
Abstract
In the era of 5G mobile communication, radio environment maps are increasingly viewed as a powerful weapon for the optimization of spectrum resources, especially in the field of autonomous vehicles. However, due to the constraint of limited resources when it comes to sensor networks, it is crucial to select a suitable scale of sensor measurements for radio environment map construction. This article proposes an adaptive ordinary Kriging algorithm based on affinity propagation clustering as a novel spatial interpolation method for the construction of the radio environment map, which can provide precise awareness of signal strength at locations where no measurements are available. Initially, a semivariogram is obtained from all the sensor measurements. Then, in order to select the minimum scale of measurements and at the same time guarantee accuracy, the affinity propagation clustering is introduced in the selection of sensors. Moreover, the sensor estimation groups are created based on the clustering result, and estimation results are obtained by ordinary Kriging. In the end, the simulation of the proposed algorithm is analyzed through comparisons with three conventional algorithms: inverse distance weighting, nearest neighbor, and ordinary Kriging. As a result, the conclusion can be drawn that the proposed algorithm is superior to others in accuracy as well as in efficiency.
Keywords
Introduction
With the large-scale application of smart terminals in the era of 5G technology, autonomous vehicle technology is experiencing revolutionary breakthroughs in engineering, resulting in an urgent requirement for many kinds of fundamental communication equipment. 1 In other words, autonomous vehicles need to communicate more efficiently and accurately with the traffic management system. 2 In this context, the quality of the communication channel is critical in fulfilling the vision of 5G autonomous vehicles. 3 However, communication quality is easily influenced by changes in the vehicle’s location, especially in urban scenarios. Many examples of radio environment map (REM) application in 5G wireless network have been proposed. 4 If knowledge about the mobility patterns and REM is available, the channel quality of the vehicle along the trip can be predicted. 5 Then, the predictions can be utilized to guide the network to learn if the vehicle is heading toward a poor coverage area and to make an adaptation of the route in time. Subsequently, it is important for the autonomous vehicle communication network to obtain information regarding the electromagnetic environment dynamically and precisely.
REMs represent an important method of information management
6
for the operation of cognitive radio networks,7,8 replacing or complementing spectrum sensing information
9
and spectrum utilization in wireless networks.
10
They provide a precise awareness of the electromagnetic environment in the spatial domain by processing the measurement of the received signal power, which can be gathered by sample capable devices like sensors fixedly deployed within a smart city context.
11
REM construction methods are classified into three basic categories:
9
direct methods applying interpolation, indirect methods utilizing transmitter location and propagation modeling,
12
and hybrid methods.
13
But the information of the signal transmitters is usually hard to obtain completely in complicated electromagnetic environments within urban areas, which has a strong negative influence on the last two construction methods. In order to solve the problem mentioned above, a direct interpolation method is applied for REM construction in the context of 5G autonomous vehicles by interpolating available signal measurements using local neighborhood, geostatistical, and variational interpolation methods.
14
The spatial interpolation methods found in the literature include inverse distance weighting (IDW),15,16 nearest neighbor (NN),
13
and ordinary Kriging (OK).17–19 Both IDW and NN have the advantage of fast construction, but the former may produce the “bull’s-eye” effect and be sensitive to outlier measurements, while the latter extrapolates poorly beyond the measurement values set and makes sharp transitions within REM zones. Among these direct interpolation methods mentioned, Kriging is the most widely used because it is a geostatistical best linear unbiased estimator (BLUE) that yields a zero mean residual error and minimizes the error variance.
20
Before the estimation of interested values at unknown points, the semivariogram (SV) is used to estimate the degree of relationship between the measurements according to the theory of spatial correlation in geostatistics.
18
But it also has the disadvantages of relatively high computational complexity among presented direct methods, which is
In an urban area, the electromagnetic environment is complicated and variant because of a large number of communication devices. After the application of the 5G autonomous vehicle communication network in the smart network context, the fast construction of an REM is required by the optimization estimation of signal strength around vehicles. Although the information of traditional REMs is not drastically changed due to the averaging procedure, the REM must be updated frequently enough to regulate the route for autonomous vehicles in the smart network. However, classical interpolation methods fail to fulfill the demand for accuracy. In order to realize dynamic and precise awareness, the REM should be refreshed frequently to meet the fast changes in the communication environment. Therefore, the computational efficiency is of great importance. This is especially true for OK interpolation since its computational complexity,
Because of the new challenges in REM construction, some revised interpolation algorithms concentrating on reducing error 21 and some modified Kriging algorithms based on mobile crowd sensing (MCS) 22 have been proposed. But these revised methods do not perform well in the scenario of fixed sensor placement within smart networks for autonomous vehicles. A distributed radio map reconstruction method for 5G automotive technology referred to as distributed incremental clustering algorithm-regression Kriging (DICA-RK) is provided in Chowdappa et al., 23 which creates the clusters of sensors according to the Kriging variance before the estimation in order to reduce the calculation complex. It chooses RK to construct the REM based on the condition that only one transmitter exists in the area of interest, as well as the parameters of the propagation model, for example, path-loss constant, are known to the system. However, in urban areas discussed in the autonomous vehicle industry, multiple transmitters and a lack of knowledge of propagation parameters should be taken into consideration because of the increasingly complicated electromagnetic environment.
Furthermore, an efficient and suitable clustering algorithm chosen to create the estimation group of sensors should fulfill the requirements below. First, in view of the random deployment of sensors within the smart city network, prior knowledge of the number of clusters cannot be confirmed. In addition, spatial correlation between each measurement should be considered as primary, which means the Euclid distance between measurement points is the significant factor for clustering. Some common clustering algorithms cannot fulfill both requirements. For example, the number of centroids of k-means need to be chosen beforehand 24 and the density-based spatial clustering of applications with noise (DBSCAN) is a density-based clustering algorithm. 25 On account of this, the affinity propagation (AP) clustering algorithm is most suitable because it is based on the concept of “message passing” between measurement points and does not require the number of clusters to be determined before clustering. 26
In this article, an adaptive OK interpolation method based on the affinity propagation clustering algorithm (APCA-OK) is proposed to construct the REM in an efficient way, with the objective of an appropriate scale of sensor measurements to process the estimation. First, the global SV of Kriging interpolation is calculated according to the measurements from all sensors, making sure the transition is smooth within the REM and increasing the stability of the estimation. Moreover, the contribution can describe the spatial correlation of the field value from all sensor measurements better than it can from part of them. In other words, all unknown points share the same SV. Then, the APCA is employed to cluster the randomly deployed sensors and confirm the exemplar of each cluster. For one specific unknown point, a few clusters are chosen to form the estimation group based on the density of sensors around the unknown point and each exemplar of those. Each unknown point has its own group of sensors for Kriging prediction, which means each different unknown point has the same SVs but different Kriging systems, and the estimation groups are formed by neighbor clusters. The estimation group size is a key factor in the proposed algorithm. On one hand, it should be as small as possible to reduce the computational complex. On the other hand, it should also be big enough to represent the field value around the unknown point. According to Oliver and Webster, 20 the Kriging method determines the estimation by minimizing the error variance of general Kriging linear estimator. Hence, the minimum Kriging variance of different combinations of neighbor clusters is utilized to regulate the size of each estimation group in the proposed algorithm. Although all sensor measurements influence the estimated value, they have different weights. The formation of the estimation group is the process of appropriate selection of sensor measurements which form the most effective base for estimation. Finally, the Kriging prediction is processed within each estimation group with the same SV but different Kriging systems so as to obtain the estimated value and Kriging variance.
The proposed algorithm reduces the demand for computational sources sharply but guarantees accuracy by choosing the most influential measurements based on the spatial correlation of sensors. Performance assessment results and interpolated maps are presented to interpret the reconstruction quality. Furthermore, the influence of the size of estimation groups is discussed through the comparisons of estimation results. In addition, REM construction time costs (TCs) are compared between APCA-OK and OK to testify to the computational efficiency of the former. Finally, the results obtained by the proposed algorithm are compared with conventional interpolation methods such as IDW, NN, and OK. The rest of the article is organized as follows. In section “Model and problem statement,” the models for the electromagnetic environment and propagation channel as well as the problem statement are described. The architecture and specific steps of the proposed algorithm are introduced in section “Algorithm description.” In section “Simulation and analysis,” simulations and results analysis of different spatial interpolation methods are discussed. And conclusions are drawn in the last section.
Model and problem statement
Spatial network model
The area of interest is considered as a two-dimensional (2D) space denoted by
The crucial process of this algorithm is to estimate the spatial value

where K is the constant path-loss factor,
Problem statement
The objective of this article is to obtain the accurate and dynamic REMs of the complicated electromagnetic environment for autonomous traffic management system. Due to the large number of communication terminals, prior information of transmitter and propagation modeling is difficult to obtain accurately. Current indirect and hybrid methods are not suitable for this problem, because their performances are highly related to the accuracy of prior information. Among direct methods, Kriging performs well in accuracy, but its high computational complexity is a constraint for fast construction of REM.
In consideration of the application of complete infrastructure facilities, the smart terminals, such as micro-cellular base stations or smart lamps along streets, can be utilized as sensors to collect the measurements. First, since these infrastructure facilities are deployed fixedly for communication purposes, these sensors cannot afford the computation or storage functions. So, distributed network of sensors is not practical for this problem. Second, these facilities can still be clustered in different estimation groups in prediction process in the fusion of network. According to the spatial correlation, the sensors are deployed closer to the unknown point, their measurements have greater influence on the interpolated result. Therefore, neighbor measurements within the estimation group can reduce the computation but still guarantee the accuracy. Based on the development of smart city, deployments of sensors can be combined with complete infrastructure facilities, and global SV is applied for the application of the central network of sensors.
In other words, we aim to construct REMs precisely and efficiently for the industry of pilotless automobile based on the smart city infrastructure facilities. First, global SV parameters
Algorithm description
The APCA-OK estimates the

Flowchart of APCA-OK algorithm.
The first step is the SV fitting. An SV describes the spatial variability of a random field from a set of measurements. It is a structural and descriptive tool measuring the spatial correlation as a function of distance. The empirical semivariogram (EV), denoted by

where
SV modeling is a significant step in spatial description. Since the EV can only provide the SV estimation at a finite set of lags, it must be replaced by the parametric SV model in order to obtain the SV estimation at arbitrary lags. The SV model is a mathematical expression that models the trend in the EV by fitting a curve onto the computed EV values. Multiple SV models have been introduced in the field of geostatistics, such as spherical, Gaussian, and exponential model. In this article, the spherical model is chosen for the SV because it outperformances other models based on the correct decision ratio in centralized Kriging, 17 whereas weighted least-squares are used to fit the model which is given by

where
After an SV model is established according to measurements from all sensors, the next step is sensor clustering. The spatial correlation of sensors, which has great influence on the accuracy of estimations, must be taken into consideration in the clustering. Thus, the AP algorithm is employed to cluster the randomly deployed sensors. For a set of location points S,

The algorithm proceeds by alternating two message passing steps to update two matrices in Frey and Dueck:
26
the “responsibility” matrix R and the “availability” matrix A. The former matrix contains values
To begin with, both matrices are initialized to all zeros, and then the responsibilities are computed using the rule

and the availabilities update is as follows

and

The iterations are performed until the cluster boundaries remain unchanged either over numerous iterations or after some predetermined number of iterations and then exemplars are extracted from the final matrices.
After the clustering system is built up, the locations of exemplars are also confirmed. The next step is to compare the distances from
The following step is the OK prediction based on the SV fitting information and estimation group establishment. Kriging interpolation can be viewed as a weighted average method where the estimation of a phenomenon at a given location is a linear combination of the neighbor values. The Kriging interpolator at an unknown point

where

and they can be obtained by solving a set of linear equations known as the Kriging system, which contains the SV drawn from an analytical model given by

where

The minimized estimation variance for n sensors, referred to as the OK variance, can be calculated as
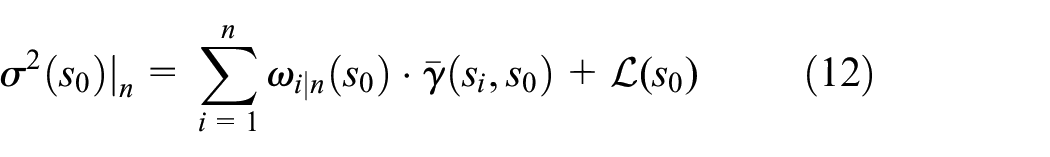
And the whole process of the APCA-OK is displayed in the Algorithm above.

Simulation and analysis
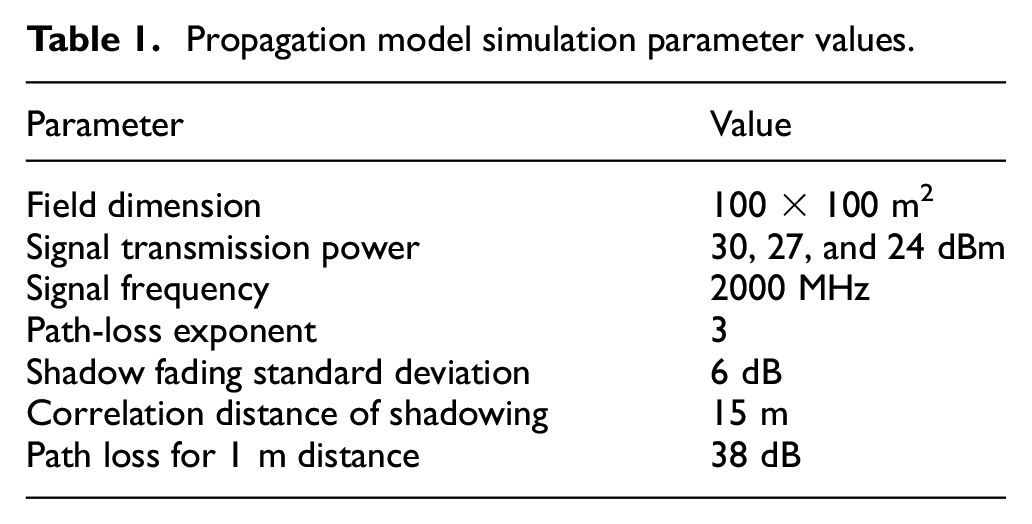
To assess the performance of the proposed APCA-OK algorithm, simulations using MATLAB have been performed on the PC with a processor of AMD Ryzen 7 2700X, 16 GB of memory, and Windows 7 Ultimate operating system, considering the scenario introduced in section “Model and problem statement.” The parameter settings of equation (1) are displayed in Table 1, which is based on the empirical values in the literature.19,22,23
Propagation model simulation parameter values.
After the construction of the scenario, all sensors are placed in the field randomly and clustered by the APCA. Figure 2(a) illustrates random placement when the number of all sensors, N, is 100 while Figure 2(b) illustrates clusters and exemplars of the placement. Since accuracy is a significant criterion to algorithm performance, the mean squared error (MSE) is utilized to analyze the accuracy of REM construction, which can be expressed as follows

where l and w are the length and width of the field, respectively,

(a) Random placement and (b) AP clustering of sensors N = 100.

(a) Original map of simulation, (b) IDW, (c) NN, (d) OK, and (e) APCA-OK REM at N = 100 and
Optimal size of estimation group in APCA-OK
The size of estimation group, that is,
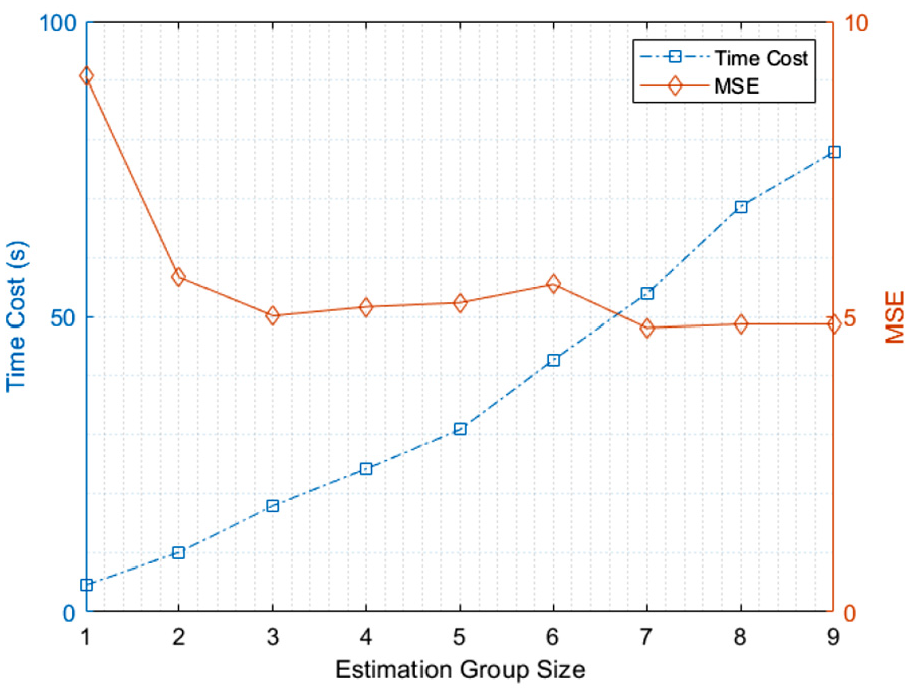
TC and MSE versus estimation group size, N = 100.
As shown in Figure 4, the increase in
Comparison of TC between OK and APCA-OK
After discussing the optimal size of the estimation group, the computational efficiency of OK and APCA-OK is also crucial, because APCA-OK is provided in order to solve the fast construction problem in dynamic REMs.
As shown in Figure 5, the TCs of OK and APCA-OK are compared in situations with different numbers of sensors. We are informed that APCA-OK always spends less time than OK on REM construction. What’s more, the TC of both methods increases with the increase in the number of sensors, but the gap between the two methods also increases. It is demonstrated clearly that APCA-OK is superior to OK with regard to computational efficiency, and the superiority is more obvious with the increase in the sample ratio of sensors.

Time cost versus number of sensors.
Comparison of MSEs between different algorithms
According to the analysis above, the superior efficiency of APCA-OK has been proven. But precision is still the most consequential factor in REM application. Therefore, the MSEs are obtained to compare the performance on accuracy of different algorithms, including OK and APCA-OK, and also in addition IDW and NN.
Overall, from Figure 6, the MSE of each algorithm reduces with the increase in number of sensors, which demonstrates that an increase in the sample ratio has a positive effect on construction accuracy. Among these four algorithms, OK and APCA-OK always have less MSE than IDW and NN. OK is slightly more precise than APCA-OK when the number of sensors is less than 100, but this phenomenon reverses when the number of sensors is more than 120, which illustrates that (1) APCA-OK has a similar level of accuracy with OK and is even better with the increase in sample ratio, (2) the estimation accuracy of OK and APCA-OK requires enough measurements for each single unknown point, and (3) the neighbor measurements have much greater influence on both estimation results than the far-away counterpart of unknown points.
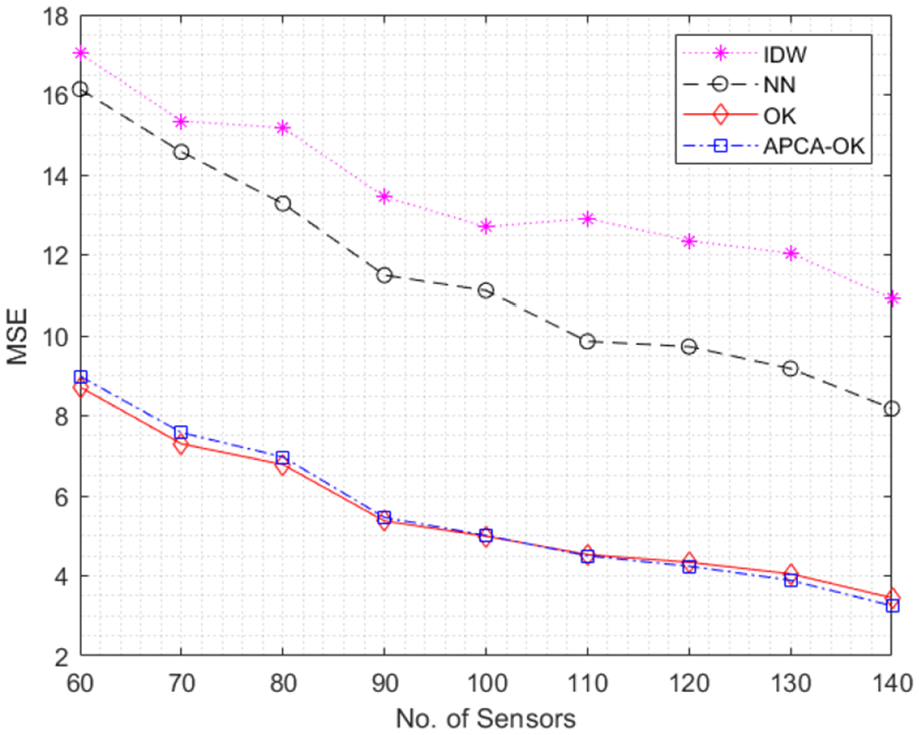
MSE versus number of sensors,
Conclusion
In this article, an adaptive clustering Kriging algorithm in smart sensor networks has been proposed so as to solve the problem of accurate and efficient REM construction for 5G autonomous application. Centralized sensor network is established based on the infrastructure facilities of smart city, and global SV is chosen to represent the spatial correlation of measurements. APCA is utilized to create sensor clusters. The estimation group is formed by comparisons of Kriging variances to add sensors clusters so as to offer a good trade-off between accuracy and computational complexity. Simulation results illustrate the most suitable size of estimation group. APCA-OK outperforms standard OK in terms of efficiency, and it retain the accuracy as the latter. In future work, we will research more on revised REM construction methods for different applications, especially those based on distributed SVs, instead of global ones, for communication terminals scattered in smart city to overcome the constraints resulting from latency in communication channel.
Footnotes
Handling Editor: Peio Lopez Iturri
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the National Natural Science Foundation of China, Grant No. 61601491 and National Natural Science Foundation of China, Grant No. U19A2058.