
Abstract
Positioning by wireless sensor network is one of its main functions and has been widely used in many fields. However, when signal propagation is hindered, serious errors, non-line-of-sight errors, occur. In order to solve this problem, this article proposes an improved particle filter algorithm, which introduces the idea of residual analysis to improve reliability. The algorithm assigns weights to the particles based on the residuals and selects the appropriate particles. In addition, the non-line-of-sight error parameter
Introduction
Wireless sensor network (WSN) is a hot topic in recent years. By using sensors to collect data, it is easy to obtain various information of the monitored area. Positioning 1 is one of its main functions and has been widely used in many fields. It uses two classes of nodes: fixed nodes and mobile nodes. The fixed nodes are distributed in the positioning area, the coordinates are known, and the mobile node is fixed on the positioning target.
Traditional methods have some errors in the actual situation: one is the measurement error, which is caused by system noise or measurement noise; the other is the non-line-of-sight (NLOS) error, which is the main challenge in positioning. It occurs when the signal propagation is hindered by some obstacles. In different scenarios, the NLOS error is subjected to different distribution functions. In order to minimize the impact of NLOS errors, some new algorithms have been proposed and they can be divided into two classes generally: one is to detect and select measurements which have no NLOS error. Shi et al. 2 used channel visual information to improve positioning accuracy. A recurrent neural network was proposed in Choi et al. 3 ; it proposed a recurrent neural network (RNN) model, which takes a series of channel state information (CSI) to identify the corresponding channel condition. Based on distributed filter, a new NLOS recognition algorithm was proposed in Pak et al. 4 ; it proposes a new NLOS identification algorithm based on distributed filtering to mitigate NLOS effects, including localization failures. Momtaz et al. 5 proposed a new algorithm based on subspace method to identify and eliminate NLOS errors.
The other is weighting data with unknown propagation status. Tomic et al. 6 proposed a positioning method using received signal strength (RSS) and angle of arrival (AOA). The positioning problem was transformed into the framework of a generalized trust region sub-problem in Tomic and Beko. 7 Abu-Shaban et al. 8 proposed a closed estimator for locating mobile stations (MSs) through three base stations (BSs) in a cellular network. There was a two-stage closed-form estimator to localize an MS by three BSs in cellular networks. It used a distance-dependent bias model to derive a range estimator as a first step. Then it used trilateration to find an estimate of the MS position. Ding and Qi 9 proposed a new convex optimization model. Wang et al. 10 proposed a deviceless wireless sensing system based on multi-domain features. Wang et al. 11 developed a new robust optimization method source location.
However, the first method will loose a lot of measurement data, resulting in lower positioning accuracy. The second method does not consider the signal propagation state, the weight does not reflect the actual situation well, and the adaptability of the algorithm is not strong. The article proposes an improved particle filter (IMPF) algorithm to solve these problems. The main innovation of the article lies in two points: it reduces the influence of NLOS error on positioning, and it has a great influence on the positioning accuracy, but there is no related paper to discuss it. All the sensors share the generated particles, so the computational complexity of the algorithm does not increase rapidly as the number of nodes increases. Different from traditional particle filter, in the article, some reasonable particles are selected to positioning by making two selections based on residual analysis. These particles will have weights based on the residuals. The selection reduces the influence of the NLOS error and the target is localized by the particles. The simulation is performed under several different NLOS errors, and results show that the algorithm is superior to Kalman filter (KF) and particle filter (PF).
Signal model
The propagation conditions of wireless communication systems are usually divided into two environments: line of sight (LOS) and non-line of sight (NLOS). In the case of obstacles, the wireless signal can only reach the receiving end through reflection, scattering, and diffraction, which we call NLOS communication. At this time, the wireless signal is received through multiple channels, and the multipath effect causes a series of problems such as delay in synchronization, signal attenuation, polarization change, and link instability, which are NLOS errors in Dou and Lei. 12
As shown in Figure 1,

Signal transmission model.
Ideally, the distance between the mobile node and the ith fixed node (i = 1, 2, …, N) at time k is defined by equation (1)
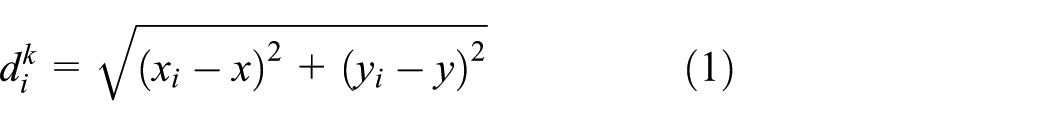
However, there are some noises in practical applications, including system noise and measurement noise. In the LOS state, the measured distance is defined by equation (2)

where
In addition, the direct path between the fixed node and the mobile node may be blocked by obstacles, as shown in Figure 1, and this propagation mode is NLOS. The signal can be diffraction, reflection, or refraction, and the distance will increase as shown in equation (3)
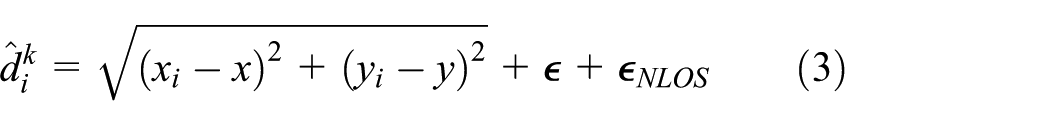
where
When it is a Gaussian distribution

where
When it is uniform distribution

where
When it is exponential distribution
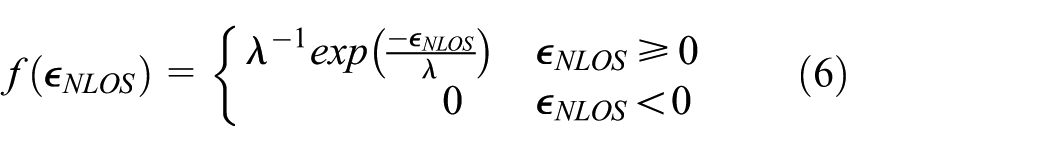
where
IMPF algorithm
Particle filter
The PF is developed in the late 1990s. It is another form of implementation of recursive Bayesian filtering. 14 It uses a set of particles (also called samples) to represent the posterior distribution of some stochastic process given noisy and/or partial observations. The state-space model can be nonlinear, and the initial state and noise distributions can take any form required. PF techniques provide a well-established methodology.15–17
There are many studies about it in positioning systems. A new fusion-simulated multi-feature-based improved simulated annealing PF tracking algorithm is proposed in Zhao et al. 18 Li and Liu 19 proposed a new PF algorithm that combines the traditional PF algorithm with the KF algorithm. Liu 20 proposed a Gaussian and PF pre-detection tracking algorithm called the Gaussian sum particle filter–track before detect (GSPF-TBD) algorithm.
Parameter description
Suppose there are P particles and N fixed nodes. At time k, the measured distance between the mobile node and the ith fixed node is

Description of the experimental scenario.
Particle weighting
The particle weight is related to the positioning result. Unlike general PF, IMPF obtains particle weight by residual analysis rather than Gaussian function. The whole process is implemented as follows:
Calculate the distance

Calculate the residuals of the pth particles of each fixed node and add them together. Define it as the residual of pth particle, denoted as

Find the reciprocal of

Particle selection
First selection
When all the particle weights are obtained, it will make the first selection. As the weight indicates the possibility that the particle is suitable for mobile node, first selection chooses some particles with larger weights and defines the average weight as threshold. Given the generated P particles and their weights W, first selection will choose S particles from them.
First selection chooses some particles with larger weights, which are reasonable at the overall level. However, once there are several fixed nodes that are inaccurate in determining the particles, some unreasonable particles can also pass first selection. Therefore, a second selection is necessary.
Second selection
The probability of NLOS errors can be estimated using particle residuals. It is assumed that the state where the residual is greater than the average contains the NLOS error. The residual ratio that is considered to contain the NLOS error is recorded as
The particle number will be checked before positioning begins. When the propagation state is terrible, most propagation between the fixed node and the mobile node have NLOS errors, and when no particles are left after selections for the contradiction, then particles selected in first selection are used; otherwise, those that are selected in second selection are used. See Table 1 for fake code of related algorithm.
Alogrithm second selection.

Location estimate
Least squares method
It is a mathematical optimization method. It finds the best function match for the data by minimizing the sum of the squares of the errors. A typical class of functional models is the linear function model. Location estimate algorithm is based on linear least squares (LLS).
Consider the overdetermined equations
Location estimate
Assuming that first selection chooses S particles and second selection chooses Q particles, and the retained particle number
Before the positioning begins, the retained particle weights will be normalized, and the weight of pth particle at time k is denoted as

We can get the distance

Then by calculating equation (11), we get equation (12)

The above equations can be expressed by the linear equation

Finally, the estimated coordinates of the mobile node is

Particle replication and motion
Once the positioning is complete, the retained particles will be utilized for next positioning. Therefore, construct replication layer to determine the particle replication process. The length of every layer is the weight of the particles. As the normalization of weights, the total length of all layers is 1. When constructing a layer, a random number satisfying uniform distribution from 0 to 1 is generated. Random numbers fall into some layer, and the corresponding particles are copied once. It can ensure that particles with larger weights have more chances to replicate while avoiding local optimization.
After the copying process is completed, the new particles will be distributed in a small range, avoiding excessive concentration of the particles. The variance of the coordinate obeys a Gaussian distribution with a mean of 0 and a variance

Simulation
The simulation runs on MATLAB, which evaluates the performance of the algorithm and compares it to the KF and the PF. The position of each Monte Carlo-operated fixed node is evenly deployed in a space of 100 × 100 m2. Root mean square error (RMSE) as an indicator, defined by equation (16)

where
NLOS error obeys the Gaussian distribution
Figure 3 shows the positioning results of IMPF. Even if the fixed nodes are randomly deployed, in most cases, the estimated value of the algorithm is very close to the true value. When a step has large error, such as x = 80, it can also be corrected quickly, and a reasonable positioning result can be obtained without error accumulation leading to positioning failure.

IMPF positioning simulation results in 100 × 100 m2.
Figure 4 shows the cumulative distribution function (CDF) of the positioning error. It can be seen that the average positioning error of IMPF is about 2.5 m and that of KF and PF is about 4 m. The error of 90% in IMPF is less than 6.2 m, that is, under the given conditions, IMPF can basically control the error within 6 m, while that of PF is 10 m, KF exceeds 10 m. The positioning accuracies are obviously different. There is a cross point between the curves of PF and KF, probably due to particle distribution. Because some particles will deviate from the target, the PF curve is lower than the KF curve, but most of the particles are distributed near the target. In addition, KF is more susceptible to NLOS, which may also be the reason of the cross point.

The trend of CDF with increasing positioning errors.
The trend of RMSE with
Figure 6 shows the effect of the number of fixed nodes on the positioning error. With the increase in the number of fixed nodes, IMPF algorithm has better positioning results than KF and PF. As the number of fixed nodes increases, more fixed nodes are again in LOS conditions where KF will get a better localization result than PF. When the number of fixed nodes is 5, compared with PF and KF, the positioning accuracy of IMPF improves by 15.4% and 23.3%, and the fixed nodes continue to increase, and this number will also increase.

The trend of RMSE with the number of increasing fixed nodes.
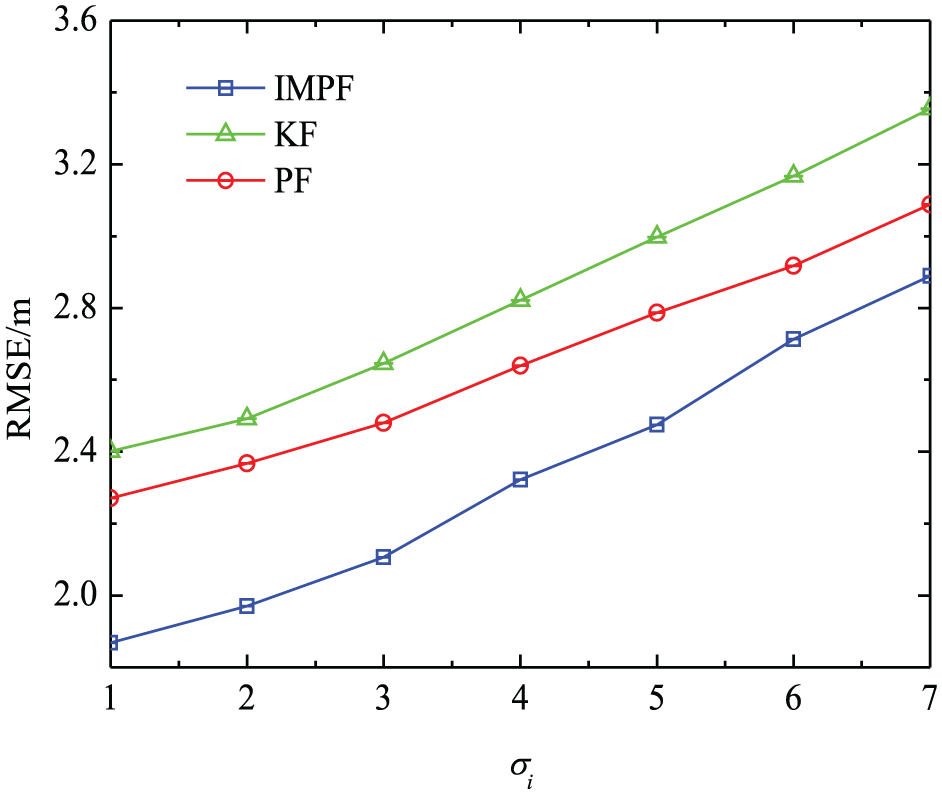
Figure 7 shows that the positioning errors increase with NLOS error. In Figure 7(a), the average of RMSE in IMPF is 2.024 m, but it is 2.554 and 2.379 m in KF and PF, respectively. The RMSE difference of the three algorithms remains basically unchanged. In Figure 7(b), the RMSE of IMPF increases slower than that of KF, and the larger the standard deviation, the more obvious the advantage of IMPF. When the standard deviation is 9, the positioning accuracy of IMPF is 25.1% higher than KF and 15.3% higher than PF.

The trend of RMSE with increasing NLOS errors: (a) mean of NLOS error and (b) standard deviation of NLOS error.
Figure 8 shows the effect of LOS propagation probability
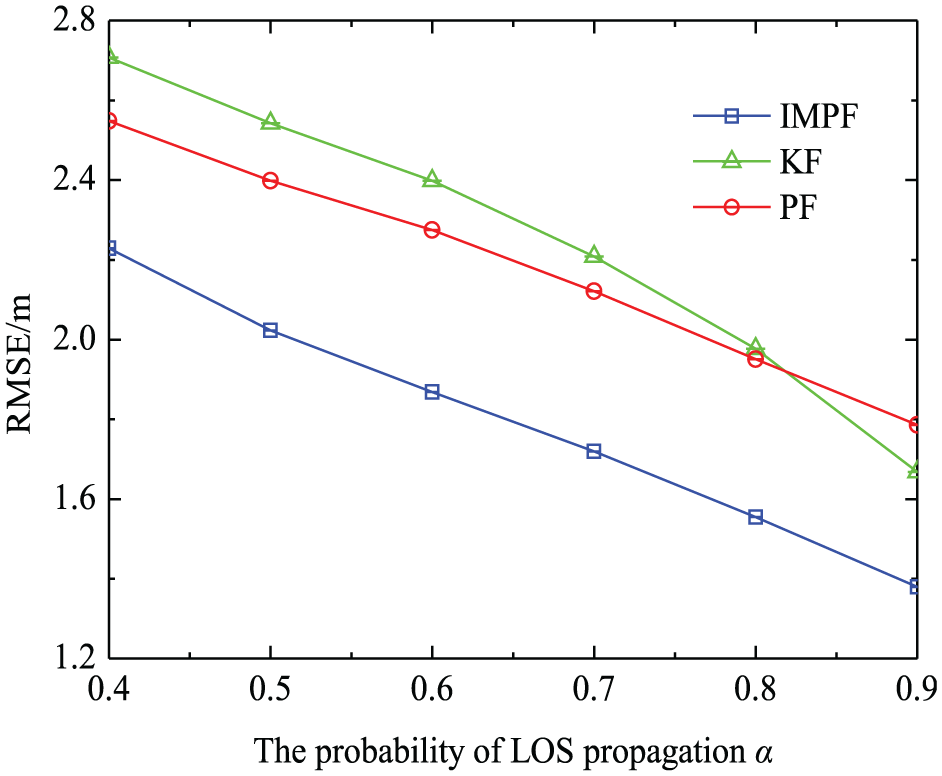
The trend of RMSE with increasing

The CDF of positioning errors.
NLOS error obeys uniform distribution
Figure 9 shows the CDF of the positioning error. The average positioning error of the IMPF is about 3.75 m. In the same case, the average error of KF and PF is about 5 m. IMPF achieves the lowest positioning error.The positioning error of the algorithm in Figure 10 is similar to that in Figure 6. It can be seen that the positioning error of IMPF is about 0.4 m lower than that of KF and about 0.1 m lower than that of PF. Compared with PF and KF, the positioning accuracy of IMPF is increased by 5.7% and 10.8%, respectively.

The trend of RMSE with
Figure 11 shows that RMSEs decline with more fixed nodes. The more fixed nodes are deployed, the less positioning errors are obtained, which is the same as Figure 7. KF and IMPF are greatly affected by the number of fixed nodes. When the number of fixed nodes increases, the positioning error will decrease rapidly. The performance of KF will exceed that of PF for the same reason in Figure 6. IMPF always maintains the lowest error throughout the change. When the number of fixed nodes is 10, the positioning accuracy of IMPF is improved by 12.7% compared with KF and 12.6% compared with PF.
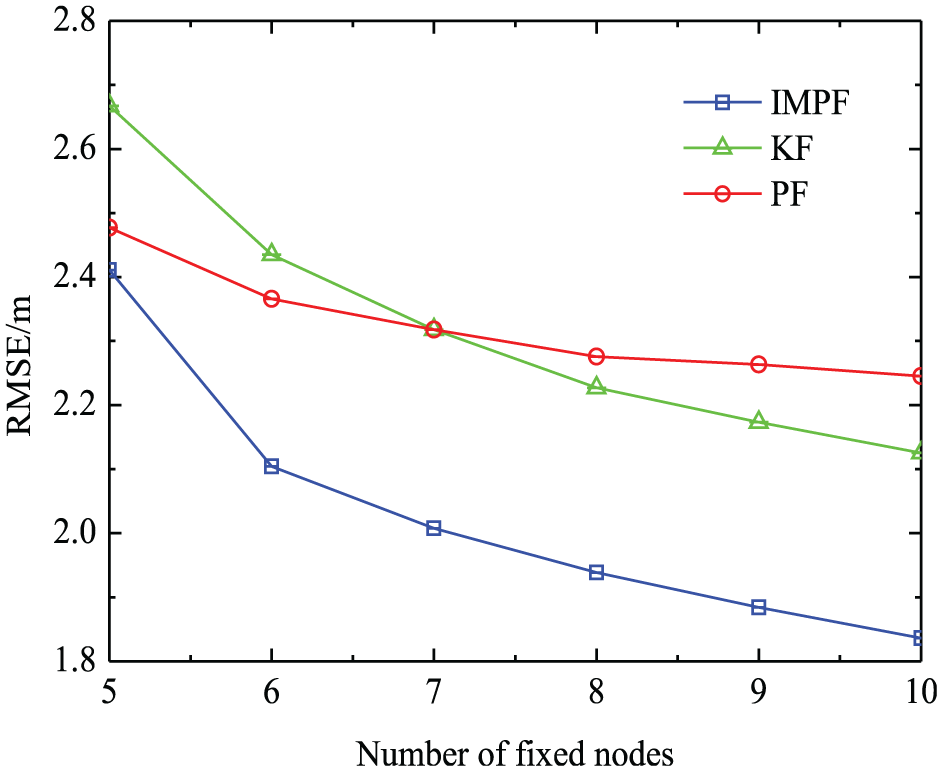
The trend of RMSE with the number of increasing fixed nodes.
The effect of the parameter
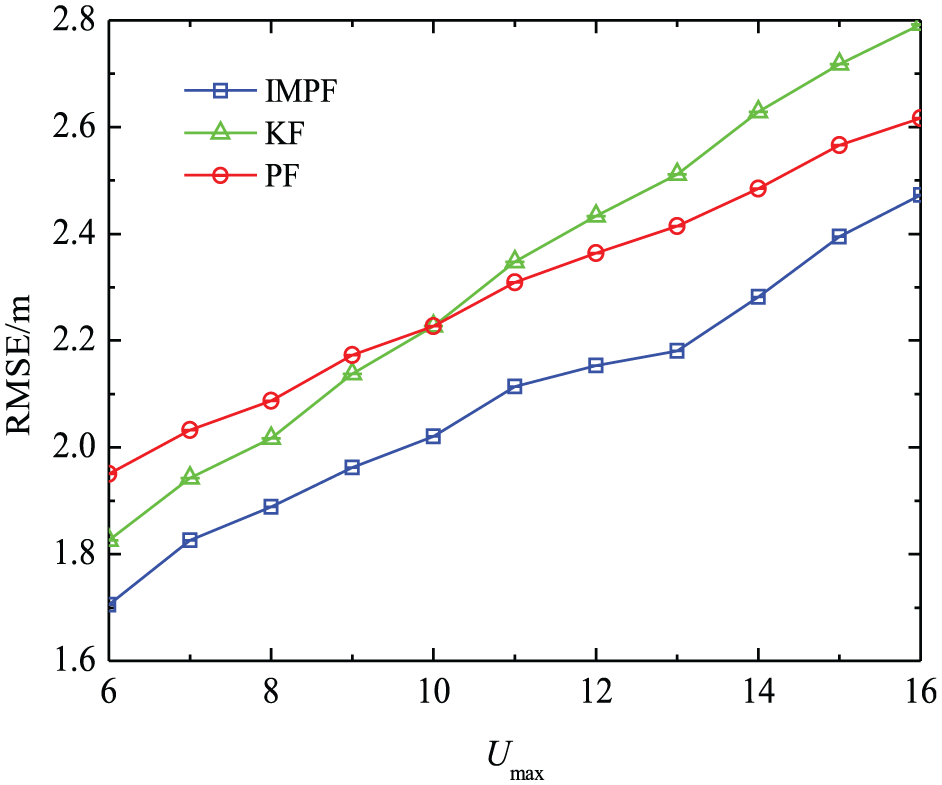
The trend of RMSE with upper limit
NLOS error obeys the exponential distribution
In Figure 13, when

The trend of RMSE with
Figure 14 shows the effect of distribution parameter when

The trend of RMSE with increasing exponential distribution parameter
Computational complexity analysis
In addition to positioning accuracy, computational complexity is also an important factor. The simulation uses runtime to express the computational complexity. The three algorithms are coded using MATLAB R2017a in the Windows 10 PC. The running time is calculated through the MATLAB
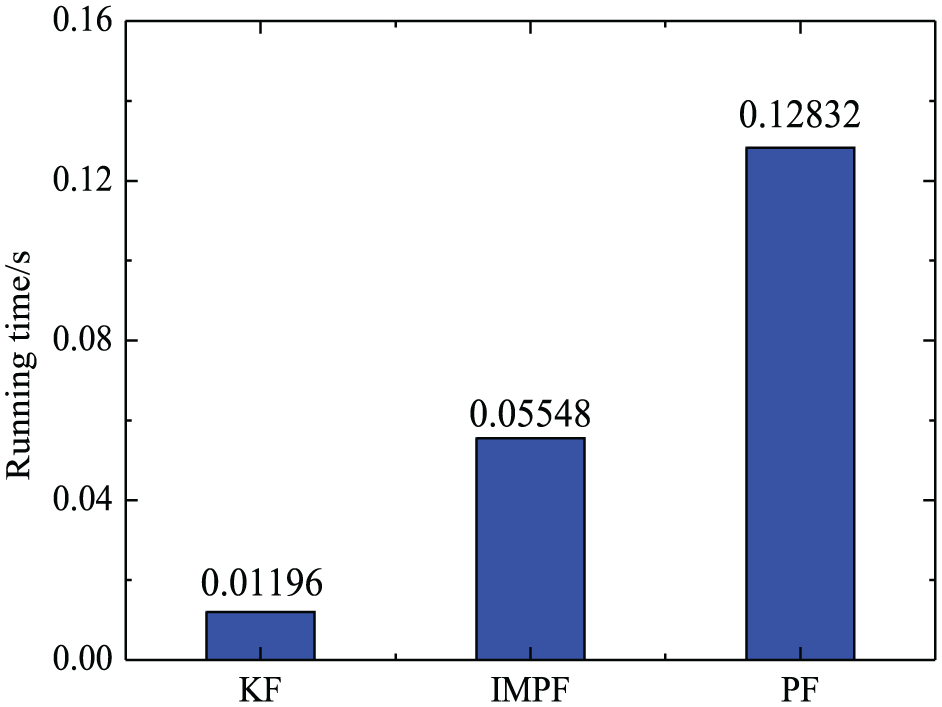
Comparison of running time in different algorithms.
Comparison with other positioning algorithms
To further demonstrate the performance of the algorithm, we simply compare it with several other algorithms—two novel positioning algorithms: sparse pseudo-input gaussian process (SPGP) 21 and import vector machine (IVM), 22 and an algorithm based on PF: joint particle filter (JPF). 23 SPGP is an NLOS mitigation method based on sparse pseudo-input gaussian process, and IVM is based on import vector machine.
All of them consider the problem of NLOS. Figure 16 shows the comparison of localization error. It can be seen that the positioning error of IMPF is better than that of JPF, which is also based on particle filtering. In addition, although IMPF is slightly worse than the other two latest algorithms, the three are very close. The average positioning errors of SPGP, IVM, and IMPF are about 0.85, 1.12, and 1.25 m, respectively.

Comparison of localization error with other algorithms.
We further compared the running time of IMPF, IVM, and SPGP, and the result is shown in Figure 17. IMPF runs significantly less time than the other two algorithms. Combining Figures 16 and 17, the performance of IMPF is better than other algorithms.

Comparison of running time with other algorithms.
Conclusion
The article proposes an IMPF algorithm, and residual is applied to the algorithm to enhance the accuracy of the positioning results. IMPF uses residuals to weight particles and select reasonable ones. Furthermore, the proposed algorithm does not make any assumptions about the distribution of NLOS errors, which means that IMPF is robust to different types of NLOS errors. Simulation results confirm the robustness of IMPF. In addition, IMPF estimates the distance from the mobile node to the fixed node, which can also be used to estimate the coordinates of the target.
The overall work of the future is to optimize the algorithm, because the algorithm is relatively simple, and the experiment only verifies our original idea. In order to get closer to the real world, we will try to add more channel noise to the simulation. At the same time, we will consider incorporating the algorithm into other new frameworks.
Footnotes
Handling Editor: Paolo Barsocchi
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National High Technology Research and Development Program of China (Grant No. 2012AA120802), National Natural Science Foundation of China (Grant No. 61771186), Postdoctoral Research Project of Heilongjiang Province (Grant No. LBH-Q15121), Undergraduate University Project of Young Scientist Creative Talent of Heilongjiang Province (Grant No. UNPYSCT-2017125), and Postgraduate Innovative Research Project of Heilongjiang University (Grant No. YJSCX2019-059HLJU).