
Abstract
Recently, many lightweight block ciphers are proposed, such as PRESENT, SIMON, SPECK, Simeck, SPARX, GIFT, and CHAM. Most of these ciphers are designed with Addition–Rotation–Xor (ARX)-based structure for the resource-constrained environment because ARX operations can be implemented efficiently, especially in software. However, if the word size of a block cipher is smaller than the register size of the target device, it may process inefficiently in the aspect of memory usage. In this article, we present a fast implementation method for ARX-based block ciphers, named two-way operation. Moreover, also we applied SPARX-64/128 and CHAM-64/128 and estimated the performance in terms of execution time (cycles per byte) on a 32-bit Advanced RISC Machines processor. As a result, we achieved a large amount of improvement in execution time. The cycles of round function and key schedule are reduced by 53.31% and 31.51% for SPARX-64/128 and 41.22% and 19.40% for CHAM-64/128.
Introduction
In these days, Internet of things (IoT) technologies were rapidly developed, and they are already involved in our lives. As IoT devices are more deeply embedded around us, the security of IoT became more important because they deal with our sensitive data. However, IoT devices consist of small memory and low power compared to generally used PC or laptop. 1 These computing environments are called resource-constrained. For the security of resource-constrained devices, security technologies have to be composed more lightly, so we need lightweight block ciphers, which can be the basis of lightweight security technologies. In reality, a lot of lightweight block ciphers are being proposed internationally such as PRESENT, 2 SIMON/SPECK, 3 Simeck, 4 SPARX, 5 GIFT, 6 and CHAM 7 . Most of these block ciphers are designed with Addition–Rotation–Xor (ARX)-based structure. ARX-based block ciphers can be implemented faster and more compact than substitution–permutation network (SPN)-based block ciphers. However, this does not mean that ARX-based block ciphers can perfectly perform without any influence that decreases the performance of IoT devices. Moreover, because of the lack of computing resources, it has to be implemented considering their operating environment.
Many of ARX-based block ciphers are recently proposed to have various instances that can support different block and key sizes. For example, in SIMON/SPECK, they provide five cases of block size (32, 48, 64, 96, and 128) and seven cases of key size (64, 72, 96, 128, 144, 192, and 256). So, SIMON/SPECK has 10 instances according to a combination of block size and key size, and it has a different number of rounds between each other. The word size can be adjusted according to block size and key size. For example, with smaller key size and block size, they perform with 16 bits of word size. And with a bigger key size and block size, they perform with 32 bits of word size. However, in reality, IoT network consists of heterogeneous devices based on various processors including AVR, MSP430, and ARM. These IoT devices are interconnected with each other. 8 When we apply the block cipher for confidentiality in this situation, we have to implement various instances of block ciphers for communicating with each other, although the block ciphers were designed for a specific target processor. If the block cipher’s word size is smaller than the word size of microcontroller (MCU), it can be inefficient because it creates empty space in the general-purpose register of MCU.
In this article, we introduce a fast implementation method of ARX-based block ciphers, including SPARX-64/128 and CHAM-64/128, on 32-bit processors. To improve block cipher’s speed, we propose a parallel implementation of modular addition and rotation, named two-way operation method to this technique. Also, we modify the round function of SPARX-64/128 and CHAM-64/128 to apply the two-way operation method. This article is organized as follows. In section “Preliminaries,” we describe the SPARX-64/128 and CHAM-64/128, which are our target cipher. And in section “Related work,” we introduce related work about the implementation of lightweight block ciphers. In section “Proposed implementation technique,” we introduce our proposal implementation technique, named two-way operation. And we also propose a fast implementation method of SPARX-64/128 and CHAM-64/128 using two-way operation technique. In section “Experiment,” we describe our experimental results in terms of performance. In section “Conclusion,” we summarize our work and conclude this article.
Preliminaries
Description of SPARX-64/128
SPARX was presented by Dinu et al. in ASIACRYPT 2006. For provable security of ARX-based block cipher, it uses large s-box (ARX-based) and simple linear permutation. This approach is named “Long trail design strategy (LTS)” and it can prove the security against differential and linear cryptanalysis. In SPARX, the large s-box is denoted as

SPARX round function.
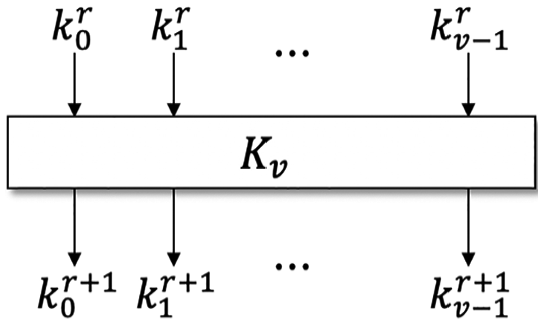
SPARX key schedule.
SPARX is family of ciphers and has three instances according to block size
Parameters of SPARX.


Step structure of SPARX-64/128.
Key schedule of SPARX-64/128;
Description of CHAM-64/128
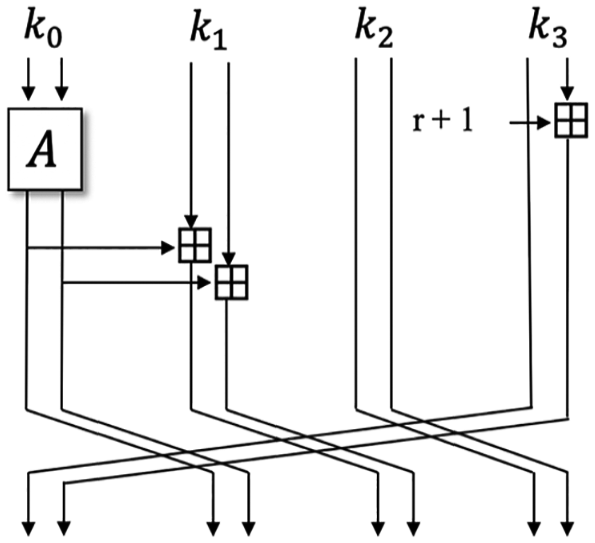
CHAM was presented by Koo et al. in ICISC 2017. For efficiency of the cipher, CHAM was designed considering the resource-constrained instruction set (8-bit AVR, 16-bit MSP). Specifically, AVR and MSP have no instructions which can rotate an arbitrary number. So, authors designed with the rotation which is close to 0 or 8 as possible in the round function, for example, 1-bit rotation and 8-bit rotation. Also, they design a very simple key schedule which can be calculated without updating the key. These features can be more efficient in terms of software. Likewise the SPARX in section “Description of SPARX-64/128,” CHAM is also a family of block ciphers and has three instances, denoted as CHAM-64/128, CHAM-128/128, and CHAM/128-256. Parameters of CHAM are shown in Table 2.
Parameters of CHAM.
In contrast to SPARX, there is no change in the structure of the round function and the key schedule in CHAM according to block size
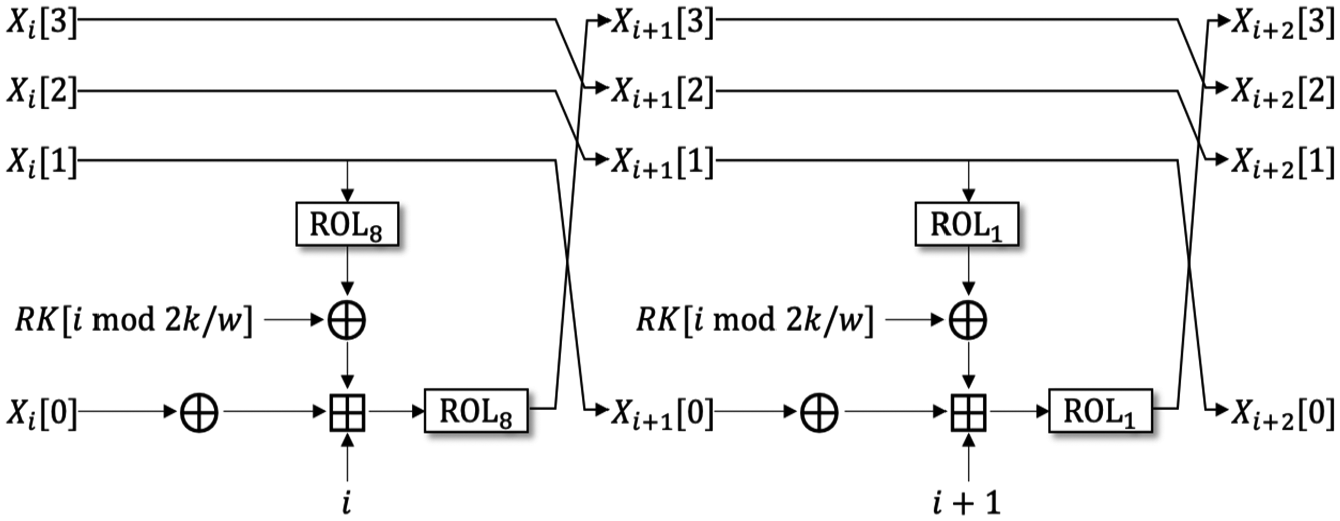
Round function of CHAM. Expression of two consecutive rounds.

Key schedule of CHAM.
Related work
In this section, we introduce some recently conducted research results that are related to software implementations of ARX-based lightweight block cipher. Most of the existing results were focused on a specific target processor, especially on AVR, MSP, and ARM, and researchers consider the architecture of the target processor or available instruction set. In LightSec ’14, Beaulieu et al. 9 introduced optimized implementation result of SIMON/SPECK on 8-bit AVR processor. They considered the feature of the instruction set of AVR and optimized memory access. Also, they present implementing techniques according to three resource-constrained scenarios (lack of RAM, lack of ROM, and required fast runtime).
In ICUFN ’17, Park et al. 10 introduced implementation technique of Simeck on 16-bit MSP430 processor. Loop unrolling method is generally used for better performance. However, if the ciphertext has to be calculated through many rounds, the code size becomes huge. So, the authors implement the round function of Simeck using loop rolling for code size minimization. Then, they store the index of the loop in general-purpose register to use the register-mode-addressing technique which can reuse the index. This approach can optimize not only code size but also cycles. And in WISA ’17, Park et al. 11 also introduced parallel implementation technique of SIMON/SPECK on 32-bit ARM-NEON processor. They use the NEON instruction set, which is a Single Instruction Multiple Data (SIMD) instructions of ARM-NEON processor. Also, they apply the Single Instruction Multiple Thread (SIMT) method. SIMT program can be parallel processing in the core of the processor. In PlatCon-18, Park et al. 12 improve the performance of Simeck on Intel processor using AVX2 instruction set.
Seo et al. 13 introduced optimized implementation technique of LEA, HIGHT on 8-bit AVR, 16-bit MSP, 32-bit ARM, and 32-bit ARM-NEON in TECS ’18. They consider the number of registers and available instruction set of each processor and then revise the internal operations of target algorithms to minimize the cycles. In ICUFN ’18, Park et al. 14 introduced implementation result of CHAM written in Javascript for use in the web browser. They revised the round function of CHAM to reduce the number of rounds and then conducted an experiment on a PC web browser such as Chrome and Firefox.
Proposed implementation technique
Two-way operation technique
Many of ARX-based block ciphers define internal operations using 16-bit variables, such as a modular addition in
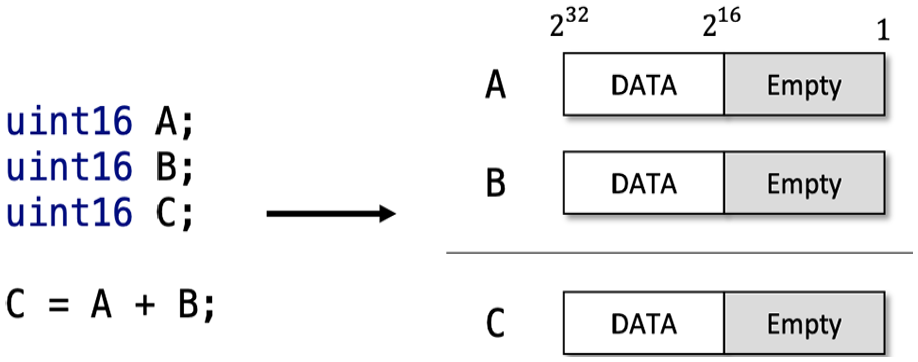
Empty space of
In this article, we named this approach the two-way operation. Two-way operation technique is simple, but it can run two operations at once and get rid of the empty space in registers. It seems similar to SIMD instructions in the perspective of the parallel implementation, which processes multiple data at a time. However, the two-way operation does not use a single instruction. This technique is an alternative method for parallel processing of multiple data on a single variable if the SIMD instruction does not exist in the target processor. The two-way operation is only for wordwise operations. We do not need to consider bitwise operations such as exclusive-or because it works without effect between each bit and also there is no any relation to variable size. It just expands the variable size and put two data to the variable. Otherwise, in the case of wordwise operations, there are relations between data size and variable size.
To calculate two modular additions defined with

To calculate two rotations defined with

Two-way operation technique can be seen requiring the additional operations like checking a carry or bit masking to calculate two operations separately. However, in terms of performance, it does not require more cost. If we implement the two operations separately, it has to load data to the register twice, and it requires more cycles than other simple mathematical operations. That is, calculating twice to general operations spend more times than two-way modular addition, two-way rotation. Furthermore, when applying the two-way operation technique to block cipher, we can achieve the additional improvement of performance with reducing some procedure of cipher such as block rotation if the structure of block cipher is revised to apply our proposed technique optimally.
Implementation of SPARX-64/128
Now, we describe how to revise SPARX-64/128 to implement using two-way operation technique. As you can see in section “Description of SPARX-64/128,” SPARX round function uses

The revised round function of SPARX-64/128.
For using the revised round function, we have to align the round keys to combined form that there are two consecutive round keys. It means that we calculate the two round keys, sort the key words, and then make the round keys by combining the sorted key words one by one. Thus, this procedure can cause a decrease in performance. So, we first prepare words which are the results of word rotation to the left side and then we combine the results with original words. Also, we revised the key schedule which operates with the revised round function. The revised key schedule uses

The revised key schedule of SPARX-64/128.
Implementation of CHAM-64/128
We also revised round function and key schedule of CHAM-64/128. The round function operates to change only one word in one round and then rotates the whole words without any changes in other words. It means that we can calculate the results of each round if we know two words used for encrypting one word. Using this feature, we can separate the results of even-round and odd-round. The revised round function of CHAM-64/128 works like as shown in Figure 10. In this revised round function, there is no word rotation because we separate each result and we can get the same results after operating four rounds of original round function. Therefore, this revised key schedule could be more efficient than the original key schedule.
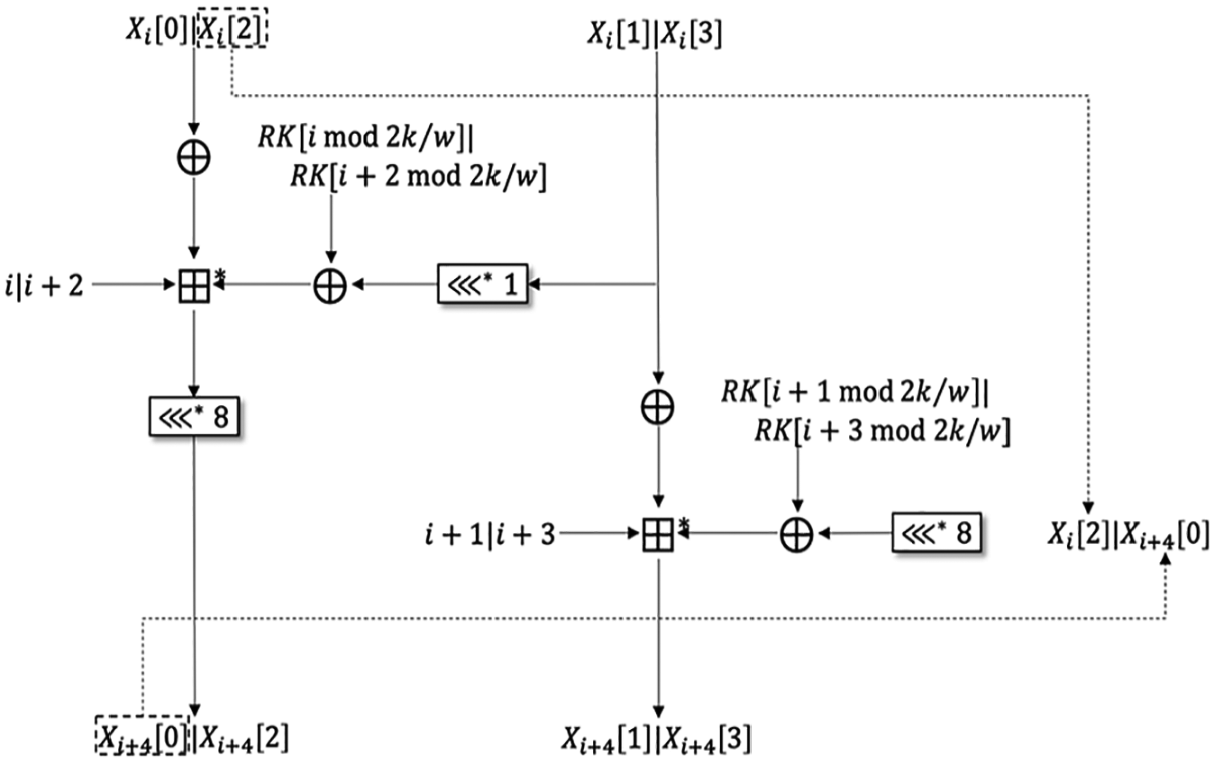
The revised round function of CHAM-64/128.
To the key schedule, we expand the variable size from 16 bits to 32 bits and then combine two key words. When combining the key words, we configure a gathering of even words or odd words for getting the aligned round key. The round key of the revised key schedule can be applied immediately to the revised round function. Also, it can calculate four round keys at once. The revised key schedule of CHAM-64/128 is shown in Figure 11.

The revised key schedule of CHAM-64/128.
Experiment
Environment for experiment
For testing our implementations, including SPARX-64/128 and CHAM-64/128, we chose a target board which is based on 32-bit ARM Cortex-M3 processor. The target board is LAUNCHXL-CC2640R2 made by Texas Instrument Inc. for evaluation of IoT software. The details of the target board are shown in Figure 12. Also, we measured the performance on the Code Composer Studio (CCS), which runs a cross-compile. This target board includes a debugger, so we can get the number of cycles that the processor consumes for processing the instructions. Our implementations are written in C languages. You can check and download the implementation results in our repository. 16

Target board: LAUNCHXL-CC2640R2. 15
Performance results
To check the improvement of our implementations, we prepared two versions of SPARX-64/128 and CHAM-64/128. One was programmed following own algorithm without any revision, and the another was programmed following the revised algorithm, which is based on two-way operations technique. Also, we compared the performances of the key schedule and the encryption. Our experiment results are shown in Table 3. Two-way operations-based implementations performed better than original implementations. In the case of SPARX-64/128, the consuming of cycle reduced about 31.61% in key schedule and 53.31% in encryption. Moreover, in the case of CHAM-64/128, the consuming of cycle reduced about 19.40% in key schedule and 41.22% in encryption. The performance of round functions improved almost twice, and it is the result of the number of rounds reduced half of the original algorithm by revising based on two-way operations. However, the performance improvement of key schedule was smaller than the case of the round function. Because the round keys have to be aligned in each round to apply the revised round function, the revised round function also requires the alignment of the input, and this alignment is carried out just at the point of beginning and end of encryption.
Implementation results of SPARX-64/128 and CHAM-64/128.

Conclusion
In this article, we presented fast implementation techniques for ARX-based lightweight block ciphers, including SPARX-64/128 and CHAM-64/128 on 32-bit processors. We proposed a method which can calculate two modular additions or two rotations defined with
In this article, the results show the improvement of SPARX and CHAM implementation performance using the proposed technique. Our experiment was conducted with C language. However, in a practical environment, many techniques are using the assembly instruction set. In future works, we will research about optimization techniques for various block ciphers and apply other optimization techniques such as SIMD assembly instructions or memory-access optimization.
Footnotes
Handling Editor: Carlos Juiz
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported as part of Military Crypto Research Center (UD170109ED) funded by Defense Acquisition Program Administration (DAPA) and Agency for Defense Development (ADD).