
Abstract
Large amount of data are being produce by Internet-of-things sensor networks and applications. Secure and efficient deduplication of Internet-of-things data in the cloud is vital to the prevalence of Internet-of-things applications. In order to ensure data security for deduplication, different data should be assigned with different privacy levels. We propose a deduplication scheme based on threshold dynamic adjustment to ensure the security of data uploading and related operations. The concept of the ideal threshold is introduced for the first time, which can be used to eliminate the drawbacks of the fixed threshold in traditional schemes. The item response theory is adopted to determine the sensitivity of different data and their privacy score, which ensures the applicability of data privacy score. It can solve the problem that some users care little about the privacy issue. We propose a privacy score query and response mechanism based on data encryption. On this basis, the dynamic adjustment method of the popularity threshold is designed for data uploading. Experiment results and analysis show that the proposed scheme based on threshold dynamic adjustment has decent scalability and practicability.
Keywords
Introduction
With the rapid development of Internet-of-things (IoT) sensor networks and applications, an increasing amount of data are generated and stored in cloud services. Cloud storage not only evolves into a major storage scheme but also provides IoT applications with abundant if not limitless storage capability. Duplicate data are almost unavoidable with thousands of IoT sensors working all day long. 1 Data sharing among users or devices has become a common requirement. These challenges are new to cloud storage providers (CSPs). As the amount of uploaded data increases, so does the extent of data redundancy. Statistics show that up to 60% of the data stored in cloud storage are redundant data, 2 and a large amount of cloud storage resources are consumed, which greatly increases the cost of storage and maintenance of the CSP, especially for IoT-sensor network–based applications. 3
In order to solve the above problems, the CSP generally adopts deduplication technology, 4 which detects identical data objects in the upload stream based on data redundancy. Deduplication enabled systems store only a single copy of the data and create links for other users (or IoT devices) who upload the same data. Deduplication schemes can be classified into block-level 5 and file-level deduplication depending on the size of the objects. Compared with traditional data compression technology, deduplication eliminates not only data redundancy in files but also redundancy between files in shared data sets.6,7 However, some users are unaware of data security, resulting in a large amount of private data information being shared without the user’s consent. In recent years, large-scale data leakage events triggered great concern about privacy issues. 8 Therefore, how to protect user privacy while improving the efficiency of cloud deduplication for IoT applications has become a key issue. 9 Harnik et al. 10 first discussed the security problem of client-side deduplication. Since then, the subject has been extensively explored and it is still under investigation in methodological aspects and concrete applications as well. A deduplication scheme for encrypting upload data is proposed for the first time in Bolosky et al., 11 known as convergent encryption. In this scheme, the hash value of the data is used as the encryption key. However, the direct relation between the key and the data reduces the security of the scheme. In Xu et al., 12 the multi-client cross-deduplication scheme Xu-CDE was first applied for the encrypted ciphertext deduplication problem. 13 The scheme protects the security of private data in the scenario, where external attackers coexist with honest but curious servers. However, in terms of applicability, this scheme has the disadvantages of low encryption efficiency, and it lacks real-time authentication mechanism. In view of the above shortcomings, MRN-CDE (MLE based and random number modified client-side deduplication of encrypted data in cloud storage) was proposed, 14 which applies random number to ensure the instantaneity of the authentication credentials. In order to reduce the amount of computation in the encryption and decryption processes and to ensure data security, the scheme extracts the key from the original data using the KP algorithm 15 in the message locked encryption (MLE) scheme. In addition, some CSP provides users with client-side encryption options, allowing users or IoT sensor networks to encrypt the data before uploading them. This method can effectively protect data privacy. However, even identical plaintext can be encrypted into different ciphertexts by different users, which makes it difficult for the CSP to perform deduplication. Therefore, although the above scheme improves the security of cloud storage, the storage efficiency is still unsatisfying. 16
For the efficiency of deduplication, Stanek et al. proposed a scheme based on popularity partition. Data of different popularity are encrypted with different encryption methods, which can effectively improve the efficiency of deduplication. 17 The scheme assigns a fixed popularity threshold (T) to all data. When the number of copies of certain data in the cloud reaches T, the data are considered to be popular; otherwise, it is regarded as nonpopular data. The cloud server only performs deduplication on popular data, which better protects data privacy while improving the efficiency. The PerfectDedup scheme was proposed by Puzio et al. They used perfect hash function 18 to query the popularity of data with the assistance of a trusted third party. However, the introduction of a trusted third party increases the communication overhead of the CSP, and it causes new security risks. In response to the above problems, Liu et al. 19 proposed a secure deduplication scheme that does not require any third-party server. This scheme uses a password-authenticated key exchange (PAKE) to achieve cross-user key delivery and then cross-user data deduplication. This solution eliminates the dependence on third-party servers and improves its practicability. However, for some popular data, users also need to encrypt them and perform PAKE protocol with other users, resulting in additional computational overhead. Existing popularity-based deduplication schemes do not perform deduplication operations until the total number of data copies reaches the threshold T.17,18 But in real-world applications, the amount of privacy data that users upload to the cloud is massive, and as a result, nonpopular data also occupy a large amount of storage space in the cloud. To further reserve cloud storage space, deduplication schemes for nonpopular data were proposed, such as the elliptic curve-based encrypted data deduplication schemes in Zhang et al. 20 and Singh et al. 21 The scheme in Zhang et al. 20 adopts an elliptic curve encryption algorithm, which is more secure and less computational intensive. Different encryption methods are used for popular data and nonpopular data. Client-side deduplication is used for popular data, which significantly reduces storage and bandwidth consumption.
In current practical cloud storage applications, the CSP simply sets a fixed threshold for all data uploaded, which leads to many problems. If the threshold is set too high, for data with low privacy, all copies need to be stored before the threshold is reached. If the threshold is set too low, data with higher privacy will be prematurely deduplicated, which may increase the security risk. Therefore, different thresholds should be set according to the privacy level of the data, and the user’s understanding of the privacy level should be considered at the same time. For example, a frequently used software installation package should have a low threshold, so that it can be quickly processed for deduplication, which minimizes the storage overhead without compromising user’s privacy. And when internal confidential files of a company are uploaded, according to the user’s understanding of the privacy level, the CSP could set a relatively large threshold for it, thereby effectively avoiding premature execution of deduplication and better protecting the user data. However, how to recognize the privacy level of each upload data and assign a reasonable threshold for the data according to its privacy level is still a difficult and open problem.
In summary, our work makes the following contribution:
We propose a deduplication scheme suitable for IoT sensor networks based on threshold dynamic adjustment to ensure the security of upload data and related operations.
We design the threshold dynamic adjustment mechanism, using the item response theory (IRT) to dynamically adjust the threshold. We use the query feedback mechanism to collect the privacy attitude of most users to determine a reasonable threshold for each data uploaded.
The concept of ideal threshold is proposed for the first time, which eliminates the disadvantages of unified threshold in traditional schemes.
The remainder of this article is organizes as follows. Section “System model and design goals” introduces the system model and design goals. Section “Preliminary knowledge” gives the preliminary knowledge of the scheme and its related formulas. Section “Deduplication scheme” elaborates on the design of our scheme from three parts: privacy score query, data uploading, and privacy score calculation. Section “Security analysis” details security analysis. Section “Performance evaluation and experiments” gives the experimental comparison and analysis. Section “Conclusion” summarizes the work and draws conclusions.
System model and design goals
System model
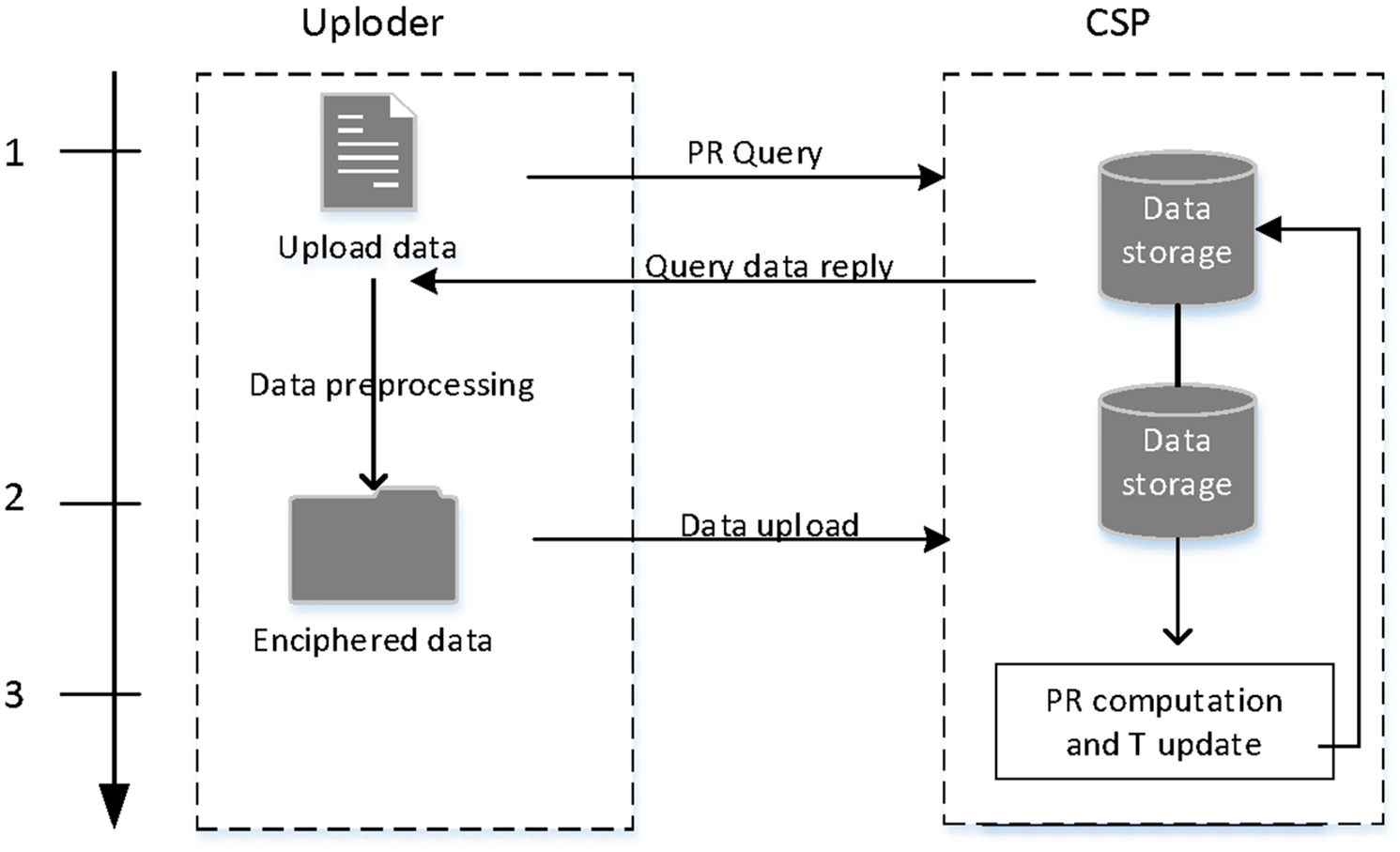
The system design is based on the IoT sensor network. The system model of this scheme only involves two types of entities: upload user and CSP. Upload user is an abstraction for IoT device, but sometimes it is an actual user in the IoT sensor network. When the system is established, the upload user can interact with the CSP. During the interaction, the upload user can play two roles: data uploader or data observer, and the CSP can only provide data storage and data sharing services for the upload user, without knowing the exact content of the data. The system model is shown in Figure 1.

System model.
This model introduces the concept of privacy scores (PR). 22 The PR of the data M is an indicator of privacy risk, and the larger the PR, the higher the privacy of the data. In the IoT sensor network, privacy risk should be measured for data generated by various sensors or devices. In the stage of data uploading, the user sends an upload request to the CSP and calculates the query label of the data using the elliptic curve encryption algorithm. After receiving the upload request, the CSP performs data query and ciphertext comparison, and detects whether M is the first uploaded without leaking the data content. If the CSP finds that the data are stored in the cloud, it returns a suggested PR to the user. The user uploads the encrypted M and its PR rating to the CSP together. After each uploading operation, the CSP adjusts and updates the data’s PR to serve as the feedback information for the subsequent upload user. After consecutive upload and adjustment, each data will acquire a corresponded PR that tends to stabilize gradually and meets the anticipation of most upload users. The CSP calculates the popularity threshold T for M based on PR and performs deduplication operation according to the actual value of T. This not only reduces the consumption of storage space but also avoids the leakage of privacy data. In the data observation stage, only the user who has uploaded the data can make a query request to the CSP, and the CSP returns the encrypted data. Furthermore, although we assume that the CSP is honest but curious, it can perform offline analysis to infer additional information. Therefore, the CSP is not trusted from the fact that users do not expect their private information to be known by any third party.
Design goals
In order to better protect data privacy, the scheme should have the following characteristics:
Confidentiality of uploaded data: uploaded data require a certain encryption operation.
Queryability of privacy scores: when users upload data, they can query and get a reasonable privacy score from the CSP as a reference.
Updateability of privacy scores and thresholds: the privacy scores and thresholds of data can be updated in real time according to the specific upload situation.
Preliminary knowledge
IRT and its characteristics
IRT 23 is a famous psychological theory, which is often used to analyze the questionnaire results and test data. This theory can infer the probability that the tested user will correctly answer a given question by measuring the ability of the tested user and the difficulty of the specific test item. Moreover, it has been proved that IRT can be applied in cloud computing scenarios. 24
The Rasch model
25
is one of the most common IRT models. It assumes that the probability function of correct response is only related to

Therefore, IRT has two notable features:
Group stableness: the difficulty of the item is a natural attribute of the item, which is independent of the tested user’s response. In other words, the parameters of an individual project are not only applicable to users current being tested but also to other types of users. 26
User independence: one tested user will not affect the answer of another tested user to a question, and the answer only depends on the question itself.
General sensitivity calculation method
Generally, the more sensitive the data are, the less likely for the user to disclose it. As shown in equation (2),

where N is the number of data items.
General visibility calculation method
In the case where the answer to the question is a binary value, we usually estimate the probability to calculate the visibility of the data.
27
Assuming that the test project and the tested users are independent of each other, that is, in a test survey, the chance of the tested user answering each question is the same. We can calculate the value of

where N is the number of data items and n is the number of users under test. The method of calculating the visibility above is to sample all possible response matrices according to the probability distribution statistically. In fact, the visibility is actually calculated by
Data privacy score
The privacy score (PR) of the data is a numerical representation of the overall privacy of the data, which is calculated. The privacy score generated for data i with user j is represented as

where operator ⊗ represents any monotone incremental combination of functions about sensitivity and visibility. The details of the calculation process are described in equations (2) and (3).
Bilinear mapping
Let
Bilinear:
Computability:
Non-degenerate:
Deduplication scheme
Overview
When a user uploads encrypted data to the CSP, the CSP can check whether the data have already been stored using the query label generated by elliptic curve technique and return a suggested PR to the user according to data information in the database if it exists. Eventually, the user uploads the data and its privacy score to the CSP, and the CSP reaggregates the privacy score and updates the threshold for it. Based on the threshold and the current number of data holders, the CSP decides whether to store it or not. The scheme consists of three parts: (1) privacy score query, (2) data uploading, and (3) privacy score calculation and threshold update, as shown in Figure 2.
The overall design of the scheme.
Privacy score query
When a user uploads data to the CSP, the user can query the current PR of the upload data. The context-based privacy score query method is an optional solution. 24 Context refers to a summary and a general idea generated from a long list of words or content, and even further, it is a representative keyword combination sorted out from the entire upload data, the general form is (field1 = value1, field2 = value2, …). For example, if an upload data contains “Bob shared the final exam score in the class group with a desktop computer,” the context in the above example would be (sharer = Bob, subject = final exam score, observer = classmate).
In Harkous et al., 24 a scheme of data privacy query using context is introduced in detail. Before querying the degree of privacy, the user forms a query set of multiple virtual contexts and sends them to the CSP, to hide the actual request context. The context-based privacy score query only needs to replace the data privacy with the corresponding privacy score based on the above scheme. When the user queries the CSP for the PR of the data by means of the context, he should avoid sending the real context directly to the CSP, to prevent the CSP from associating the data sharing operation with the context, which reduces the risk of privacy data leakage.
Context-based privacy score query is easy to implement, but we usually assume that the CSP is honest but curious, and it can obtain specific data information uploaded by users through offline analysis and other operations. Therefore, we adopt the privacy score query mechanism of encrypted data. Based on the existing research results of our team, this mechanism uses the elliptic curve-based file label query scheme
20
to facilitate the privacy score query. In Zhang et al.,
20
a popularity query protocol without online trusted third parties is proposed. By constructing a bilinear map query label
Popularity threshold
In order to improve the efficiency of deduplication, the CSP assigns a popularity threshold T to the upload data. When the total number of upload users of a certain data M is greater than the T, we consider M to be a popular data. We use the more efficient convergence encryption and perform deduplication operations on it; otherwise, we consider M to be nonpopular, which has a high degree of privacy. In that case, M needs to be protected by semantically secure symmetric encryption.
Data uploading procedure
When the

The data uploading procedure in our scheme.
When
Privacy score calculation
In this section, we design the privacy score calculation method based on IRT, in order to ensure that the data’s PR meets the requirements of most upload users.
Because different upload data
For each parameter

In other words, we need to search for the data parameters
Similarly, on the basis that the sensitivity
Finally, we integrate it through formula (6) and calculate the PR that meets the public’s wishes 22

At the same time, current PR of the data is represented by

As the number of upload users increases, the threshold changes and gradually approaches
Because different upload data are independent of each other, the CSP can compute the PR in parallel, so the scheme is efficient and of practical feasibility.
The parameters used in the privacy score calculation based on IRT are estimated by likelihood function which satisfies the property requirement of group invariance. This makes the PR corresponding to different uploaded data directly comparable.
Security analysis
The scheme is designed to better protect the security of private data through threshold dynamic adjustability. Our proposed deduplication scheme makes it impossible for the CSP to be spoofed. The data could be obtained only by obtaining the query label of the data. Here, we mainly discuss the authenticity and differentiability of the query labels. The security theorem is as follows.
Lemma 1
For a safe hash function
Theorem 1
Authenticity of data query labels. Let the initial upload user
Proof
If
Assuming that adversary A is a malicious user, then A can get parameter X.
Assuming that adversary A is CSP, parameters
In both cases, adversary A cannot construct a query label satisfying equation
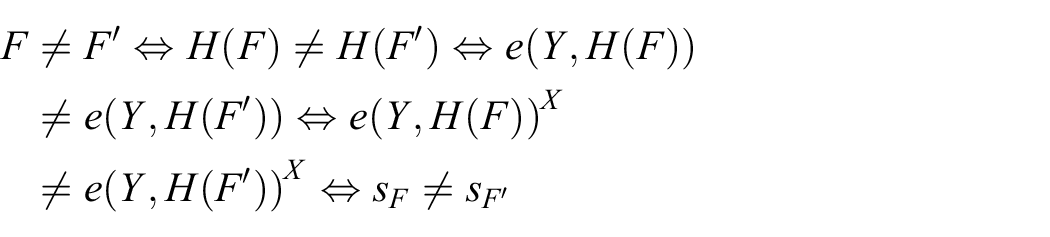
That is,
Theorem 2
Differentiability of query labels. Let the initial upload user
Proof
Suppose there is

If the above formula is valid,
Lemma 2
Compute Diffie–Hellman (CDH) problem. Suppose
Theorem 3
Security of data labels. CSP cannot attack the query label offline and get any plaintext information.
Proof
Let CSP execute an offline brute force attack on the query label
In addition, we also considered the situation of malicious scoring. We made simulations, and detailed results can be found in the next section.
Performance evaluation and experiments
The experiment uses PBC, 30 GMP, 31 PBC_bce, 32 and OPENSSL 33 function libraries, which are implemented by C++ language. It is deployed to a Tencent’s cloud storage server, which is equipped with 4 GB memory, 4-core CPU, 1 Mbps bandwidth, and 1 TB storage. In order to make it easier for users to understand and to operate, our scheme adopts a more user friendly design in the implementation of PR. When the upload user scores some data for the PR, it is only necessary to choose a value between 1 and 100 as the score. The system automatically converts the data and updates the PR and T. In accordance with the percentile scoring habit, users can understand the privacy of upload data more intuitively. Considering the difficulty of sample selection, we generate random numbers to simulate the PR of different users on a certain upload data.
Data set
In view of the problem that different data have different ideal thresholds, we carry out a comparative experiment on the overall PR and T with various of data. We use three sets of random numbers to simulate the PR of different data. Each data set consists of 100 random numbers. The first data set consists of random numbers from 80 to 100, which simulates the user’s PR for data with a high privacy level. The second data set consists of random numbers from 0 to 20, which simulates the user’s privacy score of certain data with a low degree of privacy. The third data set is composed of random numbers from 1 to 100, which simulates the random distribution of upload users’ privacy scores on given data.
In the performance comparison experiment, we choose 1000 files of 10 MB as the upload data, in which the ratio of data with lower privacy to data with higher privacy is about 3/2. Other schemes adopt the unified popularity threshold and set it to
Experimental analysis
The data of the above three groups of experimental data sets are simulated by uploading and dynamic adjusting threshold, respectively, and the changes of the whole privacy score and T value of the data are compared and analyzed.
Figures 4–6 are derived from the data set with the interval of (80–100), where Figure 4 shows the change of the PR with the number of upload users. The curve in Figure 4 is connected by 100 data points. The ordinate of each point is the result of the PR adjustment according to the feedback of the user. The horizontal coordinate is the number of users currently uploading data, and Figure 5 shows the relationship between the dynamic adjustment value of T and the PR. The curve in the figure shows how T of the data changes with the PR. The meaning of the ordinate of each point in the figure is the same as that of Figure 4, and the abscissa is the dynamic threshold of the data calculated according to the privacy fraction. The dynamic threshold T of the data is calculated as in equation (7). T is proportional to the PR of the data, where
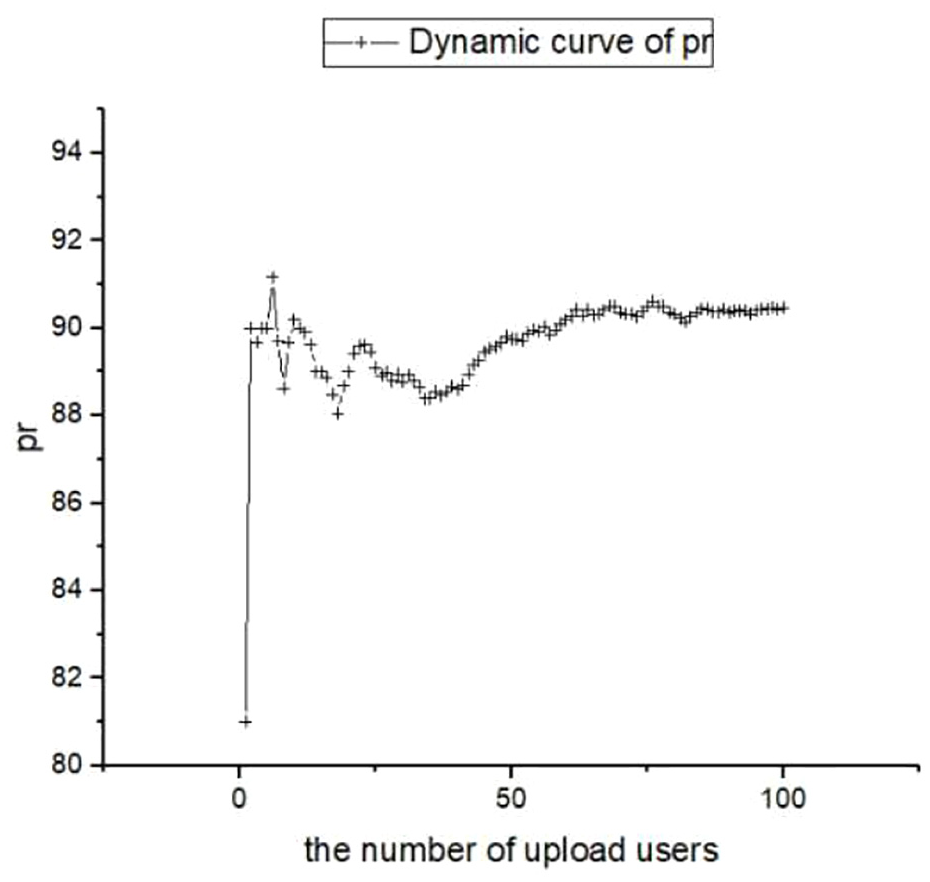
Privacy score with the number of upload users (80–100).
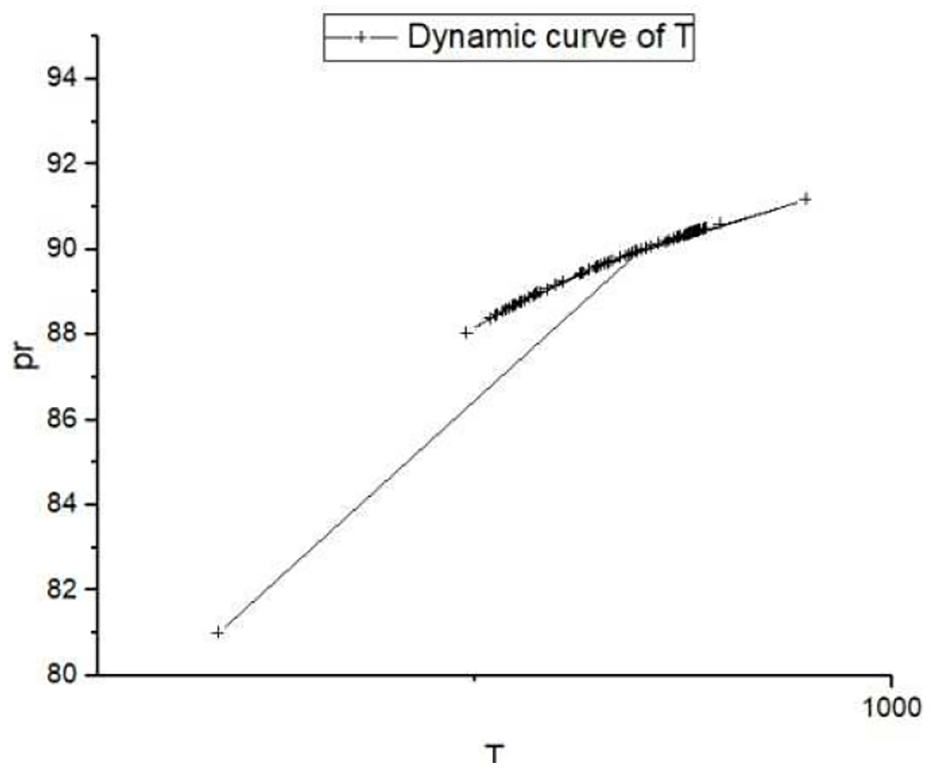
Relationship between threshold and privacy score (80–100).

Actual deduplication threshold (80–100).

Privacy score with the number of upload users (0–20).

Relationship between threshold and privacy score (0–20).

Actual deduplication threshold (0–20).

Privacy score with the number of upload users (1–100).

Relationship between threshold and privacy score (1–100).
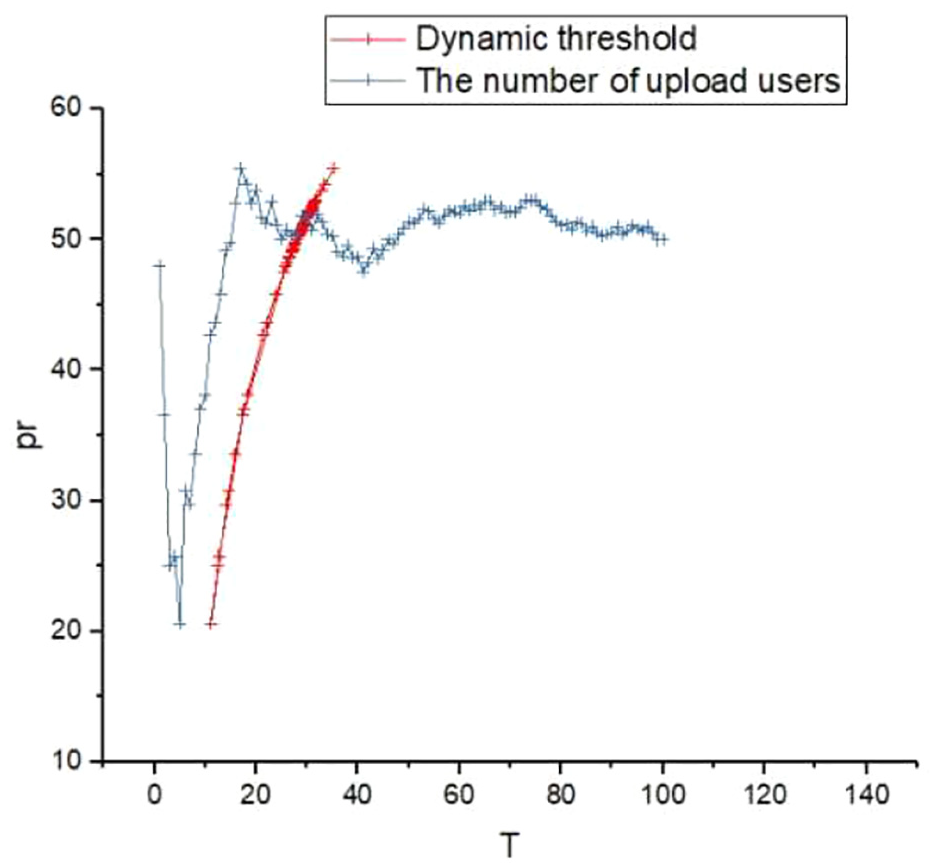
Actual deduplication threshold (1–100).
In Figure 4, all users are uploading data with low degree of privacy, but there are still small differences in the specific case in the value of numerical PR. We assume that each user will eventually choose a number from (80–100) as its PR. When the number of upload users is small, the PR chosen by the user has a greater impact on the overall PR. As the number of upload users increases, the impact of the PR chosen by a single user on the overall PR decreases. Finally, the PR is stable at about 90. Similarly, Figure 7 represents a situation where the overall PR is high, and it is stable at about 11. The curve in Figure 10 represents the PR of all users for some data which are not unified. From the curve in the figure, it can be seen that under the premise of inconsistent user opinions, when the number of upload user is small, the privacy score adjustment fluctuates greatly. As the number of upload users increases, the impact gets smaller, and the overall PR of the data will eventually be stabilized.
In Figures 4, 7, and 10, when the number of samples is large enough, T tends to stabilize as the number of users increases. This value is only related to the nature of the data and the user’s concern for privacy. The results in Figure 10 further illustrate that the final PR of data is determined by the user’s attitude. In the case of a large user population, the attitude of individual users (reflected by the score) has little impact on it. As can be seen from Figure 6, when the privacy level of data information is high, there is no intersection point between the two curves, that is, the data are not subjected to the deduplication operation, which protects the security of private data more effectively. According to Figure 9, when the data privacy level is very low, the threshold for actually deduplication is very small, which can effectively reserve cloud storage space. From Figures 10–12, it can be seen that when some upload user has a different attitude toward the privacy of certain data, the system will determine an appropriate threshold for the data according to the attitude of the majority. Therefore, on the whole, the scheme is feasible and applicable.
Anti-abuse experiment
The anti-abuse experiment mainly tests the anti-abuse capability of the scheme from the aspect of malicious scoring. We assume that a malicious user deliberately sets the privacy score to 100 when the user privacy score is generally low ((0–20) or sets the privacy score to 0 when the user privacy score is generally high (80–100)) We tested the impact of malicious user scoring in three different settings, in which there are 2%, 3%, and 4% malicious users, respectively. The experimental results are shown in Figures 13 and 14. Figure 13 reflects the situation where some malicious user intentionally chooses a larger privacy score when uploading data with a lower privacy score. Figure 14 reflects the situation where some malicious user intentionally chooses a smaller privacy score when uploading data with a higher privacy score. To facilitate better observation, we assume that malicious users send their own malicious ratings at the beginning. As can be seen from the Figures 13 and 14, the higher the proportion of malicious users is, the greater the impact on the privacy score is. The greater the population of upload users is, the minor affect the malicious score causes. When the number of upload user exceeds 70, the four curves in the figure have little difference, which indicates that the scheme has anti-abuse capability.

The impact of malicious ratings on privacy score (0–20).
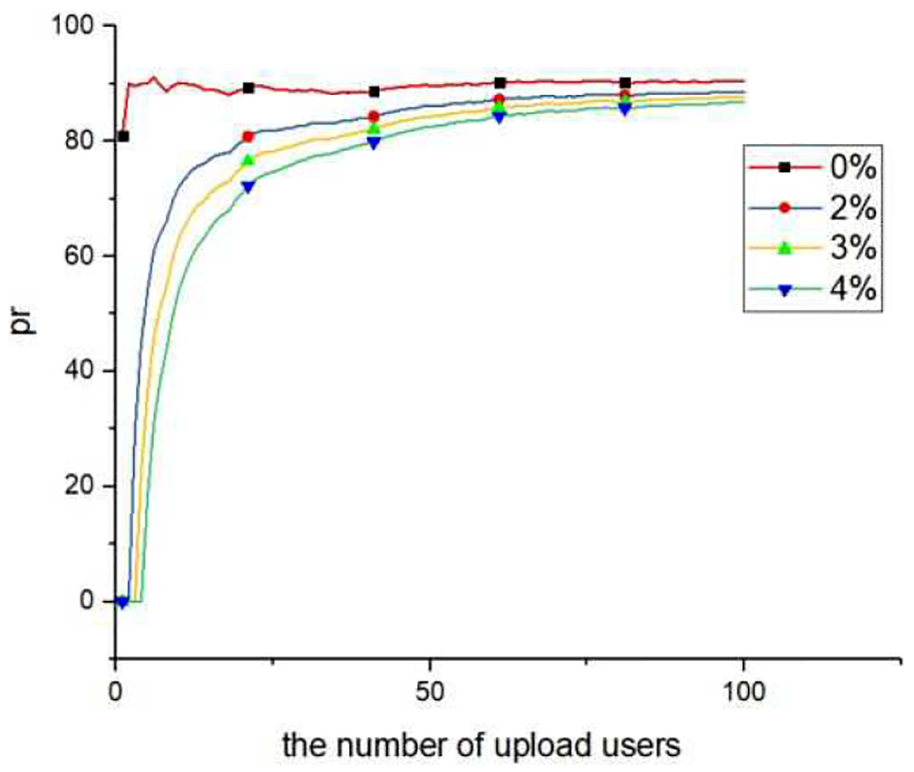
The impact of malicious ratings on privacy score (80–100).
Performance comparison
By uploading 1000 files of 10 MB, the total time consumption of our scheme is calculated and compared with that of other schemes, namely the PerfectDedup scheme, the common popularity threshold-based deduplication scheme, and the Xu-CDE scheme. The experiment is repeated for 10 times and the average result is acquired as the final result, which is shown in Figure 15. In the data encryption phase, the time consumption of the four schemes is similar. In the query stage, our scheme has advantages over other schemes that recognize data popularity. Finally, compared with other schemes, our design does not cause additional time overhead while improving the security of the deduplication operation.

Performance comparison of our scheme and other schemes.
Conclusion
In this article, we address the issue of deduplication threshold in the cloud storage scenario and propose a secure deduplication scheme for IoT sensor networks based on threshold dynamic adjustment. The concept of the ideal threshold is proposed for the first time, and the IRT is applied. By uploading the user’s feedback on the data privacy level, the privacy score can be dynamically adjusted, thereby calculating and adjusting the threshold of the deduplication. This scheme can speed up the deduplication stage for data with lower privacy, while data with a higher extent of privacy can be better protected. Experiments show that our scheme not only improves the security of deduplication operation but also avoids additional time overhead. Compared with other schemes, our scheme is more practical for real-world applications.
How to improve the efficiency of data deduplication for IoT applications while ensuring data security will be studied in future works.
Footnotes
Handling Editor: Vishal Sharma
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (61702294), the Shandong Provincial Natural Science Foundation (ZR2019MF058), and the Open Project Program of The State Key Laboratory of Integrated Services Networks (ISN19-14).