
Abstract
The application of the Internet of Things has produced large amounts of data in different scenarios, which are accompanied with problems, such as consistency and integrity violations. Existing research on dealing with data availability violations is insufficient. In this work, the detection and repair of data availability violations (DRAV) framework is proposed to detect and repair data violations in Internet of Things with a distributed parallel computing environment. DRAV uses algorithms in the MapReduce programming framework, and these include detection and repair algorithms based on enhanced conditional function dependency for data consistency violation, MapJoin, and ReduceJoin algorithms based on master data for k-nearest neighbor–based integrity violation detection, and repair algorithms. Experiments are conducted to determine the effect of the algorithms. Results show that DRAV improves data availability in Internet of Things compared with existing methods by detecting and repairing violations.
Keywords
Introduction
The Internet of Things (IoT) connect multiple information producers with sensors and actuators. Then, these producers collect and transmit surrounding information based on application demands. IoT encounters many problems as it develops. The terminal sensing devices of IoT are mostly used in areas with harsh environments, and the application scenarios are complex. To some extent, the trust rank of the data in an IoT system determines how extensively the system can be used. The data generated by IoT are multi-sourced. Thus, they are challenging to process accurately. Given that data with low availability are collected, Cisco has increased the number of factors that could lead to IoT failure. 1 Data availability and trustworthiness must be enhanced to meet the application requirements of real-time IoT.
Data availability describes the availability of data in business processes. The degree of data availability directly affects the results of business analyses. Invalid and erroneous data interfere with the regular operation of business workflow, inevitably reducing the availability of entity information. Data availability can be assessed from five aspects, namely, consistency, accuracy, integrity, timeliness, and entity identity. Concerning violations in IoT, data availability is described primarily by analyzing consistency and integrity performance. Data consistency means that the relevant information in the data information system is compatible and does not cause conflicts. Data integrity means that the data sets contain data that fully satisfy the requirements for performing various operations on the data. Our work mainly investigates data consistency and integrity and considers the detection and repair of violation elements in data sets. Distributed computing divides the problem solved into many small parts, distributes the parts to many computers for processing, and combines the calculation results to obtain the outcome. Existing methods for data availability in IoT2–7 are not described in the distributed programming model, and only a few implementations have been made for the detection and repair of distributed data availability violations. Data availability violations are random and unpredictable and cannot be quickly resolved by distributed problem-solving. The concurrency and multi-distribution of the parallel environment in IoT complicate the problem of data availability violation in detection and repair.
In this article, we investigate the issue of data availability violations in IoT and propose the detection and repair of data availability violations (DRAV) framework to detect and repair these violations. To address the shortcomings of conditional functional dependency (CFD), DRAV proposes a semantic extension of CFD and corresponding solutions in terms of data consistency. DRAV improves the existing algorithm using the clustering method and proposes a strategy to detect and repair data integrity violations. For distributed application scenarios, DRAV proposes algorithms in the MapReduce programming framework, including the consistency violation detection and repair algorithm based on enhanced conditional functional dependencies (xCFDs),
The main contributions of this article are as follows:
The proposed xCFD extends existing functional dependencies, integrates high-quality data into the logic system of CFD, and further enhances the ability to detect and repair data consistency violations by eliminating conflicts.
An improved k-NN algorithm is used to automatically calculate the best value of
The distributed solution of detecting and repairing data availability violations in IoT is realized by designing related algorithms in the MapReduce programming framework.
Related work
This section summarizes the current research on data consistency, data integrity, and violations in data availability. The detection and repair of data consistency and integrity errors in IoT are focused as follows.
Data consistency
Data consistency is an essential sub-property of data availability. Improper design of the data model and integration of multiple data sources may lead to data inconsistency. Data consistency involves expressing the data of a data set and related theoretical issues, and it lays the foundation for the judgment, detection, and repair of data consistency errors. Research results on the theoretical system of data consistency can be divided into two categories: data consistency theory based on semantic rules and statistical methods. 8
The research focuses on the theory of data consistency based on semantic rules, in which CFD is one of the classical theories. An improved mechanism called CFD
9
was proposed based on functional dependency (FD). The problem of computing the smallest tuple set to delete the original data in the process of evaluating data consistency has been studied and proven to be non-deterministic polynomial complete (NP-C). Besides, CFDs implement data constraints by binding specific values and expressing data consistency semantics. Compared with classical FD, CFD performs better in conditional expression. Thus, many studies have used CFD. Bohannon et al.
10
presented a method of consistency error detection for SQL data based on CFD. The method has been widely used in data cleaning. Fan et al.
11
proposed an algorithm for mining CFDs in data sets. The algorithm has been used to generate CFDs automatically. Miao et al.
12
systematically studied the problem of data consistency determination using CFD and measured the consistency quality of data sets. The ratio of the tuples in the most substantial subset of the rule set that satisfies CFD to the tuple number of the data set. These researchers also studied the computational complexity and approximation of the problem. Zhou and Bu
13
proposed an improved strategy for existing cleaning schemes, including introducing support to mining dependency rules and presented approximate functional dependency. Moreover, the application of CFD in data cleaning systems in the general domain has been studied. Yang
14
reported that the editing rules supplement the expressive ability of CFDs. Based on CFDs, Jin et al.
15
introduced a series of external knowledge bases, including hard, quantitative, equivalent, and non-equivalent constraints, to assist the expression of consistency constraint rules. Based on CFDs and external knowledge bases, they proposed an incremental data consistency error detection and repair algorithm. Salem and Abdo
16
presented editing rules to supplement the application of the expressive ability of FD. Extended conditional functional dependencies
17
(eCFDs) can express the semantics of
Data integrity
Data integrity is another essential sub-property of data availability. When humans input errors, the absence of non-vacancy constraints and attribute recognition of semi-structured data may lead to data integrity loss. Most of the studies on the detection and repair of data integrity errors focused on filling missing values. Filling data sources can be divided into internal and external. The internal data source includes the data set being detected and repaired, and the external data source includes the data source of other business systems or the data in the network.
Liu et al. 18 studied the problem of data integrity determination and proposed a measurement model of data integrity. The model proved that the problem of data integrity determination is NP-C. Afterward, the researchers proposed an optimization-based integrity determination algorithm. For the algorithm to apply to the processing of large amounts of data, they also proposed an approximation algorithm for big data. Razniewski and Nutt 19 studied the problem of determining the integrity of geographic data and improved relevant decision algorithms. A method to determine the data integrity of the time series 20 was proposed. Emrann et al.21,22 developed data integrity assessment measures for microbial genome databases. Libkin 23 studied the theoretical basis of filling missing values. Farooq et al. 24 provided a well-defined security architecture as a confidentiality of the user’s privacy and integrity, which could result in the architecture’s wide adoption by masses. Several studies25–29 used the method of filling in internal values. Hao et al. 30 proposed a filling algorithm based on double clustering. Concerning external data filling, some studies31,32 investigated the problem of filling missing values with data on the network. A method of filling missing values using internal and external data sources 33 was proposed. To minimize the number of network queries, Li et al. 34 developed a method of filling missing values for network data, with the number of queries as the goal.
Detection and repair of data availability violations
With the increase in data volume, this research on data consistency focuses on centralized relational data sets. Theoretical studies on distributed and non-relational data sets are few. However, in recent years, an increasing number of researchers have focused on improving the data quality of large data sets.
Most existing studies are based on the theory system of derivative self-functional dependency and aimed at structured data. An algorithm of distributed multi-functional dependency conflict detection was proposed in a previous work. 35 Fan et al. 36 presented an incremental online algorithm for detecting data consistency errors in distributed databases. Other studies37,38 developed MapReduce algorithms for consistency error detection and repair of data files using CFD in the Hadoop environment. An algorithm that extends the stand-alone offline method for batch data 39 was proposed for the Hadoop platform. Yang et al. 40 optimized a series of big data algorithms based on task merging and MapReduce. Ding et al. 41 studied the relationship among the five sub-properties of data availability and pointed out that integrity errors may be repaired in three dimensions: attribute values, tuples, and data tables. The filled data may have inconsistent errors, which may lead to the violation of the consistency constraint after repair.
Therefore, the repair of integrity violations is not entirely related to data consistency. However, the repair operation of consistency errors modifies data that violate the semantic rules into data that satisfy the consistency constraints. It does not delete the data to avoid introducing missing values that lead to integrity errors.
Detection and repair of consistency violation
Based on CFD and eCFD theories, this section defines the xCFD rule to address the limitations caused by the limited set of discrete value constraints and describes the consistency violation detection and conflict elimination algorithm based on xCFDs.
Definition and properties of xCFDs and main data
CFD, as the basis of subsequent consistency theory, belongs to the consistency theory system based on semantic rules. CFD enhances the semantics of FD commonly used in relational schemes. For relational schema
The data with benchmark nature is usually referred to as the main data. As shown in Figure 1, the main data generally has high quality, long data life cycle, low data update frequency, and small data volume. These attributes can be used to detect data errors and directly guide the repair of data errors. The author formally defines main data in the dimension of consistency. Besides, the author considers the relation

Types of IoT data and their characteristics.
As shown in the conversion example in Figure 2, for each FD of a data set, a corresponding CFD rule table containing only constant values can be generated. Conversely, the number of rule tuples in a rule table is similar to the number of tuples in a data set. In addition to consistency, the main data also have integrity, timeliness, and accuracy. Here, the main data are integrated into the system of CFDs, and the compatibility of CFDs in xCFDs is used to make it convertible. The error tuples are processed by the repair method of xCFDs.

Conversion example of the main data and CFD.
The modification of attributes in each tuple is considered in the repair proposals. When a unit group violation occurs, other irrelevant attribute values in the tuple do not affect the repair proposals. Under known rules, the proposed modification is to change the constant in the tuple against the attribute value to the constant selected in the rule. When multiple violations occur, the minimum modification method under FD constraints aggregates and groups the same
The concept of equivalence class is introduced to constrain the logical consistency of repair operations.
39
For relational schema

Process for merging equivalence classes.
The values in the rule table of CFDs can only be a specific constant or an undefined variable. CFDs cannot interfere when we express the
The formal definition of eCFD is as follows: for relational schema
When the semantics rules of
The definition of xCFDs is as follows: for relational schema
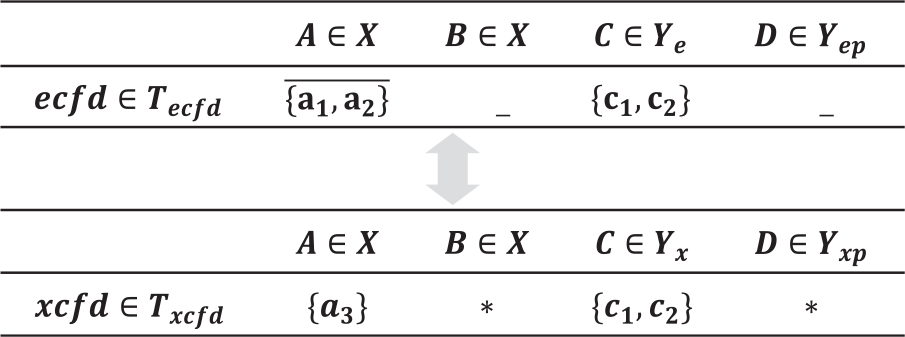
As shown in Table 1, an example of an xCFD rule is shown as follows:
Example of xCFDs rules.

The definition of xCFDs indicates that their semantic expression ability is stronger than that of eCFDs and CFDs, and for CFD and eCFD rules, corresponding expressions in xCFDs exist. To illustrate the conversion from CFD to xCFD rules, DRAV describes the conversion of CFDs to eCFDs and eCFDs to xCFDs in turn.
From these definitions and semantics, for any CFD rule

For only one rule tuple CFD
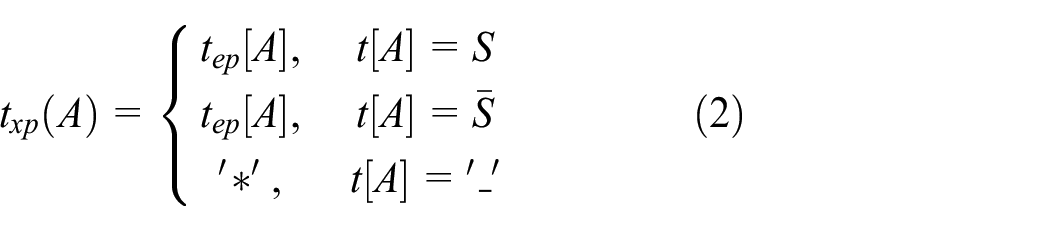

Conversion example of CFD and eCFD.
For eCFD
Conversion example of eCFD and xCFD.

Research on consistency based on xCFDs and main data
The data consistency violation detection method based on xCFDs is similar to the detection method based on eCFDs. The analogy in xCFDs is extended. For the rule tuple
To specify the specific matching method of the
The algorithm
Following the idea of consistency error detection under the eCFD system, we further expand the consistency violation of xCFD data tuples in xCFDs by matching left data with regular tuple data. Given the similarity of xCFDs and eCFDs in form and semantics, their detection algorithms are the same and can be divided into two cases.
Consistency violation of unit group composition. As shown in Table 2, consistent with the detection method of eCFDs, for data set
Conformity violation caused by multiple groups. Similarly, for data set
SQL query for consistency violation of unit groups.

SQL: Structured Query Language.
SQL query for consistency violation of multiple groups.

SQL: Structured Query Language.
Here, we present a consistency violation detection algorithm

Next, we consider the issue of consistency violation repair. When only one rule exists in xCFDs and only one rule tuple is present in the rule table, a constant in the set of CFD rules can be used to provide a repair suggestion value for the attribute value violated in the wrong tuple in the case of unit group violation. In the case of multiple group violations, the attribute values that appear most frequently in each group can be used as the repair recommendation values.
39
In the rules of CFDs, constants are used only as repair suggestions because only constants are included in the rules, except for undefined variables. In xCFDs, because rules make up a set that may contain many quantities, calculating a specific constant is necessary. To be compatible with CFDs, when the number of elements in a set is 1, the semantics of CFDs is included, and the constants calculated are the only elements in the set. Therefore, the most frequently occurring amount of constraint attributes of all tuples that conform to the rule constraints can be regarded as the repair recommendation value. To this end, the algorithm

The method of
Consistent unit group violations can be detected and repaired in the mapping process. After the unit group detection process, multigroup violations can be detected, and whether or not the data need to be grouped can be determined. In the mapping and reduction processes of the

When the amount is small, main data can be stored directly in Hadoop’s dedicated cache or memory. Thus, the join operation can be carried out in the mapping process. The

When using the reduction process to realize the connection, the main data and the data to be cleaned can be read and grouped according to the attribute value on the left side of the functional dependency. The procedure of

Conflict elimination
When a unit group violation occurs,
The specific attributes are selected, and repair suggestions are provided for
Neither
and
Atleast one of
An attribute in
Detection and repair of integrity violation
A specific detection and repair scheme for integrity violation data is provided in this section. The

Integrity violation detection
The standard definition attribute value is null when the judgment condition of integrity is missing. Decision flag
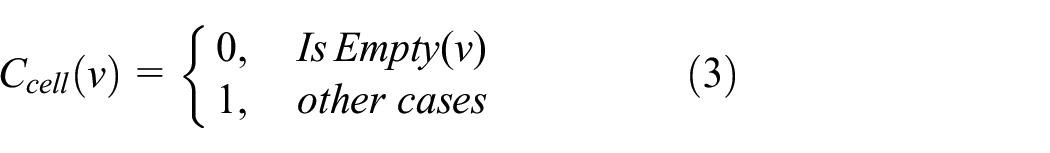
We determine
Based on defining the

The partition method
Integrity violation repair
At present, the main function of integrity repair focuses on filling missing values. The repair of integrity violation tuples involves the repair of missing values in
In pattern recognition and machine learning, the k-NN algorithm
42
is a non-parametric statistical method that can be used for classification and regression. In the classification and regression, the input is a set of data containing at least
The NN method uses the space vector model to classify cases and evaluate the possible classification of unknown category cases by calculating the distance measure from known category samples. Measuring the weights of neighbors is useful regardless of classification or regression. Thus, the weights of nearby neighbors are more important than those of distant neighbors. The disadvantage of k-NN is that it is sensitive to the local data structure. Specifically, the value calculation methods for numerical and non-numerical types of decision-making are as follows. For a numerical attribute, when

If the class with the most frequent occurrence is not unique, then the value of the class with the nearest point in the two types of points is used as the patching value. If the value can only be taken as an integer, then the result of the calculation
For each element in a set,


In

The k-NN algorithm needs to determine the value of
Experimental study
This section demonstrates the improvement of data availability by DRAV through experiments. We conducted three experiments on consistency violation detection and repair based on xCFDs, repair based on main data and integrity violation detection, and repair based on mean-k-NN.
Data sets and environment
Two IoT open data sets were used instead of actual sensor data. Data Set I (Hubway Data Visualization Challenge) has nine numerical attributes and six classification attributes, totaling to 1 million records. Data Set II (Gas Sensor Array Drift Data Set) consists of 16 numerical attributes, totaling 13,000 records.
All the experiments in this section were run on a distributed cluster. Five physical nodes were implemented on CentOS 7.3, MySQL 5.5, and Hadoop 2.7 with an Intel E3 CPU running at 3.4 GHz and with 16 GB of memory.
Detection and repair experiment of consistency violation based on xCFDs
In this experiment, the proposed method of consistency violation based on xCFDs is evaluated on Data Set I. Analysis of violation detect precision, repair quantity, repair precision, and running time comparison are partially focused. Based on the experimental data and the domain knowledge of the attributes, four constraint rules with different constraints of CFDs, eCFDs and xCFDs were generated, which cover most of the data sets. The tuples in Data Set I were randomly selected to make them violate the four rules.
Violation detect precision analysis
In this section, the influence of the proposed xCFDs on efficiency is considered by detect precision analysis. Since the detection results of consistency violations are deterministic, the respective detection accuracy results depend on the ratio of the consistency violations randomly generated on each rule. Due to the limitation of expression ability, the rule semantics of xCFDs cannot be expressed in CFDs and eCFDs. Meanwhile, the semantics of eCFDs cannot be expressed in CFDs. Therefore, CFDs cannot detect the constraints expressed by xCFDs. As shown in Figure 6, xCFDs have a better performance on the detection precision than CFDs and eCFDs at the same violation rate.

Comparison of detect precision among CFDs, eCFDs, and xCFDs.
Violation repair quantity analysis
In this section, the repair situations under different error rates of raw data are investigated. We examined the total number of CFD and xCFD based repairs. As shown in Figure 7, with the increase in error rate, the number of detected error tuples increases gradually, and the ratio of xCFDs to CFDs in the number of repairs increases with the increase in data scale. Combined with the previous experimental results, xCFDs’ enhanced expression ability in constraint semantics helps describe data errors. These rules with an appropriate repair algorithm can be used for error detection and correction. This result indicates that these xCFDs are better than classical CFDs.

Comparison of repair quantity between CFDs and xCFDs.
Violation repair precision analysis
In this section, the performance of the overall repair precision for CFDs and xCFDs is demonstrated. The error rate of each group is set according to the above group. Figure 8 shows the error repair accuracy of CFDs and xCFDs with different error rates. The constraints of using sets are weaker than using constants, especially in repair operations, due to the enhanced expressive ability of xCFDs. Overall, in the process of xCFD repair, the conflict between rules and data also increases, leading to the determinacy of the overall repair decline. Thus, repair accuracy also decreases. However, the decline rate is acceptable, and the impact on repair capacity is low.

Comparison of repair precision between CFDs and xCFDs.
Running time analysis
In this section, the influence of the proposed xCFDs on efficiency is considered by running time analysis between stand-alone SQL and Hadoop. As shown in Figure 9, the efficiency of Hadoop has apparent advantages than stand-alone SQL. With the increase in data volume, the time gap becomes increasingly significant. On the contrary, the time reduction of the Hadoop version gradually decreases, indicating that a complicated relationship exists among data volume, error rate, and parallelism. In summary, the proposed xCFDs have proper parallel detection and repair effect for data consistency violation.

Comparison of xCFDs running time between stand-alone SQL and Hadoop.
Detection and repair experiment of consistency violation based on main data
In this experiment, the proposed method of consistency violation based on main data is evaluated on Data Set I. Analysis of running time comparison is partially focused. In the previous sections, we mentioned that the relational model of main data is
Running time analysis
In this section, the influence of the proposed

Comparison of running time between
Detection and repair experiment of integrity violation
In this experiment, the proposed method of integrity violation is evaluated on Data Set II. Analysis of tuple distance and running time comparison are partially focused. Data Set II was used to select 5%–30% tuples randomly in the original data, from which an attribute value was set to be empty. The repair effects of mean-k-NN and fixed-value-NN were compared. The initial value of mean-k-NN was set to 25, and the fixed-value was set to different values.
To meet the experiment requirements, the frequency of each class in all classified attributes was collected in statistical data, and the distance between classes of all attributes is calculated. The calculation results were saved for subsequent use. The data sets were partitioned, and the input was detected in the mapping process to detect and repair integrity violations further. For the results after mapping, the distance of the internal partition elements was calculated. If the map is reduced directly after the mapping, then the results of all lists will be judged. The list in each partition only needs to maintain the minimum of the first
Tuple distance analysis
In this section, the influence of the mean-k-NN method on efficiency is considered by tuple distance analysis. As shown in Figure 11, the longitudinal axis is the Euclidean distance between the repair tuple and the actual tuple. The method in mean-k-NN has an excellent dynamic effect, and in most cases, it can be close to the value of the

Comparison of tuple distances between fillings with mean-k-NN and fixed-value-NN.
Running time analysis
In this section, the influence of the

Comparison of running time between Map-Combine-Reduce and MapReduce.
Discussion
In this article, a series of algorithms described in the MapReduce form on Hadoop have been proposed in the previous section. In research on data consistency with xCFDs,
In summary, compared with classical algorithms, the performance of the framework method is improved, but it still has room for improvement. For example, in the violation detection and repair algorithm based on xCFDs, the enhancement of expression ability is accompanied by the weakening of strict constraint ability, leading to an increase in the uncertainty of the repair results. Thus, the repair rate is lower than that of CFDs. In the mean-k-NN-based integrity repair experiment, the algorithm for calculating the optimal value of
DRAV still has room for improvement in terms of dealing with IoT data availability violations. Future work on DRAV should focus on the following aspects: (1) calculating domain-related maintenance costs by network algorithms, (2) enhancing the functional dependencies in the data sets by mining algorithms, and (3) promoting the neighbor calculation process by using the distance coefficient in the neighbor algorithm.
Conclusion
The improvement of data availability is crucial to the credibility of IoT. Our work focused on the consistency and integrity of data availability in IoT and proposed a DRAV framework that contains a series of processing algorithms. To address the deficiency of CFD in expressing data consistency, DRAV proposes an extension of CFD in semantics to enhance the expressive ability on rule constraints. Under the existing theory of error detection and correction, DRAV proposes a corresponding SQL query and standalone detection algorithm and a heuristic standalone repair scheme. Main data are formally defined by FD, which integrates high-quality data into a theoretical system of CFD and clarifies the guiding significance of high-quality data for error detection and repair. In distance measurement, a k-means method is used to compute normalized distances for IoT data to ensure the rationality of distance measurement between tuples. DRAV also uses a method to evaluate the value of the first
Footnotes
Handling Editor: Ximeng Liu
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (Nos 61472108, 61601146, and 61732022) and the National Key Research and Development Program of China (Nos 2016QY03D0501 and 2017YFB0803300).