
Abstract
In the mobile sensor networks, the sink node registers its own events in the network, and when the sensor node finds an event of interest to the sink node, it sends a response message. The data traffic of the communication process in the application scenario has a bursting feature, and sometimes network congestion occurs. Therefore, when designing the data routing protocol, it is necessary to consider how to reduce the communication overhead in the network and improve the success rate of the query. To address this issue, this article proposes a routing protocol for content-based publish/subscribe, which is applicable in mobile sensor networks. The core idea of routing protocol for content-based publish/subscribe is that all sensor nodes in the network are divided into several clusters, and the transmission of sensing events is based on these clusters. The protocol consists of event publishing, subscription, matching, and unsubscribe. The inquirers send subscription information to the network, which are saved in the cluster head network. Published events are also transmitted to the cluster head network and the matching computation is performed. If the match is successful, events will be sent to subscribers, thus improving the success rate of queries. The simulations show that compared with existing methods, routing protocol for content-based publish/subscribe consumes lower matching events transmission energy to obtain a higher success rate. In the case of a large number of published events, the network lifetime of the routing protocol for content-based publish/subscribe protocol can be increased by 28%–54%, and the subscription success rate remains above 80%.
Keywords
Introduction
In an event-driven sensor network, the mobile sink node will register only the events in the system that it is interested. When the sensor node finds the events that the sink node is interested in, it will send out the response events. This process is also known as push mode, which is a kind of many to one communication. 1 This mode is often used in monitoring multiple abnormal events. The emphasis on the data transmission process is the timeliness and reliability of communication. The data transmission is bursty, which results in network congestion. Therefore, it is necessary to consider how to reduce the communication cost when designing the data transmission protocol.
Mobile sensor network (MSN) is a common event-driven sensor network. At present, most of the researches on MSN data collection technology are aimed at how to collect the data from the sensor to a single or multiple aggregation points as indistinguishable as possible.2,3 However, in practical applications, the types of data collected by each sensor are diverse. Because the receiver of the data may only be interested in one or some of them, these data need to be transmitted by classification. For example, at disaster relief sites, different teams only need data about their respective areas of assistance. 4 For another example, different personnel are interested in different information in a military combat system. A soldier may only need data about the distribution of the enemy forces around him, while the command and control department need information about the overall deployment status of the battle field. 5 Another example is the monitoring of diseases in life. We can send the data of different kinds of diseases collected by sensors to different monitoring agencies for timely processing. 6 In order to meet the requirements of the above applications, it is necessary to set up a highly flexible and dynamic data distribution and processing system. Such data distribution and processing capabilities are provided by publish/subscribe (pub/sub) systems. 7
The implementation of the subscribe/publish function of a sensor network is challenging because the subscriber node does not know when and where the events of interest occur, and the publish node does not know which node in the sensor network is aware of the published events of interest to it. The simplest way to allow publishers and subscribers to communicate with each other is to use a radio policy, such as sending subscription messages to all nodes in broadcast form, or publishing all events to all nodes in broadcast form. Although this broadcast strategy can transmit event messages rapidly, its communication cost is intolerable for resource-constrained MSNs. 8 Another approach is to provide a central node to receive all subscription messages and publish them. Although the communication cost is minimized, the load on the central node is very large, especially when the number of subscribed messages and published messages is large. Consequently, the energy of the central node will be quickly exhausted, making the continuous communication on the network ineffective. 9
Most of the existing routing protocols are directed at traditional sensor networks, and the adaptability to mobile sink nodes is not good. Therefore, it is necessary to conduct new research on the scenarios of MSN. Combining the characteristics of the publish/subscribe system and MSN, this article proposes the routing protocol for content-based publish/subscribe (RPCP), a routing protocol based on content coverage publish and subscribe models. The protocol consists of event publishing, subscription, matching, and unsubscribe. The inquirers send subscription information to the network, which are saved in the cluster head network. Published events are also transmitted to the cluster head network, and the matching computation is performed. If the match is successful, events will be sent to subscribers to improve the transmission success rate while minimizing the energy consumption of sensor nodes. The design of RPCP protocol is suitable for MSN.
Related works
There are two kinds of nodes in MSN, namely static sensor nodes and mobile sink nodes with sufficient energy. The sensor node collects the data transmission process of the sensing data along the predetermined route to the mobile sink node, which can also be invoked based on the event propagation process. 10 The subscription/publication model is introduced into the MSN. When an aggregation node is interested in an event in the network, it can tell the MSN it is interested in the event by sending subscription information, and then, the sink node does not have to wait. When the sensor node detects the occurrence of such events, it sends a relevant event message to the interested sink node. It can also specify some event patterns and only notify the sink node when the event matches these patterns. 11 This pattern of data transmission when events occur in the network makes it an event-driven network.
For the problem that data cannot be served due to client mobility, some studies have proposed their own methods. For example, a study 12 proposes an event submission protocol based on client destination prediction. However, this protocol ignores that the arrival of events in the process of client mobility is a continuous feature. How to solve this problem has become a severe test for the system. Another study 13 considers the issue of publisher mobility and proposes four strategies to reduce the impact of publisher mobility on system performance. In addition, Leyva-Mayorga et al. 14 propose a novel algorithm to enhance the reliability of the highly dynamic network events in the transmission, which provides strong expressiveness but is less efficient. Tekin and Sahingoz 15 proposed a topic-based publish and subscribe mechanism (PSM). By using this mechanism, it is aimed to decrease the energy consumption and increase the network lifetime. The algorithm has a large event transmission delay, and the node periodically broadcasts its own subscription conditions across the entire network, causing a large amount of energy consumption and resource waste.
The communication, computing, and storage capabilities of sensor nodes may be limited, due to a fault or failure. In addition, MSNs do not require infrastructure and have strong autonomy. Therefore, it is unrealistic to choose a sensor node as a central node in MSNs to receive messages from subscribers and publishers. In order to adopt subscription/publication mechanism in MSNs, some nodes can be selected as message brokers, and cluster heads can be chosen to play this role. 16 The choice of cluster heads is very important, and improper selection of cluster heads will result in inefficient data transmission.
A study by Liu et al. 17 presents a community-based event transmitting protocol (CETP). The core idea of this protocol is that all sensor nodes in the network form a number of fixed communities based on their interconnection and transmit events based on these communities. CETP protocol consists of two parts: event transmission and queue management. In event propagation strategy, besides sending as many events as possible to mobile users, some events stored by mobile users will also be sent back to sensor nodes in the community to improve the success rate of event transmission; queue management is event based. The number and lifetime of successful transmission determine the importance of events in the storage queue and the discarding principle, thus reducing the energy consumption of network transmission. The disadvantage of the CETP is that some nodes may be outside the community, causing the loss of perceived data.
Fan et al. 18 use a mobile sink to travel around the monitoring area. When the mobile sink travels to a position, it serves as a new source. Since multiple sources can simultaneously forward data packets, flooding speed can be accelerated. The information transfer of this method leads to a large query delay. S Ganala 19 formulates the problem of scheduling the MSN in distributed manner so that the entire region is covered without coverage holes with minimum energy depletion. Finally, some computationally practical algorithms for multiple MSNs with fault and non-fault tolerant support are presented. Due to the distributed storage and matching of data, the query efficiency of this method is not high. Kumar et al. 20 propose a new ant colony optimization–based mobile sink path determination for MSNs. The objective of the proposed algorithm is to maximize the network lifetime and minimize the delay in collecting data from the sensor nodes. The disadvantage of this algorithm is that the data matching is more complicated, and the energy consumption of the node is larger, thereby reducing the network lifetime.
In MSNs, nodes are in a form of dynamic self-organization. Due to the continuous joining and exiting of nodes, the network topology changes. Publishing and subscribing system can adapt well to dynamic situations. That is to say, sensor nodes can publish their capabilities to the proxy nodes in the network, and the proxy nodes report according to the sensor nodes. The availability of the capability information of the sensor nodes, and an intelligent distribution of subscription information sent by the upper layer, makes the subscription information more targeted, but also reduce the communication of redundant information, which can effectively reduce energy consumption. In addition, the information returned by multiple nodes can be efficiently fused in the proxy node, thus further reducing the amount of data transmission.
Network model
The routing topology of sensor networks can be divided into two categories: planar structure and cluster structure. Planar structure means that all nodes in the network are identical in function and status and complete communication tasks together. The advantages of this structure are simple topology, easy implementation of routing algorithm, no need for too much structural maintenance, and no special nodes in the network. The status of all nodes in the network is equal. If a node dies, the other can take its place; hence, such a network structure is very robust. The disadvantage of this structure is poor scalability. That is, when the network monitoring range changes dramatically, there is the need to recalculate the routing. 21
Contrary to the planar structure, the nodes in the network have different levels. Some are ordinary sensor nodes, while others act as managers. 22 Cluster routing protocol divides sensor nodes into hierarchical levels. As shown in Figure 1, several adjacent nodes form a cluster and one node in each cluster acts as the cluster head. Two cluster heads can communicate directly to form a basic network backbone. All cluster communications are forwarded through the backbone network.

Network topology with cluster structure.
The cluster routing protocol includes four parts: a clustering protocol, a cluster maintenance protocol, a cluster internal routing protocol, and an inter cluster routing protocol. The clustering protocol solves how to effectively partition sensor nodes into clusters in a dynamic distributed network environment. It is the key to the cluster routing protocol. The cluster maintenance protocol is responsible for the maintenance of the cluster structure during the node movement process, including the functions of the clusters exiting and adding mobile node, cluster generation, and extinction. The inter-cluster routing protocol solves the data communication between the clusters and realizes the transmission of information among the clusters through the cluster heads. The clustering algorithm uses the method proposed by Abushiba et al. 23 The energy consumptions of cluster heads are normally high and it is easy for information in transmission to die prematurely. Therefore, the proposed algorithm will select a cluster head according to its energy consumption and perform the migration of subscription events.
The publish/subscribe system of MSNs is also composed of event publishers, event subscribers, and event agents, in which cluster heads act as agents. According to the proposed network model, the publish/subscribe system of RPCP consists of two layers. The first layer is the static sensor nodes with random distribution. They collect data and act as publishers to organize these data into events for sending. The second layer is the backbone network composed of cluster heads, which acts as agents for temporary storage and content matching of events and are responsible for data transmission. Random mobile nodes, which can be people, vehicles, and so on, generally have high energy and large storage space. They are subscribers in the network having their own subscription conditions and are interested in specific events.
Similar to most existing publish/subscribe systems, the key problem that MSN publish/subscribe systems need to solve is how to make published events reach interested subscribers as low in cost, efficient, and reliable as possible. In routing transmission strategy, the average transmission success rate of events is the most important design goal. Apart from the success rate of event transmission, energy consumption should also be taken into account. In order to achieve a balance between transmission delay and energy consumption, this article proposes an event transfer protocol RPCP based on publish/subscribe mode in MSN. The next section describes the RPCP protocol in detail.
The RPCP
In event-driven sensor networks, mobile sink acts as a subscriber. The cluster heads of each cluster are content classification libraries and message agents, and the sensor nodes are publishers.
Assuming that a subscription event consists of a set of overridden attributes, all attributes matching the subscription content S are recorded as N(S). For subscriptions S1 and S2, if
Let addSub(S) denote the establishment of a new subscription S and cancelSub(S) denote the cancelation of subscription (S). The idea of optimizing subscription coverage can be implemented in the following steps:
Step 1. If a subscription overriding S has been forwarded to the upstream content cluster head, addSub(S) will no longer forward to the upstream.
Step 2. When the upstream content cluster head receives addSub(S), deletes the routing table entries that are covered by S.
Step 3. If a query in the subscription table indicates that the overriding subscription S forwarded to an upstream cluster head has not been canceled, cancelSub(S) will not be forwarded to the cluster head at the same time.
Step 4. If cancelSub(S) is successful, end the algorithm.
For subscriptions S1 and S2, and S1 → S2, if addSub(S1) and addSub(S2) come from the same node P, then S2 is received first. This subscription mode will delete the entries of S2 from the routing table to minimize the size of the routing table. If cancelSub(S1) is issued before cancelSub(S2), the subscription mode will resend the subscription S2. From the above-mentioned description, we can see that in order to minimize the size of the routing table, more computational costs are required. In this article, a suboptimal content coverage subscription algorithm is proposed and adopted. Its idea is described as follows:
Step 1. If a subscription covering S has been forwarded to the upstream content cluster head, addSub(S) will no longer forward to the cluster head.
Step 2. If the subscription overwriting S that has been forwarded to the upstream content cluster head is not unsubscribed and addSub(S) has not been forwarded to the cluster head, then cancelSub(S) will not be forwarded to the cluster head.
Step 3. If cancelSub(S) is forwarded, it is necessary to reconsider whether to forward subscriptions covered by S.
Suboptimal subscription coverage acknowledges the fact that subscription information has been forwarded. When processing subscriptions, it does not consider whether current subscriptions cover previously received subscriptions. That is, it does not delete the subscriptions from existing subscriptions that are covered by current subscriptions, and it does not recalculate the subscription coverage relation when canceling subscriptions. For subscriptions S1 and S2, where S1 → S2, if addSub(S2) and addSub(S1) come from the same node P, S2 is received first; the suboptimal subscription coverage mode does not delete the subscription S2 after receiving the subscription S1, but still maintains the relation S1 → S2 on the cluster head. If S1 is received prior to S2, there is no need to retain subscription S2 on the cluster head. That is to say, suboptimal subscription coverage is affected by the order of subscription and therefore the size of the subscription content on the cluster head.
Selective coverage subscription content routing is based on coverage technology and utilizes the following principles: if subscription S1 covers S2, only S1 needs to be sent to the upstream cluster head, because S1 can express interest on behalf of S2. The covered subscription does not need to be forwarded to all content cluster heads, thus reducing the subscription size and routing table size of cluster head. The following sections provide an algorithmic description of the publish/subscribe system of sensor networks, by considering the algorithms for message publishing, message subscription, content matching, and message unsubscribe.
Message subscription algorithm
Message subscription algorithm in publish/subscribe systems describes the transmission of subscription messages from the sink node of subscribers to the network. The subscription messages are transmitted in the network and temporarily stored in cluster head nodes. As shown in Figure 2, subscription S1 has previously maintained a copy on each cluster head upstream.

Subscription scheme.
At this time, node C2 publishes a subscription S2 upstream. When cluster head R1 receives S2, the subscription module is responsible for judging the relation between S2 and S1. When the relation between S1 and S2 is determined, the relation will be maintained in cluster head R1. Because S1 covers S2, there is no need to forward S2 upstream. So, in the upstream cluster head R3 of R1, there is no need to maintain a copy of S2. Similarly, because S3 and S4 satisfy the relation of S3 → S4, the relation of S3 → S4 is maintained on cluster head R2, and no further transmission of S4 to upstream cluster head R3 is needed. According to the content forwarding strategy, the more coverage relations between subscription content (expressions), the smaller number of clusters will be maintained on the higher level.
How to maintain the relation between subscriptions in publish/subscribe system is the most critical issue. This will involve performance issues such as correctness, efficiency, and dynamic adjusting function.
For any node R representing a content cluster head in the content routing network, the subscription algorithm is shown in Algorithm 1. After receiving the subscription information from the downstream nodes, the cluster head node updates its own routing table. Then, look at the upstream cluster head list and forward the subscription information.

Message publishing algorithm
In the publishing algorithm of publish/subscribe system, sensor nodes in the network try their best to find the appropriate path, so that the perceived data can be sent to subscribers efficiently and reliably. The goal of message publishing algorithm design includes reliable message forwarding, reduced node energy consumption, and node load balancing. Among them, the reliability of message forwarding in the network is the main design goal.
In the publish/subscribe system, the receivers of each perceived message cannot be determined beforehand. Therefore, most of the existing publish/subscribe data transmission protocols are based on broadcasting strategy, and some optimization measures are adopted to reduce the amount of data forwarding. For the dissemination of published messages, more optimization measures are adopted to check whether the subscribers are interested in this perceived message at the cluster head; when the cluster head receives the published message, it judges whether the subscribers are interested by the coverage relationship between the published message and the subscribed message.
Define the matching function f as shown in formula (1)

where
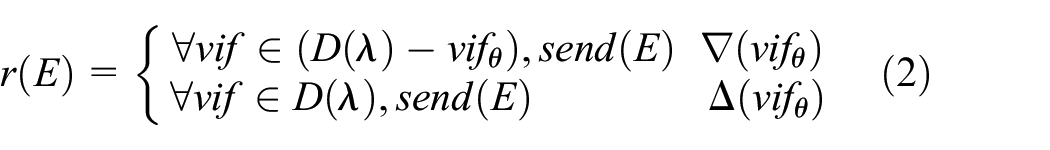
where
The routing algorithm for publishing messages is shown in Algorithm 2. When the cluster head node receives the publish message, it checks whether the message already exists and ignores the message if it already exists, otherwise saves the message. If the message comes from a downstream cluster head, it is broadcast to the upstream cluster head set. Otherwise, the message is broadcast to the downstream cluster head set.

Content matching algorithms
Content matching in publish/subscribe system mainly has two modes: centralized matching mode and distributed matching mode. Centralized matching mode is usually set up with a central server in the network. Subscribers send subscription messages to the central server for registration. Publishers also send publication messages to the central server for registration. After the central server receives the publication messages, it will automatically find out which among the subscribers meet the matching criteria in the cache. When the matching subscribers are found, the publishers will also send the published messages to the relevant subscribers.
There is no need to set up a central server in the distributed matching mode; however, some distributed nodes in the network act as the proxy. Subscribers broadcast the subscription messages to the network, and the proxy nodes in the network store the subscription information. Publishers also broadcast messages to the network. Subscription information and publication information are matched on the proxy nodes. If the matching is successful, the detailed information needed by subscribers is sent to the nodes. In this way, the matching calculation between subscription and publication messages is completed by the agent nodes distributed in the network, and no special central node is needed.
Due to the characteristic ease of failure and random distribution of sensor nodes, centralized matching mode is not suitable in this scene, but distributed matching mode can be adopted. In this article, the cluster head node is set as a local center node to avoid wasting too much energy in matching calculation for all nodes.
After receiving the publish message

Unsubscribe message algorithm
Suppose subscriptions are sent upstream in the order of S1, S2, S3, and S4, and there is an ordering relation: S2 → S1, S3 → S1, and S4 → S3. The upstream cluster heads will maintain the subscription relation structure as shown in Figure 3. If node C4 sends an unsubscribe operation

Unsubscribe scheme.
In order to better support unsubscribe function, a flag is needed for each sending to the upstream cluster head to indicate whether the subscription exists in the upstream cluster head.
As shown in Figure 3, after the unsubscribe operation is performed on the cluster head, it is necessary to check whether the upstream cluster head has the same copy or has not been unsubscribed. If the same copy still exists on the upstream cluster head, it must also be sent upstream, so that the upstream cluster head can perform the unsubscribe operation. Otherwise, the higher the cluster head, the more information that has already been unsubscribed will be accumulated. This situation is described as follows:
S 4 and S3 are sent to the upstream in sequence. Due to the relation S4 → S3, the upstream cluster heads will maintain the relation structure. If only the lowest cluster head performs the unsubscribe operation when subscribing to S4, the S4 maintained by the upstream cluster heads will remain in the cluster head forever and become the real “garbage” information. The description of the unsubscribe process is shown in Algorithm 4. After receiving the unsubscribe message from the downstream node, the cluster head updates the subscription relationship structure and the routing table information and forwards the message to the upstream cluster head set.

Performance analysis and simulation
Performance analysis
Definition 1: Set the subscription size to
Theorem 1
The closer the cluster head node (layer 0) is to the core cluster head, the smaller the subscription size is maintained.
Proof
Assume that each cluster sends a subscription. Then, the subscription size of each content cluster head in Layer
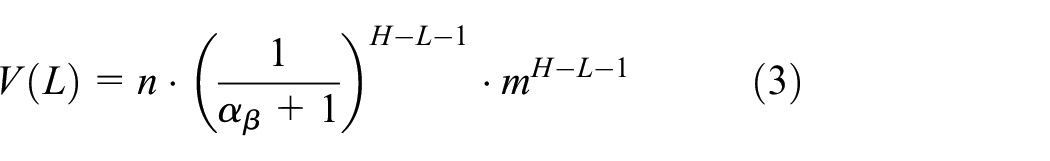
It can be seen that the function V(L) in formula (3) is incremental for L.
Therefore, the closer to the node of the core cluster head (layer 0), the smaller the subscription size maintained.
Theorem 2
When
Proof
Assume that each cluster sends a subscription. The subscription size of each content cluster head in H1 layer is n and that of the content cluster head

Obviously,

Let

Formula (7) is used for further checking

Due to
Theorem 3
The larger the value of
Proof
Assume that the message transmission time between nodes in the topological network is constant c, and the total routing time of event message from the publishing cluster head to the matching subscription cluster head at the other end is
From formula (3), the subscription size
The total routing time

For the link message transmission time of

Obviously,
For
In summary, with the increase in
Definition 2
Let the number of attributes (dimensions) of any subscription be d and the coverage ratio of attributes (dimensions) be
Theorem 4
Coverage ratio based on global subscription decreases with the increase in attribute (dimension) d; when d > 1, V(P) < V(S).
Proof
Assuming that based on the coverage ratio
Then, we can see that
Taking subscription events as the basic unit for calculating subscription size, formula (10) can be obtained from formula (9)

Because

That is, V(P) < V(S).
The above theorem shows that the larger the coverage relationship, the smaller the subscription size and the shorter the total routing time of matching event messages. Event coverage technology based on smaller granularity is the reason to improve the overall performance of the system by increasing coverage ratio
The randomness of cluster head event subscription has some influence on the performance of publish/subscribe system. Set the subscription size
For subscription size
Simulation and results
The performance of data transmission method in publish/subscribe mode is analyzed in this section, and hence, the characteristics of our proposed method are illustrated by comparing with several existing methods through simulations.
To verify the capability of the proposed RPCP algorithm, we performed simulation to compare its performance with two publish/subscribe messaging algorithms: PSM 15 and CETP. 17 In the simulation, we used MATLAB as the simulation software. We also assumed that there are 200 nodes in MSNs, and the nodes are randomly distributed in the area with radius of 200 m. The various parameters we set for the simulation are presented in Table 1.
Simulation parameters.

In this investigation, three groups of simulations are carried out to analyze and compare the event matching time and the successful subscription time for different scale of published events. In order to reduce the impact of random events on the simulation results, each group of simulations was performed five times, and the arithmetic mean of the five times was taken as the basis for comparison.
Simulation 1: The impact of publication size on subscription success time
Subscription success time is the time it takes a subscriber to send a subscription message to the network and to receive matching awareness data. Generally speaking, the larger number of published event content to be processed, the longer the processing time of the algorithm. This consequently increases the time of event transmission to subscribers, thus affecting the efficiency of event processing. Simulation 1 compares the average time required for subscribers to successfully receive published events. We performed the simulation using three publish/subscribe messaging algorithms with varying numbers of published events.
The data curves in Figure 4 show that the receiving time of RPCP algorithm increases slowly, and CETP algorithm is close to RPCP algorithm in terms of average receiving time performance. The PSM algorithm is mostly affected by the size of the publication. When the number of publications is less than 800, its performance is close to or even better than RPCP algorithm. When the number of publications is more than 800, the average receiving time sharply increases. The RPCP algorithm uses the cluster head to deliver the publish and subscribe messages, which can effectively reduce the number of times the message is forwarded, so that the time for obtaining the subscription result is shorter.

Comparison of average receive time at different number of published events.
Simulation 2: The impact of published scale on network lifetime
When there are more events in the network, the energy of nodes will be exhausted quickly, resulting in network holes, and the rate of packet loss in data transmission will increase. The network is considered dead when the packet loss rate reaches a specified threshold. Figure 5 compares the network lifetime of the three publish/subscribe messaging algorithms under different number of events.

Comparison of network lifetime at different number of published events.
Figure 5 shows that the decline in the network lifetime of RPCP is gradual as the number of published events increase, and it has the longest network lifetime for almost all published events sizes. It can be seen from Figure 6 that the network life of the proposed method is higher than the other two methods when the nodes are denser. For example, when there are 50 published events, the network life of the three methods is not much different, and when there are 800 published events, the RPCP method is 54% longer than CETP and 28% longer than PSM. CETP has the fastest decline in network lifetime due to the need to maintain the community structure for more communications. The RPCP algorithm sets a reasonable number of cluster heads and allows the cluster head to periodically rotate, thereby reducing the energy consumption of the entire network and improving the survival time of the network.

Comparison of energy consumption at different number of published events.
Simulation 3: The effect of the published scale on energy consumption
As shown in Figure 6, the three methods will increase the energy consumption with the number of published events increasing. The CETP method consumes more power because each message needs to be negotiated multiple times with neighboring nodes before transmission. When the message in the message queue is full, the old message in the queue needs to be deleted so that we can receive new messages. The PSM policy only uses the distance value of the message as a reference for the transmission cost. Therefore, as long as the short-distance message, it can replace the long-distance message. Meanwhile, the method does not consider whether the message is a useful message, which may cause a large amount of invalid data to be forwarded and meaninglessly consume network energy. For sensor nodes, the most energy is consumed when sending and receiving data. The RPCP method proposed in this article filters the publishing and subscription information, thus effectively reducing the amount of information that needs to be transmitted in the network, thus effectively reducing the network energy consumption.
Simulation 4: The effect of the published scale on success rate
As can be seen from Figure 7, since the method proposed in this article allows the cluster head node to play the role of information matching and better save energy, as the number of events in the network increases, the subscription success rate decreases slowly. The cluster head nodes in the network adopting the RPCP method have the matching function of publishing and subscribing messages, so that a high success rate can be maintained. When the number of published messages is large, the message growth in the network may cause delay and loss, resulting in a decrease in subscription success rate. However, the method proposed in this article is the slowest decline and remains above 80%, because the selective forwarding of messages by the cluster head node effectively reduces the amount of communication in the network.

Comparison of success rate at different number of published events.
Conclusion
This article first summarizes the concept and characteristics of publish/subscribe system and then introduces the research status of using publish/subscribe system in sensor networks. By using existing clustering routing protocols, cluster head nodes are defined as message agents in publish/subscribe systems to collect and match publish and subscribe information. The basic idea of content-based publish/subscribe system is elaborated in detail. The publish event algorithm, subscribe event algorithm, content matching algorithm, and unsubscribe event algorithm involved in the system are elaborated in detail. The implementation algorithm is given. The effectiveness of the method is proved by performance analysis and simulations.
Footnotes
Handling Editor: Zhong Shen
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is partly supported by National Natural Science Foundation of China (NSFC grant numbers: U1836116), the project of Jiangsu provincial Six Talent Peaks (Grant numbers: XYDXXJS-016), and Open Project Program of Jiangsu Key Laboratory of Security Tech. for Industrial Cyberspace (Grant numbers: STICB201905).