
Abstract
With the emerging of participatory sensing, crowdsensing-based lost people finding is arising. As a special location-centric task, participant selection is a key factor to determine success or failure of lost people finding result. Besides traditional influence, like Quality of Information contribution, candidate’s spatial proximity to the lost people is crucial in participant selection procedure. In order to evaluate how possible a candidate can approach lost people, the probability distribution of their tracing points should be predicted. However, the sparse sensing data problem has been a bottleneck of estimating people’s probable position. To overcome these issues, we study the problem of selecting optimal participants according to each candidate’s spatial proximity and Quality of Information contribution. In the first procedure, we proposed a Received Signal Strength Indicator Positioning–Determined Compressive Sensing algorithm to interpolate missing Received Signal Strength Indicator data. Then, a location-important marking method is put forward to select a set of high-quality data for estimating missing people’s location. In the third procedure, a double-condition greedy participant selection approach, which guarantees candidates’ spatial proximity and Quality of Information contribution, is executed to select optimal participants. Simulation results demonstrate that the proposed mechanism outperforms the other algorithms both in accuracy of positioning and quality of uploaded sensing data.
Introduction
People missing is a serious realistic problem, statistical report claims more than 1,370 people age 60 years or over go missing every day in China (see http://www.thestar.com.my/tech/tech-news/2016/10/11/online-app-helps-find-100-lost-elderly-in-china/). Locating or tracking the lost people is usually a challenging long-term task, which may last for several hours or even a couple of years. The main reason comes from two aspects. First, it may take a long time to start the people searching procedure, because (1) a careless carer or parent may be slow to catch on to that situation until the person has gone missing for a long time and (2) police will only begin looking for a missing person at a specific amount of time after the person was last seen. Second, it would take a long time to actually find the accurate location of the lost person. The major reason is that the existing technical means (e.g. smart phone–based anti-lost applications) are not applicable, especially in some extreme cases. That is, because (1) a mobile phone can be easily lost by the elderly or children, so it is hard to locate a missing person by mobile phone–based positioning. (2) The short battery life of a mobile phone limits the prime time of searching. Once the battery runs out, it would be unlikely to find lost people with mobile phone positioning. (3) Lost people may not have the opportunity to use mobile phones to share their locations with rescuers in some extreme cases, like abduction or kidnapping. Hence, an option is to develop a tiny portable device with long battery life and hide somewhere in the lost people’s body.
Existing locating or tracking solutions mainly rely on GNSS (Global Navigation Satellite System, for example, GPS), mobile base stations and RF (Radio Frequency, for example, Wi-Fi, Zigbee, RFID (Radio-Frequency Identification), and Bluetooth) technologies. Considering the particularity of lost people finding task, these solutions are not applicable. The main reasons can be stated as follows: (1) GPS-based positioning approach offers good location accuracy, but the GPS module is power-hungry. This shortage determines that GPS-based solutions do not fit into long-term task. (2) With regard to the base station–based positioning technologies, the positioning accuracy is highly dependent on the number of surrounding base stations. It is hard to guarantee that lost people can be located in the area within accuracy range. (3) Zigbee-, RFID-, or Bluetooth-based solutions can only locate objects nearby due to its lower transmit power.
Crowdsensing, a type of participative activity, in which individuals of varying knowledge, heterogeneity, and motivation are recruited to fulfill a task, has emerged as a popular data collection paradigm.1–4 By leveraging its powerful capacity of magnifying data-sensing ability, crowdsensing can expand the temporal–spatial data-sensing range of lost people finding task. Motivated by this benefit, a crowdsensing-based lost people finding model is proposed in this article. This model consists of three parts: a task management platform, a number of candidate participants, and a target people (the lost people). We assume that (1) lost people wear a lightweight BTLE (Bluetooth Low Energy) bracelet, which could transmit Bluetooth signal in a long time period; (2) all candidate participants hold smart mobile device, which can report its own GPS coordinates and received RSSI (Received Signal Strength Indicator) value to task management platform; and (3) task management platform is responsible for publishing lost people finding task, selecting appropriate participants, estimating lost people’s possible location with reported RSSI value, and delivery incentive to participants. The whole process can be briefly broken down into the following steps. Once the task management platform publishes a people finding task, motivated by incentive, the candidates who are dispersed over a wide area may apply for this task. The task management platform iteratively selects a portion of candidates as participants to search for the lost people by sensing their Bluetooth signal. Then, the platform starts a positioning calculation process to estimate the lost people’s location if enough sensing data have been collected. If the lost people are found according to the estimated position, the task terminates otherwise a new round of participant selection is initiated.
Two important issues would be settled in crowdsensing-based lost people finding model. First, due to adopting BTLE device as signal generator, the energy consumption is no longer a constraint for long-term people finding task. Second, by iteratively involving a number of people scattered all over the places as participants to collect the lost people’s Bluetooth signal, the effective range of positioning is greatly expanded. However, the greatest challenge of this model lies with how to locate the lost people with inadequate sensing data. Random moving behavior of the lost people as well as the large searching area together makes it a pretty small chance for participants to encounter the lost people up closely for receiving their BTLE signal.
Therefore, we conclude that finding people who got lost using crowdsensing-based paradigm is the key problem we aim to study in this article, within which data sparseness is the major challenge for this task. Actually, this problem can be turned into a participant selection optimization problem. In traditional crowdsensing tasks, Quality of Information (QoI) is the only consideration in participant selection, it is a widely used index to describe task publisher’s requirement, or evaluate the actual performance of crowdsensing tasks. Broadly speaking, it relates to the ability to judge whether information is fit for use for a particular purpose. QoI can be characterized by a number of attributes, including sensing locations, required amount of data at each location, the incentive each participant required, the reputation of participant, and the energy efficiency of sensing device. 5 For lost people finding, appropriate participants who are geographically close to lost people may contribute more effective sensing data. Thus, in addition to the QoI index (it is assumed the QoI is characterized by participant’s reputation value, incentive request and device’s energy efficiency for lost people finding task), we also take candidate’s location as key factors to select appropriate participants for contributing more effective sensing data. So, in order to address the problem of participant selection in people finding, we propose a three-phase approach. First, a RSSI Positioning–Determined Compressive Sensing (RPD-CS) algorithm is designed to interpolate missing RSSI data. In the second procedure, a location-important marking method is put forward to select a set of high-quality data for estimating missing people’s location with three-point localization method. In the third procedure, a double-condition greedy (DC-greedy) participant selection approach, which guarantees candidates’ spatial proximity and QoI contribution, is executed to select optimal participants.
The remaining of this article is organized as follow: section “Related work” reviews the literature of related works. The detailed scenario and processing flow is introduced in section “Scenario description.” Model description and detailed algorithms are elaborated in section “Model and algorithm description.” Section “Experimental evaluation” illustrates the experimental evaluation and section “Conclusion” summarizes and draws a conclusion.
Related work
Our work builds upon and extends prior work in (1) crowdsensing, (2) participant selection mechanism, (3) positioning technologies, and (4) compressive sensing (CS). So, we will review the literatures from the following four areas.
Crowdsensing
Crowdsensing, also referred to as mobile sensing, is an emerging technique which involves a group of individuals having mobile devices to collectively share sensing data and use the extracted information to measure and analyze common interest. Mobile devices equipped with various sensors have been ubiquitous, the embedded sensors can sense light, noise, location, and movement. With the huge amount of data source, mobile sensing is applied in environmental monitoring, road and traffic control, large-scale event monitoring, and other scenario. Air quality estimation is a typical application in mobile sensing. Feng et al. 6 designed a fine-grained PM 2.5 monitoring approach with abundant images, which are collected with mobile sensing. Besides air quality prediction, electromagnetic environment monitoring is also well studied. For example, Longo et al. 7 presented an electromagnetic device-mediated monitoring to gather and process electromagnetic field level sensed by the 3G/4G antennas on personal communication devices. Zappatore et al. 8 presented a mobile crowd sensing platform exploiting smartphone’s built-in microphones as sound sensing devices for creating large-scale noise maps and for suggesting city managers’ suitable noise reduction interventions. In order to facilitate public facility management and provide convenient services for smart city, Wang et al. 9 developed a mobile crowd sensing platform (PublicSense) for participatory public information reporting, issues intelligent classification, and intelligent tagging. Traffic events detection is another area where mobile sensing can play an important role. Wang et al. 10 presented a pedestrian safety alarm system by leveraging mobile crowd sensing and crowd intelligence aggregation to detect temporary obstacles and make effective alerts for distracted walkers. Rui et al. 11 studied the problem of allocating location-dependent tasks in vehicular crowdsensing applications. Similarly, Kong et al. 12 proposed a system called CrackDetector to detect cracks and estimate their types (i.e. horizontal, vertical, net) and size (i.e. the width and the length of the crack) with the sensing data collected in mobile crowd sensing pattern. The most similar applications to our task is crowdsensing-based anti-lost systems.13,14 These works focused on crowdsensing-based anti-lost systems by leveraging social features, but they did not explore how to locate the lost items with limited sensing data.
Participant selection
Existing works about participant selection for location-centric crowdsensing tasks mainly take data coverage ratio as primary factor. In the early stage, researchers focused on how to select a predefined number of participants to make the spatial coverage being maximized. 15 Later, some works realized that as spatial coverage goes up, data redundancy in some regions increases inevitably as well. Redundant data in sensing regions not only increases the cost but also leads to a decline to the QoI. Thus, researchers attempted to leverage the spatial coverage and redundancy. 16 Hereafter, besides data redundancy, various factors are introduced in participant selection procedure. For example, Li et al. 17 designed a reputation-based incentives scheme for data dissemination which can be used for motivating participants to deliver reliable data messages in mobile participatory sensing networks. Messaoud and Ghamri-Doudane 18 designed a Fair QoI and Energy-aware Mobile Sensing Scheme (F-QEMSS) to ensure both requestors’ and participants’ satisfaction by taking full consideration of various factors related to QoI, a heuristic tabu search algorithm is utilized to maximize the overall QoI. Compared with the existing works, we do not take coverage ratio as the major metric when we make participant selection decision. Instead, location importance is introduced as a major metric, with which the probability of participant’s spatial proximity to the lost people can be well represented.
Positioning techniques
Positioning has emerged as a critical function in people’s daily life and military applications. There are several major groups of positioning solutions depending on which type of propagation medium they are based on. The first group is RF-based technologies. RF systems estimate location by measuring different properties of RF signals. RF technologies include Wi-Fi, WSN (Wireless Sensor Network), Bluetooth, RFID, NFC (Near Field Communication), and two emerging technologies, that is, UWB (Ultra Wide Band) 19 and LoRaWAN (Long Range WAN). 20 The second group is IR (infrared) and visible-light-based. IR-based solutions use IR signals to determine object’s position, and the systems are usually made up of a network of IR sensors linked by wires and connected to a centralized location or server. IR positioning systems have a good battery life and is at low cost in room level. But its coverage range and accuracy is limited considering the Line-of-Sight (LOS) problems. 21 Visible light positioning technologies use visible light to determine the position of object. It is mainly based on the intensity modulation and direct detection module scheme. 22 The main drawback of visible light positioning is it has limitations which may be overlooked depending on coverage area and computational costs. 21 The third group is ultrasonic based. Ultrasonic positioning system rely on time-of-flight (ToF) measurement of ultrasonic signal, calculating using velocity and sound. It offers a number of advantages over other location systems in terms of low system cost, reliability, high energy efficiency. 23 From the perspective of implementation principles and application scenarios, existing positioning techniques could be grouped into the following categories. (1) Client-based positioning and Server-based positioning. In client-based positioning approaches, positioning is done directly on devices. Applications running on client can analyze the received signals of Wi-Fi access point or beacons and match the signal strength with its local database. On the contrary, in server-based positioning mode, a specific hardware captures the unique signals which are sent out by a Wi-Fi enabled device or a Bluetooth beacon and then transmits them to a server which calculates the position via finger printing based on the signal strength and coordinates. (2) Outdoor-oriented and Indoor-oriented positioning. Outdoor-oriented positioning techniques are mainly developed based on a reference station or a network of stations. Outdoor positioning also can rely on ubiquitous mobile network base stations, but the precision can only reach the order of several meters at best and highly depends on the number of surrounding base stations. For indoor-oriented techniques, there is no prevailing standard. Wi-Fi and Bluetooth/BTLE are the most adopted technologies in indoor-positioning due to their ubiquitous deployment. 24 They both use ranging based on RSSI measurements, which yield accuracy in the order of meters. (3) LOS and NLOS (Non-Line-of-Sight) scenario. According to the quality of wireless transmission channel in different scenarios, positioning approaches can be classified into LOS/NLOS modes. Plenty of researches on positioning methods in LOS environment have been conducted. 25 NLOS refers to the radio transmissions across a path that is partially obstructed, usually by a physical object in the innermost Fresnel zone. In NLOS environment, only signals which can reflect or diffract can reach the receiver, causing NLOS errors in Time-of-Arrival measurement.
CS
CS, a novel signal processing theory, is attracting increasing attention due to its powerful capability in reconstructing a sparse matrix based on its low rank property. 26 Since its appearance, CS has inspired a wave of researches in a broad area of applications including statistics, image processing, signal recovery, and machine learning. As for missing data recovery, it has been adopted in network traffic estimation, 27 vehicular infotainment systems, 28 localization in mobile networks, 29 and loss data reconstruction in sensor networks. 30 Besides, CS also inspired a new research trend in crowdsensing. Wang et al.31,32 proposed a framework called compressive crowdsensing task allocation (CCS-TA) to dynamically select a minimum number of sub-areas for sensing task allocation in each sensing cycle, while deducing the missing data of unallocated sub-areas under a probabilistic data accuracy guarantee. Cheng et al. 33 designed a framework called DECO to detect false values for crowdsensing in the presence of missing data. By applying a tailored spatio–temporal CS approach, their framework can detect the false data and estimate both false and missing value for data correction. Yu et al. 34 proposed a Compressed Sensing–based and Implicit Cooperativity–based Data Gathering algorithm (CIDG) in mobile crowdsensing systems, they discovered and defined implicit cooperativity between data and further exploited it to estimate un-transmitted data, and finally recovered the original data by exploiting the compressed sensing reconstruction algorithm. However, two deficiencies make existing general CS algorithms unable to fit neatly into the demand of lost people finding. The first is that most CS algorithms have high time complexity, especially for those matrixes with high sparsity. The second reason is that the sensing data (RSSI) is sensitive to external environment, the effect of noise should be taken into account in data imputation process. Therefore, a temporal–spatial RPD-CS algorithm is proposed in this article. On one hand, RPD-CS balances the requirement of positioning accuracy and efficiency, on the other hand, the recovered data can best fit the characteristic of temporal–spatial distributed RSSI data by incorporating the effect of noise.
Scenario description
Figure 1 describes the whole process model. A lost people finding task is released by crowdsensing platform at time

Processing flow of crowdsensing-based lost people finding: (a) selected candidate participants for tn time slice, (b) data collection and missing data deducing at time slice tn, (c) estimated position of the lost people at tn time slice, (d) predicted position of the lost people at tn + 1 time slice according to the updated accumulated predicted trajectory, and (e) selected candidate participants for tn + 1 time slice.
To accomplish the above elaborated tasks, four challenges should be properly addressed.
How to infer missing data (RSSI) which should have been sensed in vacant grids? Sparseness of sensing data leads to difficulty in locating lost people’s tracing point. Imputed missing data can, to some extent, compensate position deviation caused by information insufficiency. In consideration of the wireless signal’s attenuation characteristic, a temporal–spatial RPD-CS algorithm is proposed.
How to select suitable data to deduce lost people’s possible position at each task cycle? Quality of each referred data (RSSI value) differs much with regard to a specific positioning algorithm. Data refinery is an essential stage to extract a best fit set of the sensing/imputed data for subsequent position calculation. Thus, a location-important imputed data marking algorithm is proposed.
How to predict the lost people’s next position with estimated tracing points? Considering the temporal and spatial continuity of motion objects, the historical inferred trajectory of the lost person will determine his or her next position to a large extent. For this scenario, Markov Chain is adopted to solve the problem.
How to select optimal participants for each sensing cycle? Spatial proximity is of crucial importance for participant selection in crowdsensing-based lost people finding scenario. Besides, QoI contribution is also an important factor that should be balanced. Thus, a DC-greedy algorithm is proposed, not only to ensure spatial proximity’s significance but also to accommodate the concerns of a participant’s QoI contribution.
Model and algorithm description
CS-based missing data imputation
CS is an effective means to recover low-rank matrix which has lots of missing data. The basic principle of CS is that, according to the Shannon–Nyquist sampling theorem, 35 the sparsity of a signal can be recovered from far fewer samples than required through optimization. Two conditions are necessary under which data recovery is possible with CS. The first condition is sparsity, which requires the signal to be sparse in some domain. The second condition is incoherence applied through the isometric property, which is sufficient for sparse signals. In most cases, only a few participants can receive the signal sent from the lost people, so the sensing data are sparse in both spatial and temporal dimensions. It is not difficult to reveal the low-rank structure of the sensing data matrix. Meanwhile, the missingness pattern does meet requirement of pure random distribution. Thus, CS is applicable for referring those missing RSSI value. Key concepts in CS-based data imputation can be defined as below.
Definition 1
Environment matrix (EM): denoted as
Definition 2
Binary matrix (BM): denoted as

Definition 3
Sensing matrix (SM): denoted as

Here, the operation ° denotes Hadamard product, which is a binary operation that takes two matrices of the same dimensions and produces another matrix where each element
Definition 4
Reconstruction matrix (RM) is generated by interpolating missing data in

Definition 5
Noise Matrix (NM) is an
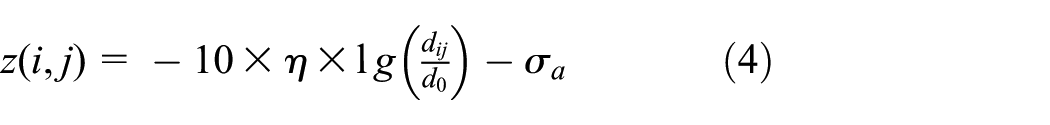
The path loss exponent

As stated in equation (3), the goal of data recovery task is to estimate

So, through an inverse process, we can also create an

This

It is still difficult to solve this minimization problem with equation (8), since it is non-convex. To solve this problem, we take advantage of the SVD-like factorization according to equation (6)

where

Instead of solving equation (10) directly, we solve the following equation using Lagrange multiplier method

where the Lagrange multiplier

For simplicity, the above described missing data imputation algorithm is named as RPD-CS, the detailed description is illustrated in Algorithm 1.

RPD-CS algorithm solves the optimization problem in an iterative manner.

This equation can be rewritten as
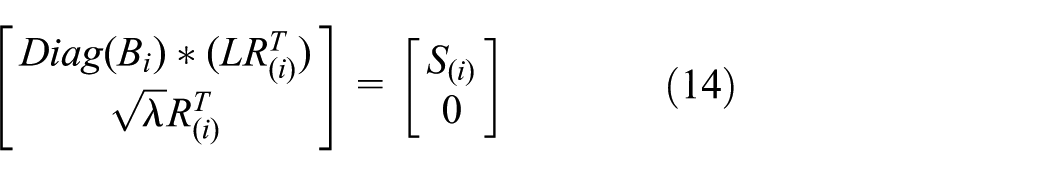
where
Location-important data marking
The data in different grids have different impacts on positioning the lost people’s possible location. It is assumed that (1) the impact of a grid is partly determined by its previous effectiveness. In other words, if the lost people’s location in previous time slots has ever been determined with the data associated with this grid, it has greater impact than other grids. (2) The nearer a grid approximates to those grids where RSSI signal has ever been captured in present or past task cycles, the more important the grid is. So, two criteria, that is, Cumulative Impact and Temporal–Spatial Proximity, are defined to evaluate a grid’s importance in position calculation. Cumulative Impact is a metric which reflects the cumulative contribution of a rigid, while Temporal–Spatial Proximity depicts the reliability of a imputed data in both temporal and spatial dimensions.
Definition 6
Cumulative Impact Vector (CIV) is a
Definition 7
Temporal–Spatial Proximity Vector (TSPV) is a

Based on the two criteria discussed above, the importance of each data could be defined as equation (16)

Accordingly, top

Position estimation with three-point localization
Three-point localization method is adopted for estimating lost people’s tracing point, so
With each of the
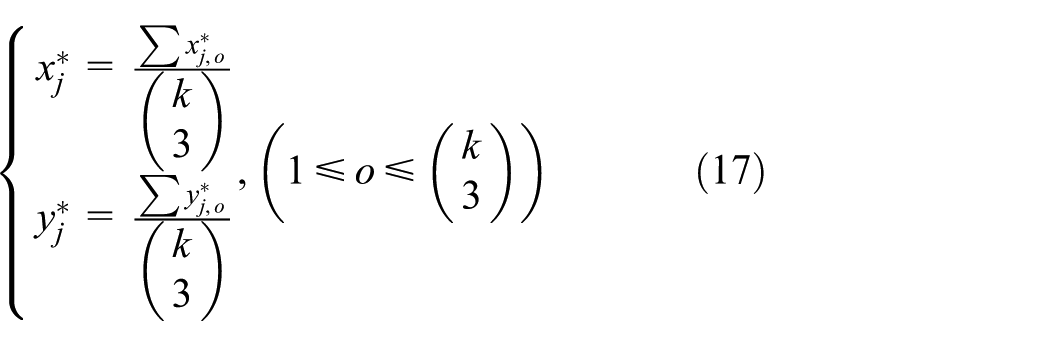
It is important to note that the degree of positioning precision largely determines the success of lost people finding task. According to most people’s talent for face recognition, the precision in order of meters is an appropriate requirement. As stated in the previous subsection, the Cumulative Impact of the

Position contribution
Assume that the lost people’s random walk obeys Markov process.
38
Let
It is worth noting that
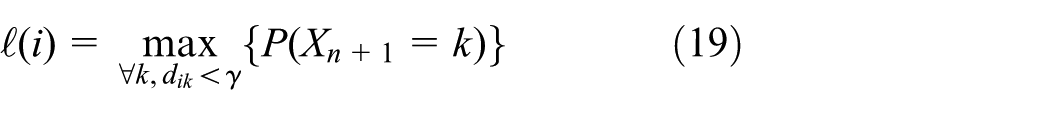
Participant selection
To select an optimal set of participants in each task cycle, a DC-Greedy algorithm is proposed. Position contribution

Definition 8
Participants matrix (PM): denoted as

Algorithm 3 describes the detailed procedure. First, grids with same position contribution value are grouped as a sub region and then all grids are sorted according to the position contribution in descending order. Second, in each region, an optimal set of users are selected according to their QoI contribution. Besides, in order to ensure necessary coverage ratio, at most

Privacy preserving
Privacy preserving is crucial in crowdsensing applications. In order to protect participant’s sensitive information, an encryption method is utilized to prevent participant’s personal identity and location information from being distorted or misappropriated. At the initial phase, the task platform generates a pair of keys

After receiving the encrypted data packet from participants, platform decrypts packets with
Experimental evaluation
Setup
In order to assess the proposed model, two open access datasets are utilized. The first dataset (http://crawdad.org/kth/rss/20160105) is collected by a robot in both indoor (KTH) and outdoor (Dortmund) environments. The second dataset (https://www.researchgate.net/publication/286170356) is collected by an unmanned aerial vehicle in a mixed indoor–outdoor environment. The robot and the unmanned aerial vehicle were both equipped with a wireless data receiver to capture the radio signal transmitted by sensors which were randomly deployed in different places. Both datasets contain RSS (Radio Signal Strength) data received by the robot or unmanned aerial vehicle, and RSSI metric is used to collect the RSS data in terms of dBm. Taking the following factors into consideration, we decided to simulate the lost people finding scenario with the above mentioned datasets. First, the communication mode between robot/aerial vehicle and wireless sensors coincide with that between the participants and lost people. Second, the datasets contain a sequence of time-stamped points that contain the wireless data receiver’s latitude, longitude, and received RSSI value, which is well suited for simulating the data characteristic of participants in lost people finding scenario. Third, the wireless data transmitters are randomly deployed across the task area, which is in partial compliance with the random-walking behavior of the lost people. Fourth, the opportunistic communication mode between robot/aerial vehicle is similar to the encountering problem between participants and lost people. Thus, neglecting the impact of both participants and lost people’s conscious psychological factor, the lost people finding scenario can be simulated with the datasets in considering the similar communication mode, data characteristic, and the opportunistic encountering character.
To simulate the crowdsensing-based lost people finding scenario, the following preprocessings are required. First, we store all the time-stamped points along with receiver’s latitude, longitude, and RSSI value in a geographical MySql database, and the entire region is divided into grids with fixed size. Second, the wireless data transmitters deployed in different grids are emulated as a lost people and the integrated path between adjacent transmitters is then deemed as the lost people’s trajectory. Third, the wireless data receivers (robot/unmanned vehicle) are regarded as participants, and their reputation, incentive request, and energy efficiency values are allocated with a random number generator. Only a portion of sensing data (RSSI) in some grids are available in the dataset. So, it shows an obvious sparseness in both temporal and spatial dimensions. Table 1 describes the detailed information of each dataset.
Detailed information of datasets.

All the environment settings and experiments are implemented by Python script files, and a server with Intel CPU i7-8700k (3.70 Ghz), 64G DDR4 memory is adopted as experimental platform.
Parameter tuning
Before evaluating the performance of our proposed model, a series of parameters have to be tuned. Iteration times in missing data imputation procedure is a parameter which has important impact on the data recovery accuracy. The number of selected location-important data is another important parameter which may affect the final result of lost people finding. So, in this part, we would elaborate the detail of parameter tuning process.
Iteration times tuning
As mentioned in subsection “CS-based missing data imputation,” data imputation is computationally intensive, so in order to balance the computation cost and the imputation accuracy, a proper iteration time is of great necessity.
First, in order to measure the accuracy of data imputation, index of

Actually,

Data imputation with different CS algorithms: (a) indoor, (b) outdoor, and (c) indoor–outdoor mixed.
Comparison experiments are also conducted on the basic CS algorithm and its enhanced version Spatial–Temporal Compressive Sensing (ESTI-CS). 30 Figure 2 illustrates the performance of each algorithm in different environments. Our proposed RPD-CS algorithm outperforms other two algorithms, since it takes signal attenuation into consideration, meanwhile it reduces unnecessary iterations while keeping a relative accuracy of data recovery. Take outdoor dataset as an example, the error ratio of RPD-CS is about 16% and 10% lower than CS and ESTI-CS, respectively, when coming to steady state.
Marking ratio tuning
Remember that, in order to improve the positioning accuracy, most top
First, in order to investigate how data marking affects positioning accuracy, index Mean Deviation of Positioning is introduced as

Here,

Performance of positioning accuracy.
As shown in Table 2, RPD-CS achieves 2%–4%, 10%–14%, and 4%–6% lower Error Ratio of Data Recovery than ESTI-CS and CS for indoor, outdoor, and mixed environments. Meanwhile, RPD-CS outperforms ESTI-CS and CS in Mean Deviation of Positioning which controls the positioning accuracy near 10 m.
Performance comparison in data imputation and position calculation.

CS: Compressive Sensing; ESTI-CS: enhanced version Spatial–Temporal Compressive Sensing; RPD-CS: Received Signal Strength Indicator Positioning–Determined Compressive Sensing.
Performance evaluation
Based on the pre-set parameters, the following experiments are designed to evaluate the performance of our proposed participant selection approach from three aspects: how much QoI gain the selected participants can contribute? how possible the selected participants can approach the lost people? and how many rounds would it take to finally locate the lost people?
As previously stated, participants’ reputation, incentive request, and energy efficiency are randomly allocated in the simulation environment. Considering their equal importance, we set their weight, that is,
QoI contribution comparison
QoI is an important index for evaluating the data quality in crowdsensing tasks. Appropriate participant selection algorithm can benefit higher QoI gain. So, in this part, we would make comparisons between our proposed DC-Greedy algorithm with the other participant selection approaches according to QoI Contribution Ratio. Based on the definition of QoI Contribution (refers to equation (20)), we further define QoI Contribution Ratio

Actually, it reflects the relative quality of selected participants, the greater the index

User coverage versus QoI contribution ratio: (a) indoor, (b) outdoor, and (c) indoor–outdoor mixed.
Proximity comparison
In order to further analyze the performance of participant selection, the following experiments are conducted to measure the degree of participants’ proximity to the lost people. Thus, the index of Deviation of Distance for Participant Selection is introduced as

where
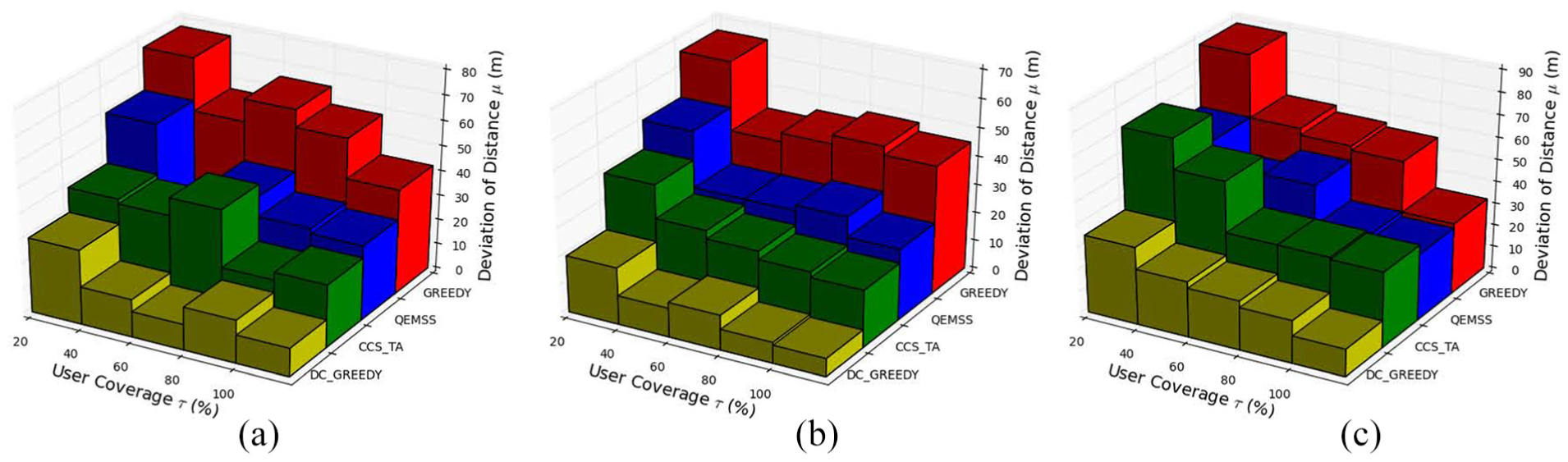
User coverage versus deviation of distance: (a) indoor, (b) outdoor, and (c) indoor–outdoor mixed.
Table 3 shows DC-Greedy algorithm achieves 12%–23%, 13%–29% and 0%–7% higher QoI Contribution Ratio than Greedy, QEMSS and CCS-TA for indoor, outdoor and mixed environments. Meanwhile, only DC-Greedy algorithm controls the index Deviation of Distance for Participant Selection near 10 m for indoor and outdoor environments and controls near 20 m in mixed environment.
Performance of participant selection.

QEMSS: Quality of Information and Energy-aware Mobile Sensing Scheme; DC-greedy: double-condition greedy.
Achievement orientation comparison
In this part, experiments are conducted to compare the overall performance of different schemes. More specifically, we will combine different data imputation algorithms and participant selection algorithms to see how many rounds will they take to finally locate the lost people. In order to facilitate comparison, all schemes adopt same location-important data marking approach and three-point localization method. As illustrated in Table 4, the combination of RPD-CS and DC-Greedy outperforms the other schemes. It only takes 8, 15, and 7 rounds, respectively, to finally locate the lost people. The major reason is that the PRD-CS and DC-Greedy model can provide relative accurate imputed data for calculating lost people’s possible position, meanwhile a QoI driven participant selection approach ensures more suitable participants can be recruited for the lost people finding task (Table 4).
Achievement orientation comparison.

CS: Compressive Sensing; ESTI-CS: enhanced version Spatial–Temporal Compressive Sensing; QEMSS: Quality of Information and Energy-aware Mobile Sensing Scheme; RPD-CS: Received Signal Strength Indicator Positioning–Determined Compressive Sensing; DC-greedy: double-condition greedy.
Conclusion
Participatory sensing has opened a new methodology for addressing lost people finding issue. However, people’s random walk in large open area bring challenges for accurate positioning or tracing target person. To address this problem, we present a novel framework. First, in order to solve sensing data sparse problem, a RPD-CS algorithm is proposed to infer the missing RSSI data in numerous task grids. Second, a location-important imputed data marking method is applied to improve the quality of data for estimating people’s position with three-point localization algorithm. Third, trajectory prediction is applied to predict the probability distribution of lost people’s next position with the series of estimated historical tracing points. Finally, a DC-greedy participant selection approach, which guarantees candidate’s spatial proximity and QoI contribution, selects the most appropriate set of participants. Experimental evaluation shows that our solution achieves higher quality of sensing data than other algorithms. Meanwhile, it ensures the required accuracy of position calculation. There are many potential future directions of this work. It would be interesting to further study the incentive and privacy mechanisms in our future work.
Footnotes
Handling Editor: Zhiyuan Tan
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partly supported by the National Natural Science Foundation of China (No. 61602051, 61802022 and 61802027) and the Fundamental Research Funds for the Central Universities (No. 2017RC11).