
Abstract
Currently, big data is a new and hot issue. Particularly, the rapid growth of the Internet of Things causes a sharp growth of data. Enormous amounts of networking sensors are continuously collecting and transmitting data to be stored and processed in the cloud, including remote sensing data, environmental data, and geographical data. And region is regarded as the very important object in remote sensing data, which is mainly researched in this article. Region search is a crucial task in remote sensing process, especially for military area and civilian fields. It is difficult to fast search region accurately and achieve generalizability of the regions’ features due to the complex background information, as well as the smaller size. Especially, when processing region search in large-scale remote sensing image, detailed information as the feature can be extracted in inner region. To overcome the above difficulty region search task, we propose an accurate and fast region search in optical remote sensing images under cloud computing environment, which is based on hybrid convolutional neural network. The proposed region search method partitioned into four processes. First, fully convolutional network is adopted to produce all the candidate regions that contain the possible object regions. This process avoids exhaustive search for input images. Then, the features of all candidate regions are extracted by a fast region-based convolutional neural network structure. Third, we design a new difficult sample mining method for the training process. At the end, in order to improve the region search precision, we use an iterative bounding box regression algorithm to normalize the detected bounding boxes, in which the regions contain candidate objects. The proposed algorithm is evaluated on optical remote sensing images acquired from Google Earth. Finally, we conduct the experiments, and the obtained results show that the proposed region search method constantly achieves better results regardless of the type of images tested. Compared with traditional region search methods, such as region-based convolutional neural network and newest feature extraction frameworks, our proposed methods show better robustness with complex context semantic information and backgrounds.
Keywords
Introduction
Recently, with the continuous progress of Internet of Things (IoT) big data, mobile Internet, cloud computing, grid computing, and other new technologies, system integration becomes more complex. IoT is with the purpose of improving the quality of human life by handling the massive amount of data, collected by the sensing devices connected to the Internet.1–3 When processing information and data, it encounters lots of challenges, for instance, data storage and management, efficient processing of massive data, structured and unstructured data fusion and analysis, and multi-type data visualization. Especially, remote sensing technologies are promoted quickly; the spatial resolution, temporal resolution, spectral resolution, and radiative resolution of remote sensing data are becoming higher and higher, which contain abundant data. Remote sensing data have the obvious big data characteristics such as large capacity, high efficiency, multi-type, and high value, which indicate that remote sensing has entered into big data era. Based on the aerospace science and technologies, an integrated space–air information network has been formed, which provides ultra-high dimensional and frequency earth observation data. Remote sensing images have significant applications in both military and civilian areas. For the civil area, remote sensing images can be used for meteorological forecasting, land planning, environmental monitoring, and other aspects to make a significant contribution to the development of national economy.4–6 In terms of military, remote sensing images can be used for strategic reconnaissance, military surveying and mapping, marine monitoring, and so on, which can acquire various military targets intelligence information without affected by national boundaries and geographical restrictions.7–10 Detecting all kinds of important military targets accurately and realizing the rapid transformation of remote sensing images to intelligence information, this can not only save human resources but also improve the efficiency of information acquisition.
Region/object detection based on image technology refers to that it uses relevant technologies such as computer vision to detect the targets from the image; meanwhile, judge the categories of objects, location, size, and confidence degree automatically. At present, the technology has been widely used in marine surveillance, precision guidance, video monitoring, and so on. Among all the military targets, region search has attracted considerable research attention.
However, due to the complex background, the size of region is very dissimilar, which greatly increases the difficulty of the region search task. 11 At present, the hot region search is the main research point; thus, we carry out the automatic detection for region search, which has the vital significance for enhancing the intelligence information level of military battlefield.
In recent years, the region search technology has attracted more attention from researchers in deep learning and computer vision. Traditional region search tasks such as histogram of oriented gradients (HOG), 12 local binary pattern (LBP) feature, 13 and scale invariant feature transformation (SIFT) 14 with classifier (boosting, support vector machine (SVM), etc.) cannot satisfy the requirements for next image process like object detection or localization accurately. The rule of feature extraction by using artificial design method is that it extracts feature information in the original image, and inputs feature into the classifier to learn classification rules. Finally, the trained classifier is used for object detection. This artificial feature modeling methods have achieved good results in face recognition, pedestrian detection, and other fields, which greatly promote the development of image region search technology. However, artificial feature modeling method only contains the original pixel image feature and texture gradient information; it does not have high-level semantic abstract ability, which makes this method have low detection effeteness under the complicated scene. Convolutional neural network (CNN) was proposed for ImageNet image segmentation by Krizhevsky et al. 15 A breakthrough was made in image classification, target detection, image segmentation, and other image processing tasks with CNN. Compared with the feature description of the traditional manual design, the deep convolution feature has a subversive enhancement in the semantic abstraction ability.
Actually, region search and region localization have a delicate difference. The aim of region search is to find out the location of all region objects in one image and they need to be detected. Nevertheless, region localization should locate the region objects in image accurately. Obviously, region localization has a higher precision than many region search algorithms. Thus, a region search framework is proposed for the specific region object, that is, airport and harbor, in this article. Therefore, we lay more emphasis on fast region search to realize the core work of this article. Feature extraction problem for region search is addressed by CNN, because there is a deeper layer structure in CNN, which has better learning abilities than other classifiers. We design a new accurate and fast region search framework based on hybrid convolutional neural network (HCNN) in optical remote sensing images under cloud computing environment.
This article is organized as follows. First, related works on region search and applications of CNN are reviewed in remote sensing images in the “Related work” section. Then, the “Proposed region search method” section shows the detailed proposed region search framework and its main implementation issues are discussed. The “Experimental results” section discusses the region search experiments and gives the analysis. Finally, the “Conclusion” section summarizes this article.
Related work
Significant research has been devoted to region search through multi-scale gradient histograms and CNN-based methods. The classical region object detection network contains two parts: candidate region extraction and object region recognition. Girshick et al. 16 proposed the region-based convolutional neural network (R-CNN) for object detection. Its main idea is that it uses selective search method 17 to extract the proposal regions containing possible objects. Then, the CNN is adopted to extract convolution features for proposal regions. SVM is used to make a discrimination for the proposal regions. Finally, bounding box algorithm is used for making correction. However, the method needs to calculate the convolution feature in each proposal region; the calculation efficiency is very low. In addition, all the proposal regions are normalized to the same scale resulting in the distortion of the image, which affects the final detection result. Li et al. 18 presented a framework that integrated R-CNN and deformable part-based model (DPM) for detecting multiple objects. Liu et al. 19 focused on the last step of the system to aggregate thousands of scored box proposals into final object prediction, which was called proposal decimation. Girshick 20 proposed a fast R-CNN for object detection, which addressed the issues of R-CNN. Meanwhile, the discriminant of the proposal area and the bounding box regression were integrated into a framework, which effectively improved the accuracy and efficiency of the object detection. Wang et al. 21 proposed a multi-scale mask-based fast R-CNN framework, which generated saliency score of each region. Since the regions were segmented using edge-preserved methods, the results were naturally with sharp boundaries. Lou et al. 22 proposed an object detection system based on standard fast R-CNN object detection branch and DeepLap semantic segmentation branch. This method was divided into three processes. Ren et al. 23 introduced a region proposal network (RPN) that shared full-image convolutional features with the detection network, thus enabling nearly cost-free region proposals. Chen et al. 24 improved the cross-domain robustness of object detection. He tackled the domain shift on two levels: (1) the image-level shift, such as image style and illumination, and (2) the instance-level shift, such as object appearance and size. The method built the approach based on the recent state-of-the-art faster R-CNN model, and designed two domain adaptation components, on image level and instance level, to reduce the domain discrepancy. The two domain adaptation components were based on H-divergence theory, and were implemented by learning a domain classifier in adversarial training manner. The domain classifiers on different levels were further reinforced with a consistency regularization to learn a domain-invariant RPN in the faster R-CNN model. Redmon et al. 25 presented You Only Look Once (a real-time object detection), a new approach to object detection. It directly made regression for multiple region categories and bounding box on the convolution feature maps, realizing the end-to-end training and testing for input image. The method greatly improved the object detection speed. Liu et al. 26 presented a single deep neural network single shot multibox detector (SSD) for detecting objects in images. SSD discretized the output space of bounding boxes into a set of default boxes over different aspect ratios and scales per feature map location. In addition, the network combined predictions from multiple feature maps with different resolutions to naturally handle objects of various sizes.
However, with the increasing of CNN layers, dimensions of feature map are getting smaller. The features become more abstract, and semantic feature is more obvious, namely, the location information is very fuzzy. Therefore, location is not accurate; although the bounding box can remit the problem, it still exists difference for different input images; sometimes, the correction effect is very poor. Multiple convolution and pooling alternately execute the operation, making smaller objects correspond to small unit size. Inadequate feature expression leads to poor performance for small object detection.
In this article, we propose a fast region search based on HCNN in optical remote sensing images. Fully convolutional network (FCN) generates all the candidate regions avoiding the influence of different sizes of input images. Then, the features of all candidate regions are extracted by fast R-CNN structure. A new difficult sample mining method is designed for the training process. To improve the accuracy of region search, we use iterative bounding box regression (IBBR) algorithm to make the bounding boxes of searched regions perfect. Experiments show that the proposed region search method shows better robustness with complex context semantic information and backgrounds than other state-of-the-art object region detection methods.
Proposed region search method
The proposed region search method consists of three stages: region proposal, feature extraction, and output result, as shown in Figure 1.
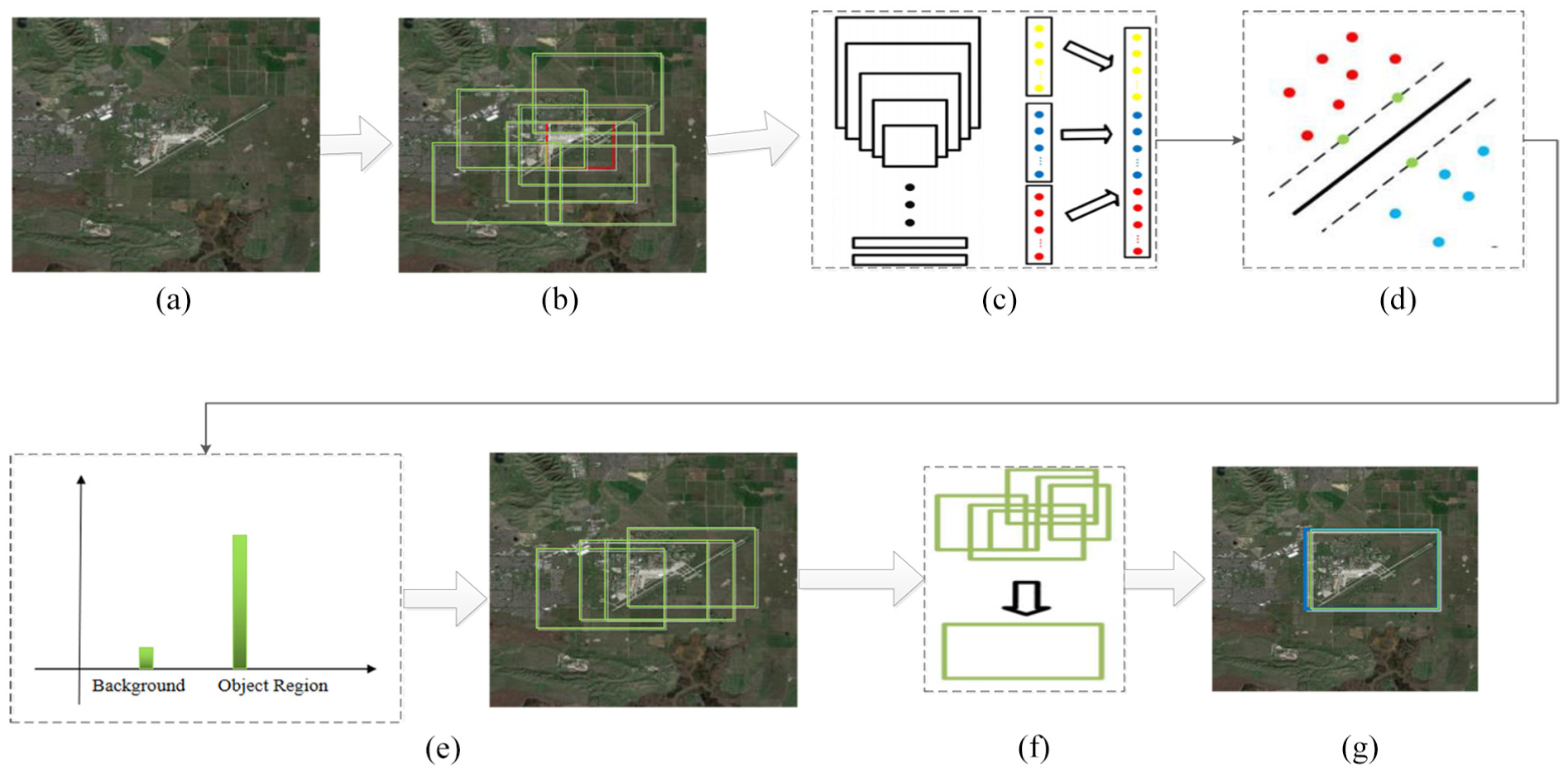
Total framework of proposed method: (a) original image, (b) FCN produces the candidate regions, (c) fast R-CNN is used for extracting the features from these candidate regions, (d) Softmax is used for classifying the objects, (e) false alarms are removed, (f) IBBR is applied to optimize the bounding boxes, and (g) final object region results.
First, potential candidate boxes are generated by using FCN method for the input remote sensing images. Second, fast R-CNN is adopted for extracted feature of all the potential candidate boxes. Finally, IBBR is designed to address the problem of box redundancy and optimize the region locations, and then get the accurate searched regions. The following is the detailed illustration for each process.
Proposal region extraction with FCN
FCN was used for segmenting semantic content. 27 In this article, we use FCN to generate the proposal regions with possible regions. As we all know, exhaustive search method such as sliding window technique for object detection is computationally expensive. FCN can effectively address this problem. More importantly, only a few training examples are required when using FCN. FCN defines many classes in convolutional network, where the output of the final parameterized layer is a grid rather than a vector, which has parameters that are learned from the data. That is beneficial for semantic segmentation, where each location is the window corresponds to the predicted region class of a pixel.
FCN has two obvious advantages: (1) it can accept any size of input images without requiring the same size of all training images and test images; and (2) after one convolution, it can get the features of multiple regions, which avoids the repeated calculation problems, so it is more efficient.
First, FCN is constructed. Any size of the images is input to this convolution network, and the eigenmatrix representation of image is acquired; each location in feature representation corresponds to an object region in the original image. Given an image, it gets the feature representation by using FCN. To detect different sizes of regions, the images need to be made multi-scale transformation, and it obtains feature matrix. Finally, it makes similarity comparison between detected object feature and feature matrix of image in database. The optimal matching position and similar values are obtained. Framework of FCN is shown in Figure 2.

Framework of FCN: (a) original image, (b) FCN network, and (c) matrix representation.
After training FCN, it can get the feature matrix representation of input image. For the object image, scaling is executed to keep the same size with that of FCN. Region search will be directly affected by the quality of extracted region proposals. Therefore, FCN improves the quality of region proposals for region search to some extent.
Feature extraction with fast R-CNN
Above all, the fast R-CNN deals with all the detected candidate regions with several convolutional (conv) and maximum pooling layers to produce a conv feature map. Then, it adds the ROI (region of interest) pooling layer, to extract the feature representation of a fixed dimension for each region, and then conducts type identification through normal Softmax.
ROI pooling layer can transform any valid candidate regions into a small feature map with a fixed spatial extent of H × W. Here, H and W are layer hyper-parameters that are independent of any particular ROI. Each ROI is defined by a four-tuple (r, c, h, w) that specifies its top-left corner (r, c) and its height and width (h, w).
Feature matrix is obtained by FCN. This process means that it selects fixed sliding window based on certain step length. After a forward convolution, it can get the feature of the area. This fixed window size may result in some areas without covering the objects, which can influence the region search result. In this article, we perform multi-scale transformation to detect the different size objects.
Deep CNN usually has millions of model parameters that need to be trained, and the training samples and hardware conditions are very necessary. At present, the general approach is to use pre-trained network models on the ImageNet. Then, transfer learning method is adopted to modify and fine-tune the parameters for specific images. Generally, feature map of region extraction and detection image should contain more rich information, including semantic information and location information. In addition, feature map should have appropriate size; smaller size will lead to insufficient expression of feature and bigger size will affect the computational efficiency. Deep CNN model contains LeNet, AlexNet, VGGNet, GoogLeNet, and so on.28–30 There are five convolutional layers and three full connection layers in the final network structure of AlexNet, as shown in Figure 3. It uses dropout and activation function Rectified Linear Units (ReLU) to improve the accuracy and reduce training time. In addition, due to the limitation of experiment condition, in this article, we use AlexNet model for FCN. When training the network, size of input image is 227 × 227.

Architecture of AlexNet CNN. This network is composed of five successive convolutional layers (C1, C2, C3, C4, and C5) followed by three fully connected layers (FC6, FC7, and FC8).
Fast R-CNN can avoid the repeated overlap computation, although with the bounding box calculation to realize the end-to-end training. Fast R-CNN does not need to run all of the images to get FC7 feature. Therefore, fast R-CNN is used for feature extraction in this work.
Difficult sample mining method
In order to train the extracted candidate regions, we need to label the samples of the original proposal regions corresponding to each sliding window. If the intersection-of-union (IoU) between original proposal region and ground truth bounding box is the biggest, or

where
Classification layer adopts a cross-entropy classification function based on dichotomies and a loss function,
After sample labeling, the object is limited in the image. Negative samples are usually greater than that of positive samples. The imbalance distribution of samples may lead to the unstable training, so it needs to make an adjustment between positive sample number and negative sample number in the training process. In this article, we set the proportion of positive and negative samples as

By adding the corresponding weight coefficient for the loss function of positive and negative samples, it ensures that if the positive samples are less than the setting number, it can increase the positive proportion in the loss function through controlling the weight coefficient, which makes the weight of the positive and negative samples remain balanced in loss function.
Improved bounding box regression IBBR
Bounding box regression 32 plays a significant role in detection models. We then derive a novel bounding box regression loss, which better matches the goal of maximizing IoU while maintaining good convergence properties (smoothness, robustness, etc.). We define the regression loss function as

where sm function is defined as
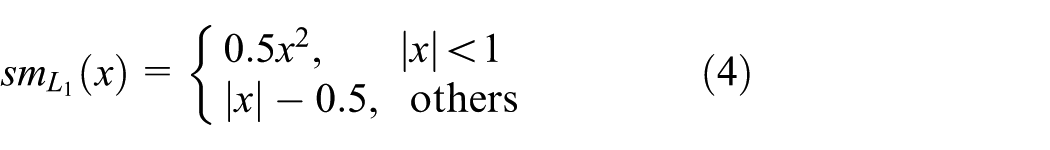
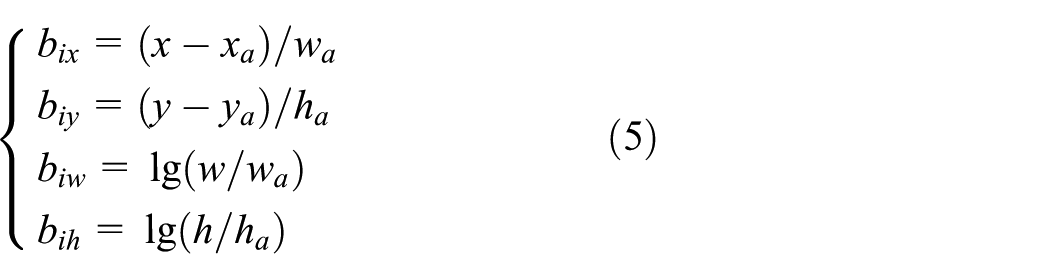
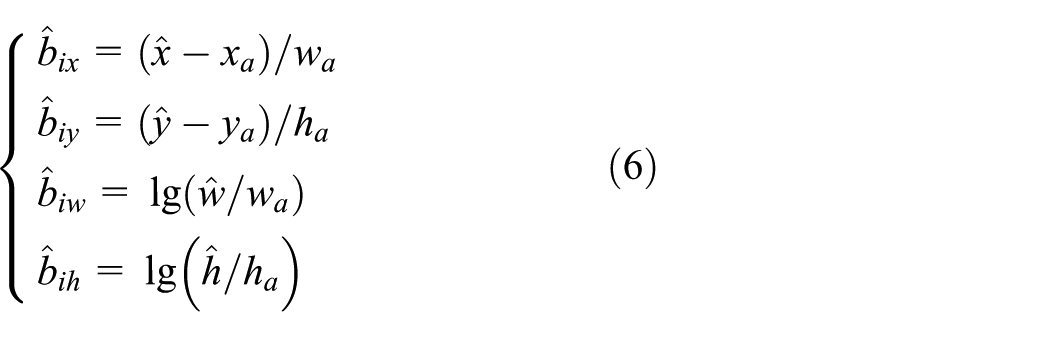
where x,

where N is the convolutional layer number,
Final results
The whole object region search network carries out end-to-end training by reverse propagation and stochastic gradient descent. Reverse propagation calculates the error between the actual output

where ⊗ denotes multiplication of each element.

The weight is scaled by BS


The above is the process of reverse propagation. Then, we use IBBR to optimize the detected bounding boxes. The regression pattern setting is applied, 33 , 34 where patterns are pre-defined as a set of three-dimensional scale changes and offset vectors OE

Given a detection window

In each pattern,


where
More importantly, redundant regression can be generated. To avoid this phenomenon, a function as a terminate condition is defined. It is used to evaluate the performance of detection after every bounding box regression

where s, x, y represent the integrated result of the airport-displacement pattern. If it cannot meet the condition in formula (16), it implies that the detected bounding box at current iteration is not better to locate a candidate region. Thus, the bounding box would be fed into AlexNet again and the operation described above executed. So, we will execute this process several times until a better bounding box generated.
Experimental results
Data set
We collect the regions (mainly airports and harbors), images from Google Earth with 2-m resolution, and label them intended for airport/harbor search in optical remote sensing images. The size of the images is 2048 × 2048 pixels, which is resized from large-scale images before processing. The ground truth of the airport and harbor images is determined by manual annotation. In the test images, the object regions have different sizes and shapes.
When using fast R-CNN for training process, ample training samples are necessary for acquiring better learning abilities. The size and quality of training data set are very critical. Therefore, when selecting the training data set, high-quality training data set is chosen. All the data set contains positive samples including 806 images with each image containing at least one target (in this article, there are 1021 airports) to be detected and negative samples including 100 images that do not contain any targets of the given objects which is at a ratio of 4:1. Figure 4 shows positive and negative training samples.

Examples from the training data set: (a) positive samples and (b) negative samples.
Evaluation metrics
By following the work, 35 when we judge a region detection whether it is correct or incorrect depending on the bounding box, the process overlaps more than 70% with the ground truth bounding box. It the overlap is greater than 70%, it is better search result; otherwise, the detected object region is regarded as a false positive. Nevertheless, if a single ground truth bounding box has several same bounding boxes overlap, there is only one considered as true positive and the others are regarded as false positives in this article. We adopted the standard precision-recall curve to quantitatively evaluate the developed framework. The precision measures the fraction of detections that are true positive and the recall measures the fraction of positive examples that are correctly detected. Let TP, FP, and FN denote the number of correctly detected objects, the number of false alarms, and the number of undetected objects in test images. The precision and recall can be formulated as


We also use F-score to calculate weighting-harmonic-mean for precision and recall

A high F-score indicates that the accuracy of algorithm is better.
Experimental results and comparison
Based on the successful application of AlexNet that has been pre-trained on the ImageNet data set, we train our HCNN model. The experiment is partitioned into three procedures: training process, testing, and the search process. In training process, we use graphics processing unit (GPU) and NVIDIA (NVIDIA: This is a comprehensive software that can implement graphics, audio, video, communications, storage and security functions) to enhance the training speed.36,37 Meanwhile, we can obtain the trained CNN models. Then, testing images are input to validate the algorithm. The search process is used to detect regions in test images. We use IBBR to improve the search accuracy as described in the preceding section. The learning rate is also an important factor. Figure 5 is the comparison of learning rate with HCNN method (from left to right in x-coordinate, learning rate = 0.01, 0.005, 1e–6 in turn).

F-score measurement in terms of different learning rates.
So we set learning rate to 1e–6. Minibatch size is constructed as 32. We use small patches cropped from raw image to train our CNN models through the backpropagation algorithm, by employing the GPU and compute unified device architecture (CUDA) for AlexNet model to improve the speed.
In order to evaluate the better performance of the presented region search method, we compare to other two state-of-the-art detection methods in this article, namely, cascade region-based convolutional neural network (CR-CNN) 38 and DLU (DLU is the highly summarized abbreviation from deep learning U-net). 39
We select four optical remote sensing images to test the performance. To train our HCNN model, if the candidate proposals are greater than 0.3 IoU overlap with a ground truth box, then they are deemed to be positives, and the others are as negatives. And Figures 6–11 show a portion of the comparison of the search results of the CR-CNN, DLU, and HCNN methods.

Airport search results with the CR-CNN method.
Airport search results with the DLU method.

Airport search results with the HCNN method.

Harbor search results with the CR-CNN method.

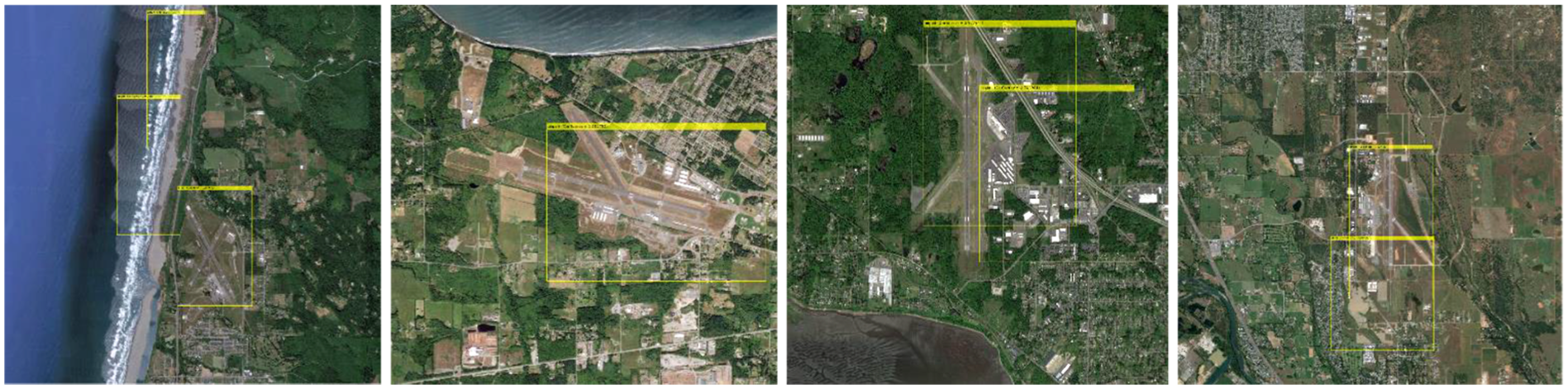
Harbor search results with the DLU method.

Harbor search results with the HCNN method.
In Figures 6 and 9, the CR-CNN method suffers from many false airport/harbor regions and many missed detections. The DLU method achieves a better search performance than CR-CNN shown in Figures 7 and 10, but it is worse than the proposed method. Although the object regions have different orientations and different sizes, the proposed method has successfully searched and detected most of them. Due to the low target and the background, there are missing alarms.
Tables 1–3 show the quantitative comparison results of the three different methods, measured by F-score values, average running time per image, respectively.
Airport performance comparison of CR-CNN, DLU, and HCNN.

CR-CNN: cascade region-based convolutional neural network; HCNN: hybrid convolutional neural network.
The bold-faced values are better results.
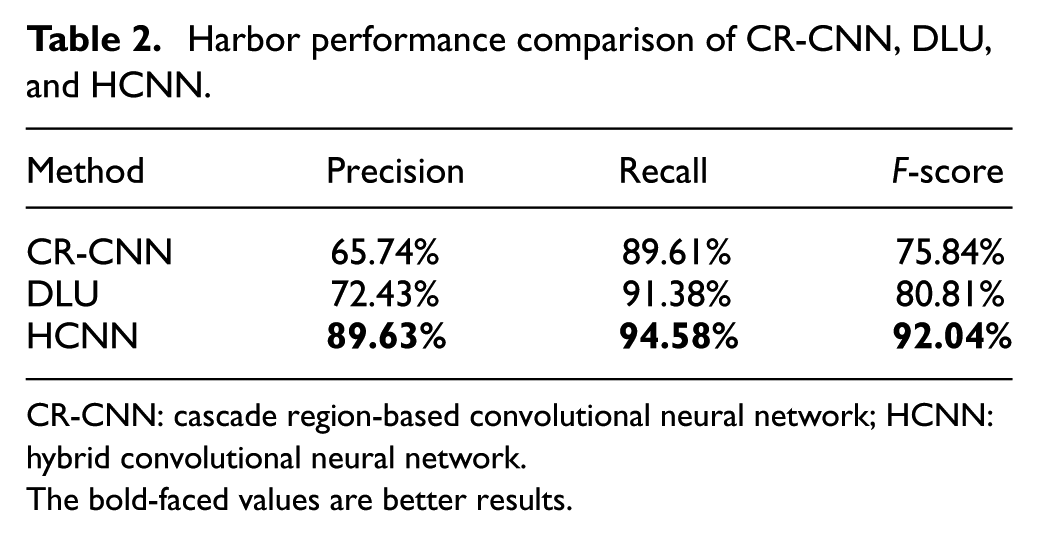
Harbor performance comparison of CR-CNN, DLU, and HCNN.
CR-CNN: cascade region-based convolutional neural network; HCNN: hybrid convolutional neural network.
The bold-faced values are better results.
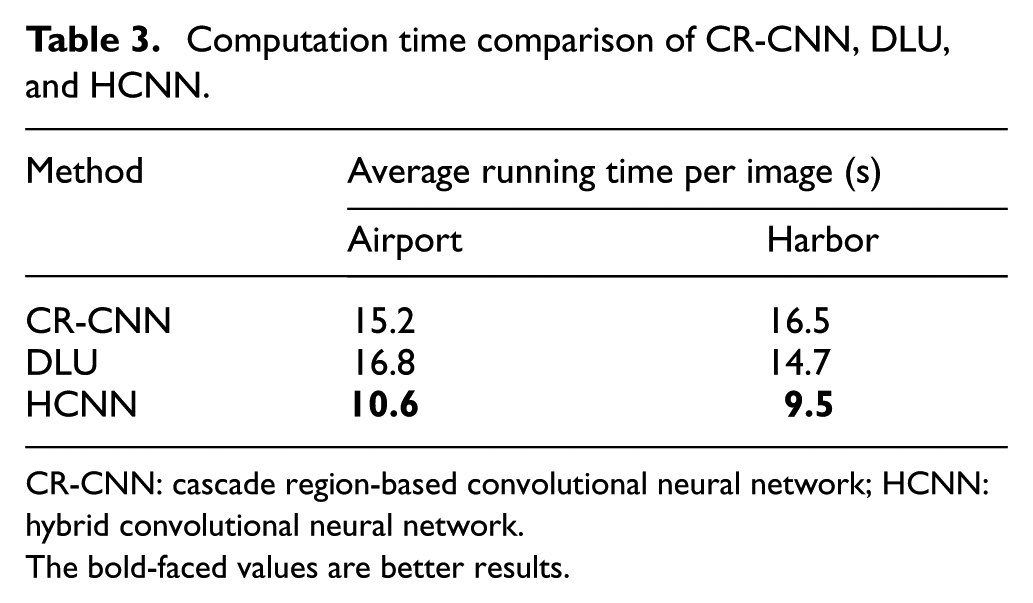
Computation time comparison of CR-CNN, DLU, and HCNN.
CR-CNN: cascade region-based convolutional neural network; HCNN: hybrid convolutional neural network.
The bold-faced values are better results.
As can be seen from them, we derive the following conclusions. (1) The proposed HCNN model method with IBBR outperforms all other comparison approaches for airports and harbors in terms of F-score. Specifically, our HCNN method obtains 92.06%, compared with the CR-CNN, and DLU for airport. This demonstrates the high superiority of the proposed method compared with the existing state-of-the-art methods. (2) For running time, HCNN takes nearly 10 s lower than other two methods. (3) With the other same computation cost, our HCNN model improves the newly trained CNN-model-based method significantly for airports and other regions. This adequately shows the effectiveness of the proposed HCNN model learning method.
Conclusion
In this work, an effective region search framework based on HCNN has been developed. This proposed region search method contains three main procedures: generating candidate regions, feature extraction, and final search. FCN is used to generate a coarse-object-sensitive map, thereby effectively rejecting many regions that do not contain objects in the process of first stage. Then, we use the newest fast R-CNN to extract region features. Finally, IBBR is used for optimizing bounding box to produce more accuracy region search. At last, the performance of the proposed framework has been evaluated qualitatively and quantitatively using airport and harbor optimal remote sensing images. Comprehensive comparisons with state-of-the-art approaches have demonstrated the effectiveness of the developed region search framework. In terms of precision, recall, and F-score, the results with proposed HCNN method are superior to other methods.
Although our new proposed method has been shown to be effective to obtain promising region search performance, some problems still exist: (1) some geospatial objects, having similar appearances to targets in structure and shape, may result in the false alarms, and (2) cluttered background and low contrast between the object and the background may lead to miss alarm.
Therefore, our future work may include the following issues: (1) integrate contextual background cues with the developed framework to improve region search performance; (2) develop new CNN-based model to address the mis-classification problems; (3) use this method to locate more objects, such as bridge, oil tank, and helicopter, and enhance the scene understanding, and especially has a significant military area; and (4) adopt airplane as the feature to detect airport in large-scale remote sensing image.
Footnotes
Handling Editor: Qingchen Zhang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Defense Industrial Technology Development Program under Grant JCKY2016603C004.