
Abstract
Mobile crowdsensing is an emerging technology in which participants contribute sensor readings for different sensing applications. This technology enables a broad range of sensing applications by utilizing smartphones and tablets worldwide to improve people’s quality of life. Protecting participants’ privacy and ensuring the trustworthiness of the sensor readings are conflicting objectives and key challenges in this field. Privacy issues arise from the disclosure of the participant-related context information, such as participants’ location. Trustworthiness issues arise from the open nature of sensing system because anyone can contribute data. This article proposes a privacy-preserving collaborative reputation system that preserves privacy and ensures data trustworthiness of the sensor readings for mobile crowdsensing applications. The proposed work also counters a number of possible attacks that might occur in mobile crowdsensing applications. We provide a detailed security analysis to prove the effectiveness of privacy-preserving collaborative reputation system against a number of attacks. We conduct an extensive simulation to investigate the performance of our schema. The obtained results show that the proposed schema is practical; it succeeds in identifying malicious users in most scenarios. In addition, it tolerates a large number of colluding adversaries even if their number surpass 65%. Moreover, it detects on-off attackers even if they report trusted data with high probability (0.8).
Introduction
Mobile crowdsensing (MCS) is an emerging technology and a wide sensing model in which mobile users including participants, smartphone objects, and data providers can collect and contribute valuable data for different applications. This technology enables a broad range of sensing applications by leveraging mobile objects worldwide to improve people’s quality of life. There are many domains that benefit from MCS, such as smart cities, road transportation, healthcare, and marketing.1–3
Although many applications have been developed and benefited from MCS, there are two important challenges in MCS evolution: protecting the privacy of data providers and ensuring the trustworthiness of sensing data. The privacy in MCS is to secure the personal information of the participant when he or she reports the sensor reading, because this reading may expose sensitive information about its contributor such as the route that he or she takes when he or she collects it. However, the trustworthiness of the contributed sensor readings represents how much reliable these data are. Hence, for protecting the privacy, we need to hide any identification of the participant or any trace for the spatiotemporal information of his or her sensor readings. In contrast, to ensure the trustworthiness of the sensor reading, we need to determine whether it was captured inside the area of interest, at the appropriate time and by a honest participant. Achieving full anonymity of participant makes the guaranteeing of trustworthiness of the contributed data much difficult. Hence, these two issues represent key challenges and conflicting objectives in MCS applications.
In MCS applications, privacy challenges arise from the disclosure of the user-related context information of participants, such as participants’ identities, IP addresses, locations, and lifestyle-related information.1,4,5 Moreover, there are common attacks against participant privacy, such as traffic analysis, monitoring, eavesdropping, and collusion, in which several attackers collude together to correlate information about a target participant. However, the trustworthiness of sensing data is important in MCS applications to provide confidence to end users, who use these sensing data. Data trustworthiness has several common attack models, including erroneous or malicious contributions and collision attacks. In addition, a Sybil attack,5,6 in which the attacker has multiple identities, may threaten MCS systems. Also, several attackers can collude together to provide unified false contribution or false feedback. 1 The current literature does not address these issues effectively. In general, they either ensure the trustworthiness of sensed data and neglect participant’s privacy7,8 or vice versa.9,10 Even the MCS approaches that address both the issues fail to address the common attacks on sensing systems (Sybil 11 or collision attacks 12 ). The participants’ reputation model can be used to improve the trustworthiness of the sensed data,6,8,12 but it remains a research challenge to develop a unified and fair approach to adjust participants’ reputation scores based on their performance in different applications. As a result, some important questions come to the surface:
How can we construct a schema that protects participant personal information and their spatiotemporal information?
How can we manage the participant reputation based on instantaneous trust without revealing his sensitive information?
How can the proposed schema be resistance to different kinds of attacks that aim to corrupt the reputation system or breach the anonymity of participants?
The proposed schema in this article tries to answer the above research questions. We present a privacy-preserving collaborative reputation system (PCRS) that preserves the participant’s privacy exploiting collaborative path-hiding (CPH) 11 concept and ensures the trustworthiness of the contributed sensing data using centralized reputation distributed trust (CRDT) framework. 13 The CRDT is used to manage, update, and store the trust and reputation value for the participant which makes the system effective for MCS applications.
In particular, the main contributions of this article are as follows:
We design a PCRS utilizing CRDT and CPH;
We develop a method for computing the local trust (LT) for participants without exposing their privacy based on the feedback received from their neighbors, their past behavior, and the quality of service provided by these participants;
We introduce two mechanisms to defend against colluding participants;
We present a detailed security analysis to justify the proposed scheme is resistant against a number of attacks;
We evaluate the performance of the PCRS through extensive simulations to prove its effectiveness.
The rest of this article is organized as follows. Section “Background” presents the preliminaries of the used techniques and the threat models. Section “Related work” summarizes the primary research issues and the current state of privacy-preserving and reputation schema in MCS system. In section “The PCRS,” we introduce PCRS schema and its different phases. Section “Security analysis” analyzes the security and privacy of the proposed schema. The experimental results after conducting the simulation are discussed in section “Experimental evaluation.” Finally, section “Conclusion” concludes the article.
Background
In this section, we present a definition of MCS, CPH concept, and CRDT mechanism, and then we introduce our threat model and assumptions.
MCS
MCS has a typical architecture, as depicted in Figure 1. It has three main entities: the participant, the application server, and the data consumer. First, the data consumer generates a sensing task and distributes it to the participant in the vicinity of the site of interest through the application server (steps 1 and 2). Next, the sensing data are collected by participants and reported to the server through a Wi-Fi or cellular network (step 3). In the server, the data are analyzed and processed, and then made available to the data consumer (step 4). Then, the data consumer analyzes this data and makes it available in various forms (e.g. a graphical representation) (step 5). After this, a data consumer may give feedback to the server regarding this data (step 6). Finally, the server processes this feedback and gives it to the participant as a reward or a penalty (step 7). 6

Mobile crowdsensing architecture.
CPH
Mobile devices utilize the concept of CPH to protect their privacy. In this decentralized and collaborative mechanism, participants ensure their privacy by themselves, without needing to trust an application to protect it, by exchanging information physically between them in an opportunistic fashion. This breaks the association between the participant’s real identity and the spatiotemporal information at which the sensor reading was taken. So, the path of contributed data that will be reported to the server is the aggregation of subpaths jumbled with other participants’ paths. The exchange process can be completed according to one of the exchange strategies: (1) random-fair, (2) random-unfair, and (3) realistic. 14 Although CPH is more suitable for an application without real-time constraints for data delivery because of the need for other participants to exchange the sensing data with them before submitting it to the server, this privacy-preserving technique is considered more practical, efficient, and feasible compared to other techniques. First, it does not use pseudonyms,6,12 and hence has a minimum computation overhead. Second, it does not need cloaking or perturbation schema, 15 and therefore does not need a trusted third party (TTP) server to manage these processes, thereby avoiding endangering user privacy when reporting information to TTP servers. Finally, participants ensure their privacy themselves without the need to trust an application to protect them, as in data perturbation.16,17
CRDT
To manage, update, and store the trust and reputation value for participants, we utilize the CRDT mechanism. This mechanism is used in sensor and tactical network environments to enhance security levels and to assess the similarity of multiple information reports about the same event from different sources, for example, sensors or satellites. In this mechanism, a trust model is used to help decision-makers evaluate the data received from other nodes. The trustworthiness of these nodes is evaluated in a feedback manner, and the received data are assessed using two values. 13 Most of the time, the concepts of “trust” and “reputation” are used interchangeably, but we consider them as different terms. “Trust” is the locally stored value that represents the probability that a participant sends a correct report to other participants. However, “reputation” is a globally stored value which represents the synthesized probability that the participants are trusted, as perceived by all other participants with whom they interact. Based on how we have defined “trust” and “reputation” in MCS system, we utilize this scheme to evaluate the sensing data by applying two values. First, the LT value is stored locally on each participant’s device, which reflects his or her opinion of other participants that information has been received from. This value represents a distributed value that is updated by observing other participants and is stored in a LT table. The higher the LT value that a participant receives, the higher the probability that he or she trusts on sensing data. Second, the global reputation (GR) value is stored in the central reputation manager (CRM) unit on the server, which reflects all other participants’ opinion about a particular participant. 13 The CRM contains a table of GR values for every participant in the system. Each participant should always use the LT instead of the GR value to evaluate the trustworthiness of any participant. However, a participant can always request other participants’ GR values from the CRM and use it as their initial LT value.
Threat model and assumptions
We assume that the attackers follow the Dolev–Yao threat model, 18 where the attackers are not able to break cryptographic mechanisms although they can listen to all communication, replay, fabricate, and destroy the message. In addition, due to the nature of the path-hiding concept, participants can become attackers by attempting to break each other’s privacy by accessing the triplet content during the exchange process. Participants can give whatever feedback during LT computation and vote whatever value during the reputation computation process. Moreover, we assume that malicious participants can collude with each other to launch collusion attack by giving each other positive feedback. Furthermore, a malicious participant can attempt to create a fake ID and launch a Sybil attack (adopting multiple identities) in order to increase his or her reputation level by self-promotion. Also, there are multiple attack models that can affect the accuracy of the reputation and trust models such as bad mouthing attacks, on-off attacks, and conflicting behavior attacks.19,20 In a bad mouthing attack, the attacker gives dishonest feedback to decrease the trust/reputation of a good participant and the opposite for a malicious one. In an on-off attack, the attacker acts good and bad alternatively, and in a conflicting behavior attack, the attacker acts differently to different participants in order to decrease the trust/reputation of a good participant. Denial-of-service (DoS) attack, such as traffic jamming and attacks via the communication channels, are out of the scope of this work, and we assume that the participant has authenticated with the server when they are communicating.
Related work
This section presents the recent researches regarding the protection of data provider privacy, sensor data reliability, and the different efforts that have been achieved in MCS. In addition, it discusses several types of attacks that MCS systems may face due to the inherent open nature of sensing systems, 7 allowing anyone to volunteer and contribute their data, and exposing these systems to malicious and incorrect contributions.
State-of-the-art research efforts have been made to assess and verify the reliability of user-contributed data in the crowdsensing field. Hence, reputation systems have been proposed7,8 that generate reputation scores for participants based on the quality of their contributions. One reputation system proposed by Huang et al. 7 evaluates the trustworthiness of mobile devices contributing to participatory sensing (PS) systems. It uses the Gompertz function, which computes a reputation score that reflects the level of trust provided by a server regarding contributed data. The main drawback of this system is the accumulative feature of the reputation score. This leads to de-anonymizing participants and compromising their privacy by linking the trust value associated with multiple contributions from the same device. In addition, this system does not take into account the high requirements for privacy and anonymity. Mousa et al. 8 proposed a reputation system, the dynamic trusted set–based resutation system (DTSRS), which accurately estimates the quality of a participant’s contributions. Each participant is given a reputation score by the system and his or her contributions are given a trust score using the contribution evolution module. However, this system did not address Sybil attacks, nor did it clarify how it reduces system overhead.
Several systems have been proposed to ensure participants’ privacy in the crowdsensing area. These systems are based on the multiple pseudonyms, blind signature technique,9,10 anonymization, and cloaking or perturbation techniques. 15 A novel PS framework architecture that guarantees security and accountability was proposed by Gisdakis et al., 9 called the security and privacy-preserving architecture (SPPEAR) architecture. In addition to preserving user privacy, it provides incentives to PS participants. Furthermore, this framework can defend against compromised and colluding entities. The process to defend against a malicious user is not straightforward enough to evict intelligent, cooperating, and numerous adversaries. In addition, there is a tradeoff between the overhead and the use of multiple pseudonyms. Re-using one pseudonym to protect more than one report involves trading participants’ privacy for overhead. A highly similar approach is taken by Gao et al., 10 who present an enhanced trajectory privacy-preserving framework (TrPF). It is based on a TTP server that functions as a privacy-preserving agent by providing a certificate to the ligament participants and unlinking the identities of those participants from their spatiotemporal information. However, the connection anonymization is not suitable for applications with fine-grained information, and there is a tradeoff between the efficiency of data transmission and privacy protection. Christin et al. proposed the TrustMeter 11 scheme to assess the participants’ contributions in a privacy-preserving mechanism. This schema utilizes a CPH concept 14 to unlink participants’ real identities and the spatiotemporal context of the reported data. In addition, a trust level is assigned to each user based on the peer-based ratings of past exchange reports. However, it does not prevent multiple identity attacks, that is, Sybil attacks. Lord of the sense (LotS) is a privacy-preserving reputation system for sensing applications that was proposed by Michalas and Komninos. 21 This system aims to provide participants privacy, anonymity, and accountability, as well as support users’ reputations. The privacy and anonymity of users can be achieved through a cryptographic mechanism that is used to unlink the identities of the participants from the reports they contributed. Moreover, it prevents collusion attacks by verifying user credentials, but it fails to address the profiling of user attacks, as well as how to defend against malicious attacks in a trust evaluation when the identity of a user is preserved. IncogniSense, proposed by Christin et al., 12 is an anonymous reputation framework based on the blind signature technique used to achieve periodic pseudonyms and secure reputation transfers between these pseudonyms. Although this framework is an energy-efficient schema, it acquires additional communication and management overhead. Furthermore, it lacks a voting procedure, which is an important feature of PS applications.
Two privacy-preserving reputation management schemes were proposed by L Ma et al. 22 These schemes utilize edge computing–enhanced MCS (EC-MCS) to concurrently ensure the privacy of participants and the reliability of the sensing data in MCS systems. To preserve the contributors’ privacy and deal with malicious participants, a basic privacy-preserving reputation management (B-PPRM) scheme is designed. So, all the contributed data are encrypted and only the interested participants can decrypt the final aggregation result. In addition, an advanced privacy-preserving reputation management (A-PPRM) scheme has been introduced that updates the reputation values according to the ranking of the deviations of encrypted sensing data. These schemes effectively handle malicious participants who contributed to false sensing data. However, updating the reputation utilizing the ranking of the devotion causes computation overhead. D Wu et al. 23 proposed a strategy for dynamical credibility assessment of privacy-preserving (CAPP). It is based on a dynamic trust-evaluation method for evaluating the social relationship and data quality with pseudonyms and blind identities. For the data reliability, a multiple-path transmission is established to gather the sensor data. Moreover, a dynamic message-splitting method based on a trust relationship is utilized to achieve higher privacy protection. Although this mechanism is effective and efficient in terms of privacy protection and data transmission, it is designed only for opportunistic MCS. It does not address the Sybil, on-fff, or conflicting behavior attacks.
In general, neither privacy-preserving nor data trustworthiness mechanisms are optimal. In the end, there is a tradeoff between increasing privacy or data trustworthiness. The proposed schema in this article achieves participants’ privacy using CPH 14 mechanism that does not depend on any other applications, pseudonyms, perpetuation, or cloaking techniques. Instead, this is done by enabling the participant to protect his privacy by himself. At the same time, the proposed schema ensures the trustworthiness of the contributed sensing data under the CRDT 13 model. This is, to our knowledge, the first to be used in MCS that assess the trust using two values: central and distributed values. These values do not compromise participants’ privacy and reflect the trustworthiness of the contributed data. In addition, the proposed schema defends against a variety of attack models that MCS applications may face.
The PCRS
Proposed framework
This section describes a proposed PCRS framework for MCS applications using CRDT based on the CPH concept. Figure 2 shows the framework for the proposed scheme. Our framework consists of the application server (App. Server) and participants (client and mobile devices). The participants collect a sensing reading from their surroundings and prepare it to be exchanged with another participant using the CPH concept. Then each participant reports the exchange and his own triplet (time, location, and sensor reading) to the server periodically. Trust and reputation are computed based on CRDT manner. Specifically, the trust level computes locally for each participant and the reputation value computes globally at the server in the CRM.

Privacy-preserving collaborative reputation system (PCRS) framework.
Triplet exchange and reporting
A participant collects a triplet (time, location, and sensor reading) and stores it in his mobile device until he encounters another trusted participant. The triplet is encrypted using the public key of the server to prevent others from accessing its content, and it has a unique ID. The triplet ID is a one-way hash function (SHA-252) using participants’ ID, the triplet timestamp, and a random number.
After verifying the trustworthiness of the opposite party, each participant starts exchanging triplets using one of the exchange strategies mentioned in section “CPH.” The exchanged and collected triplets are reported to the server to be processed, analyzed, and made available to the data consumer (end users). Subsequently, participants request a list of triplet IDs delivered to the server since their last connection. The main reason for this list is to remove successfully delivered triplets from the participant’s internal storage. Each triplet has a delivery timeout; if it expires before it reaches the server, it is considered lost and requires the participant to exchange it again.
LT update
The LT value is stored locally in a trust table on the participant’s device and reflects his or her opinion for participants that he or she has received information from. Each participant examines the trust level of the opposite party by looking at the LT value in the LT table. The examination is based on the difference between the LT values of the exchanging peers of the participants. If this difference is less than a predefined threshold, they are considered trusted and start the exchange using one of the exchange strategies mentioned in section “CPH.” If it is greater than the predefined threshold, the connection between these peers drops and they start to search for another participant to exchange with. A participant should always use an LT value instead of a GR value to evaluate the trust level of the other participant. Such a distributed mechanism for estimating trust minimizes the traffic overhead. Each participant would use the LT value to estimate the opposite party’s trust level without the need to contact the server for trusted information, except in some cases such as to initialize the LT for participants that communicate for the first time. If this is the first encounter between the two participants, they ask the server for each other’s reputation value to initialize LT. After the exchange of triplets between two participants, each of them updates their corresponding LT value. For example, if participant A exchanges triplets with participant B, A updates the LT value for B such that A asks other participants (neighbor participants) to give feedback for B. Local trust feedback (LTF) is the feedback that a participant gets from the nearest neighbors about a specific participant in the range of 10 m. This feedback’s weight is based on a trust factor (K) that ranges between [0,1] and reflects how much A trusts these neighbors, as depicted in Figure 3. The feedback from a participant with high LT in the requester table is more trusted; thus, C gives high feedback about B and C has a high LT value in A’s LT table, hence A gives C’s feedback more weight and the opposite is done in the case of feedback from D. In the case of E, who has no LT value in A’s LT table, the K value is 0 as if E has not given feedback for B.

Feedback process for updating the local trust.
Quality of service (W) is the ratio of the number of delivered triplets to the total number of exchange triplets as shown in equation (1)

If W is low, that means that B does not deliver all the triplets that were exchanged with A to the server. We can obtain this information when A reports the sensing data to the server and requests a list of triplet IDs delivered to the server since their last connection. Then, A can compute the LT value of B as equation (2)
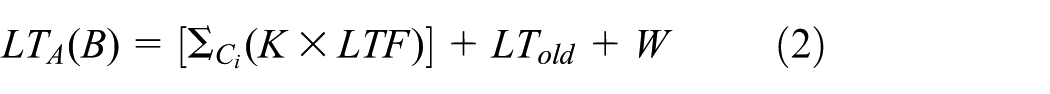
where
Since

Second, we normalize W to a range between

Since

GR update
The CRM of the server computes and maintains a GR value for each participant in the system, and these values are stored in a GR table. The CRM periodically updates these values by an asynchronous voting process. Here, each participant’s vote contains two values: (1) the LT for the participant for whom the server wants to compute reputation and (2) the number of times (F) the voter gives feedback to this participant in order to weight the vote. So, reputation is based on votes from all participants who interact with the specific participant. In case the server does not have a GR value for this (new) participant, it initializes reputation with GR0. For example, if the server wants to compute the reputation of participant B, it requests a vote from all participants who interact with B (denoted as


where
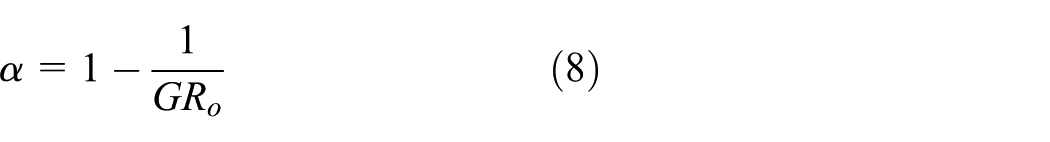
Equation (8) signifies that the value of
Similar to the normalization of LT, we normalize

Second, we normalize
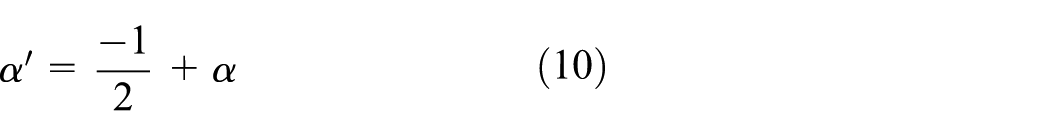
Finally, the value of the GR is expressed as equation (11)

Security analysis
In this section, we analyzed the behavior of PCRS schema when different types of attack take place. We also proved that PCRS schema achieves our goals and is secure. First, we assume that this schema is suitable for a mobile-sensing application without real-time data-delivery constraints. Second, each participant must authenticate himself or herself to the server, and both the server and CRM are well protected.
Proposition 1: the server cannot correlate the participant identity with his original sensing report
We have used the CPH concept so that each time participants want to report sensing data to the server, they report a combination of their own triplet and the triplet of the exchanging partner, so that the server is not able to determine the exact participant who collects these triplets. Moreover, the process of exchanging information between participants physically breaks the association between participant identity and the spatiotemporal information at which the sensor reading was taken.
Proposition 2: participants cannot collude together to give each other positive feedback without being detected
One of the contributions of our proposed schema is providing two mechanisms to defend against colluding participants. The server keeps a list of the partners that each participant exchanges with, and an irregular rate of high-frequency exchange between the same participants can be identified. Also, if two participants keep exchanging information with each other and give positive feedback to each other, this increases only their mutual LT, not affecting the LT feedback given by other participants. Moreover, the use of centralized reputation (GR) reflects all other participants’ opinions on a specific participant. As we mentioned in section “GR update,” the level of GR value is not greatly affected in the case of colluding participants.
Proposition 3: participants cannot attempt to alter the computed reputation
The server and the CRM are protected against any unauthorized access by the use of standard cryptographic primitives, well-established algorithms that are used to build cryptographic protocols for computer-security systems such as encryption functions, guaranteeing that no one can manipulate the reputation values.
Proposition 4: participants cannot attempt to report incorrect information on behalf of another participant
We assume that each participant has a unique ID and public–private key pair to authenticate with the server. The proposed schema protects trusted participants against this attack by enforcing them to be authenticated with the server. So, this attack cannot be launched without accessing the private key of the target participant, which is beyond the scope of this research.
Proposition 5: participants cannot launch replay or Sybil attacks
An adversary can abuse the feature of triplet retransmission, which is permitted when the delivery timeout has expired, to increase their reputation by replaying triplets. However, when the same triplets are reported to the server at abnormal rates, the server treats them as spam. The proposed schema mitigated the attempt to launch a Sybil attack (adopting multiple identities) because the attackers need first to build a reputation before launching any attack and because each time new participants enter the system, their reputation is initialized with 0. Moreover, as illustrated in the example in section “LT update,” if a participant E gives a feedback about participant B and the requester A has no LT value for E, it is as though E gives no feedback. Even in the voting process, we set an upper limit of (
Proposition 6: participants cannot launch bad mouthing attack
The LT update process takes into account the LT of the participants who provide feedback, as described in section “LT update” (equation (2)). We weight each feedback using a K factor, which reflects how much the requester trusts these feedback providers. Also, in the reputation-update process, all votes are weighted based on the reputation level of the corresponding voters, as explained in section “GR update” (equation (6)). We give a high value to the feedback and vote from a participant who is highly trusted. Thus, the higher the value that voters have as their reputation, the lower the probability of their launching an attack. By this mechanism, the bad-mouthing attack is effectively mitigated and the honest participants are protected.
Proposition 7: participants cannot launch on-off attack
We give more weight to recent reputations as compared to old reputations, and this could be a key factor in defending against an on-off attack. We utilize a factor
Proposition 8: participants cannot launch conflicting behavior attack
The LT update process is based on four parameters, as mentioned in equation (2) of section “LT update.” In computing LT value, we rely not only on other participant’s feedback but also on the past behavior of the participant and the quality of the service that he or she provides. So, even if a participant behaves differently to different participants to disrupt the feedback process, other aspects besides the feedback recommendations are considered in computing the trust. Moreover, in the feedback process for updating the LT, these feedbacks are weighted according to how much the requester trusts the neighbors who provide the feedback. Thus, it is difficult for the malicious participant to know who is highly trusted by the targeting participant.
Proposition 9: the proposed mechanisms does not impose additional communication overhead
The proposed schema does not incur additional communication overhead, compared to other mechanisms. First, the privacy mechanism that was used is a simple and effective one that does not require the generation of pseudonyms or a blind signature by communicating with any server. Second, the reputation mechanism in this schema uses distributed trust, so the participants use a LT to examine the opposite party’s trust level without the need to contact the server, except in some cases as mentioned in section “LT update.” That outperforms, 11 in which when two participants encounter each other, they first examine the trust level of the opposite party provided by the server, so that during each transmission, the server needs to disseminate a table containing the trust levels of all participants. Furthermore, the LT computation used in the reputation mechanism in the proposed schema is based on three parameters: (1) feedback from neighbors, (2) past behavior, and (3) quality of service, without the need to use the provenance meta-data, which imposes communication overhead such as in Wang et al. 13
Experimental evaluation
In this section, we report the results of several simulation tests evaluating the performance of the proposed schema. In addition, we evaluate the schema resistance to adversaries. Finally, we compare our results with those of state-of-the-art approaches in the same field.
Simulation setup
To measure the accuracy of the CRDT mechanisms, we implemented our schema on the Eclipse simulator with Java. We performed the operations of PCRS on a laptop with an Intel Core i5-3210M CPU, 2.50 GHz clock rate, and 4GB memory. Because communication is not a concern in this work, we implemented the server and the participants on the same machine. First, we define the adversary nature, which is the probability of the adversaries sending correct sensing data. It enables the adversaries to launch on-off attacks. The adversary ratio is the number of adversaries in the system. 6 In addition, we assume the worst-case scenario in which the adversaries launch collusion attack to corrupt the reputation system by sending all incorrect sensing data The trusted participants always send honest, correct sensing data. We evaluate the performance of PCRS using the following cases:
Impact of adversary nature on GR;
Impact of adversary nature on LT;
Impact of adversary ratio on GR;
Impact of adversary ratio on LT;
Impact of trusted participants ratio on GR;
Impact of trusted participants ratio on LT.
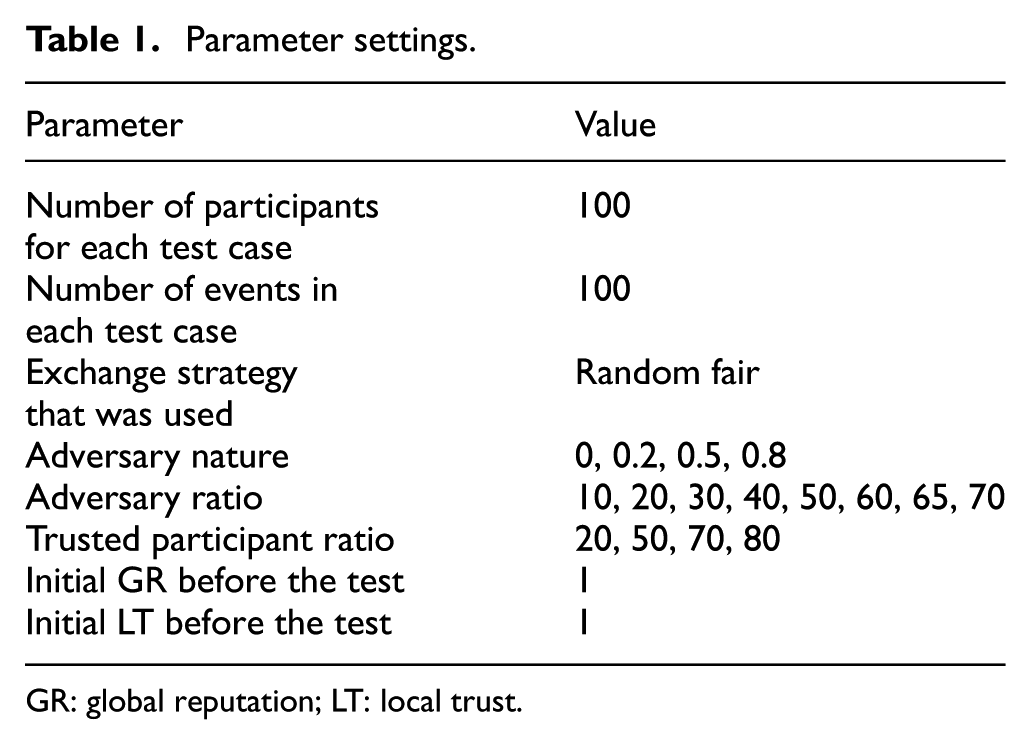
Each test case was simulated using the parameter settings listed and defined in Table 1. For each test case, we averaged the value obtained over 10 random runs.
Parameter settings.
GR: global reputation; LT: local trust.
Simulation results
The following subsections describe the results of each test case.
Impact of adversary nature
To see how an adversary nature affected the participant’s LT and GR, we used four adversaries with nature values of 0, 0.2, 0.5, and 0.8, respectively. We assume that all adversaries had good behavior initially until their LT and GR values reached 1. We conducted the test for 100 tasks (events).
Figure 4 illustrates that the GR of these adversaries decreases rapidly as the number of events increases. Particularly in the case of an adversary with a nature value of 0, which means that all the sensing data that it sent were incorrect, the adversary reputation decreases until it reached 0. In addition, the reputations of the adversaries with nature values of 0.2 and 0.5 degrade very quickly to low levels. Furthermore, the reputations of the adversaries with the highest nature value, 0.8, (80% probability of the sent data being correct), decrease, but not to low levels. This illustrates that bad behavior has a greater influence on GR than good behavior, signifying adversaries were strictly penalized for incorrect data but gradually rewarded for correct data. The result also depicts that the PCRS prevents on-off attacks.

Impact of adversary nature on global reputation.
Second, we examine the LT values using the same adversary nature. Figure 5 shows that the LT of an adversary with a nature of 0 was set as 1 at the beginning of the test, when its reputation was still high, to see its effect. As the figure shows, the value of LT decreases to 0 and it remains to this value indicating that the adversary is untrusted. In contrast, because each had a probability of sending correct data, the LTs of the adversaries with nature values of 0.2, 0.5, and 0.8 fluctuate implying that they report mixtures of correct and incorrect sensing data. As Figure 5 illustrates, the higher the nature of adversary, the higher the LT value.
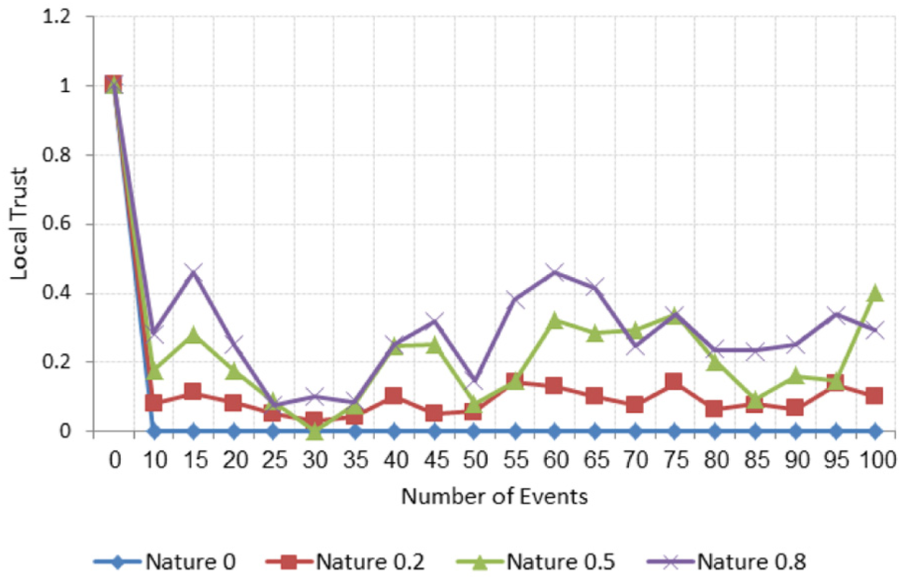
Impact of adversary nature on local trust.
Impact of adversary ratio
To measure the resistance of the proposed schema to collusion attack, the third test examines how the number of adversaries affects the LT and GR values. We set the number of adversaries to be 10, 20, 30, 40, 60, 65, and 70 out of 100 participants, and we set the nature of all adversaries at 0, which is the worst-case scenario, meaning that all the data from the adversary are incorrect.
Figure 6 illustrates how the ratio of the adversaries affects the GR. It shows that the system can identify the adversaries after only a small number of events. The system immediately and easily identifies even a large number of adversaries (e.g. 70) and their reputations do not go above 0.5. The reputations of the adversaries with ratios up to 40 decreases rapidly to levels close to 0. The system also identifies the reputations of adversaries with ratios of 60, 65, and 70, indicating that 60, 65, or 70 participants of 100 send incorrect data, and their reputations decrease slowly, and do not exceed 0.5. The result assures that the system successfully identifies that even the adversary ratios reach 70.

Impact of adversary ratio on global reputation.
Then, we evaluate the effects of adversary ratios on LT levels using the same settings. As Figure 7 depicts, the LTs of the adversaries with ratios of up to 60 decrease to low values. In particular, when the number of adversaries is low, they are immediately detected since their LTs decrease considerably. For example, if 10 participants act as adversaries, their LTs dropped to level close to 0. Even when the ratio of adversaries reaches 70, the trust curve still fluctuates, manifesting the contributed LT values of these adversaries are still untrusted. The trust curve fluctuates much more than the reputation curve, increases when correct data are received and decreases for incorrect data reception. This is due to the W parameter that affects the individual LTs. This also indicates that the PCRS is resistant to conflicting behavior attacks. In addition, the foregoing tests proved that our schema is resistant to both collusion and conflicting behavior attacks.

Impact of adversary ratio on local trust.
Impact of trusted participants’ ratio
We test the accuracy of the proposed schema to correctly identify the trusted participants. We assume that the participants are new to the system and set the ratio of the trusted participants at 20, 50, 70, and 80 out of 100 participants. Figure 8 shows the results of the effects of the trusted participant ratios on GR levels. As the ratio of trusted participants increases, the reputation levels also increase to high value after a small number of events.

Impact of trusted participants’ ratio on global reputation.
We also evaluate the effect of the number of trusted participants on the LT values. In Figure 9, the curves follow the same trend as in Figure 8: the LT values increase as the ratio of trusted participants increases. To summarize, our proposed schema flawlessly identifies both trusted and adversarial participants. In addition, it successfully addressed on-off attacks, conflicting behavior attacks, and collusion attacks. This proves that our schema is practical and robust enough to identify various types of attacks.

Impact of trusted participants’ ratio on local trust.
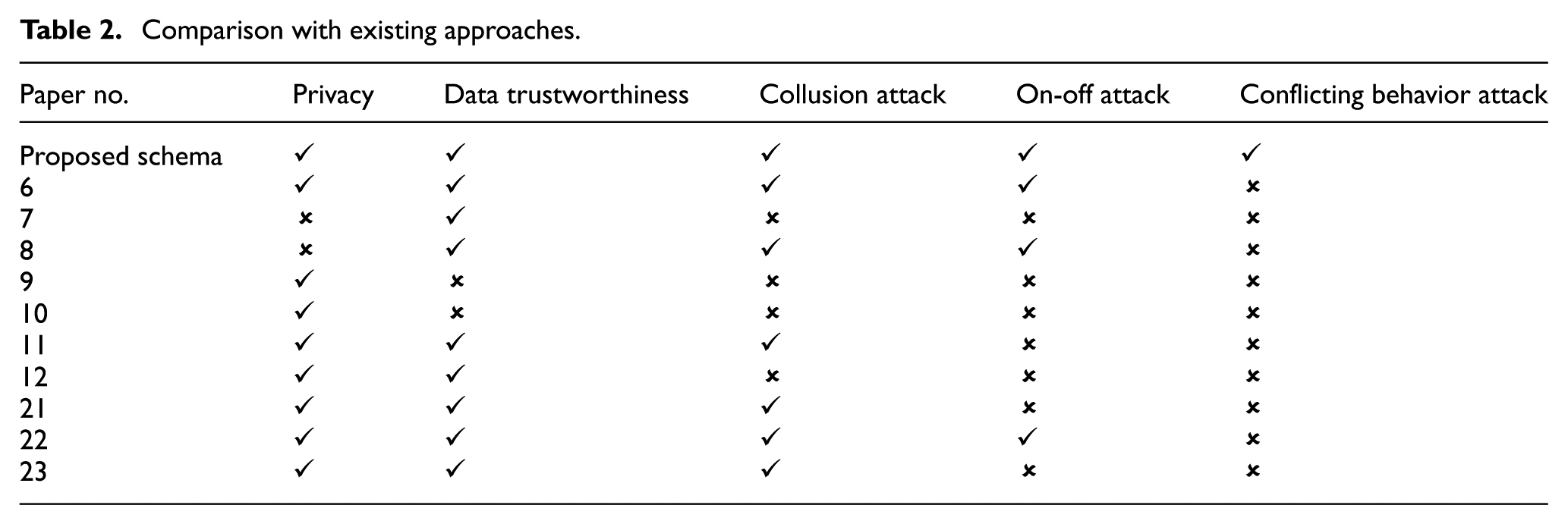
Performance comparison with existing approaches
The proposed schema outperforms the state-of-the-art approaches in the MCS field as illustrated in Table 2. It ensures participant’s privacy and trustworthiness of the contributed sensing data at the same time. Furthermore, the results prove that collusion, conflicting behavior, and on-off attacks are prevented by this schema.
Comparison with existing approaches.
Conclusion
This work proposes PCRS schema that effectively preserves the privacy of the participants and ensures their trustworthiness in the MCS. PCRS schema preserves participant’s privacy by leveraging the path-hiding concept to provide a decentralized, collaborative mechanism that enables participants to ensure their privacy themselves without needing to trust an application to protect it by exchanging information among themselves physically in an opportunistic fashion. In addition, the schema ensures the trustworthiness of the contributed sensing data using the CRDT mechanism, which assesses the trustworthiness of sensing data by applying two values: LT values, which are stored locally on each participant’s device, and GR values, which are stored on the central server. Finally, we evaluated CRS performance and effectiveness by conducting an extensive simulation in a Java environment. All the results demonstrated that the proposed schema is effective, feasible, and robust against various types of attacks. It can identify both the adversaries and the trusted participants, even when there are high ratios and natures of adversaries. The schema’s performance mitigates malicious behavior in the system.
Footnotes
Acknowledgements
This article extends the work published in the Proceedings of IEMIS’18.
Handling Editor: Kim-Kwang R Choo
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This paper contains the results and fundings of a research project that is funded by King Abdulaziz City for Science and Technology (KACST) under grant No. 1-17-02-009-0006.