
Abstract
Uploading all Internet of Things big data to a centralized cloud for data analytics is infeasible because of the excessive latency and bandwidth limitation of the Internet. A promising approach to addressing the challenges for data analytics in Internet of Things is “edge cloud” that pushes various computing and data analysis capabilities to multiple edge clouds. MapReduce provides an efficient way to deal with a large amount of data. When performing data analysis, a challenge is to predict the performance of MapReduce jobs. In this article, we propose and evaluate InSTechEM, which is an extended Internet of Things big data–oriented model for predicting MapReduce performance in multiple edge clouds. InSTechEM is able to predict MapReduce jobs’ total execution time in a general implementation scenario with varying reduce amounts and cluster scales. The proposed model is built based on historical job execution records and employs locally weighted linear regression techniques to predict the execution time of each job. By modifying the prediction model used in Hadoop 1 and extracting more representative features to represent a job, the InSTechEM model can effectively predict the total execution time of MapReduce applications with the average relative error of less than 10% in Hadoop 2 with Ceph as the storage system.
Keywords
Introduction
With the development and popularity of many Internet applications and services, the exponential growth in users data is described by the term Big Data. 1 It is dramatically crucial for big data practitioners to understand the methods of providing users with shorter response time and user-friendly experience based on the physical machines. At the same time, Internet of Things (IoT) consists of billions of sensors that range from nano-sensors to smart high-definition video cameras. However, migrating all IoT data to a centralized cloud for data analytics is infeasible because of the excessive latency and bandwidth limitation. For example, excessive latency may cause applications with real-time or near-real-time requirements, such as surveillance or smart transportation management, to fail in detecting suspicious objects or crucial traffic patterns in a timely manner. A promising approach to addressing the challenges for data analytics in IoT is developing the “edge cloud” that pushes various computing and data analysis capabilities to multiple edge clouds.
MapReduce 2 provides an efficient way for dealing with “Big Data.” Users specify the computation in terms of a map and a reduce function. The underlying runtime system automatically parallelizes the computation throughout the large-scale clusters of machines, handles machine failures, and schedules inter-machine communication to efficiently use networks and disks. 2
The MapReduce system is easy to use and Hadoop 3 is an open-source implementation of MapReduce, providing easy access to parallel computing. A lot of Internet companies have deployed Hadoop clusters for big data processing. However, it is challenging to reasonably allocate resources when fulfilling a job. It is desirable to achieve the performance goal without wasting resources. 4 Moreover, Hadoop parameter tuning, scheduling policy, and job performance optimization are important issues, which are closely related to job performance prediction. It is worth to mention that Amazon has offered Hadoop services for several years as Amazon Elastic MapReduce (EMR) in the Amazon public cloud; however, Hadoop clusters running in one centralized cloud for IoT data real-time analytics has serious bottleneck problems, as all the geo-distributed sensors need to transfer all the data to the centralized cloud.
In this article, we propose InSTechEM, an extended IoT big data–oriented model for better prediction of MapReduce job execution time in multiple edge clouds. Based on the job profile, input dataset size, and allocated resources, a MapReduce performance model is presented to predict the job completion time using multivariate local weighted linear regression. 5
The main contributions of this article are summarized as follows:
We propose our IoT big data edge cloud architecture to address the challenges of data analytics in IoT using “edge cloud” that pushes various computing and data analysis capabilities to multiple edge clouds.
We propose InSTechEM, an extended IoT big data–oriented model for predicting MapReduce performances using the locally weighted linear regression (LWLR) model in multiple Edge Clouds Hadoop 2 environments. By extracting distinguishing features for job representations, InSTechEM selects a cluster scale as a crucial parameter and improves the prediction model used in Hadoop 1 to adapt to Hadoop 2.
We propose our IoT Big data Edge Cloud Architecture based on Ceph, even though many previous researches on MapReduce performance prediction are mostly based on hadoop distributed file system (HDFS). Ceph is a unified, distributed storage system designed for excellent performance, reliability, and scalability.
We have validated the accuracy of the proposed MapReduce performance model using TestDFSIO and Sort benchmark applications in the IoT Big data Edge Cloud Architecture environment based on Hadoop 2 with Ceph as storage system.
The rest of the article is organized as follows. Section “Related work” gives related work. Section “IoT big data multiple edge clouds architecture” proposes IoT big data edge clouds architecture. Section “InSTechEM: an IoT big data–oriented extended MapReduce performance model in multiple edge clouds” presents the extended job execution prediction model InSTechEM. Section “Experiment and performance evaluation” evaluates the accuracy and effectiveness of the proposed approach. Section “Conclusion and future work” concludes the article and points out future work.
Related work
Hadoop performance modeling has received great attention recently, involving job optimizations, scheduling, predictions, and resource provisioning. Meanwhile, IoT technology is gradually driving edge computing and edge cloud research to become a hot topic. Therefore, we should consider deploying IoT-big data–oriented Hadoop platforms in multiple edge clouds.
A number of models have been proposed for predicting MapReduce performances. Herodotou 6 developed an expensive and comprehensive mathematical model of each phase of MapReduce. The execution of a MapReduce job included mapping tasks and reducing tasks. A map task execution was divided into five phases, which included Read, Map, Collect, Spill, and Merge. Reduce task execution was divided into four phases, including Shuffle, Merge, Reduce, and Write.
Kambatla et al. 7 used historical execution traces of MapReduce to profile jobs and predict performance. Many models7–9 used test runs on small-scale settings to characterize the behaviors of large-scale settings. Lin et al. 10 divided the job processing from the perspective of resource dimensions instead of the execution order and proposed a cost vector that contained the cost of disk I/O, network traffic, computational complexity, central processing unit (CPU), and internal sorting for predicting the execution durations of the map and reduce tasks. However, no prediction on reduce tasks were presented.
Song et al. 11 presented a dynamic lightweight Hadoop job analyzer, and a prediction module using locally weighted regression methods. Tian and Chen 12 and Chen et al. 13 proposed a cost model that showed the relationships among the amount of input data, the available system resources (Map and Reduce slots), and the complexity of the Reduce function for the target MapReduce job. Based on the cost model, optimal resource provisioning could be obtained.
Performance prediction modeling for MapReduce applications with large-scale data is a very important issue. In Wang et al., 14 we used the LWLR algorithm and linear regression (LR) algorithm to establish three kinds of prediction models based on different characteristics to estimate the execution time of the applications that have large-scale data and run on the Hadoop framework. We also made comparison and improvement to the three models. Verma et al. 15 proposed a framework automatic resource inference and allocation (ARIA), for a Hadoop deadline-based scheduler which extracts and utilizes the job profiles from the past executions. These job profiles were used to compute the lower and upper bounds on the job completion time. Furthermore, ARIA model gave the resource provisioning model.
Based on ARIA model, the Hewlett-Packard Development Company (HP) model 16 added scaling factors and used a simple LR to predict the job execution when processing larger datasets. Zhang et al. 17 employed ARIA model 15 to predict the MapReduce job completion time periods in heterogeneous Hadoop cluster environments. The work presented in Zhang et al. 18 used a set of micro-benchmarks to profile generic phases of the MapReduce processing pipeline of a given Hadoop cluster. Zhang et al. 18 divided the map phase and reduce phase into six generic sub-phases and used a regression technique to predict the durations of these sub-phases. Then, the overall job execution time could be computed using the method presented in Verma et al. 15
Building on the HP model, 16 Khan et al. 19 presented an improved HP model for Hadoop job execution prediction and resource provisioning. The improved HP model employed LWLR instead of a simple regression technique to predict the execution time of a Hadoop job with a variety of reduce tasks. Furthermore, it took multiple waves into consideration.
In our paper, 4 we designed, implemented, and evaluated the InSTechAH, an autoscaling scheme for a Hadoop system in a private cloud, which attempted to improve the resource utilization in cloud data centers as well as maintain required quality of services by autoscaling and scheduling background analytics tasks. We evaluated our scheme partially at a real data trace and partially on simulations, with Hadoop as the parallel data analytics framework and OpenStack as the cloud management architecture, to show efficiency of the InSTechAH system.
In Engin et al., 20 proactive content caching in 5G wireless networks was investigated and a big-data-enabled architecture was proposed. In this practical architecture, a vast amount of data is harnessed for content popularity estimation, and strategic contents are cached at 5G base stations to achieve higher user satisfaction and backhaul central cloud offloading.
In Mathew et al., 21 the authors presented Nebula: a dispersed cloud infrastructure that uses voluntary edge resources for both computation and data storage. They described the lightweight Nebula architecture that enables distributed data-intensive computing through a number of optimizations, including location-aware data and computation placement, replication, and recovery. The authors evaluated Nebula’s performance on an emulated volunteer platform that spanned over 50 PlanetLab nodes distributed across Europe, and showed how MapReduce can be deployed and run on Nebula, as the common data-intensive framework. They showed that Nebula MapReduce is robust for a wide array of failures and substantially outperforms other wide-area versions based on a Berkeley Open Infrastructure for Network Computing (BOINC)-like model.
S Ola et al. 22 proposed that the main objective of mobile edge computing (MEC) solution was export of central cloud capabilities to user’s proximity for decreasing latency, augmenting available bandwidth, and decreasing traffic load on the core network. On the other hand, IoT obtains benefits from the proliferation in mobile phone usage. Many mobile applications have been developed to connect a world of “things” (e.g. wearables, home automation systems, sensors, and radio frequency identification (RFID) tags) with the Internet. Even if it was an incomplete solution to scalable IoT architecture, time-sensitive IoT applications (e.g. e-healthcare, real-time monitoring) would be optimized from using MEC architecture.
W Shi and D Schahram 23 described that the success of IoT and rich cloud services have helped creating the need for edge computing, in which data processing occurs in part at the network edge, rather than completely in the centralized cloud. Edge computing could address concerns such as latency, mobile devices’ limited battery life, bandwidth costs, security, and privacy. Stream processing frameworks (SPF, for example, Apache Storm) were solutions that facilitated and managed the execution of processing topologies that consisted of multiple parallelizable steps/tasks and involved continuous data exchanges. Streaming from the world of Cloud-centric Big Data processing often failed in addressing certain requirements of IoT systems. Apostolos et al. 24 described topology-aware SPF extensions, which can eliminate latency requirement violations and reduce cloud-to-edge bandwidth consumption to 1/3 comparing to Apache Storm.
In Cheng et al., 25 the authors focus on enabling flexible and efficient edge analytics for large-scale IoT systems to process stream data both at the network edges and in the Cloud dynamically and transparently. As compared with existing centralized cloud stream processing platforms, GeeLytics is designed to support dynamic topology to achieve low latency results for efficient task sharing and scheduling while minimizing the bandwidth consumption between the network edges and the Cloud, as shown in Figure 1.

System setup for GeeLytics. 25
As we see, the end points could be various sensors like cars, glasses, video cameras, and mobile phones, connected to the system via different types of edge networks (e.g. WiFi, ZigBee, or 4G, but maybe also fixed networks). 25 They are constantly reporting heterogeneous, dimensional, and unstructured data over time. The Cloud represents the central control point with powerful processing capability and large storage. Between the end points and the Cloud, there are a large number of edge nodes distributed at different locations. These edge nodes have certain processing power and are able to process immediately the incoming stream data, therefore reducing both the bandwidth required to send raw data to the Cloud and the delay to prepare a response for actuators. 25
IoT big data multiple edge clouds architecture
IoT big data edge cloud architecture
Mobile or static sensors such as video cameras, audio sensors, air sensors, environment sensors, and motion sensors are becoming ubiquitous in the IoT. In many smart cities, a large number of IoT sensors are now widely deployed at different locations, producing a huge amount of stream data. Although the generated data provide us great potential to observe our city environments, it still remains a big challenge to efficiently analyze real-time results from sensor data to make fast and smart decisions. Current big data processing platforms, such as Storm, Spark Streaming, and S4, are well designed to process stream data within a cluster in the centralized cloud, but they are not suitable for geographically distributed IoT systems in which data are naturally geo-distributed and low latency analytics results are expected to be shared across users and applications. Therefore, centralized cloud-based big data infrastructure suffer from inefficient data mobility due to the centralization of cloud resources, and hence, edge cloud infrastructures are highly unsuited for dispersed-data-intensive applications, where the data may be spread at multiple geographical locations. 21 Therefore, we propose our IoT Big data Edge Cloud Architecture, where our approach to addressing the challenges for data analytics in IoT is “edge cloud” that pushes various computing and data analysis capabilities to multiple edge clouds.
As shown in Figure 2, when the IoT sensors collect a lot of data and transfer all the data to the remote centralized cloud-host big data platform, the centralized cloud will become a bottleneck with network delay. We cooperated with one famous CDN company that has many edge network data centers across China and constructed a multiple edge clouds-based big data platform in their edge network data centers to enable IoT sensors to transport their data to the nearest edge cloud. In every edge big data platform, we build many Hadoop clusters as computing nodes; at the same time, we use Ceph distributed storage architecture as storage node. When many IoT sensor groups collect a lot of data, the multiple edge clouds redirector will allocate different sensor groups to different edge clouds based on the nearest node allocation policy. After one sensor group is allocated to an edge cloud, the edge cloud will carry out data cleaning and resource allocation. The edge cloud’s resource allocator will determine the amount of cluster resource to be allocated to handle this sensor group’s IoT data based on the collected data size and data processing type, such as CPU-intensive or IO-intensive task. After that, most IoT data intermediate processing of the sensor group is carried out in the allocated cluster, and only some aggregation processing is sent to the centralized cloud to be completed there. This architecture is similar to the idea of CDN, which may greatly reduce the load of the centralized cloud by allowing the IoT data to be distributed to multiple edge clouds for processing.
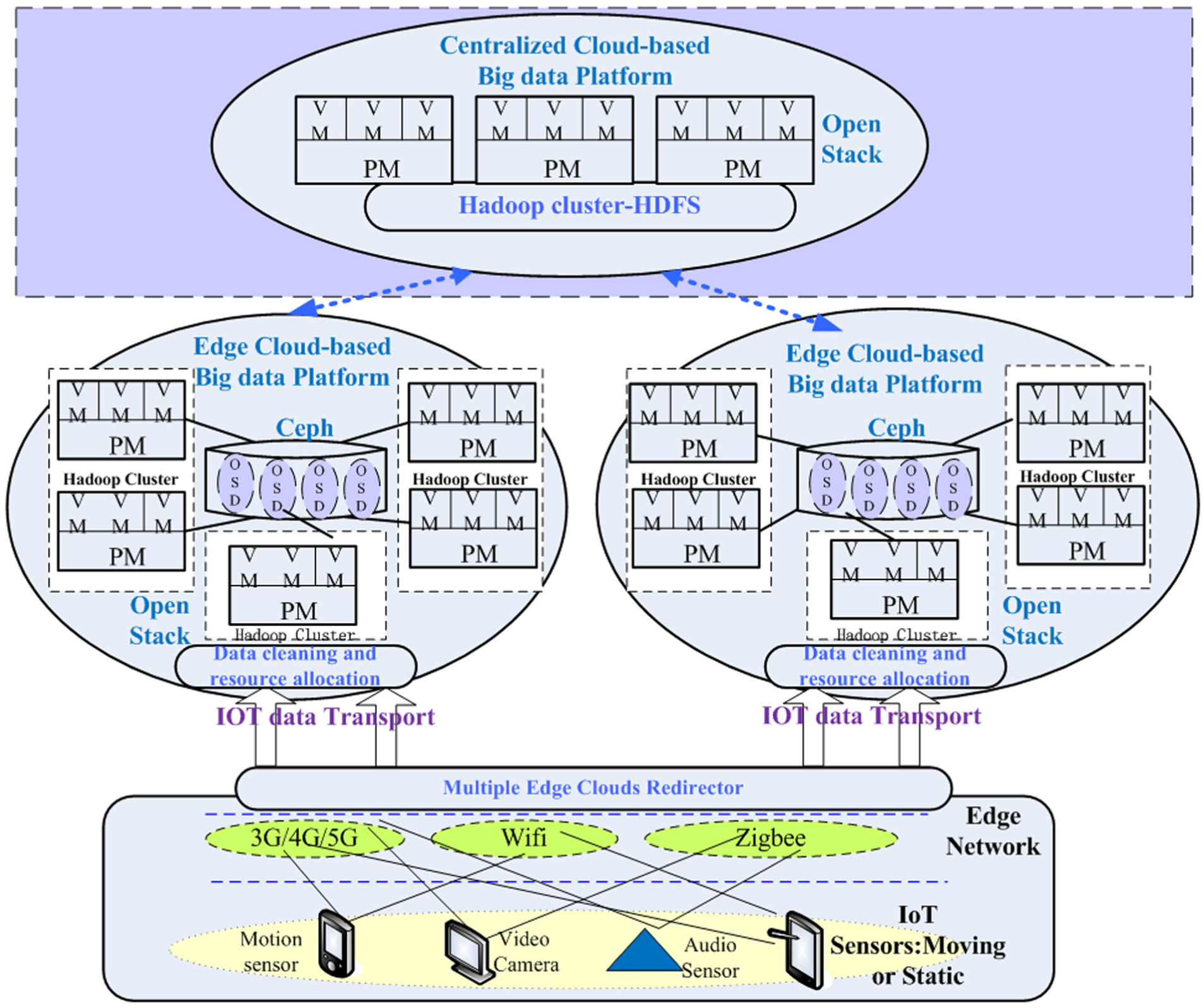
IoT big data multiple edge clouds architecture.
Ceph is a massively scalable, open-source, distributed storage system. It comprises an object store, block store, and a Portable Operating System Interface of UNIX (POSIX)-compliant distributed file system. The platform is capable of autoscaling to the exabyte level and beyond. It runs on commodity hardware and is self-healing and self-managing with no single point of failure. Ceph is in the Linux kernel and can be integrated with the OpenStack cloud operating system. In our architecture, we use Ceph as the storage of Hadoop, so there is no need for moving data to HDFS since all the data are already stored on Ceph. In addition, it is easy to realize computing node autoscaling in the edge cloud environment. The potential disadvantages is that while all the data reading and writing operation are passing through the network switch of Ceph, the switch node bandwidth may become the bottleneck. But as we use multiple edge clouds architecture, we can distribute different IoT sensors to different edge clouds and thus can avoid the occurrence of bottleneck of Ceph switch network node. Therefore, this architecture is very scalable and flexible.
InSTechEM: an IoT big data–oriented extended MapReduce performance model in multiple edge clouds
In IoT >big data multiple edge clouds architecture, different sensor groups are allocated into different edge clouds based on the nearest cloud node allocation strategy. In each edge cloud, we need to determine how large cluster resource to be allocated to handle IoT data from different sensor groups based on the collected data size and data processing type, such as CPU-intensive or input/output (IO)-intensive task. In order to achieve reasonable resource allocation in multiple edge clouds architecture, we can use many methods including Hadoop parameters tuning, scheduling policy and job performance optimization, and job performance prediction. In this article, we focus on MapReduce job performance prediction and propose InSTechEM as an extended IoT Big data–oriented model for MapReduce performance prediction using the LWLR model in multiple Edge Clouds Hadoop2 environment. In InSTechEM, more representative features are extracted to represent a job and different features are assigned different weights for better prediction, which can support IoT data process job prediction in multiple edge clouds architecture.
InSTechEM model parameters selection
The performance model relies on a set of parameters to predict the total job execution time. The key factors of job execution time include Hadoop parameters configuration, job setting, cluster scale, application type, and its workload.
A general MapReduce performance model can be formalized as

where P is the impact of Hadoop parameter configuration, S is the impact of job setting, C represents cluster scale, T is application type, and W is its workload.
MapReduce programs have very different logic and time complexity; the performance functions should be different from application to application. 13 However, they can share some general form, only differing in the setting of parameters. So we build models for each different application.
Cluster scale has influence on performance model, which is obvious that the same application running on different clusters may have different execution times. In this article, we keep the physical machine distribution unchanged and vary cluster scale by controlling the number of virtual machines to find the relationship between these characteristics in the performance model.
There are a lot of Hadoop parameters that are set to be constants in our experiments for simplification. As for job setting, we choose the most important one, reduce number, to construct the model.
A more specific model will be in the form of

where R is the reduce number of jobs, C represents the number of working machines in the cluster, and D is input files sizes.
Apply LWLR model to enhance performance prediction
LWLR algorithm 5 is a non-parametric learning algorithm while LR is a parametric learning algorithm. In parametric learning algorithm, there exist fixed specific parameters that will not be changed once established. Trained sample data are used to determine the parameters and then training samples are discarded in parametric learning algorithm. Non-parametric learning algorithms need to keep training sample all the time since for each prediction, they will learn a new set of parameters. That is, the parameters are variables.
When the capacity of the training set is large, non-parametric learning algorithms cost more storage space and are relatively slow in computation speed. However, it is important and difficult to select the appropriate feature for the parametric learning algorithm like LR model. Models built on very different features may lead to very different results.
Many performance models are presented using LR of different feature selection.14–18
Since LWLR model is relaxed on feature sets and provides a better fit to real data, this article utilizes LWLR to predict the corresponding data.
LWLR is a memory-based method that performs a regression around a point of interest using only training data that are “local” to that point. 5
More data points lead to better fit but dramatically increase computational cost.
As the below equations show, LWLR model assigns weight coefficient to each sample point. The rule is that points are weighted by proximity to the predicted x using a kernel. LWLR model tries to fit the parameter

where
Obviously, the weight coefficient is approximately 1 when a sample point is very close to the predicted point and approximately 0 while the sample point is far from the predicted point. The value of τ establishes the scope of neighbors and is crucial to LWLR.
Bound-based prediction in Hadoop 2
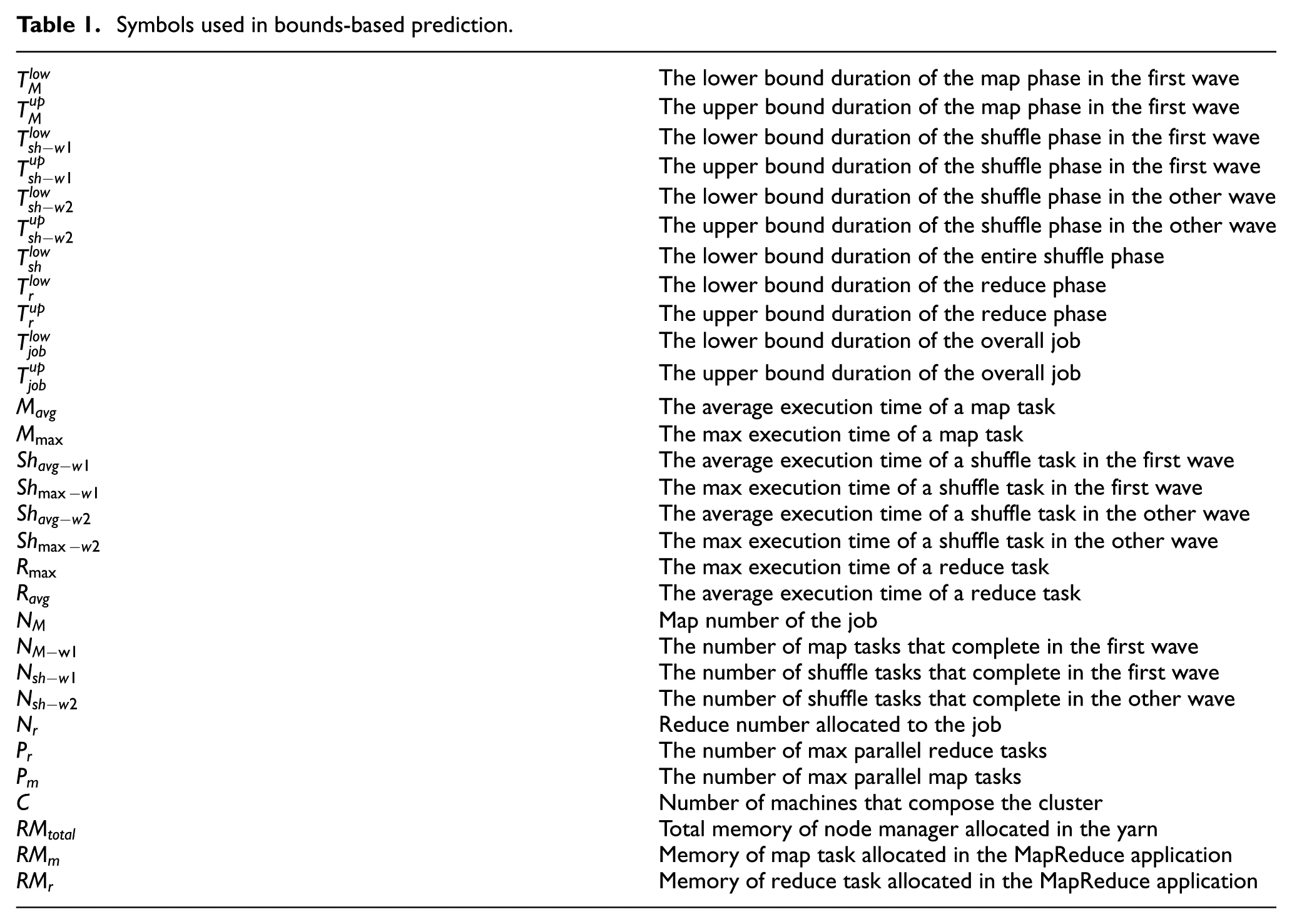
Bound-based performance model is proposed in ARIA 15 for predicting the MapReduce job completion time. The improved HP model 19 modifies the upper bound to get a narrower gap between lower and upper bounds. We apply this model to the Hadoop 2 environment. Table 1 lists all symbols’ meanings used in this part.
Symbols used in bounds-based prediction.
Even if the same configured job is submitted in a given execution environment, the job execution time may vary every time. Network, IO performance, and non-determinism of task scheduling are all the factors that may impact the final result. Taking this into consideration, it is reasonable to predict the time bounds and the gap between lower and upper bounds indicating the range of possible completion time.
First, using LWLR model introduced before, we predict the average and maximum task durations of different execution phases including map, shuffle, and reduce phases. Then, we utilize the bound-based model to compute the upper bound and lower bound of execution time for different phases in the job process which are completed in multiple waves. The equations are listed below




In HDFS and Ceph file systems, a job with a new dataset is partitioned into
In this situation, max parallel map and reduce tasks are determined by max containers that can be allocated to the tasks. They can be determined using the following expressions

Usually,
It is worth noting that since there exists overlap between shuffle phase and map phase, we need to divide the shuffle phase into two parts: the overlapping portion with map stage and the non-overlapping part. We characterize the two shuffle phases.
If the reduce number allocated to a MapReduce job is less than the total max parallel reduce tasks, then the shuffle phase will be finished in one single execution. The lower bound time spent on the shuffle phase can be calculated as the following formula

Finally, the overall job execution prediction time can be calculated using the following equation

Extended job execution prediction model
By extracting more representative features to represent a job and assigning weights to different features, we extend the improved HP model proposed in Khan et al. 19 for predicting the MapReduce job completion time.
In this article, LWLR is used to predict the durations of the map, shuffle, and reduce phases. In fact, LWLR can be used to predict any time and what we need to do is to change the corresponding representing values in Y.
The feature sets employed in the LWLR are the modeling parameters listed before. That is, we use input file sizes

where m is the number of sample points.
Each variable
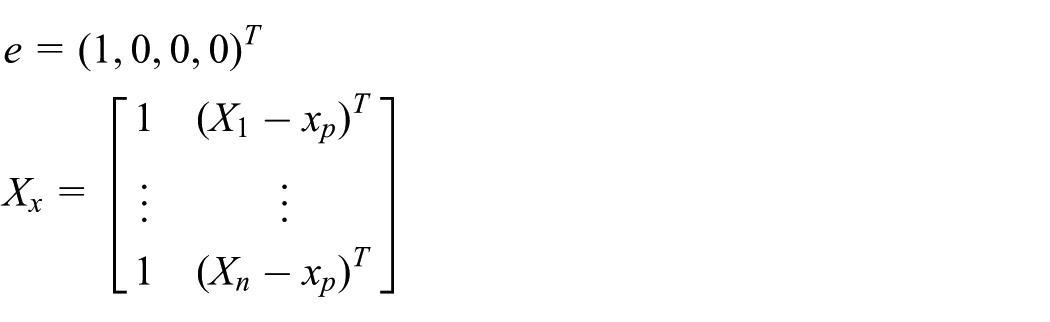
Then, we define a matrix X to contain all the training dataset and a vector Y to express the time that corresponds to the sample point

For the prediction of

Finally, from standard weighted least-squares theory, we get the prediction time of new instance

Here,
Experiment and performance evaluation
In this section, we will evaluate the performance and accuracy of InSTechEM prediction model.
Experimental setup
Hardware and Hadoop configuration
In the experiment, we set up our edge cloud on an OpenStack cloud platform in our lab, which is composed of nine physical machines and eight of them are compute nodes hosting virtual machine (VMs). Each compute node has a 12-core Intel 2.4 GHz CPU, 64 GB memory, 10 Gbps network bandwidth, and 2T disk capacity, and runs CentOS 7.1. Each VM runs Ubuntu 12.04 64bit. Each compute node hosts six VMs and each VM is allocated with two CPU cores, 5 GB memory, and 80 GB disk storage. We use Hadoop-2.7.1 and set the replication level of data block to 3 and the max container of map/reduce to 5 per node. A physical topological diagram of the experiment environment is shown in Figure 3. In our edge cloud experiment environment, Hadoop directly uses Ceph 26 instead of HDFS as the storage platform which takes VM as the unit. Ceph, a free-software storage platform, presents object, block, and file storage from a single distributed computer cluster. When deploying Hadoop, we manually configure the components to get to Ceph osds by S3 API. Ceph osd configuration is 1.8 TB disk (every pm has one disk) and we have five Ceph nodes. We build four Hadoop clusters. They all have the same VM placement and VM specification but with different numbers of VMs (i.e. different cluster scales). Number of VMs that compose the clusters is 12, 24, 36, and 48.

Edge cloud big data platform experiment environment.
Tested programs
We employ two typical MapReduce applications. The TestDFSIO benchmark is a read and write test for file systems. It is helpful for tasks to discover performance bottlenecks in the network. Map tasks of TestDFSIO perform parallel read and write jobs, respectively, and the reduce task processes statistical information to get the throughput and average IO speed. The Sort benchmark simply uses the map/reduce framework to sort input data. The inputs and outputs must be sequence files where the keys and values are bytes writable.
Datasets
We test our performance model with data varying from 1 to 100 GB for TestDFSIO and data varying from 1 to 45 GB for Sort. TestDFSIO write job generates data for the read benchmark. RandomWriter 3 tool in the Hadoop package is utilized to generate random data. These types of data are used by the Sort program.
Job profile information
We perform our experiments with TestDFSIO and the Sort benchmarks on the four Hadoop clusters, respectively, and gather the job profiles from the Hadoop log. Table 2 shows the job profile information of Sort that is carried out on 12 VMs. We vary the reduce number from 72 to 144.
Job profile information of Sort.

Job execution prediction
We implement and evaluate the performance model InSTechEM in three scenarios with Sort as shown in Figure 4. The blue line on the graph shows the InSTechEM solution that serves as a model for the job which represents predicted job execution time and the red dots are duration measurements. Shorter distance between the two lines indicates better quality that the model achieves. All of the four subgraphs show excellent fit.

Prediction of job execution time of Sort: (a) VM = 24, (b) VM = 36, (c) VM = 12, and (d) all data.
TestDFSIO only has 1 reduce task and we set 8 map tasks for 1 GB data size and 80 map tasks for other data sizes. We run TestDFSIO read and write benchmark on Hadoop clusters with VM number set to 24, 36, and 48. We compare predicted job execution time to the measured execution time as shown in Figure 5. Figure 5(a) shows the prediction of TestDFSIO write jobs under VM number fixed to 48 and Figure 5(b) shows the prediction time with all the training data of TestDFSIO write job. Both graphs show that the calculated values coincide with the experimental results. Similar results can be obtained from TestDFSIO read jobs as shown in Figure 5(c) and (d).

Prediction of job execution time of TestDFSIO read and write: (a) VM = 48 (write), (b) all data (write), (c) VM = 48 (read), and (d) all data (write).
Accuracy of the MapReduce performance model
Cross validation
We perform a leave-one-out cross validation 12 to study the prediction accuracy of the model. That is, if there are N samples, each sample is used as a validation set separately and the rest N − 1 samples as the training set. We utilize average relative errors (ARE) over the N rounds of testing to formally assess the accuracy of performance model. ARE can be computed using the following equation

where
Table 3 shows ARE and
ARE and

ARE: average relative error.

Relative error of Sort and TestDFSIO.
Conclusion and future work
In this article, we proposed and evaluated the InSTechEM, an IoT Big data–oriented extended model (EM) for MapReduce performance prediction in multiple edge clouds architecture, which predicts MapReduce job total execution time in a more general scenario with various reduce numbers and cluster scales. The proposed model is built based on historical job execution records and employs LWLR technique. By extracting more representative features to represent a job, the extended model (EM) can effectively predict the total execution time of MapReduce applications with the average relative error of less than 10%.
With the growing number of IoT sensors, the multiple edge clouds will expand across many distributed locations. As future work, we plan to consider a scalable multi-tier edge clouds architecture to address the possible performance bottlenecks caused by a small number of edge clouds with one centralized cloud. At the same time, we will keep improving the MapReduce performance prediction model by studying details of MapReduce and Hadoop framework. Furthermore, the enhanced performance prediction model is utilized to estimate the amount of resources for Hadoop jobs with deadline requirements in multiple edge clouds.
Footnotes
Acknowledgements
The authors thank Professor Duan Qiang at the Pennsylvania State University Abington College, USA, for valuable suggestions and English correction of the manuscript.
Academic Editor: Chin-Tser Huang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by 2016–2019 National Natural Science Foundation of China under Grant No. 61572137 (Multiple Clouds based CDN as a Service Key Technology Research), Shanghai 2016 Innovation Action Project under Grant No. 16DZ1100200 (Data-trade-supporting Big data Testbed), and 2015–2017 Shanghai Innovation Action Project under Grant No. 1551110700 (New media-oriented Big data analysis and content delivery key technology and application).