
Abstract
Recently, support vector machines, a supervised learning algorithm, have been widely used in the scope of credit risk management. However, noise may increase the complexity of the algorithm building and destroy the performance of classifier. In our work, we propose an ensemble support vector machine model to solve the risk assessment of supply chain finance, combined with reducing noises method. The main characteristics of this approach include that (1) a novel noise filtering scheme that avoids the noisy examples based on fuzzy clustering and principal component analysis algorithm is proposed to remove both attribute noise and class noise to achieve an optimal clean set, and (2) support vector machine classifiers, based on the improved particle swarm optimization algorithm, are seen as component classifiers. Then, we obtained the final classification results by combining finally individual prediction through AdaBoosting algorithm on the new sample set. Some experiments are applied on supply chain financial analysis of China’s listed companies. Results indicate that the credit assessment accuracy can be increased by applying this approach.
Keywords
Introduction
Supply chain financing (SCF) is a recently emerged field, which is also a means of substituting for lower credit availability to play a more active role among small and medium firms and their corresponding banks. 1 SCF is different from traditional trade credit where one corporation extending own credit to the upstream or downstream corporation. The main attempt is to create cash flow for the supply chain and integrate bank loans to optimize both cost of capital and the availability within the given suppliers and buyers. 2 In recent years, some machine learning techniques have been widely applied on credit assessment area, including neural network approaches, 3 fuzzy theory,4,5k-nearest neighbors (K-NN), and evolutionary algorithm. 6
The literature reveals that support vector machines (SVMs) are new techniques to tackle credit risk problem.7–9 There are some papers focused on improving ability of credit scoring with using the intelligent optimization algorithms. Yao and Lu 10 proposed an SVM classifier method using neighborhood rough set, which is applied for credit scoring. Cao et al. 11 constructed an five-category loan classification (FCLC) learning scheme using improved SVM based on particle swarm optimization (PSO) to decrease loan risk of microfinance bank. Another major approach is the development of SVM ensemble models to solve the problem of credit risk. 12 Chen et al. 13 concentrated on the performance of ensemble techniques in the context of cost-sensitive credit scoring using different financial datasets. An approach, combining clustering and classification, is constructed to ensemble learning for credit granting decisions. 14 Wang and Ma introduced an random subspace into bagging (RSB)-SVM ensemble approach, which is based on bagging and random subspace and uses SVMs as base learner. The results show that models have a better performance. 15
The main viewpoints of above-mentioned studies focus on general credit assessment technique and ensemble credit scoring studies. In real-world finance credit datasets, imperfections or noise can also confuse a classification model in the training phase. 16 In classification datasets, we find two different types of noise, which are attribute noises and class noises. Attribute noises are regarded as some errors that are added to the erroneous attribute values or the missing attribute values. Class noises are represented by misclassification samples and contradictory samples. 17 Researchers have undertaken much work for decreasing the effect of noises. Almast proposed the fast and de-noise SVM method using fuzzy clustering method. The main idea is that the noisy data will be eliminated based on the change of the center of the convex hull that computed via the QHull algorithm. 16 Tang 18 proposed smaller weight or even zero weight to reduce noisy data or remove them. In other studies, statistical methods 19 and hybrid methods 17 are also proposed to reduce the class noises. In addition, several studies have deployed the attribute selection to eliminate the attribute noises used for credit scoring.20–22
Our proposal is different from previous method. We will remove two kinds of noise simultaneously. In the first stage, the principal component analysis (PCA) algorithm is introduced to reduce the attribute noise. Then, a clustering method is used to eliminate the class noise. In the second state, we adapt adaptive mutation particle swarm to optimize parameters of SVM classifiers (proximal support vector machine (PSVM)), which are used as component classifiers in AdaBoosting (AdaPSVM) to address risk assessment in SCF fields.
The remainder structure of the article is as follows: conventional SVM theory is introduced in the “Formulations of SVMs” section; fuzzy c-means (FCM) algorithm and the value of validity measure are presented in “The fuzzy algorithm and clustering validity measure” section; SVM-based ensemble model is formulated and improved with eliminating noise (EN) approach, which is discussed in “A novel AdaBoosting ensemble SVM model” section; experimental results and discussion are described in the “Experimental results and discussion” section; and conclusions are drawn in the “Conclusion” section.
Formulations of SVMs
Decision boundary of SVMs is the maximum-margin hyperplane for solving learning samples.
23
Its decision function is shown in equation (1). We construct and solve constrained optimization problem in order to obtain the optimal values of

{xi, yi} is training set of samples, where
Minimize equation (2), where C is the penalty parameter and ξ is the slack variable
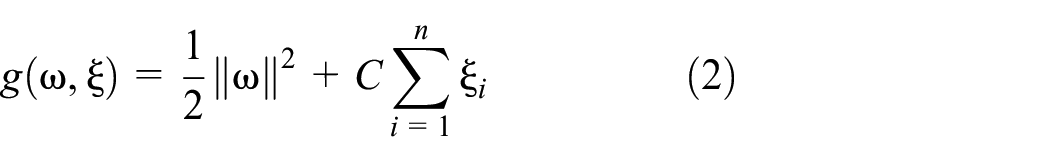
Subject to equation (3)

Combining the method of Lagrange multipliers, the minimization problem is shown as follows:
Maximize equation (4)
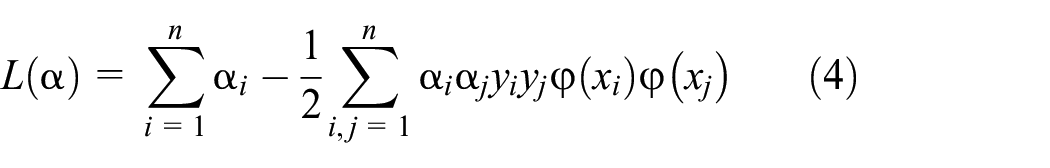
Subject to equation (5)

Next, equation (6) is the nonlinear decision function

In formula (6), we use the function

There are four kernel functions, among them, the radial bases function (RBF) has best performance in some applications,24,25 which is shown in equation (8). RBF kernel is used in this article. The performance of SVMs is affected by
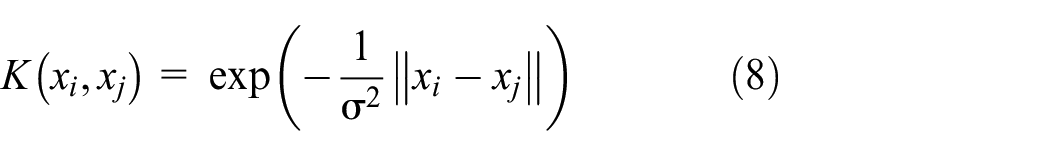
In order to illustrate the effect of noise on SVMs, two kinds of samples (Class A and Class B) are randomly generated with the default values of penalty parameter C and the kernel function parameter

(a) Visualization of SVM classification results of noiseless samples is shown, and (b) red dots denote noisy samples.
The fuzzy algorithm and clustering validity measure
FCM
FCM algorithm, as an unsupervised machine learning method, was improved by Bezdek. 26 The algorithm is defined to minimize an objective function as shown in equation (9)

where V is a vector and determined as
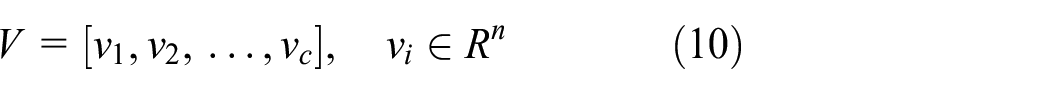
Then, we determine an inner-product distance as equation (11)

The objective function can be shown in equation (12), which be adjoined by the constraint

If

and

where
Partition index (SC)
There are three validity measures, namely, partition index (SC), Xie and Beni’s Index (XB), and Dunn’s Index (DI). SC (shown in equation (15)) can reflect the compactness and separation of clustering. 27 The smaller the value of SC, the better the partition
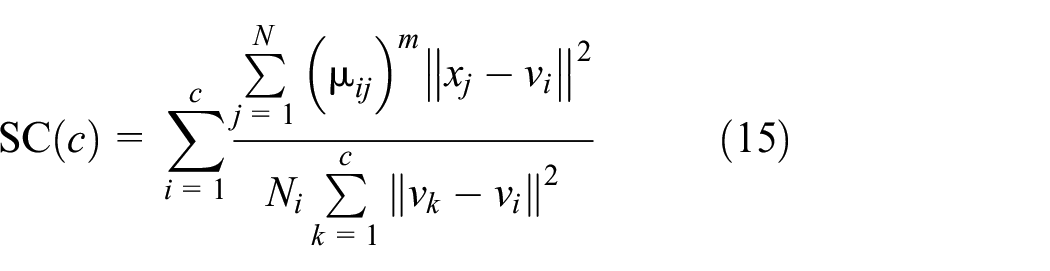
XB
XB (shown in equation (16)) is the ratio of the separation of clusters. 28 A lower value indicates a better separation

DI
DI (defined as equation (17)) can detect a good intra-cluster and inter-cluster relationships, which is the same with other cluster validity indices. 29 The larger the value of DI, the better the clustering
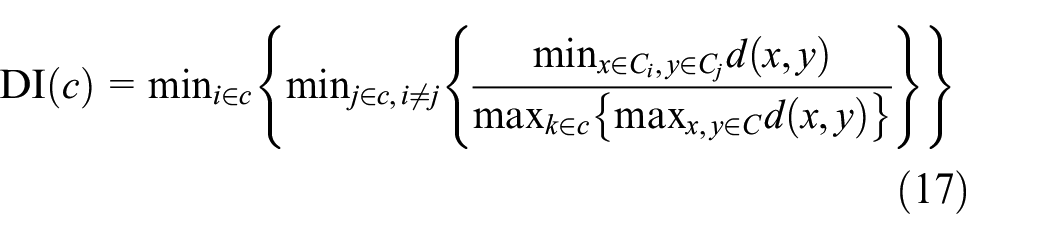
A novel AdaBoosting ensemble SVM model
Definition of a sufficient and non-noisy training set and selection of an effective component classifier are the most crucial problems to improve the ability of classification. In this section, the proposed ensembled SVM model improved with reducing noises for supply chain financial credit assessment (Figure 2). It contains three main stages: (1) data gathering and preparing, (2) reducing noises, and (3) modeling (classification). The full methodology of the model is as follows.

The block diagram of the proposed model.
Data gathering and preparation
According to the definition of SCF, supply chain participants include small and medium-sized enterprises (SMEs), supply chain relationship, and the core enterprises. Each participant in the supply chain has a different effect on the risk assessment, among which the core enterprises of the supply chain play an important role, SME directly or indirectly connected with the core business to obtain an influence. In our study, dataset is dependent on annual report of the listed company of China and information disclosure data from stock trading platform. In addition, in order to use more effectively the dataset for the proposed model, in here, there are some methods applied for data preparation as follows: (1) data transformation, (2) data normalization, (3) data visualization, and (4) new features creation.
EN method
EN method proposes that irrelevant or redundant attributes can be deleted to form a new subset of attributes by using PCA algorithm. Second, the mean of samples is regarded as the initial center. We use the FCM algorithm to detect the noisy samples and calculate the membership function. The specific steps are shown in Table 1.
Eliminate noises algorithm.
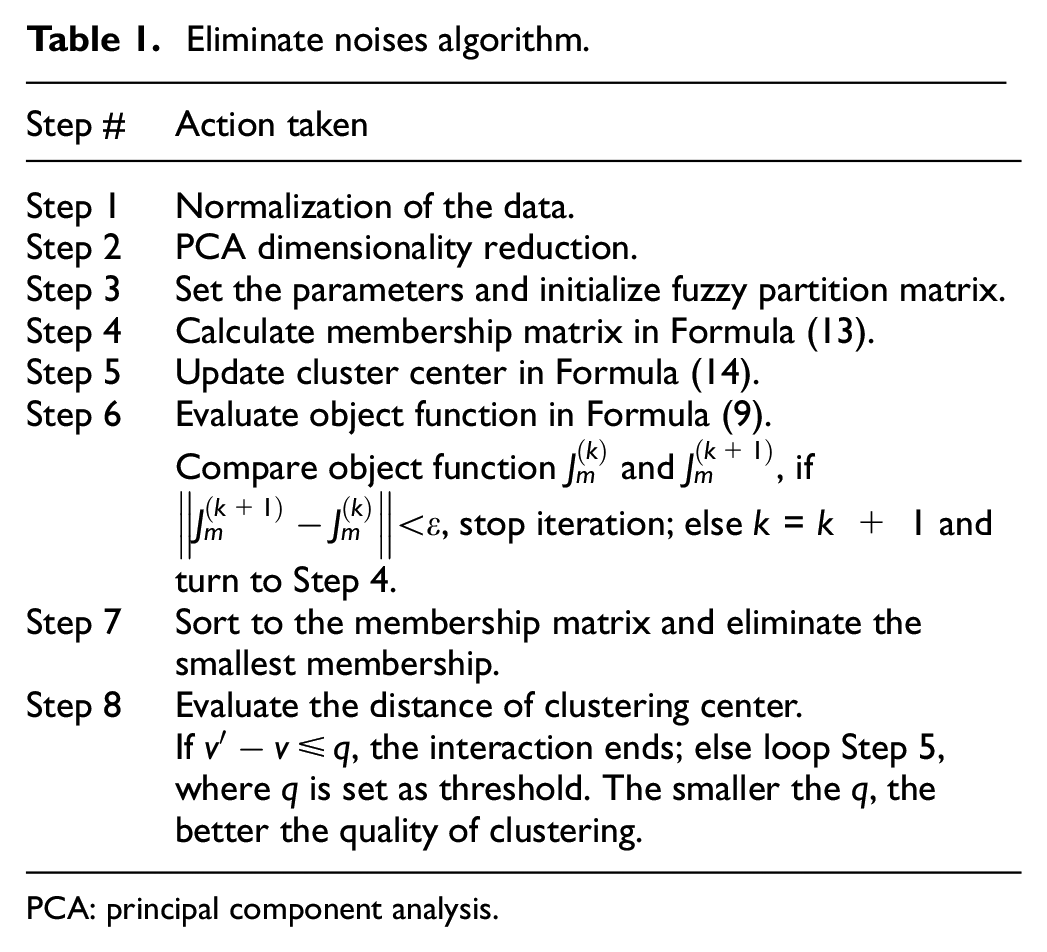
PCA: principal component analysis.
AdaPSVM modeling based on EN algorithm(EN-AdaPSVM)
As the most popular ensemble method, AdaBoosting adaptively adjust weights to enhance the ensembled capability after each Boosting iteration. Some studies use neural networks or decision trees as component classifiers. However, difficulties remained are as follows: how to avoid to overfitting phenomenon of neural networks and how to know about the suitable tree size of decision trees. In this article, we choose SVMs as component classifiers. One of the excellent kernels used in SVMs is the RBF kernel, which has kernel function parameter, the gamma
In this article, we call the proposed PSVM-based AdaBoosting ensemble model improved EN approach as EN-AdaPSVM, which is shown in Table 2. Given a set of training samples, we use PCA and FCM method separately to eliminate attribute and class noises. A weight distribution w will be maintained by AdaBoosting. PSVM is used as component classifier. The number of cycles is T. At cycle t, EN-AdaPSVM provides non-noisy training samples with a distribution wt that is updated according to the prediction results of component classifier ht. Finally, EN-AdaPSVM combines all the component classifiers into a single final hypothesis f.
EN-AdaPSVM algorithm.

EN: eliminating noise; PSVM: proximal support vector machine.
Experimental results and discussion
Samples and indices
At present, the major supply chain financial business focuses on auto, steel, energy, and telecommunication fields. Among them, auto manufacturing industry (AMI) is a typical organization. Motivated by this, in this article, the auto industry will be chosen as research object. The supply chain components of AMI can be divided into three parts: (1) the upstream enterprises: supplying automobile accessories, (2) the midstream enterprises: manufacturing vehicle assembly, and (3) the downstream enterprises: selling by distribution logistics. And core enterprises are in the midstream of the whole supply chain. In this article, the SMEs, which are studied, will be supplier of upstream and distributor of downstream.
The samples are selected from the SMEs in the listed companies. The whole auto manufacturing companies are seen as the core parts. At the same time, choosing the tire and engine manufacturing, hardware accessories, software manufacturing car selling, and so on, the total number of eligible companies is 58. Samples are divided into two classes: risky companies (R) and not risky companies (NR). The 232 samples (2012–2015) are grouped into training set and testing set (Table 3).
Number of samples.

NR: not risky; R: risky.
According to SCF definition, the article has selected 3 one-class indices, 9 two-class indices, and 28 three-class indices (as shown in Table 4). The indices include the condition of financing enterprises (indices from X1 to X17), funds and credit condition of core enterprises (indices from X18 to X23), and supply chain relationship (indices from X24 to X28).
Indices of SCF.

SCF: supply chain financing.
Dimensionality reduction method based on PCA
In this part, we first perform feasibility analysis for PCA. The overall number of samples (n = 232) is used for the exploratory factor analysis. In this study, the Kaiser–Meyer–Olkin (KMO) value obtained is equal to 0.802. The KMO value over 0.6 is effective. In addition, Bartlett’s test of sphericity is another measure of the correlation among variables, which reached statistical significance (<.05). Next, the underlying factor structure of SCF dataset will be investigated through PCA. Primarily, PCA shows the presence of 14 components with eigenvalues exceeding 0.85. From the 15 factors onward, the line is almost flat; thus, we choose 14 factors as main features of SCF.
Eliminating class noises by clustering algorithm
In this experiment, the number of noisy samples is less than 1/10 of the each class sample. At the same time, the number of selected noisy samples is 0.5% of the each class sample in each iteration. The total number of training subset is 147, including 94 NR samples and 53 R samples. Hence, we choose to eliminate one noisy sample of each class in each iteration. Figure 3 shows the result of elimination noisy samples. The NR samples are marked with red stars, and the R samples are specified with green crosses. The position of two centers of classes is shown with blue crosses; 12 noisy samples had been eliminated after six iterations, 147 training sample sets (shown in Figure 3(a)) is redefined, and it contains a total of 135 training samples as shown in Figure 3(d). It is obvious that existing noisy data can be eliminated using fuzzy clustering algorithm. As one can see in Table 5, based on the three indices (SC, XB, and DI) for fuzzy clustering, usually, the lower value of SC and XB indices and the larger value of DI index indicate a better partition or a better clustering performance. As one can see in Figure 4, based on the three indices for fuzzy clustering, the final dataset (135 samples) has the best clustering results when the noisy samples are removed through continuous iteration. In our proposed ensemble model, it is accordingly adopted as training set to train individual classifier.

(a) The dataset (the 145 training samples) and FCM clustering results with (b) the first clustering, (c) the third clustering, and (d) the final training samples. Red stars and green crosses express two different classes. Blue crosses represent clustering centers.
Values of SC, XB, and DI.

XB: Xie and Beni’s Index; DI: Dunn’s Index.
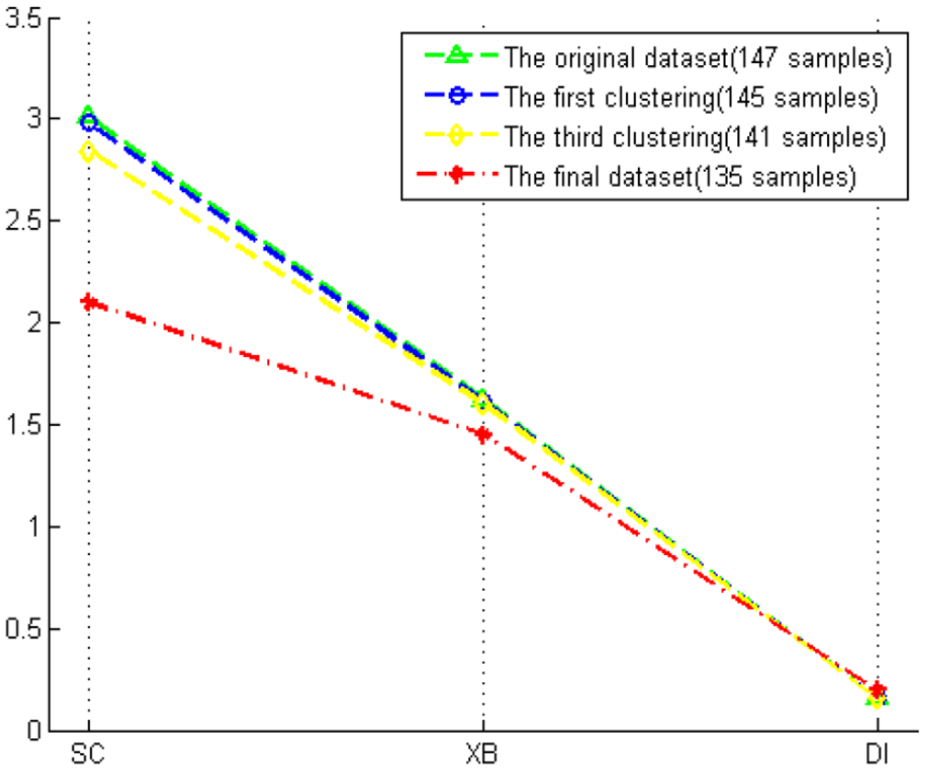
Clustering indices of different sample sizes.
SCF risk assessment results with EN-AdaPSVM model
Different from the traditional assessment (TA) model that only focuses on the financing enterprises’ status, SCF should monitor both the financial and operational conditions of the whole supply chain. Thus, in this experiment, we use two kinds of evaluation indices, which are indices of TA model and indices of SCF assessment model. TA indices are only constructed by 17 indices, that is, the one class of SCF, namely, funds and credit condition of financing enterprises, while SCF assessment indices include 28 indices (shown in Table 4). Our proposed EN-AdaPSVM is compared with other four models. Among them, we call the optimization parameters of SVM model based on cross-validation approach as CSVM. The CSVM and PSVM based on improved EN approach are separately called as EN-CSVM and EN-PSVM. The results of prediction on the testing set by the five models are shown in Table 6. The experiment results of the credit assessment are listed by two types of errors, namely Type I and Type II. Type I error occurs when mistakenly classifying any NR company as an R company, Type II error occurs when mistakenly classifying any R company as an NR company.
Results of prediction using two kinds of indices.

SCF: supply chain financing; PSVM: proximal support vector machine.
We draw the following conclusions through the comparison of different models:
The accuracy of the model used the SCF indices are better than that used the TA indices as shown as Table 6, whether the total error ratio or error ratio of Type I and Type II. Therefore, the selection of indices determines the success of construction of the model. Compared to traditional indices, SCF pay more attention to the credit condition of the total supply chain, rather than only consider individual situation of loan enterprise.
The probability of a Type II error occurring in any of the six models is maximal, which demonstrates that NR companies have normal financial data and are more easily distinguished than those classified as R companies due to significant imbalance of financial data. Table 3 shows that the ratio is close to 2:1 for NR and R samples. The implicit assumption of an equal occurrence of each class for imbalanced samples can affect the performance of classification models.
As can be seen in Table 6, for two kinds of evaluation indices, the classification performance of the six models is improved after using EN filtering method to a great extent. Thus, removing noisy examples from the training data is conducive to increase the classification accuracy. EN-AdaPSVM has the lowest total false rate (i.e. 11.76%, 2.35%), followed by AdaPSVM (i.e. 13.41%, 4.69%). CSVM has the highest total false classification rate (i.e. 32.94%, 26.23%). Among these models, the classification accuracy of AdaPSVM is closest to EN-AdaPSVM, which shows that AdaBoost algorithm performs better than EN-PSVM when dealing with noise data. The test results illustrate that the performance of EN-AdaPSVM using SCF assessment indices (2.35%) is better than TA indices (11.76%), and so it can better handle the risk evaluation problems (shown in Figure 5).

Comparison with different models.
Conclusion
Noisy data and parameter values can affect the classification accuracy and generalization ability of the model. In this work, SVM-based ensemble improved with eliminating noisy samples that we call EN-AdaPSVM model is proposed. Here, FCM is presented to search and eliminate noisy samples. In addition, PCA is also introduced to reducing attribute noises. SVMs based on improved PSO are seen as component classifiers. Then, we construct EN-AdaPSVM model using AdaBoosting ensemble algorithm. We implement our models to address risk assessment for supply chain financial fields. Experimental results on both kinds of assessment indices indicate that (1) the performance of EN-AdaPSVM model has better performance than CSVM or PSVM model, and (2) the ability of classification using SCF assessment indices is better than that using TA indices.
Footnotes
Handling Editor: Xiaoyang Wang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by National Natural Science Foundation of China (grant no. 61402193), the Foundation of Jilin Provincial Science & Technology Department (grant no. 20180101337JC), and Society Science Foundation of Jilin Province (grant no. 2019B67) and Jilin Provincial Department of education (grant no. JJKH20200139KJ).