
Abstract
The low bandwidth utilization is a serious problem for mobile services over vehicular networks. This is mainly resulted from the high-rate transmission of packets carrying small payloads. Some solutions are proposed to forward packets by context identifier, instead of IP address, based on header compression and software-defined networking technology. However, these solutions cannot be deployed in vehicular networks successfully, due to the limitations on processing capacity and routing scalability. In this article, we propose a scalable end-to-end header compression scheme, which takes advantage of the locator/identifier separation concept and some characteristics of software-defined networking. We propose to utilize a forwarding identifier to indicate the compressor’s location, separating the header compression process from the packet forwarding process. In this way, context identifiers with an identical value are allowed to coexist in the same network, and flow table entries matching the compressed flows can be aggregated. Extensive simulations have been conducted and the results demonstrate that scalable end-to-end header compression experiences outstanding performances in bandwidth utilization and delay, showing its greater suitability for vehicular network transmission optimization.
Keywords
Introduction
The data transmission over vehicular networks has attracted a noticeable amount of research interests from the academia and industry. As an important part of the intelligent transportation system (ITS), vehicular networks have a significant influence on improving traffic safety and providing convenience for passengers. With the exponential growth in the number of mobile devices and multimedia applications, the data transmitted in vehicular networks are becoming more and more diverse, such as the road and weather conditions for vehicles, and entertainment information for passengers.1,2 These emerging services pose challenging demands for vehicular networks, including higher data rates and lower latency. 3 To satisfy their interactivity requirements, most mobile services send high rates of small-payload packets in which the average payloads are tens of bytes. For example, a typical voice over internet protocol (VoIP) packet usually carries a 20-byte payload and a 40-byte header, where the payload only accounts for 33% of the packet. Traffic patterns with low payload–header ratio are known as “small-packet services,” and their significant overhead at all layers translates into serious impairment of bandwidth utilization and delay. In the foreseeable future, the widespread use of IP-based multimedia services will further increase the bandwidth consumption and delay. Thus, the methods to save bandwidth and reduce delay are very desirable for vehicular networks.
The header compression concept has been recognized as a promising solution for current transmission issues. Because of the high correlation between the headers of two consecutive packets, the essential idea of header compression is to remove the header fields on the sender and restore them on the receiver, transmitting only the difference between them. 4 Many excellent mechanisms have been proposed with surprising compression efficiency, and they have been vetted through commercial vendors in industry. However, these mechanisms have to be operated based on a hop-by-hop process. To transmit an end-to-end communication, the packets need to be compressed and decompressed at each node on the path. These compression–decompression cycles would imply additional delay and computation cost.
Recent evolution of software-defined networking (SDN) has brought new opportunities for packet processing. Many researchers have proposed using SDN to establish virtual end-to-end tunnels, so that the compressed packets can be forwarded based on their remaining headers. The experiment results indicate that the ingenious combination of two techniques can reduce the transit delay and computation cost effectively. However, due to the lack of scalability, the current scheme is not suitable to be deployed in vehicular networks. First, the current scheme must assign a unique context identifier (CID) for each data flow, resulting in an insufficient processing capacity. Second, the current scheme establishes a customized tunnel for each compressed flow, causing a dramatic increase in interactive information. Third, the current scheme cannot aggregate flow table entries that match the compressed packets, wasting precious flow table space.
In this article, we propose a novel end-to-end header compression scheme, namely, scalable end-to-end header compression (SEHC). Different from the current scheme, SEHC has excellent scalability: First, SEHC has an increased processing capacity with the expansion of network scale. Second, SEHC only updates few flow table entries when routing compressed flows, effectively reducing the interactive information. Third, SEHC can forward different compressed flows with the same flow table entry, saving the flow table space. These advantages enable SEHC to be successfully deployed in vehicular networks, effectively improving bandwidth utilization and reducing delay. We summarize the main contributions of this work as follows:
We have proved that the current header compression scheme has limitations in processing capacity and routing scalability, which critically impede its deployment in vehicular networks.
A novel end-to-end header compression scheme, SEHC, is proposed, which takes advantage of the locator/identifier separation concept and some characteristics of SDN to achieve excellent scalability.
Extensive simulations have been conducted, and the results show that SEHC can effectively improve bandwidth utilization and reduce delay, which is suitable for vehicular network transmission optimization.
The remainder of this article is organized as follows. The “Related work” section overviews the recent researches on the application of SDN in vehicular networks and the combination of header compression and SDN, and investigates their deficiencies for deployments. The “Optimized header compression scheme” section proposes the system model of SEHC in detail. Then, in the “Benefit analysis” section, we analyze the theoretical benefit of SEHC in comparison with the current scheme. The experiments and simulations are presented in the “Experiment evaluation” section. Finally, we conclude in the “Conclusion” section.
Related work
SDN and vehicular networks
As a novel architecture, SDN provides a viable solution to control the network in a systematic way. In SDN, based on the radical separation of control plane and data plane, the network resources become programmable and manageable with knowledge of the entire network. Meanwhile, standardized protocols such as OpenFlow support flexible matching patterns and various actions, allowing the network to provide customized communication for each data flow. With its high efficiency and flexibility in network management and configuration, SDN has been widely expected to play a key role to unlock the potential of future networks.
Recently, a significant amount of researches have been conducted on the application of SDN in vehicular networks. Ku et al. 5 proposed a software-defined vehicular network architecture and described several operational modes and services that can be provided. They also demonstrated its feasibility using some simulation evaluations. Riggio et al. 6 presented a set of programming abstractions modeling the fundamental aspects of a wireless SDN, namely, state management, resource allocation, network monitoring, and network reconfiguration. Salahuddin et al. 7 proposed a vehicular cloud architecture implemented using SDN, which consists of traditional roadside units (RSUs) and specialized RSUs containing micro-data centers. Based on the idea of centralized control, SDN can overcome the difficulties in vehicle cooperation caused by the no-center and multi-changing characteristics of vehicular networks. With its flexible management and allocation of network resources, SDN has obvious technical advantages in scalability and efficiency. These advantages can meet the requirements of vehicular networks in aspects of mobility, dynamic topology, and network scale.
End-to-end header compression
The study of bandwidth optimization has never stopped. As the most famous compression scheme, RObust Header Compression (ROHC) is widely used in wireless networks with high bit error rate, high losses, and long round-trip time. 8 It has already been integrated into 3rd generation partnership project (3GPP)-universal mobile telecommunications system (UMTS) specifications 9 and standards for long term evolution (LTE) networks. However, this scheme is operated on a hop-by-hop basis. When transmitting an end-to-end communication, the packets are processed, as Figure 1 shows. In Figure 1, the context records the recent information about the field values and their change patterns in the packet header, and the CID is a number used to identify the correct context. Obviously, there will be a lot of compression–decompression cycles, which cause additional delay and computation cost.

Compression–decompression cycles.
One solution is to use an end-to-end tunnel to avoid the processing on intermediate nodes, while multiplexing multiple header-compressed packets together to share the tunnel overhead. Saldana et al. 10 proposed a generic and lightweight multiplexing protocol Simplemux, which can multiplex packets belonging to one protocol into another. Therefore, a number of compressed packets can be transmitted together, greatly reducing bandwidth usage and packet rate. They also studied the feasibility of applying this combination to the traffic of massively multiplayer online role-playing games. 11 Tömösközi et al. 12 presented the power consumption measurements for the tunnel with ROHC version 2, and they found that the usage of header compression on modern mobile devices is unlikely to result in increased power consumption and even decrease the battery drain when payloads are small. However, the tunnel overhead reduces the savings obtained by header compression, and a multiplexing delay is required to pack multiple packets together.
Advanced header compression mechanisms are needed to provide a high quality in both bandwidth saving and time experience. Jivorasetkul et al. 13 first proposed to incorporate header compression techniques into an OpenFlow-based SDN, with the aim of reducing both packet size and time delay. In this scheme, the controller performs routing algorithm and adds new flow table entries to OpenFlow switches, to establish end-to-end tunnels. The link layer information is used to identify compressed flows and plays a key role in packet routing. The authors gave a more detailed description about their scheme, 14 and proposed an identifier substitution technique to prevent potential conflicts, when distinct flows that are assigned an identical identifier by different compressors share the same link. However, in this scheme, packets are compressed and decompressed on end hosts; the controller cannot manage the compression process in a centralized manner. In addition, this scheme uses media access control (MAC) addresses to identify compressed flows, making it impossible to handle cases that have two or more flows to be compressed between the sending host and the receiving host.
Saldana et al. 15 proposed another scheme that implements header compression within an OpenFlow-based SDN. In this scheme, the static header fields that present in OpenFlow tuple are removed from packet headers, providing significant bandwidth savings. Meanwhile, in order to further improve the bandwidth utilization, a packet multiplexing technology is also taken into consideration. The authors applied their optimization scheme to four public Internet traffic traces, 16 and the results demonstrated that the bandwidth consumption is significantly reduced, especially in traces where the percentage of small-payload packets is high. Furthermore, the additional delay can be kept very low in high-throughput traces. However, this scheme only compresses the static header fields, resulting in a low compression ratio.
In addition to the above disadvantages, the current scheme also has some deficiencies in scalability. (a) Insufficient processing capacity: In header compression, the number of CID determines the amount of data flows that can be processed. The current scheme must ensure the uniqueness of each CID to prevent potential conflicts at intermediate nodes, so it is only suitable for networks with few data flows. (b) Exploding interactive information: The current scheme creates a customized tunnel for each compressed flow, where the controller needs to add flow table entries to all switches on the routing path. Therefore, the increase in the number of switches and flows would lead to a dramatic increase in interactive information between the controller and switches. (c) Wasted flow table space: Most commercial SDN switches are equipped with small-sized ternary content-addressable memories that support a few thousand flow entries. 17 Thus, forwarding is based on aggregates. 18 However, in the current scheme, a flow table entry can only match one compressed flow, which results in inefficient use of flow table space.
Optimized header compression scheme
In this section, we propose a novel header compression scheme—SEHC. We first give the critical design of header compression implementation on switches. Then we present the signaling process and controller algorithms.
Header compression implementation
In SEHC, header compression is implemented on the switches, with the aim of achieving the centralized control of compression process. These switches are called compressors or decompressors, in order to distinguish them from normal switches which only forward packets. We study the recent instance of adding new extensions to SDN 19 and decide to integrate the ROHC library into compressor as a call module. ROHC is used because it can provide both high compression ratio and high robustness. The controller can communicate with the header compression entity in both directions. According to the flow characteristics and network status, the controller can control which flow to be compressed and provide relevant parameters such as CID.
The identity and location binding is the root cause of the current scheme’s poor scalability. Besides as the context indicator, the CID is also used as the forwarding label to match the flow entries in switches. The dual semantics of CID makes it inevitable to establish the customized tunnels. Thus, it is necessary to introduce the locator/identifier separation concept into the current scheme, which was proposed to address the routing scalability problem. 20 The basic idea of locator/identifier separation is to create two addresses for each network node: one for its identity (identifier) and the other for its location in the network (locator). This separation allows a node to keep the same identity even when its location changes, providing effective mobility and scalability support. 21 Locator/ID separation protocol (LISP) 22 is the most famous locator/identifier separation scheme, which encapsulates the locator ahead of the identifier. Similarly, we propose to append a forwarding identifier (FID) in front of the compressed packet to indicate its decompressor’s location. In this way, the header compression process is separated from the packet forwarding process. Considering a 1-byte FID, it is enough to provide the location namespace of compressors in a large-scale network. The logical components of a compressor are shown in Figure 2, in which the header compression module is composed of two parts: One, named compression module, can encode header fields and decompress header-compressed packets; the other, named encapsulation module, can append FID to the front of packets.
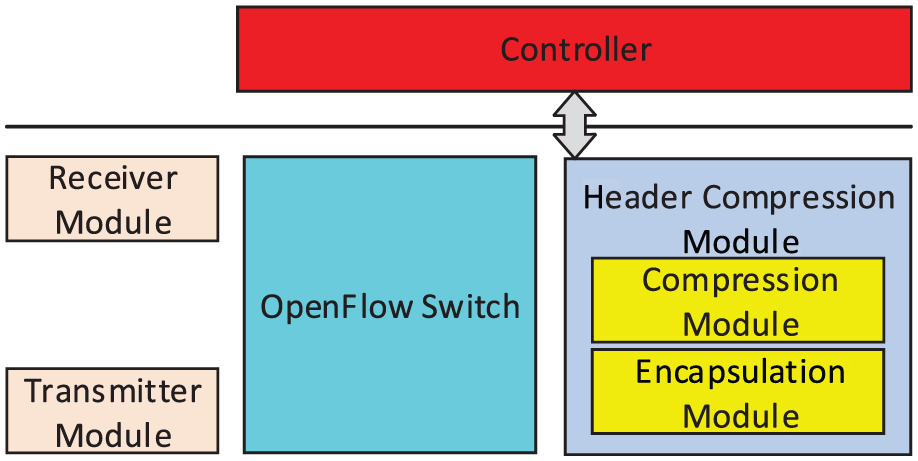
Compressor components.
Signaling process and controller algorithm
In SEHC, the controller not only controls the header compression but also manages the forwarding of compressed packet. Its general workflow includes the following processes: system initialization, CID and FID decision, and flow table installation.
1. System initialization: When the controller detects the access of a vehicle within its jurisdiction, it confirms whether the vehicle is a switch or a compressor, and acquires relevant connection information and performance parameters such as maximum CID value. For a compressor, the controller creates and maintains three tables: table
2. CID and FID decision: When the controller receives the first packet in a new flow, besides calculating the transmission path, it decides whether to compress this flow. Generally, there are multiple compressors on the transmission path. In order to save the bandwidth as much as possible, the data flow should be compressed at the ingress vehicle and decompressed at the egress vehicle. However, the ingress and egress vehicles are not always compressors, or all the CIDs of one of them are occupied. In this case, a decision mechanism, that is, Algorithm 2, is needed to select the most appropriate compressor and decompressor. First, along the transmission path, each compressor is associated with all decompressors behind it, forming compressor–decompressor pairs. Next, the distances of these pairs (e.g. hops) are calculated, and sorted from large to small. Starting from the pair with the largest distance, the controller tries to obtain an available CID from their tables. For a compressor–decompressor pair, CIDs that are unoccupied both in the table

where



Then the controller removes the
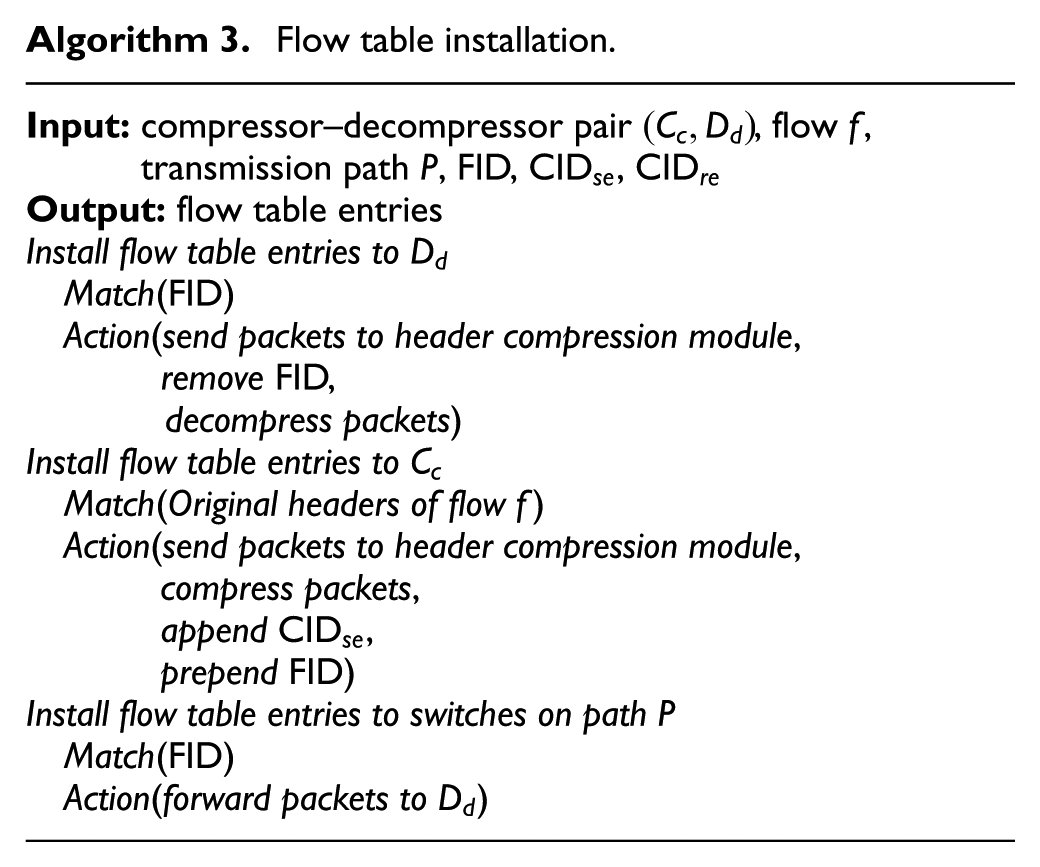
3. Flow table installation: After determining the appropriate identifiers, the controller begins to install flow table entries to the compressor, the decompressor, and switches using Algorithm 3. The controller first sends the FID to the decompressor and commands it to forward packets carrying this FID to the header compression module. When the decompressor is ready, the controller sends the
When all flow table entries are properly installed, the packets of this new flow will be processed, as Figure 3 shows. First, the packets are forwarded from the ingress vehicle to the compressor. Next, the compression module of the compressor establishes a context for this data flow, encodes the dynamic fields of packets, and appends the

Diagram of packet processing.
Benefit analysis
In this section, we analyze the theoretical benefit of SEHC in the aspect of processing capacity, routing scalability, and bandwidth savings and delay, compared with the current scheme. For illustration concisely, we consider a vehicular network containing
Processing capacity
In the current scheme, a CID has double semantics. The scheme must ensure that each CID is unique, in order to prevent conflicts at intermediate nodes. Therefore, the maximum processing capacity to compress flows is determined by the highest CID number that can be used, and the same is the expectation

As for SEHC, the CID only serves as a context indicator; multiple CIDs with an identical value can appear in the same nodes or links. Thus, the maximum processing capacity is equal to the total number of

When the number of compressors is 2, the maximum processing capacity can be reached, and the expectation is

We would like to calculate the expectation of our optimized scheme. In SEHC, the assignment of different CID values is absolutely independent, so the assignment of all values can be regarded as
Let
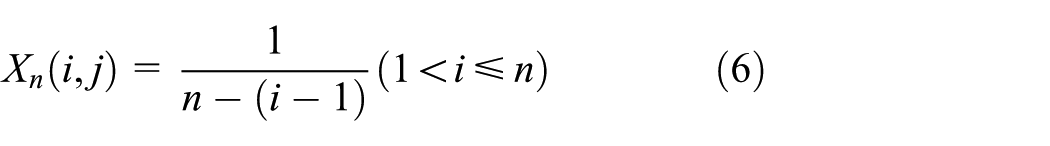
While in the second condition one of them is the

We let
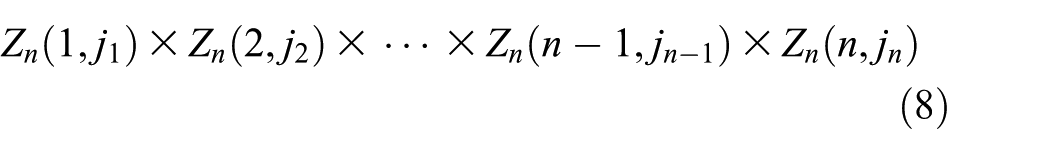
where

Thus,


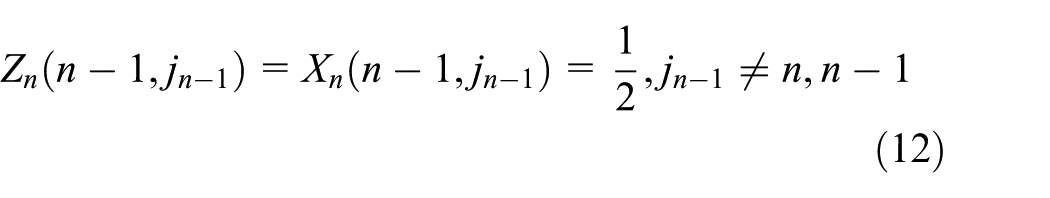
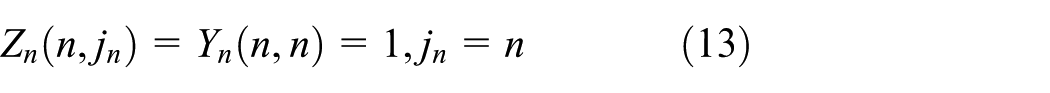
Equation (10) reflects the fact that
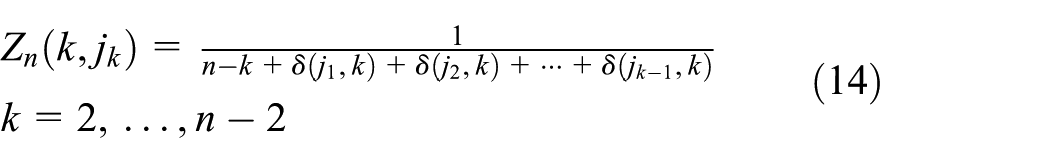
Hence, the required probability

The number of
As mentioned before, the number of remaining

Apparently, compared with the current scheme, SEHC can increase the processing capacity by nearly
Routing scalability
Compared with the current scheme, the routing scalability of SEHC is mainly embodied in the following two aspects:
Interactive information reduction: The current scheme establishes tunnels with the purpose of transmitting a single flow; hence, the controller needs to add numerous flow table entries to switches for each flow. While the goal of SEHC is to connect compressors and decompressors, the idea of a generic FID makes the switches agnostic of the CIDs of data flows. Once the tunnel is complete, the controller will no longer need to send forwarding entries for a single flow. Meanwhile, the dynamic changes of the data flows would have little influence on the flow table update of switches. Thus, the interactive information between the control plane and the data plane can be greatly reduced.
Flow table size reduction: The current scheme provides fine-grained control based on CID. For each compressed flow, there is a flow table entry in every switch on its transmission path. As a result, the number of entries in a switch is almost equal to the number of data flows across it. The flow table size would grow to hundreds of thousands in a large-scale network. While in SEHC, we can give a coarse-grained forwarding mechanism by aggregating entries that match the same FID into one. Thus, the number of forwarding entries in a switch is at most equal to the number of FIDs in the network. Obviously, the number of FIDs is much smaller than the number of data flows, so the flow tables used to match compressed flows can be kept very small. In addition, the cooperation between FID and CID can be used to implement some fine-grained forwarding when more flexibility is needed.
With such good routing scalability, the network can quickly recover its stability when network load increases or topology changes, resulting in better bandwidth utilization.
Bandwidth savings and delay
In this section, we compare the performance of the current scheme and SEHC in terms of bandwidth savings and delay. Let

Regarding data flows with the same protocol combination and payload size, the given equation can be transformed into
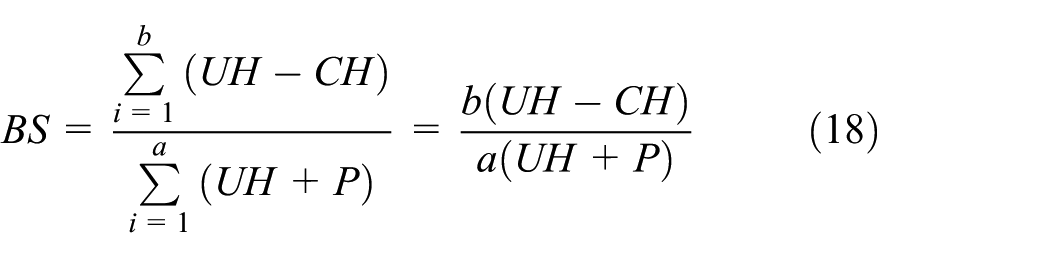
The ratio of
In fact, however, not all data flows can be compressed. On one hand, the number of compressed flows cannot exceed the processing capacity of the network, that is, the total number of available CIDs. On the other hand, the compressed flows cannot be transmitted when the flow table space is exhausted. When there are only a few data flows, both the current scheme and SEHC can compress all these flows and achieve high bandwidth savings. However, when a lot of data flows pour into the network, the current scheme will soon reach the upper limit of its processing capacity (maximum CID value
Using header compression for VoIP streams, a single packet can save up to 39 bytes. Let
SEHC has much larger processing capacity than the current scheme, greatly increasing the upper limit of the number of compressed flows (nearly
Experiment evaluation
In this section, we conducted a series of experiments and simulations to evaluate SEHC focusing on its realizability and scalability. We first describe the operation of SEHC on an actual network. Then some simulation results demonstrate the scalability of SEHC.
System implementation
In order to validate the realizability of SEHC, we carried out experiments in a six-node OpenFlow network. Figure 4 shows the actual experiment topology, in which two hosts are connected through three Open vSwitch switches, and an OpenDaylight Controller is used to manage the network. In each SDN-enabled component, a 32-bit Ubuntu OS version 12.04 is used, running on a dual-core Intel Xeon E5606 CPU @2.13 GHz and 8 GB of RAM memory. We integrated the ROHC library 2.2.0 release into two switches to implement header compression, according to the design in the “Optimized header compression scheme” section. We also developed the controller algorithm of SEHC on the application plane and rebuilt OpenDaylight to fit it. Furthermore, the MAC address is used as FID because it is unique inside a single domain and it may not be changed in every hop in OpenFlow network.

Experimental topology for realizability verification.
For testing purposes, an ICMP echo request message was sent from host A to host B. Then, we operated the controller to assign a CID and instruct the compressors to compress the message. In this way, the request packets were compressed in compressor A and then decompressed in compressor B, passing through the intermediate switch. We captured packets in the switch and analyzed them using Wireshark, as Figure 5 shows. In Figure 5(a), it can be seen that the size of an uncompressed packet is 74 bytes, including a 14-byte Ethernet protocol header, a 20-byte IP header, and a 40-byte ICMP payload. While in Figure 5(b), the packet size is reduced to 60 bytes and the encapsulation protocol becomes ROHC. The reduction of 14 bytes indicates the effective operation of the header compression modules on the compressors. In addition, only the request packets transported from host A to host B are compressed, while the reply packets remain unchanged. This proves that the controller can control the compression process accurately and effectively.

Packets captured in the switch: (a) uncompressed packets and (b) compressed packets.
Scalability evaluation
Processing capacity
The processing capacity is an important index to evaluate the end-to-end header compression scheme, which determines the number of data flows that can be compressed. According to the analysis in the “Benefit analysis” section, SEHC can achieve nearly
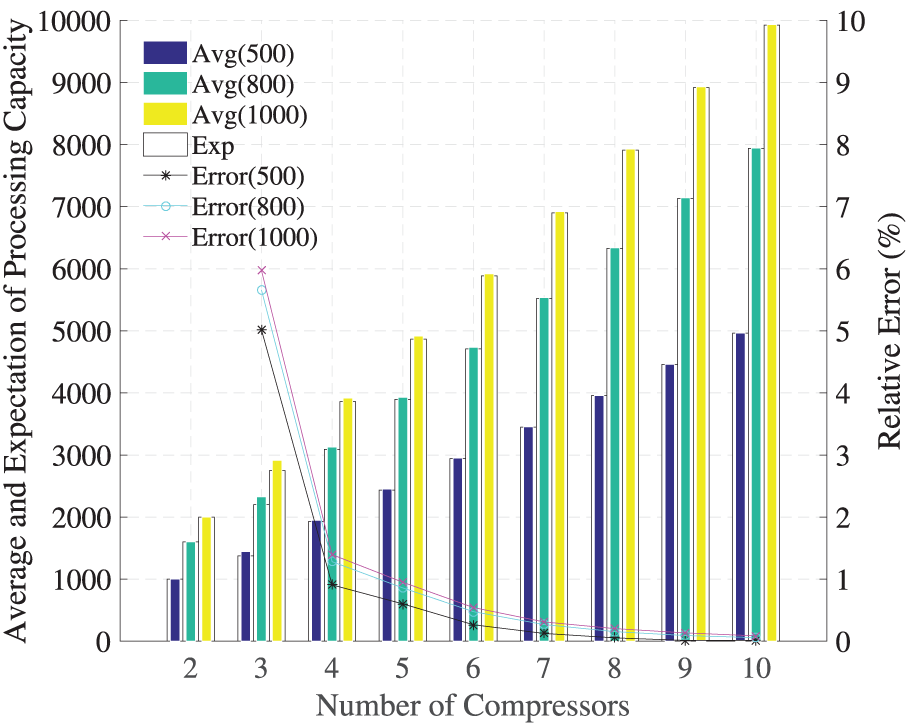
Average and expectation of processing capacity and their relative errors.
The average and expectation of processing capacity are represented by the bar graph in Figure 6. With the increase in the number of compressors and the maximum CID value, the processing capacity is greatly improved. When the number of compressors is 2, the average value is exactly equal to the maximum, that is, twice the maximum CID value. Then, as the number of compressors increases, the average value increases almost linearly and is very close to the upper limit. In addition, the larger the maximum CID value, the faster the average value increases. We calculated the expectation in each condition using equation (16) in the “Benefit analysis” section. It can be observed that the average values are almost equal to the expectations, but slightly higher than the latter.
To get further results, we calculated the relative errors of the average values and expectations, and represented them by the broken line graph in Figure 6. When the number of compressors is 3, the relative error reaches its maximum value. Then, as the number of compressors increases, the relative error decreases rapidly and approaches zero. In addition, the larger the maximum CID value, the larger the relative error. When the maximum CID value is 1000, the relative error is less than 6%, within an acceptable range of tolerance.
These results reflect that SEHC experiences an outstanding improvement in processing capacity, as we estimated. We note that these results can characterize much larger instances, where the number of compressors, maximum CID value, and processing capacity increase accordingly.
Routing scalability
In this article, we evaluated the current scheme and SEHC in simulation scenarios with different network scales. The network scale varies in two ways: the topology size and the number of compressed flows. We studied the recent simulation instance and performed our simulation over a grid-type road network generated by Simulation of Urban Mobility (SUMO). The network spans an area of 2000 × 2000 m2 and includes four vertical roads and four horizontal roads. An SDN controller is deployed in the center of the area and its communication range can cover all vehicles. Vehicles have the same transmission rate of 2 Mbps and communication range of 250 m. Only 10% of the vehicles are equipped with header compression modules and they move circularly on the road. The maximum speed is set to 50 km/h. In each simulation run, a VoIP flow using RTP/UDP/IP encapsulation and G.723.1 codec with a 6.3-kbps rate is generated between a pair of random vehicles. Each packet contains 40 bytes headers and 20 bytes payload. The maximum CID value and flow table space are set to be large enough to support the compression of all data flows.
In scenario 1, we built 10 networks of different scales, with node densities varying from 50 to 500, and 1000 data flows were compressed. Then the statistics of the interactive information produced by the controller and the flow table entries remained in switches are shown in Figures 7 and 8, respectively.
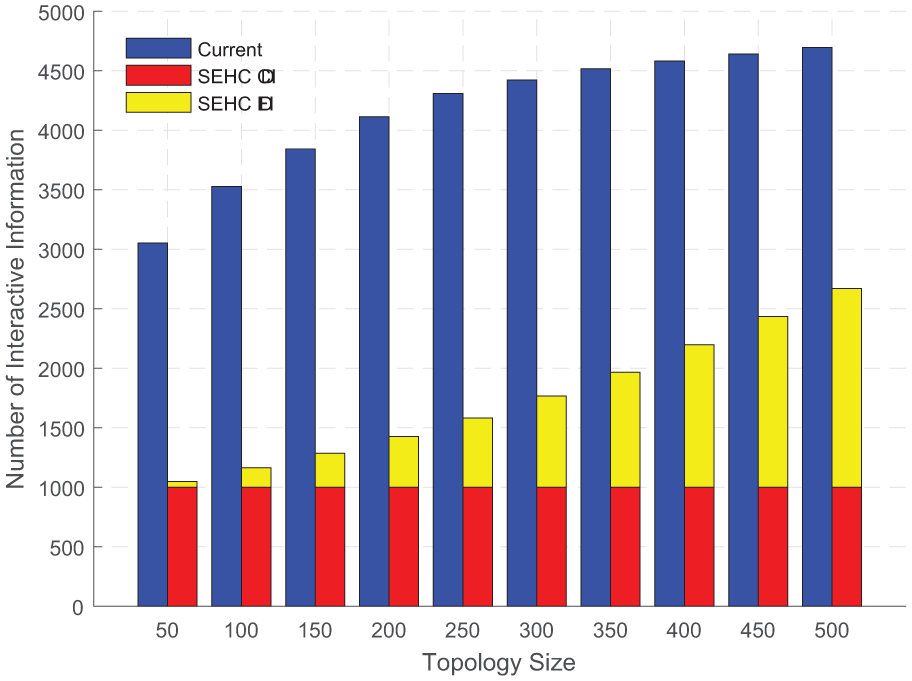
The number of interactive information in networks with increasing topology size.
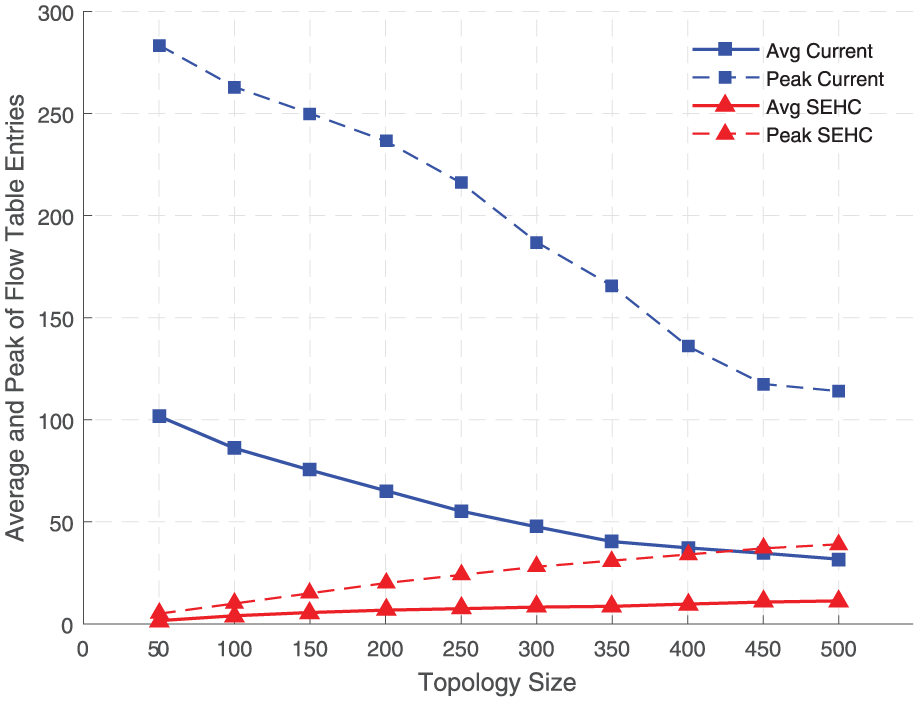
The average and peak value of flow table entries in networks with increasing topology size.
In Figure 7, the number of interactive information generated by the two schemes is both increasing. This is because as the topology size increases, a data flow may travel through more nodes, so the controller would send more flow table entries accordingly. However, SEHC generates far less interactive information than the current scheme. For the current scheme, the number of interactive information increases from 3052 to 4694, growing at a rate similar to that of the average path length. For SEHC, the interactive information consists of two parts: the CID for header compression modules and the FID for forwarding nodes. It can be seen that the number of interactive information about the CID is constant, equal to the number of compressed flows (1000), while the number of interactive information about the FID increases from 48 to 1670. Although the latter is growing at an alarming rate, it tends to be a stable value when the topology size is determined, as shown in the latter part of this article.
From Figure 8, we can get some further results. With the increase in topology size, the average flow table sizes of the two schemes display different trends. For the current scheme, the average flow table size decreases from 101.7 to 31.7 entries. This is because there are more transmission paths in networks with larger topology size; thus, the traffic is evenly distributed among all nodes. However, the peak value of the entries shows that there are still hundreds of entries in some hot nodes. For SEHC, the average flow table size increases from 1.6 to 11.3 entries. There are more FIDs remained in networks with more compressors, but their total number is far less than the result of the current scheme. Furthermore, the peak value of the entries is at most equal to the number of compressors the network owns.
In scenario 2, the network topology size is invariant, consisting of 270 switches and 30 compressors, while the number of compressed flows varies from 200 to 2000. Then the statistics of the interactive information and flow table entries are shown in Figures 9 and 10, respectively.
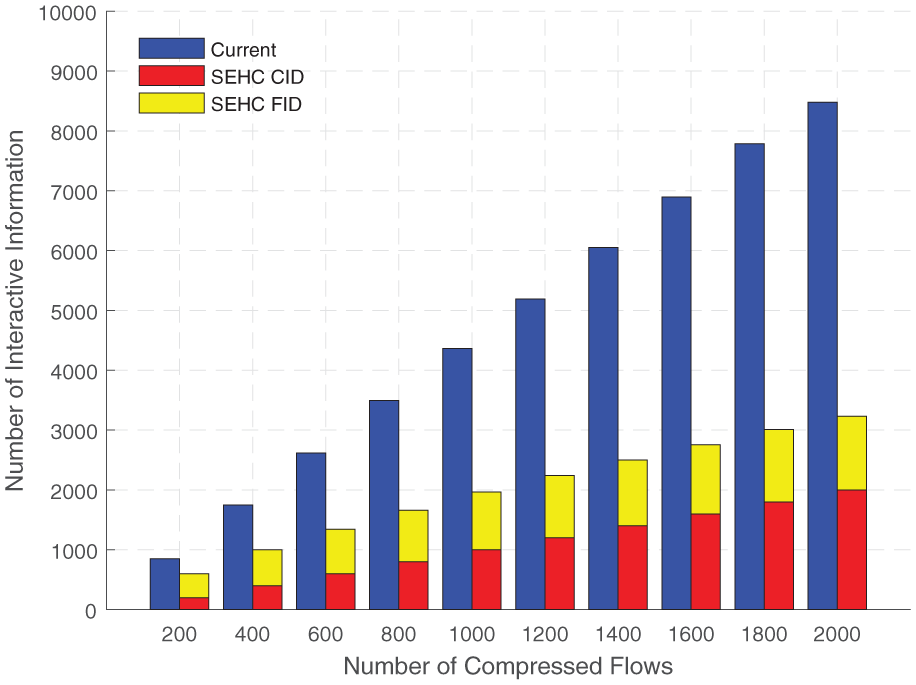
The number of interactive information in networks with increasing compressed flows.

The average and peak value of flow table entries in networks with increasing compressed flows.
From Figure 9, it can be seen that as the number of compressed flows increases, the number of interactive information of the two schemes grows proportionally. For the current scheme, the number of interactive information increases from 852 to 8477, growing at a rate similar to that of the number of compressed flows. For SEHC, the number of interactive information about the CID is equal to the number of compressed flows. While the number of interactive information about the FID only increases from 400 to 1232, its growth rate is decreasing gradually. With a huge difference in their growth rates, the gap between the current scheme and SEHC has doubled and redoubled.
In Figure 10, the average flow table sizes of the current scheme and SEHC are gradually increasing. The average flow table size of the current scheme increases from 10.3 to 88.3 entries, while SEHC increases from 4.8 to 12.8 entries. It should be noted that the growth trend of flow table size is similar to that of the interactive information (for SEHC, it means the interactive information about the FID). This is because the number of compressors in these networks is the same, so the two parameters are mainly affected by the average path length. We also depict the peak value of the entries and the results show that the current scheme suffers a dramatic increase in the flow table size while SEHC keeps it at a very low level (at most 30 entries).
These results demonstrate that SEHC has much better performance than the current scheme in routing scalability.
Performance evaluation
Bandwidth savings
In this section, we present a simulation with the aim of studying the influence of the current scheme and SEHC on bandwidth savings. We used a configuration similar to scenario 2, but limited the maximum CID value to 2000, 3000, and 4000, or the flow table space to 400, 600, and 800 entries. The results in different conditions are represented in Figures 11 and 12.

Bandwidth savings with different maximum CID values.

Bandwidth savings with different flow table space.
From Figure 11, it can be seen that for the current scheme, large bandwidth savings can be obtained when the number of data flows is less than the maximum CID value. Once all CIDs are occupied, subsequent data flows will not be compressed, resulting in a significant decrease in bandwidth savings. In contrast, SEHC has an extremely high-processing capacity under the same conditions, far more than the number of data flows. Thus, the bandwidth savings can be always at a high level.
A similar result is found in Figure 12. When the number of data flows is greater than a certain value, the bandwidth savings are significantly reduced. We found that this value has great relationship with the flow table space of hot nodes. In the current scheme, the flow table space of some hot nodes is exhausted rapidly. Although the data flows are allowed to be compressed, they cannot be transmitted through those nodes. On the contrary, SEHC requires very little flow table space, guaranteeing the transmission of all compressed flows.
The larger processing capacity enables the network to compress more data flows, and the better scalability ensures the transmission of compressed flows. Having both advantages simultaneously brings great benefit to the application of end-to-end header compression in vehicular networks, improving the bandwidth utilization effectively.
Transmission delay
In this section, we observed the performance of SEHC and hop-by-hop header compression in terms of transmission delay. A string topology is used to simulate a multi-hop environment, in which the distance between vehicles is 100 m and each vehicle can only communicate directly with its neighbors. Then the voice traffic was transmitted over the network with various hops. Simulations without header compression were also carried out in order to provide a comparative analysis. The end-to-end delay for the three cases is shown in Figure 13.

End-to-end delay for traffic over different hops.
It can be seen that the end-to-end delay increases as the number of hops increases. The uncompressed case shows the highest value for delay, while there is an average of 16% reduction in delay when header compression is implemented. The primary reason for this is that the high compression gain reduces the packet size, thus reducing the time spent to send the packet through the channel. When only one hop exists, SEHC and hop-by-hop case have the same delay. When the number of hops is more than one, SEHC shows lower delay values than hop-by-hop case, that is, due to the increased processing delay when performing the compression–decompression cycle at each node for hop-by-hop case. Following this reasoning, we could say that our SEHC should show a better reduction in delay as the number of hops increases.
Conclusion
In order to improve the bandwidth utilization for mobile services, some researchers have proposed to implement end-to-end header compression. In this article, we first highlight that the current scheme cannot be successfully deployed in vehicular networks, due to the limitations on processing capacity and routing scalability. Then based on the careful study of existing work, we propose an SEHC. We utilize a FID to indicate the compressor’s location, separating the header compression process from the packet forwarding process. In this way, CIDs with an identical value can coexist in the same network, and flow table entries matching the compressed flows can be aggregated. We detail the system model of SEHC and analyze its performance in comparison with the current scheme. Some experiments have been performed, and the results show that SEHC has outstanding performance in bandwidth utilization and delay, showing its greater suitability for vehicular network transmission optimization.
Footnotes
Acknowledgements
A preliminary version of this paper, focusing on the initial construction of the compression scheme in wireless networks, appears in the Proceedings of the Australasian Computer Science Week Multiconference (ACSW 2017). This version describes the detailed design and implementation of our scheme in vehicular networks, and performs a lot of new tests to prove its effectiveness.
Handling Editor: Razi Iqbal
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Fundamental Research Funds for the Central Universities (Grant no. 2017YJS031) and the Beijing Municipal Natural Science Foundation of China (Grant no. 4182048).