
Abstract
It is difficult to reconstruct the complete light field, and the reconstructed light field can only recognize specific fixed targets. These have limited the applications of the light field in practice. To solve the problems above, this article introduces the multi-perspective distributed information fusion into light field reconstruction to monitor and recognize the maneuvering targets. First, the light field is represented as sub-light fields at different perspectives (i.e. the Multi-sensor distributed network), and sparse representation and reconstruction are then performed. Second, we establish the multi-perspective distributed information fusion under the condition of regional full-coverage constraints. Finally, the light field data from multiple perspectives are fused and the states of the maneuvering targets are estimated. Experimental results show that the light field reconstruction time of the proposed method is less than 583 s, and the reconstruction accuracy exceeds 92.447% compared with the existing spatially variable bidirectional reflectance distribution function, micro-lens array, and others. In the aspect of maneuvering target recognition, the recognition time of the algorithm in this article is no more than 3.5 s. The recognition accuracy of the algorithm in this article is up to 86.739%. Moreover, the more viewing angles used, the higher the accuracy.
Keywords
Introduction
The light field was first proposed by, a former Soviet Union physicist, Gershun 1 in a classic book in 1936. Gershun pointed out that the light field was the all-light function of a point in a given direction, and the function value represented the brightness per unit area. Due to a large amount of data in the light field and the higher acquisition cost, it is difficult to obtain the light field in reality. In 1996, Levoy and Hanrahan 2 introduced the concept of the light field into the range of computer graphics for the first time. They simplified the seven-dimensional (7D) function expression of light into a four-dimensional (4D) function expression. By using a small amount of scene geometry information to achieve the entire light field rendering, the initial reconstruction has achieved desired results.
Light field is the parametric representation of a 4D light radiation field that contains the position and direction information in space. In other words, it contains all images taken at the same object in the different positions and angles. The multi-perspective light field is to represent the complete light field with different perspectives. By combining the captured target information through the collaboration among the sensors, it is able to obtain the light field data set under many sensors. Therefore, it can be seen that the light field can naturally serve as a feature library of the target images.
Maneuvering target recognition is the process in which a particular target in movement is distinguished from other targets. The essence of maneuvering target recognition is to determine the image information of the maneuvering target in each frame. In a word, the process of target recognition not only includes the identification of similar targets but also includes the identification of the different type of targets.
With the rapid development of light field reconstruction technologies, the maneuvering target recognition based on light field has been widely studied in the fields of computer vision, pattern recognition, and image processing. Many researchers use the sparsity of the light field in the angle domain to monitor and identify the target. The use of the light field reconstruction technology can ignore the angle problem of shooting images and reduce the conditional constraints of the target recognition, which makes its application more extensive.
The main contributions of this article are as follows:
The multi-perspective representation of the complete light field is the reconstruction of the sub-light field at different perspectives based on the sparsity of the light field itself. This method reduces the amount of data during reconstruction and improves the accuracy of reconstruction.
For the maneuvering targets, the collaboration mechanism model of the multi-perspective light field under regional full-coverage constraints is established to fuse the information captured by the multi-perspective distributed network and to estimate the state of the maneuvering target.
This article conducts extensive experiments to evaluate the performance of the proposed method when recognizing both fixed target and maneuvering targets. The experimental results indicate that the proposed method outperforms state of the art methods.
The remainder of this article is organized as follows. The “Related work” section provides an overview of the related literature. Sections “The multi-perspective representation and reconstruction model of light field,”“The multi-perspective distributed information fusion mechanism,” and “Maneuvering target recognition based on the information fusion of different sub-light fields” describe the models of the representation and the reconstruction for the multi-perspective light field, and the multi-perspective collaboration mechanism, and the maneuvering target recognition method based on the perspectives, respectively. The simulation experiments are discussed in the “Experimental results and analyses” section. Finally, the “Conclusion” section concludes the article, as shown in Figure 1.
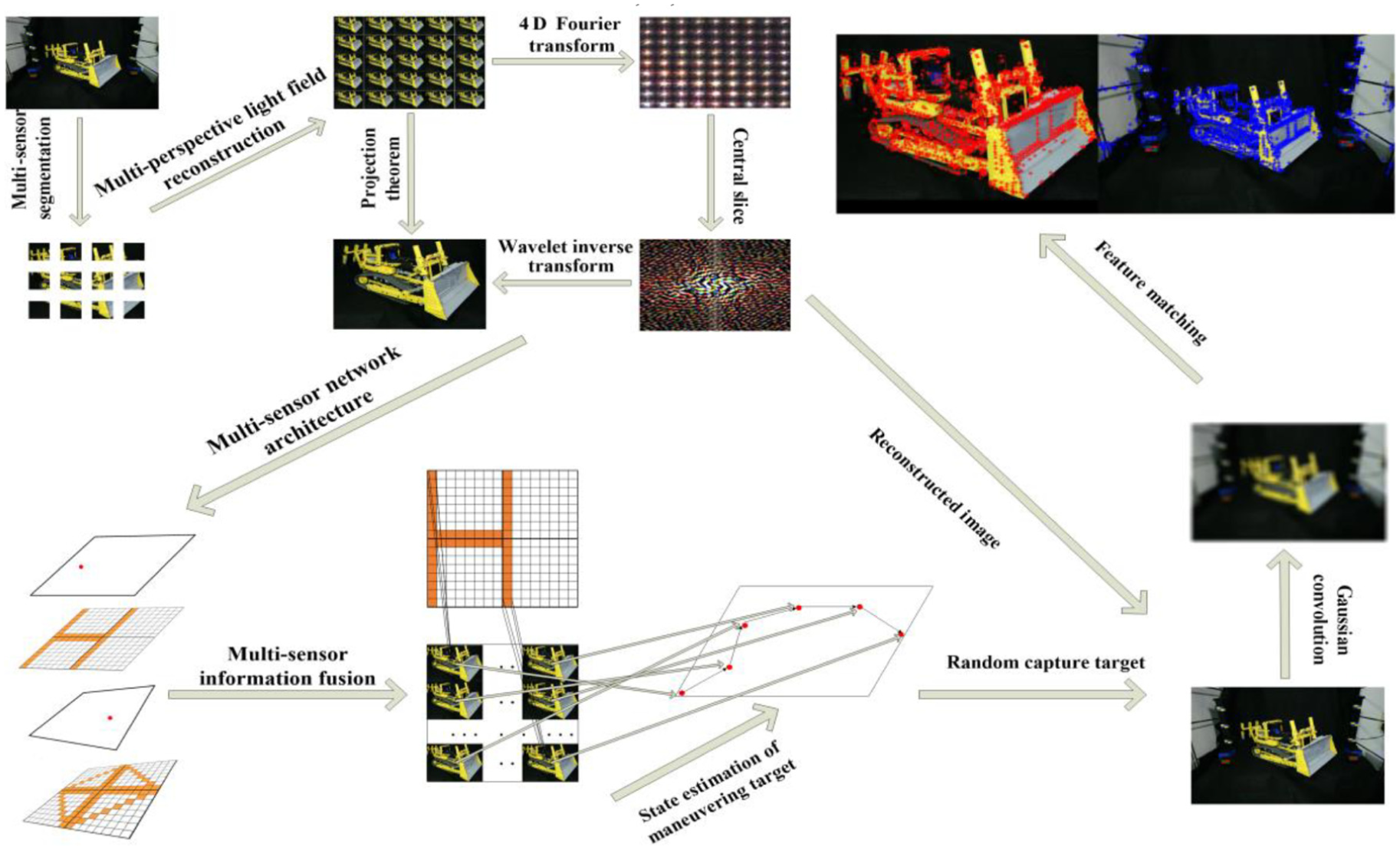
Maneuvering target recognition method based on the multi-perspective light field reconstruction.
Related work
It is difficult to obtain a complete light field. Large amounts of data and complex spots are the obstacles in the process of constructing the light field. Therefore, many researchers have proposed the concept of light field reconstruction using the sparsity of the light field to reconstruct the unknown information of the targets from locally known information. In order to improve the sampling efficiency and image quality of Fourier transform ghost imaging, Zhu et al. 3 proposed a spatial multiplexing reconstruction method. Experimental results show that the Fourier spectrum reconstructed by this method has better visibility and signal-to-noise ratio. Lu et al. 4 effectively solved the scattering problem of underwater light field images through deep convolutional neural networks with depth estimation. Light field cameras are widely used due to the convenient three-dimensional (3D) imaging method. Zhu et al. 5 reported a basic comparison between unfocused light field (ULF) and focused light field (FLF) cameras. Wang et al. 6 proposed a spatially variable bidirectional reflectance distribution function ((SV)BRDF) invariance theory for recovering the 3D shape and reflectivity in a light field camera, and carry out a large number of experiments to demonstrate their own methods. Zhao et al. 7 proposed a 3D flame temperature measurement optical section tomography (OST) technique combining light field imaging. Light field OST (LF-OST) system has the advantage of being simple and fast compared to conventional imaging. Cai et al. 8 proposed a 3D-structured light field (SLF) and depth-SLF 9 methods to solve the multi-perspective reconstruction problem. The experimental results show that the above methods all achieve efficient reconstruction of SLF. In order to record the direction information of the light, Chen et al. 10 proposed the selected structural key views (SC-SKV) encoder. Performance has improved significantly compared to traditional methods. Schedl et al. 11 proposed an angular super-resolution method by minimizing the consistency of the representative global dictionary to obtain the optimal sampling mask. This method has undergone an essential change compared to the prior art. In order to solve the limitation of the spatial resolution of the light field camera in the micro-lenses, Zhou et al. 12 proposed a method for reconstructing high-resolution from the angular images. The experimental result with a magnification ratio of 8 demonstrates the effectiveness of the proposed method. Alam and Gunturk 13 proposed a hybrid stereo imaging system. The experimental results show that the method effectively solves the problem of light field camera and retains the ability of light field imaging.
In the area of maneuvering target recognition, Nam and Han 14 proposed a visual tracking algorithm based on convolutional neural networks. In tracking the target, the method combines the pretrained shared layer with a new two-level layer and updates online. For the model drift problem in online tracking, Zhang et al. 15 proposed a multi-expert recovery scheme. In the experiment, the multi-expert recovery scheme proposed by this method significantly improved the robustness of the tracker, especially in the case of frequent occlusion and repeated applications. Tao et al. 16 proposed a new tracker. This method only uses the original observation of the target in the first frame, which is enough to achieve the best performance state. For the visual tracking method lacking training data, Danelljan et al. 17 proposed a discriminative correlation filter (DCF)-based spatial regularization discriminant filter. The goal is to introduce a spatial regularization component correlation filter in penalty learning. Experiments show that the recognition accuracy of this method is higher than the existing trackers in the four data sets. Valmadre et al. 18 proposed an algorithm for training linear templates to distinguish images. The algorithm interprets the closed-form filter as a differential learner and overcomes the limitations of the differentiable layer in deep neural networks. The experimental results show that the method achieves the most advanced performance at high frame rate compared with the existing algorithms.
To sum up, in terms of light field reconstruction and target recognition, many researchers have made effective improvement in light field reconstruction. However, many problems are still existing: (1) obtaining the complete light field is still difficult, (2) the viewing range of the complete light field is limited, and (3) the target may be lost when monitoring the maneuvering target.
The multi-perspective representation and reconstruction model of light field
In the reconstruction process, the large amount of data will lead to the increased error and other problems, so that the running time and the recognition accuracy based on light field reconstruction are not ideal. Thus, the multi-perspective representation model of the light field is presented. By using this model, the complete light field can be effectively divided into the multi-perspective light fields, and the multi-perspective light fields are then reconstructed.
The multi-perspective representation model of light field
The Lego Bulldozer of the light field library of the Stanford University is represented as a weight graph

where

Let

In this article, the convex representation of image segmentation
19
is introduced into multi-perspective light field reconstruction. The region

The marker function

Therefore, the light field model is divided into many perspectives, as shown in Figure 2.

The multi-perspective 3D segmentation model.
The reconstruction model of multi-perspective light field
According to the model of the multi-perspective light field, the multi-perspective light field is reconstructed using the light field reconstruction algorithm combined with wavelet transform and sparse Fourier transform. The original light field image is a

The light field imaging model.
The original image is made up a series of pixels, and each pixel is a micro-lens image


Then, the point imaging function can be gotten in any plane if
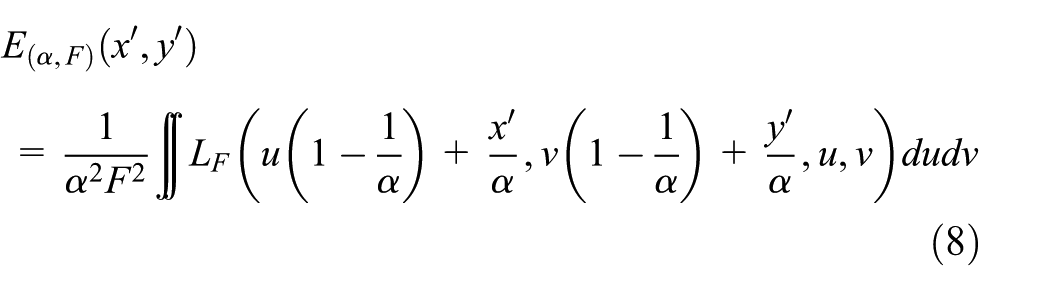
Based on the algorithm, the frequency domain information of images can be obtained by 4D Fourier transform of the multi-perspective light field. In this algorithm, the images are reconstructed by central slice and wavelet inverse transform. The multi-perspective light field is obtained as shown in Figure 4.

The multi-perspective light field reconstruction flowchart.
The multi-perspective distributed information fusion mechanism
The visual range of the complete light field is limited when monitoring targets.20,21 This article proposes the multi-perspective light field collaboration mechanism. In the process of monitoring the targets, different sub-light fields are fused according to other perspective information.22–26
The multi-perspective light field digraph

The directed graph model of the multi-perspective light field.
There is a diagonal matrix as in equation (9)

The state errors among every perspective are

Therefore, the closed loop system of the different perspectives is

The directed graph network is made of different perspectives, and the dynamic performance is demonstrated as in equation (12)

Let the state equation of a certain angle of view

According to the above formula, the state equation of

The analysis process is achieved in the directed graph topological structure, and the overall coordination of the multi-perspective light field is consistent.
Suppose the target Z is in the alliance distribution
If

By formula (15), when the target appears, there must be two or more than two perspective light fields to monitor them, as shown in Figure 6.
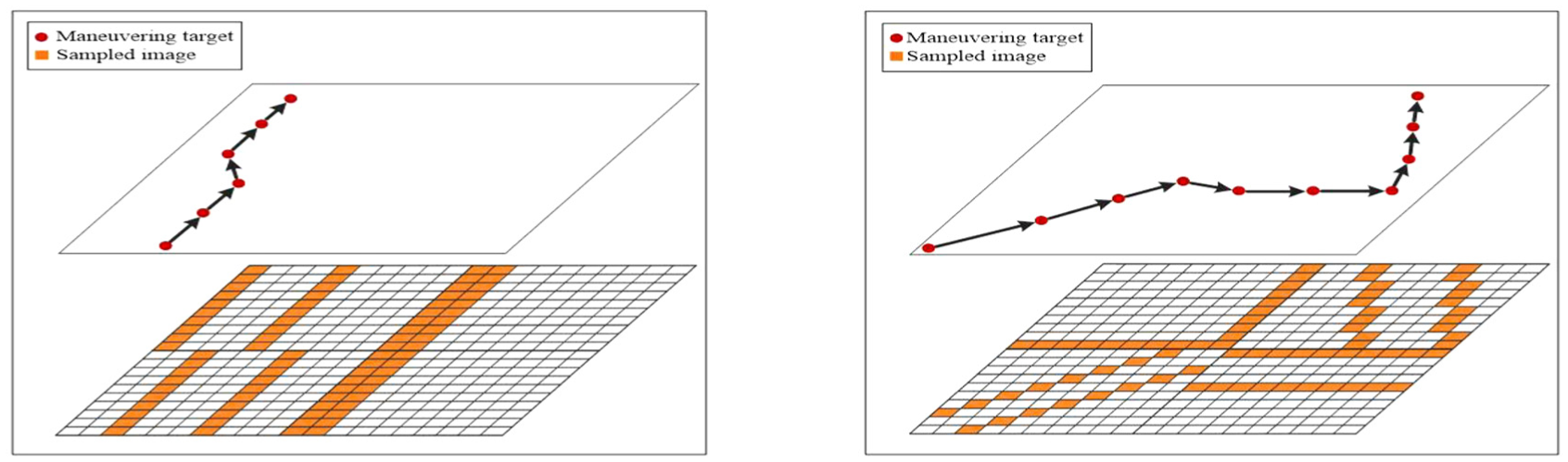
The multi-perspective cooperative sampling model.
Maneuvering target recognition based on the information fusion of different sub-light fields
The information fusion of different sub-light fields
The target information is detected by each perspective (i.e. sub-light field) to be fused, and the consistency of the average of all observations is obtained through the support of the capture of information by each perspective.27–29
The degree of each perspective is

In formula (16),
In formula (17),
In formula (18),


In formula (19),

According to the above formula, the fused information of the maneuvering target is obtained, and the observation value of the maneuvering target under the multi-perspective light field is acquired.
The state estimation model of the maneuvering target
The state estimation for maneuvering target is achieved by introducing multiple target motion models,30–32 and the state estimation of each motion model is weighted. According to a certain probability, it achieves the monitoring of the maneuvering target.
Maneuvering target state estimation process
It is assumed that the target state
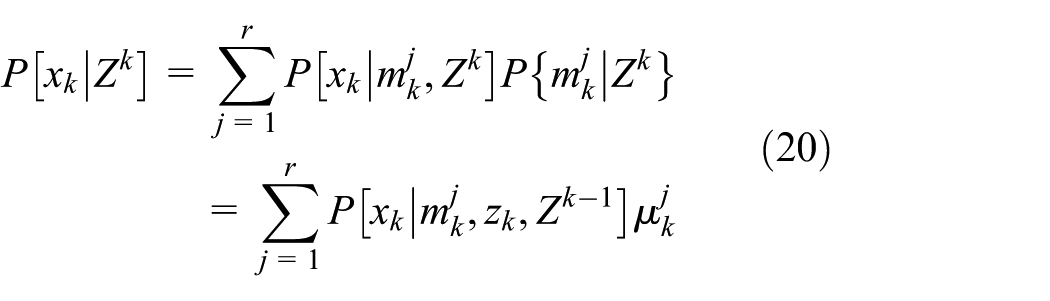
In the above formula,
The posterior probability function of the maneuvering target’s state is

The covariance and state estimation of the sub-light fields are integrated


Equation (23) shows that the target is monitored through introducing the diverse of maneuvering target motion models and the probability of each model is weighted.
Maneuvering target recognition
When the multi-perspective light field is scheduled,33–36 the important focus is how to sure maneuvering target just as the same target. This part uses the proposed algorithm to identify feature point matching targets for maneuvering targets entering the monitoring area.
The Gaussian scale space of an image can be obtained with different Gaussian convolutions where



The above formula can be obtained, and
The feature point

Since

If the contrast threshold is

If
Experimental results and analyses
Experimental settings
Controller hardware
In this article, we use MATLAB under the windows 10 system for experimental simulation. The simulation calculation runs on a small server with a CPU of E5-2630 v4, the main frequency of 2.2 GHz, and a memory of 32 GB.
Experimental parameters
This chapter uses the Stanford University Light Field Library as a light field data set for simulation experiments. The data set contains 17 × 17 angle trials. In order to ensure the feasibility of the experiment, the pixel is changed to 256 × 256. In terms of the light field reconstruction sampling scheme, this article adopts the line model. The sampling rate is the number of sampled lines and dimension of the angle domain.
The multi-perspective light field reconstruction algorithm
The data for this experiment is from the Stanford University Square database. And compared with the existing algorithms (SV)BRDF, 6 LF-OST, 7 3D-SLF, 8 micro-lens array (MLA) 13 reconstruction results.
According to Figure 7 and Table 1, the reconstruction accuracy and reconstruction time of each algorithm in the experiment can be clearly seen. Due to the limitation of LF-OST 7 application background, the reconstruction time of this method is above 600 s, and the reconstruction accuracy is less than 91%. (SV)BRDF 6 and MLA 13 are both innovative methods of light field camera reconstruction, and the two algorithms should be compared. The reconstruction accuracy of (SV)BRDF 6 in Lego Bulldozer was 93.583%, and the reconstruction time in Bracelet was 235 s. Both parameters are higher than the experimental results of the algorithm. The reconstruction time of MLA 13 on Chess and Lego Bulldozer is less than (SV)BRDF, 6 but the reconstruction accuracy is lower than (SV)BRDF 6 and the algorithm. 3D-SLF 8 belongs to the scope of 3D reconstruction, which increases the complexity of light field reconstruction, so the reconstruction accuracy is low. The reconstruction time of the algorithm is less than 600 s, and the reconstruction accuracy exceeds 92%. Among the eight parameters of the experimental results, the algorithm has six parameters which are superior to the similar algorithms. Therefore, the algorithm in this article is effective.

The multi-perspective light field reconstruction experiment results. The red box area is the light field reconstruction part of the experiment.
Comparison of light field reconstruction algorithms.
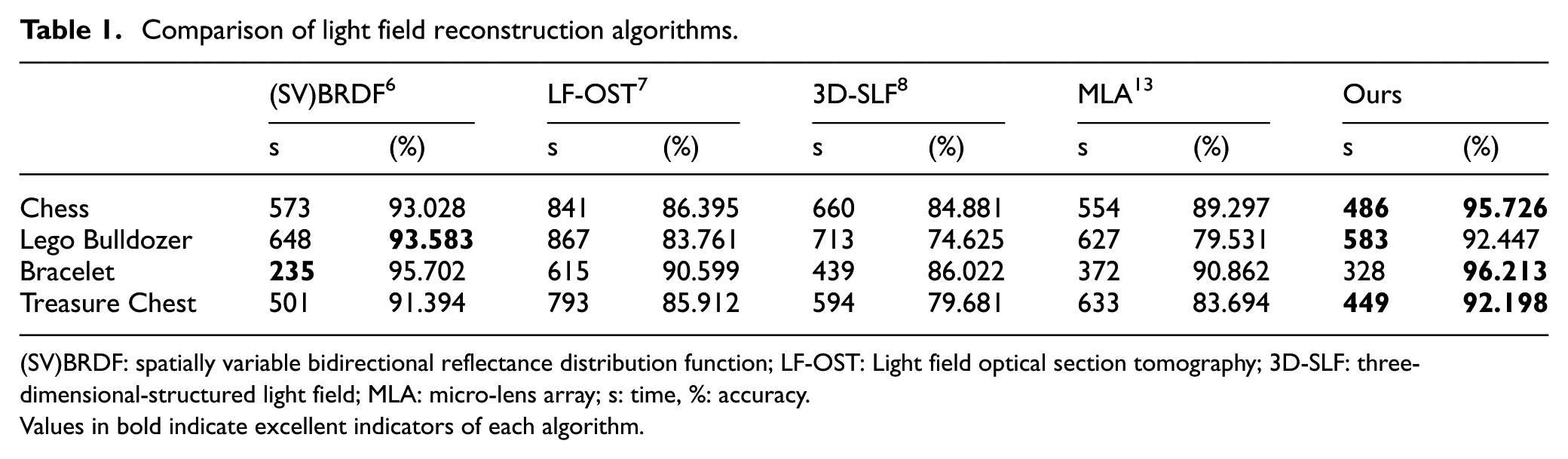
(SV)BRDF: spatially variable bidirectional reflectance distribution function; LF-OST: Light field optical section tomography; 3D-SLF: three-dimensional-structured light field; MLA: micro-lens array; s: time, %: accuracy.
Values in bold indicate excellent indicators of each algorithm.
Maneuvering target recognition performance testing based on the multi-perspective light field reconstruction
In order to verify the effectiveness of the algorithm in this article, this chapter will use the TB-50 and TB-100 video data sets as test data sets in simulation experiments. In this article, we use TensorFlow for experimental simulation under the windows 10 system. The analog calculation runs on a small server with a CPU of E5-2630 v4, a clock speed of 2.2 GHz and a memory of 32 GB. In this chapter, several representative data are selected for recognition, and the algorithm in this article identifies moving targets simultaneously with existing MDNet, 14 MEEM, 15 SINT, 16 SRDCF, 17 CFNet 18 algorithms, as shown in Figure 8. The experimental data for maneuvering target recognition is divided into two categories, one is human and the other is a car. The human video data set includes Kitesurf, Matrix, and Skiting2. In the Kitesurf video data set, all algorithms effectively identify the target, but CFNet 18 has the phenomenon of recognizing the box offset. In the second image of the Matrix video data set, MEEM 15 identifies targets other than the subject. Other algorithms are effective in identifying targets. In the fourth of the Skating2 video data set, only the algorithm effectively identifies the target because the target is severely occluded. The car video data set includes Car24, Blurcar4, and CarScale. In the Car24 video data set, MEEM, 15 SINT, 16 and CFNet 18 identify targets outside the subject. Both the second and fifth images of the Blurcar4 video data set showed severe motion blur. All algorithms effectively identify the target, and the algorithm uses a small red box to characterize the target in the second image. In the CarScale video data set, only MEEM 15 has a frame offset in the first two frames of the video.

Maneuvering target recognition result.
The time analysis of maneuvering target recognition is shown in Figure 9. Ours-1 represents the single-perspective recognition of the algorithm. In the second and fifth frames of the Car24 video data set, the target recognition time is less than 2 s. In this scenario (green histogram), Ours-1 is the fastest compared to other algorithms. However, the recognition accuracy of Ours-1 in the Car24 video data set is comparable to that of similar algorithms, as shown in Table 2.

Maneuvering target recognition time for various algorithms in different scenarios. The X-axis represents a scene, and different colors represent different scenes. The Y-axis stands for time. The Z-axis represents different algorithms and different perspectives of the algorithm.
Maneuvering target recognition accuracy.

TB-50 and TB-100 detected average accuracy (%). Ours-1: a perspective to detect the target, Ours-2: two perspectives to detect the target, Ours-3: three perspectives to detect the target, Ours-Multiple: four and more than four perspectives to detect the target.
Values in bold indicate excellent indicators of each algorithm.
In the target recognition of the Car24 video data set of Figure 9, we can clearly see that as the viewing angle increases, the target recognition time will also increase. Ours-Multiple average recognition time is close to 3 s, which is 0.3 s–1 s higher than similar algorithms. However, in the six video data sets in Table 2, Ours-Multiple has the highest target recognition rate among the five video data sets. In summary, the algorithm in this article is effective in maneuvering target recognition.
Conclusion
When the light field is reconstructed with a large amount of data, a complex scene and a long time, it is difficult to achieve a complete light field. The monitoring range is limited because the complete light field is stationary. Since the state of the maneuvering target keeps changing, the information of the target motion will be incomplete. In order to solve the above problems, a maneuvering target recognition method based on multi-perspective light field reconstruction is proposed in this article. First, the multi-perspective representation of the complete light field is performed. Based on the sparsity of the light field itself, the sub-light field at different perspectives is performed. Second, the multi-perspective distributed information fusion model under regional full-coverage constraints are established. According to the location of the target, the light fields in each perspective are optimized for sampling. Third, the sampling information of the Multi-perspective distributed network is merged to estimate the maneuvering target state. It can be seen from the experimental results that the proposed method is efficient in both the reconstruction accuracy and the maneuvering target recognition accuracy. There are still some shortcomings in the method proposed in this article. The more angles of view are used, the more difficult it is to converge at the initial position. As a result, the target recognition time increases. In the future work, we will focus on the above issues as the focus of research to solve the problems of large initial errors and difficulties in convergence.
Footnotes
Handling Editor: Salvatore Serrano
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This article was supported by the National Natural Science Foundation of China (61703143), Science and Technology Project of Henan Province (192102310260), Scientific and Technological Innovation Talents in Xinxiang (CXRC17004), the young backbone teacher training project of Henan University (2017GGJS123), and Science and Technology Major Special Project of Xinxiang City (ZD18006).