
Abstract
As a large amount of data streams occur rapidly in many recent applications such as social network service, Internet of Things, and smart factory, sampling techniques have attracted many attentions to handle such data streams efficiently. In this article, we address the performance improvement of binary Bernoulli sampling in the multi-source stream environment. Binary Bernoulli sampling has the n:1 structure where n sites transmit data to 1 coordinator. However, as the number of sites increases or the input stream explosively increases, the binary Bernoulli sampling may cause a severe bottleneck in the coordinator. In addition, bidirectional communication over different networks among the coordinator and sites may incur excessive communication overhead. In this article, we propose a novel distributed processing model of binary Bernoulli sampling to solve these coordinator bottleneck and communication overhead problems. We first present a multiple-coordinator structure to solve the coordinator bottleneck. We then present a new sampling model with an integrated framework and shared memory to alleviate the communication overhead. To verify the effectiveness and scalability of the proposed model, we perform its actual implementation in Apache Storm, a real-time distributed stream processing system. Experimental results show that our Storm-based binary Bernoulli sampling improves performance by up to 1.8 times compared with the legacy method and maintains high performance even when the input stream largely increases. These results indicate that the proposed distributed processing model is an excellent approach that solves the performance degradation problem of binary Bernoulli sampling and verifies its superiority through the actual implementation on Apache Storm.
Keywords
Introduction
Recently, a large volume of data streams are rapidly and continuously generated in many industrial fields such as telecommunication, transportation, social network service (SNS), Internet of Things (IoT), 1 and smart factories. Simply speaking, a data stream is the real-time, continuously generated data.2–4 For real-time processing of such a data stream, it is effective to use a sample that reflects its characteristics well.5–8 Sampling is a method of extracting a part of data representing a population, and representative sampling examples include reservoir sampling, 9 priority sampling, 10 binary Bernoulli sampling, 11 cluster sampling, 12 and stratified sampling. 13 In this article, we focus on improving the performance of binary Bernoulli sampling, which performs sampling in the environment of multiple input sources. More precisely, we deal with the distributed processing of binary Bernoulli sampling in large data stream environments.
A framework for binary Bernoulli sampling consists of several sites and a coordinator. 11 Each site receives a data stream from a data source, determines candidate data that can be selected as a sample, and sends it to the coordinator. The coordinator selects the final sample from the candidate data received from the sites. In binary Bernoulli sampling, however, if the number of sites increases or input data explosively occurs, the coordinator may incur a severe bottleneck due to excessive concentration of candidate data. In addition, since the coordinator and sites performing bidirectional communications can be connected through different networks, the communication process may incur excessive communication overhead. These bottleneck and communication overhead are major causes of poor sampling performance. Please refer to the following Example 1 that describes a real-life scenario explaining the above problems explicitly.
Example 1
An airplane has two Pratt & Whitney’s Geared Turbo Fan (GTF) engines, and each engine has more than 5000 sensors. This engine generates huge data streams of 10 GB/s, and each airline operates hundreds of airplanes per hour. If we apply binary Bernoulli sampling to this environment, GTF engines correspond to source sites, and their data collection server corresponds to a coordinator. When hundreds or thousands of airplanes are in operation, the corresponding hundreds or thousands of sites transmit very huge amount of data streams to the coordinator at the same time, causing the coordinator bottleneck and communication overhead problems mentioned above.
Therefore, in this article, we propose a novel distributed processing model of binary Bernoulli sampling to solve the performance degradation due to coordinator bottleneck and communication overhead. In order to verify the effectiveness and scalability of the proposed model, we implement it in Apache Storm,14–16 a representative distributed processing system.
For the distributed processing of binary Bernoulli sampling, the proposed system architecture satisfies three design philosophies. First, we present a multiple-coordinator structure to solve the coordinator bottleneck problem. When the number of data sources increases or data explosion occurs, it is difficult for one coordinator to process all candidate data. Accordingly, by processing the candidate data in multiple coordinators, we alleviate the coordinator bottleneck problem. Second, we introduce an integrated framework structure in which both site and coordinator functions operate in a single distributed framework so as to reduce the communication overhead. The integrated framework limits most of communications to the inside of the framework, and thus, its communication overhead between the site and the coordinator is much lower than in the conventional structure. Third, we propose a shared memory structure in which multiple coordinators can share sample results and parameters simultaneously. Since we adopt the multiple-coordinator structure in the proposed model, bidirectional communications among coordinators occur in addition to bidirectional communications between the coordinator and the site. The shared memory structure can greatly alleviate the communication overhead between these coordinators. That is, shared memory can be accessed by multiple nodes at the same time, so the communication overhead can be significantly reduced when multiple coordinators are distributed over several nodes. Table 1 summarizes the performance degradation problems of the binary Bernoulli sampling and their solutions.
Performance problems of binary Bernoulli sampling and their corresponding solutions.

In this article, we implement the proposed distributed model of binary Bernoulli sampling on Apache Storm and evaluate its effectiveness and scalability. As a representative distributed processing system, Storm is specialized in data stream processing. For the Storm-based distributed model, we first implement the input data source as Spout, which is an input component of Storm. We next implement the site or the coordinator as Bolt, which is a computing component of Storm. We then integrate these Spouts and Bolts using Topology, which defines the execution procedure of Storm components. As the shared memory structure, we use Redis,17,18 an in-memory database management system (DBMS). Experimental results show that the proposed Storm-based binary Bernoulli sampling improves performance up to 1.8 times higher than the original binary Bernoulli sampling and maintains the high performance even when the input data stream increases.
Contributions of the paper can be summarized as follows. First, through in-depth analysis of binary Bernoulli sampling, we derive coordinator bottleneck and communication overhead problems and their causes. Second, we present three desirable structures, which are multiple-coordinator, integrated framework, and shared memory structures, to solve the coordinator bottleneck and communication overhead problems. Third, we propose a novel distributed processing model of binary Bernoulli sampling by adopting three design structures. Fourth, we implement the proposed distributed model on Apache Storm and verify its practicality by evaluating effectiveness and scalability. Fifth, through experiments on real data, we show that the Storm-based binary Bernoulli sampling is more suitable for large data stream environments than the original binary Bernoulli sampling.
The rest of the paper is organized as follows. Section “Background” describes the related work on binary Bernoulli sampling and Apache Storm. Section “Distributed processing model of binary Bernoulli sampling” proposes the distributed model of binary Bernoulli sampling. Section “Storm-based distributed binary Bernoulli sampling” explains in detail how we implement the proposed model on Apache Storm. Section “Experimental evaluation” presents the results of experimental evaluation. Finally, section “Related work” summarizes and concludes the paper.
Background
Binary Bernoulli sampling
Binary Bernoulli sampling 11 is a representative probability-based sampling algorithm that samples data at the same probability when data streams come from multiple sources. As shown in Figure 1, the general architecture for binary Bernoulli sampling consists of a coordinator and several sites. Binary Bernoulli sampling uses an infinite binary string of 0s and 1s entered together with the data to determine whether we would sample the data or not. We briefly explain its operation procedure as follows. First, each site can locate both inside and outside the sampling server, and it receives a data stream generated from an internal or external data source. Then, the site receives the round from the coordinator, selects the candidate data suitable for the sample in the current round, and sends it to the coordinator. In other words, the site performs the pre-sampling at the front end to reduce the overload of the coordinator. Next, the coordinator selects the actual samples from the candidate samples received from the sites. If the round changes during the sampling, the coordinator sends the changed round to all sites. The coordinator and sites constantly repeat these candidate/sample selection and round change/transmission processes in binary Bernoulli sampling.

An example operation diagram of binary Bernoulli sampling.
As we mentioned earlier, binary Bernoulli sampling suffers from significant performance degradation when the number of sites increases or data explosion occurs. As shown in Figure 1, binary Bernoulli sampling basically has an
Apache Storm
Apache Storm 14 is a real-time distributed processing system that handles stream data rapidly over a number of distributed servers. Figure 2 shows the operating structure of Apache Storm. As shown in the figure, Storm has a master/slave architecture similar to Apache Hadoop.19,20 That is, Storm’s Nimbus and Supervisor correspond to Hadoop’s master and slave, respectively. We also use Apache Zookeeper21,22 to manage metadata of Nimbus and Supervisor. Nimbus assigns and distributes jobs to Supervisors, investigates Supervisors’ working status, and responds to their failures. Each Supervisor performs the job assigned by Nimbus and reports its status to Nimbus. This communication between Nimbus and Supervisor is done by recording the corresponding metadata in Zookeeper.

Operating structure of Apache Storm.
To process a given work, Storm uses three components: Topology, Spout, and Bolt. First, a Topology is a distributed operation structure of Storm, and it represents one data processing logic. A Topology consists of one or more Spouts, one or more Bolts, input streams, and output devices. Second, a Spout takes the data from the streaming sources, converts the data to tuples, 22 the data type used by Storm, and passes the tuples to Bolts. Third, a Bolt processes the tuples received from Spouts or other Bolts and delivers them to the next Bolts, or sends the results to the output or storage devices. Figure 3 shows an example of Storm Topology.
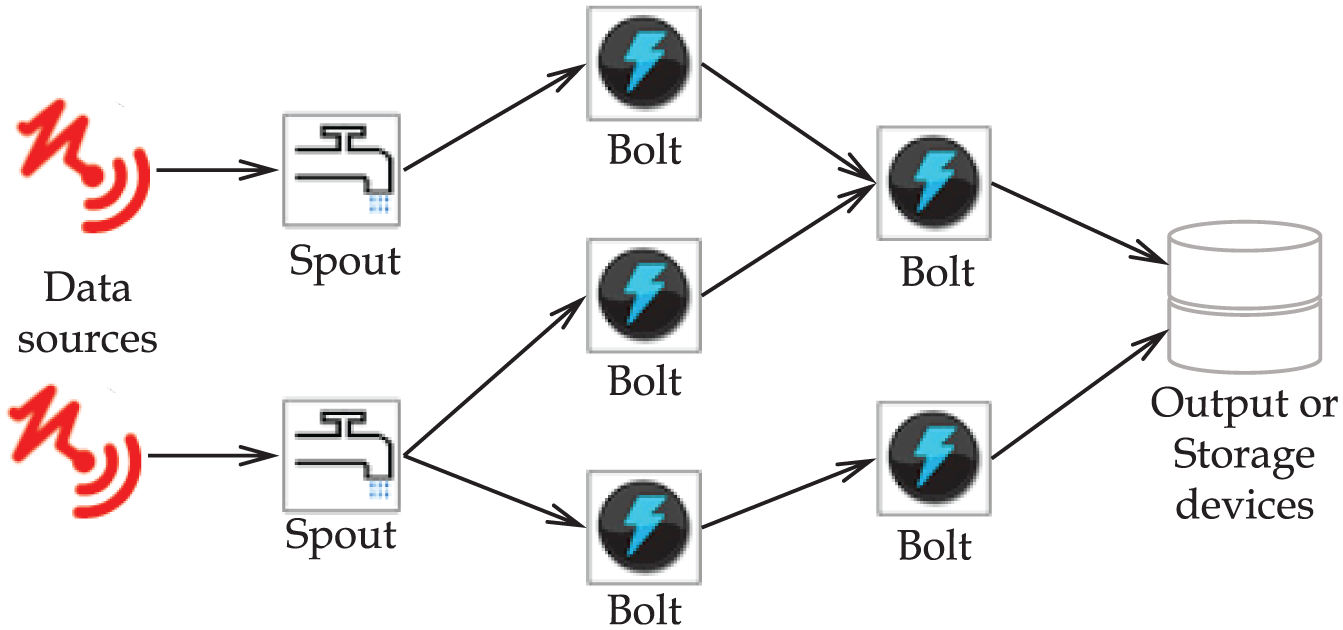
An example configuration of Storm Topology.
An important advantage of Storm is parallelism. That is, we can run Spouts or Bolts performing the same operation in parallel on different servers at the same time. The parallelism of Storm is managed by a node that stands for a server, a worker for a process, an executor for a thread, and a task for an object. Thus, Storm has a hierarchical structure such that a node has multiple workers, a worker has multiple executors, and an executor has multiple tasks. In this article, we use this parallelism of Storm to implement the proposed distributed model of binary Bernoulli sampling.
Distributed processing model of binary Bernoulli sampling
As described in the “Introduction” section, the existing binary Bernoulli sampling results in the coordinator bottleneck (Problem 1 in Table 1) and the excessive communication overhead (Problems 2 and 3 in Table 1) in large data stream environments. In this section, we analyze these problems in detail and propose a distributed processing model to solve the problems.
Problem 1 occurs when the Coordinator cannot process a large amount of candidate data received from the Sites in real time. In particular, this coordinator bottleneck occurs when the number of Sites increases or the data streams explode. That is, although multiple Sites perform the pre-sampling to alleviate the overhead of the Coordinator, there is a limitation in that only one Coordinator processes all the candidate data in real time in the large-capacity stream environment. Therefore, in this article, we propose a multiple-coordinator structure in which multiple Coordinators process candidate data in a distributed manner to solve Problem 1 of coordinator bottleneck.
Figure 4 shows the operational architecture of Sites and Coordinators in binary Bernoulli sampling, where we adopt the multiple-coordinator structure. As you can see, the mapping structure of Coordinators and Sites changes from

Operational architecture of binary Bernoulli sampling using the multiple-coordinator structure.
Problem 2 is an excessive communication overhead problem that occurs when some Sites are located in external networks. Each Site communicates with the Coordinator bidirectionally to exchange the candidate data and round information. However, if the Site is located in the external network, a large communication cost is incurred in data transmission compared to the internal network. This communication cost is also a major cause in lowering the sampling performance. Therefore, in this article, we propose an integrated framework structure that enables both Site and Coordinator functions to operate in a single framework to alleviate the external communication cost.
Figure 5 shows a cluster architecture that provides both Site and Coordinator functions in an integrated framework structure. As shown in the figure, regardless of where the data stream occurs, all the Sites work in an integrated distributed framework. We note here that the integrated framework works over a cluster of nodes connected in an internal network. More precisely, the data stream located outside the framework transmits data to the Site located inside the framework through external communication, and the Site delivers the candidate data to the Coordinator through internal communication. Thus, only internal communications occur in between Sites and Coordinators in the integrated framework. The round information is also delivered from Coordinators to Sites through internal communication. As a result, by introducing the integrated framework structure, both Sites and Coordinators in the framework perform internal communication only, and we can significantly reduce the communication overhead of Problem 2.

Integrated framework structure of managing Sites and Coordinators in cluster nodes of an internal network.
Problem 3 is an additional internal communication overhead problem caused by applying the multiple-coordinator structure. That is, the multiple Coordinators applied to solve the bottleneck of Problem 1 cause additional communication overhead between Sites and Coordinators and between Coordinators. In particular, since the proposed binary Bernoulli sampling works in a multi-node environment rather than a single node, Sites and Coordinators usually operate in different nodes, resulting in a lot of substantial node-to-node communications. In this article, to solve this internal communication overhead, we use a shared memory structure where several nodes simultaneously share data. Using the shared memory, we can change bidirectional communication between Sites and Coordinators to unidirectional communication from Sites to Coordinators. Also, all Coordinators as well as all Sites can share the round information through the shared memory. In addition, we can eliminate the communication among Coordinators by storing the sampling results in the shared memory.
Figure 6 shows the structure of applying the shared memory to binary Bernoulli sampling. Compared to Figure 5, we can see that three communication configurations have changed. First, the bidirectional communication between Sites and Coordinators is changed to unidirectional. Second, the round information is transmitted to Sites through the shared memory without direct communicating with Coordinators. Third, by storing the sampling results in the shared memory, we can eliminate communications between Coordinators, thereby solving the problem of communication overhead due to the multiple-coordinator structure. Although using shared memory may cause some additional communication overhead, we use Redis17,18 for shared memory for the following reasons. First, the communication cost is greatly reduced by the three optimizations described above. Second, Redis provides very fast access features since it is an in-memory DBMS. Third, the communication overhead of Redis caused by multiple coordinators structure is much smaller than coordinator bottleneck overhead caused by the single coordinator structure. In this article, we construct a distributed processing model of binary Bernoulli sampling using the three proposed structures: multiple-coordinator, integrated framework, and shared memory structures, which correspond to solutions of Problems 1, 2, and 3, respectively.
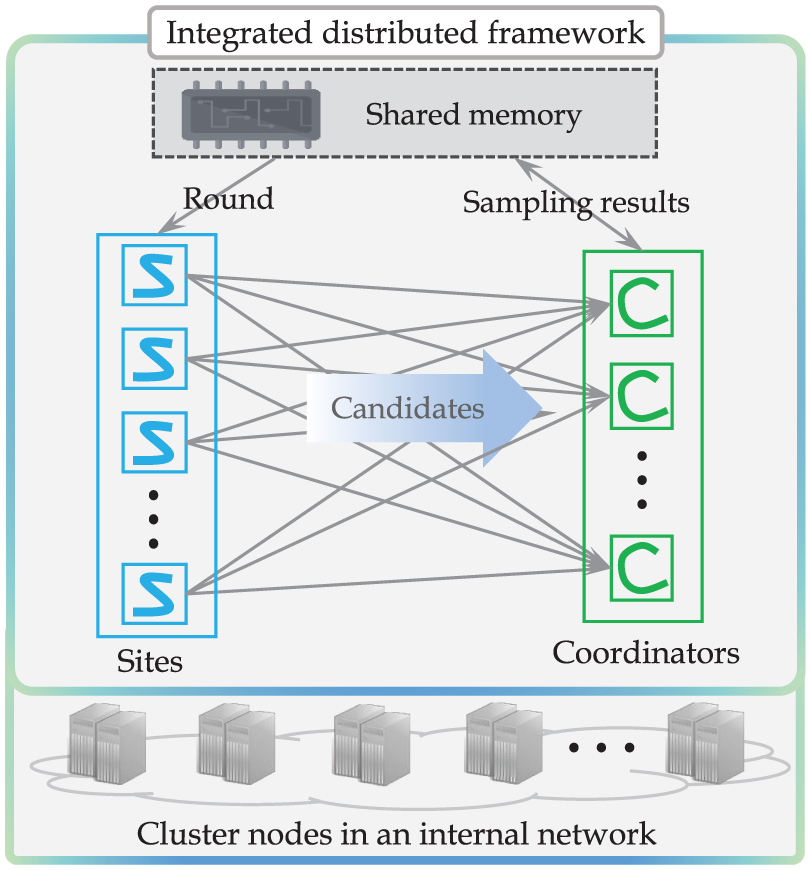
Communication structure of Sites and Coordinators using shared memory.
Figure 7 shows the overall architecture of the distributed processing model of binary Bernoulli sampling. As shown in the figure, the proposed model adopts the multiple-coordinator, integrated framework, and shared memory structures discussed so far. Operation procedures of the proposed distributed processing model are as follows:
The system receives multiple data streams in the same manner as the original binary Bernoulli sampling.
Each Site performing the pre-sampling reads the current round from the shared memory.
It selects candidate data from the input stream for the current round and sends the selected candidate data to the Coordinator.
The Coordinator compares the candidate data received from the Site with the sample data in the shared memory and selects the intermediate or final sample data. Note that for sharing the intermediate or final sample data, Coordinators maintain the sampling results in the shared memory.
If one of Coordinators changes the current round, it reflects the new round in the shared memory so that Sites and other Coordinators use the same round information.
Since the sampling results are stored in shared memory, the user reads and uses the results from the shared memory.

Overall architecture for distributed processing of binary Bernoulli sampling.
Storm-based distributed binary Bernoulli sampling
In this article, we implement the proposed distributed processing model in Apache Storm to verify its practicality. Storm is a representative distributed processing system, specializing in processing real-time data streams. Figure 8 shows an overall framework of Storm-based binary Bernoulli sampling, which operates on an Apache Hadoop cluster. 19
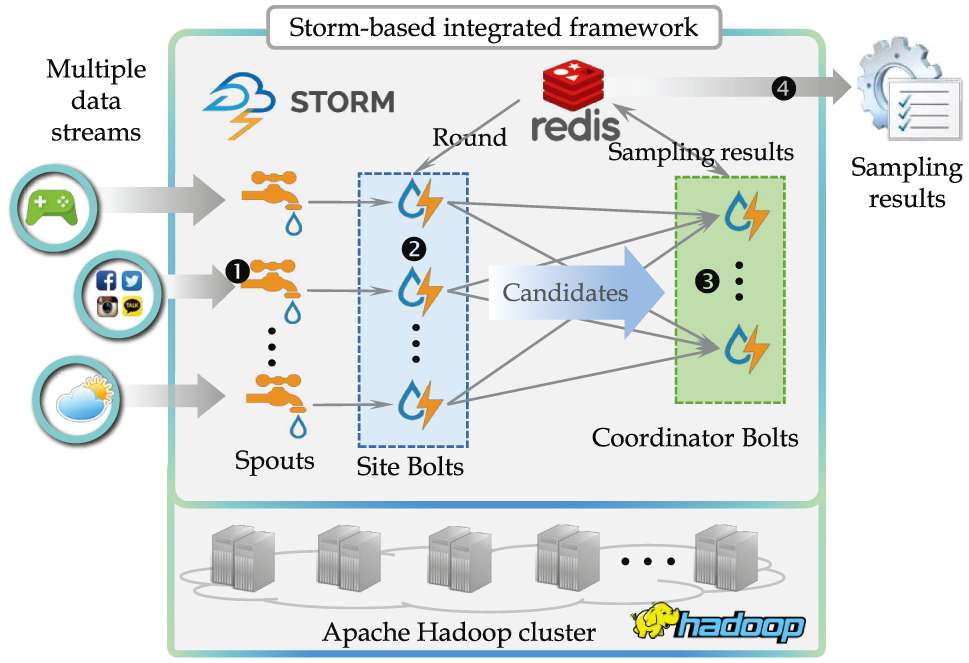
Overall framework of Storm-based binary Bernoulli sampling.
Binary Bernoulli sampling can also be implemented in other distributed processing platforms such as Apache Spark. The reasons why we choose Storm rather than Spark are as follows. First, Spark is not suitable for the actual practical stream environment because it processes continuous stream data in a batch manner, and this batch style incurs severe waiting time until the batch is full. As you know, Spark focuses on processing a large volume of stored data rather than streaming data. Second, Spark cannot control the parallelism properly that largely affects the processing performance. Third, through the preliminary experiment, we already see that Storm outperforms Spark in processing stream data. As shown in Table 2, although Storm is worse than Spark in query processing time, the overall turnaround time of Storm is shorter than that of Spark due to the very long queueing time of Spark. By these three reasons, we choose Storm as the distributed processing platform of real stream data.
Stream data processing times of Storm and Spark.

Comparing Figure 8 with Figure 7, there are three major changes. First, we implement all Sites and Coordinators in Figure 7 as Bolts in Storm in Figure 8. In Storm, all processing takes place in Bolts. Thus, we implement Sites and Coordinators performing the sampling operation Site Bolts and Coordinator Bolts, respectively. Second, we implement multiple data streams as Spouts in Storm. A Spout is a component that refers to the source of a data stream. In Storm, a Spout reads data from the data source and sends the data to one or more Bolts. Thus, as shown in Figure 8, we use Spouts so that receive the stream data from inside or outside, convert the data to tuples, and send the tuples to Site Bolts. Third, we implement the shared memory as Redis.17,18 Redis is a representative distributed in-memory DBMS that can share the server’s memory-resident data in real time in distributed environments. Thus, we use Redis so that Site and Coordinator Bolts distributed at multiple nodes can share sampling results and round information in real time.
If multiple coordinators share sampling results in shared memory, two synchronization problems may occur. The first problem is locking synchronization for shared data. In this article, we solve this problem using Redis,17,18 an in-memory DBMS. As a key function of DBMS, Redis basically provides locking mechanism, and we use its locking features to access shared data in a synchronized manner. The second problem is logical synchronization. This problem means that while a coordinator redistributes the sample, other coordinators may add the data to the sample at the same time. In this article, we solve this problem by sharing an atomic flag in shared memory. Using the atomic flag, while a coordinator accesses the sample, other coordinators cannot proceed the sampling at the same time. We reflect this flag (sync-flag) mechanism in the algorithm of Figure 9.

Distributed binary Bernoulli sampling algorithm over Apache Storm.
The operation structure of the proposed Storm-based binary Bernoulli sampling consists of the following four stages:
Data input stage: Data streams generated in real time from inside or outside are transmitted to Spouts. Then, Spouts convert the received stream data into tuples and send the tuples to Site Bolts.
Candidate data selection stage: Each Site Bolt determines whether the data received from the Spout corresponds to candidate data in the current round. It then sends the selected candidate data to the Coordinator Bolt. Here, all nodes share the same round information in real time through Redis.
Sampling stage: Each Coordinator Bolt may update the sample by comparing the candidate data received from the Site Bolt with the current sample data. In this process, we store the current sample data in Redis so that Coordinator Bolts share the data in real time.
Sampling results delivery stage: We deliver the final sampling results stored in Redis to the user or store them into storage devices.
By repeating the above four stages, we can efficiently process binary Bernoulli sampling in the distributed environment of Storm. Figure 9 shows the Storm-based binary Bernoulli sampling algorithm proposed in this article. First, the Spout algorithm receives the data stream from multiple data sources and then transforms the data stream into tuples to be processed in Storm. And it sends the tuples to Site Bolts. Next, the Site Bolt algorithm receives the data from Spouts and fetches the current round from Redis. If the binary string of the data is 0 up to the current round, it selects the current data as candidate data and transmits it to the Coordinator Bolt. Finally, the Coordinator Bolt algorithm takes candidate data from the Site and fetches the current round from Redis. At this time, if the (round + 1)th element of the binary string is 0, it inserts the current data into the final samples. If the sample data are full and the current round is over, the Coordinator redistributes the samples and increases the current round of Redis by 1. For the detailed internal procedures, readers are referred to the binary Bernoulli sampling algorithm by Cormode et al. 11
Experimental evaluation
Experimental data and environment
In the experiment, we measure the actual execution time to compare the proposed Storm-based binary Bernoulli sampling and the existing binary Bernoulli sampling, which operates in a single node, by varying the amount of data streams. The hardware platform consists one master node and eight slave nodes: the master node is equipped with Xeon E5-2630V3 2.4 GHz, 8 Core, 32 GB RAM, and 256 GB solid state drive (SSD); each slave node is equipped with Xeon E5-2630V3 2.4 GHz, 6 Core, 32 GB RAM, and 256 GB SSD. The software platform is CentOS Linux 7.2.1511, and we implement sampling algorithms using Java language. We use Ethernet with 1 Gbps bandwidth as the network. The data used in the experiment is a stream composed of <real number, text string> pairs, and we input 1,000,000 data pairs into each Spout.
Next, we support load balancing and failure recovery functions through Storm. First, we use Shuffle grouping 14 of Storm to distribute the candidate samples from the sites to the coordinators. Shuffle grouping randomly distributes the data to multiple nodes. Actually, we can also use other grouping methods such as Direct and Local-or-Shuffle groupings of Storm, which means that our proposed method is orthogonal to the grouping methods of Storm. Second, Storm handles node failures using the Nimbus failover algorithm, and thus, using Storm as the distributed processing platform, we can also handle the node failures.
We conduct two experiments to confirm that the proposed model improves the performance and resolves the bottleneck. The first experiment is to confirm the performance improvement, which is related to Problems 2 and 3 in Table 1. For the fixed number of Coordinator Bolts and for the fixed ratio
Experimental results
First, we explain the experimental results on different numbers of Spouts and different numbers of nodes. Table 3 shows the sampling execution times measured by single-node (i.e. the original binary Bernoulli sampling) and multi-node (i.e. the proposed binary Bernoulli sampling) algorithms, and Figure 10 shows the graph corresponding to Table 3. In the experiment, we increase the number of Spouts and Site Bolts by
Execution times for single-node and multi-node binary Bernoulli sampling algorithms.

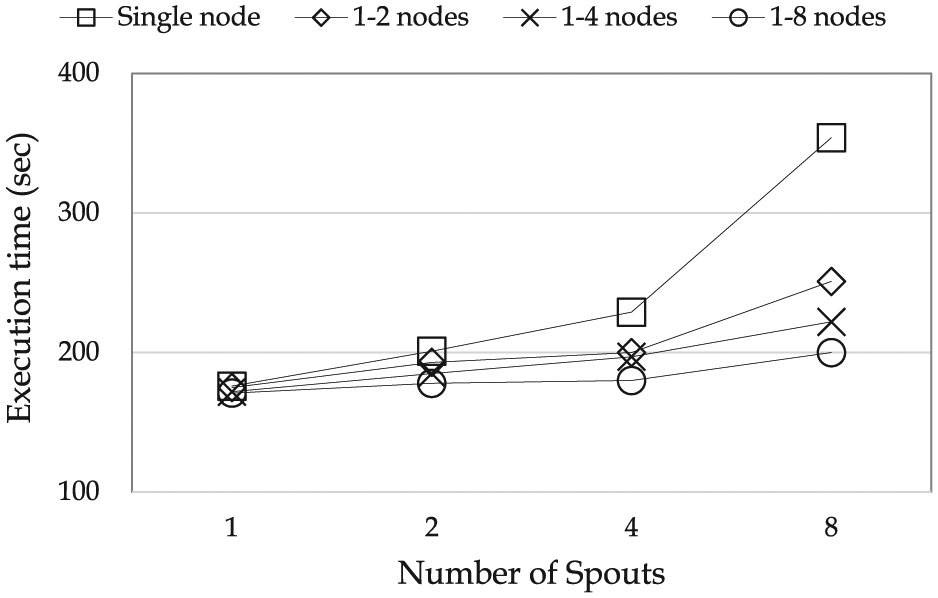
Comparison of execution times for single-node and multi-node binary Bernoulli sampling algorithms.
As shown in Table 2 and Figure 10, the higher the number of nodes, the faster the execution time of the proposed distributed processing model. In particular, we note that as the number of Spouts increases, that is, as the amount of input streams increases, the execution time for multiple nodes is greatly reduced. More specifically, when the amount of input data increases by a factor of 2, the execution times of single node, 1–2 nodes, 1–4 nodes, and 1–8 nodes, increase by 1.54 times, 1.25 times, 1.12 times, and 1.11 times, respectively. This is because as the number of nodes increases, the number of Spouts, Site Bolts, and Coordinator Bolts configured in one node decreases, which increases each node’s processing performance. In Figure 10, we also note that in the same bandwidth environment, as the number of nodes increases, the processing performance also increases. It means that the more nodes we use, the higher bandwidth utilization and the better processing performance we can get.
Second, we explain the experimental results on the coordinator bottleneck, where we investigate how much the bottleneck is alleviated according to the number of Coordinator Bolts. In the bottleneck experiment, we use one master and eight slave nodes and set the number of Spouts to four and the number of Site Bolts to eight, respectively. Then, we measure the sampling time by increasing the number of Coordinator Bolts from one to five. Table 3 shows the sampling execution times according to the number of Coordinator Bolts, and Figure 11 shows the graph corresponding to Table 4. The experimental results show that the processing time in Coordinator Bolts occupies most of the entire sampling time. This means that if we can improve Coordinators’ performance, we can also improve the overall sampling performance.

Sampling times according to the number of Coordinator Bolts.
Site and Coordinator Bolts’ processing times according to the number of Coordinator Bolts.

Let us investigate in detail the results of Table 4 and Figure 11. First, in case of one Coordinator Bolt, it cannot process all the data due to an excessive bottleneck, and we cannot measure the sampling execution time. Next, as the number of Coordinator Bolts increases, their processing times greatly decrease, and accordingly, the entire sampling times also greatly decrease. Briefly speaking, as the number of Coordinator Bolts increases, the sampling time is shortened. This means that we can resolve the bottleneck problem by increasing the number of Coordinator Bolts. Another notable aspect of the experimental results is that there are no significant performance differences between experiments with five Coordinator Bolts and four Coordinator Bolts. This is because eight Site Bolts already perform pre-sampling, so four Coordinator Bolts are enough to process all candidate data. It means that there is no limit on the scalability of Coordinator Bolts. This is because the number of communications between the Site Bolts and the Coordinator Bolts is only proportional to the amount of data streams regardless of the number of Coordinators. Thus, as the number of Coordinator Bolts increases, the processing performance also improves gradually. In summary, when the number of Coordinator Bolts increases from two to five, the performance is improved about 1.8 times, 1.4 times, and 1.2 times, respectively. This performance improvement shows up to the case where the number of Coordinator Bolts is
Experimental results presented so far show that the proposed distributed model of binary Bernoulli sampling significantly improves the sampling performance and at the same time largely alleviates the coordinator bottleneck. Thus, we believe that the proposed model is an excellent approach suitable for handling a large amount of data streams in the multi-source stream environment.
Related work
Distributed sampling in this article is a research field that combines sampling with distributed environment. Sampling is a technique for extracting samples well reflecting characteristics of original data, that is, population. Generally, sampling extracts as many samples as desired by a certain criterion or probability from the population. However, traditional sampling techniques cannot efficiently handle huge amounts of data such as social network data, graph data, and image/video data due to a lot of processing cost. In order to reduce the processing cost, there have been many research efforts on applying distributed processing mechanism to sampling.
Levin and Kanza 23 proposed the distributed sampling for processing multi-stratified-sampling queries in the social network environment. This study uses the MapReduce framework to stratified-sampling social big data. In addition, graph analysis showing the relationship between users has been actively studied in SNS. Since graphs are complex structures of big data, many studies try to use the distributed processing platform such as MapReduce24,25 and Apache Spark. 26 However, they focus on sampling of the collected and stored large data in a batch manner.
Haque et al. 27 proposed a MapReduce-based sampling approach to improve the performance of image-based machine learning. Similarly, Xing et al. 28 also proposed the MapReduce-based sampling for earth observation data processing. In addition, there have been many studies related to distributed processing of image sampling. However, these studies are mostly aimed at batch processing of large data rather than real-time processing of stream data.
As we have seen so far, most of the previous studies focus on distributed sampling for large-scale data in the batch environment. In other words, distributed real-time sampling in the stream environment, especially, multi-source sampling has not yet been studied. Therefore, Storm-based binary Bernoulli sampling proposed in this article can be regarded as a novel approach to support multi-source data streams sampling which is difficult to solve with existing sampling.
Conclusion
In this article, we proposed a distributed processing model of binary Bernoulli sampling and implemented the model on Apache Storm. In the existing binary Bernoulli sampling operated in a single-node environment, multiple Sites sent a large volume of stream data to one Coordinator, and thus, the coordinator bottleneck occurred in a large data stream environment. In addition, frequent communications over internal or external networks might lead to excessive communication overhead. In order to solve these coordinator bottleneck and communication overhead problems in binary Bernoulli sampling, in this article, we proposed a novel distributed processing model that performed sampling at multiple nodes. Also, to verify the practicality and scalability of the proposed model, we implemented it in Apache Storm, a representative distributed processing system. The experimental result on the number of nodes showed that the proposed Storm-based binary Bernoulli sampling reduced the execution time by up to 1.8 times compared to the existing single-node-based binary Bernoulli sampling. In addition, the experimental result on the number of Coordinators showed that the proposed model shortened the sampling execution time up to 1.8 times.
From these results, we conclude that the proposed model is a very meaningful study not only to extend the sampling into the distributed model of the multi-source environment but also to verify the performance improvement through actual implementation on a practical distributed processing system. As the future work, we will focus on reducing the communication overhead. For this, we will first investigate how to apply InfiniBand, 29 which has a larger bandwidth than Ethernet, to our Storm-based platform. We will also consider data encoding methods to improve data distribution efficiency.
Footnotes
Acknowledgements
Earlier preliminary versions of this article are published in ICIC Express Letters, November 2017, and Proc. of IEEE Int’l Conf. on Big Data and Smart Computing, Shanghai, China, January 2018. This is a fully extended and completed version of those preliminary works.
Handling Editor: Paolo Bellavista
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partly supported by Institute for Information & Communications Technology Promotion (IITP) grant funded by the Korea government (MSIP) (no. 2016-0-00179, Development of an Intelligent Sampling and Filtering Techniques for Purifying Data Streams). This work was also partly supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Science and ICT (NRF-2017R1A2B4008991) and Korea Electric Power Corporation (grant number: R18XA05).