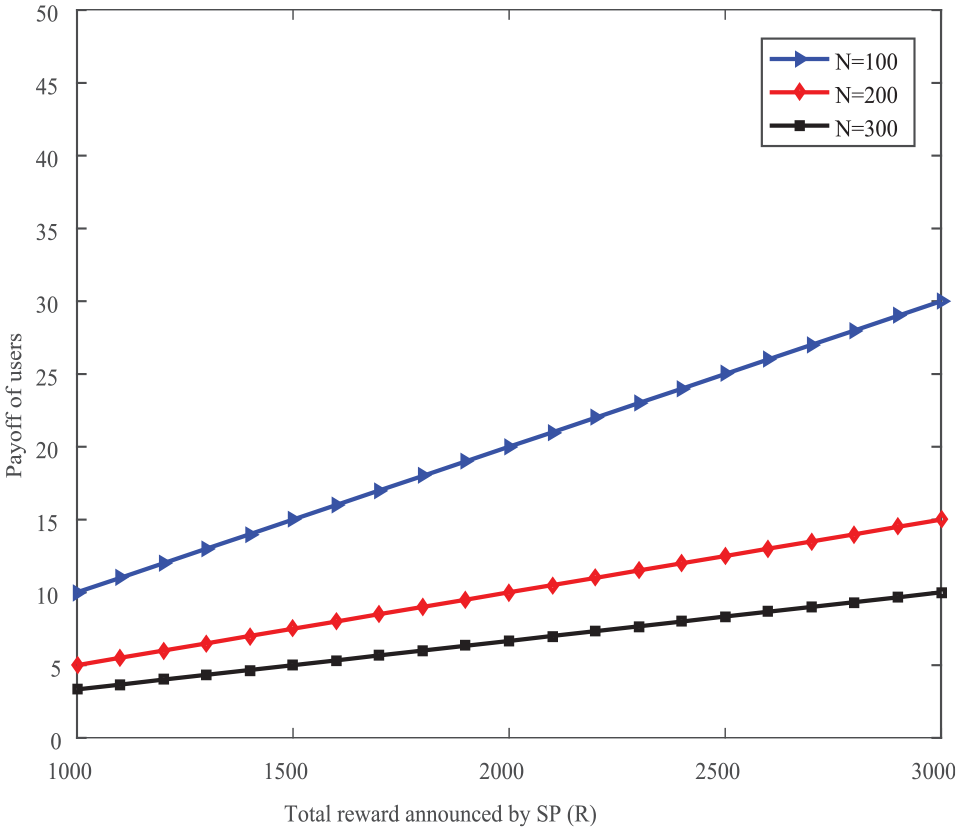
Changes in the average payoff of users with R.
Average utility of users
Figure 3 shows the relationship between the average utility of users and the total reward R given by the SP in the algorithm. The utility of the user is the payoff subtracted by the cost when user complete the sensing task. In Figure 3, the average utility of users increases with the total reward R. Moreover, the total reward R is linearly related to the average utility of users. Under the condition of R, as the number of users selected increase, the average utility of the users reduce. Because the number of users goes up, the weight of each user’s optimal strategy goes down. Thus, the payoff of each user will be less, and the user’s utility will be reduced correspondingly.

Changes in the average utility of users with R.
Utility of the SP
Figure 4 shows the relationship between the utility of SP and the total reward R paid by SP to users. The utility of SP is related to the resource contribution level Xi of the users and the total reward R of SP. The experimental result shows the utility of SP decreases as the total reward R increases. The resource contribution level of the users is fixed when the number of selected users is constant. Thus, the utility of the SP is less when the total reward R increases. Given a certain total reward R, SP will obtain more utility when the number of users is more.

Relationship between the utility of the SP and R.
Resource contribution coefficient βi of the user
Figure 5 shows the relationship between the resource contribution coefficient βi of the user wi and the total reward R of the SP. The resource contribution coefficient βi of the user wi is related to the resource contribution level Xi and the user’s energy ratio Ei’. The experimental results show that the smaller the number of users, the larger βi the user has. And the resource contribution coefficient βi of the user is unsteadiness. The reason is the smaller the number of users, each user has the more reward when R is fixed. Thus, the weight of the user’s optimal strategy will increase. βi will not change significantly with the increasing of R because the optimal strategy of the user is different when R is distinct.

Relationship between the resource contribution coefficient βi and R.
Reputation evaluation
Figure 6 analyzes the relationship between the user wi’s reputation and the quality evaluation matrix eii of user wi in collecting sensing data. The quality evaluation matrix eii of the user in submitting the sensing data approximately follows the same normal distribution, 34 where μ = 0.75 and σ = 0.125. Figure 5 shows a linear relationship between the quality evaluation matrix and reputation. When the quality evaluation matrix eii of user wi in submitting the sensing data is smaller, the user wi’s reputation is correspondingly lower in the sensing task. However, if the quality evaluation matrix of the user wi’s is larger in the sensing task, then the reputation of the user wi will be higher.

Relationship between the quality evaluation matrix of sensing data and the user’s reputation.
Analyzing the reputation value of selected users
Table 2 analyzes the comparison of different historical reputation values between randomly selected users and selected trusted users. First, the SP chooses trusted users who have higher average historical reputation value than randomly selected users. Then, the average historical reputation value of users has a small difference when randomly selecting users. However, when selecting trusted users, the average historical reputation value of users is high if the number of selected users is small.
Average historical reputation values of selected users.

Conclusion
In this study, an incentive mechanism (RCIMA) is proposed on the basis of the Stackelberg game that considers the benefit of the SP and users for MCS. The overall mechanism includes choosing trusted users, RCGA, and reputation update and reward distribution method. The credibility of the collected sensing data has an obvious improvement because the users are selected by the reputation. Compared with the random selected users, the proposed model in this article has higher average historical reputation value. The utility of SC and MUs in the proposed method is good in the RCGA. Meanwhile, two conversion methods between virtual currency and real currency are used to ensure flexible application of the users’ total payoff in the MCS system. However, this article does not consider the user selection task problem when multiple tasks are released. Therefore, the incentive mechanism considering multiple TPs will be investigated in future work. Moreover, the submission of sensing data by users will be studied to prevent the leakage of private information.
Footnotes
Handling Editor: Dr Yanjiao Chen
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded in part by the National Key Research and Development Program, grant number 2017YFB1401800 and Jilin Province Education Department projects, grant number JJKH20200802KJ and JJKH20200791KJ.