
Abstract
Intelligent automated crane systems are now an integral part of container port automation. Accurate corner casting detection boosts the performance of an automated crane system which ultimately automates ships loading and unloading. Existing techniques use various traditional laser-based and vision-based methods for corner casting detection. Challenging weather conditions, varying lighting conditions, light reflections from ground, and container rusting conditions are the main problems that affect the performance of automated cranes. From this line of research, we propose an end-to-end method that takes a low-quality video input and produces bounding boxes around corner castings by applying a recurrent neural network along with long short-term memory units. The expressive image features from GoogLeNet are used to produce intermediate image representations that are further tuned for our system. The proposed system uses back-propagation to allow joint tuning of all components. At least, four cameras are mounted on each crane and input stream is combined into a single image to reduce the computational cost. The proposed system outperforms all existing methods in terms of precision, recall, and F-measure. The proposed method is implemented in a real-time port and produces more than 98% accuracy in all conditions.
Keywords
Introduction
The last decade has seen a great rise in import–export in the shipping market. Large ports throughout the world are facing the container throughput capacity problem. To handle this uprising increase in freight volume, intelligent automation of cranes is a vital step. In recent years, automated container ports have become an important factor in port construction all over the world. Port cranes being vital engineering machines require complete automation and intelligence. Many researchers and engineers have elaborated different ways to attain automated and flexible guidance for port cranes. Therefore, automation container terminals are becoming key projects worldwide.1–4
Previously, an automated terminal crane equipment’s self-direction function was controlled by the encoder. This approach may not be potent enough as compared to the directing method of machine vision. In recent years, the machine vision system has been an effective way to materialize automation.5–7 Therefore, computer vision–based automated guide port cranes for loading and unloading containers are the most common ways. Earlier, laser vision systems were used for port automation. For automated ship loader in Luojing Bulk Port in Shanghai, Zhaoji 8 used a laser measurement system (LMS) as the key vision measurement system. Mi et al.9,10 went through point cloud images generated by LMS for ships and later on designed much faster algorithms which recognized and positioned the ship cargo holds. World’s biggest port crane manufacturers have also developed an automated container position system based on laser vision. 5 Although laser vision systems are efficient and easy to use, they come with certain disadvantages that cause inefficiency to this system. During a scanning cycle, laser vision systems can only scan one plane of the target and due to this reason these systems should be connected with servomechanisms for implementing multi-plane scanning. 5 A laser vision system may be inefficient if it scans the whole target because the servo mechanism is time-consuming. Advancements in computer hardware encouraged many researchers to use image vision systems to position and recognize targets. Image vision–based systems were initially used to recognize symbols written on containers. Wu et al. 3 and some other researchers utilized image vision to recognize the container codes. 4 Due to some encouraging results, a lot of researchers and engineers used image vision solutions to meet the requirements of automated ports. Using image processing, some researchers resolved port personnel safety problems.9,11 Shapira et al. 12 and Yang et al. 13 studied the improvements of crane automation operations using image vision systems. Some researchers are focusing on the auxiliary functionalities of cranes like personal safety and operation tracking, while others pay attention to crane automation systems. Using image vision, Kim et al. 14 and some researchers developed an anti-sway control technique. 15 An image processing–based automated landing system was implemented by Park et al. 7 for container cranes. Big targets like container trucks and spreaders are tracked by these image vision systems. However, using vision systems, the problem of quick tracking and positioning the small and key targets remains a difficult task to be implemented. By making use of image vision, Yoon et al. 16 tracked and positioned the hanging holes of containers. According to this method, the edges of the container are supposed to be recognized first and, after that, holes at the corners can be positioned. Therefore, this technique does not directly recognize and position small hanging holes. For automated container ports, recognition of containers’ accessory devices is mandatory in automated cranes. Corner casting detection is an important accessory information that should be efficiently detected to calculate the positions of other accessory devices. Therefore, corner casting detection remains an open research area due to the difficulty to recognize small accessory information like corner castings, different weather conditions, and poor container conditions.
In this article, we have proposed a deep convolutional neural network (CNN)-based highly efficient and accurate solution to detect corner castings for automated unmanned cranes, where each crane is mounted with four cameras. The video stream is combined into a single image which leads to robust and efficient corner casting detection. In order to evaluate the effectiveness of the proposed system, we collected data in four challenging conditions: dawn, night, rainy, and sunset. We used more than a million images for training collected under different conditions and testing is done on more than 3 million images, and currently this system has developed and worked 24/7 perfectly with each crane streaming four live cameras. The proposed system produces more than 98% accuracy in real-time scenarios. This article has the following contributions:
A deep learning–based fully automated corner casting detection system is proposed to efficiently handle loading and unloading at ports;
The proposed method efficiently handles different challenging weather and lighting conditions to detect corner castings accurately;
The proposed system converts streams from four cameras into one image and then reduces the computational cost to make it suitable for real-time scenarios.
The rest of the article is organized as follows: section “The proposed model” presents the methodology, section “Experiments and results” explains the experimental setup and results followed by the conclusion and future work.
The proposed model
In this work, we have used a CNN to detect corner castings. CNNs comprise multiple layers of pooling, convolutions, dense, dropout, and so on. These layers are the main components of a convolutional network which are stacked over one in a hierarchical way. This data structure forms the feature maps. These feature maps are taken as an input by each layer from the preceding one except the first convolutional layer which is connected directly, while the convolutional layer creates a number of feature maps as the output. CNN is able to learn a complex set of features by generating a system of feature maps making them useful and robust in pattern recognition in images.
Connection weights along with kernels are learned using back-propagation. In the back-propagation model, input images are passed through the network and the predictions made are compared with the output labels. Updating these weights starts from the last layer moving toward the first layer and the input. CNN generates a translation-invariant feature map so the same feature is detected for the whole data by a single kernel in a convolution layer. CNN generates translation-invariant feature maps and thus the same feature is detected for the whole data are calculated using the single kernel from the convolution layer. The neural network learns features directly from images rather than using feature vector as used by traditional classifiers. Neural network kernels can be designed for different sizes like 3 × 3, 5 × 5, 7 × 7, and so on. The underlying information is considered in order to vary the size of the kernel. The kernels in the convolution layer noticeably share quite a resemblance with the edge detectors learning various features according to properties of training data.
Deep convolutional architectures for the formation of image representations are extremely beneficial for various tasks. Deep representations can jointly encode the occurrence of multiple objects. However, in order to recognize this prospect, components must be augmented for various instance prediction. In this research article, these components are designed using recurrent neural networks (RNNs) and long short-term memory (LSTM) units.17,18 The following properties make the combination of RNN-based decoders with deep CNNs more captivating: (1) the ability to use the powerful deep convolution representation and (2) to generate the coherent sets of variable length predictions. The generation of coherent sets is highly beneficial in our case due to its ability to preserve already-produced predictions.
A convolutional architecture converts an image into high-level descriptors which are then decoded into bounded boxes. We design recurring LSTM units and consider it as the core machinery that predicts variable length output. All images are converted to a 1024-dimensional feature vector in stridden regions of the whole image. Contents of the region are summarized by the 1024-dimensional vector which also holds rich information about object positioning. The LSTM serves as a controller and extracts information from the source images to pass the information during the decoding steps. The LSTM generates a new bounding box after each decoding step along with the confidence of the previously missed corner castings at that location.
This procedure takes place in iterations and boxes are more likely to be produced in the descending confidence order. A stop signal is generated when LSTM cannot find a new box, the confidence level of which is higher than the defined threshold. Collection of a sequence of outputs is taken place and then given out as ultimate description of collective instances belonging to the specific area. The proposed methodology is shown in Figure 1. This figure explains how images are input to the CNN and then training and testing are carried out. The flow diagram of the proposed system is shown in Figure 2. For real-time testing, Live555 is used which is a set of open source C++ libraries developed by Live Networks, Inc. for multimedia streaming.

The designed architecture of the corner cost detection system.

The flow of activities for an end to end corner cost detection system.
Implementation details
We designed our model in a way that it can perform encoding of the image into a 15 × 20 grid of 1024-dimensional top-level GoogLeNet features. There is a receptive field of size 139 × 139 for every grid cell. Each cell is trained for generating a set of distinct bounding boxes in the center 64 × 64 region. The 64 × 64 size was kept considerably substantial so that stiff local occlusion interactions could be captured easily. The larger regions can also be used but provide less information here. In parallel, 300 distinct LSTM controllers perform, one for each 1 × 1 × 1024 cell of the grid. Our LSTM units consist of 250 memory states with no output nonlinearities and no bias terms. Concatenation of GoogLeNet features with the output of the foregoing LSTM unit is done at every step. The result is stored in the next upcoming LSTM unit. We claim similar results by feeding the image into the first LSTM unit which shows that numerous presentations of the image might be unnecessary. A systemized batch of decoding operation can be obtained by generating each region of full 480 × 640 images in parallel. A detailed structure is shown in Figure 3. In the learning period, our model must be capable enough of learning how to regress on bounding box locations through the LSTM decoder. While training takes place, the decoder outputs an over-complete set of bounding boxes. Each of these boxes is presented with its corresponding confidence. The cardinality is set to a fixed value to maintain the batching efficiency and ease of use for any number of ground truth boxes. In this way, LSTM is trained in such a way to generate high confidence values and correct localization for all boxes corresponding to ground truth while keeping low scores elsewhere. The system learns from experience and produces high confidence.

Structure of the deep learning module of the corner cost detection system.
Using the bipartite matching function after sequence generation, ground truth instances are matched to predictions. It favors candidates that are output earlier and closer to the ground truth targets. We also back-propagate the Hungarian loss described in its equation through the full network by optimal matching.
Experiments and results
Dataset
There is no large-scale diverse public dataset available for corner casting for a crane automation system. In this study, we have collected data from four live cameras mounted on three types of cranes: rail-mounted quayside crane (RMQC), rail-mounted gantry crane (RMGC), and rubber-tired gantry crane (RTGC). Total unit numbers of the digital port crane were around 50 with 38 units of advanced unmanned automated RMGCs in Busan New Port Phase 2-2, and other overseas terminals such as Pasir Panjang Terminal in PSA Singapore. The camera used for data collection is AXIS P5414-E.
As the main aim of this study is to develop an efficient real-time corner casting system that can handle different challenging lighting and weather conditions, we collected data in different challenging conditions: dawn, night, rainy, sunset, and snow. These conditions make it difficult to detect corner holes efficiently. There are some other factors that cause difficulties to detect corners like poor container conditions, different light conditions, and light reflection from the ground. Some of the sample images were extracted from dataset videos. The sample images for each condition are shown in Figure 4.

The sample images for four different weather conditions including day, night, rainy, and sunset (one sample image for each condition is taken from rain).
Evaluation metrics
The performance of the proposed deep learning–based corner detection system is evaluated using precision, recall, and F-measure.19–25 To calculate these evaluation metrics, these images are manually labeled as the corners of container holes (refer to Table 1).
Confusion matrix.

Here each row represents actual class and each column represents predicted class.
Precision is the most widely used performance evaluation measure for image segmentation and classification systems. Precision can be defined as the probability that the identified corners of the container are relevant.24,26 It shows the specificity of the corner casting system and can be mathematically defined by equation (1)

where

where

Comparison with the baseline systems
We have randomly divided the data into 80% for the training set and 20% for the testing set. We further used fivefold cross-validation on the training set for parameter learning. To evaluate the performance of our proposed scheme, a comparison is drawn between our algorithms with the previous techniques utilized. These techniques include the models utilizing scale-invariant feature transform (SIFT) and support vector machine (SVM), edge density features and SVM, and saliency-driven normalized cut. Each of the existing models is briefly discussed below.
SIFT and SVM
SIFT is a local feature descriptor algorithm. 27 The algorithm works by extracting key points from reference images that can be used to provide the feature description of an object. An object can be detected and recognized based on the key points in an image. SIFT extracts those key point descriptors that remain detectable under any variation in noise, scale, and illumination. Such feature descriptors are then fed into the SVM, which are classified into their respective classes.
SVM is a supervised learning algorithm well known for binary classification. The classification algorithm works by minimizing the classification error and maximizing the geometric margin separating the two classes. The classifier classifies the feature descriptor points extracted using SIFT by plotting those points over the N-dimensional feature space and finding the right hyperplane to separate the points into two classes. A binary classification map of those data points is obtained in the result.
Edge density feature
Edge density feature is an attribute of an image that determines the magnitude of the edge of an object and is helpful in object detection. 28 The image undergoes the RGB-to-grayscale conversion and the distance between the two adjacent pixels of the image is found. Based on that distance, edges are preserved using edge-preserving operations. The final edge obtained as a result is used to determine edge density through the edge density matrix. The edge density feature extracted is then classified using SVM which binary classifies the feature vector by drawing the hyperplane in the feature space maximizing the intra-class distance.
Saliency-driven normalized cut
Saliency is a perspective based algorithm used to determine the standing out object that is most relevant in the image. 29 It is used to automate the process of understanding the important objects in the image. It works by detecting the most salient regions within the image that results in an overall fast processing when applied to those regions. The significance of regions in an image is determined through a saliency map in which the pixel value in the saliency map represents the saliency degree.
Salient detection can be performed through multiple methods in which normalized cut–based saliency detection considers the dataset as a graph where nodes are the data points and edges represent the weight between the nodes. The saliency detection based on the normalized cut returns the objects that stand out in the image and are segmented based on the saliency map.
Comparison in terms of precision, recall, and F-measure
In our first experiment, we have collected the 20 sample videos collected from real-time cameras mounted on cranes. The input camera streams are merged into a single image for processing. The results for precision, recall, and F-measure for all 20 videos are shown in Figure 5. These videos are recorded during snow, day, night, snow night time, rain, heavy rain, and dawn to cover all real-time challenging weather and lighting conditions. It can be interpreted from the results that the traditional SIFT + SVM method performs worst among all the methods, as this method is based on local features and the aim was to detect the region of interest (ROI) that contains corner castings. This method achieves the best precision of 0.28 for corner casting detection in snow conditions. The average precision of this method for 20 videos is 0.19 which is extremely poor for a real-time scenario. The general trends for recall and F-measure are also the same for this method. The performance in terms of recall is slightly better as compared to precision and F-measure. The average recall and F-measure values are 0.23 and 0.20, respectively, which show its poor performance for this problem.
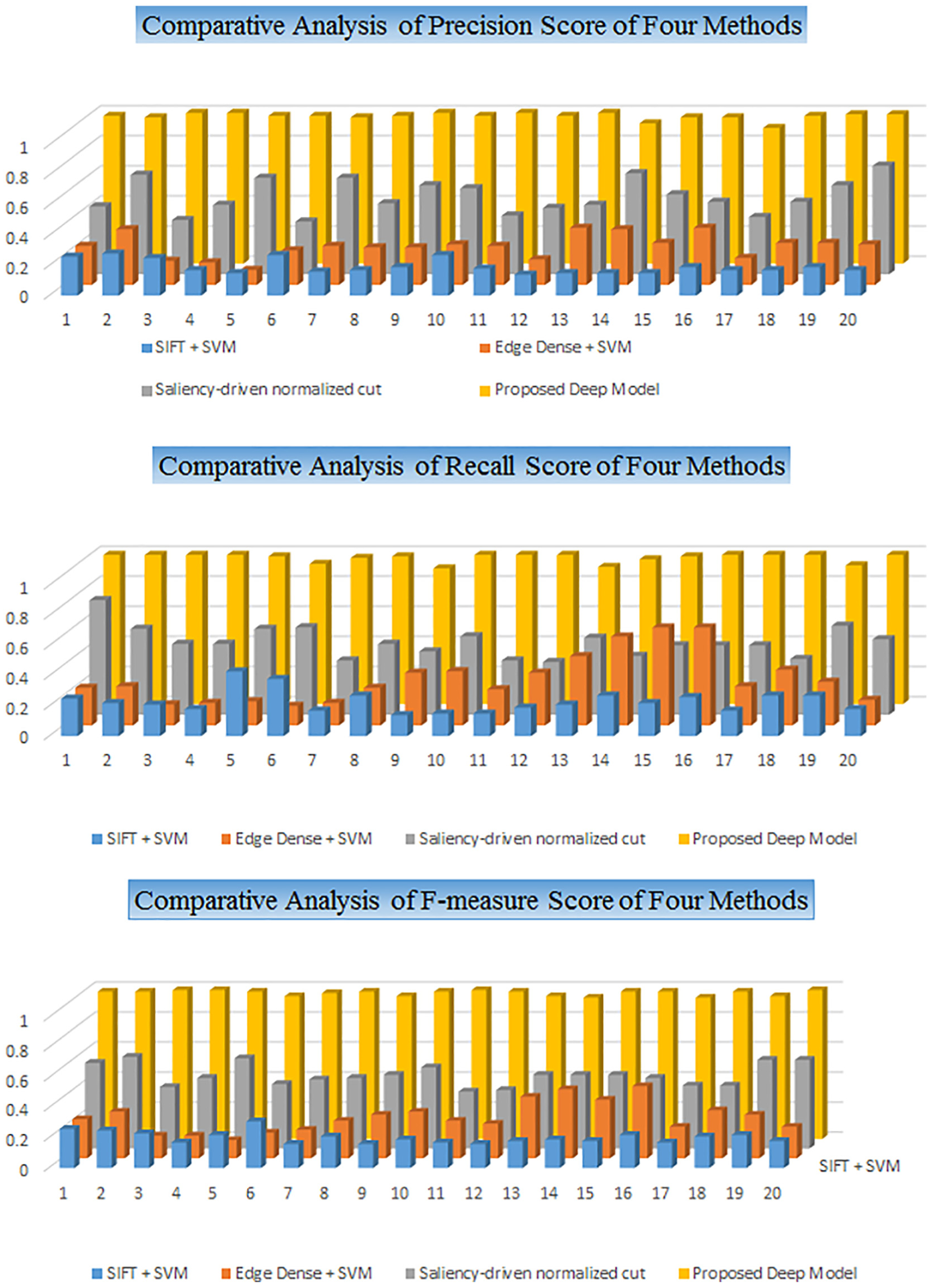
Comparative analysis of the proposed method with three other methods in terms of recall, precision, and F-measure.
In our second experiment, the same dataset for videos is tested using Edge Dense + SVM. This method tries to detect vertical edges and then SVM is used to classify ROI that contains corner castings. It is evident from the results that this method is not an efficient technique. This technique shows almost similar results for all videos. It shows the best precision of 0.38 for a video recorded in rain and 0.37 for a video recorded in the snow.
Surprisingly, the lowest precision is also on a video recorded in the rain which shows the inconsistency of this technique. The performance of all other recorded videos is not good either. The average performance in terms of precision, recall, and F-measure is 0.26, 0.31, and 0.27, respectively. The performance of this method is also not satisfactory for real-time systems.
In our third experiment, the same dataset of 20 videos is tested using the saliency-driven normalized cut method. The performance of this method is much better as compared to two previous traditional methods—SIFT + SVM and Edge Dense + SVM. The performance of the saliency-driven normalized cut performs best for video recorded in the daytime with a precision of 0.72. In general, the performance of all videos is better for every kind of videos. This system also gives the worst performance for a video recorded in the daytime which shows that the real-time scenarios do not guarantee performance improvement in any specific condition. The average performance in terms of precision, recall, and F-measure is 0.52, 0.48, and 0.49, respectively.
In our fourth experiment, we tested the same 20 videos by our proposed deep learning–based algorithm. The performance of our proposed method gives exceptionally well and consistent performance. The least performance of the proposed method is 0.90 for a video recorded in rain. The second least performance in terms of precision is 0.97 for two videos recorded in snow and rain. This lowest precision for this method is still way better than the other traditional methods. The average precision for corner casting identification is mostly 100% for all recorded videos. The same level of performance is observed in terms of recall and F-measure. The system faces some problems only for the videos recorded in rain. This exceptional performance of the proposed system shows that the traditional methods are not sufficient for real-time videos recorded in challenging conditions. Most of the traditional approaches use low-level features and computer vision methods that seem to be insufficient for this problem, while deep learning–based systems prove to detect efficient corner casting detection under challenging conditions. The inconsistencies of results on similar type videos, that is, rain, show that weather conditions are not the only factor affecting the performance of the systems, lighting, condition of containers, and light reflection also play an important role in corner casting detection. The existing systems work well for limited videos to show good performance.
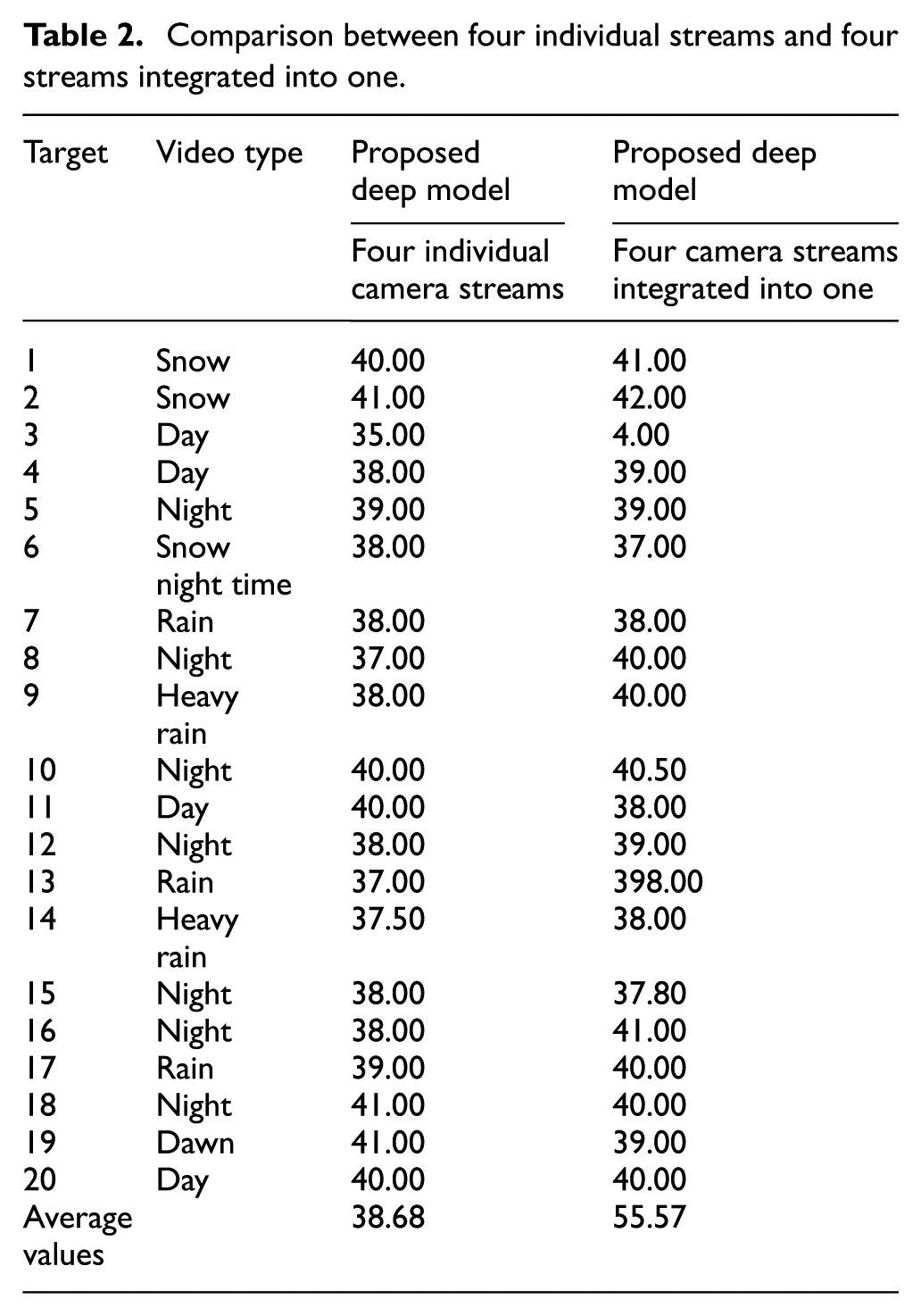
The live streams from four cameras mounted on the crane are combined into a single image. This was done to improve the time required to identify corner castings of the container. The results for the average time per frame for each video are given in Table 2. The average time per frame for all videos is 38.68 and 55.57 ms for four individual streams and four cameras integrated into one video stream, respectively. When four cameras are integrated into one, the computational cost improves a lot.
Comparison between four individual streams and four streams integrated into one.
A comparative analysis carried out between our proposed technique and existing systems is presented in Table 3. Shen et al. 30 proposed a system which used basic image processing techniques for corner casting detection. First, they convert the input image into a binary image and then used morphology operators to separate containers from the background. They used Hough transform to detect corner castings as circles. Their system gives the overall precision of 97.63% on a limited number of images taken from simple conditions. The computational time this system used is 141 ms. This system can only detect simple circles and can face serious issues in tough challenging conditions. The second system we used for comparison is a computer vision–based system. 1 The system is used with histogram of oriented gradients (HOG) features to train SVM classifier.
A comparative analysis between existing systems and the proposed method in terms of dataset, precision, recall, and computational time.

HOG: histogram of oriented gradients; SVM: support vector machine; RNN: recurrent neural network; LSTM: long short-term memory.
They used different techniques to detect the right and left casting corners of the container. The trained SVM classifier was used to detect the right corner and the left corner was detected through symmetry. The precision achieved for this was 94.85% with a computational time of 300 ms for each frame. This system used symmetry-based features that are not suitable to be used in generic and extreme weather conditions, while our proposed system can handle extreme weather conditions. We have tested it over a sample of 20 videos recorded in different weather conditions. The proposed system not only gives excellent precision but also improves the computational time per frame and reduces it to 55.57 ms per frame.
Conclusion
Container port automation heavily relied on intelligent crane automation systems. The performance of the crane automated systems is improved by efficiently detecting corner castings. Existing laser-based and computer vision–based techniques face some limitations, that is, challenging weather conditions, different light conditions, and light reflections from different angles. The proposed system is tested over 20 videos (each spanning more than 24 h) recorded in the field in different weather conditions: snow, day, night, rain, heavy rain, and dawn.
The proposed system detects crane corner with an average accuracy of 98%. Furthermore, it has been compared with the traditional and state-of-the-art methods. The precision values generated by SIFT–SVM, Edge Dense + SVM, and saliency-based normalized cut are 0.19, 0.26, and 0.52, respectively. The recall values generated by SIFT–SVM, Edge Dense + SVM, and saliency-based normalized cut are 0.23, 0.31, and 0.48, respectively. The F-measure values generated by SIFT–SVM, Edge Dense + SVM, and saliency-based normalized cut are 0.20, 0.27, and 0.49, respectively. The results show that our proposed system outperformed these existing techniques.
The proposed system takes input from four camera streams and combines into one integrated stream, and this reduces the computational cost. The cost for an individual input stream is 38.68 ms, while by combining the four streams the average computational cost is 55.57 ms, which is significantly less than the processing cost of the four images. However, this time still creates some delay and hurdles in real-time analysis. In the future, we are planning to use more sophisticated and smart models to further decrease the time complexity of the system. Moreover, we aim to enhance the Live555 streaming module to decrease the video capturing and streaming time.
Footnotes
Acknowledgements
We acknowledge all the support provided by Seoho Electric Company for this research work. This work is the property of Seoho Electric Company and cannot be used in any other replicated form without consent.
Handling Editor: Salvatore Serrano
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Seoho Electric Company.