
Abstract
In this article, the authors propose a new approach to automate the analysis of the political discourse of the citizens and public servants, to allow public administrations to better react to their needs and claims. The tool presented in this article can be applied to the analysis of the underlying political themes in any type of text, in order to better understand the reasons behind it. To do so, the authors have built a discourse classifier using multi-scale convolutional neural networks in seven different languages: Spanish, Finnish, Danish, English, German, French, and Italian. Each of the language-specific discourse classifiers has been trained with sentences extracted from annotated parties’ election manifestos. The analysis proves that enhancing the multi-scale convolutional neural networks with context data improves the political analysis results.
Keywords
Introduction
A large part of citizen participation in politics occurs in the written media: newspapers, online forums, social media and so on. Furthermore, the rise of new communication technologies has allowed citizens to become participants in the construction of the political agenda, forcing political parties to use more direct means of communication than the mainstream press and media. For this reason, new ways to analyse text with political content in an automated way must be found.
For that purpose, the authors propose a multidisciplinary approach, to build a text categorization classifier using manually annotated sentences from political manifestos and use it to analyse the underlying discourse on the claims of both the citizens and the politicians. Therefore, the authors combine the political science knowledge from the social scientists involved in the annotation of the political manifestos with natural language processing, in order to be able to process large quantities of data and study how the political discourse evolves online and off-line.
Since analysing the political discourse is a complex and time-consuming task, the authors propose in this research work a new approach for automatically analysing it in texts using multi-scale CNNs with word embeddings and using two types of context data as extra features: the previous sentence in the manifesto and the political leaning of the person. These extra features drastically improve the performance of the classifier as it will be demonstrated in the evaluation section.
This article is organized as follows. Section ‘Related work’ offers an overview of previous related work on the use of political manifestos for automated text analysis, sentence classification and social network analysis. Section ‘Automated analysis of the political discourse’ describes the research framework: used training data, performed data pre-processing and used architecture. Section ‘Evaluation’ explains how the developed classifier has been evaluated and its results. Finally, section ‘Conclusion and future work’ draws some conclusions and proposes further work.
Related work
Even though historically there has not been relevant works concerning the automatic codification of political manifestos and the use of this codification schema for the analysis of other types of political texts besides political manifestos, recently there have been some authors who have worked in this field.
In 2016, Zirn et al. 1 presented an approach for automated classification of political manifestos. The authors trained and validated their approach using six US manifestos (Republican and Democrat manifestos from 2004, 2008 and 2012 elections). Instead of using the original codification schema of 56 categories, they only worked with the seven policy domains. Their approach consisted in combining two different classifiers: one including only information about the sentence and the second one a binary classifier which predicts if two adjacent sentences have the same code or not. Finally, Zirn et al. combine these two classifiers with information about the topic distribution in the corpus (rules representing the conditional probabilities of domain transitions). They reached the best performance combining the previously explained two classifiers and using a transition rule which indicates that consecutive sentences have the same domain label.
However, this approach cannot be applied to other types of political texts since Zirn et al. used the distribution of topics, sequences of topics and topic transitions in the manifestos as an extra feature. For example, the structure of the text to be analysed can be completely different to the structure of a manifesto where sections or subsections with similar topics are discussed together and therefore topic transitions are easier to predict. In the presented approach, this is solved using the previous sentence or the political leaning of the person who has written the text are used instead of features such as topic transitions or distribution of topics.
Nanni et al. 2 used annotated political manifestos and speeches in order to analyse the speeches from the 2008, 2012 and 2016 US presidential campaigns in the seven main domains defined by the manifestos project. The main difference between Nanni et al.’s work and this research is that first, only annotated manifestos have been used as training data (while Nanni et al. used annotated speeches too) to later apply this knowledge to another texts, and second, our research work uses more than the seven main domains defined by the manifestos project.
In 2017, Glavaš et al. 3 proposed an approach for cross-lingual topical coding of sentences from electoral manifestos using as training data, manually coded manifestos with a total of 77,500 sentences in four languages: English, French, German and Italian. Using convolutional neural networks (CNNs) with word embeddings and inducing a joint multilingual embedding space, Glavas et al. obtained better results than monolingual classifiers in English, French and Italian. However, they achieved worse results with their multilingual classifier than a monolingual classifier in German. According to Glavas et al., this happened because they had two decades of German political manifestos covering a wider span of political issues with a high language variation.
Regarding other approaches of automated analysis of political text, some researchers have detected the polarity of raw text using natural language processing techniques. Iyyer et al. 4 designed a recursive neural network in order to identify the political polarity of a sentence. Authors used two datasets to evaluate their model: an existing one and another one annotated by them by means of crowdsourcing. Authors were able to identify most conservative or liberal n-grams and detect bias more accurately. Similar works have been conducted on Twitter. Rao et al. 5 used word embeddings and long short-term memory (LSTM) recurrent neural networks (RNNs) in order to classify twitter messages as democratic or republicans. Author established the ground truth using Twitter Lists, where users are categorized in different groups (democratic or republican) by other users.
However, some research works 6 have criticized the approach of raw machine learning classification techniques whose objective is to correctly classify the highest percentage of individual documents. According to Hopkings et al., those classification techniques can lead to highly biased category distributions which may derive in inaccurate analysis. Political discourse analyses are not interested in whether a sentence is correctly classified or not, and its goal is to globally analyse how the discourse evolves, which are the main topics of interests and so on. In other words, political discourse analyses are interested in the aggregate proportions of the topics. To solve this problem, authors proposed to use the misclassification probabilities in order to correct the predicted category proportions.
In regard to the natural language processing techniques used in the area, most of them have already been mentioned above: different size n-grams, lexicons, web-derived polarity lexicons, 7 word embeddings and LSTMs or raw RNNs. However, the model is based on the work made by Kalchbrenner et al. 8 and Yoon Kim, 9 where Kim presented a model for sentence classification tasks with CNNs trained on top of pre-trained word embeddings. The model improved state-of-the-art benchmarks on four out of seven tasks, sentimental analysis and question classification among them. Furthermore, different researchers have based their work on this model, building new models with different additions depending on the task10,11 or Zhang and Wallace 12 giving some guidelines about how those hyperparameters should be chosen in this kind of models.
Automated analysis of the political discourse
Training data
The main reason why the authors use political manifestos as training data is that political scientists have been manually annotating political parties’ manifestos for years in order to apply content analysis methods and perform political analyses. Some examples of the performed political analyses are the comparison between different types of manifestos (national and European level manifestos by Wüst and Volkens 13 ), analysing how much parties emphasize certain topics and which are their positions in some concrete topics depending on the elections context, 14 how these positions have evolved over the years 15 or to estimate policy positions for political parties on left-right scales using measures such as RILE scale 16 or other alternatives. 17
The precursors of this methodology were the Manifesto Project, formerly known as the manifesto research group (MRG) and comparative manifestos project (CMP). 18 In 2001, they created the Manifesto Coding Handbook 19 which has evolved over the years. The handbook provides instructions to the annotators about how political parties’ manifestos should be coded for later content analysis and a category scheme that indicates the set of codes available for codification. Nowadays, the category scheme for manifestos annotation consists in 56 categories grouped into seven major policy areas 20 (see Table 1): external relations, freedom and democracy, political system, economy, welfare and quality of life and social groups.
Categories in seven policy domains. 20

Due to the high number of available categories for annotation, manifestos annotation is not an easy task even for trained political scientists as Mikhaylov et al. 21 demonstrated, where after examining several annotators’ intercoder reliability in two manifestos they concluded that the coding process is highly prone to misclassification. In order to annotate these types of political texts, annotators need a previous training to ensure maximum reliability and comparability of data which have been annotated by different people. To do so, annotators have to learn a set of coding rules and when to use each of the codes of the coding scheme. Moreover, these annotators must be under the supervision of an expert annotator throughout the whole training process in order to clarify any doubts that may arise.
Political discourse classifier
In order to address the text classification task and demonstrate that context information such as the previous sentence or the political leaning of the person who has written the sentence can improve the performance of an automated political discourse analyser, the authors have built a classifier using CNNs with Word2Vec word embeddings. Recently, CNNs have achieved excellent results in several text classification tasks.9,22,23 This, combined with the fact that this type of classifier allows the use and fine-tuning of word embeddings, allowing us to extract knowledge from non-annotated texts, is the reason why this approach has been adopted.
Semantic embeddings for sentence representation
The inputs of the model are the sentences which are fed to the neural network as sequences of words. These sequences have a maximum length of 60 words. The maximum length has been decided after an analysis of the corpus sentences’ length and detecting that most of the sentences have 60 or less words. Therefore, the CNNs used for this task have an input size of 60.
However, the words are not inserted as raw text to the CNN. The words are inserted as word vectors, a multidimensional representation of each word. Those word vectors have been generated using the Word2Vec 24 unsupervised learning algorithm, which produces a large vector space having non-annotated raw text as input. Using Word2Vec, each word of the corpus is positioned in a multidimensional vector space taking into account its context (its surrounding words). Word’s position in the N-dimensional vector space (being N the number of dimensions of the defined vector space) is used as its representation (word vector).
For example, given a sentence
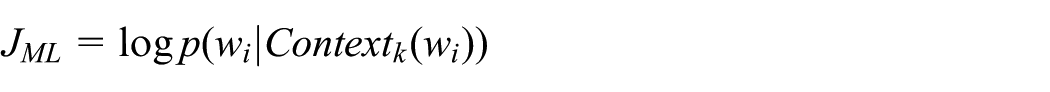
The authors have chosen 300 as word vectors’ size (number of dimensions of the multidimensional space where the words are positioned) to take advantage of already pre-trained Word2Vec models in several languages published by Kyubyong Park. 25 However, for the Spanish Word2Vec model, the authors have taken advantage of a 300 Word2Vec model created with 3 billion words. 26 In the case of the English Word2vec, the authors have used a Word2vec model pretrained with Google News corpus (3 billion running words).
Once all the word vectors have been computed, the following is performed. First of all, a dictionary D where words are mapped to indexes
Therefore, the embedding matrix works as a dictionary whose input is the word index and its output is the vector representation as it can be seen in Figure 1. The embedding matrix can be both static and non-static. On one hand, the static approach treats all the word vectors as static values which cannot change through the training process and therefore all those weights per word defined by Word2Vec remain constant through all the training. On the other hand, a non-static embedding matrix changes as the training process evolves since the word vectors are interpreted as new parameters for the model and they are fine-tuned during the training. The authors have opted for the non-static word-embedding since it improves model’s performance. 9

Raw text transformation into a matrix of word vectors.
Convolutional model for political discourse classification
Once the phrase has been transformed from a sequence of words to a sequence of word indexes and finally to a sequence of word vectors (see Figure 1), the phrase can finally be fed into the CNN, since the sequence of word vectors are in fact a matrix which dimensions are
The CNNs are a specific type of neural networks with neurons, weights and biases where convolution operations are performed and had been traditionally used for recognizing visual patterns directly from images (pixels). 27 However, as previously has been explained, in recent years, CNNs have also been used for text classification. In brief, convolution operations consist in moving different windows (filters made of neurons) with different sizes (filter sizes) analysing different regions in the matrix (an image or a list of word vectors) to extract different features. The proposed model performs convolution operations with three different filter sizes, batch normalization 28 and ReLU as the activation function. Batch normalization acts as an extra regularizer and increases the performance of the model.
The defined filter sizes are
After the convolutional layer, there is a pooling layer whose objective is to reduce the dimensionality of the incoming data. There are different pooling strategies: average pooling, max-pooling, 1-max-pooling and so on. The authors have opted for the 1-max-pooling 29 strategy since it has been proved in Zhang and Wallace 12 that is the best approach for natural language processing tasks. It captures the most important feature (the highest value) from each of the feature maps. Therefore, the output of the pooling is a feature per filter which are later concatenated into a feature vector.
Next, a dropout 30 rate of 0.5 is applied as regularization in order to prevent the network from over-fitting, followed by a fully connected layer with ReLU as the activation function and batch normalization. Then, a 0.5 dropout is applied. 12 Finally, the softmax function computes the probability distribution over the labels.
To sum up, the flowchart of the model is the following (see Figure 2):
The phrase and the previous phrase are inserted as a list of words.
The embedding matrix replaces each word with its corresponding word vector, generating a sequence of word vectors from a sequence of words.
The phrase and the previous phrase are fed into two different structures of CNNs with 100 filters and filter sizes of
The 1-max-pooling reduces the dimensionality of the feature maps generated by each group of filters.
Once their dimensionality has been reduced, the feature maps generated from the phrase and the previous phrase are concatenated.
If the political party to which the text belongs to is used, its one hot codification is concatenated with the feature extracted from the CNNs.
A dropout rate of 0.5 is applied.
Then, to classify the phrases to the objective political topics, a fully connected layer with ReLu as activation function is used.
A dropout rate of 0.5 is applied.
The layer with softmax computes the probability distribution over the labels.
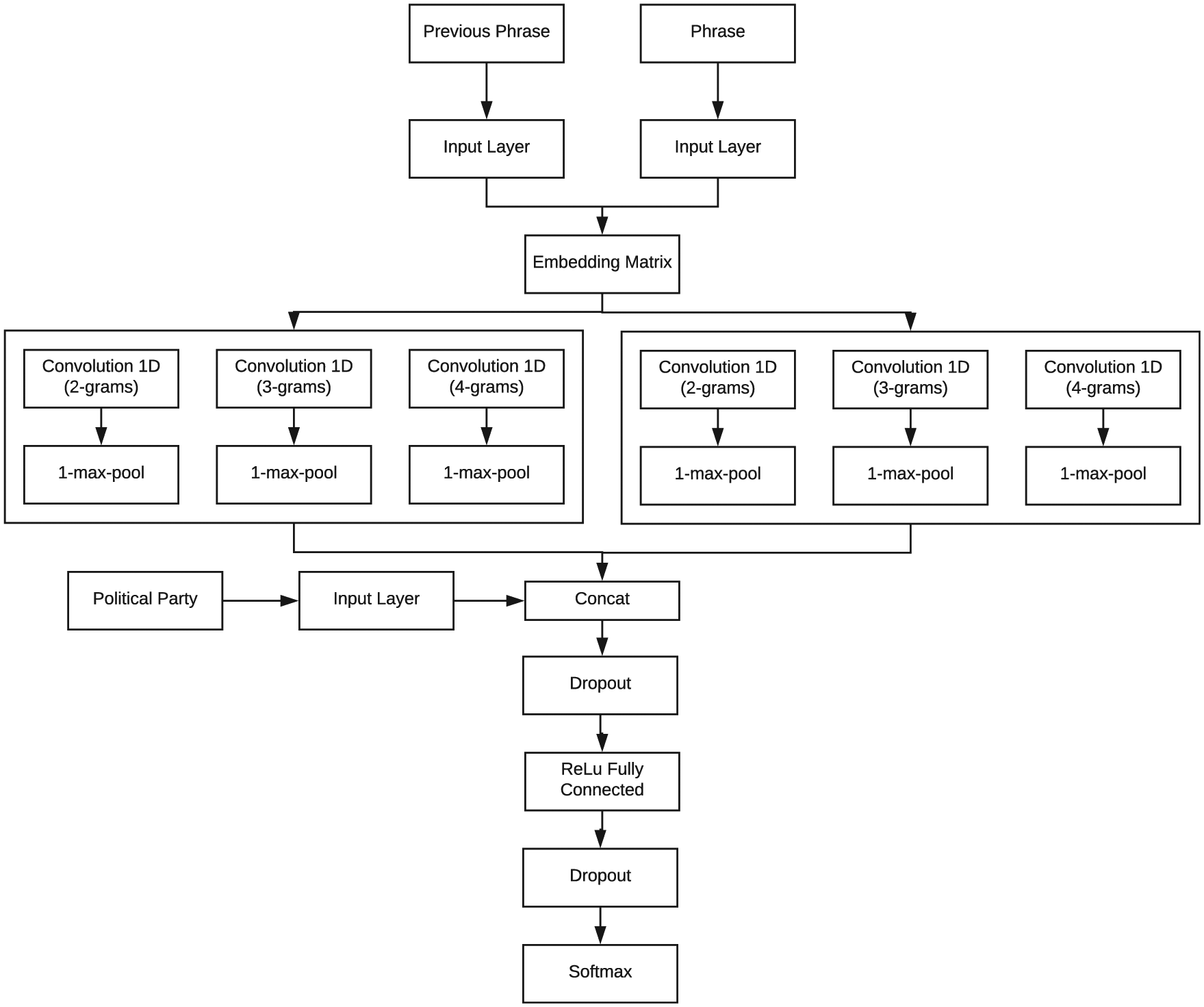
Multi-scale CNN architecture for political discourse analysis.
The categorical cross-entropy loss has been used as training objective function since it supports multiclass classifications. Regarding the optimizer, the optimization has been performed using Adam 31 with the parameters of the original manuscript.
Contextual data as new inputs
Regarding how the authors have added the previous phrase to the model as a new input in order to improve the performance of the model as it will be demonstrated in the next section, two different approaches have been tested:
As a second channel in the convolutional layers: when convolution operations are applied to text only one channel is used, the channel where the sentence to be classified is inserted. However, in this approach, a second channel is used to insert the previous sentence. Therefore, the convolution operations are applied to two channels.
Replicating for the previous phrase, the same convolution-pooling process is used in the actual phrase as it can be seen in Figure 2.
With regard to the political leaning, it is represented with a one-hot encoding scheme. Therefore, the size of the one-hot encoding will vary depending on the number of political parties whose manifestos has been used to train the model. Then, the authors have concatenated a one-hot-encoding representation of the political party which the phrase belongs to, to the feature maps obtained after the convolutions as it can be seen in Figure 2.
Evaluation
Dataset
The experimentation performed in this research work has been done using Manifesto Project’s public corpus of annotated political manifestos. 32 In particular, political manifestos written in Spanish, Finnish, Danish, English, German, French and Italian have been used (see datasets’ statistics in Table 2).
Datasets’ statistics. 32

Results and discussion
The proposed approach has been evaluated using seven different datasets (one per language) and two types of codifications for the political discourse: domains and subdomains:
Domains: the seven major policy areas in the Manifestos’ project codification schema.
Subdomains: the 56 categories defined by the Manifestos’ project codification schema
As it can be seen from Table 3, the distribution of samples over the seven domains is imbalanced in the seven languages. When domains like External Relations and Freedom and Democracy usually have around 8% and 7% of the samples, respectively, Economy and Welfare and Quality of Life have more than 60% of the samples. With regard to the subdomains, the imbalancedness is even worse since the already imbalanced domain samples are split in 56 different subdomains where some classes have very few samples. For instance, in the Spanish dataset the category 504 (Welfare State Expansion) has 9.05% of the samples, while 502 (Culture) and 204 (Constitutionalism: Negative) 3.9% and 0.25%, respectively.
Domain codes’ distribution per dataset.

Due to the imbalance, the results have been presented using three different measures: the accuracy rate, the F-Measure and G-Mean. Moreover, in order to statistically evaluate the improvement given by the auxiliary information, the recommendations provided by Demšar 33 have been followed. The author proposes the use of non-parametric statistical tests to check whether there are differences among different algorithms or not. Specifically, Demšar concludes that Friedman test 34 with the corresponding post hoc tests is the most suitable approach when comparing more than two classifiers over different datasets.
In order to evaluate the proposed approach, the dataset has been divided into two different subsets: training and validation sets (85%), and test set (15%). The training and validation set has been used in order to create models with fivefold cross-validation to later test their performance with the same test set. The reason why the authors have split the dataset in two subsets and then apply cross-validation to one of them is because early stopping 35 has been used in order to stop model’s training when it started to over-fit. Early stopping compares the training accuracy with the validation accuracy and after some epochs without any improvements in the validation accuracy it stops the training. However, the model may have over-fitted with respect to the validation set; therefore, a third set, the test set, is needed in order to measure the real performance of the model.
Furthermore, since the dataset is imbalanced, the authors have applied stratification in order to preserve the same percentage of samples for each class. Using this approach the authors are able to evaluate how each class is classified since it ensures that in each of the subsets there will be a representation of each class.
Tables 4 and 5 show the results of domain and subdomain datasets, respectively, for each of the used languages. Five different classifier configurations are tested with each of the datasets:
E1. Only the sentence to be classified with no additional context;
E2. The sentence plus the political party which belongs to;
E3. The sentence plus the previous sentence in an additional channel on the CNNs;
E4. The sentence plus the previous sentence in another CNNs structure, concatenating the features extracted by both networks;
E5. The sentence, the political party to which the sentence belongs to and the previous sentence in another CNN.
Domain results for each one of the experiment configuration and datasets.

The accuracy (acc), f-measure (F1) and G-Mean (G-M) of each experiment is shown.
The best scores are highlighted in bold.
Subdomain results for each one of the experiment configuration and datasets.

The accuracy (acc), f-measure (F1) and G-Mean (G-M) of each experiment is shown.
The best scores are highlighted in bold.
If we compare the accuracy, F1 and G-mean scores shown in Tables 4 and 5 without any statistical analysis, the following conclusions can be drawn:
Adding the previous sentence (as a channel or in another CNNs structure) improves the performance of the classifier on domains and subdomains.
Adding the political party to which the text belongs to significantly improves the performance of the classifier in some languages (more than 1 point in F1): Spanish, Finnish, Danish and French. This improvement is more remarkable when classifying the sentences on subdomains.
The previous phrase and the political party are not always complementary features when classifying domains as it can be seen in Table 4. However, they are complementary when classifying subdomains (see Table 5).
Another way to analyse the improvement resulting of each approach is to apply the Friedman test. However, when a statistical analysis of the results is made, the conclusions vary slightly. The Friedman test has been applied with two different metrics: F-measure and G-mean. On one hand, after applying the Friedman test with the F-measures, the resulting p-value is
Since the two p-values are smaller than 0.01, the null hypothesis (that all algorithms perform equally) can be rejected. Once the null hypothesis has been rejected, the corresponding post hoc tests can be performed in order to compare the different algorithms between them and analyse which are different.
In order to compare all the algorithms pairwise, Demar proposes the use of the Nemenyi test.
36
This post hoc test determines the critical difference
The Nemenyi test has been performed with a significance of
Differences between the average ranking of the tested algorithms computed with the Nemenyi test and F-measures of the classifiers.

Differences between the average ranking of the tested algorithms computed with the Nemenyi test and G-means of the classifiers.

After analysing the results shown in Tables 6 and 7, the following conclusions can be drawn:
The comparisons where the null hypothesis has been rejected (in bold font) are quite similar in both tables. However, contrary to F-measure, using the G-Mean as metric does not reject the null hypothesis when comparing E3 and E5.
In both cases, it is statistically validated that adding the previous phrase in an additional channel (E3) or another CNNs structure (E4) have a different behaviour than the baseline without any context data. Therefore, it can be affirmed that adding the previous phrase in an additional channel or as another CNNs structure improves the performance of the classifier, as it can be seen in Tables 4 and 5.
Regarding the use of the political party which says the phrase, it has not been possible to statistically validate that there is an improvement when it is used. However, there is an improvement in performance in the majority of performed experiments, particularly when classifying subdomains and it is combined with the previous phrase as it can be seen in Table 5. One of the possible reasons for this could be that it has not been possible to perform the statistical tests with a greater number of datasets.
Conclusion and future work
In this research, the authors have introduced and validated a novel approach for automated analysis of the political discourse in texts, which helps to better understand its underlying themes. The proposed approach is based in multi-scale CNNs enhanced with context information (the political leaning of the speaker and the raw text of previous phrase, which to the best of our knowledge has not been used before). The proposed approach has been validated using two different types of codifications for the political discourse: domains (7 categories) and subdomains (56 categories).
The proposed system has been validated using the Friedman test with the corresponding post hoc tests (Nemenyi test). It has been statistically certified that adding the previous phrase as an additional channel or in another CNNs structure improves the performance of the classifier. However, the authors have not been able to statistically validate that the political party which the phrase belongs to improves the performance of the classifier, even though there is an improvement in performance in the majority of performed experiments, particularly when classifying subdomains and it is combined with the previous phrase as it can be seen in Table 5.
As future work, the authors plan to improve the current system by studying how training it with datasets in different languages can help to enhance its generalization capabilities using transfer learning techniques. Author’s intuition is that the abstract representation of the sentences obtained after the convolutional layers will have similar structures for the same categories across different languages. It is also planned to analyse different attention mechanisms to identify the words that are more relevant in each sentence to improve the whole process.
Footnotes
Acknowledgements
We gratefully acknowledge the support of NVIDIA Corporation for the donation of Titan X used in this research.
Handling Editor: Antonino Staiano
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: We gratefully acknowledge the support of the Basque Government’s Department of Education for the predoctoral funding, the Ministry of Economy, Industry and Competitiveness of Spain under Grant No. CSO2015-64495-R (Electronic Regional Manifestos Project).