
Abstract
The cooperative simultaneous localization and mapping problem has acquired growing attention over the years. Even though mapping of very large environments is theoretically quicker than a single robot simultaneous localization and mapping, it has several additional challenges such as the map alignment and the merging processes, network latency, administering various coordinate systems and assuring synchronized and updated data from all robots and also it demands massive computation. This article proposes an efficient architecture for cloud-based cooperative simultaneous localization and mapping to parallelize its complex steps via the multiprocessor (computing nodes) and free the robots from all of the computation efforts. Furthermore, this work improves the map alignment part using hybrid combination strategies, random sample consensus, and inter-robot observations to exploit fully their advantages. The results show that the proposed approach increases mapping performance with less response time.
Introduction
Nowadays, cooperative multi-robot systems (CMRSs) 1 play an important role in implementing complex tasks such as mapping, exploration, rescue, and search operations. Constructing a team of simple robots may be faster and more reliable than a single complex robot system. There are many challenges in the field of multi-agent systems: communication techniques, decision-making, a planning mechanism, and integration of partial maps from the different robots (combining the information gathered by multiple robots). One of the major requirements for achieving completely autonomous mobile robots in an unknown environment is to implement simultaneous localization and mapping (SLAM), 2 which enables the robots to build a map of their surroundings and, at the same time, localize themselves in it. Mobile robots can cooperate with each other to solve the SLAM problem—known as cooperative SLAM. This article focuses on the issues of cooperative SLAM, particularly the map-merging part.
Map merging is critical for maximizing efficiency and accuracy of the multi-robot SLAM, which has been receiving further attention in the literature. Every robot builds a local map of its surrounding, but the important question is how to combine these local maps into a single global one. The merging process demands calculation of a transformation matrix for converting all the local maps to the same global reference frame—referred to as map alignment. There are several approaches to align the different maps such as data association and inter-robot observation methods. Nossair et al. 3 shows that these methods do not work efficiently; therefore, they have the constraints in cases of different states of merging process. As a result, this article proposes an innovative approach for performing cooperative SLAM, maximizing efficiency of the mapping, and minimizing the costs. Therefore, according to the case of current merging, the algorithm decides if either of the two methods (data association or inter-robot observations) is more robust to execute alignment tasks. Due to a massive exchange of data between the robots, which requires increasing processing, the traditional processing may no longer be practical (effective). As a consequence, this article proposes to distribute all of the computation load of cooperative SLAM to systems running in the cloud 4 —called CCSLAM. The addition of this technology provides further reduction of the execution time of tasks of multi-robots with low cost by parallelizing the intensive computations via the cloud-computing servers.
The structure of this article is organized as follows. Section “Related work” discusses an overview of related work. Section “Background” discusses the two alignment methods. In section “Proposed method—cooperative SLAM as service in the cloud,” the proposed method is described in detail. Experimental results are presented in section “Experimental results,” which demonstrates the efficiency and accuracy of the presented approach. The last section concludes this article.
Related work
Cooperative SLAM is one of the most researched subjects in the robotics field. Waniek et al. 5 used the particle filter algorithm 6 for cooperatively solving the SLAM problem by two small mobile robots via only one remote computer. However, their works do not show one of the biggest challenges of multi-robot SLAM, that is, combining the information collected by multiple robots. Yan et al. 7 proposes issues of multiple mobile robot systems (MMRSs) such as communication technique, a planning mechanism, and a decision structure. Benavidez et al. 8 implement the visual simultaneous localization and mapping (VSLAM) algorithm for single robot running in the cloud-distributed processing, thus this algorithm is divided into two stages. The first stage is to make a landmark database. The second stage is to utilize the landmark database to determine the pose of the robot. Kamburugamuve et al. 9 implements a particle filtering–based SLAM algorithm using the Internet of things (IoT) Cloud framework. 10
Arumugam et al. 11 proposed a cloud framework called Distributed Agents with Collective Intelligence (DAvinCi). Thus, Hadoop framework is used, which consists eight Intel quad-core server nodes for service robots in large environments. Riazuelo et al. 12 present a real-time performance of cooperative SLAM using two RGBD cameras via a two-nodes cloud. Thus, the mobile robots can build their local maps and integrate them together. If an overlap is detected, then the duplicated points between these maps are deleted. The contribution of the proposed approach is that it allows the combination of the partial landmark-based maps in multi-robot systems according to the state of the environment until the case of disjoint partial maps. In addition, the incoming map of the other robot is merged simultaneously with another map. If the landmarks are previously observed, the other robot’s estimation is considered as evidence of the best map merging with lowest amount of error.
Mohanarajah et al. 13 present a platform for cooperative building and map-merging processes from two robots via the cloud framework. The merging task is executed using the random sample consensus (RANSAC) algorithm while the matching key-frames of the two maps are found. After map merging, the robots are re-localized in the updated map. The essential contributions of this article are as follows:
A novel solution of cooperative SLAM based on hybrid integration of two map alignment techniques to merge the local maps with highest quality and efficiency.
Parallel mapping and merging mechanism are implemented via multiple nodes.
Multi Map/Reduce jobs are used to build large environments by four inexpensive robots as a service in the proposed cloud platform; the robots are freed from all intensive computational processes.
Background
In order to create a global map from the partial maps, the first step is a calculation of the coordinate transformation for a pair of the correspondence points for one reference frame, which consists of three alignment parameters: translation in


Alignment using RANSAC
RANSAC is one of the most common approaches to align landmark-based maps using data association, which depends on creating a list of possible matches between the landmarks of the partial map and their correspondences in another partial map. The two pairs of correspondences are used to compute the alignment parameters (




Alignment using robot–robot observation
This method depends on exchanging the necessary information between the robots for merging their partial maps. It does not rely on the overlap between their local map. It instead relies on the rendezvous case to measure the relative positions of two robots. One of the robots sends this information, which includes its local map, its position, and its observation (
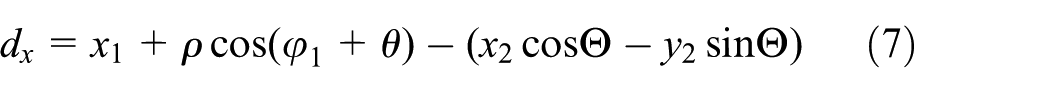
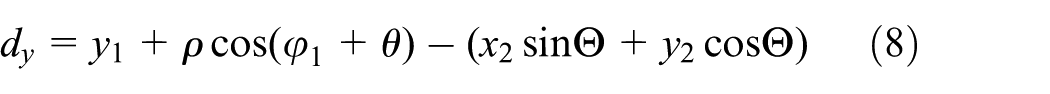

where
Map merging
As mentioned previously, the map fusion is performed in two phases: map alignment and map merging. After converting each entity in the incoming partial map by applying the transformation matrix as in equation (2), the second phase starts to merge one of the partial maps into a single global map. The Euclidean distance is used to detect the corresponding landmarks; thus if the landmark is a new one, it is simply added to the global map, and if it is known, evaluation of the other robot is used as the best prediction for a position of the landmark. The common landmarks for the other robot are integrated as follows


where
Hadoop Map/Reduce
Developers face several problems while running their applications, such as heavy input data and complex computations. To solve these issues, an automatic parallelization and distribution of computations across hundreds and thousands of CPUs is required, which is achieved by Map/Reduce programming model. Hadoop Map/Reduce is a software framework, which allows programmers to exploit huge amounts of resources easily for distributing and processing computational tasks in parallel on a large number of computing clusters. Map/Reduce model provides multiple functions—Map and Reduce—to process the big data by several nodes at the same time to increase execution speed. The Map/Reduce is widespread because it is very easy and straightforward to execute.
Figure 1 shows how Map/Reduce operations are actually carried out in Hadoop.19,20 While the client writes a program to make a job, the JobClient will transmit a request to the JobTracker to get a JobID. The JobClient will store the configuration files and JAR files—containing a description of the job—to the Hadoop distributed file system (HDFS). According to the job scheduler, JobTracker can manage several requests in a queue. The JobTracker restores the input data from HDFS to determine the number of the Map tasks. The Reduce tasks are decided by the parameters of the configuration files. The Mapping and Reducing refers to the functional programming languages. The TaskTracker will make a new TaskRunner for executing the Map task and then, the TaskRunner run the map() function inside a Java virtual machine (JVM). While all the Map tasks have been finished, the JobTracker will tell a certain Reduce TaskTracker to implement the reduce() function in other JVMs after downloading the output results from the Map TaskTracker. The Map task picks the input data and generates a set of intermediate (key, value) pairs, which are sorted and partitioned. Then, reducers take the output of the map to produce the final results and will send them to the HDFS. One of the important features of the Map/Reduce model is that the computational process is permanently transported to nodes, which have data.

Overview of the Map/Reduce operations. 19
The main goal of Hadoop is to process massive amount of data sets by splitting these data into smaller chunks. HDFS breaks down huge files into large blocks with size of 16–128 megabyte (MB) optimal for the tasks. Hadoop uses a logical representation of the data—named as input splits. Input split is a part of the input processed by an individual map task. The number of splits determines the number of mappers. The split size can be calculated by three parameters of Hadoop properties: mapred.min.split.size, mapred.max.split.size, and dfs.block.size as shown in the formula: Input Split Size= max(minimum Size, min(maximum Size, block Size)).
Figure 2 presents an example to show how the task deals with the data as key/value pairs. 20 Each map task receives data according to the split size. There are three map tasks that classify the data as odd and even numbers, then each map task sends the results to a certain reduce task based on its key.

Map/Reduce example for categorizing a set of numbers as even or odd. 19
Proposed method—cooperative SLAM as service in the cloud
Nossair et al., 3 performed three experiments to evaluate the two alignment strategies (data association and inter-robot observations) under different conditions such as a number of overlaps between the partial maps and an effect of the noise. The results of these experiments proved that the data association method does not efficiently work in case of disjoint maps.
Using the relative distance measure between robots avoids this problem; thus, the estimation of coordinate transformation depends on the pose of robot and the performed observation only and not on correspondences between landmarks. Therefore, the inter-robot observations method is used in case of small degree of the overlap, and the data association method is used in case of large noise. As a result, robots can travel in any environment and merge their partial maps with the highest quality. The leader robot has the two alignment methods (data association and inter-robot observations), and after receiving the information from the follower robots, it begins to check the degree of overlap between their partial maps using landmark’s signature and then decides which of the two methods is currently more appropriate for calculating the coordinate transformation between the robot reference frames. The selection between the two methods is illustrated in Figure 3. Results of these experiments prove that if the number of overlap landmarks between the two partial maps is greater than a certain threshold (
Selecting one of the alignment methods.
This article proposes an improved map alignment method for obtaining on an accurate merging of the partial maps. In addition, the proposed architecture exploits the parallel processing via the cloud to reduce the merging time with high accuracy and quality in any conditions of the very large environments.
The proposed method is spilt into two Hadoop jobs. First, the local maps are created by each robot. Second, the global maps are generated by choosing the suitable alignment method depending on the degree of overlap between the partial maps to merge them accurately. There are different approaches (several choices) for launching multiple Map/Reduce jobs, 21 such as Apache Oozie, JobControl object, and job chaining, which rely on using the output of one as the input to the next, meaning the last reduce output will be used as input for the next map job.
In Figure 4, the first job consists of 400 map tasks. Each robot executes 100 map tasks using the FastSLAM 2.0 algorithm to build its local map using 100 particles. Then, four reduce tasks are used to choose the local map of each robot, which has the highest importance weight. The result of this job produces four local maps. The second job checks the degree of overlapping between each local map and the local map of the master robot to choose one of alignment methods, as a result, there are three map tasks and one reduce task to generate the single global map.

Implementation of cooperative SLAM in Map/Reduce framework (cooperative SLAM) as service in the cloud.
Experimental results
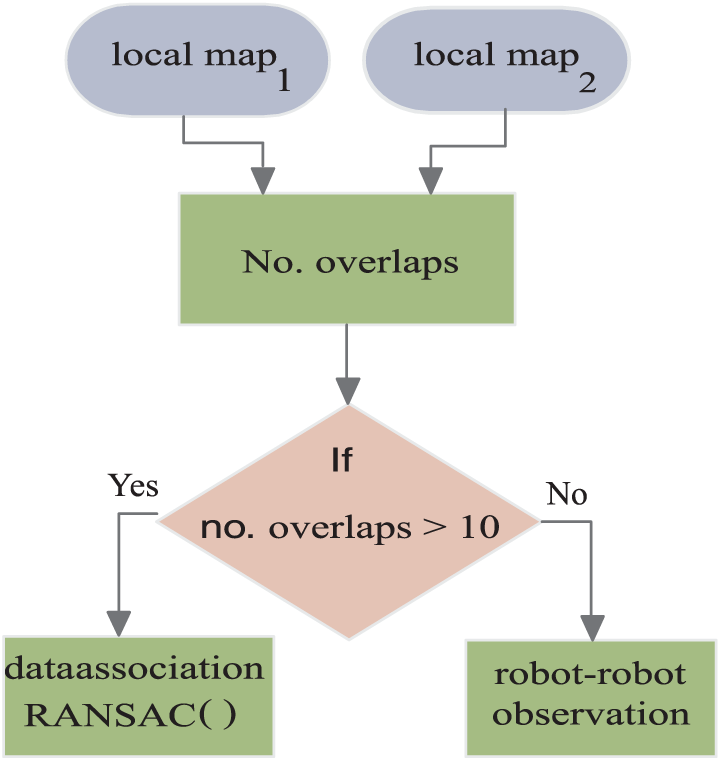
In this section, the experiment is presented to evaluate the proposed approach on two different grid map dimensions (100 × 100 and 300 × 300) as shown in Figure 5. The algorithm is implemented by using a single-node, three-nodes, and finally eight-nodes Hadoop cluster by four robots and a single robot. The proposed algorithm is written as multiple pass Map/Reduce tasks using C++ language and is run on nodes that are dual-core server at 7.5 GB RAM.
The global maps with dimensions (a) 100 × 100, (b) 100 x 100, and (c) 300 × 300.
As shown in Figure 6, the results show that the computation time of the proposed approach by the four robots is reduced 60% compared to its execution on a single-robot platform using a single PC. When the robot—single or four—requests the SLAM service from the cloud, the execution time further reduces. It can be noticed that in small environments (100 × 100) and with increasing number of VM, the computational cost for the single robot and four robots is nearly equal; as a result, the cloud saves number of the devices—used robots—for performing any tasks. In case of very large environments (300 × 300), the four robots execute cooperative SLAM as service cloud with 94.8% reduced computation time using an eight node Hadoop cluster only. The presented method maps a large area with lower computational time and higher accuracy than the onboard system of a robot.

Execution time of FastSLAM 2.0 in Hadoop versus number of nodes by four robots and single robot: (a) grid dimensions: 100 × 100 and (b) grid dimensions: 300 × 300.
Conclusion
This article presented a novel approach for distributing cooperative SLAM, where the map building and the merging tasks are run outside the robot—the cloud. Each robot only collects its sensor information, then sends it to a remote server. A direct consequence is that the robots are freed from all computational load. In addition, the presented work proposed an improved method for map alignment. The system can decide which of the two alignment methods (data association method and inter robot–robot observations) is currently more appropriate for calculating coordinate transformation between the robot reference frames. The results show that the proposed technique enhances creation of the global map for very large environments from a group of the robots in a reasonable time with higher quality and efficiency.
Footnotes
Handling Editor: Antonio Puliafito
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.